【测试语言篇一】Python进阶篇:内置容器数据类型
一、列表
列表(List)是一种有序且可变的容器数据类型。 与集合(Set)不同,列表允许重复的元素。 它方便保存数据序列并对其进行进一步迭代。 列表用方括号创建。
my_list = ["banana", "cherry", "apple"]
Python中基本的内置容器数据类型的比较:
-
列表(List)是一个有序且可变的数据类型。 允许重复的成员。
-
元组(Tuple)是有序且不可变的数据类型。 允许重复的成员。
-
集合(Set)是无序和未索引的数据类型。 不允许重复的成员。
-
字典(Dict)是无序,可变和可索引的数据类型。 没有重复的成员。
-
字符串是Unicode代码的不可变序列。
1、创建列表
列表使用方括号创建,或者内置的 list 函数。
list_1 = ["banana", "cherry", "apple"]
print(list_1)# 或者使用 list 函数创建空列表
list_2 = list()
print(list_2)# 列表允许不同的数据类
list_3 = [5, True, "apple"]
print(list_3)# 列表允许重复元素
list_4 = [0, 0, 1, 1]
print(list_4)['banana', 'cherry', 'apple'][][5, True, 'apple'][0, 0, 1, 1]
2、访问元素
可以通过索引号访问列表项。 请注意,索引从0开始。
item = list_1[0]
print(item)# 你也可以使用负索引,比如 -1 表示最后一个元素,
# -2 表示倒数第二个元素,以此类推
item = list_1[-1]
print(item)bananaapple
3、修改元素
只需访问索引并分配一个新值即可。
# 列表创建之后可以被修改
list_1[2] = "lemon"
print(list_1)['banana', 'cherry', 'lemon']
4、列表方法
查看Python文档以查看所有列表方法:5. Data Structures — Python 3.13.0 documentation
my_list = ["banana", "cherry", "apple"]# len() : 获取列表的元素个数
print("Length:", len(my_list))# append() : 添加一个元素到列表末尾
my_list.append("orange")# insert() : 添加元素到特定位置
my_list.insert(1, "blueberry")
print(my_list)# pop() : 移除并返回特定位置的元素,默认为最后一个
item = my_list.pop()
print("Popped item: ", item)# remove() : 移除列表中的元素
my_list.remove("cherry") # 如果元素没有在列表中,则触发 Value error
print(my_list)# clear() : 移除列表所有元素
my_list.clear()
print(my_list)# reverse() : 翻转列表
my_list = ["banana", "cherry", "apple"]
my_list.reverse()
print('Reversed: ', my_list)# sort() : 升序排列元素
my_list.sort()
print('Sorted: ', my_list)# 使用 sorted() 得到一个新列表,原来的列表不受影响
# sorted() 对任何可迭代类型起作用,不只是列表
my_list = ["banana", "cherry", "apple"]
new_list = sorted(my_list)# 创建具有重复元素的列表
list_with_zeros = [0] * 5
print(list_with_zeros)# 列表拼接
list_concat = list_with_zeros + my_list
print(list_concat)# 字符串转列表
string_to_list = list('Hello')
print(string_to_list)输出结果:
Length: 3
['banana', 'blueberry', 'cherry', 'apple', 'orange']
Popped item: orange
['banana', 'blueberry', 'apple']
[]
Reversed: ['apple', 'cherry', 'banana']
Sorted: ['apple', 'banana', 'cherry']
[0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 'banana', 'cherry', 'apple']
['H', 'e', 'l', 'l', 'o']
5、复制列表
复制引用(references)时要小心。
list_org = ["banana", "cherry", "apple"]# 这只是将引用复制到列表中,要小心
list_copy = list_org# 现在,修改复制的列表也会影响原来的列表
list_copy.append(True)
print(list_copy)
print(list_org)# 使用 copy(), 或者 list(x) 来真正复制列表
# 切片(slicing)也可以复制:list_copy = list_org[:]
list_org = ["banana", "cherry", "apple"]list_copy = list_org.copy()
# list_copy = list(list_org)
# list_copy = list_org[:]# 现在,修改复制的列表不会影响原来的列表
list_copy.append(True)
print(list_copy)
print(list_org)['banana', 'cherry', 'apple', True]['banana', 'cherry', 'apple', True]['banana', 'cherry', 'apple', True]['banana', 'cherry', 'apple']
6、迭代
# 使用for循环迭代列表
for i in list_1:print(i)banana cherry lemon
7、检查元素是否存在
if "banana" in list_1:print("yes")
else:print("no")yes
8、切片
和字符串一样,使用冒号( :)访问列表的子部分。
# a[start:stop:step], 默认步长为 1
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b = a[1:3] # 注意,最后一个索引不包括
print(b)
b = a[2:] # 直到最后
print(b)
b = a[:3] # 从第一个元素开始
print(b)
a[0:3] = [0] # 替换子部分,需要可迭代
print(a)
b = a[::2] # 从头到为每隔两个元素
print(b)
a = a[::-1] # 使用负步长翻转列表
print(a)
b = a[:] # 使用切片复制元素
print(b)[2, 3][3, 4, 5, 6, 7, 8, 9, 10][1, 2, 3][0, 4, 5, 6, 7, 8, 9, 10][0, 5, 7, 9][10, 9, 8, 7, 6, 5, 4, 0][10, 9, 8, 7, 6, 5, 4, 0]
9、列表推导
一种从现有列表创建新列表的简便快捷方法。
列表推导方括号内包含一个表达式,后跟for语句。
a = [1, 2, 3, 4, 5, 6, 7, 8]
b = [i * i for i in a] # 每个元素平方
print(b)[1, 4, 9, 16, 25, 36, 49, 64]
10、嵌套列表
a = [[1, 2], [3, 4]]
print(a)
print(a[0])[[1, 2], [3, 4]][1, 2]
二、元组
元组(Tuple)是对象的集合,它有序且不可变。 元组类似于列表,主要区别在于不可变性。 在Python中,元组用圆括号和逗号分隔的值书写。
my_tuple = ("Max", 28, "New York")
使用元组而不使用列表的原因
-
通常用于属于同一目标的对象。
-
将元组用于异构(不同)数据类型,将列表用于同类(相似)数据类型。
-
由于元组是不可变的,因此通过元组进行迭代比使用列表进行迭代要快一些。
-
具有不可变元素的元组可以用作字典的键。 使用列表做为键是不可能的。
-
如果你有不变的数据,则将其实现为元组将确保其有写保护。
1、创建元组
用圆括号和逗号分隔的值创建元组,或使用内置的 tuple 函数。
tuple_1 = ("Max", 28, "New York")
tuple_2 = "Linda", 25, "Miami" # 括弧可选# 特殊情况:只有一个元素的元组需要在在最后添加逗号,否则不会被识别为元组
tuple_3 = (25,)
print(tuple_1)
print(tuple_2)
print(tuple_3)# 或者使用内置 tuple 函数将可迭代对象(list,dict,string)转变为元组
tuple_4 = tuple([1,2,3])
print(tuple_4) ('Max', 28, 'New York')('Linda', 25, 'Miami')(25,)(1, 2, 3)
2、访问元素
可以通过引用索引号访问元组项。 请注意,索引从0开始。
item = tuple_1[0]
print(item)
# 你也可以使用负索引,比如 -1 表示最后一个元素,-2 表示倒数第二个元素,以此类推
item = tuple_1[-1]
print(item)MaxNew York
3、添加或者修改元素
不可能,会触发 TypeError 错误。
tuple_1[2] = "Boston"
---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-5-c391d8981369> in <module>----> 1 tuple_1[2] = "Boston"TypeError: 'tuple' object does not support item assignment
4、删除元组
del tuple_2
5、迭代
# 使用 for 循环迭代元组
for i in tuple_1:print(i)Max28New York
6、检查元素是否存在
if "New York" in tuple_1:print("yes")
else:print("no")yes
7、元祖方法
my_tuple = ('a','p','p','l','e',)# len() : 获取元组元素个数
print(len(my_tuple))# count(x) : 返回与 x 相等的元素个数
print(my_tuple.count('p'))# index(x) : 返回与 x 相等的第一个元素索引
print(my_tuple.index('l'))# 重复
my_tuple = ('a', 'b') * 5
print(my_tuple)# 拼接
my_tuple = (1,2,3) + (4,5,6)
print(my_tuple)# 将列表转为元组,以及将元组转为列表
my_list = ['a', 'b', 'c', 'd']
list_to_tuple = tuple(my_list)
print(list_to_tuple)tuple_to_list = list(list_to_tuple)
print(tuple_to_list)# convert string to tuple
string_to_tuple = tuple('Hello')
print(string_to_tuple) 523('a', 'b', 'a', 'b', 'a', 'b', 'a', 'b', 'a', 'b')(1, 2, 3, 4, 5, 6)('a', 'b', 'c', 'd')['a', 'b', 'c', 'd']('H', 'e', 'l', 'l', 'o')
8、切片
和字符串一样,使用冒号(:)访问列表的子部分。
# a[start:stop:step], 默认步长为 1
a = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
b = a[1:3] # 注意,最后一个索引不包括
print(b)
b = a[2:] # 知道最后
print(b)
b = a[:3] # 从最前头开始
print(b)
b = a[::2] # 从前往后没两个元素
print(b)
b = a[::-1] # 翻转元组
print(b)(2, 3)(3, 4, 5, 6, 7, 8, 9, 10)(1, 2, 3)(1, 3, 5, 7, 9)(10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
9、元组解包
# 变量个数必需与元组元素个数相同
tuple_1 = ("Max", 28, "New York")
name, age, city = tuple_1
print(name)
print(age)
print(city)# 提示: 使用 * 解包多个元素到列表
my_tuple = (0, 1, 2, 3, 4, 5)
item_first, *items_between, item_last = my_tuple
print(item_first)
print(items_between)
print(item_last)Max28New York0[1, 2, 3, 4]5
10、嵌套元组
a = ((0, 1), ('age', 'height'))
print(a)
print(a[0]) ((0, 1), ('age', 'height'))(0, 1)
11、比较元组和列表
元组的不可变性使Python可以进行内部优化。 因此,在处理大数据时,元组可以更高效。
# 比较大小
import sys
my_list = [0, 1, 2, "hello", True]
my_tuple = (0, 1, 2, "hello", True)
print(sys.getsizeof(my_list), "bytes")
print(sys.getsizeof(my_tuple), "bytes")# 比较列表和元组创建语句的执行时间
import timeit
print(timeit.timeit(stmt="[0, 1, 2, 3, 4, 5]", number=1000000))
print(timeit.timeit(stmt="(0, 1, 2, 3, 4, 5)", number=1000000))104 bytes88 bytes0.124749817000008530.014836141000017733
三、字典
字典是无序,可变和可索引的集合。 字典由键值对的集合组成。 每个键值对将键映射到其关联值。 字典用大括号书写。 每对键值均以冒号( : )分隔,并且各项之间以逗号分隔。
my_dict = {"name":"Max", "age":28, "city":"New York"}
创建字典
使用大括号或者内置的 dict 函数创建。
my_dict = {"name":"Max", "age":28, "city":"New York"}
print(my_dict)# 或者使用字典构造器,注意:键不需要引号。
my_dict_2 = dict(name="Lisa", age=27, city="Boston")
print(my_dict_2) {'name': 'Max', 'age': 28, 'city': 'New York'}{'name': 'Lisa', 'age': 27, 'city': 'Boston'}
访问元素
name_in_dict = my_dict["name"] print(name_in_dict)# 如果键没有找到,引发 KeyError 错误 # print(my_dict["lastname"])
Max
添加或修改元素
只需添加或访问键并分配值即可。
# 添加新键
my_dict["email"] = "max@xyz.com"
print(my_dict)# 覆盖已经存在的键
my_dict["email"] = "coolmax@xyz.com"
print(my_dict) {'name': 'Max', 'age': 28, 'city': 'New York', 'email': 'max@xyz.com'}{'name': 'Max', 'age': 28, 'city': 'New York', 'email': 'coolmax@xyz.com'}
删除元素
# 删除键值对
del my_dict["email"]# pop 返回值并删除键值对
print("popped value:", my_dict.pop("age"))# 返回并移除最后插入的价值对
# (在 Python 3.7 之前,移除任意键值对)
print("popped item:", my_dict.popitem())print(my_dict)# clear() : 移除所有键值对
# my_dict.clear()popped value: 28popped item: ('city', 'New York'){'name': 'Max'}
检查键my_dict = {"name":"Max", "age":28, "city":"New York"}
# 使用 if .. in ..
if "name" in my_dict:print(my_dict["name"])# 使用 try except
try:print(my_dict["firstname"])
except KeyError:print("No key found")MaxNo key found
遍历字典
# 遍历键
for key in my_dict:print(key, my_dict[key])# 遍历键
for key in my_dict.keys():print(key)# 遍历值
for value in my_dict.values():print(value)# 遍历键和值
for key, value in my_dict.items():print(key, value)name Maxage 28city New YorknameagecityMax28New Yorkname Maxage 28city New York
复制字典
复制索引时请注意。
dict_org = {"name":"Max", "age":28, "city":"New York"}# 这只复制字典的引用,需要小心
dict_copy = dict_org# 修改复制字典也会影响原来的字典
dict_copy["name"] = "Lisa"
print(dict_copy)
print(dict_org)# 使用 copy() 或者 dict(x) 来真正复制字典
dict_org = {"name":"Max", "age":28, "city":"New York"}dict_copy = dict_org.copy()
# dict_copy = dict(dict_org)# 现在修改复制字典不会影响原来的字典
dict_copy["name"] = "Lisa"
print(dict_copy)
print(dict_org) {'name': 'Lisa', 'age': 28, 'city': 'New York'}{'name': 'Lisa', 'age': 28, 'city': 'New York'}{'name': 'Lisa', 'age': 28, 'city': 'New York'}{'name': 'Max', 'age': 28, 'city': 'New York'}
合并两个字典
# 使用 update() 方法合两个字典
# 存在的键会被覆盖,新键会被添加
my_dict = {"name":"Max", "age":28, "email":"max@xyz.com"}
my_dict_2 = dict(name="Lisa", age=27, city="Boston")my_dict.update(my_dict_2)
print(my_dict) {'name': 'Lisa', 'age': 27, 'email': 'max@xyz.com', 'city': 'Boston'}
可能的键类型
任何不可变的类型(例如字符串或数字)都可以用作键。 另外,如果元组仅包含不可变元素,则可以使用它作为键。
# 使用数字做键,但要小心
my_dict = {3: 9, 6: 36, 9:81}
# 不要将键误认为是列表的索引,例如,在这里无法使用 my_dict[0]
print(my_dict[3], my_dict[6], my_dict[9])# 使用仅包含不可变元素(例如数字,字符串)的元组
my_tuple = (8, 7)
my_dict = {my_tuple: 15}print(my_dict[my_tuple])
# print(my_dict[8, 7])# 不能使用列表,因为列表是可变的,会抛出错误:
# my_list = [8, 7]
# my_dict = {my_list: 15}9 36 8115
嵌套字典
值也可以是容器类型(例如列表,元组,字典)。
my_dict_1 = {"name": "Max", "age": 28}
my_dict_2 = {"name": "Alex", "age": 25}
nested_dict = {"dictA": my_dict_1,"dictB": my_dict_2}
print(nested_dict) {'dictA': {'name': 'Max', 'age': 28}, 'dictB': {'name': 'Alex', 'age': 25}}
四、 字符串
字符串是字符序列。 Python中的字符串用双引号或单引号引起来。
my_string = 'Hello'
Python字符串是不可变的,这意味着它们在创建后就无法更改。
创建
# 使用单引号后者双引号
my_string = 'Hello'
my_string = "Hello"
my_string = "I' m a 'Geek'"# 转义反斜杠
my_string = 'I\' m a "Geek"'
my_string = 'I\' m a \'Geek\''
print(my_string)# 多行字符串使用三个引号
my_string = """Hello
World"""
print(my_string)# 如果需要字符串在下一行继续,使用反斜杠
my_string = "Hello \
World"
print(my_string)I' m a 'Geek'HelloWorldHello World
访问字符和子字符串
my_string = "Hello World"# 使用索引获取字符
b = my_string[0]
print(b)# 通过切片获取子字符串
b = my_string[1:3] # 注意,最后一个索引不包括
print(b)
b = my_string[:5] # 从第一个元素开始
print(b)
b = my_string[6:] # 直到最后
print(b)
b = my_string[::2] # 从头到为每隔两个元素
print(b)
b = my_string[::-1] # 使用负步长翻转列表
print(b)HelHelloWorldHloWrddlroW olleH
连接两个或多个字符串
# 使用 + 拼接字符串
greeting = "Hello"
name = "Tom"
sentence = greeting + ' ' + name
print(sentence)Hello Tom
迭代
# 使用for循环迭代列表
my_string = 'Hello'
for i in my_string:print(i)Hello
检查字符或子字符串是否存在
if "e" in "Hello":print("yes")
if "llo" in "Hello":print("yes")yesyes
有用的方法
my_string = " Hello World "# 去除空格
my_string = my_string.strip()
print(my_string)# 字符的个数
print(len(my_string))# 大小写
print(my_string.upper())
print(my_string.lower())# startswith 和 endswith
print("hello".startswith("he"))
print("hello".endswith("llo"))# 找到子字符串的第一个索引,没有则返回 -1
print("Hello".find("o"))# 计算字符或者子字符串的个数
print("Hello".count("e"))# 使用其他字符串代替子字符串(当且仅当子字符串存在时)
# 注意:原字符串保持不变
message = "Hello World"
new_message = message.replace("World", "Universe")
print(new_message)# 将字符串切分为为列表
my_string = "how are you doing"
a = my_string.split() # default argument is " "
print(a)
my_string = "one,two,three"
a = my_string.split(",")
print(a)# 将列表拼接为字符串
my_list = ['How', 'are', 'you', 'doing']
a = ' '.join(my_list) # 给出的字符串是分隔符,比如在每个元素之间添加 ' '
print(a)Hello World11HELLO WORLDhello world['how', 'are', 'you', 'doing']['one', 'two', 'three']TrueTrue41Hello UniverseHow are you doing
格式化
新样式使用 format() 方法,旧样式使用 % 操作符。
# 使用大括号做占位符
a = "Hello {0} and {1}".format("Bob", "Tom")
print(a)# 默认顺序时位置可以不写
a = "Hello {} and {}".format("Bob", "Tom")
print(a)a = "The integer value is {}".format(2)
print(a)# 一些数字的特殊格式化规则
a = "The float value is {0:.3f}".format(2.1234)
print(a)
a = "The float value is {0:e}".format(2.1234)
print(a)
a = "The binary value is {0:b}".format(2)
print(a)# old style formatting by using % operator
# 旧的方式使用 % 操作符
print("Hello %s and %s" % ("Bob", "Tom")) # 多个参数时必需是元组
val = 3.14159265359
print("The decimal value is %d" % val)
print("The float value is %f" % val)
print("The float value is %.2f" % val)Hello Bob and TomHello Bob and TomThe integer value is 2The float value is 2.123The float value is 2.123400e+00The binary value is 10Hello Bob and TomThe decimal value is 10The float value is 10.123450The float value is 10.12
f-Strings
从 Python 3.6 起,可以直接在花括号内使用变量。
name = "Eric"
age = 25
a = f"Hello, {name}. You are {age}."
print(a)
pi = 3.14159
a = f"Pi is {pi:.3f}"
print(a)
# f-Strings 在运行时计算,可以允许表达式
a = f"The value is {2*60}"
print(a)Hello, Eric. You are 25.Pi is 3.142The value is 120
更多关于不变性和拼接
# 因为字符串不可变,所以使用 + 或者 += 拼接字符串总是生成新的字符串 # 因此,多个操作时更加耗时。使用 join 方法更快。
from timeit import default_timer as timer
my_list = ["a"] * 1000000# bad
start = timer()
a = ""
for i in my_list:a += i
end = timer()
print("concatenate string with + : %.5f" % (end - start))# good
start = timer()
a = "".join(my_list)
end = timer()
print("concatenate string with join(): %.5f" % (end - start))concat string with + : 0.34527concat string with join(): 0.01191
# a[start:stop:step], 默认步长为 1 a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] b = a[1:3] # 注意,最后一个索引不包括 print(b) b = a[2:] # 直到最后 print(b) b = a[:3] # 从第一个元素开始 print(b) a[0:3] = [0] # 替换子部分,需要可迭代 print(a) b = a[::2] # 从头到为每隔两个元素 print(b) a = a[::-1] # 使用负步长翻转列表 print(a) b = a[:] # 使用切片复制元素 print(b)
五、集合
集合是无序的容器数据类型,它是无索引的,可变的并且没有重复的元素。 集合用大括号创建。
my_set = {"apple", "banana", "cherry"}
创建集合
使用花括号或内置的 set 函数。
my_set = {"apple", "banana", "cherry"}
print(my_set)# 或者使用 set 函数从可迭代对象创建,比如列表,元组,字符串
my_set_2 = set(["one", "two", "three"])
my_set_2 = set(("one", "two", "three"))
print(my_set_2)my_set_3 = set("aaabbbcccdddeeeeeffff")
print(my_set_3)# 注意:一个空的元组不能使用 {} 创建,这个会识别为字典
# 使用 set() 进行创建
a = {}
print(type(a))
a = set()
print(type(a)) {'banana', 'apple', 'cherry'}{'three', 'one', 'two'}{'b', 'c', 'd', 'e', 'f', 'a'}<class 'dict'><class 'set'>
添加元素(add方法)
my_set = set()# 使用 add() 方法添加元素
my_set.add(42)
my_set.add(True)
my_set.add("Hello")# 注意:顺序不重要,只会影响打印输出
print(my_set)# 元素已经存在是没有影响
my_set.add(42)
print(my_set) {True, 42, 'Hello'}{True, 42, 'Hello'}
移除元素(remove方法)
# remove(x): 移除 x, 如果元素不存在则引发 KeyError 错误
my_set = {"apple", "banana", "cherry"}
my_set.remove("apple")
print(my_set)# KeyError:
# my_set.remove("orange")# discard(x): 移除 x, 如果元素不存在则什么也不做
my_set.discard("cherry")
my_set.discard("blueberry")
print(my_set)# clear() : 移除所有元素
my_set.clear()
print(my_set)# pop() : 移除并返回随机一个元素
a = {True, 2, False, "hi", "hello"}
print(a.pop())
print(a) {'banana', 'cherry'}{'banana'}set()False{True, 2, 'hi', 'hello'}
检查元素是否存在
my_set = {"apple", "banana", "cherry"}
if "apple" in my_set:print("yes")yes
迭代
# 使用 for 循环迭代集合
# 注意:顺序不重要
my_set = {"apple", "banana", "cherry"}
for i in my_set:print(i)bananaapplecherry
并集和交集
odds = {1, 3, 5, 7, 9}
evens = {0, 2, 4, 6, 8}
primes = {2, 3, 5, 7}# union() : 合并来自两个集合的元素,不重复
# 注意这不会改变两个集合
u = odds.union(evens)
print(u)# intersection(): 选择在两个集合中都存在的元素
i = odds.intersection(evens)
print(i)i = odds.intersection(primes)
print(i)i = evens.intersection(primes)
print(i) {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}set(){3, 5, 7}{2}
集合的差
setA = {1, 2, 3, 4, 5, 6, 7, 8, 9}
setB = {1, 2, 3, 10, 11, 12}# difference() : 返回集合 setA 中不在集合 setB 中的元素的集合
diff_set = setA.difference(setB)
print(diff_set)# A.difference(B) 与 B.difference(A) 不一样
diff_set = setB.difference(setA)
print(diff_set)# symmetric_difference() : 返回集合 setA 和 setB 中不同时在两个集合中的元素的集合
diff_set = setA.symmetric_difference(setB)
print(diff_set)# A.symmetric_difference(B) = B.symmetric_difference(A)
diff_set = setB.symmetric_difference(setA)
print(diff_set) {4, 5, 6, 7, 8, 9}{10, 11, 12}{4, 5, 6, 7, 8, 9, 10, 11, 12}{4, 5, 6, 7, 8, 9, 10, 11, 12}
更新集合
setA = {1, 2, 3, 4, 5, 6, 7, 8, 9}
setB = {1, 2, 3, 10, 11, 12}# update() : 通过添加其他集合的元素进行更新
setA.update(setB)
print(setA)# intersection_update() : 通过保留共同的元素进行更新
setA = {1, 2, 3, 4, 5, 6, 7, 8, 9}
setA.intersection_update(setB)
print(setA)# difference_update() : 通过移除与其他集合中相同的元素进行更新
setA = {1, 2, 3, 4, 5, 6, 7, 8, 9}
setA.difference_update(setB)
print(setA)# symmetric_difference_update() : 通过保留只出现在一个集合而不出现在另一个集合中的元素进行更新
setA = {1, 2, 3, 4, 5, 6, 7, 8, 9}
setA.symmetric_difference_update(setB)
print(setA)# 注意:所有的更新方法同时适用于其他可迭代对象作为参数,比如列表,元组
# setA.update([1, 2, 3, 4, 5, 6]) {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}{1, 2, 3}{4, 5, 6, 7, 8, 9}{4, 5, 6, 7, 8, 9, 10, 11, 12}
复制
set_org = {1, 2, 3, 4, 5}# 只是引用的复制,需要注意
set_copy = set_org# 修改复制集合也会影响原来的集合
set_copy.update([3, 4, 5, 6, 7])
print(set_copy)
print(set_org)# 使用 copy() 真正复制集合
set_org = {1, 2, 3, 4, 5}
set_copy = set_org.copy()# 现在修改复制集合不会影响原来的集合
set_copy.update([3, 4, 5, 6, 7])
print(set_copy)
print(set_org) {1, 2, 3, 4, 5, 6, 7}{1, 2, 3, 4, 5, 6, 7}{1, 2, 3, 4, 5, 6, 7}{1, 2, 3, 4, 5}
子集,超集和不交集
setA = {1, 2, 3, 4, 5, 6}
setB = {1, 2, 3}
# issubset(setX): 如果 setX 包含集合,返回 True
print(setA.issubset(setB))
print(setB.issubset(setA)) # True# issuperset(setX): 如果集合包含 setX,返回 True
print(setA.issuperset(setB)) # True
print(setB.issuperset(setA))# isdisjoint(setX) : 如果两个集合交集为空,比如没有相同的元素,返回 True
setC = {7, 8, 9}
print(setA.isdisjoint(setB))
print(setA.isdisjoint(setC))FalseTrueTrueFalseFalseTrue
Frozenset
Frozenset 只是普通集和的不变版本。 尽管可以随时修改集合的元素,但 Frozenset 的元素在创建后保持不变。 创建方式:
my_frozenset = frozenset(iterable)
a = frozenset([0, 1, 2, 3, 4])# 以下操作不允许:
# a.add(5)
# a.remove(1)
# a.discard(1)
# a.clear()# 同时,更新方法也不允许:
# a.update([1,2,3])# 其他集合操作可行
odds = frozenset({1, 3, 5, 7, 9})
evens = frozenset({0, 2, 4, 6, 8})
print(odds.union(evens))
print(odds.intersection(evens))
print(odds.difference(evens)) frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})frozenset()frozenset({1, 3, 5, 7, 9})
相关文章:

【测试语言篇一】Python进阶篇:内置容器数据类型
一、列表 列表(List)是一种有序且可变的容器数据类型。 与集合(Set)不同,列表允许重复的元素。 它方便保存数据序列并对其进行进一步迭代。 列表用方括号创建。 my_list ["banana", "cherry", …...
湘潭大学软件工程专业选修 SOA 期末考试复习(二)
文章目录 回顾序言第一章课后题填空选择简答 第二章课后题填空选择编程 计划第三章课后题填空选择简答编程 第四章课后题填空选择简答编程 第五章课后题填空选择简答编程 第六章课后题说明 第七章课后题填空选择简答编程 第八章课后题填空选择简答编程 第九章课后题填空选择简答…...

改进的正弦余弦算法复现
本文所涉及所有资源均在 传知代码平台 可获取。 目录 一、背景及意义 (一)背包问题背景...

Day13杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 class Solution {public List<List<Integer>> generate(int numRows) {List<List<Integer>> res new Arra…...

【c知道】Hadoop工作原理。
请解释一下Hadoop中MapReduce的工作原理,并说明如何进行MapReduce程序的编写和调试。 Hadoop MapReduce是一种分布式计算模型,它将大规模的数据处理任务分解成一系列小的、独立的任务(Map任务)和后续的聚合任务(Reduce…...
 懒加载)
React.lazy() 懒加载
概要 React.lazy() 是 React 16.6 引入的一个功能,用于实现代码分割(code splitting)。它允许你懒加载组件,即在需要时才加载组件,而不是在应用初始加载时就加载所有组件。这种方法可以显著提高应用的性能,…...
【自学笔记】神经网络(1)
文章目录 介绍模型结构层(Layer)神经元 前向传播反向传播Q1: 为什么要用向量Q2: 不用激活函数会发生什么 介绍 我们已经学习了简单的分类任务和回归任务,也认识了逻辑回归和正则化等技巧,已经可以搭建一个简单的神经网络模型了。 …...

c#————扩展方法
关键点: 定义扩展方法的类和方法必须是静态的: 扩展方法必须在一个静态类中定义。扩展方法本身也必须是静态的。第一个参数使用 this 关键字: 扩展方法的第一个参数指定要扩展的类型,并且在这个参数前加上 this 关键字。这个参数…...
资料汇总)
前向-后向卡尔曼滤波器(Forward-Backward Kalman Filter)资料汇总
《卡尔曼滤波引出的RTS平滑》参考位置2《卡尔曼滤波系列——(六)卡尔曼平滑》《关于卡尔曼滤波和卡尔曼平滑关系的理解》——有m语言例程《Forward Backwards Kalman Filter》——Matlab软件《卡尔曼滤波与隐马尔可夫模型》...
云集电商:如何通过 OceanBase 实现降本 87.5%|OceanBase案例
云集电商,一家聚焦于社交电商的电商公司,专注于‘精选’理念,致力于为会员提供超高性价比的全品类精选商品,以“批发价”让亿万消费者买到质量可靠的商品。面对近年来外部环境的变化,公司对成本控制提出了更高要求&…...

详解Rust标准库:BTreeMap
std::collections::BTreeMap定义 B树也称B-树,注意不是减号,是一棵多路平衡查找树;理论上,二叉搜索树 (BST) 是最佳的选择排序映射,但是每次查找时层数越多I/O次数越多,B 树使每个节…...

.NET WPF CommunityToolkit.Mvvm框架
文章目录 .NET WPF CommunityToolkit.Mvvm框架1 源生成器1.1 ObservablePropertyAttribute & RelayCommandAttribute1.2 INotifyPropertyChangedAttribute 2 可观测对象2.1 ObservableValidator2.2 ObservableRecipient .NET WPF CommunityToolkit.Mvvm框架 1 源生成器 1…...
微信小程序使用阿里巴巴矢量图标库正确姿势
1、打开官网:https://www.iconfont.cn/,把整理好的图标下载解压。 2、由于微信小程序不支持直接在wxss中引入.ttf/.woff/.woff2(在开发工具生效,手机不生效)。我们需要对下载的文件进一步处理。 eot:IE系列…...

【K8S问题系列 |1 】Kubernetes 中 NodePort 类型的 Service 无法访问【已解决】
在 Kubernetes 中,NodePort 类型的 Service 允许用户通过每个节点的 IP 地址和指定的端口访问应用程序。如果 NodePort 类型的 Service 无法通过节点的 IP 地址和指定端口进行访问,可能会导致用户无法访问应用。本文将详细分析该问题的常见原因及其解决方…...

Java基础Day-Thirteen
Java字符串 String类 创建String对象的方法 方法一:创建一个字符串对象imooc,名为s1 String s1"imooc"; 方法二:创建一个空字符串对象,名为s2 String s2new String(); 方法三:创建一个字符串对象imooc&a…...
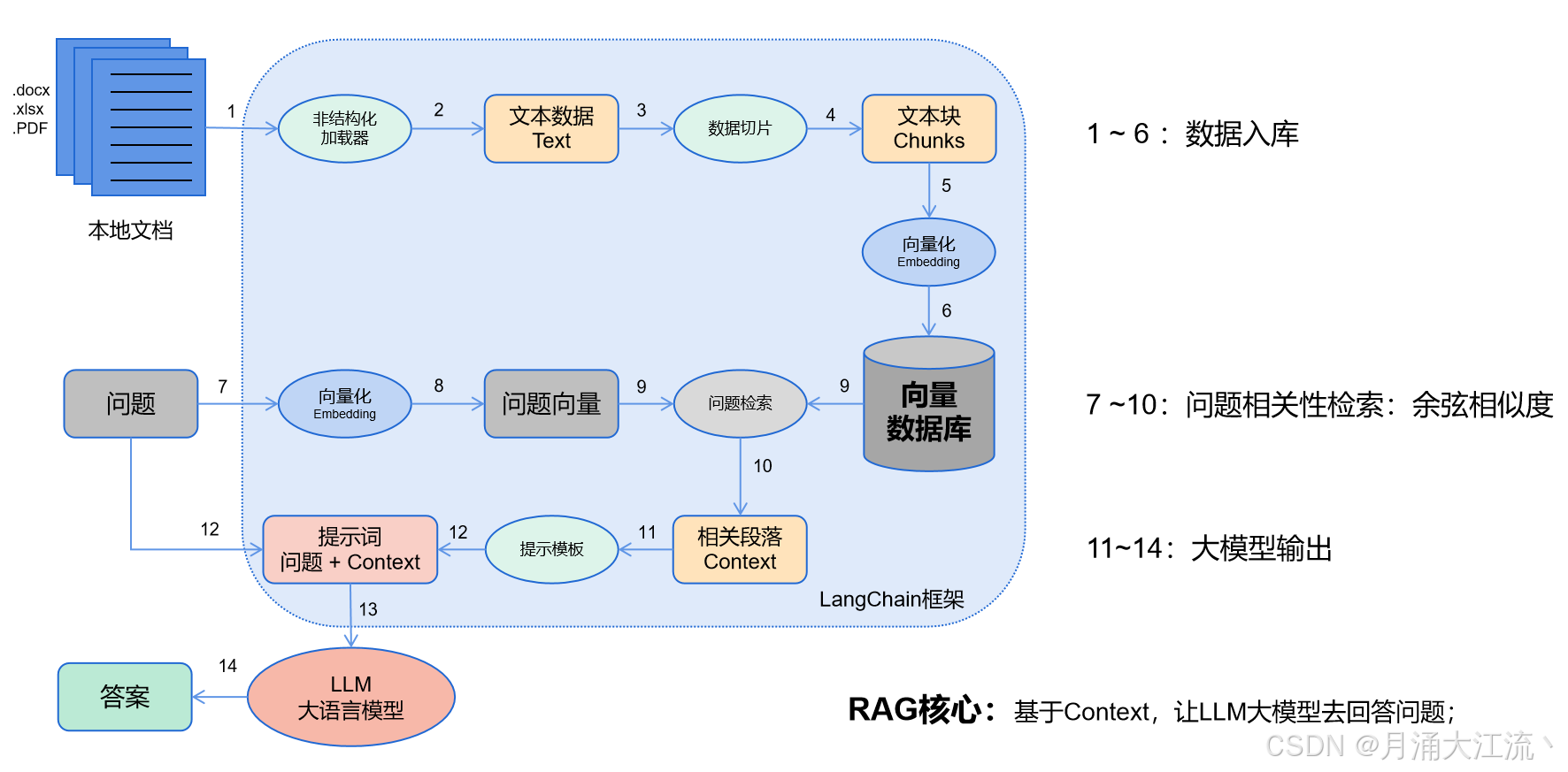
LangChain实际应用
1、LangChain与RAG检索增强生成技术 LangChain是个开源框架,可以将大语言模型与本地数据源相结合,该框架目前以Python或JavaScript包的形式提供; 大语言模型:可以是GPT-4或HuggingFace的模型;本地数据源:…...

【数据结构】哈希/散列表
目录 一、哈希表的概念二、哈希冲突2.1 冲突概念2.2 冲突避免2.2.1 方式一哈希函数设计2.2.2 方式二负载因子调节 2.3 冲突解决2.3.1 闭散列2.3.2 开散列(哈希桶) 2.4 性能分析 三、实现简单hash桶3.1 内部类与成员变量3.2 插入3.3 获取value值3.4 总代码…...
flutter 项目初建碰到的控制台报错无法启动问题
在第一次运行flutter时,会碰见一直卡在Runing Gradle task assembleDebug的问题。其实出现这个问题的原因有两个。 一:如果你flutter -doctor 检测都很ok,而且环境配置都很正确,那么大概率就是需要多等一会,少则几十分…...

Java字符串深度解析:String的实现、常量池与性能优化
引言 在Java编程中,字符串操作是最常见的任务之一。String 类在 Java 中有着独特的实现和特性,理解其背后的原理对于编写高效、安全的代码至关重要。本文将深入探讨 String 的实现机制、字符串常量池、不可变性的优点,以及 String、StringBu…...

leetcode 2043.简易银行系统
1.题目要求: 示例: 输入: ["Bank", "withdraw", "transfer", "deposit", "transfer", "withdraw"] [[[10, 100, 20, 50, 30]], [3, 10], [5, 1, 20], [5, 20], [3, 4, 15], [10, 50]] 输出ÿ…...

pdf2pptx:打破学术演示壁垒的智能转换神器
pdf2pptx:打破学术演示壁垒的智能转换神器 【免费下载链接】pdf2pptx Convert your (Beamer) PDF slides to (Powerpoint) PPTX 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2pptx 你是否曾因LaTeX Beamer制作的精美数学公式幻灯片无法在PowerPoint中完…...
3步掌握TransNet V2:从零开始实现智能视频镜头检测
3步掌握TransNet V2:从零开始实现智能视频镜头检测 【免费下载链接】TransNetV2 TransNet V2: Shot Boundary Detection Neural Network 项目地址: https://gitcode.com/gh_mirrors/tr/TransNetV2 想要快速分析视频内容结构,自动识别镜头切换点吗…...

思源宋体完全指南:免费开源中文字体的终极解决方案
思源宋体完全指南:免费开源中文字体的终极解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中的中文字体授权费用而烦恼吗?或者在不同平台…...

3步打造个人漫画库:BiliBili-Manga-Downloader完整使用指南
3步打造个人漫画库:BiliBili-Manga-Downloader完整使用指南 【免费下载链接】BiliBili-Manga-Downloader 一个好用的哔哩哔哩漫画下载器,拥有图形界面,支持关键词搜索漫画和二维码登入,黑科技下载未解锁章节,多线程下载…...

Unity 2D基础:Rigidbody2D刚体的运动控制
Unity 2D基础:Rigidbody2D刚体的运动控制📚 本章学习目标:深入理解Rigidbody2D刚体的运动控制的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2D基础篇…...

Rust编程学习.0-安装及环境搭建
目录 前言 一、Rust是什么? 二、Rust安装及环境搭建 1.安装 2.环境搭建 总结 前言 本人借助工作的机会准备好好学习语言编程以及深造嵌入式开发方向,更加系统深入网络,为了不再和之前一样做完再花时间回忆并记录,0帧起手开始…...

3步掌握HTTrack:免费网站离线下载工具终极指南
3步掌握HTTrack:免费网站离线下载工具终极指南 【免费下载链接】httrack HTTrack Website Copier, copy websites to your computer (Official repository) 项目地址: https://gitcode.com/gh_mirrors/ht/httrack 你是否经常遇到网络不稳定,却急需…...

2026年计算机专业就业现状,不想35岁被淘汰?网络安全或许是程序员的最佳转型方向!
计算机专业虽进入分化阶段,但网络安全人才缺口达300万,高端领域供不应求。高校扩招与市场需求脱节导致供需失衡,未来"计算机行业"的复合型人才更具竞争力。建议早做规划,构建"T型能力体系",掌握前…...

Arm Neoverse N2与CMN-700系统中的PoC与缓存一致性解析
1. Neoverse N2与CMN-700系统中的PoC定位解析 在基于Arm Neoverse N2处理器和CMN-700互连架构的系统中,理解Point of Coherency(PoC)的位置对于正确执行缓存维护操作至关重要。PoC是系统中所有能够访问内存的代理(包括那些未连接到…...

Keil MDK-ARM许可证错误-25的解决方案
1. 问题现象与背景解析最近在升级Keil MDK-ARM到新版本后,不少开发者遇到了一个棘手的许可证错误。当尝试编译项目时,系统会弹出如下错误提示:Error: A9555E: License checkout for feature mdk_xxx_compiler5 with version 5.0201411 has be…...