redis笔记-数据结构
zset
zset一方面它是一个 set,保证了内部value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。
zset的底层是由字典和跳表实现。
字典主要用来存储value和score的对应关系。跳表这个数据结构主要用来提供zset按照score排序的功能、指定score范围获取value列表的功能。
struct zset {dict *dict; // all values value=>scorezskiplist *zsl;
}
跳表
跳表数据结构包含的属性:
- header:表示kv head的地址
- maxLevel:最高层级
struct zskiplist {zslnode* header; // 跳跃列表头指针int maxLevel; // 跳跃列表当前的最高层map<string, zslnode*> ht; // hash 结构的所有键值对
}
以下就是跳表的示意图:
每一个kv按照score有序排列的,不同的 kv 层高可能不一样,层数越高的 kv 越少。也就是不同 kv 的level[ ]长度不一样。同一层的 kv 会使用指针串起来。每一个层元素的遍历都是从 kv header 出发。
为什么需要这么设计呢?如果只有一层,也就是一个双链表,所有元素按照score排序,我们如果想要快速定位到某个score,我们就需要从头指针依次遍历,时间复杂度为O(n)。如果我们设计成跳表这个多层结构,效果类似于二分查找,时间复杂度为O(lg(n))。

每一个结点包含的属性如下:
struct zslnode {string value;double score;zslforward*[] level; // 多层连接指针zslnode* backward; // 回溯指针
}
struct zslforward {zslnode* forward;long span; // 跨度
}
查找
如果当前节点的下一个节点包含的值比目标元素值小,则继续向右查找。如果下一个节点的值比目标值大,就转到当前层的下一层去查找。

比如说要查找21,当查找到6这个结点时,6比21小,继续向右查找,因为此时在6结点level[3],level[3]的下一个结点是nil,不符合,那么就转到6的level[2],level[2]的下一个结点是(6->level[2].forward)25,比目标值大,继续转到6的level[1],level[1]的下一个结点是9,9比21小,继续向右查找……
注意: zset 的排序元素不只看 score 值,如果score 值相同还需要再比较 value 值 (字符串比较)。为了防止如果每个元素的score值都相同的话,查找时间复杂度变成O(n)。
插入
当客户端使用 zset add 命令时,redis底层插入元素的过程:

zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) {// 存储搜索路径zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;// 存储经过的节点跨度unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));x = zsl->header;// 逐步降级寻找目标节点,得到「搜索路径」for (i = zsl->level-1; i >= 0; i--) {rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&compareStringObjects(x->level[i].forward->obj,obj) < 0))) {// 累计搜索路径中经过各结点的跨度。也就是最后查询到的元素的rank值。rank[i] += x->level[i].span;x = x->level[i].forward;}update[i] = x;}/**正式进入插入过程**/// 随机一个层数level = zslRandomLevel();if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}// 创建新节点x = zslCreateNode(level,score,obj);// 重排一下前向指针for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}// 重排一下后向指针x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;zsl->length++;return x;
}
- 通过 kv head 这个结点获得最高层的结点地址。
- 逐层降级寻找目标结点,所经过的结点存储在搜索路径update[]数组中。
- 创建一个新结点。
- 为这个结点算一个随机层数,表示这个结点的level[]最大是第几层。
- 遍历update数组,为这个新创建的结点的每层level设置好前后指针。
删除
删除过程和插入过程类似,都需先把这个「搜索路径」找出来。然后对于每个层的相关节点都重排一下前向后向指针就可以了。同时还要注意更新一下最高层数 maxLevel。
更新
当我们调用 zadd 方法时,如果对应的 value 不存在,那就是【插入过程】。
如果这个value 已经存在了,只是调整一下 score 的值,
- 假设这个新的score 值不会带来排序位置上的改变,那么就不需要调整位置,直接修改元素的 score 值就可以了。
- 如果新的score值让排序位置改变了,那就要调整位置。如何调整位置?直接将这个元素删了,然后插入。这一点可以优化,因为如果直接删,然后再插入,需要两次路径搜索,对于改变score值后仍不需要调整位置的情况就可以优化。
字典
dict数据结构可以应用在:
- hash 结构的数据
- 整个 Redis 数据库的所有 key 和 value
- 带过期时间的 key 集合
- zset 集合中存储 value 和 score 值的映射关系
struct RedisDb {dict* dict; // all keys key=>valuedict* expires; // all expired keys key=>long(timestamp)
}
struct zset {dict *dict; // all values value=>scorezskiplist *zsl;
}
dict数据结构包含的属性:
struct dict {...dictht ht[2]; // 两个dictht结构,也就是两个hashtable
}
struct dictht {dictEntry** table; // 二维,第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。long size; // 第一维数组的长度long used; // hash 表中的元素个数...
}
struct dictEntry {void* key;void* val;dictEntry* next; // 链接下一个 entry
}
rehash
rehash条件:
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
哈希表的 LoadFactor > 5 ;
rehash过程:(渐进式rehash)
-
计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
-
设置dict.rehashidx = 0,标示开始rehash
-
将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1](注意,这里不是一次性就将所有entry移到ht[1]中。)
每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]。—渐进式哈希
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存。
-
将rehashidx赋值为-1,代表rehash结束。
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空。
rehash时机:
rehash将ht[0]的数据搬迁到ht[1]是在客户端执行命令中时发生的。也就是渐进性哈希。如果客户端闲下来,redis则通过定时任务对字典进行搬迁。
string
Redis 中的字符串是可以修改的字符串,在内存中它是以字节数组的形式存在的。这个字符串叫「SDS」,也就是 Simple Dynamic String。它的结构是一个带长度信息的字节数组。
SDS
struct SDS<T> {T capacity; // 数组容量T len; // 数组长度byte flags; // 特殊标识位,不理睬它byte[] content; // 数组内容
}

如上图所示,capacity 表示所分配数组的长度,len 表示字符串的实际长度。
embstr vs raw
Redis 的字符串有两种存储方式,在长度特别短时,使用 emb 形式存储 (embeded),当长度超过 44 时,使用 raw 形式存储。
所有redis对象都有下面这个结构头,包括我们现在研究的SDS对象也会有这个对象头。
struct RedisObject {int4 type; // 4bits 不同的对象具有不同的类型int4 encoding; // 4bits 同一个类型的 type 会有不同的存储形式encoding(4bit),int24 lru; // 24bits int32 refcount; // 4bytes 每个对象都有个引用计数,当引用计数为零时,对象就会被销毁,内存被回收。void *ptr; // 8bytes,64-bit system ptr 指针将指向对象内容 (body) 的具体存储位置。
} robj;
这样一个 RedisObject 对象头需要占据 16 字节的存储空间。
我们再看 SDS 结构体的大小:
struct SDS {int8 capacity; // 1byteint8 len; // 1byteint8 flags; // 1bytebyte[] content; // 内联数组,长度为 capacity
}
一个SDS对象头至少是3字节,那么一整个SDS对象至少是3+16=19字节,也就是说分配一个字符串最小空间占用为19字节。

- embstr 存储形式将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配。
- raw 存储形式需要两次malloc,两个对象头在内存地址上一般是不连续的。
内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等等,为了能容纳一个完整的 embstr 对象,**jemalloc 最少会分配 32 字节的空间,如果字符串再稍微长一点,那就是 64 字节的空间。**如果总体超出了 64 字节,Redis 认为它是一个大字符串,不再使用 emdstr 形式存储,而该用 raw 形式。
也就是如果分配的是64字节的空间,那么扣掉SDS对象头和redis对象头,剩下64 - 19 = 45字节给字符串,而字符串是以字节\0 结尾的,因此字符串长度最大为44字节,如果超过44字节,那么用raw形式存储。
oc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等等,为了能容纳一个完整的 embstr 对象,**jemalloc 最少会分配 32 字节的空间,如果字符串再稍微长一点,那就是 64 字节的空间。**如果总体超出了 64 字节,Redis 认为它是一个大字符串,不再使用 emdstr 形式存储,而该用 raw 形式。
也就是如果分配的是64字节的空间,那么扣掉SDS对象头和redis对象头,剩下64 - 19 = 45字节给字符串,而字符串是以字节\0 结尾的,因此字符串长度最大为44字节,如果超过44字节,那么用raw形式存储。
参考
《Redis深度历险:核心原理和应用实践》
https://www.jianshu.com/p/09c3b0835ba6
相关文章:
redis笔记-数据结构
zset zset一方面它是一个 set,保证了内部value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。 zset的底层是由字典和跳表实现。 字典主要用来存储value和score的对应关系。跳表这个数据结构主要用来提…...

webpack的常见配置
Webpack 是一个现代 JavaScript 应用的模块打包工具,用于将项目中的多个文件和依赖打包成浏览器可以识别的文件,通常是一个或多个 JavaScript、CSS 或其他静态资源的 bundle(将多个模块或文件合并成一个或几个文件的过程,这些合并…...

text-embedding-ada-002;BGE模型;M3E模型是Moka Massive Mixed Embedding;BERT
目录 text-embedding-ada-002 一、模型概述 二、模型功能 三、模型特点 四、模型应用 五、模型优势 BGE模型 一、模型背景与特点 二、模型性能与表现 三、模型迭代与发展 M3E模型是Moka Massive Mixed Embedding 一、基本信息 二、技术特点 三、应用场景 四、性能…...
WebRTC 环境搭建
主题 本文主要描述webrtc开发过程中所需的环境搭建 环境: 运行环境:ubuntu 20.04 Node.js环境搭建 安装编译 Node.js 所需的依赖包: sudo apt-get update sudo apt-get install -y build-essential libssl-dev 下载 Node.js 源码: curl -sL htt…...

FastHTML快速入门:http方法,CSS文件和内联样式,其他静态媒体文件位置
HTTP方法 FastHTML通过函数名与HTTP方法进行匹配。到目前为止,我们定义的URL路由都是针对HTTP GET方法的,这是网页最常见的方法。 表单提交通常作为HTTP POST发送。在处理更动态的网页设计时,也就是所谓的单页应用(SPA࿰…...
项目管理和研发管理中的痛点及其解决方案
在现代企业中,研发管理和项目管理面临着多重挑战,包括资源配置不当、沟通不畅、目标不明确、进度控制困难等。这些痛点不仅影响项目的顺利推进,还可能导致企业在市场竞争中处于劣势。尤其是在资源配置不当方面,企业往往难以合理分…...

机器学习(基础1)
数据集 sklearn玩具数据集 数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取 sklearn现实世界数据集 数据量大,数据只能通过网络获取(为国外数据集,下载需要梯子) skle…...

我谈维纳(Wiener)复原滤波器
Rafael Gonzalez的《数字图像处理》中,图像复原这章内容几乎全错。上篇谈了图像去噪,这篇谈图像复原。 图像复原也称为盲解卷积,不处理点扩散函数(光学传递函数)的都不是图像复原。几何校正不属于图像复原,…...

怎么看真假国企啊?怎么识别假冒国企的千层套路?
一、怎么看真假国企啊? 1.使用具有迷惑性的名称:假冒国企往往在名称中使用“中国”、“中”、“国”等字样,或与知名国企名称相似的字号,以增加其可信度。 2.注册资本虚高:为了显示实力,假冒国企可能会在…...

C#中break和continue的区别?
在C#编程语言中,break和continue是两个用于控制循环流程的关键字,但它们的作用和用途有所不同。 break关键字 break关键字用于立即终止它所在的最内层循环或switch语句,并跳出该循环或switch块。程序执行将继续进行循环或switch语句之后的下一…...

Linux部署nginx访问文件403
问题描述:在linux服务器上通过nginx部署,访问文件403 新配置了一个用户来部署服务,将部署文件更新到原有目录下,结果nginx访问403 原因:没有配置文件的读写权限,默认不可读写,nginx无法访问到文…...

华为OD机试 - 数字排列 - 深度优先搜索dfs算法(Python/JS/C/C++ 2024 C卷 200分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...

Scrapy爬取heima论坛所有页面内容并保存到数据库中
前期准备: Scrapy入门_win10安装scrapy-CSDN博客 新建 Scrapy项目 scrapy startproject mySpider03 # 项目名为mySpider03 进入到spiders目录 cd mySpider03/mySpider03/spiders 创建爬虫 scrapy genspider heima bbs.itheima.com # 爬虫名为heima &#…...

Kafka参数了解
Kafka配置参数完整说明 1. 基础配置 参数名说明推荐值参考值broker.idbroker的唯一标识符每个节点唯一的整数1delete.topic.enable是否允许删除topictruetruelistenersbroker监听地址SASL_PLAINTEXT://host:9092SASL_PLAINTEXT://172.24.77.15:9092advertised.listeners对外发…...

sql专题 之 where和join on
文章目录 前言where介绍使用过滤结果集关联两个表 连接外连接内连接自然连接 使用inner join和直接使用where关联两个表的区别总结 前言 从数据库查询数据时,一张表不足以查询到我们想要的数据,更多的时候我们需要联表查询。 联表查询我们一般会使用连接…...

day12:版本控制器
版本控制 使用到的命令: ls -al查看当前目录下的文件及文件夹mkdir新建目录rm -rf递归强制删除文件夹 一、安装配置 1、下载地址 Git 2、初始配置 #用户名 git config --global user.name "自定义用户名" #邮箱(公司的联系方式--追责&…...

第四十一章 Vue之初识VueX
目录 一、引言 1.1. vuex的概念 1.2. vuex使用场景 1.3. 优势 二、创建演示项目 2.1. 构建项目步骤 2.2. 项目最终生成结构 2.3. 创建项目文件 2.3.1. App.vue 2.3.2. Son1.vue 2.3.3. Son2.vue 三、创建一个空仓库 3.1. 安装vuex 3.2. 新建仓库 3.3. 挂载仓库…...
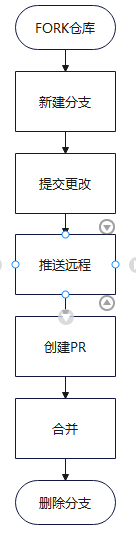
GIT的基本使用与进阶
GIT的简单入门 一.什么是git? Git 是一个开源的分布式版本控制系统,用于跟踪文件更改、管理代码版本以及协作开发。它主要由 Linus Torvalds 于 2005 年创建,最初是为 Linux 内核开发而设计的。如今,Git 已经成为现代软件开发中…...

【Linux系统】—— 基本指令(二)
【Linux系统】—— 基本指令(二) 1 「alias」命令1.1 「ll」命令1.2 「alias」命令 2 「rmdir」指令与「rm」指令2.1 「rmdir」2.2 「rm」2.2.1 「rm」 删除普通文件2.2.2 「rm」 删除目录2.2.3 『 * 』 通配符 3 「man」 指令4 「cp」 指令4.1 拷贝普通…...

MFC工控项目实例三十实现一个简单的流程
启动按钮夹紧 密闭,时间0到平衡 进气,时间1到进气关,时间2到平衡关 检测,时间3到平衡 排气,时间4到夹紧开、密闭开、排气关。 相关代码 void CSEAL_PRESSUREDlg::OnTimer_2(UINT nIDEvent_2) {// if (nIDEvent_21 &am…...

芯片设计中的工程迷信与理性实践:从经验法则到数据驱动
1. 项目概述:从“黑色星期五”迷信到工程设计的理性思考作为一名在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年的工程师,我每天打交道的是精确到纳秒的时序分析、纳米级的物理规则和数以亿计的晶体管布局。在这个世界里&…...

从苹果三星2016年困境看消费电子行业创新与供应链管理
1. 行业巨头的十字路口:苹果与三星的2016年镜像2016年,对于全球消费电子行业而言,是一个充满微妙转折的年份。站在聚光灯下的两大巨头——苹果与三星,仿佛站在了同一面镜子的两侧,映照出截然不同的困境,却又…...

忆阻器神经形态计算与模块化建模技术解析
1. 忆阻器与神经形态计算基础忆阻器(Memristor)作为继电阻、电容、电感之后的第四种基本电路元件,其核心特性在于阻值会"记忆"过往通过的电荷量。这种记忆特性源于器件内部的可逆物理变化,例如离子迁移、氧空位形成或聚…...

2025注安备考资料全套|视频+讲义+前导课,直接拿来就能学
大家好,最近很多备考注册安全工程师的同学都在找系统、完整的备考资料,要么是课程零散不全,要么是讲义和视频不配套,复习起来特别费劲。为了帮大家省去整理资料的时间,我把自己整理的2024-2025注安全套备考资料分享出来…...

眼动追踪技术:DINOv3与合成数据的优化方案
1. 眼动追踪技术概述与挑战眼动追踪技术通过捕捉和分析人眼的注视点位置,能够精确还原用户的视觉注意力分布。这项技术在多个领域展现出重要价值:在VR/AR设备中实现自然交互,在心理学研究中量化视觉认知过程,在用户体验测试中优化…...

深度解析开源工具:八大网盘直链获取实战指南
深度解析开源工具:八大网盘直链获取实战指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

从GAN到领域自适应:揭秘‘特征对齐’如何让AI模型跨域工作
从GAN到领域自适应:特征对齐如何突破AI模型的跨域瓶颈 想象一下,你花费数月训练的视觉识别模型在实验室测试集上准确率高达98%,但部署到真实场景后性能骤降至60%。这种"实验室到现实"的落差,正是领域自适应(Domain Adap…...

深入AMD Ryzen硬件调试:SMUDebugTool技术原理与高级应用指南
深入AMD Ryzen硬件调试:SMUDebugTool技术原理与高级应用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

为什么你的Mac无法写入Windows硬盘?5分钟彻底解决NTFS读写难题
为什么你的Mac无法写入Windows硬盘?5分钟彻底解决NTFS读写难题 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and manag…...

炉石传说HsMod插件终极指南:55项功能完整配置与使用教程
炉石传说HsMod插件终极指南:55项功能完整配置与使用教程 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是基于BepInEx框架开发的炉石传说多功能增强插件,为玩…...