Oracle 第22章:数据仓库与OLAP
第22章:数据仓库与OLAP
1. 数据仓库概念
数据仓库(Data Warehouse, DW) 是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。数据仓库中的数据通常来自不同的操作型系统或外部数据源,经过清洗、转换后加载到数据仓库中。数据仓库的设计目的是为了更好地进行数据分析,提供决策支持。
主要特点:
- 面向主题: 数据仓库是围绕特定的主题组织数据,而非日常操作的业务流程。
- 集成性: 数据仓库中的数据是从多个源系统中抽取并整合在一起的,这些数据可能来源于不同的平台和技术。
- 稳定性: 一旦数据进入数据仓库,它通常不会被修改,这保证了数据的历史性和一致性。
- 反映历史: 数据仓库存储的是长时间段内的数据,可以用来分析过去的情况,预测未来的趋势。
2. OLAP技术的应用
联机分析处理(Online Analytical Processing, OLAP) 是一种快速地对大量复杂的数据进行多维度分析的技术。OLAP 技术使得用户能够从多个角度、以多种方式查看数据,从而帮助用户做出更加准确的商业决策。
OLAP的主要功能包括:
- 切片和切块(Slice and Dice): 从不同的角度查看数据。
- 钻取(Drill Down/Up): 从汇总数据深入到详细数据,或者从详细数据向上汇总。
- 旋转(Pivot): 改变数据展示的方式,比如将行变为列或将列变为行。
- 滚动(Rolling): 在时间维度上向前或向后移动查看数据。
案例分析:零售业销售分析
假设有一家大型零售公司,该公司希望利用数据仓库和OLAP技术来分析其销售数据,以便更好地了解销售趋势、顾客偏好等信息,从而优化库存管理和营销策略。
数据仓库设计:
- 源数据提取: 从销售点系统、客户关系管理系统、供应链管理系统等多个系统中提取数据。
- 数据转换: 清洗数据,确保数据质量;转换数据格式,使其符合数据仓库的要求。
- 数据加载: 将转换后的数据加载到数据仓库中,构建星型模式或雪花模式的数据模型,其中心为事实表,周围为维度表(如产品、时间、地理位置、客户等)。
OLAP应用:
- 销售趋势分析: 使用OLAP工具,可以从时间维度分析不同产品的销售趋势,发现季节性变化规律。
- 客户行为分析: 通过分析客户的购买记录,了解不同客户群体的偏好,为个性化推荐提供依据。
- 库存优化: 分析哪些商品销量好,哪些商品滞销,据此调整库存水平,减少库存成本。
- 营销效果评估: 评估各种营销活动的效果,了解哪些渠道最有效,为未来的营销策略提供指导。
源码示例:
以下是一个简单的SQL查询示例,用于从数据仓库中获取特定时间段内按产品分类的总销售额:
SELECT p.product_category,SUM(sales.amount) AS total_sales
FROM sales_fact AS sales
JOIN product_dim AS p ON sales.product_id = p.product_id
WHERE sales.sale_date BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY p.product_category;
此查询可以帮助管理层了解各产品类别的年度销售表现,进而作出相应的战略调整。
通过上述案例,我们可以看到数据仓库与OLAP技术在实际商业场景中的强大作用。它们不仅能够帮助企业更高效地收集和整理数据,还能通过深入分析为企业带来更多的商业价值。
深入案例分析:零售业销售分析
3. 高级分析功能
除了基本的OLAP操作外,高级分析功能也是数据仓库和OLAP技术的重要组成部分。这些功能可以帮助企业更深入地理解其业务,制定更加精细的策略。
3.1 市场篮子分析
市场篮子分析是一种用于发现商品之间关联性的方法,例如哪些商品经常一起被购买。这种分析对于优化商品摆放、促销组合和交叉销售策略非常有用。
案例实现:
假设我们想要找出经常一起购买的商品组合。可以使用关联规则算法(如Apriori算法)来分析销售数据。这里是一个简化版的SQL查询示例,用于查找同时出现在同一笔交易中的商品:
WITH ItemPairs AS (SELECT t1.product_id AS product1,t2.product_id AS product2,COUNT(*) AS pair_countFROM sales_fact t1JOIN sales_fact t2 ON t1.transaction_id = t2.transaction_id AND t1.product_id < t2.product_idGROUP BY t1.product_id, t2.product_id
)
SELECT p1.product_name AS product1,p2.product_name AS product2,ip.pair_count
FROM ItemPairs ip
JOIN product_dim p1 ON ip.product1 = p1.product_id
JOIN product_dim p2 ON ip.product2 = p2.product_id
ORDER BY ip.pair_count DESC;
这个查询会返回最常见的商品组合及其出现次数,有助于零售商设计更有效的促销活动。
3.2 客户生命周期价值分析
客户生命周期价值(Customer Lifetime Value, CLV)是指一个客户在其整个生命周期中为企业带来的预期利润总值。通过分析CLV,企业可以更好地理解不同客户群体的价值,并针对性地制定客户保留和增长策略。
案例实现:
计算每个客户的生命周期价值可以通过以下步骤完成:
- 计算每位客户的总消费金额:
SELECT c.customer_id,c.customer_name,SUM(s.amount) AS total_spent
FROM customer_dim c
JOIN sales_fact s ON c.customer_id = s.customer_id
GROUP BY c.customer_id, c.customer_name;
- 计算每位客户的平均订单价值:
WITH CustomerTotalSpent AS (SELECT c.customer_id,c.customer_name,SUM(s.amount) AS total_spent,COUNT(DISTINCT s.transaction_id) AS order_countFROM customer_dim cJOIN sales_fact s ON c.customer_id = s.customer_idGROUP BY c.customer_id, c.customer_name
)
SELECT customer_id,customer_name,total_spent / order_count AS average_order_value
FROM CustomerTotalSpent;
- 估计每位客户的生命周期价值:
假设我们知道客户的平均购买频率和平均客户寿命,可以进一步计算CLV:
WITH CustomerAverageOrderValue AS (SELECT customer_id,customer_name,total_spent / order_count AS average_order_valueFROM (SELECT c.customer_id,c.customer_name,SUM(s.amount) AS total_spent,COUNT(DISTINCT s.transaction_id) AS order_countFROM customer_dim cJOIN sales_fact s ON c.customer_id = s.customer_idGROUP BY c.customer_id, c.customer_name) AS subquery
),
CustomerFrequency AS (SELECT customer_id,COUNT(DISTINCT DATE_TRUNC('month', sale_date)) AS purchase_frequencyFROM sales_factGROUP BY customer_id
),
CustomerLifetime AS (SELECT customer_id,MAX(sale_date) - MIN(sale_date) AS customer_lifetimeFROM sales_factGROUP BY customer_id
)
SELECT co.customer_id,co.customer_name,co.average_order_value * cf.purchase_frequency * cl.customer_lifetime AS clv
FROM CustomerAverageOrderValue co
JOIN CustomerFrequency cf ON co.customer_id = cf.customer_id
JOIN CustomerLifetime cl ON co.customer_id = cl.customer_id;
这个查询将返回每位客户的预计生命周期价值,帮助企业更好地进行客户细分和个性化营销。
4. 数据仓库与OLAP的最佳实践
4.1 数据模型设计
- 星型模式 vs. 雪花模式: 星型模式简单直接,适合大多数OLAP查询;雪花模式则更加规范化,适合需要高度数据一致性和存储效率的场景。
- 事实表与维度表分离: 事实表存储度量值,维度表存储描述性信息,这样可以提高查询性能。
4.2 性能优化
- 索引优化: 对于频繁查询的字段创建索引,可以显著提高查询速度。
- 分区表: 对于大数据量的事实表,使用分区表可以提高查询效率。
- 缓存机制: 利用数据库的缓存机制,减少重复查询的时间开销。
4.3 安全与合规
- 数据脱敏: 对敏感数据进行脱敏处理,保护客户隐私。
- 访问控制: 实施严格的访问控制策略,确保只有授权用户才能访问数据。
通过以上案例和最佳实践,我们可以看到数据仓库和OLAP技术在现代商业智能中的重要作用。它们不仅能够帮助企业高效地管理和分析数据,还能够为企业提供有价值的洞察,推动业务发展。
继续深入:数据仓库与OLAP的最佳实践与案例分析
5. 高级分析技术
除了基本的OLAP操作和高级分析功能之外,还有一些高级分析技术可以进一步提升数据仓库的价值。这些技术包括预测分析、机器学习和人工智能等。
5.1 预测分析
预测分析是利用历史数据来预测未来趋势的一种方法。在零售业中,预测分析可以用于预测销售趋势、库存需求和客户行为等。
案例实现:
假设我们要预测下个月的销售情况。可以使用时间序列分析方法(如ARIMA模型)来进行预测。
步骤:
- 准备历史销售数据:
SELECT EXTRACT(YEAR FROM sale_date) AS year,EXTRACT(MONTH FROM sale_date) AS month,SUM(amount) AS total_sales
FROM sales_fact
GROUP BY EXTRACT(YEAR FROM sale_date), EXTRACT(MONTH FROM sale_date)
ORDER BY year, month;
- 使用Python进行预测:
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt# 读取数据
data = pd.read_sql_query("""SELECT EXTRACT(YEAR FROM sale_date) AS year,EXTRACT(MONTH FROM sale_date) AS month,SUM(amount) AS total_salesFROM sales_factGROUP BY EXTRACT(YEAR FROM sale_date), EXTRACT(MONTH FROM sale_date)ORDER BY year, month;
""", con=your_database_connection)# 转换为时间序列
data['date'] = pd.to_datetime(data[['year', 'month']].assign(day=1))
data.set_index('date', inplace=True)# 训练ARIMA模型
model = ARIMA(data['total_sales'], order=(5,1,0))
model_fit = model.fit()# 预测未来几个月的销售
forecast = model_fit.forecast(steps=3)# 可视化结果
plt.figure(figsize=(10, 6))
plt.plot(data.index, data['total_sales'], label='Historical Sales')
plt.plot(forecast.index, forecast, label='Predicted Sales', color='red')
plt.xlabel('Date')
plt.ylabel('Sales Amount')
plt.title('Sales Forecast')
plt.legend()
plt.show()
这个例子展示了如何使用ARIMA模型来预测未来的销售情况,帮助企业提前做好库存管理和营销计划。
5.2 机器学习与人工智能
机器学习和人工智能可以用于更复杂的分析任务,如客户细分、推荐系统和异常检测等。
案例实现:
假设我们要构建一个客户细分模型,以识别不同类型的客户群体。
步骤:
- 准备客户数据:
SELECT c.customer_id,c.customer_name,SUM(s.amount) AS total_spent,COUNT(DISTINCT s.transaction_id) AS order_count,AVG(s.amount) AS average_order_value,MAX(s.sale_date) - MIN(s.sale_date) AS customer_lifetime
FROM customer_dim c
JOIN sales_fact s ON c.customer_id = s.customer_id
GROUP BY c.customer_id, c.customer_name;
- 使用Python进行聚类分析:
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 读取数据
data = pd.read_sql_query("""SELECT c.customer_id,c.customer_name,SUM(s.amount) AS total_spent,COUNT(DISTINCT s.transaction_id) AS order_count,AVG(s.amount) AS average_order_value,MAX(s.sale_date) - MIN(s.sale_date) AS customer_lifetimeFROM customer_dim cJOIN sales_fact s ON c.customer_id = s.customer_idGROUP BY c.customer_id, c.customer_name;
""", con=your_database_connection)# 选择特征
features = data[['total_spent', 'order_count', 'average_order_value', 'customer_lifetime']]# 标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)# 应用KMeans聚类
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(scaled_features)
data['cluster'] = kmeans.labels_# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(data['total_spent'], data['average_order_value'], c=data['cluster'], cmap='viridis')
plt.xlabel('Total Spent')
plt.ylabel('Average Order Value')
plt.title('Customer Segmentation')
plt.colorbar(label='Cluster')
plt.show()
这个例子展示了如何使用KMeans聚类算法对客户进行细分,帮助企业更好地理解不同客户群体的特点,从而制定更有针对性的营销策略。
6. 数据仓库与OLAP的实施挑战与解决方案
尽管数据仓库和OLAP技术带来了许多优势,但在实施过程中也会遇到一些挑战。以下是一些常见的挑战及其解决方案:
6.1 数据质量问题
挑战: 数据不完整、不一致或错误的数据会影响分析结果的准确性。
解决方案:
- 数据清洗: 在数据加载到数据仓库之前,进行数据清洗,去除重复数据、填充缺失值和纠正错误数据。
- 数据验证: 使用数据验证规则确保数据的一致性和完整性。
6.2 性能问题
挑战: 大规模数据集的查询和分析可能会导致性能瓶颈。
解决方案:
- 索引优化: 对频繁查询的字段创建索引,提高查询速度。
- 分区表: 对大表进行分区,减少查询范围,提高查询效率。
- 硬件升级: 升级服务器硬件,增加内存和CPU资源。
6.3 安全与合规问题
挑战: 保护敏感数据,确保数据的安全性和合规性。
解决方案:
- 数据脱敏: 对敏感数据进行脱敏处理,保护客户隐私。
- 访问控制: 实施严格的访问控制策略,确保只有授权用户才能访问数据。
- 审计日志: 记录所有数据访问和修改操作,便于追踪和审计。
6.4 用户培训与接受度
挑战: 用户可能对新的技术和工具不熟悉,影响系统的使用效果。
解决方案:
- 培训计划: 提供详细的培训材料和培训课程,帮助用户快速上手。
- 技术支持: 设立专门的技术支持团队,解决用户在使用过程中遇到的问题。
通过以上案例和解决方案,我们可以看到数据仓库和OLAP技术在实际应用中的广泛价值和面临的挑战。正确地设计和实施数据仓库,结合先进的分析技术,可以为企业带来巨大的商业价值。
相关文章:

Oracle 第22章:数据仓库与OLAP
第22章:数据仓库与OLAP 1. 数据仓库概念 数据仓库(Data Warehouse, DW) 是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。数据仓库中的数据通常来自不同的操作型系统或外部数据源,…...

在Ubuntu上安装TensorFlow与Keras
文章目录 1. 查看系统和Python版本信息1.1 查看Ubuntu版本信息1.2 查看Python版本信息 2. 安装pip2.1 下载get-pip.py2.2 运行get-pip.py2.3 查看pip版本 3. 安装Jupyter Notebook3.1 安装Jupyter Notebook3.2 运行Jupyter Notebook3.3 安装jupyter-core3.4 配置Jupyter Notebo…...

vue data变量之间相互赋值或进行数据联动
摘要: 使用vue时开发会用到data中是数据是相互驱动,经常会想到watch,computed,总结一下! 直接赋值: 在 data 函数中定义的变量可以直接在方法中进行赋值。 export default {data() {return {a: 1,b: 2};},methods: {u…...

如何理解ref,toRef,和toRefs
1. ref ref 是 Vue 3 提供的一个用于创建响应式数据的 API。它可以用来创建简单的响应式变量,例如数字、字符串、布尔值或对象等。通过使用ref,当数据发生变化时,相关的组件视图会自动更新。 用法 创建响应式数据: import { ref …...

从单一到多元:揭秘 Hexo Diversity 主题的运行原理
揭秘 Hexo Diversity 主题的运行原理 一、 引言二、 Diversity 主题2.1 Hexo 控制台命令2.2 Hexo 核心 API2.3 运行原理2.3.1 多主题配置相关2.3.2 多主题执行指令 2.4 版本演进2.4.1 V1版本2.4.2 V2版本2.4.2.1 PC 端2.4.2.2 Phone 端 2.5 后续展望 三、 总结 一、 引言 众所…...
软考中级(系统集成项目管理工程师)案例分析计算题-笔记
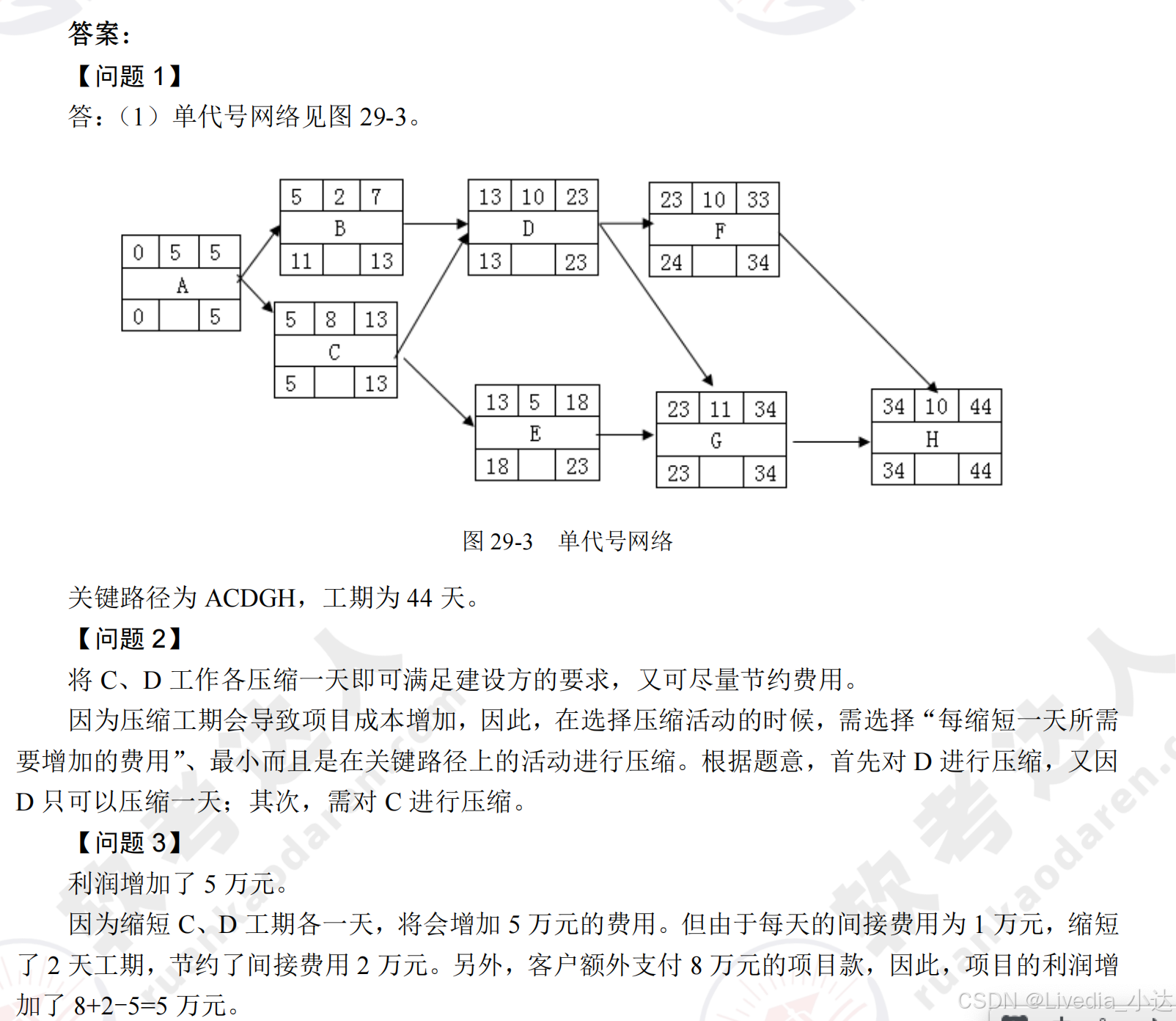
案例分析计算题必拿分!! 1.成本进度管理 初中数学题,整了一堆缩写,容易给人绕晕 知道英文全称后就好理解了名词汇总: 英文缩写英文全称含义公式PVPlanned Value (计划值)按照计划到当前时间点需要花费的钱根据题目自…...
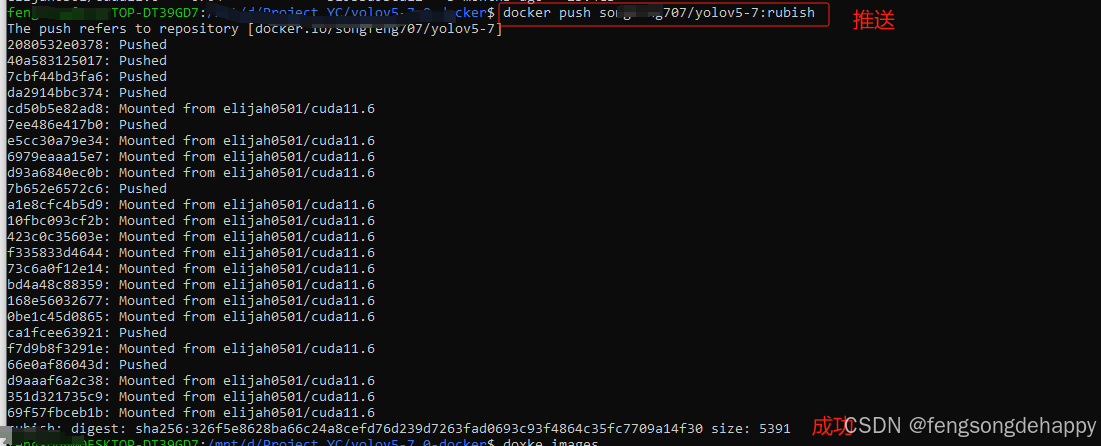
Docker打包自己项目推到Docker hub仓库(windows10)
一、启用Hyper-V和容器特性 1.应用和功能 2.点击程序和功能 3.启用或关闭Windows功能 4.开启Hyper-V 和 容器特性 记得重启生效!!! 二、安装WSL2:写文章-CSDN创作中心https://mp.csdn.net/mp_blog/creation/editor/143057041 三…...

CesiumJS 案例 P20:监听鼠标滚轮、监听鼠标左键按下与松开、监听鼠标右键按下与松开、监听鼠标左击落点
CesiumJS CesiumJS 是一个开源的 JavaScript 库,它用于在网页中创建和控制 3D 地球仪(地图) CesiumJS 官网:https://www.cesium.com/ CesiumJS 下载地址:https://www.cesium.com/platform/cesiumjs/ CesiumJS API 文…...
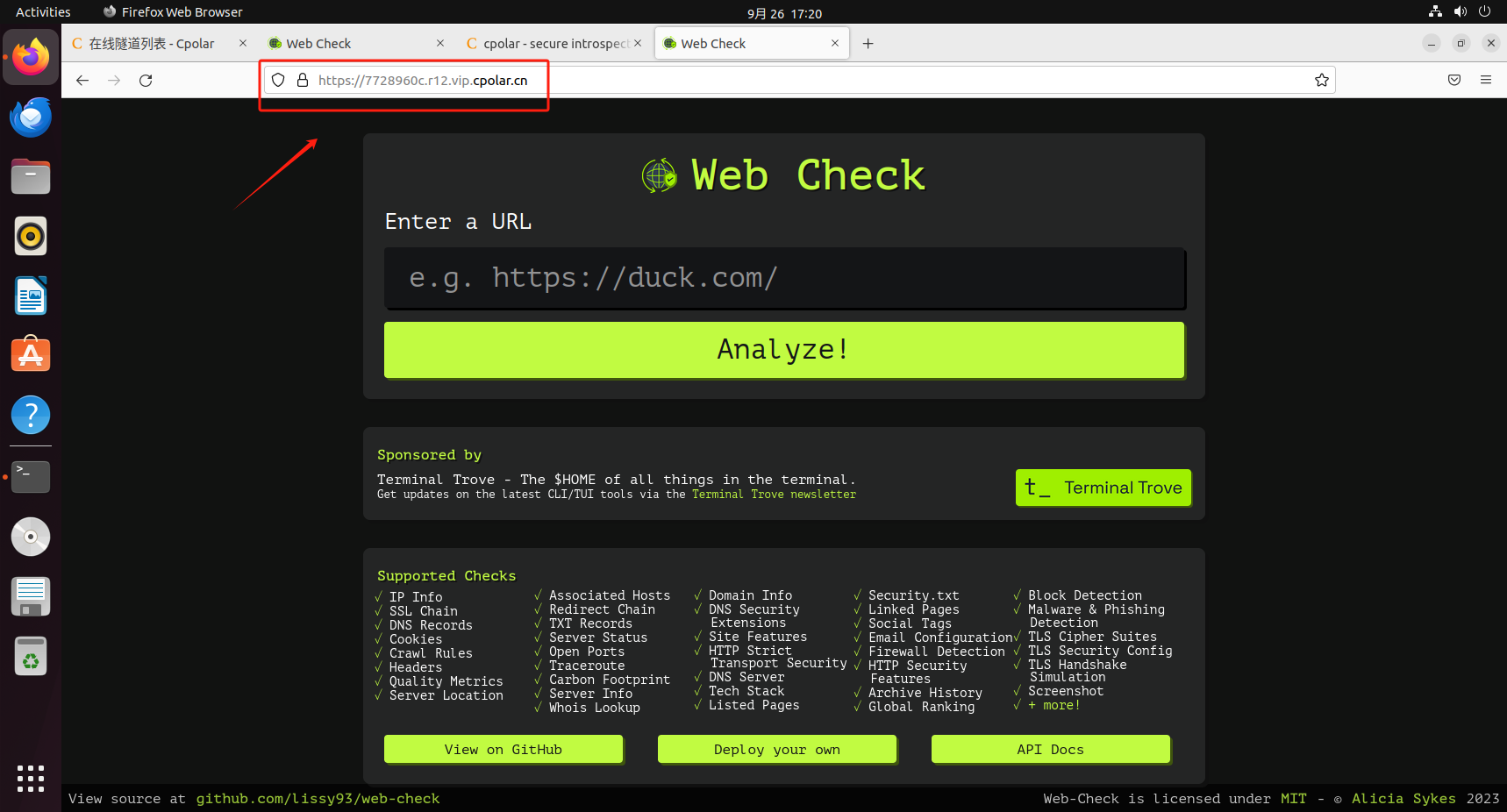
如何使用Web-Check和cpolar实现安全的远程网站监测与管理
文章目录 前言1.关于Web-Check2.功能特点3.安装Docker4.创建并启动Web-Check容器5.本地访问测试6.公网远程访问本地Web-Check7.内网穿透工具安装8.创建远程连接公网地址9.使用固定公网地址远程访问 前言 本期给大家分享一个网站检测工具Web-Check,能帮你全面了解网…...

随机生成100组N个数并对比,C++,python,matlab,pair,std::piecewise_construct
随机生成100组N个数,数的范围是1到35,并检查是否包含目标数组的数字 python版本 import numpy as np def count_groups_containing_obj(N, obj):# 随机生成100组N个数,数的范围是1到35groups np.random.randint(1, 36, size(1000, N))#pri…...

python爬虫获取数据后的数据提取
文章目录 python爬虫中的数据提取1.Json格式数据的数据提取2.Html格式数据提取之bs4解析器如何使用快速使用对象的种类Tagname和attributes属性NavigableString(字符串)BeautifulSoupComment 子节点.contents.children.descendants 父节点.parent.parents 节点内容.string.stri…...

前段(vue)
目录 跨域是什么? SprinBoot跨域的三种解决方法 JavaScript 有 8 种数据类型, 金额的用什么类型。 前段 区别 JQuery使用$.ajax()实现异步请求 Vue 父子组件间的三种通信方式 Vue2 和 Vue3 存在多方面的区别。 跨域是什么? 跨域是指…...

pairwise算法之rank svm
众所周知,point-wise/pair-wise/list-wise是机器学习领域中重要的几种建模方法。比如,最常见的分类算法使用了point-wise,即一条样本对应一个label(0/1),根据多条正负样本,使用交叉熵(cross entropy&#x…...

SAP RFC 用户安全授权
一、SAP 通讯用户 对于RFC接口的用户,使用五种用户类型之一的“通讯”类型,这种类型的用户没有登陆SAPGUI的权限。 二、对调用的RFC授权 在通讯用户内部,权限对象:S_RFC中,限制进一步可以调用的RFC函数授权ÿ…...

记录新建wordpress站的实践踩坑:wordpress 上传源码新建站因权限问题导致无法访问、配置新站建站向导以及插件主题上传配置的解决办法
官方文档:How to install WordPress – Advanced Administration Handbook | Developer.WordPress.org 但是没写权限问题,可以下载到 wordpress官方包。 把下载的wordpresscn的包解压并上传到服务器目录下,但是因为是root上传导致了权限问题…...

为啥学习数据结构和算法
基础知识就像是一座大楼的地基,它决定了我们的技术高度。而要想快速做出点事情,前提条件一定是基础能力过硬,“内功”要到位。 想要通关大厂面试,千万别让数据结构和算法拖了后腿 我们学任何知识都是为了“用”的,是为…...

Java - 免费图文识别_Java_免费_图片转文字_文字识别_spring ai_spring ai alibaba
本文主要是介绍借助阿里云免费的大模型额度来做高质量的图转文识别,图片转文字,或者文字识别都可以使用,比传统的OCR模式要直接和高效很多 。 本文使用的技术是spring ai qwen vl 。 Qwen vl有 100万Token 免费额度,可以用来免费…...

《JVM第6课》本地方法栈
文章目录 1 什么是本地方法1.1 本地方法的好处1.2 声明本地方法1.3 实现本地方法1. 生成头文件2. 编写C语言实现3. 编译C代码4. 运行Java程序 1.4 使用JNA1.5 总结 2 本地方法栈2.1 特点2.2 本地方法栈与Java虚拟机栈的区别2.3 本地方法栈的工作流程2.4 总结 无痛快速学习入门J…...

3.1 快速启动Flink集群
文章目录 1. 环境配置2. 本地启动3. 集群启动4. 向集群提交作业4.1 提交作业概述4.2 添加打包插件4.3 将项目打包4.4 在Web UI上提交作业4.5 命令行提交作业 在本实战中,我们将快速启动Apache Flink 1.13.0集群,并在Hadoop集群环境中提交作业。首先&…...

如何设计一个毫秒级的接口?
设计一个毫秒级的接口需要考虑多个方面,包括网络延迟、服务器性能、代码效率、数据库查询优化等。以下是一些建议,帮助你设计一个毫秒级的接口: 网络优化: 使用HTTP/2或更高版本,以减少连接建立和传输的开销。尽可能减…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...