Group By、Having用法总结(常见踩雷点总结—SQL)
Group By、Having用法总结
目录
- Group By、Having用法总结
- 一、 GROUP BY 用法
- 二、 HAVING 用法
- 三、 `GROUP BY` 和 `HAVING` 的常见踩雷点
- 3.1 `GROUP BY` 选择的列必须出现在 `SELECT` 中(🤣最重要的一点)
- 3.2 `HAVING` 与 `WHERE` 的区别
- 3.3 `GROUP BY` 可以有多个列
- 3.4 `GROUP BY` 和 `ORDER BY` 的关系
- 3.5 聚合函数的计算顺序
- 3.6 `HAVING` 中的聚合函数和常量比较
- 3.7 避免在 `HAVING` 中做不必要的计算
- 各位看客老爷 万福金安🤣一键三连呀🤣🤣🤣

一、 GROUP BY 用法
GROUP BY 子句用来根据一个或多个列将结果集进行分组,常与聚合函数(如 COUNT(), SUM(), AVG(), MAX(), MIN())一起使用。
SELECT column1, column2, aggregate_function(column3)
FROM table
GROUP BY column1, column2;
SELECT department, AVG(salary)
FROM employees
GROUP BY department;
-- 根据 `department` 列对 `employees` 表进行分组,然后计算每个部门的平均工资。
二、 HAVING 用法
HAVING子句用于过滤GROUP BY生成的分组数据。- 它与
WHERE子句的不同之处在于,WHERE在分组前过滤行,而HAVING是在分组后对结果进行过滤。
SELECT column1, aggregate_function(column2)
FROM table
GROUP BY column1
HAVING aggregate_function(column2) condition;
SELECT department, AVG(salary)
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;
-- 返回平均工资大于 50000 的部门。
三、 GROUP BY 和 HAVING 的常见踩雷点
3.1 GROUP BY 选择的列必须出现在 SELECT 中(🤣最重要的一点)
-
使用
GROUP BY时,SELECT中的非聚合列必须出现在GROUP BY子句中,或者是聚合函数的一部分。 -
不能在 GROUP BY 后直接选择没有参与分组或没有应用聚合函数的字段,否则 SQL 会报错。
-
错误示例:
SELECT department, name, AVG(salary) FROM employees GROUP BY department;name列没有出现在GROUP BY中,也没有被聚合,会引发错误。 -
SQL 不知道如何处理 name,因为它没有被分组(GROUP BY 只会根据 department 分组),也没有被聚合(没有 MAX(name) 或 MIN(name))。
-
可以去掉 name 字段,或者使用聚合函数对它进行处理。
SELECT department, MIN(name), AVG(salary) FROM employees GROUP BY department;
Tips:
-
在分组后,SQL 已经将多个行数据合并为一个分组(代表一组相关的记录)。
-
在这个合并的过程中,SQL 无法直接决定非分组字段应该取什么值,因为每个字段的值在一个分组中可能是不同的。Eg.如果一个部门有多个员工,你无法直接从中选择一个特定的员工姓名,因为在一个分组中,有多个员工姓名。
-
That’s why,SQL 只允许你选择分组字段或通过聚合函数“汇总”一个分组中的多个行。
来两个正确用法巩固一下脑子哈哈:
(不能在 GROUP BY 后的 SELECT 中选择没有聚合的字段,或者没有在 GROUP BY 中出现的字段!!!)
SELECT department, job_title, AVG(salary)
FROM employees
GROUP BY department, job_title;
SELECT department, job_title, MAX(employee_name), AVG(salary)
FROM employees
GROUP BY department, job_title;
3.2 HAVING 与 WHERE 的区别
WHERE用于过滤行数据,而HAVING用于过滤分组数据。- 不能在
HAVING中使用列名,而必须使用聚合函数或已经被分组的列。 - 错误示例:
SELECT department, COUNT(*) FROM employees GROUP BY department HAVING department = 'HR'; -- 错误,因为 department 在 HAVING 中不应该用
3.3 GROUP BY 可以有多个列
- 可以在
GROUP BY中使用多个列,创建更细致的分组。
按照 department 和 job_title 进行多列分组:
SELECT department, job_title, COUNT(*)
FROM employees
GROUP BY department, job_title;
3.4 GROUP BY 和 ORDER BY 的关系
GROUP BY用于分组数据,而ORDER BY用于排序数据。它们的顺序不一样。- 可以在
GROUP BY后面使用ORDER BY来对结果进行排序。
按平均工资降序排序。:
SELECT department, AVG(salary)
FROM employees
GROUP BY department
ORDER BY AVG(salary) DESC;
-- 按平均工资降序排序。
3.5 聚合函数的计算顺序
-
GROUP BY会先分组,然后应用聚合函数。如果需要在聚合函数的结果上进一步过滤数据,应该使用HAVING而不是WHERE。SELECT department, SUM(salary) FROM employees WHERE hire_date > '2020-01-01' -- WHERE 在聚合之前 GROUP BY department;
3.6 HAVING 中的聚合函数和常量比较
-
在
HAVING子句中,通常会看到聚合函数与某个常量进行比较。这样做没有问题,但必须要确保聚合函数的语法正确。SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 10; -- 这个是正确的
3.7 避免在 HAVING 中做不必要的计算
-
不要在
HAVING中做不必要的计算,可能会导致性能下降。如果能在WHERE中提前过滤,就避免使用HAVING。SELECT department, SUM(salary) FROM employees WHERE salary > 50000 -- 提前过滤 GROUP BY department;
各位看客老爷 万福金安🤣一键三连呀🤣🤣🤣
相关文章:
Group By、Having用法总结(常见踩雷点总结—SQL)
Group By、Having用法总结 目录 Group By、Having用法总结一、 GROUP BY 用法二、 HAVING 用法三、 GROUP BY 和 HAVING 的常见踩雷点3.1 GROUP BY 选择的列必须出现在 SELECT 中(🤣最重要的一点)3.2 HAVING 与 WHERE 的区别3.3 GROUP BY 可以…...

Redis持久化机制——针对实习面试
目录 Redis持久化机制Redis为什么要有持久化机制?Redis持久化方式有哪些?AOF持久化工作原理是什么?有什么优缺点?AOF持久化工作原理AOF的优点AOF的缺点 RDB持久化工作原理是什么?有什么优缺点?RDB持久化工作…...

Windows系统服务器怎么设置远程连接?详细步骤
一、什么是Windows远程桌面连接? Windows远程桌面(Remote Desktop)功能使用户能够通过网络连接到另一台Windows计算机,实现远程操作。远程桌面非常适合系统管理员、技术支持人员以及那些需要远程工作的人,它允许用户以图形界面的方式访问远程计算机&…...

【Rust设计模式之建造者模式】
Rust设计模式之建造者模式 什么是建造者模式 什么是建造者模式 即将结构体属性方法与构建解离,使用专门的builder进行建造,说白了就是new和其他的方法分开,集中处理更方便。 直接上代码: #[derive(Debug)] struct children {nam…...
智算大会暨人工智能产业大会即将盛大启幕)
2024中国移动(南京)智算大会暨人工智能产业大会即将盛大启幕
11月9日,2024中国移动(南京)智算大会暨人工智能产业大会将在南京国际博览中心盛大举行。此次盛会将汇聚政界、学界与商界的顶尖力量,共同探讨智能计算与人工智能的未来发展方向,为智能计算与人工智能产业的发展注入新的…...

计算机毕业设计 | SpringBoot咖啡商城 购物采买平台 后台管理软件(附源码)
1,项目背景 1.1 当前的问题和困惑 系统稳定性: 在高并发访问时,商城系统容易出现卡顿、崩溃等问题,影响了用户体验和销售额。支付安全性: 支付环节存在潜在的安全隐患,如何确保支付过程的安全性和用户资金…...

CosyVoice文本转语音:轻松创造个性化音频
CosyVoice文本转语音:轻松创造个性化音频" 要实现一个使用通义语音合成模型CosyVoice将文字转换为音频的图形界面应用,可以使用Python的tkinter库来创建图形用户界面(GUI),并使用requests库来调用CosyVoice的API…...

法语nous sommes
法语短语 “nous sommes” 的词源可以追溯到拉丁语,具体分析如下: 1. “Nous” 的词源: “Nous” 是法语中表示 “我们” 的人称代词,源自拉丁语的 “nos”,它表示 “我们” 的意思。 拉丁语 “nos” 是第一人称复数…...

《化学进展》
《化学进展》主要栏目有:综述,评论,中国化学印记,Mini Accounts等。本刊可供化学及相关学科领域的科研、教学、决策管理人员及研究生阅读。 《化学进展》投稿指南稿件要求 (1)本刊仅接受综述与评论性的…...

CNN和RCNN的关系和区别
RCNN(Region-based Convolutional Neural Network)和 CNN(Convolutional Neural Network)是两种不同的神经网络架构,它们在应用和结构上有所不同。以下是它们之间的主要区别: 1. 基本概念 CNN(…...

Chromium 进程降权和提权模拟示例c++
一、背景知识概念参考微软链接: 强制完整性控制 - Win32 应用程序 |Microsoft 学习 授权) (模拟级别 - Win32 apps | Microsoft Learn DuplicateTokenEx 函数 (securitybaseapi.h) - Win32 apps | Microsoft Learn 本文主要演示 low, medium, high, and system 四…...

【测试语言篇一】Python进阶篇:内置容器数据类型
一、列表 列表(List)是一种有序且可变的容器数据类型。 与集合(Set)不同,列表允许重复的元素。 它方便保存数据序列并对其进行进一步迭代。 列表用方括号创建。 my_list ["banana", "cherry", …...
湘潭大学软件工程专业选修 SOA 期末考试复习(二)
文章目录 回顾序言第一章课后题填空选择简答 第二章课后题填空选择编程 计划第三章课后题填空选择简答编程 第四章课后题填空选择简答编程 第五章课后题填空选择简答编程 第六章课后题说明 第七章课后题填空选择简答编程 第八章课后题填空选择简答编程 第九章课后题填空选择简答…...

改进的正弦余弦算法复现
本文所涉及所有资源均在 传知代码平台 可获取。 目录 一、背景及意义 (一)背包问题背景...

Day13杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 class Solution {public List<List<Integer>> generate(int numRows) {List<List<Integer>> res new Arra…...

【c知道】Hadoop工作原理。
请解释一下Hadoop中MapReduce的工作原理,并说明如何进行MapReduce程序的编写和调试。 Hadoop MapReduce是一种分布式计算模型,它将大规模的数据处理任务分解成一系列小的、独立的任务(Map任务)和后续的聚合任务(Reduce…...
 懒加载)
React.lazy() 懒加载
概要 React.lazy() 是 React 16.6 引入的一个功能,用于实现代码分割(code splitting)。它允许你懒加载组件,即在需要时才加载组件,而不是在应用初始加载时就加载所有组件。这种方法可以显著提高应用的性能,…...
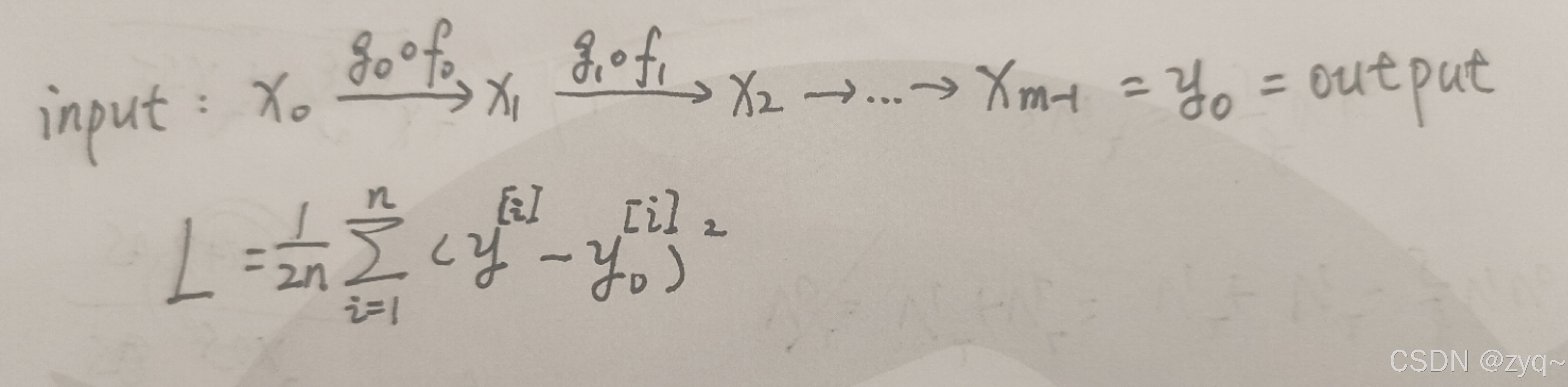
【自学笔记】神经网络(1)
文章目录 介绍模型结构层(Layer)神经元 前向传播反向传播Q1: 为什么要用向量Q2: 不用激活函数会发生什么 介绍 我们已经学习了简单的分类任务和回归任务,也认识了逻辑回归和正则化等技巧,已经可以搭建一个简单的神经网络模型了。 …...

c#————扩展方法
关键点: 定义扩展方法的类和方法必须是静态的: 扩展方法必须在一个静态类中定义。扩展方法本身也必须是静态的。第一个参数使用 this 关键字: 扩展方法的第一个参数指定要扩展的类型,并且在这个参数前加上 this 关键字。这个参数…...
资料汇总)
前向-后向卡尔曼滤波器(Forward-Backward Kalman Filter)资料汇总
《卡尔曼滤波引出的RTS平滑》参考位置2《卡尔曼滤波系列——(六)卡尔曼平滑》《关于卡尔曼滤波和卡尔曼平滑关系的理解》——有m语言例程《Forward Backwards Kalman Filter》——Matlab软件《卡尔曼滤波与隐马尔可夫模型》...

别再只会用OpenCV的equalizeHist了!用Python实战图像增强,让你的目标检测模型精度提升一个台阶
突破OpenCV基础操作:Python图像增强实战与目标检测精度优化 在目标检测项目的实际开发中,我们常常遇到这样的困境:模型在标准测试集上表现优异,一旦部署到真实场景,面对复杂光照、低对比度的图像时,性能却…...
)
Perplexity环境新闻检索失效真相(2024最新API响应延迟根因分析)
更多请点击: https://kaifayun.com 第一章:Perplexity环境新闻搜索 Perplexity 是一款基于大语言模型的实时信息检索工具,其核心优势在于融合权威信源与上下文感知能力,特别适用于需要高时效性与高可信度的新闻类查询场景。在该环…...

终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界
终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 想要个性化修…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...

UniApp跨端开发实战:一套代码给TabBar同时穿上iOS和Material Design的“毛玻璃”外衣
UniApp跨端毛玻璃TabBar实战:融合iOS与Material Design的设计语言 在移动应用开发中,底部导航栏(TabBar)作为核心交互组件,其设计直接影响用户体验。随着iOS毛玻璃(Blur Effect)和Android Mater…...

极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍
极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,面对老师全屏广…...

5分钟掌握Pearcleaner:macOS深度清理的终极免费方案
5分钟掌握Pearcleaner:macOS深度清理的终极免费方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 您是否曾为macOS上卸载应用后残留的配置文件…...

RT-Thread开发者大会技术解析:从RTOS内核到AIoT平台实战指南
1. 项目概述:一场国产嵌入式技术的年度盛会 2021年的RT-Thread开发者大会,对于当时国内嵌入式软件圈的从业者来说,绝对是一个绕不开的关键节点。那一年,整个行业正处在一个微妙的转折期:一方面,芯片供应链…...

Android Studio中文界面完整汉化指南:三步打造母语开发环境
Android Studio中文界面完整汉化指南:三步打造母语开发环境 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为And…...

AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程
AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...