C++——unordered_map和unordered_set的封装
unordered_map和unordered_set的底层结构用到的都是在哈希表模拟实现中的哈希桶的实现方式,哈希桶的具体实现我已经在哈希表的模拟实现里做过详细的介绍,这边会引用里面的代码进行改造和封装,同时为了方便操作,同样我采用二倍扩容的方式。
一、哈希桶的基本结构
首先对哈希桶的模版参数进行改造,原本我们是直接采用K_V的结构来定义这个哈希桶,但是在封装的过程中,unordered_map和unordered_set的存储数据是不一样的,unordered_set只存一个Key值,unordered_map存储的是key_value的键值对,但是他们在增删查改的中间的行为又是一样的,所以我们给哈希桶多传入几个参数,T表示的是我们要存储的数据,让上层的容器传入决定,这样就能让unordered_map和unordered_set分别存储不同的数据类型。
KeyOfT的模版参数是一个仿函数,因为我们并不知道T里存储的数据究竟是一个Key还是一个Key、Value,所以我要让上层的结构自己实现出怎么从T中取出Key的方法。这里也有人会疑惑,那既然有了KeyOfT的这个仿函数,那为什么还要传入K的模版参数呢?
比如在使用查找的功能的时候,我们是需要用Key找到对应的Value值,如果我们只有KeyOfT的仿函数的话,我们就必须要求用户传入一个完整的数据才能使用查找功能,这样使用起来就会非常的不方便,所以还要让上层的容器确定它的Key的类型是什么。
template<class K>struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};template<>struct HashFunc<string>{size_t operator()(const string& s){size_t hashi = 0;//BKDRfor (auto e : s){hashi += e;hashi *= 131;}return hashi;}};template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};// K 为 T 中key的类型// T 可能是键值对,也可能是K// KeyOfT: 从T中提取key// Hash将key转化为整形,因为哈希函数使用除留余数法template<class K, class T, class KeyOfT, class Hash>class HashTable{typedef HashNode<T> Node;public:HashTable(){_tables.resize(10, nullptr);}// 哈希桶的销毁~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}// 插入值为data的元素,如果data存在则不插入bool Insert(const T& data){KeyOfT kot;Hash hs;//插入的数据已经存在if (it != End())return false;//负载因子为1时扩容if (_n == _tables.size()){vector<Node*> newHT(_tables.size()*2,nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;//头插到新表里size_t hashi = hs(kot(cur->_data)) % newHT.size();cur->_next = newHT[hashi];newHT[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newHT);}size_t hashi = hs(kot(data)) % _tables.size();//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}// 在哈希桶中查找值为key的元素,存在返回true否则返回falsebool Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();//在对应的桶里查找数据Node* cur = _tables[hashi];KeyOfT kot;while (cur){if (kot(cur->_data) == key)return true;cur = cur->_next;}return false;}// 哈希桶中删除key的元素,删除成功返回true,否则返回falsebool Erase(const K& key){Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){//删除结点为头结点if (prev == nullptr){_tables[hashi] = cur->_next;}//删除结点为中间结点else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数};二、迭代器
这里的迭代器看似要传入很多的模版参数,但是其实和我们在实现list时实现的迭代器没有什么本质上的区别,只不过多套了几个模版参数,同时这里的迭代器是一个单向迭代器,所以只需要实现++的功能即可。这里需要细讲的其实也就只有这个++的操作。
第一种情况,当前桶里还有数据,那么直接接着访问下一个结点即可。
第二种情况,当前桶里的数据都被访问过了,但是哈希表并没有被遍历完,此时我们就要去到哈希表的下一个位置去找元素,这里我们就需要用到这个哈希表的数据了,这里和之前实现过的迭代器都不同的地方就在这里了。我们需要使用到哈希表里的数据,最重要的是我们需要去访问哈希表底层的那个数组,我们不可能因为这个在迭代器里开一个数组来存储哈希表里每个头结点的信息,这样不仅浪费空间,还会多出很多不必要的操作,这里的解决方案其实很简单,给迭代器增加一个指向哈希表的指针即可。其实这样又引出了两个问题,一个是这样做其实不能完全解决问题,因为我们要访问的是哈希表里底层的数组,这个数组是一个私有的成员变量,我们在外部是没办法访问的,所以我们要把这个迭代器声明成HashTable的友元类,这样我们的迭代器就能访问HashTable的数组了;带模版参数的友元类的声明和之前声明的友元类有一些不同点,我们在声明的时候要把它的类型完整的声明出来;第二个问题就是会出现报错,HashTable是在迭代器后续实现的一个类,编译器在编译的时候是从上往下的顺序进行的,编译进行到HTIterator这里时,它发现在前面的代码中,没有发现HashTable,也就是说编译器不认识这个类型,所以就出现了这个报错,这里解决这个问题的办法也很简单,我们只要在HTIterator之前把HashTable声明了就行,这个做法叫做提前声明,就是告诉编译器这个东西是一个我们自己定义的类,你继续向后编译就好,后面就我们的具体实现。
template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K,class T,class Ref,class Ptr,class KeyOfT,class Hash>struct HTIterator{typedef HashNode<T> Node;typedef HTIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;typedef HashTable<K, T, KeyOfT, Hash> HT;HTIterator(Node* node,const HT* ht):_node(node),_ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator==(const Self& s){return _node == s._node;}bool operator!=(const Self& s){return _node != s._node;}Self& operator++(){if (_node->_next)_node = _node->_next;else{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){_node = _ht->_tables[hashi];if (_node)break;else++hashi;}}return *this;}Node* _node;const HT* _ht;};template<class K, class T, class KeyOfT, class Hash>class HashTable{template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct HTIterator;};三、哈希表里的迭代器调用
这里其实很简单,就是简单的去找哈希表里的第一个数据就是Begin函数需要做的功能,而End其实就是空,主要是我们可以通过迭代器去改造Find函数和Insert的函数,这样不仅能通过这个Insert函数实现后续unordered_map的重载[],还能方便操作。但是其实这里的ConstIterator版本的Begin函数还出现了一个问题,会在后续说明。
template<class K, class T, class KeyOfT, class Hash>class HashTable{public:typedef HTIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;typedef HTIterator<K, T, const T&, const T*, KeyOfT, Hash> ConstIterator;Iterator Begin(){if (_n == 0)return End();for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur)return Iterator(cur, this);}}Iterator End(){return Iterator(nullptr, this);}ConstIterator Begin() const{if (_n == 0)return End();for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur)return ConstIterator(cur, this);}}ConstIterator End() const{return ConstIterator(nullptr, this);}pair<Iterator, bool> Insert(const T& data){KeyOfT kot;Hash hs;Iterator it = Find(kot(data));//插入的数据已经存在if (it != End())return { it ,false };//负载因子为1时扩容if (_n == _tables.size()){vector<Node*> newHT(_tables.size()*2,nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;//头插到新表里size_t hashi = hs(kot(cur->_data)) % newHT.size();cur->_next = newHT[hashi];newHT[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newHT);}size_t hashi = hs(kot(data)) % _tables.size();//头插Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return { Iterator(newnode,this),true };}// 在哈希桶中查找值为key的元素,存在返回true否则返回falseIterator Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();//在对应的桶里查找数据Node* cur = _tables[hashi];KeyOfT kot;while (cur){if (kot(cur->_data) == key)return Iterator(cur,this);cur = cur->_next;}return End();}};四、封装容器
其实到这里就没有什么可说的了,也没有什么难点了,无非就是实现一个KeyOfT的仿函数然后再对我们实现好的哈希表和迭代的功能进行调用罢了,unordered_set里的细节只有一个,就是在给哈希表传参的时候,我们可以直接给第二个参数直接加上的const的,第二个模版参数对应的是T,unordered_set存储的本来就只有一个Key值,本身就是不支持修改的,加上const修饰也可以防止误操作。
还有一个细节点就是我们在给迭代器传参以及定义指向哈希表的指针的时候,一定要用const修饰,不然就会引发第三点中说的问题ConstIterator版本的Begin和End都是被const修饰的,表示Begin和End中this指针指向的对象是被const的修饰的,这样原来的哈希表就变成了一个被const修饰的哈希表边,此时在调用ConstIterator版本的迭代器的时候就会出现参数类型不匹配的问题;但是如果用const修饰以后,普通版本的迭代器传入的this指向的对象是没有被const修饰的,但是权限是能给缩小的,所以也不会出现错误。
template<class K, class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K, const K, SetKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, const K, SetKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:HashTable<K, const K, SetKeyOfT, Hash> _ht;};unordered_map这里要多实现一个重载[]的功能,这里这个写法的意思就是,利用Insert的功能去找出这个Key值是否在哈希表中存在,如果存在就返回它对应的结点,如果不存在就会直接插入这个结点,这个结点对应Value值是V类型的默认构造出来的。
return ret.first->second;的第一个.first是取到pair这个对里的第一个类型是这个一个迭代器,->second的意思是:我们的迭代器重载了->这个操作符,这个操作符的作用是取出迭代器指向结点存储的内容,也就是T类型,在unordered_mapT类型是我们的pair<K,V>,所以它的second就是我们对应的V,这样就能做到Key存在时进行修改操作,Key不存在时进行插入和修改的操作了。
template<class K, class V, class Hash = HashFunc<K>>class unordered_map{public:struct MapKeyOfT{const K& operator()(const pair<const K, V>& kv){return kv.first;}};typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::ConstIterator const_iterator;iterator begin(){return _ht.Begin();}iterator end(){return _ht.End();}const_iterator begin()const{return _ht.Begin();}const_iterator end()const{return _ht.End();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert({ key,V() });return ret.first->second;}private:HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};相关文章:

C++——unordered_map和unordered_set的封装
unordered_map和unordered_set的底层结构用到的都是在哈希表模拟实现中的哈希桶的实现方式,哈希桶的具体实现我已经在哈希表的模拟实现里做过详细的介绍,这边会引用里面的代码进行改造和封装,同时为了方便操作,同样我采用二倍扩容…...

微信小程序scroll-view吸顶css样式化表格的表头及iOS上下滑动表头的颜色覆盖、z-index应用及性能分析
微信小程序scroll-view吸顶css样式化表格的表头及iOS上下滑动表头的颜色覆盖、z-index应用及性能分析 目录 微信小程序scroll-view吸顶css样式化表格的表头及iOS上下滑动表头的颜色覆盖、z-index应用及性能分析 1、iOS在scroll-view内部上下滑动吸顶的现象 正常的上下滑动吸顶…...

【高中数学】数列
等差数列前 n n n 项和性质 公式一: S n n ( a 1 a n ) 2 S_n\frac{n(a_1a_n)}{2} Sn2n(a1an) 公式二: S n n a 1 n ( n − 1 ) 2 d S_nna_1\frac{n(n-1)}{2}d Snna12n(n−1)d 性质1:等差数列中依次 k k k 项之和 S …...

数字媒体技术基础:AMF(ACES 元数据文件 )
在现代电影和电视制作中,色彩管理变得越来越重要。ACES(Academy Color Encoding System,美国电影艺术与科学学院颜色编码系统)是一个广泛采用的色彩管理和交换系统,旨在解决不同设备、软件和工作流程之间的色彩不一致问…...

Apache Dubbo (RPC框架)
本文参考官方文档:Apache Dubbo 1. Dubbo 简介与核心功能 Apache Dubbo 是一个高性能、轻量级的开源Java RPC框架,用于快速开发高性能的服务。它提供了服务的注册、发现、调用、监控等核心功能,以及负载均衡、流量控制、服务降级等高级功能。…...
LeetCode 3226. 使两个整数相等的位更改次数
. - 力扣(LeetCode) 题目 给你两个正整数 n 和 k。你可以选择 n 的 二进制表示 中任意一个值为 1 的位,并将其改为 0。 返回使得 n 等于 k 所需要的更改次数。如果无法实现,返回 -1。 示例 1: 输入: n …...

面试经典 150 题:189、383
189. 轮转数组 【参考代码】 class Solution { public:void rotate(vector<int>& nums, int k) {int size nums.size();if(1 size){return;}vector<int> temp(size);//k k % size;for(int i0; i<size; i){temp[(i k) % size] nums[i];}nums temp; }…...

Python模拟真人动态生成鼠标滑动路径
一.简介 鼠标轨迹算法是一种模拟人类鼠标操作的程序,它能够模拟出自然而真实的鼠标移动路径。 鼠标轨迹算法的底层实现采用C/C语言,原因在于C/C提供了高性能的执行能力和直接访问操作系统底层资源的能力。 鼠标轨迹算法具有以下优势: 模拟…...
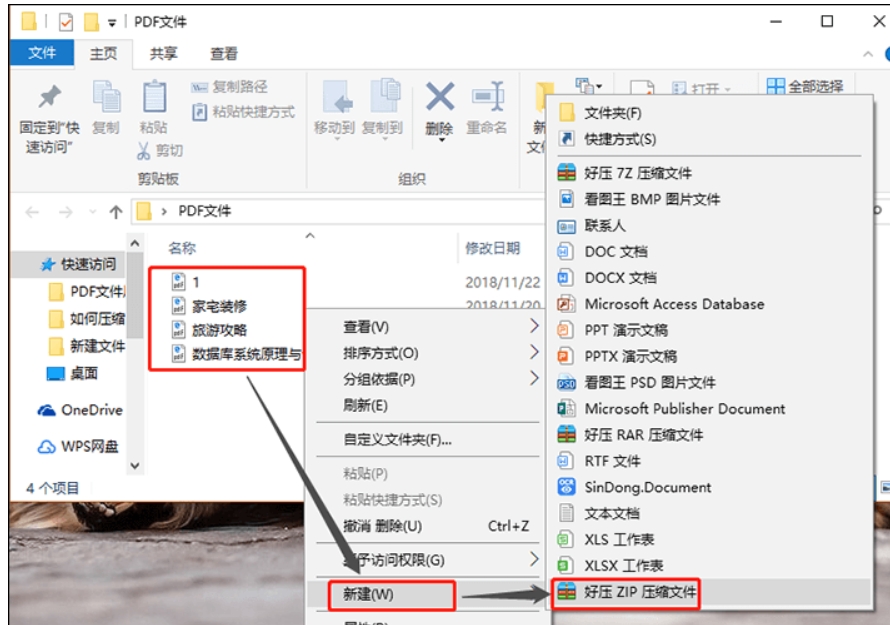
如何压缩pdf文件的大小?5分钟压缩pdf的方法推荐
如何压缩pdf文件的大小?在现代办公和学习中,PDF文件因其稳定性和广泛的兼容性被广泛使用。然而,随着文件内容的增多,制作好的PDF文件常常变得过大,给使用带来了诸多不便。无论是电子邮件附件的发送,还是在线…...

【SQL】[2BP01] ERROR: cannot drop table course because other objects depend on it
问题描述 在尝试执行以下SQL语句时,发生错误。 DROP TABLE Course RESTRICT;执行以上语句后,系统返回了一个错误提示: [2BP01] ERROR: cannot drop table course because other objects depend on it 详细:constraint sc_cno_…...

gbase8s之spring框架用druid中间件报语法错误
spring框架 调用druid中间件 时报这个错: MetaDataAccessException: Could not get Connection for extracting meta-data; nested exception is org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception …...
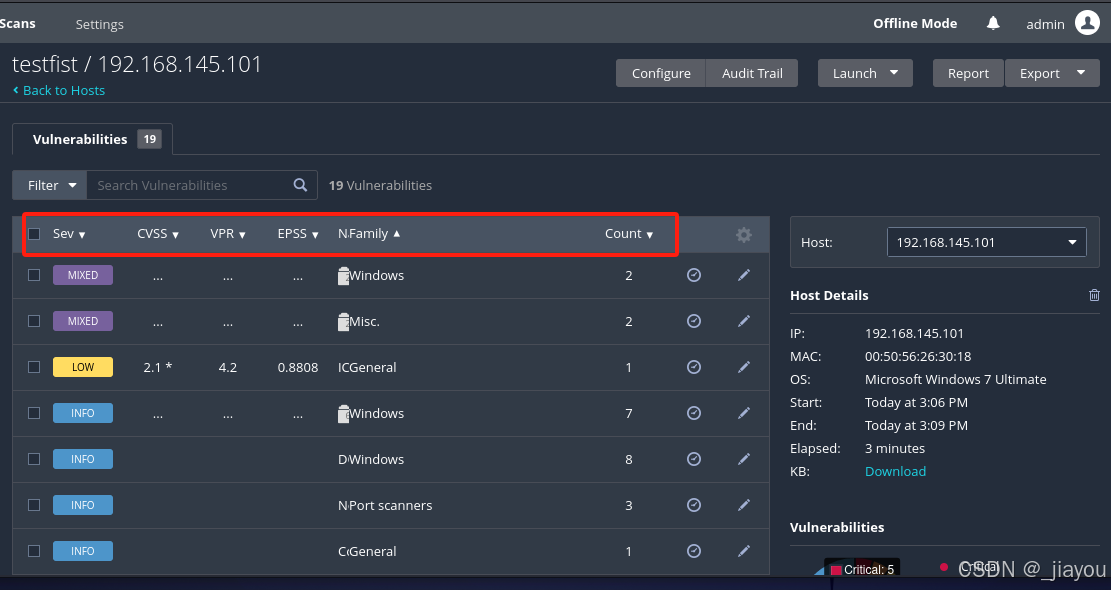
【网络安全】|nessus使用
1、扫描结果分析: Sev:漏洞的严重性级别 CVSS:量化漏洞严重性的标准,通过计算得出一个分数,分数越高表示漏洞越严重。 VPR:基于风险的评分系统,帮助组织优先处理风险最高的漏洞。 EPSS…...

CSRA2的LINUX操作系统24年11月2日上午上课笔记
几个查找命令: .whereis:查看文件的路径,查看可执行文件的路径,一级相应文档路径。 .which:查看系统可执行的文件的路径,以及命令的别名等信息 .local:他会将linux中的所有文件的路径信息保存到数据库中,在数据库中查…...
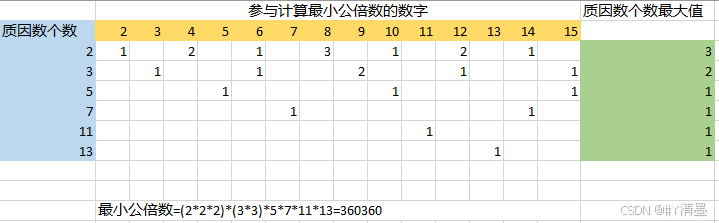
通过分解质因数求若干个数的最小公倍数
求最小公倍数的常规方法回顾 暴力枚举法 long long work(long long a,long long b) {for(long long imax(a,b);;i)if(i%a0&&i%b0)return i; }大数翻倍法 long long work(long long a,long long b) {if(a<b) swap(a,b);for(long long ia;;ia) // i 是 a 的倍数&#…...
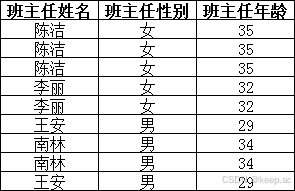
数据库三范式(1NF、2NF、3NF)
1NF(第一范式) 定义:确保每一列都是原子值,即是不可分割的基础数据项。 所谓第一范式(1NF)是指在关系模型中,对于添加列的一个规范要求,所有的列都 应该是原子性的,即数…...

C语言_数据结构_顺序表
1. 本章重点 顺序表初始化顺序表尾插顺序表尾删顺序表头插顺序表头删顺序表查找顺序表在pos位置插入x顺序表删除pos位置的值顺序表销毁顺序表打印 2. 顺序表的概念及结构 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储…...
Llama 3.2 Vision Molmo:多模态开源生态系统基础
编者按: 视觉功能的融入对模型能力和推理方式的影响如何?当我们需要一个既能看懂图像、又能生成文本的 AI 助手时,是否只能依赖于 GPT-4V 这样的闭源解决方案? 我们今天为大家分享的这篇文章,作者的核心观点是…...

【数据结构与算法】第6课—数据结构之栈
文章目录 1. 栈2. 栈的初始化和栈的销毁3. 入栈和出栈(压栈)4. 取栈顶元素并打印5. 栈的练习题5.1 有效的括号 1. 栈 栈:也是一种线性表,其数据结构与动态顺序表的数据结构类似栈分为栈顶和栈底,在栈中,插入…...

开源全站第一个Nextron(NextJS+electron)项目--NextTalk:一款集成chatgpt的实时聊天工具
NextTalk 简介 该项目是一个基于Nextron(NextJSElectron)的桌面端实时聊天工具。 但由于使用了NextJS中的ssr及api route功能,该程序只能在开发环境运行。 关于生产版本:我将其网页端部分分离,并用Pake将其打包成桌面端,生产体…...

多样化的编程模型:并发与并行策略
因为经常看着某些框架设计的编程模型很晕,所以自己梳理总结了一下编程模型的分类,总共六个大类,基本所有常见框架设计的编程模型都是基于这六个大类来实现的,如果有错误的地方,请见谅并不吝赐教,感谢&#…...

OpenClaw核心揭秘:Agentic Loop如何驱动AI持续思考与行动?
上一篇讲了 Gateway——它像餐厅前台,负责接收订单、分发任务。 但订单到了厨房,厨师是怎么做菜的? 这就是 Agentic Loop(推理循环)的事了。 它是 OpenClaw 的"大脑",决定 Agent 如何思考、如何行…...
)
手把手教你用Node.js和Bun配置Cursor AI与Figma的MCP通信(附完整避坑清单)
从零构建Cursor AI与Figma的MCP通信桥梁:Node.jsBun全链路配置指南 当设计工具与AI代码助手实现双向通信时,创意工作流将迎来革命性变化。本文面向具备Node.js基础的前端/全栈开发者,深入解析如何搭建Cursor AI与Figma间的MCP协议通信通道。…...
)
避坑指南:Prescan8.5安装常见报错解决方案(含MATLAB集成配置)
Prescan8.5安装避坑指南:7类典型报错与MATLAB集成深度解析 当仿真工程师第一次打开Prescan8.5安装包时,很少有人能预料到接下来可能遭遇的"技术迷宫"。作为自动驾驶仿真领域的重要工具,Prescan的安装过程就像它的功能一样复杂——从…...

51单片机Proteus仿真实战:从零构建流水灯系统
1. 环境准备:搭建51单片机开发环境 第一次接触51单片机的朋友可能会被各种工具软件搞晕,其实只需要两个核心工具就能完成流水灯仿真:Proteus和Keil。我刚开始学单片机时也踩过不少坑,这里把最稳定的版本和安装要点分享给大家。 Pr…...

d-id AI studio会员值得买吗?实测3大核心功能与免费版对比
d-id AI studio会员深度评测:三大核心功能实测与免费版差异全解析 在数字内容创作领域,AI视频工具正掀起一场革命。作为行业新锐,d-id AI studio凭借其独特的面部动画技术,让普通用户也能轻松制作专业级动态视频。但对于已经体验…...
)
手机拍照为啥总感觉差点意思?聊聊藏在ISP里的那些‘魔法’算法(从RawNR到TNR)
手机拍照为啥总感觉差点意思?聊聊藏在ISP里的那些‘魔法’算法(从RawNR到TNR) 每次看到别人用同款手机拍出的大片,再看看自己相册里灰蒙蒙的夜景照,是不是总觉得少了点什么?这背后其实藏着一整套名为ISP&am…...

OpCore-Simplify:零基础黑苹果配置终极指南,5分钟搞定复杂EFI
OpCore-Simplify:零基础黑苹果配置终极指南,5分钟搞定复杂EFI 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置…...

QwQ-32B在ollama中的推理效果展示:数学定理推导、算法设计全过程
QwQ-32B在ollama中的推理效果展示:数学定理推导、算法设计全过程 1. 模型简介与部署准备 QwQ-32B是Qwen系列中专注于推理能力的语言模型,与传统指令调优模型相比,它在解决复杂问题和推理任务方面表现突出。这款中等规模模型拥有325亿参数&a…...
)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例)
汽车电子工程师必看:如何用MPC5643L实现ASIL-D级别的功能安全设计(附完整代码示例) 在智能驾驶技术快速发展的今天,功能安全已成为汽车电子系统设计的核心考量。作为汽车电子工程师,我们面临的挑战不仅在于实现复杂功…...

用DolphinScheduler实现数仓自动化:从零搭建ETL工作流实战
用DolphinScheduler构建电商数仓ETL流水线:实战设计与优化指南 电商平台每天产生的TB级订单数据,如何转化为精准的用户画像和实时销售报表?本文将带你从零搭建一个基于DolphinScheduler的自动化数据处理流水线,解决实际业务场景中…...