【大象数据集】大象图像识别 目标检测 机器视觉(含数据集)
一、背景意义
在信息时代,数据的收集和分析技术得到了飞速发展。深度学习算法的出现,为处理和分析这些复杂的鱼类数据集提供了强大的工具。深度学习具有强大的模式识别和特征提取能力,能够从海量的数据中自动学习和发现规律,为鱼类研究带来了新的机遇和方法。例如,通过对大量鱼类图像数据的深度学习分析,可以实现鱼类物种的快速准确识别,这在传统的基于人工特征的分类方法中是难以实现的。
二、数据集
2.1数据采集
首先,需要大量的大象图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示大象特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在标注大象数据集这一任务中,由于大象作为复杂的生物群体,其外观、姿态和环境背景可能具有多样性和复杂性,因此标注工作将面临一定的挑战和工作量。使用标注工具如LabelImg来标注大象数据集将需要耗费大量时间和精力,以确保标注的准确性和完整性。
标注工作的复杂性和工作量突出表现在以下方面:
-
姿态和角度多样性:大象可能出现多种姿态和角度,包括站立、行走、休息等,标注者需要标注每个大象实例的位置和姿态,以确保对其完整性的捕捉。
-
遮挡和多目标情况:在自然环境中,大象之间可能会相互遮挡,或者与其他物体重叠,这需要标注者仔细分析和标注每个目标的边界,以避免遮挡部分的遗漏。
-
背景复杂性:大象生活的生态环境多种多样,可能包括树木、灌木、草地等各种背景元素,标注者需要将大象与背景进行有效区分,确保标注的准确性。
-
数据集规模:大象数据集可能包含大量的图像,每张图像可能涉及多个大象实例,标注每个实例的边界框需要耗费大量时间和精力,工作量较大。

包含3280张大象图片,数据集中包含以下类别
- 大象:陆生动物,以其巨大的体型、长长的象鼻和智慧而闻名。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
在深度学习中,卷积神经网络(CNN)是一种非常适合大象识别的算法,以其在图像处理和分类任务中的卓越表现而广泛应用。CNN的基本结构包括输入层、卷积层、激活层、池化层和全连接层,能够有效地从输入图像中提取重要特征,如大象的轮廓、耳朵和象鼻等。其优势在于特征自动学习,无需手动设计特征提取方法,适应性强,特别适合变化多样的自然环境;局部连接和权重共享显著减少了模型参数数量,提高了训练效率,适合处理大规模图像数据集;平移不变性使得CNN能够有效识别不同位置和角度的大象;随着网络深度的增加,CNN能够提取更高层次的抽象特征,提升识别精度。这些特点使得CNN在大象识别的应用中表现出色,为保护和研究这些重要动物提供了强有力的技术支持。

在大象识别中,卷积神经网络(CNN)可用于多种关键任务,极大地提高了生态研究和保护工作的效率。首先,在识别与分类方面,通过训练CNN模型,能够高效区分不同种类的大象,如非洲象和亚洲象,并进行个体识别,从而为生态监测和保护策略提供数据支持。其次,结合CNN与物体检测框架(如YOLO或Faster R-CNN),可以实现对图像中大象的定位与分类,这不仅帮助研究人员监测野生动物的数量和分布,还能够有效识别并记录其活动模式。第三,运用分割网络(如U-Net),CNN可以对大象进行精确分割,提供更详细的生态行为分析,帮助科学家理解大象在栖息地中的相互作用和环境影响。

3.2模型训练
开发一个YOLO项目以进行大象识别的过程分为多个关键步骤。以下是对每个步骤的详细描述:
数据集准备:在进行模型训练之前,首先需要准备好数据集。数据集通常由图像和相应的标签文件组成。对于YOLO,标签文件包含每个物体的类别及其在图像中的边界框坐标,所有坐标均为相对于图像尺寸的归一化值。详细步骤:
- 收集图像:确保图像质量良好,涵盖不同的拍摄角度和光照条件。
- 创建标签:使用标注工具(如LabelImg)手动标注图像,生成YOLO所需格式的标签文件。
- 组织数据:将图像和标签文件按照一定的目录结构存储,例如分为训练集和验证集。
import os
import cv2def prepare_dataset(images_dir, labels_dir, output_dir):if not os.path.exists(output_dir):os.makedirs(output_dir)for filename in os.listdir(images_dir):if filename.endswith('.jpg'):img_path = os.path.join(images_dir, filename)label_path = os.path.join(labels_dir, filename.replace('.jpg', '.txt'))# 读取图像image = cv2.imread(img_path)height, width, _ = image.shape# 读取标签with open(label_path, 'r') as f:labels = f.readlines()# 处理标签并保存到新的格式with open(os.path.join(output_dir, filename.replace('.jpg', '.txt')), 'w') as out:for label in labels:class_id, x_center, y_center, bbox_width, bbox_height = map(float, label.split())# 归一化边界框坐标x_center /= widthy_center /= heightbbox_width /= widthbbox_height /= heightout.write(f"{class_id} {x_center} {y_center} {bbox_width} {bbox_height}\n")prepare_dataset('images/', 'labels/', 'prepared_dataset/')
设置YOLO环境:在训练模型之前,必须设置YOLO环境,这包括安装所需的库和配置YOLO模型。YOLOv5是一个流行的实现,提供了丰富的功能和灵活性。详细步骤:
- 安装依赖:确保安装Python和相关的深度学习库,如PyTorch和Torchvision。
- 克隆YOLOv5代码库:从GitHub上克隆YOLOv5的代码库,以获取代码和模型框架。
# 安装必要的库
pip install torch torchvision# 克隆YOLOv5代码库
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
配置模型:YOLO项目需要配置模型参数和数据集信息。此步骤通常涉及到创建一个YAML文件,该文件描述了数据集的路径和类别。详细步骤:
- 创建数据配置文件:定义训练和验证数据的路径,以及类别数和类别名称。
- 检查数据路径:确保路径正确,指向准备好的数据集。
# data.yaml
train: prepared_dataset/train # 训练数据路径
val: prepared_dataset/val # 验证数据路径nc: 2 # 类别数
names: ['African Elephant', 'Asian Elephant'] # 类别名称
训练模型:在配置完成后,你可以开始训练模型。训练过程将使用准备好的数据集,通过反向传播调整模型参数,以优化其性能。详细步骤:
- 选择超参数:设置图像大小、批量大小、训练轮数等超参数。
- 运行训练命令:使用YOLO的训练脚本开始训练过程。
# 在YOLOv5目录下执行训练命令
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt --cache
评估模型:训练完成后,需要评估模型的性能,查看准确率、召回率和F1分数等指标,以确定模型的有效性。详细步骤:
- 运行评估脚本:使用YOLO提供的评估工具,检查模型在验证集上的表现。
- 分析结果:根据评估结果调整模型参数或训练策略。
# 使用验证集评估模型
python val.py --weights runs/train/exp/weights/best.pt --data data.yaml --img 640
推理与检测:使用训练好的模型进行推理,以检测新图像中的大象。通过加载模型并处理输入图像,可以获取检测结果。详细步骤:
- 加载训练好的模型:使用YOLO框架加载训练好的权重文件。
- 处理输入图像:读取图像并进行预处理。
- 执行推理:运行模型进行推理,获取检测结果并可视化。
四、总结
大象数据集是一个丰富多样的图像数据集,专注于大象目标的标注和分类。这个数据集包含了大量真实世界场景中大象的图像样本,涵盖了各种不同姿态和环境条件下的大象。通过该数据集,研究人员和保护机构可以进行大象行为分析、生态研究以及野生动物保护工作。这一数据集的建立旨在为大象相关领域的机器学习和计算机视觉研究提供重要的支持和资源。
相关文章:
【大象数据集】大象图像识别 目标检测 机器视觉(含数据集)
一、背景意义 在信息时代,数据的收集和分析技术得到了飞速发展。深度学习算法的出现,为处理和分析这些复杂的鱼类数据集提供了强大的工具。深度学习具有强大的模式识别和特征提取能力,能够从海量的数据中自动学习和发现规律,为鱼…...

LN 在 LLMs 中的不同位置 有什么区别么
Layer Normalization(LN)是一种在深度学习中用于稳定和加速神经网络训练的归一化技术。它通过对单个样本的所有激活进行归一化来工作,与Batch Normalization(BN)不同,BN是对一个mini-batch中的所有样本的激…...

【代码随想录Day57】图论Part08
拓扑排序精讲 题目链接/文章讲解:代码随想录 import java.util.*;public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);// 读取文件数量 n 和依赖关系数量 mint n scanner.nextInt();int m scanner.nextInt()…...

记录一次mmpretrain训练数据并转onnx推理
目录 1.前言 2.代码 3.数据形态【分类用】 4.配置文件 5.训练 6.测试-分析-混淆矩阵等等,测试图片效果等 7.导出onnx 8.onnx推理 9.docker环境简单补充 1.前言 好久没有做图像分类了,于是想用商汤的mmclassification快速搞一波,发现已…...

shodan5,参数使用,批量查找Mongodb未授权登录,jenkins批量挖掘
查找美国安全局漏洞 nww.nsa.gov(美国安全局官方网站) net参数使用 搜索指定的ip网段 shodan search --limit 10 --fields ip_str,port net:208.88.84.0/24 (老美国家安全局的一个网段)可能直接访问不太行,可以使用host参数,得到域名再去…...

telnet 密码模式 访问路由器
telnet 密码访问华为路由器 模拟被访问路由 sy [Huawei]int g0/0/0 //选中 g0/0/0端口 [Huawei-GigabitEthernet0/0/0]ip add 192.168.1.1 24 //设置端口ip [Huawei]user-interface vty 0 4 //配置vty [Huawei-ui-vty0-4]set authentication password cipher huawei123 //设置…...

文心一言 VS 讯飞星火 VS chatgpt (380)-- 算法导论24.4 12题
十二、给出一个有效算法来解决 A x ⩽ b Ax⩽b Ax⩽b 的差分约束系统,这里 b b b 的所有元素为实数,而变量 x i x_i xi 中某个给定的子集是整数。如果要写代码,请用go语言。 文心一言: 差分约束系统问题通常用于解决带有约…...
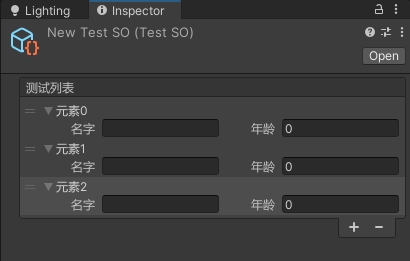
Unity自定义数组在Inspector窗口的显示方式
了解 单行高度:EditorGUIUtility.singleLineHeight获取 PropertyField 控件所需的高度:EditorGUI.GetPropertyHeight属性是否在Inspector窗口展开:SerializedProperty.isExpanded可重新排序列表类:ReorderableList绘制纯色矩形:EditorGUI.Dr…...
--SPCL论文阅读笔记(2024-10-29))
ERC论文阅读(03)--SPCL论文阅读笔记(2024-10-29)
SPCL论文阅读笔记 论文中心思想 这篇论文是研究ERC任务的论文,作者提出了监督原型对比学习的方法用于ERC任务。 论文 EMNLP2022 paper “Supervised Prototypical Contrastive Learning for Emotion Recognition in Conversation” 现存问题 现存的使用监督对…...

Straightforward Layer-wise Pruning for More Efficient Visual Adaptation
对于模型中冗余的参数,一个常见的方法是通过结构化剪枝方法减少参数容量。例如,基于幅度值和基于梯度的剪枝方法。尽管这些方法在传统训练上通用性,本文关注的PETL迁移有两个不可避免的问题: 显著增加了模型存储负担。由于不同的…...

喜讯 | 创邻科技杭州电子科技大学联合实验室揭牌成立!
近日,杭州电子科技大学图书情报专业硕士行业导师聘任仪式暨杭电-创邻图技术与数字化联合实验室(图书档案文物数字云联合研发中心)揭牌仪式在杭州电子科技大学隆重举行。杭州电子科技大学原副校长吕金海、研究生院副院长潘建江,科研…...

海外媒体发稿:如何打造媒体发稿策略
新闻媒体的发稿推广策略对于提升品牌知名度、吸引流量以及增加收入非常重要。本文将介绍一套在21天内打造爆款新闻媒体发稿推广策略的方法。 第一天至第七天:明确目标和定位 在这个阶段,你需要明确你的目标和定位,以便为你的新闻媒体建立一个…...

PyTorch模型保存与加载
1.保存与加载的概念(序列化与反序列化) 模型训练完毕之后,肯定想要把它保存下来,供以后使用,不需要再次去训练。 那么在pytorch中如何把训练好的模型,保存,保存之后又如何加载呢? 这就用需要序列化与反序列化,序列化与反序列化的概念如下图所示: 因为在内…...
CH569开发前的测试
为了玩转准备Ch569的开发工作 ,准备了如下硬件和软件: 硬件 1.官方的 Ch569 开发板,官方买到的是两块插接在一起的;除了HSPI接口那里的电阻,这两块可以说是一样的。也意味着两块板子的开发也需要烧录两次;…...
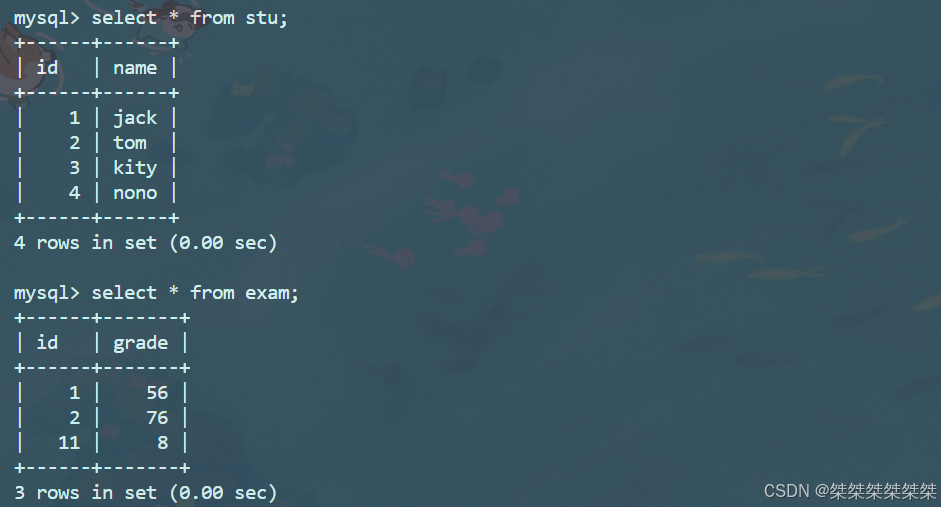
MySQL中表的外连接和内连接
内连接和外连接 表的连接分为内连接和外连接,内连接就是将需要连接的表形成笛卡尔积筛选;外连接分为左外连接和右外连接,左外连接为左侧的表需要完全显示,右外连接为右侧的表现需要完全显示。 文章目录 内连接和外连接内连接外…...

Ubuntu 上安装 Redmine 5.1 指南
文章目录 官网安装文档:命令步骤相关介绍GemRubyRailsBundler 安装 Redmine更新系统包列表和软件包:安装必要的依赖:安装 Ruby:安装 bundler下载 Redmine 源代码:安装 MySQL配置 Redmine 的数据库配置文件:…...
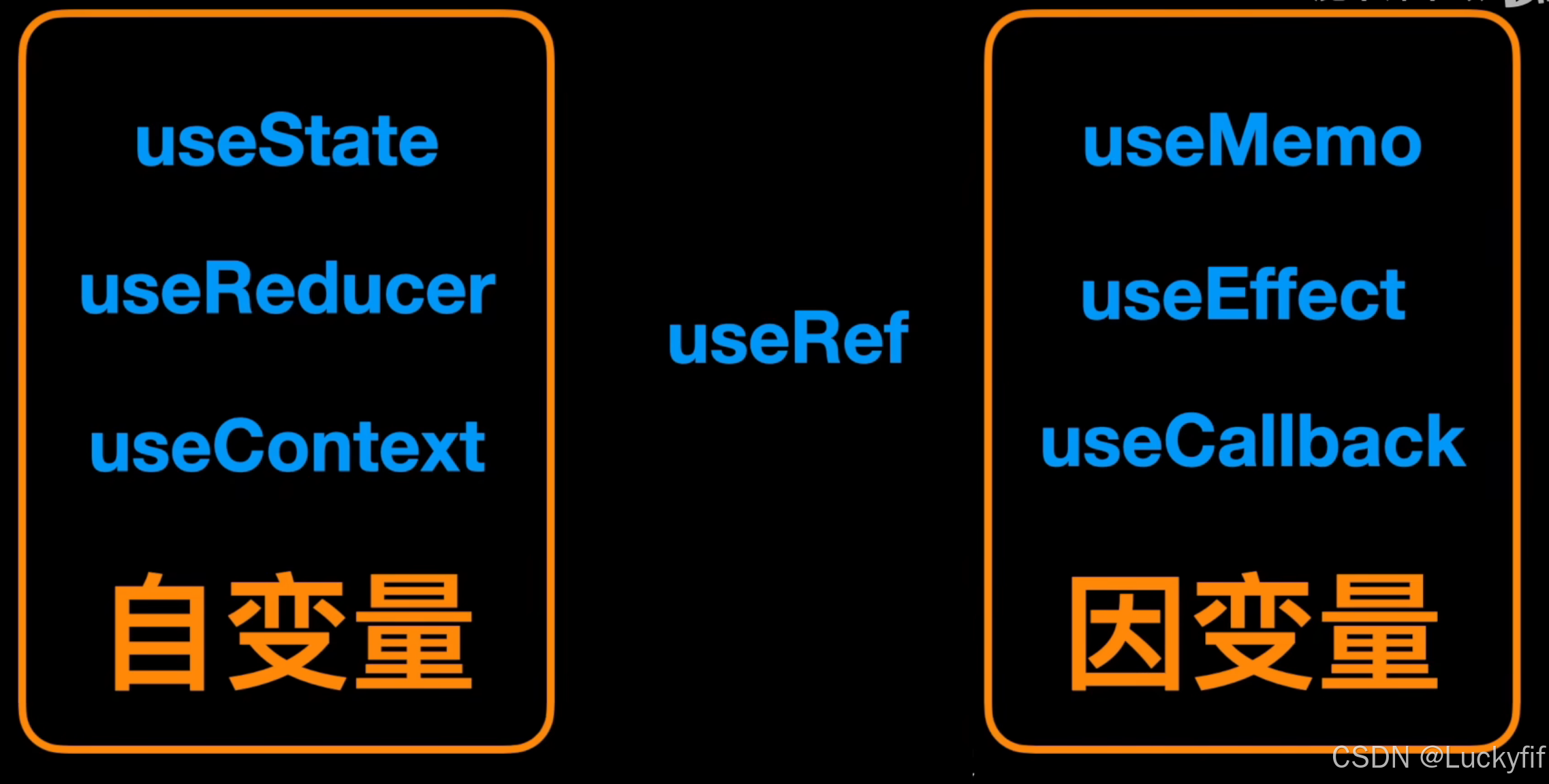
从变量的角度理解 Hooks , 变得更简单了
从变量角度理解Hooks 在React的世界里,Hooks的引入为函数式组件带来了前所未有的灵活性和能力。它们让我们得以完全摆脱class式的写法,在函数式组件中完成生命周期管理、状态管理、逻辑复用等几乎全部组件开发工作。这次,我们就从变量的角度…...
LabVIEW Modbus通讯稳定性提升
在LabVIEW开发Modbus通讯程序时,通讯不稳定是一个常见问题,可能导致数据丢失、延迟或错误。为了确保通讯的可靠性,可以从多个角度进行优化,以下是一些有效的解决方案,结合实际案例进行分析。 1. 优化通讯参数设置 通讯…...
(8) cuda分析工具
文章目录 Nvidia GPU性能分析工具Nsight SystemNvidia GPU性能分析工具Nsight System Nvidia GPU性能分析工具Nsight System NVIDIA Nsight Systems是一个系统级的性能分析工具,用于分析和优化整个CUDA应用程序或系统的性能。它可以提供对应用程序整体性能的全面见…...

C语言 | Leetcode C语言题解之第517题超级洗衣机
题目: 题解: int findMinMoves(int* machines, int machinesSize){int sum0;for(int i0;i<machinesSize;i){summachines[i];}if(sum%machinesSize!0){return -1;}int psum/machinesSize;int ans0;int cur0;for(int i0;i<machinesSize;i){cur(mac…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲…...

2026 年行业真相:履职规范背后的管理秘密
现场冲突:安全与进度的激烈碰撞在工程建设领域,安全与进度的冲突一直是个老大难问题。就拿上海中心的建设来说,如此庞大复杂的项目,施工过程中安全管理难度极大。在某些施工阶段,为了赶进度,部分施工人员可…...

基于插件化架构的OBS实时音乐信息集成系统技术解析
基于插件化架构的OBS实时音乐信息集成系统技术解析 【免费下载链接】tuna Song information plugin for obs-studio 项目地址: https://gitcode.com/gh_mirrors/tuna1/tuna Tuna是一款面向OBS Studio的高性能插件化实时音乐信息集成系统,采用模块化架构设计&…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

【仅限首批200名开发者】DeepSeek毒性检测白皮书V3.1泄露版:含未公开的multilingual bias benchmark结果
更多请点击: https://intelliparadigm.com 第一章:DeepSeek毒性检测模型的演进与V3.1泄露事件全景 DeepSeek Toxicity Detection(DTDD)系列模型自2022年发布初版以来,持续迭代强化对中文语境下隐性偏见、诱导性话术、…...

收藏!小白程序员必看:AI时代如何从执行者变身价值创造者?
本文指出,85%的知识工作者使用AI,但仅16%真正获得突破性价值。这些"前沿专业人士"并非更会使用工具,而是懂得重新定义工作。他们通过保持核心技能敏锐度、判断AI输出质量、构建人机协作系统等方式,创造80%的新价值。文章…...

QT 导出可执行 EXE 文件的方法
简介 本文分为两部分 第一部分导出exe文件,但是此文件需要很多其他文件支持,就是在一个文件夹里,里面不仅有exe,还有很多支持文件,使用的时候需要拷贝整个文件夹。 第二部分是单独导出exe,实际是在第一部…...

分类记单词:哺乳动物
分类记单词:哺乳动物快来记单词,这里有好多哺乳动物哦一、宠物、家畜 pet 宠物cat 猫tom 公猫;汤姆dog 狗pup 小狗bitch 母狗;泼妇pig 猪sow 母猪;播种boar 未阉的公猪;野猪piglet 小猪livestock 牲口cattl…...

利用 JiuwenClaw AgentTeam 打造自动化研发团队
利用 JiuwenClaw AgentTeam 打造自动化研发团队 本文介绍如何通过 JiuwenClaw AgentTeam 构建自动化研发团队,实现字幕软件开发、AtomGit Issue/PR 智能处理与飞书文档同步。 目录 JiuwenClaw 平台概述 系统架构预置智能体类型 什么是 AgentTeams飞书群中添加机器人…...

AI技能gate-of-oss:智能海巡GitHub,高效开源项目选型
1. 项目概述:一个帮你“海巡”GitHub的AI技能在软件开发这个行当里,我敢说,几乎每个开发者都经历过这样的时刻:为了解决一个具体问题,或者想给项目引入一个新功能,一头扎进GitHub的汪洋大海,试图…...