【大数据学习 | kafka】producer之拦截器,序列化器与分区器
1. 自定义拦截器
interceptor是拦截器,可以拦截到发送到kafka中的数据进行二次处理,它是producer组成部分的第一个组件。
public static class MyInterceptor implements ProducerInterceptor<String,String>{@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {return null;}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}}实现拦截器需要实现ProducerInterceptor这个接口,其中的泛型要和producer端发送的数据的类型一致。
onSend方法是最主要的方法用户拦截数据并且处理完毕发送
onAcknowledgement 获取确认应答的方法,这个方法和producer端的差不多,只能知道结果通知
close是执行完毕拦截器最后执行的方法
configure方法是用于获取配置文件信息的方法
我们拦截器的实现基于场景是获取到producer端的数据然后给数据加上时间戳。
整体代码如下:
package com.hainiu.kafka.producer;/*** ClassName : producer_intercepter* Package : com.hainiu.kafka.producer* Description** @Author HeXua* @Create 2024/10/31 22:56* Version 1.0*/import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Date;
import java.util.Map;
import java.util.Properties;public class producer_intercepter {public static class MyInterceptor implements ProducerInterceptor<String,String>{@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {String value = record.value();Long time = new Date().getTime();String topic = record.topic();//获取原始数据并且构建新的数据,增加时间戳信息return new ProducerRecord<String,String>(topic,time+"-->"+value);}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {//获取确认应答和producer端的代码逻辑相同String topic = metadata.topic();int partition = metadata.partition();long offset = metadata.offset();if(exception == null ){System.out.println("success"+" "+topic+" "+partition+" "+offset);}else{System.out.println("fail"+" "+topic+" "+partition+" "+offset);}}@Overridepublic void close() {//不需要任何操作//no op}@Overridepublic void configure(Map<String, ?> configs) {//不需要任何操作//no op}}public static void main(String[] args) {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.ACKS_CONFIG, "all");pro.put(ProducerConfig.RETRIES_CONFIG,3 );pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);pro.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,MyInterceptor.class.getName());//设定拦截器KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");for(int i=0;i<5;i++){producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {String topic = metadata.topic();int partition = metadata.partition();long offset = metadata.offset();if(exception == null ){System.out.println("success"+" "+topic+" "+partition+" "+offset);}else{System.out.println("fail"+" "+topic+" "+partition+" "+offset);}}});}producer.close();}
}ack返回的元数据信息。
success topic_a 0 17
success topic_a 0 17
success topic_a 0 18
success topic_a 0 18
success topic_a 0 19
success topic_a 0 19
success topic_a 0 20
success topic_a 0 20
success topic_a 0 21
success topic_a 0 21
查看consumer端消费的数据。

在客户端消费者中可以打印出来信息带有时间戳。
拦截器一般很少人为定义,比如一般producer在生产环境中都是有flume替代,一般flume会设定自己的时间戳拦截器,指定数据采集时间,相比producer更加方便实用。
2. 自定义序列化器
kafka中的数据存储是二进制的byte数组形式,所以我们在存储数据的时候要使用序列化器进行数据的转换,序列化器的结构要和存储数据的kv的类型一致。
比如我们要实现系统的String类型序列化器。
2.1 实现String类型的序列化器
package com.hainiu.kafka.producer;/*** ClassName : producer_String_Serializer* Package : com.hainiu.kafka.producer* Description** @Author HeXua* @Create 2024/10/31 23:12* Version 1.0*/
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.nio.charset.StandardCharsets;
import java.util.Map;
import java.util.Properties;public class producer_String_Serializer {public static void main(String[] args) {Properties pro = new Properties();//bootstrap-server key value batch-size linger.ms ack retries interceptorpro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");// 自定义生产记录的key和value的序列化器pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());pro.put(ProducerConfig.BATCH_SIZE_CONFIG,16*1024);pro.put(ProducerConfig.LINGER_MS_CONFIG,0);pro.put(ProducerConfig.ACKS_CONFIG,"all");pro.put(ProducerConfig.RETRIES_CONFIG,3);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);for (int i = 0; i < 100; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "hainiu","message_" + i);producer.send(record);}producer.close();}public static class MyStringSerializer implements Serializer<String>{@Overridepublic byte[] serialize(String topic, String data) {return data.getBytes(StandardCharsets.UTF_8);}}
}
消费者消费数据:
message_0
message_1
message_2
message_3
message_4
message_5
message_6
message_7
message_8
message_9
message_10
message_11
message_12
..........2.2 序列化对象整体
package com.hainiu.kafka.producer;/*** ClassName : producer_Student_Serializer* Package : com.hainiu.kafka.producer* Description** @Author HeXua* @Create 2024/10/31 23:20* Version 1.0*/import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;/*** producerRecord==> key:string,value:student*/
public class producer_Student_Serializer {public static class Student implements Serializable{private int id;private String name;private int age;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Student() {}public Student(int id, String name, int age) {this.id = id;this.name = name;this.age = age;}}public static class MyStudentSerializer implements Serializer<Student>{// ByteArrayOutputStream
// ObjectOutputStream@Overridepublic byte[] serialize(String topic, Student data) {ByteArrayOutputStream byteOS = null;ObjectOutputStream objectOS = null;try {byteOS =new ByteArrayOutputStream();objectOS = new ObjectOutputStream(byteOS);objectOS.writeObject(data);} catch (IOException e) {throw new RuntimeException(e);}finally {try {byteOS.close();objectOS.close();} catch (IOException e) {throw new RuntimeException(e);}}return byteOS.toByteArray();}}public static void main(String[] args) {Properties pro = new Properties();//bootstrap-server key value batch-size linger.ms ack retries interceptorpro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.BATCH_SIZE_CONFIG,16*1024);pro.put(ProducerConfig.LINGER_MS_CONFIG,0);pro.put(ProducerConfig.ACKS_CONFIG,"all");pro.put(ProducerConfig.RETRIES_CONFIG,3);pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,MyStudentSerializer.class.getName());KafkaProducer<String, Student> producer = new KafkaProducer<>(pro);Student s1 = new Student(1, "zhangsan", 20);Student s2 = new Student(2, "lisi", 30);ProducerRecord<String, Student> r1 = new ProducerRecord<>("topic_a", "hainiu", s1);ProducerRecord<String, Student> r2 = new ProducerRecord<>("topic_a", "hainiu", s2);producer.send(r1);producer.send(r2);producer.close();}消费的数据:
[hexuan@hadoop107 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop106:9092 --topic topic_a
¬첲=com.hainiu.kafka.producer.producer_Student_Serializer$Student8Ӯ¥ClOIageIidLnametLjava/lang/String;xpzhangsan
¬첲=com.hainiu.kafka.producer.producer_Student_Serializer$Student8Ӯ¥ClOIageIidLnametLjava/lang/String;xptlisi
XshellXshell
2.3 序列化对象字段信息
比如我们想要发送一个Student对象,其中包含id name age等字段,这个数据需要对应的序列化器
序列化器的实现需要指定类型并且实现。
需要实现serializer接口,并且实现serialize的方法用于将数据对象转换为二进制的数组
整体代码如下:
package com.hainiu.kafka.producer;/*** ClassName : producer_Student_Serializer2* Package : com.hainiu.kafka.producer* Description** @Author HeXua* @Create 2024/10/31 23:30* Version 1.0*/
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.nio.charset.Charset;
import java.util.Properties;public class producer_Student_Serializer2 {public static void main(String[] args) {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//key因为没有放入任何值,所以序列化器使用原生的就可以pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StudentSeria.class.getName());//value的序列化器需要指定相应的student序列化器pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);KafkaProducer<String, Student> producer = new KafkaProducer<String, Student>(pro);//producer生产的数据类型也必须是string,student类型的kvStudent student = new Student(1, "zhangsan", 30);ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);producer.send(record);producer.close();}public static class Student{private int id;private String name;private int age;public int getId() {return id;}public Student() {}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Student(int id, String name, int age) {this.id = id;this.name = name;this.age = age;}}public static class StudentSeria implements Serializer<Student> {@Overridepublic byte[] serialize(String topic, Student data) {String line =data.getId()+" "+data.getName()+" "+data.getAge();//获取student对象中的所有数据信息return line.getBytes(Charset.forName("utf-8"));//转换为byte数组返回}}
}消费者消费数据:
[hexuan@hadoop107 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop106:9092 --topic topic_a
1 zhangsan 30
3. 分区器
首先在kafka存储数据的时候topic中的数据是分为多个分区进行存储的,topic设定分区的好处是可以进行分布式存储和分布式管理,那么好的分区器可以让数据尽量均匀的分布到不同的机器节点,数据更加均匀,那么kafka中的分区器是如果实现的呢?
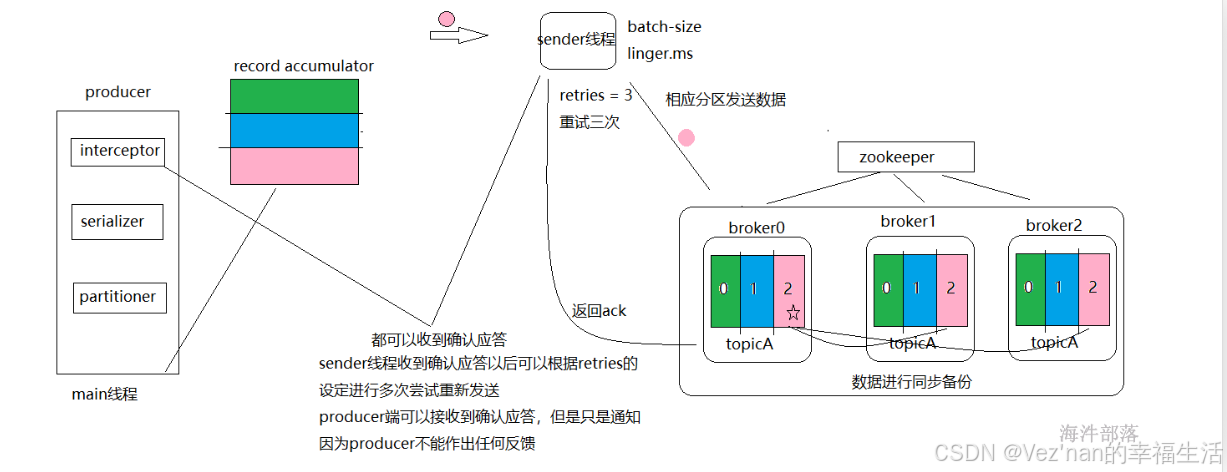
根据图我们可以看出数据首先通过分区器进行分类,在本地的累加器中进行存储缓存,然后在复制到kafka集群中,所以分区器产生作用的位置在本地的缓存之前。
kafka的分区规则是如何实现的呢?
ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);
producer.send(record);kafka的生产者数据发送是通过上面的方法实现的
首先要构造一个ProducerRecord对象,然后通过producer.send来进行发送数据。
其中ProducerRecord对象的构造器种类分为以下几种。
1. 构造器指定分区,包含key, value。
2. 构造器没有指定分区,但有key,有value。
3. 构造器只有value。
/*** Creates a record to be sent to a specified topic and partition** @param topic The topic the record will be appended to* @param partition The partition to which the record should be sent* @param key The key that will be included in the record* @param value The record contents*/
public ProducerRecord(String topic, Integer partition, K key, V value) {this(topic, partition, null, key, value, null);}/*** Create a record to be sent to Kafka* * @param topic The topic the record will be appended to* @param key The key that will be included in the record* @param value The record contents*/
public ProducerRecord(String topic, K key, V value) {this(topic, null, null, key, value, null);
}/*** Create a record with no key* * @param topic The topic this record should be sent to* @param value The record contents*/
public ProducerRecord(String topic, V value) {this(topic, null, null, null, value, null);
}我们想要发送一个数据到kafka的时候可以构造以上的ProducerRecord但是构造的方式却不同,大家可以发现携带的参数也有所不同,当携带不同参数的时候数据会以什么样的策略发送出去呢,这个时候需要引入一个默认分区器,就是在用户没有指定任何规则的时候系统自带的分区器规则。
在ProducerConfig源码中看到:
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";private static final String PARTITIONER_CLASS_DOC = "A class to use to determine which partition to be send to when produce the records. Available options are:" +"<ul>" +"<li>If not set, the default partitioning logic is used. " +"This strategy will try sticking to a partition until " + BATCH_SIZE_CONFIG + " bytes is produced to the partition. It works with the strategy:" +"<ul>" +"<li>If no partition is specified but a key is present, choose a partition based on a hash of the key</li>" +"<li>If no partition or key is present, choose the sticky partition that changes when " + BATCH_SIZE_CONFIG + " bytes are produced to the partition.</li>" +"</ul>" +"</li>" +"<li><code>org.apache.kafka.clients.producer.RoundRobinPartitioner</code>: This partitioning strategy is that " +"each record in a series of consecutive records will be sent to a different partition(no matter if the 'key' is provided or not), " +"until we run out of partitions and start over again. Note: There's a known issue that will cause uneven distribution when new batch is created. " +"Please check KAFKA-9965 for more detail." +"</li>" +"</ul>" +"<p>Implementing the <code>org.apache.kafka.clients.producer.Partitioner</code> interface allows you to plug in a custom partitioner.";
在producerConfig对象中我们可以看到源码指示,如果没有任何人为分区器规则指定,那么默认使用的DefaultPartitioner的规则.
package org.apache.kafka.clients.producer.internals;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;/*** NOTE this partitioner is deprecated and shouldn't be used. To use default partitioning logic* remove partitioner.class configuration setting. See KIP-794 for more info.** The default partitioning strategy:* <ul>* <li>If a partition is specified in the record, use it* <li>If no partition is specified but a key is present choose a partition based on a hash of the key* <li>If no partition or key is present choose the sticky partition that changes when the batch is full.* * See KIP-480 for details about sticky partitioning.*/
@Deprecated
public class DefaultPartitioner implements Partitioner {private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();public void configure(Map<String, ?> configs) {}/*** Compute the partition for the given record.** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes serialized key to partition on (or null if no key)* @param value The value to partition on or null* @param valueBytes serialized value to partition on or null* @param cluster The current cluster metadata*/public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());}/*** Compute the partition for the given record.** @param topic The topic name* @param numPartitions The number of partitions of the given {@code topic}* @param key The key to partition on (or null if no key)* @param keyBytes serialized key to partition on (or null if no key)* @param value The value to partition on or null* @param valueBytes serialized value to partition on or null* @param cluster The current cluster metadata*/public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,int numPartitions) {if (keyBytes == null) {return stickyPartitionCache.partition(topic, cluster);}return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);}public void close() {}/*** If a batch completed for the current sticky partition, change the sticky partition. * Alternately, if no sticky partition has been determined, set one.*/@SuppressWarnings("deprecation")public void onNewBatch(String topic, Cluster cluster, int prevPartition) {stickyPartitionCache.nextPartition(topic, cluster, prevPartition);}
}
而打开DefaultPartitioner以后可以看到他的分区器规则,就是在构建ProducerRecord的时候
new ProducerRecord(topic,partition,k,v);
//指定分区直接发送数据到相应分区中
new ProducerRecord(topic,k,v);
//没有指定分区就按照k的hashcode发送到不同分区
new ProducerRecord(topic,v);
//如果k和partition都没有指定就使用粘性分区partition方法中,如果key为空就放入到粘性缓冲中,它的意思就是如果满足batch-size或者linger.ms就会触发应用执行,将数据复制到kafka中,并且再次随机到其他分区,所以简单来说粘性分区就是可一个分区放入数据,一旦满了以后才会改变分区,粘性分区规则使用主要是为了让每次复制数据更加快捷方便都赋值到一个分区中。
而如果key不为空那么就按照hashcode值进行取余处理。(哈希分区器)
总的来说就是分为默认分区分为三种情况:
1. 如果指定了分区,即往指定的分区复制到kafka集群。
2. 如果没有指定分区,但又有key存在,那么将会对key求哈希值再取余。
即 key.hashCode()%numPartition,将得到一个数字,消息将会被复制到kafka集群的该数字对应的分区。
3. 如果没有指定分区,并且不存在key,只有value。那么我们会采用粘性分区策略。
即产生一个随机值k,并将没有key的记录都放入粘性缓冲,如果满足batch-size或者linger.ms就会触发应用执行,将粘性缓冲的消息复制到kafka集群。然后再随机复制到kafka集群。
相关文章:
【大数据学习 | kafka】producer之拦截器,序列化器与分区器
1. 自定义拦截器 interceptor是拦截器,可以拦截到发送到kafka中的数据进行二次处理,它是producer组成部分的第一个组件。 public static class MyInterceptor implements ProducerInterceptor<String,String>{Overridepublic ProducerRecord<…...

零基础学西班牙语,柯桥专业小语种培训泓畅学校
No te comas el coco, seguro que te ha salido bien la entrevista. Ya te llamarn. 别瞎想了!我保证你的面试很顺利。他们会给你打电话的。 这里的椰子是"头"的比喻。在西班牙的口语中,我们也可以听到其他同义表达,比如&#x…...
)
C++学习:类和对象(三)
一、深入讲解构造函数 1. 什么是构造函数? 构造函数(Constructor)是在创建对象时自动调用的特殊成员函数,用于初始化对象的成员变量。构造函数的名称与类名相同,没有返回类型 2. 构造函数的类型 (1&…...
高阶数据结构--图(graph)
图(graph) 1.并查集1. 并查集原理2. 并查集实现3. 并查集应用 2.图的基本概念3. 图的存储结构3.1 邻接矩阵3.2 邻接矩阵的代码实现3.3 邻接表3.4 邻接表的代码实现 4. 图的遍历4.1 图的广度优先遍历4.2 广度优先遍历的代码 1.并查集 1. 并查集原理 在一…...
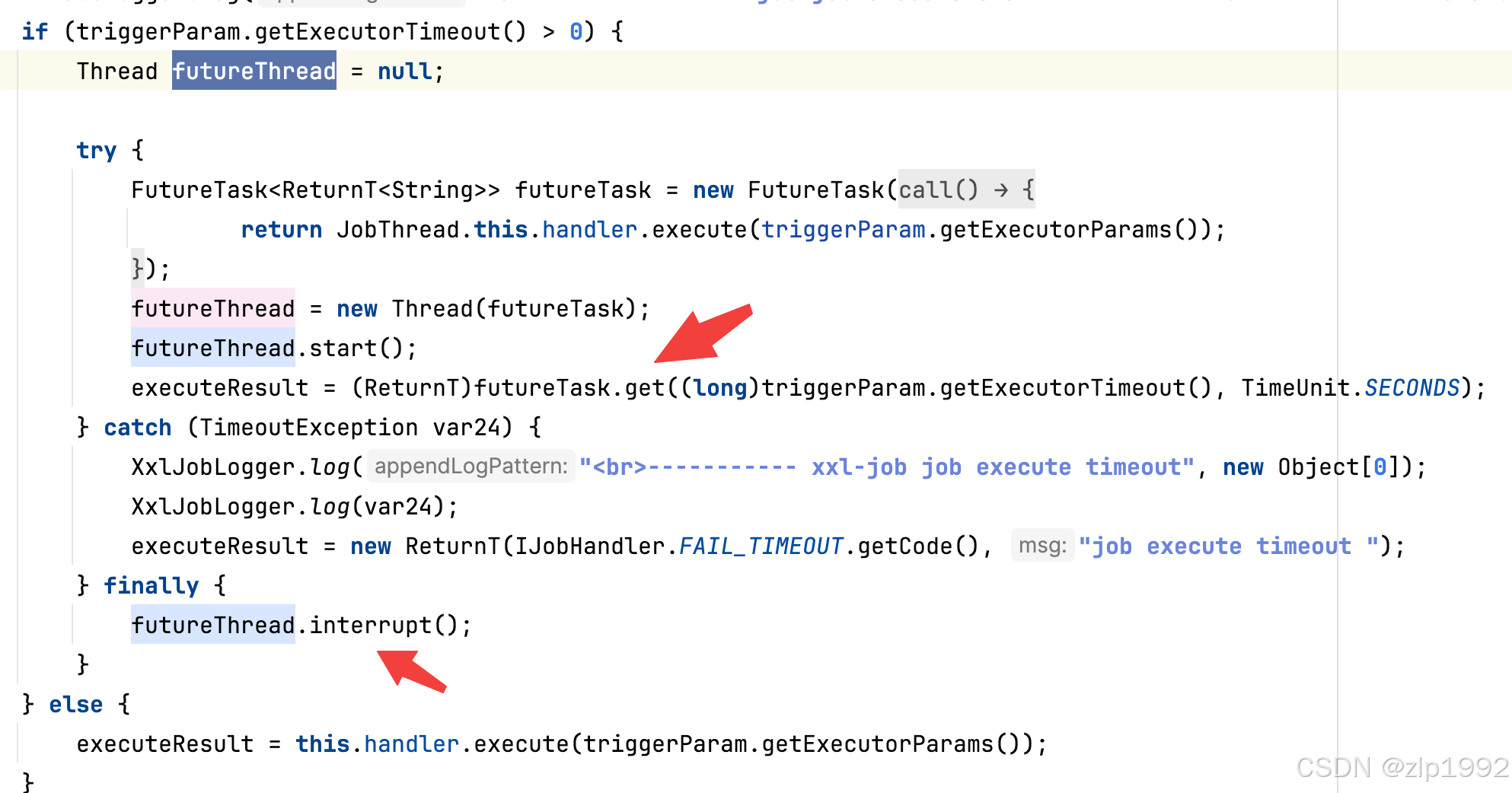
xxl-job java.sql.SQLException: interrupt问题排查
近期生产环境固定凌晨报错,提示 ConnectionManager [Thread-23069] getWriteConnection db:***,pattern: error, jdbcUrl: jdbc:mysql://***:3306/***?connectTimeout3000&socketTimeout180000&autoReconnecttrue&zeroDateTimeBehaviorCONVERT_TO_NUL…...
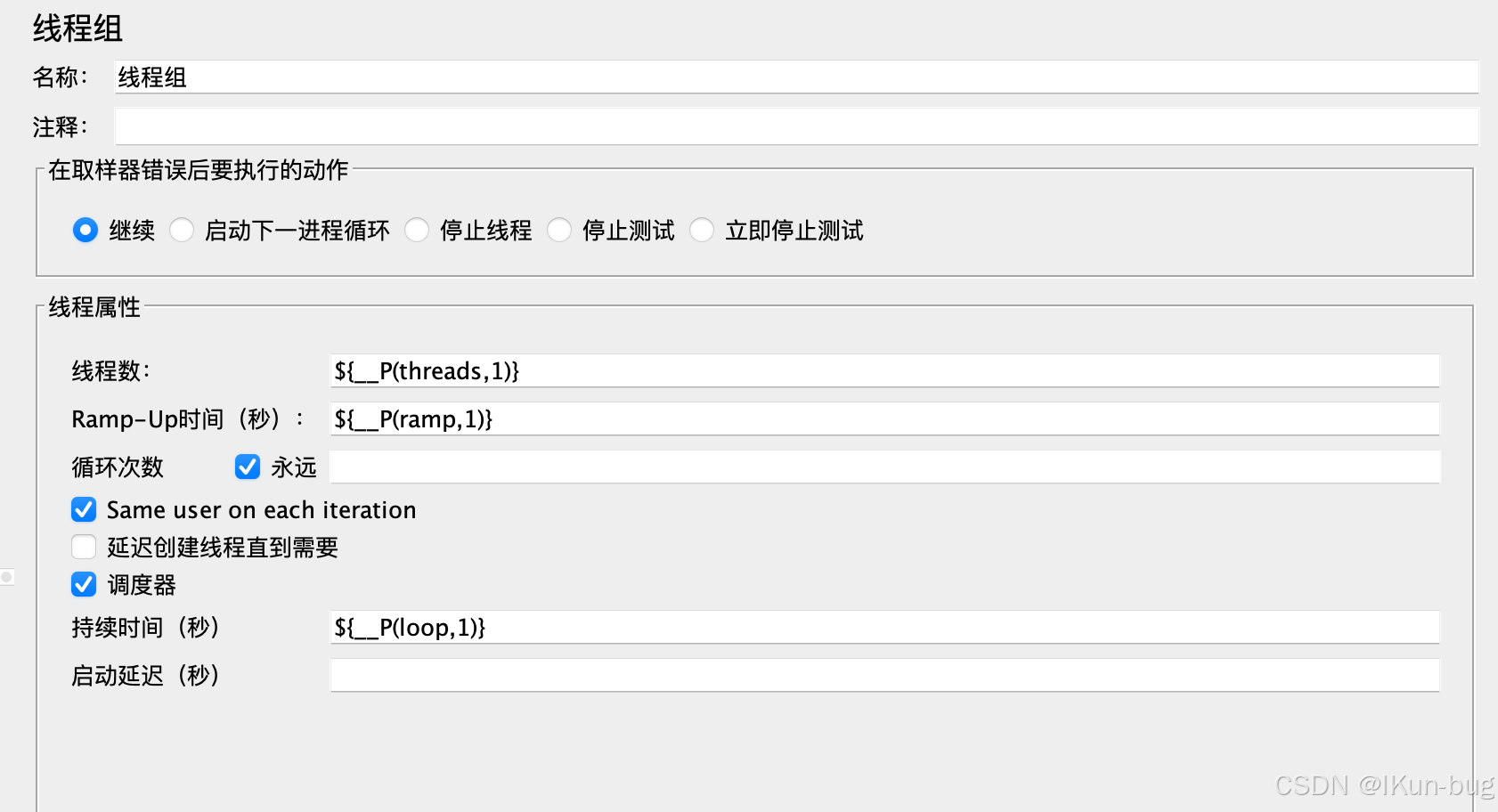
jmeter压测工具环境搭建(Linux、Mac)
目录 java环境安装 1、anaconda安装java环境(推荐) 2、直接在本地环境安装java环境 yum方式安装jdk 二进制方式安装jdk jmeter环境安装 1、jmeter单机安装 启动jmeter 配置环境变量 jmeter配置中文 2、jmeter集群搭建 多台机器部署jmeter集群…...

docker设置加速
sudo tee /etc/docker/daemon.json <<-‘EOF’ { “registry-mirrors”: [ “https://register.liberx.info”, “https://dockerpull.com”, “https://docker.anyhub.us.kg”, “https://dockerhub.jobcher.com”, “https://dockerhub.icu”, “https://docker.awsl95…...

使用requestAnimationFrame写防抖和节流
debounce.ts 防抖工具函数: function Animate() {this.timer null; }Animate.prototype.start function (fn) {if (!fn) {throw new Error(需要执行函数);}if (this.timer) {this.stop();}this.timer requestAnimationFrame(fn); }Animate.prototype.stop function () {i…...

Puppeteer 与浏览器版本兼容性:自动化测试的最佳实践
Puppeteer 支持的浏览器版本映射:从 v20.0.0 到 v23.6.0 自 Puppeteer v20.0.0 起,这个强大的自动化库开始支持与 Chrome 浏览器的无头模式和有头模式共享相同代码路径,为自动化测试带来了更多便利。从 v23.0.0 开始,Puppeteer 进…...

Java方法重写
在Java中,方法重写是指在子类中重新定义父类中已经定义的方法。以下是Java方法重写的基本原则: 子类中的重写方法必须具有相同的方法签名(即相同的方法名、参数类型和返回类型)。子类中的重写方法不能比父类中的原方法具有更低的…...
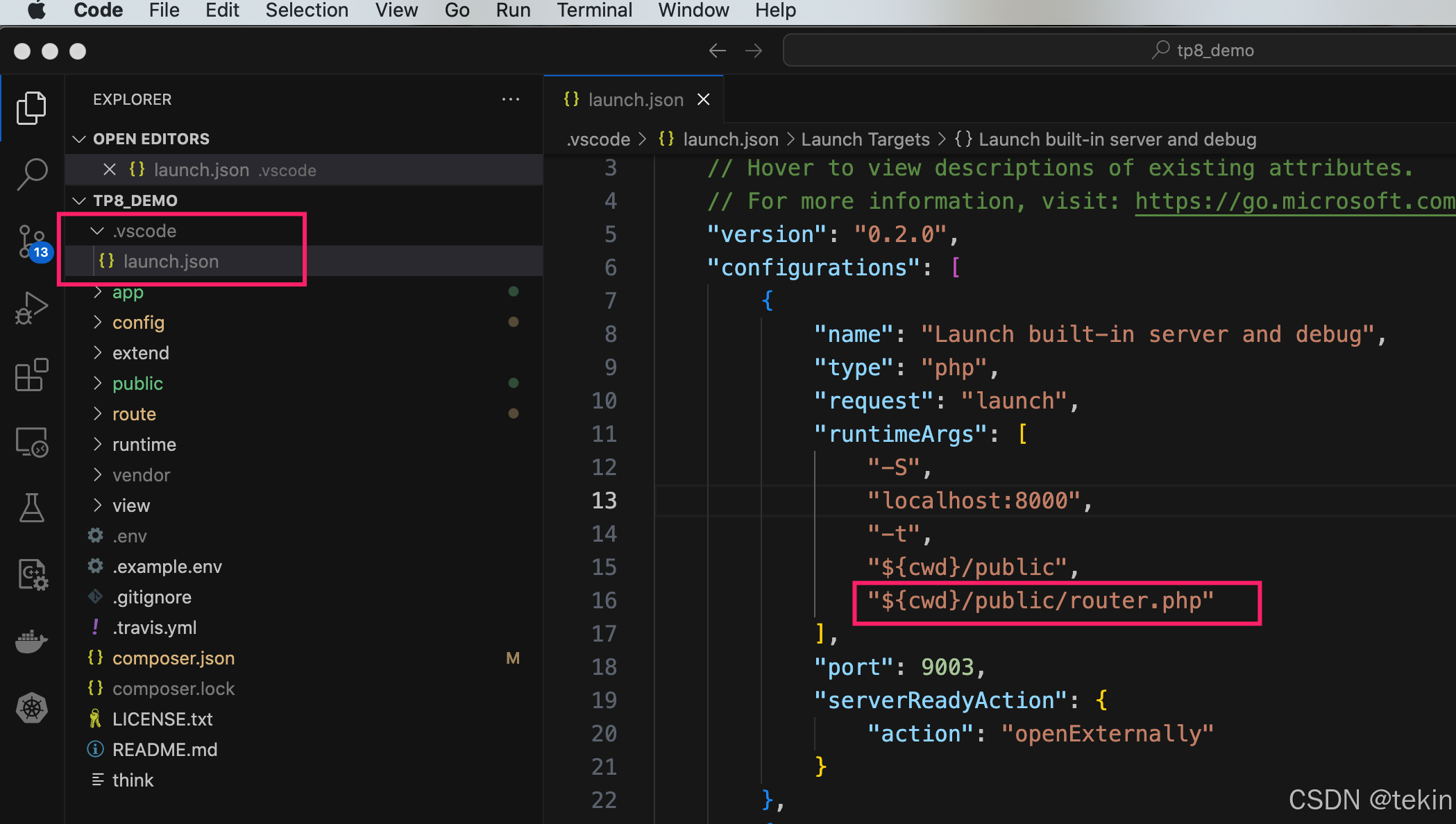
vscode通过.vscode/launch.json 内置php服务启动thinkphp 应用后无法加载路由解决方法
我们在使用vscode的 .vscode/launch.json Launch built-in server and debug 启动thinkphp应用后默认是未加载thinkphp的路由文件的, 这个就导致了,某些thinkphp的一些url路由无法访问的情况, 如http://0.0.0.0:8000/api/auth.admin/info这…...
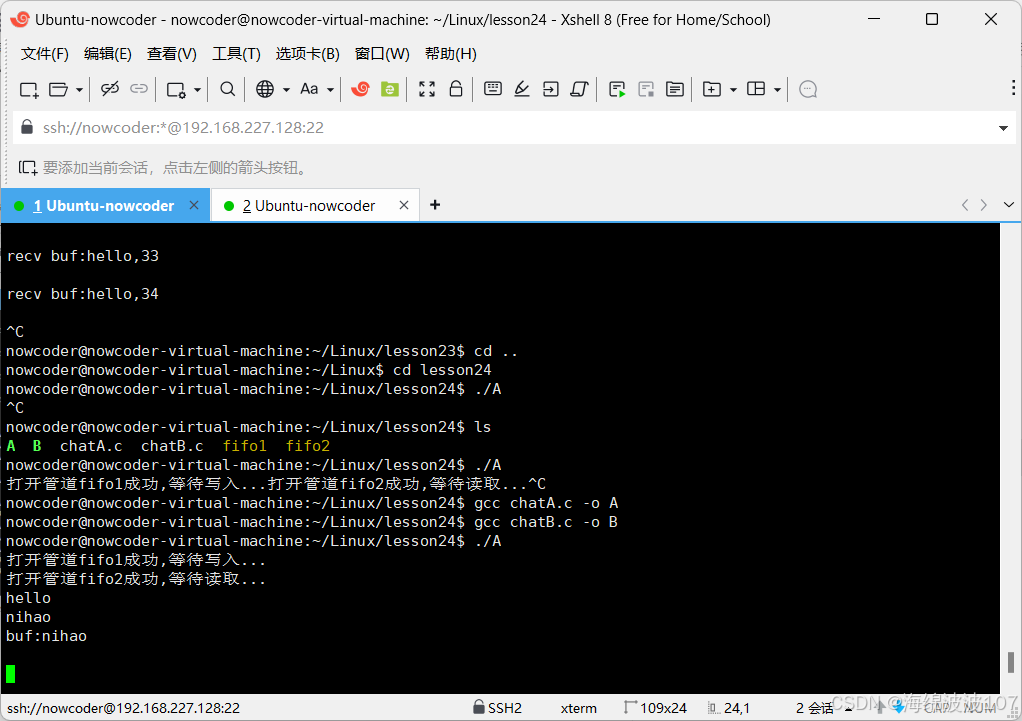
Webserver(2.6)有名管道
目录 有名管道有名管道使用有名管道的注意事项读写特性有名管道实现简单版聊天功能拓展:如何解决聊天过程的阻塞 有名管道 可以用在没有关系的进程之间,进行通信 有名管道使用 通过命令创建有名管道 mkfifo 名字 通过函数创建有名管道 int mkfifo …...
四足机器人实战篇之一:波士顿spot机器人工程实现分析
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 TODO:写完再整理 文章目录 系列文章目录前言一、机器人发展历史二、硬件系统及电机执行器篇硬件系统电机执行器传感器机处理器电气连接三、感知(视觉点云、局部地图、定位)篇1.深度相机获取…...

TensorFlow 预训练目标检测模型集合
Tensorflow 提供了一系列在不同数据集上预训练的目标检测模型,包括 COCO 数据集、Kitti 数据集、Open Images 数据集、AVA v2.1 数据集、iNaturalist 物种检测数据集 和 Snapshot Serengeti 数据集。这些模型可以直接用于推理,特别是当你对这些数据集中已…...

字符串的区别
C 和 Java 字符串的区别 最近 C 和 Java 在同步学习,都有个字符串类型,但二者不太一样,于是就做了些许研究。 在编程中,字符串作为数据类型广泛应用于不同的场景。虽然 C 和 Java 都允许我们处理字符串,但它们在字符…...

EMR Serverless Spark:一站式全托管湖仓分析利器
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人: 李钰(绝顶) | 阿里云智能集团资深技术专家,阿里云 EMR 团队负责人 活动: 2024 云栖大会 AI - 开源大数据专场 数据平台技术演变 …...

Linux find 匹配文件内容
在Linux中,你可以使用find命令结合-exec或者-execgrep来查找匹配特定内容的文件。以下是一些示例: 查找当前目录及其子目录下所有文件内容中包含"exampleText"的文件: find . -type f -exec grep -l "exampleText" {} \…...
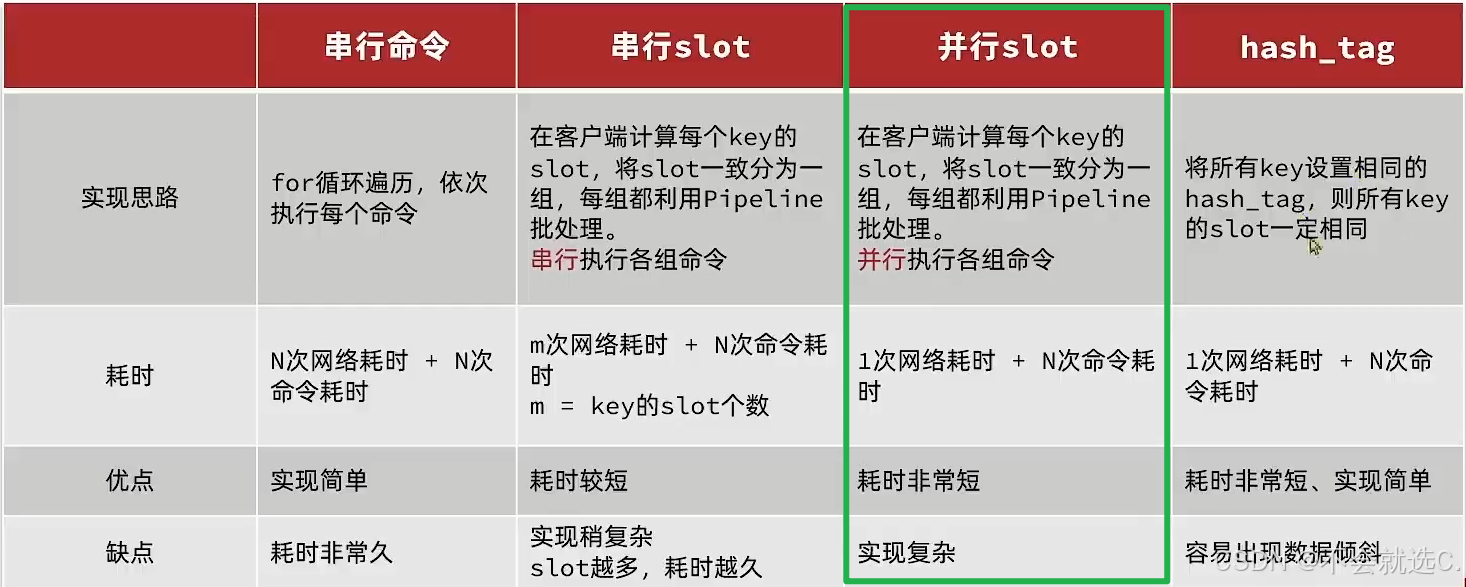
【Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key】
Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key 一、Key的设计1. 命名规范2. 长度限制在44字节以内 二、BigKey优化1. 查找bigkey2. 删除BigKey3. 优化BigKey 三、Pipeline批处理Key1. 单节点的Pipeline2. 集群下的Pipeline 一、Key的设计…...
数据结构与算法分析:你真的理解图算法吗——深度优先搜索(代码详解+万字长文)
一、前言 图是计算机科学中用来表示复杂结构信息的一种基本结构。本章我们会讨论一些通用的围表示法,以及一些频繁使用的图算法。本质上来说,一个图包含一个元素集合(也就是顶点),以及元素两两之间的关系(也就是边),由于应用范围所限,本章我们仅仅讨论简单图,简单围并不会如(a…...
LinkedList 分析
LinkedList 简介 LinkedList 是一个基于双向链表实现的集合类,经常被拿来和 ArrayList 做比较。关于 LinkedList 和ArrayList的详细对比,我们 Java 集合常见面试题总结(上)有详细介绍到。 双向链表 不过,我们在项目中一般是不会使用到 Link…...

戴尔G15散热控制终极指南:免费开源工具TCC-G15告别过热降频
戴尔G15散热控制终极指南:免费开源工具TCC-G15告别过热降频 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否为戴尔G15笔记本在游戏或高强度工…...

Faster RCNN PyTorch CUDA扩展:RoI Pooling层的GPU实现终极指南
Faster RCNN PyTorch CUDA扩展:RoI Pooling层的GPU实现终极指南 【免费下载链接】faster_rcnn_pytorch Faster RCNN with PyTorch 项目地址: https://gitcode.com/gh_mirrors/fa/faster_rcnn_pytorch 在目标检测领域,Faster RCNN一直是经典算法之…...

3分钟学会使用PPT计时器:告别演讲超时的终极解决方案
3分钟学会使用PPT计时器:告别演讲超时的终极解决方案 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 你是否在PPT演示时总是担心超时?是否希望有一个工具能自动帮你管理演讲时间&#x…...
)
2026年第六届FIC全国网络空间取证大赛-初赛详细版Writeup(服务器+互联网+二进制)
2026年第六届FIC全国网络空间取证大赛-初赛详细版Writeup(服务器互联网二进制) 前言:服务器:1. 该服务器主机操作系统版本为2. 该服务器根分区硬盘的uuid号为3. 该服务器中最新的docker镜像创建时间为4. 该服务器根分区快照路径为…...

告别Wi-Fi卡顿!手把手教你读懂802.11ax的BSR机制,优化家庭网络上行体验
告别Wi-Fi卡顿!手把手教你读懂802.11ax的BSR机制,优化家庭网络上行体验 你是否经历过这样的场景:视频会议时画面突然卡成马赛克,游戏团战时操作延迟飙升,或是上传文件进度条像蜗牛爬行?这些恼人的问题往往源…...
)
手把手教你用Google Cloud语音API为Android App加个“耳朵”和“嘴巴”(附免费额度避坑指南)
实战指南:在Android应用中集成Google Cloud语音技术 想象一下,你的Android应用能够听懂用户说话,还能用自然流畅的语音回应——这不再是科幻电影里的场景。借助Google Cloud的语音API,即使是独立开发者也能快速为应用添加专业的语…...

Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘
Cat-Catch浏览器资源嗅探扩展深度解析:高性能流媒体捕获架构揭秘 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch Cat-Catch作为一款专业…...

深入浅出:拆解Xilinx ERNIC IP的硬件架构,看RoCE v2如何卸载CPU
深入浅出:拆解Xilinx ERNIC IP的硬件架构,看RoCE v2如何卸载CPU 在数据中心和高性能计算领域,RDMA(远程直接内存访问)技术正成为突破网络性能瓶颈的关键。Xilinx的ERNIC IP核作为RoCE v2协议的硬件实现,通过…...

PB 级自动驾驶数据秒级检索:Apache Doris 统一多模态数据平台实践
导读:多模态数据正成为企业核心资产,但规模化管理仍具挑战。自动驾驶在 PB 级图像、点云、视频等数据治理中积累了可复用经验。本文介绍某公司以 Apache Doris 统一标签、元数据、全文和向量检索,将查询从分钟级提升至秒级。 多模态数据正在成…...

MySql学习杂谈 --- “连接“”
第一步:忘掉所有术语,记住一个生活场景 想象你要做一件事:查全班同学的考试成绩 表A(同学名单):张三,李四,王五,赵六 表B(考试成绩)࿱…...