python爬虫获取数据后的数据提取
文章目录
- python爬虫中的数据提取
- 1.Json格式数据的数据提取
- 2.Html格式数据提取之bs4
- 解析器
- 如何使用
- 快速使用
- 对象的种类
- Tag
- name和attributes属性
- NavigableString(字符串)
- BeautifulSoup
- Comment
- 子节点
- .contents
- .children
- .descendants
- 父节点
- .parent
- .parents
- 节点内容
- .string
- .strings
- .stripped_strings
- .text
- find_all函数
- find函数
- find_parents() 和 find_parent()
- beautifulsoup的css选择器
- 通过标签名查找
- 通过类名查找
- id名查找
- 组合查找
- 属性查找
- 3.Html格式数据提取之XPATH
- 解析流程与使用
- xpath语法
- 路径表达式
- 谓语(Predicates)
- 选取未知节点
- 选取若干路径
- 属性值获取
- 获取节点内容转换成字符串
- 4.提取数据之正则
- 匹配单个字符与数字
- 匹配锚字符
- 限定符
- 修正符
- re模块中常用函数
- match()函数
- search()函数
- findall()函数(返回列表)
- finditer()函数
- split()函数
- 贪婪与非贪婪
- 编译
- 练习
- 练习1.提取手机号与邮箱
- 练习2 匹配出 2016/06/17格式的年月日
- 练习3 正则匹配所有标题
python爬虫中的数据提取
当我们利用python爬虫模拟浏览器发送请求获取数据时,返回有用的数据通常有两种形式,一种是
json格式的数据,一种是html形式的数据。
1.Json格式数据的数据提取
现在的网站不同于从前了. 习惯性用
json来传递数据. 所以, 我们必须要知道json是啥, 以及python如何处理json.
json是一种类似字典一样的东西. 对于python而言,json是字符串.
s = '{"name": "jay", "age": 18}'
你看. 这破玩意就是json
当我们获取
json字符串时,就可以将其转换为字典来进行处理,想获取数据就像字典那样取就行了。
json字符串 => python字典
import json
s = '{"name": "jay", "age": 18}'
dic = json.loads(s)
print(type(dic))
python字典 => json字符串
import json
dic = {"name": "jay", "age": 18}
s = json.dumps(dic)
print(type(s))
json获取数据就是转换为字典进行获取数据,当然也还可以使用正则,接下来我们了解正则。
2.Html格式数据提取之bs4
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
- 安装
pip install beautifulsoup4
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
pip install lxml
如何使用
将一段文档传入BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
from bs4 import BeautifulSoupsoup = BeautifulSoup(open("index.html"), 'lxml')soup = BeautifulSoup("<html>data</html>", 'lxml')
然后,Beautiful Soup选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档。
快速使用
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p><p class="story">...</p> """使用
BeautifulSoup解析这段代码,能够得到一个BeautifulSoup的对象,并能按照标准的缩进格式的结构输出:from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'lxml') # html进行美化 print(soup.prettify())匹配代码
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p><p class="story">...</p></body> </html>
几个简单的浏览结构化数据的方法:soup.title # 获取标签title # <title>The Dormouse's story</title>soup.title.name # 获取标签名称 # 'title'soup.title.string # 获取标签title内的内容 # 'The Dormouse's story'soup.title.parent # 获取父级标签soup.title.parent.name # 获取父级标签名称 # 'head'soup.p # <p class="title"><b>The Dormouse's story</b></p>soup.p['class'] # 获取p的class属性值 # 'title'soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]soup.find(id="link3") # 获取id为link3的标签 # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
从文档中找到所有\<a>标签的链接:for link in soup.find_all('a'):print(link.get('href'))# http://example.com/elsie# http://example.com/lacie# http://example.com/tillie
从文档中获取所有文字内容:print(soup.get_text())
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为种
Tag,NavigableString,BeautifulSoup,Comment.
Tag
通俗点讲就是
HTML中的一个个标签,Tag 对象与XML或HTML原生文档中的tag相同:soup = BeautifulSoup('<b class="boldest">Extremely bold</b>') tag = soup.b type(tag) # <class 'bs4.element.Tag'>如果想获取 标签,只要用
soup.head:soup.head # <head><title>The Dormouse's story</title></head>soup.title # <title>The Dormouse's story</title>这是个获取tag的小窍门,可以在文档树的tag中多次调用这个方法.下面的代码可以获取<body>标签中的第一个<b>标签:
soup.body.b # <b>The Dormouse's story</b>通过点取属性的方式只能获得当前名字的第一个tag:
soup.a # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>如果想要得到所有的<a>标签,或是通过名字得到比一个tag更多的内容的时候,就需要用到 Searching the tree 中描述的方法,比如: find_all()
soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]我们可以利用 soup加标签名轻松地获取这些标签的内容,注意,它查找的是在所有内容中的第一个符合要求的标签。
name和attributes属性
Tag有很多方法和属性,现在介绍一下tag中最重要的属性:
name和attributes每个tag都有自己的名字,通过
.name来获取:tag.name # 'b'tag['class'] # 'boldest'tag.attrs # {'class': 'boldest'}tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样(了解)
tag['class'] = 'verybold' tag['id'] = 1 tag # <blockquote class="verybold" id="1">Extremely bold</blockquote>del tag['class'] del tag['id'] tag # <blockquote>Extremely bold</blockquote>tag['class'] # KeyError: 'class' print(tag.get('class')) # None
NavigableString(字符串)
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可.
字符串常被包含在tag内.Beautiful Soup用
NavigableString类来包装tag中的字符串tag.string # 'Extremely bold' type(tag.string) # <class 'bs4.element.NavigableString'>
BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性。
print(type(soup.name))
# <class 'str'>
print(soup.name)
# [document]
print(soup.attrs)
# {} 空字典
Comment
如果字符串内容为注释 则为Comment
html_doc='<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>'soup = BeautifulSoup(html_doc, 'html.parser')print(soup.a.string) # Elsie print(type(soup.a.string)) # <class 'bs4.element.Comment'>a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
子节点
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点.Beautiful Soup提供了许多操作和遍历子节点的属性.
注意: Beautiful Soup中字符串节点不支持这些属性,因为字符串没有子节点。
.contents
tag的
.contents属性可以将tag的子节点以列表的方式输出:head_tag = soup.head head_tag # <head><title>The Dormouse's story</title></head>head_tag.contents [<title>The Dormouse's story</title>]title_tag = head_tag.contents[0] title_tag # <title>The Dormouse's story</title> title_tag.contents # [u'The Dormouse's story']字符串没有
.contents属性,因为字符串没有子节点:text = title_tag.contents[0] text.contents # AttributeError: 'NavigableString' object has no attribute 'contents'
.children
.children它返回的不是一个 list,不过我们可以通过遍历获取所有子节点。我们打印输出 .children 看一下,可以发现它是一个 list 生成器对象
通过tag的
.children生成器,可以对tag的子节点进行循环:print(title_tag.children) # <list_iterator object at 0x101b78860> print(type(title_tag.children)) # <class 'list_iterator'>for child in title_tag.children:print(child)# The Dormouse's story
.descendants
.contents和.children属性仅包含tag的直接子节点.例如,<head>标签只有一个直接子节点<title>head_tag.contents # [<title>The Dormouse's story</title>]但是<title>标签也包含一个子节点:字符串 “The Dormouse’s story”,这种情况下字符串 “The Dormouse’s story”也属于<head>标签的子孙节点.
.descendants属性可以对所有tag的子孙节点进行递归循环 。for child in head_tag.descendants:print(child)# <title>The Dormouse's story</title># The Dormouse's story上面的例子中, <head>标签只有一个子节点,但是有2个子孙节点:<head>节点和<head>的子节点,
BeautifulSoup有一个直接子节点(<html>节点),却有很多子孙节点:len(list(soup.children)) # 1 len(list(soup.descendants)) # 25
父节点
.parent
通过
.parent属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,<head>标签是<title>标签的父节点:title_tag = soup.title title_tag # <title>The Dormouse's story</title> title_tag.parent # <head><title>The Dormouse's story</title></head>文档的顶层节点比如<html>的父节点是
BeautifulSoup对象:html_tag = soup.html type(html_tag.parent) # <class 'bs4.BeautifulSoup'>
.parents
通过元素的
.parents属性可以递归得到元素的所有父辈节点,下面的例子使用了.parents方法遍历了<a>标签到根节点的所有节点.link = soup.a link # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> for parent in link.parents:if parent is None:print(parent)else:print(parent.name) # p # body # html # [document] # None
节点内容
.string
如果tag只有一个
NavigableString类型子节点,那么这个tag可以使用.string得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用.string方法,输出结果与当前唯一子节点的.string结果相同。通俗点说就是:如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。例如:
print (soup.head.string) #The Dormouse's story # <title><b>The Dormouse's story</b></title> print (soup.title.string) #The Dormouse's story如果tag包含了多个子节点,tag就无法确定,string 方法应该调用哪个子节点的内容, .string 的输出结果是 None
print (soup.html.string) #None
.strings
获取多个内容,不过需要遍历获取,比如下面的例子:
for string in soup.strings:print(repr(string))''''\n' "The Dormouse's story" '\n' '\n' "The Dormouse's story" '\n' 'Once upon a time there were three little sisters; and their names were\n' 'Elsie' ',\n' 'Lacie' ' and\n' 'Tillie' ';\nand they lived at the bottom of a well.' '\n' '...' '\n' '''
.stripped_strings
输出的字符串中可能包含了很多空格或空行,使用
.stripped_strings可以去除多余空白内容for string in soup.stripped_strings:print(repr(string))'''"The Dormouse's story" "The Dormouse's story" 'Once upon a time there were three little sisters; and their names were' 'Elsie' ',' 'Lacie' 'and' 'Tillie' ';\nand they lived at the bottom of a well.' '...''''
.text
如果tag包含了多个子节点, text则会返回内部所有文本内容
print (soup.html.text)
注意:
strings和text都可以返回所有文本内容
区别:text返回内容为字符串类型 strings为生成器generator
find_all函数
find_all( name , attrs , recursive , string , **kwargs )
-
name 参数
-
name参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉. -
简单的用法如下:
soup.find_all("title") # [<title>The Dormouse's story</title>]搜索
name参数的值可以使任一类型的 过滤器 ,字符串,正则表达式,列表,方法或是True. -
传字符串
-
soup.find_all('b') # [<b>The Dormouse's story</b>] -
传正则表达式
-
import re for tag in soup.find_all(re.compile("^b")):print(tag.name) # body # b -
传列表
-
soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
-
-
keyword 参数
-
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为
id的参数,Beautiful Soup会搜索每个tag的”id”属性.soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]import re # 超链接包含elsie标签 print(soup.find_all(href=re.compile("elsie"))) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] # 以The作为开头的字符串 print(soup.find_all(text=re.compile("^The"))) # ["The Dormouse's story", "The Dormouse's story"] # class选择器包含st的节点 print(soup.find_all(class_=re.compile("st")))搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含
id属性的tag,无论id的值是什么:soup.find_all(id=True) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]在这里我们想用 class 过滤,不过 class 是 python 的关键词,这怎么办?加个下划线就可以
print(soup.find_all("a", class_="sister"))''' [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> ]'''通过
find_all()方法的attrs参数定义一个字典参数来搜索包含特殊属性的tag:data_soup.find_all(attrs={"data-foo": "value"}) # [<div data-foo="value">foo!</div>]注意:如何查看条件id和class同时存在时的写法
print(soup.find_all('b', class_="story", id="x")) print(soup.find_all('b', attrs={"class":"story", "id":"x"}))- text 参数
通过
text参数可以搜搜文档中的字符串内容.与name参数的可选值一样,text参数接受 字符串 , 正则表达式 , 列表, Trueimport reprint(soup.find_all(text="Elsie")) # ['Elsie']print(soup.find_all(text=["Tillie", "Elsie", "Lacie"])) # ['Elsie', 'Lacie', 'Tillie']# 只要包含Dormouse就可以 print(soup.find_all(text=re.compile("Dormouse"))) # ["The Dormouse's story", "The Dormouse's story"]- limit 参数
find_all()方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用limit参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到limit的限制时,就停止搜索返回结果.print(soup.find_all("a",limit=2)) print(soup.find_all("a")[0:2])''' [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] '''
-
find_all()方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件:soup.find_all("title") # [<title>The Dormouse's story</title>]soup.find_all("p", "title") # [<p class="title"><b>The Dormouse's story</b></p>]soup.find_all("a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]soup.find_all(id="link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]import re # 模糊查询 包含sisters的就可以 soup.find(string=re.compile("sisters")) # 'Once upon a time there were three little sisters; and their names were\n'
find函数
find(name , attrs , recursive , string , **kwargs )
find_all()方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用find_all()方法来查找<body>标签就不太合适, 使用find_all方法并设置limit=1参数不如直接使用find()方法.下面两行代码是等价的:soup.find_all('title', limit=1) # [<title>The Dormouse's story</title>]soup.find('title') # <title>The Dormouse's story</title>唯一的区别是
find_all()方法的返回结果是值包含一个元素的列表,而find()方法直接返回结果.
find_all()方法没有找到目标是返回空列表,find()方法找不到目标时,返回None.print(soup.find("nosuchtag")) # None
soup.head.title是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的find()方法:soup.head.title # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title>
find_parents() 和 find_parent()
a_string = soup.find(text="Lacie")
print(a_string) # Lacieprint(a_string.find_parent())
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
print(a_string.find_parents())
print(a_string.find_parent("p"))
'''
<p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.
</p>'''
beautifulsoup的css选择器
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
通过标签名查找
print(soup.select("title")) #[<title>The Dormouse's story</title>]
print(soup.select("b")) #[<b>The Dormouse's story</b>]
通过类名查找
print(soup.select(".sister")) '''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
id名查找
print(soup.select("#link1"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print(soup.select("p #link2"))#[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
直接子标签查找
print(soup.select("p > #link2"))
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
查找既有class也有id选择器的标签
a_string = soup.select(".story#test")
查找有多个class选择器的标签
a_string = soup.select(".story.test")
查找有多个class选择器和一个id选择器的标签
a_string = soup.select(".story.test#book")
属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select("a[href='http://example.com/tillie']"))
#[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容:
for title in soup.select('a'):print (title.get_text())'''
Elsie
Lacie
Tillie
'''
3.Html格式数据提取之XPATH
-
安装
-
安装lxml库
pip install lxml -i pip源
-
解析流程与使用
解析流程
- 实例化一个etree的对象,把即将被解析的页面源码加载到该对象
- 调用该对象的xpath方法结合着不同形式的xpath表达进行标签定位和数据提取
使用
导入lxml.etree
from lxml import etree
etree.parse()
解析本地html文件
html_tree = etree.parse(‘XX.html’)
etree.HTML()(建议)
解析网络的html字符串
html_tree = etree.HTML(html字符串)
html_tree.xpath()
使用xpath路径查询信息,返回一个列表
注意:如果lxml解析本地HTML文件报错可以安装如下添加参数
parser = etree.HTMLParser(encoding="utf-8") selector = etree.parse('./lol_1.html',parser=parser) result=etree.tostring(selector)
xpath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
路径表达式
表达式 描述 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 ./ 当前节点再次进行xpath @ 选取属性。
实例在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果 /html 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! //li 选取所有li 子元素,而不管它们在文档中的位置。 //ul//a 选择属于 ul元素的后代的所有 li元素,而不管它们位于 ul之下的什么位置。 节点对象.xpath(‘./div’) 选择当前节点对象里面的第一个div节点 //@href 选取名为 href 的所有属性。
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果 /ul/li[1] 选取属于 ul子元素的第一个 li元素。 /ul/li[last()] 选取属于 ul子元素的最后一个 li元素。 /ul/li[last()-1] 选取属于 ul子元素的倒数第二个 li元素。 //ul/li[position()❤️] 选取最前面的两个属于 ul元素的子元素的 li元素。 //a[@title] 选取所有拥有名为 title的属性的 a元素。 //a[@title=‘xx’] 选取所有 a元素,且这些元素拥有值为 xx的 title属性。 //a[@title>10] > < >= <= !=选取 a元素的所有 title元素,且其中的 title元素的值须大于 10。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
属性查询
- 查找所有包含id属性的div节点
//div[@id]
- 查找所有id属性等于maincontent的div标签
//div[@id="maincontent"]
- 查找所有的class属性
//@class
- //@attrName
//li[@name="xx"]//text() # 获取li标签name为xx的里面的文本内容
获取第几个标签 索引从1开始tree.xpath('//li[1]/a/text()') # 获取第一个 tree.xpath('//li[last()]/a/text()') # 获取最后一个 tree.xpath('//li[last()-1]/a/text()') # 获取倒数第二个
模糊查询
- 查询所有id属性中包含he的div标签
//div[contains(@id, "he")]
- 查询所有id属性中包以he开头的div标签
//div[starts-with(@id, "he")]
内容查询查找所有div标签下的直接子节点h1的内容
//div/h1/text()
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述 * 匹配任何元素节点。 一般用于浏览器copy xpath会出现 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 /ul/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。 //node() 获取所有节点
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
逻辑运算
查找所有id属性等于head并且class属性等于s_down的div标签
//div[@id="head" and @class="s_down"]选取文档中的所有 title 和 price 元素。
//title | //price注意: “|”两边必须是完整的xpath路径
属性值获取
//div/a/@href 获取a里面的href属性值获取所有
//* #获取所有 //*[@class="xx"] #获取所有class为xx的标签
获取节点内容转换成字符串
c = tree.xpath('//li/a')[0]
result=etree.tostring(c, encoding='utf-8')
print(result.decode('UTF-8'))
4.提取数据之正则
概述: 正则表达式,又称规则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern)
正则匹配是一个
模糊的匹配(不是精确匹配)
re:python自1.5版本开始增加了re模块,该模块提供了perl风格的正则表达式模式,re模块是python语言拥有了所有正则表达式的功能
- 如下四个方法经常使用
match()search()findall()finditer()
匹配单个字符与数字
| 匹配 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符,当flags被设置为re.S时,可以匹配包含换行符以内的所有字符 |
| [] | 里面是字符集合,匹配[]里任意一个字符 |
| [0123456789] | 匹配任意一个数字字符 |
| [0-9] | 匹配任意一个数字字符 |
| [a-z] | 匹配任意一个小写英文字母字符 |
| [A-Z] | 匹配任意一个大写英文字母字符 |
| [A-Za-z] | 匹配任意一个英文字母字符 |
| [A-Za-z0-9] | 匹配任意一个数字或英文字母字符 |
| [^magician] | []里的^称为脱字符,表示非,匹配不在[]内的任意一个字符 |
^[magician] | 以[]中内的某一个字符作为开头 |
| \d | 匹配任意一个数字字符,相当于[0-9] |
| \D | 匹配任意一个非数字字符,相当于[^0-9] |
| \w | 匹配字母、下划线、数字中的任意一个字符,相当于[0-9A-Za-z_] |
| \W | 匹配非字母、下划线、数字中的任意一个字符,相当于[^0-9A-Za-z_] |
| \s | 匹配空白符(空格、换页、换行、回车、制表),相当于[ \f\n\r\t] |
| \S | 匹配非空白符(空格、换页、换行、回车、制表),相当于[^ \f\n\r\t] |
匹配锚字符
锚字符:用来判定是否按照规定开始或者结尾
| 匹配 | 说明 |
|---|---|
| ^ | 行首匹配,和[]里的^不是一个意思 |
| $ | 行尾匹配 |
| \A | 匹配字符串的开始,和^的区别是\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配其他行的行首 |
| \Z | 匹配字符串的结尾,和$的区别是\Z只匹配整个字符串的结尾,即使在re.M模式下也不会匹配其他行的行尾 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
| 匹配 | 说明 |
|---|---|
| (xyz) | 匹配括号内的xyz,作为一个整体去匹配 一个单元 子存储 |
| x? | 匹配0个或者1个x,非贪婪匹配 |
| x* | 匹配0个或任意多个x |
| x+ | 匹配至少一个x |
| x{n} | 确定匹配n个x,n是非负数 |
| x{n,} | 至少匹配n个x |
| x{n,m} | 匹配至少n个最多m个x |
| x|y | |表示或的意思,匹配x或y |
通用flags(修正符)
修正符
-
作用
对正则进行修正
-
使用
search/match/findall/sub/subn/finditer等函数 flags参数的使用 -
修正符
re.I 不区分大小写匹配re.M 多行匹配 影响到^ 和 $ 的功能re.S 使.可以匹配换行符 匹配任意字符 -
使用
re.Iprint(re.findall('[a-z]','AaBb')) print(re.findall('[a-z]','AaBb', flags=re.I))re.M(实际)myStr = """asadasdd1\nbsadasdd2\ncsadasdd3""" print(re.findall('^[a-z]',myStr, )) print(re.findall('\A[a-z]',myStr)) print(re.findall('\d$',myStr)) print(re.findall('\d\Z',myStr)) # re.M print(re.findall('^[a-z]',myStr, flags=re.M)) print(re.findall('\A[a-z]',myStr, flags=re.M)) print(re.findall('\d$',myStr, flags=re.M)) print(re.findall('\d\Z',myStr, flags=re.M))re.Sprint(re.findall('<b>.*?</b>','<b>b标签</b>')) print(re.findall('<b>.*?</b>','<b>b标\n签</b>', flags=re.S))
通用函数
-
获取匹配结果
-
使用
group()方法 获取到匹配的值 -
groups()返回一个包含所有小组字符串的元组(也就是自存储的值),从 1 到 所含的小组号。
-
re模块中常用函数
match()函数
原型
def match(pattern, string, flags=0)参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 功能
匹配成功返回 匹配的对象
匹配失败 返回 None
获取匹配结果
使用group()方法 获取到匹配的值
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
注意:从第一位开始匹配 只匹配一次
示例:
import reres = re.match('\d{2}','123') print(res.group()) print(res.span())#给当前匹配到的结果起别名 s = '3G4HFD567' re.match("(?P<value>\d+)",s) print(x.group(0)) print(x.group('value'))import re # 导入re正则模块 # match 只匹配一次 必须从第一位开始 类似于 search("^") # print(re.match("a", '123456')) # print(re.match("[a-z]", '123456')) # print(re.match("[a-z]", '123x456')) # print(re.search("[a-z]", '123x456')) # print(re.match("[a-z][a-z]", '123x456')) # print(re.search("[a-z][a-z]", '123ab456')) # print(re.search("[a-z][a-z]", '123ax456b')) # print(re.search("1[3-9][0-9]{9}", '15611833906')) # print(re.search("1[3-9][0-9]{9}", '15611833906a')) # 包含 也就是字符串中包含我要的则为成功 # print(re.match("1[3-9][0-9]{9}", 'x15611833906a')) # 包含 也就是字符串中包含我要的则为成功 # print(re.search("^1[3-9][0-9]{9}", 'x15611833906a')) # print(re.search("^1[3-9][0-9]{9}", '15611833906a')) # 获取匹配的内容 # print(re.match("1[3-9][0-9]{9}$", '15611833906').group()) # 完全匹配 # 等同于下方 # print(re.search("^1[3-9][0-9]{9}$", '15611833906').group()) # 完全匹配 print(re.search("^1[3-9][0-9]{9}$", 'a15611833906').group()) # 完全匹配 # AttributeError: 'NoneType' object has no attribute 'group'
search()函数
原型
def search(pattern, string, flags=0)参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 功能
扫描整个字符串string,并返回第一个pattern模式成功的匹配
匹配失败 返回 None
注意:
只要字符串包含就可以
只匹配一次
示例
import re # 导入re正则模块 # search 只匹配一次 # print(re.search("a", '123456')) # print(re.search("[a-z]", '123456')) # print(re.search("[a-z]", '123x456')) # print(re.search("[a-z][a-z]", '123x456')) # print(re.search("[a-z][a-z]", '123ab456')) # print(re.search("[a-z][a-z]", '123ax456b')) # print(re.search("1[3-9][0-9]{9}", '15611833906')) # print(re.search("1[3-9][0-9]{9}", '15611833906a')) # 包含 也就是字符串中包含我要的则为成功 # print(re.search("1[3-9][0-9]{9}", 'x15611833906a')) # 包含 也就是字符串中包含我要的则为成功 # print(re.search("^1[3-9][0-9]{9}", 'x15611833906a')) # print(re.search("^1[3-9][0-9]{9}", '15611833906a')) # print(re.search("^1[3-9][0-9]{9}$", '15611833906a')) # 完全匹配 # print(re.search("^1[3-9][0-9]{9}$", '15611833906')) # 完全匹配 # print(re.search("^1[3-9][0-9]{9}$", '1561183390')) # 完全匹配# 获取匹配的内容 # print(re.search("^1[3-9][0-9]{9}$", '15611833906').group()) # 完全匹配
注意与match的区别
相同点:
都只匹配一次
不同点:
- search是在要匹配的字符串中 包含正则表达式的内容就可以
- match 必须第一位就开始匹配 否则匹配失败
findall()函数(返回列表)
原型
def findall(pattern, string, flags=0)参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 功能
扫描整个字符串string,并返回所有匹配的pattern模式结果的字符串列表
示例
myStr = """ <a href="http://www.baidu.com">百度</a> <A href="http://www.taobao.com">淘宝</A> <a href="http://www.id97.com">电 影网站</a> <i>我是倾斜1</i> <i>我是倾斜2</i> <em>我是倾斜2</em> """ # html里是不区分大小写 # (1)给正则里面匹配的 加上圆括号 会将括号里面的内容进行 单独的返回 res = re.findall("(<a href=\"http://www\.(.*?)\.com\">(.*?)</a>)",myStr) #[('<a href="http://www.baidu.com">百度</a>', 'baidu', '百度')]# 括号的区别 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr) #['<a href="http://www.baidu.com">百度</a>']#(2) 不区分大小写的匹配 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr,re.I) #['<a href="http://www.baidu.com">百度</a>', '<A href="http://www.taobao.com">淘宝</A>'] res = re.findall("<[aA] href=\"http://www\..*?\.com\">.*?</[aA]>",myStr) #['<a href="http://www.baidu.com">百度</a>'] # (3) 使.支持换行匹配 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr,re.S) ## (4) 支持换行 支持不区分大小写匹配 res = re.findall("<a href=\"http://www\..*?\.com\">.*?</a>",myStr,re.S|re.I) #print(res)
finditer()函数
原型
def finditer(pattern, string, flags=0)参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 功能
与
findall()类似,返回一个迭代器代码
import reres = re.finditer('\w', '12hsakda1') print(res) print(next(res))for i in res:print(i)
split()函数
作用:切割字符串
原型:
def split(patter, string, maxsplit=0, flags=0)参数
pattern正则表达式
string要拆分的字符串
maxsplit最大拆分次数 默认拆分全部
flags修正符示例
import re myStr = "asdas\rd&a\ts12d\n*a3sd@a_1sd" #通过特殊字符 对其进行拆分 成列表 res = re.split("[^a-z]",myStr) res = re.split("\W",myStr)
贪婪与非贪婪
-
贪婪模式
贪婪概念:匹配尽可能多的字符
.+匹配换行符以外的字符至少一次.*匹配换行符以外的字符任意次
实例
res = re.search('<b>.+</b>', '<b></b><b>b标签</b>') res = re.search('<b>.*</b>', '<b>b标签</b><b>b标签</b><b>b标签</b><b>b标签</b>') -
非贪婪模式
非贪婪概念:尽可能少的匹配称为非贪婪匹配,*?、+?即可
-
.+?匹配换行符以外的字符至少一次 拒绝贪婪.*?匹配换行符以外的字符任意次 拒绝贪婪
实例
res = re.search('<b>.+?</b>', '<b>b标签</b><b>b标签</b>') res = re.search('<b>.*?</b>', '<b>b标签</b><b>b标签</b><b>b标签</b><b>b标签</b>')
编译
-
概念
当在python中使用正则表达式时,re模块会做两件事,一件是
编译正则表达式,如果表达式的字符串本身不合法,会报错。另一件是用编译好的正则表达式提取匹配字符串 -
编译优点
如果一个正则表达式要使用几千遍,每一次都会编译,出于效率的考虑进行正则表达式的编译,就不需要每次都编译了,节省了编译的时间,从而提升效率
-
compile()函数
-
原型
def compile(pattern, flags=0) -
作用
将pattern模式编译成正则对象
-
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) flags 标识位,用于控制正则表达式的匹配方式 -
flags
值 说明 re.I 是匹配对大小写不敏感 re.M 多行匹配,影响到^和$ re.S 使.匹配包括换行符在内的所有字符 -
返回值
编译好的正则对象
-
示例
import re re_phone = re.compile(r"(0\d{2,3}-\d{7,8})") print(re_phone, type(re_phone)) -
编译后其他方法的使用
原型
def match(self, string, pos=0, endpos=-1) def search(self, string, pos=0, endpos=-1) def findall(self, string, pos=0, endpos=-1) def finditer(self, string, pos=0, endpos=-1) 参数
参数 说明 string 待匹配的字符串 pos 从string字符串pos下标开始 endpos 结束下标 示例
s1 = "lucky's phone is 010-88888888" s2 = "kaige's phone is 010-99999999" ret1 = re_phone.search(s1) print(ret1, ret1.group(1)) ret2 = re_phone.search(s2) print(ret2, ret2.group(1)) -
练习
练习1.提取手机号与邮箱
import re myStr = """caoxigang@baidu.html 曹 艳 Caoyan 6895 13811661805 caoyan@baidu.html 曹 宇 Yu Cao 8366 13911404565 caoyu@baidu.html 曹 越 Shirley Cao 6519 13683604090 caoyue@baidu.html 曹 政 Cao Zheng 8290 13718160690 caozheng@baidu.html 查玲莉 Zha Lingli 6259 13552551952 zhalingli@baidu.html 查 杉 Zha Shan 8580 13811691291 zhashan@baidu.html 查 宇 Rachel 8825 13341012971 zhayu@baidu.html 柴桥子 John 6262 13141498105 chaiqiaozi@baidu.html 常丽莉 lily 6190 13661003657 changlili@baidu.html 车承轩 Che Chengxuan 6358 13810729040 chechengxuan@baidu.html 陈 洁 Che 13811696984 chenxi_cs@baidu.html 陈 超 allen 8391 13810707562 chenchao@baidu.html 陈朝辉 13714189826 chenchaohui@baidu.html 陈 辰 Chen Chen 6729 13126735289 chenchen_qa@baidu.html 陈 枫 windy 8361 13601365213 chenfeng@baidu.html 陈海腾 Chen Haiteng 8684 13911884480 chenhaiteng@baidu.html 陈 红 Hebe 8614 13581610652 chenhong@baidu.html 陈后猛 Chen Houmeng 8238 13811753474 chenhoumeng@baidu.html 陈健军 Chen Jianjun 8692 13910828583 chenjianjun@baidu.html 陈 景 Chen Jing 6227 13366069932 chenjing@baidu.html 陈竞凯 Chen Jingkai 6511 13911087971 jchen@baidu.html 陈 坤 Isa13810136756 chenlei@baidu.html 陈 林 Lin Chen 6828 13520364278 chenlin@qq.com """ #匹配 手机号 print(re.findall('\d{11}',myStr)) #匹配 邮箱 print(re.findall('\w+@\w+\.\w+',myStr)) # (1) 手机号 # res = re.findall("[1][3-8]\d{9}",myStr) #(2)邮箱 # res = re.findall("\w+@.+\.\w+",myStr) # print(res)
练习2 匹配出 2016/06/17格式的年月日
import re myStr = """ 124528 男 14年 2012年5月以前 路人(0) 2017/02/21 2 顺便签约客服 940064306 男 9年 2016/07/12 宗师(1285) 2017/06/26 3 世间尽是妖魔鬼怪"(oДo*) 90年代的新一辈_ 1193887909 男 7年 2016/10/17 宗师(1084) 2017/06/26 4 萧十三楼 905519160 男 9年 2016/07/08 宗师(972) 2017/06/24 5 石头哥 北京-php-石头 2669288101 男 2年 2016/06/17 宗师(772) 2017/06/23 6缄默。 1393144035 未知 7年 2016/10/08 宗师(754) 2017/06/25 """ print(re.findall('\d+/\d+/\d+', myStr)) #老师答案: res = re.findall("[0-9]{4}/[0-9]{2}/[0-9]{2}",myStr) #1 匹配所有正常的年 7年 9年 #匹配出 2016/06/17格式的年月日 # res = re.findall("\t(\d{1,2}年)",myStr) # res = re.findall("[0-9]{4}/[0-9]{2}/[0-9]{2}",myStr) # res = re.findall("\d{4}/\d{2}/\d{2}",myStr)
练习3 正则匹配所有标题
import re
# 读取数据
f = open('豆瓣.html','r',encoding='utf-8')
data = f.read()
f.close()
"""
<a href="https://book.douban.com/subject/27104959/">离开的,留下的</a>
<a href="https://book.douban.com/subject/26961102/">灵契</a>
<a href="https://book.douban.com/subject/27054039/">寓言</a>
<a href="https://book.douban.com/subject/27139971/">高难度对话:如何与挑剔的人愉快相处</a>
"""# 正则匹配所有标题
pattern = re.compile('<a href="https://book.douban.com/subject/\d+/">(.*?)</a>')
titleList = pattern.findall(data)
print(titleList)
for i in pattern.finditer(data):print(i.groups()[0])相关文章:

python爬虫获取数据后的数据提取
文章目录 python爬虫中的数据提取1.Json格式数据的数据提取2.Html格式数据提取之bs4解析器如何使用快速使用对象的种类Tagname和attributes属性NavigableString(字符串)BeautifulSoupComment 子节点.contents.children.descendants 父节点.parent.parents 节点内容.string.stri…...

前段(vue)
目录 跨域是什么? SprinBoot跨域的三种解决方法 JavaScript 有 8 种数据类型, 金额的用什么类型。 前段 区别 JQuery使用$.ajax()实现异步请求 Vue 父子组件间的三种通信方式 Vue2 和 Vue3 存在多方面的区别。 跨域是什么? 跨域是指…...

pairwise算法之rank svm
众所周知,point-wise/pair-wise/list-wise是机器学习领域中重要的几种建模方法。比如,最常见的分类算法使用了point-wise,即一条样本对应一个label(0/1),根据多条正负样本,使用交叉熵(cross entropy&#x…...

SAP RFC 用户安全授权
一、SAP 通讯用户 对于RFC接口的用户,使用五种用户类型之一的“通讯”类型,这种类型的用户没有登陆SAPGUI的权限。 二、对调用的RFC授权 在通讯用户内部,权限对象:S_RFC中,限制进一步可以调用的RFC函数授权ÿ…...

记录新建wordpress站的实践踩坑:wordpress 上传源码新建站因权限问题导致无法访问、配置新站建站向导以及插件主题上传配置的解决办法
官方文档:How to install WordPress – Advanced Administration Handbook | Developer.WordPress.org 但是没写权限问题,可以下载到 wordpress官方包。 把下载的wordpresscn的包解压并上传到服务器目录下,但是因为是root上传导致了权限问题…...

为啥学习数据结构和算法
基础知识就像是一座大楼的地基,它决定了我们的技术高度。而要想快速做出点事情,前提条件一定是基础能力过硬,“内功”要到位。 想要通关大厂面试,千万别让数据结构和算法拖了后腿 我们学任何知识都是为了“用”的,是为…...

Java - 免费图文识别_Java_免费_图片转文字_文字识别_spring ai_spring ai alibaba
本文主要是介绍借助阿里云免费的大模型额度来做高质量的图转文识别,图片转文字,或者文字识别都可以使用,比传统的OCR模式要直接和高效很多 。 本文使用的技术是spring ai qwen vl 。 Qwen vl有 100万Token 免费额度,可以用来免费…...

《JVM第6课》本地方法栈
文章目录 1 什么是本地方法1.1 本地方法的好处1.2 声明本地方法1.3 实现本地方法1. 生成头文件2. 编写C语言实现3. 编译C代码4. 运行Java程序 1.4 使用JNA1.5 总结 2 本地方法栈2.1 特点2.2 本地方法栈与Java虚拟机栈的区别2.3 本地方法栈的工作流程2.4 总结 无痛快速学习入门J…...

3.1 快速启动Flink集群
文章目录 1. 环境配置2. 本地启动3. 集群启动4. 向集群提交作业4.1 提交作业概述4.2 添加打包插件4.3 将项目打包4.4 在Web UI上提交作业4.5 命令行提交作业 在本实战中,我们将快速启动Apache Flink 1.13.0集群,并在Hadoop集群环境中提交作业。首先&…...

如何设计一个毫秒级的接口?
设计一个毫秒级的接口需要考虑多个方面,包括网络延迟、服务器性能、代码效率、数据库查询优化等。以下是一些建议,帮助你设计一个毫秒级的接口: 网络优化: 使用HTTP/2或更高版本,以减少连接建立和传输的开销。尽可能减…...

从语义实施工程师到大数据开发工程师的职业转型
在信息技术行业,随着数据驱动决策的流行和企业对大数据需求的急剧增加,越来越多的专业人士开始考虑将他们的技能转移到大数据领域。本文将探讨如何从一个语义实施工程师转变为一个大数据开发工程师。两者虽然都与数据密切相关,但在技术重点和…...

关联容器笔记
关联容器总结 有序关联容器 键值的顺序自动排序,键值必须支持 < 操作符 底层数据结构 使用平衡树,比如(红黑树)增删查的平均时间复杂度接近 O(logn) 种类 std::set:集合,包含唯一的键元素。 std…...
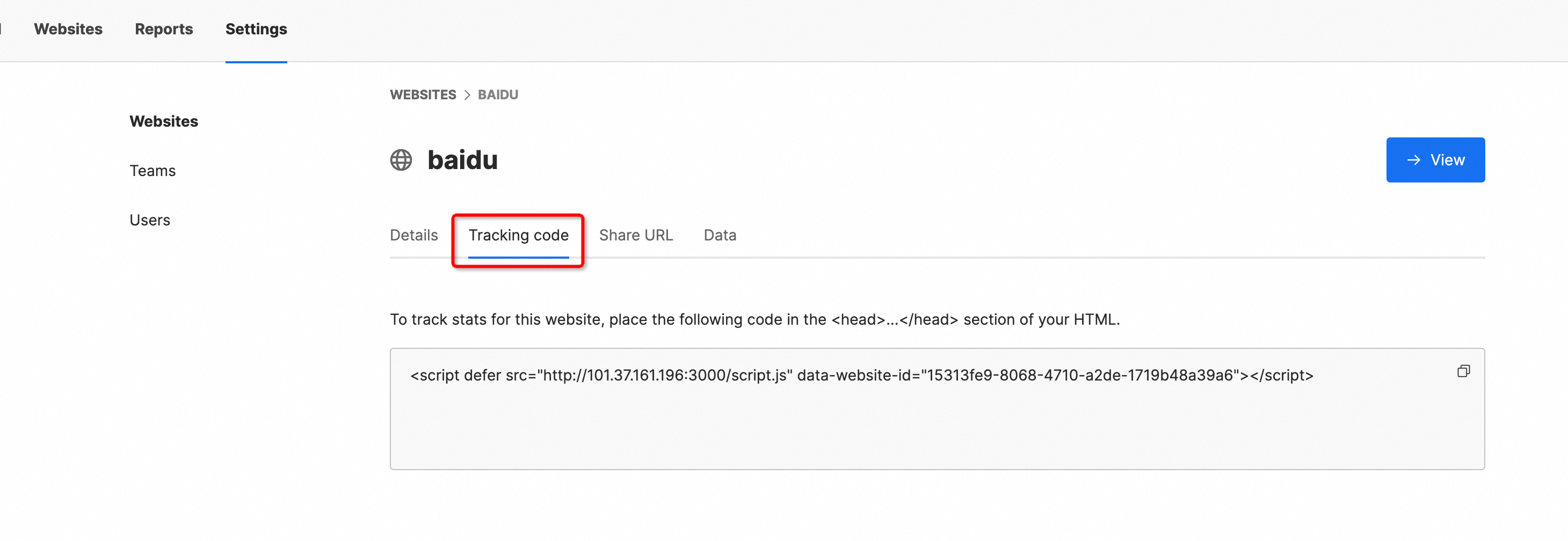
在阿里云快速启动Umami玩转网页分析
阿里云计算巢提供了Umami快速部署能力,使用者不需要自己下载代码,不需要自己安装复杂的依赖,不需要了解底层技术,只需要在控制台图形界面点击几下鼠标就可以快速部署并启动Umami,非技术同学也能轻松搞定。 什么是Umam…...

Linux练习作业
1.搭建dns服务器能够对自定义的正向或者反向域完成数据解析查询。 2.配置从DNS服务器,对主dns服务器进行数据备份 环境准备 主从服务器都需要进行的操作#关闭防火墙、SELinnux systemctl stop firewalld setenforce 0#软件安装 yum install bind -y实验一&#…...
--- Linux 下基于X11枚举所有可见窗口,并获取标题、图标、缩略图、进程路径等信息)
FFMPEG录屏(21)--- Linux 下基于X11枚举所有可见窗口,并获取标题、图标、缩略图、进程路径等信息
在 Linux X11 下枚举窗口并获取窗口信息 在 Linux 系统中,X11 是一个非常流行的窗口系统,它提供了丰富的 API 用于管理和操作窗口。在这篇博客中,我们将详细介绍如何使用 X11 枚举当前系统中的窗口,并获取它们的标题、截图、进程…...
)
mybatis resultMap标签注意事项(pageHelper结合使用的坑)
背景 使用pageHelper时,发现分页数据异常,经过排查发现是resultMap 的问题。 resultMap介绍 在使用mybatis时,我们经常会使用在xml文件中编写一些复杂的sql语句,例如多表的join,在映射实体类时,又会使用…...

100种算法【Python版】第33篇——Tonelli-Shanks算法
本文目录 1 模素数下的二次剩余问题2 算法原理2.1 背景知识2.2 算法步骤3 算法示例4 python代码5 算法应用1 模素数下的二次剩余问题 在数论中,给定一个素数 p p p 和一个整数 n n n...

深度学习基础知识-全连接层
全连接(Fully Connected,简称 FC)层是深度学习神经网络中一种基本的层结构。它主要用于神经网络的最后几层,将高层特征映射到输出空间中。全连接层对数据的每个输入节点与每个输出节点进行连接,用于实现输入特征和输出…...

ffmpeg 提取mp4文件中的音频文件并保存
要从一个 MP4 文件中提取音频并保存为单独的音频文件,可以使用 ffmpeg 工具。以下是一个简单的命令示例: 命令格式 ffmpeg -i input.mp4 -vn -acodec copy output.mp3 参数解释 -i input.mp4: 指定输入文件为 input.mp4。 -vn: 禁用视频流࿰…...

【MySQL 保姆级教学】 复合查询--超级详细(10)
复合查询 1. 复合查询的作用2. 创建将进行操作的表2.1 员工表 emp2.2 部门表 dept2.3 薪资等级表 3. 基本查询回顾4. 多表查询4.1 多表查询的定义4.2 笛卡尔积4.3 内连接 inner join4.4 交叉连接 cross join4.5 左外连接 left join4.6 右外连接 right join4.7 自连接 5. 子查询…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...
从模糊到电影级景深:Midjourney + Topaz Gigapixel联调方案(含LUT预设包+PSD分层模板)
更多请点击: https://codechina.net 第一章:从模糊到电影级景深:Midjourney Topaz Gigapixel联调方案(含LUT预设包PSD分层模板) 当Midjourney生成的图像存在主体边缘柔化、背景层次缺失或分辨率不足等问题时…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...