【数据结构】【线性表】一文讲完队列(附C语言源码)
队列
- 队列的基本概念
- 基本术语
- 基本操作
- 队列的顺序实现
- 顺序队列结构体的创建
- 顺序队列的初始化
- 顺序队列入队
- 顺序队列出队
- 顺序队列存在的问题分析
- 循环队列
- 代码汇总
- 队列的链式实现
- 链式队列的创建
- 链式队列初始化-不带头结点
- 链式队列入队-不带头节点
- 链式队列出队-不带头结点
- 带头结点的链式队列各个基本操作源码
队列的基本概念
今天介绍一下线性表的另一个类型,队列。队列和栈类似,都是在操作规则上有一定要求的线性表:
- 栈是一个只允许在一端进行插入或者删除操作的线性表;
- 队列是一个只允许在一端插入,另一端删除的线性表。
和栈不同的是,栈的插入或删除规定在同一端进行,但队列将插入和删除分开在了两端进行。我们可以将其理解成排队打饭,先去排队的人先打到饭,自然也是先离开,因此队列遵循的是先进先出的原则。队列逻辑结构示意图如图:
![![[Pasted image 20241122133855.png]]](https://i-blog.csdnimg.cn/direct/f06d00c96c1e4d3789379a3437ddef2c.png)
基本术语
- 队头:等效于排队的队头,是第一个出去的即删除端;
- 队尾:等效于排队的队尾,是加入队伍的一端即插入端;
- 队头元素:队伍的第一个元素;
- 队尾元素:队伍的最后一个元素;
- 空队列:没有一个元素的队列;
基本操作
- 初始化队列:创建一个空队列Q
- 销毁队列:销毁队列,释放队列Q所占用的空间
- 入队:队列Q没有满的情况下,加入新的元素到队尾
- 出队:队列Q没有空的情况下,删除队头元素
- 读队头元素:队列Q没有空的情况下,获取第一个元素的数据
队列的顺序实现
顺序队列是以类似顺序表的方式实现队列,即队列各个元素的存储空间连续且顺序,其结构体的创建也与顺序表类似。
顺序队列结构体的创建
创建顺序队列有两个主要的点:一个是队列空间的创建;另一个是队列的队头与队尾指针的构建。
![![[顺序队列示意图.png]]](https://i-blog.csdnimg.cn/direct/080506e217ec4b0d87e8a07d81eab0e9.png)
其相关程序如下:
#define MaxSize 10//队列最大长度
typedef struct{ElemType data[MaxSize];//数组存放队列元素int front,rear;//队头指针和队尾指针
}SqQueue;//顺序队列
顺序队列的初始化
初始化主要是清除空间的残余数据,并将front和rear指针分别指向队头和队尾。具体程序如下:
void InitQueue(SqQueue &Q){//初始化队内各个元素数据for(int i=0;i<MaxSize;i++)Q.data[i]=0;Q.front=Q.rear=0;//初始化队头和队尾指针
}
顺序队列入队
入队的逻辑是在队尾插入一个新元素,然后将指针+1即可,示意图:
![![[顺序队列入队示意图.png]]](https://i-blog.csdnimg.cn/direct/9372de45b2224a3b9a725e90ecdf09fe.png)
我们可以看到,这里的rear一般指向空元素内存,具体程序如下:
bool EnQueue(SqQueue &Q,ElemType e){if(队列判满)return false;//队列已满,入队失败Q.datd[Q.rear]=e;//队列未满,元素入队//rear指针加一return true;//入队成功
}
在这里有些同学会有一些疑惑:
- 队列判满为什么没有写
- 入队完队尾指针为什么没有具体代码
这里先不急,后续我们再讨论这个问题
顺序队列出队
出队的逻辑是将队头元素输出,然后指针加一即可,顺序队列出列示意图
![![[顺序队列出列示意图.png]]](https://i-blog.csdnimg.cn/direct/03f676e4a60d42f7859c1d56592bfca4.png)
这里的front指向的都是有元素的空间,具体程序如下:
bool DeQueue(SqQueue &Q,ElemType &e){if(队列判空)return false;//队列以空,出队失败e=Q.datd[Q.front];//队列未空,元素出队//front指针加一return true;//出队成功
}
在这里,我们也出现两个问题:
- 队列判空为什么不写
- 出队完队头指针为什么不写具体代码
接下来我们就来讨论一下上述问题
顺序队列存在的问题分析
在讨论上述顺序队列判空、判满以及指针加一的问题之前,我先抛出一个问题:
- 队列的队头和队尾指针是固定不变的嘛?
答案显示不是,入队队尾指针需要加一,同样的出队队头指针也需要加一。不知道你们发现问题没有,入队和出队的指针增长方向是一致的,对于已经分配好的静态空间来说,那经过一番出队入队的操作,其内存会形成以下现象:
![![[顺序队列指针的增长方向.png]]](https://i-blog.csdnimg.cn/direct/47cb19e03bac4fc396e1dc7fa927af49.png)
如图所示fornt和rear的增长方向一致,那么front之前的内存如何处理呢?如果任期发展下去,可能会出现front和rear都会在队尾,空队列也会成为满队列,front之前的空间变成一次性空间了:
![![[顺序队列的指针窘境.png]]](https://i-blog.csdnimg.cn/direct/cbbd6fd22a4b45b780f05f78ce027cf3.png)
显然这样的队列肯定不是一个好队列,因此我们需要如何解决这个问题,其实有人到这时候会想到顺序表或者排队,前面的每走一个,后面的就向前一步不就可以了嘛。确实也是,顺序表就是这样做的。但这无疑会给队列的基本运算带来更大的工作量。
我们需要一个方法,使其在队头和队尾指针增长方向一致的情况下,也利用到front前面的空间,这样做势必要让front回到前面的空间,将到这里,答案也呼之欲出了,那就是循环!
接下来我们就用循环队列来讲述以下如何判空和判满以及front和rear指针的变化
循环队列
将队列的头尾相接,构成循环队列,如此构建,哪怕队头和队尾指针都向一个方向增长,我们都可以让队列的每一个空间都可以利用到。
循环队列示意图:
![![[循环队列示意图.png]]](https://i-blog.csdnimg.cn/direct/c37052c4c28649b98839f5c8c4f3e58a.png)
解决问题的思路是构建循环队列,但我们还是要落实的具体的东西来,回归我们要解决的两个问题:
- 队列判空和判满
- front和rear指针增长
我们通过循环队列先去解决队列的判空和判满问题
伪满判断法
观察示意图中红色表示有元素,深青色表示无元素,当rear的下一个是front时说明满队列。但这个时候其实也有人发现了,10并没有元素,这也是一个伪满队列。如果我们让10也插入元素,那么就会有rear == front。但在这里我们将rear == front作为判断空栈的条件了,为了做出区分满队列和空队列,我们牺牲一个结点空间让front == rear+1作为判断满栈的条件。
判满条件: - front == rear+1
判空条件: - rear == front
长度判断法
那有没有办法不牺牲空间的情况下去做这件事呢?那么首先我们要搞清楚其特点,从指针上看,循环队列的两个指针在队列空和队列满的时候都是一样的。那么我们应该从其他角度上去做改进,第一个想到的就是顺序表的length,当前表长。显然这个就很合适,但这个需要该队列的结构体:
#define MaxSize 10
typedef struct{ElemType data[MaxSize];int front,rear;int length;
}SqQueue;
判满条件:
- length == MaxSize
判空条件: - length == 0
过程判断法
我们在将视野放长一点,看一下满队列和空队列的具体情况,一个队列要满,肯定是需要通过入队这个操作;而一个队列要空则有两种情况,一个是新创建的队列,一个是通过出队使得队列变空。在了解了这一段动态区别之后,即便满队和空队的front指针和rear指针指向同一位置,也可以辨别其状态。类似的我们也需要改变其结构体用于记录其操作过程。
#define MaxSize 10
typedef struct{ElemType data[MaxSize];int front,rear;int flag;
}SqQueue;
- flag为1时表示操作为入队
- flag为0时表示操作为出队
- 队列初始化时需要将flag置为0;
判满条件: - front == rear && flag == 1
判空条件: - front == rear && flag == 0
上述解决了判空和判满的问题,但我们还有一个问题没解决:front和rear指针的增长问题。以往我们认为无论是出队还是入队操作我们只需要将rear或front加一即可,但一直的+必定在某个时刻指针会超限,即超过MaxSize。我们在引入循环队列之后,指针也需要做出改变,即不能超过MaxSize同时要在增长过程中不断循环。我们可以采用取余的方式实现,每次指针超限通过取余又回到范围:
front指针增长:
front=(front+1)%MaxSize;
rear指针增长:
rear=(rear+1)%MaxSize;
代码汇总
循环队列伪满队列方法:
/*顺序队列结构体创建*/
#define MaxSize 10//队列最大长度
typedef struct{int data[MaxSize];//数组存放队列元素int front,rear;//队头指针和队尾指针
}SqQueue;//顺序队列/*顺序队列初始化*/
void InitQueue(SqQueue &Q){//初始化队内各个元素数据for(int i=0;i<MaxSize;i++)Q.data[i]=0;Q.front=Q.rear=0;//初始化队头和队尾指针
}/*顺序队列入队*/
bool EnQueue(SqQueue &Q,int e){if(front==rear)//队列判满return false;//队列已满,入队失败Q.datd[Q.rear]=e;//队列未满,元素入队rear=(rear+1)%MaxSize;//rear指针加一return true;//入队成功
}/*顺序队列出队*/
bool DeQueue(SqQueue &Q,int &e){if(front==rear)//队列判空return false;//队列以空,出队失败e=Q.datd[Q.front];//队列未空,元素出队front=(front+1)%MaxSize;//front指针加一return true;//出队成功
}
循环队列队列长度方法:
/*顺序队列结构体创建*/
#define MaxSize 10//队列最大长度
typedef struct{int data[MaxSize];//数组存放队列元素int front,rear;//队头指针和队尾指针int length;
}SqQueue;//顺序队列/*顺序队列初始化*/
void InitQueue(SqQueue &Q){//初始化队内各个元素数据for(int i=0;i<MaxSize;i++)Q.data[i]=0;Q.front=Q.rear=0;//初始化队头和队尾指针Q.length=0;//初始化队列长度
}/*顺序队列入队*/
bool EnQueue(SqQueue &Q,int e){if(Q.length==MaxSize)//队列判满return false;//队列已满,入队失败Q.datd[Q.rear]=e;//队列未满,元素入队rear=(rear+1)%MaxSize;//rear指针加一Q.length=Q.length+1;//队列长度加一return true;//入队成功
}/*顺序队列出队*/
bool DeQueue(SqQueue &Q,int &e){if(Q.length==0)//队列判空return false;//队列以空,出队失败e=Q.datd[Q.front];//队列未空,元素出队front=(front+1)%MaxSize;//front指针加一Q.length=Q.length-1;return true;//出队成功
}
循环队列操作过程法:
/*顺序队列结构体创建*/
#define MaxSize 10//队列最大长度
typedef struct{int data[MaxSize];//数组存放队列元素int front,rear;//队头指针和队尾指针int flag;
}SqQueue;//顺序队列/*顺序队列初始化*/
void InitQueue(SqQueue &Q){//初始化队内各个元素数据for(int i=0;i<MaxSize;i++)Q.data[i]=0;Q.front=Q.rear=0;//初始化队头和队尾指针Q.flag=0;//初始化队列长度
}/*顺序队列入队*/
bool EnQueue(SqQueue &Q,int e){if(front==rear && Q.flag==1 )//队列判满return false;//队列已满,入队失败Q.datd[Q.rear]=e;//队列未满,元素入队rear=(rear+1)%MaxSize;//rear指针加一Q.flag=1;//队列长度加一return true;//入队成功
}/*顺序队列出队*/
bool DeQueue(SqQueue &Q,int &e){if(front==rear && Q.flag==0)//队列判空return false;//队列以空,出队失败e=Q.datd[Q.front];//队列未空,元素出队front=(front+1)%MaxSize;//front指针加一Q.flag=0;return true;//出队成功
}
队列的链式实现
类似的,队列可以仿照顺序表的物理结构存储方式实现顺序队列,我们也可以仿照链表的存储方式实现链式队列.同样的,链式队列也有带头结点和不带头结点的区分
![![[链式队列.png]]](https://i-blog.csdnimg.cn/direct/5c7b139c9cac42bab75acc9511d4cca2.png)
和链式栈类似,因为队列是对两端操作,带不带头结点其实差别不大,接下来我们先以不带头结点为例子进行讲解
链式队列的创建
队列对于元素本身只需要存储数据和next指针,但对于整个队列,非常重要的是队列的队头和队尾指针,因此在这里我们需要创建两个结构体,一个是元素结点的结构体,记录元素的数据和next指针,另一个是队列的结构体,记录队列的队头指针和队尾指针。
/*队列结点结构体*/
typedef struct LinkNode{ElemType datd;struct LinkNode *next;
}LinkNode;/*队列结构体*/
typedef struct {LinkNode *front,rear;
}LinkQueue;
链式队列初始化-不带头结点
因为没有头结点,同时初始化时的队列不存在元素,因此链式队列的front和rear指针总是指向NULL
bool InitQueue(LinkQueue &Q){Q.front=NULL;Q.rear=NULL;
}
链式队列入队-不带头节点
链式队列的入队主要就是指针的改变,唯一需要注意的是因为没有头结点的存在,第一个元素入队时和其他元素入队会有一点不一样:
void EnQueue(LinkQueue &Q,ElemType e){LinkNode *s=(LinkNode*)malloc(sizeof(LinkNode));//创建插入结点空间s->dada=e;//结点数据s->next=NULL;//新结点next为空//第一个元素入队需要特殊处理,头尾指针均指向第一个结点if(Q.front==NULL){Q.front=s;Q.rear=s;}else{Q.rear->next=s;//原来的尾结点指向新结点Q.rear=s;//更新队尾指针指向新结点}
}
在这里我们没有判断队满,因为链式队列的空间是动态的,除非内存空间不足,这是几乎不可能出现的。
链式队列出队-不带头结点
链式队列出队主要是修改front指针和释放结点空间,需要注意的是最后一个结点出队时的不同
bool DeQueue(LinkQueue &Q,ElemType &e){if(Q.front==NULL)//判空return false;//空队列,出队失败LinkNode *s=Q.front;//暂存出队结点e=s->data;//返回出队元素数据Q.front=s->next;//更新队头指针//最后一个结点出队特殊处理if(Q.rear==s){Q.front=NULL;Q.rear=NULL;}free(s);//释放空间return true;//出队成功
}
通过上述的基本操作我们可以看出来,没有头结点的链式队列在空间上可以节省一个结点的内存,但在出队入队的操作上,需要对第一个结点特殊处理,如果是有头结点则不需要.
带头结点的链式队列各个基本操作源码
/*队列结点结构体*/
typedef struct LinkNode{ElemType datd;struct LinkNode *next;
}LinkNode;/*队列结构体*/
typedef struct {LinkNode *front,rear;
}LinkQueue;/*有头结点链式队列初始化*/
bool InitQueue(LinkQueue &Q){//头 尾指针都指向头结点Q.front=Q.rear=(LinkNode*)malloc(sizeof(LinkNode));//创建头结点并初始化头尾指针Q.front->next=NULL;//初始化头结点的next指向空
}/*有头结点链式队列入队*/
void EnQueue(LinkQueue &Q,ElemType e){LinkNode *s=(LinkNode*)malloc(sizeof(LinkNode));//创建插入结点空间s->dada=e;//结点数据s->next=NULL;//新结点next为空Q.rear->next=s;//原来的尾结点指向新结点Q.rear=s;//更新队尾指针指向新结点
}/*有头结点链式队列出队*/
bool DeQueue(LinkQueue &Q,ElemType &e){if(Q.front==NULL)//判空return false;//空队列,出队失败LinkNode *s=Q.front;//暂存出队结点e=s->data;//返回出队元素数据Q.front->next=s->next;//更新头结点指针//最后一个结点出队特殊处理if(Q.rear==s)Q.rear=Q.front;free(s);//释放空间return true;//出队成功
}
相关文章:
【数据结构】【线性表】一文讲完队列(附C语言源码)
队列 队列的基本概念基本术语基本操作 队列的顺序实现顺序队列结构体的创建顺序队列的初始化顺序队列入队顺序队列出队顺序队列存在的问题分析循环队列代码汇总 队列的链式实现链式队列的创建链式队列初始化-不带头结点链式队列入队-不带头节点链式队列出队-不带头结点带头结点…...

2024年11月最新 Alfred 5 Powerpack (MACOS)下载
在现代数字化办公中,我们常常被繁杂的任务所包围,而时间的高效利用成为一项核心需求。Alfred 5 Powerpack 是一款专为 macOS 用户打造的高效工作流工具,以其强大的定制化功能和流畅的用户体验,成为众多效率爱好者的首选。 点击链…...

ODBC连接PostgreSQL数据库后,网卡DOWN后,客户端进程阻塞问题解决方法
问题现象:数据库客户端进程数据库连接成功后,再把跟数据库交互的网卡down掉,客户端进程就会阻塞,无法进行其他处理。该问题跟TCP keepalive机制有关。 可以在odbc.ini文件中增加相应的属性来解决,在odbc.ini 增加如下…...
_vscode commit很慢解决方法)
VsCode使用git提交很慢(一直显示在提交)_vscode commit很慢解决方法
VsCode使用git提交很慢(一直显示在提交)_vscode commit很慢...

linux从0到1——shell编程9
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

计算机网络技术专业,热门就业方向和就业前景
前言 在数字化飞速发展的今天,计算机网络技术专业成为了众多学子和职场人士关注的焦点。这一专业不仅涵盖了计算机硬件、软件和网络通信等多个领域的知识,更在就业市场上展现出强大的竞争力。本文将带您一探计算机网络技术专业的就业方向和就业前景&…...

C++中定义类型名的方法
什么是 C 中的类型别名和 using 声明? 类型别名与using都是为了提高代码的可读性。 有两种方法可以定义类型别名 一种是使用关键字typedef起别名使用别名声明来定义类型的别名,即使用using. typedef 关键字typedef作为声明语句中的基本数据类型的一…...

从零开始学习 sg200x 多核开发之 camera-sensor 添加与测试
sg2002 集成了 H.264 视频压缩编解码器, H.265 视频压缩编码器和 ISP;支持 HDR 宽动态、3D 降噪、除雾、镜头畸变校正等多种图像增强和矫正算法。 sophpi 中没有提供相关图像 sensor。本次实验是在 milkv-duo256m 上添加 GC2083。 GC2083 格科微的 GC2083 是一款…...

前端三剑客(二):CSS
目录 1. CSS 基础 1.1 什么是 CSS 1.2 语法格式 1.3 引入方式 1.3.1 行内样式 1.3.2 内部样式 1.3.3 外部样式 1.4 CSS 编码规范 2. 选择器 2.1 标签选择器 2.2 id 选择器 2.3 class 选择器(类选择器) 2.4 复合选择器 2.5 通配符选择器 3. 常用 CSS 样式 3.1 c…...

国土变更调查拓扑错误自动化修复工具的研究
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、拓扑错误的形成原因 1.边界不一致 2.不规则图形 3.尖锐角 4.局部狭长 5.细小碎面 6.更新层相互重叠 二、修复成果展示 1.边界不一致 2.不规则图形 3.尖锐角 4.局部狭…...

深度学习图像视觉 RKNN Toolkit2 部署 RK3588S边缘端 过程全记录
深度学习图像视觉 RKNN Toolkit2 部署 RK3588S边缘端 过程全记录 认识RKNN Toolkit2 工程文件学习路线: Anaconda Miniconda安装.condarc 文件配置镜像源自定义conda虚拟环境路径创建Conda虚拟环境 本地训练环境本地转换环境安装 RKNN-Toolkit2:添加 lin…...
)
Linux应用编程(C语言编译过程)
目录 1. 举例 2.预处理 2.1 预处理命令 2.2 .i文件内容解读 3.编译 4.汇编 5.链接 5.1 链接方式 5.1.1 静态链接 5.1.2 动态链接 5.1.3 混合链接 1. 举例 Linux的C语言开发,一般选择GCC工具链进行编译,通过下面的例子来演示GCC如何使用&#…...

ssm实战项目──哈米音乐(二)
目录 1、流派搜索与分页 2、流派的添加 3、流派的修改 4、流派的删除 接上篇:ssm实战项目──哈米音乐(一),我们完成了项目的整体搭建,接下来进行后台模块的开发。 首先是流派模块: 在该模块中采用分…...

Python 获取微博用户信息及作品(完整版)
在当今的社交媒体时代,微博作为一个热门的社交平台,蕴含着海量的用户信息和丰富多样的内容。今天,我将带大家深入了解一段 Python 代码,它能够帮助我们获取微博用户的基本信息以及下载其微博中的相关素材,比如图片等。…...
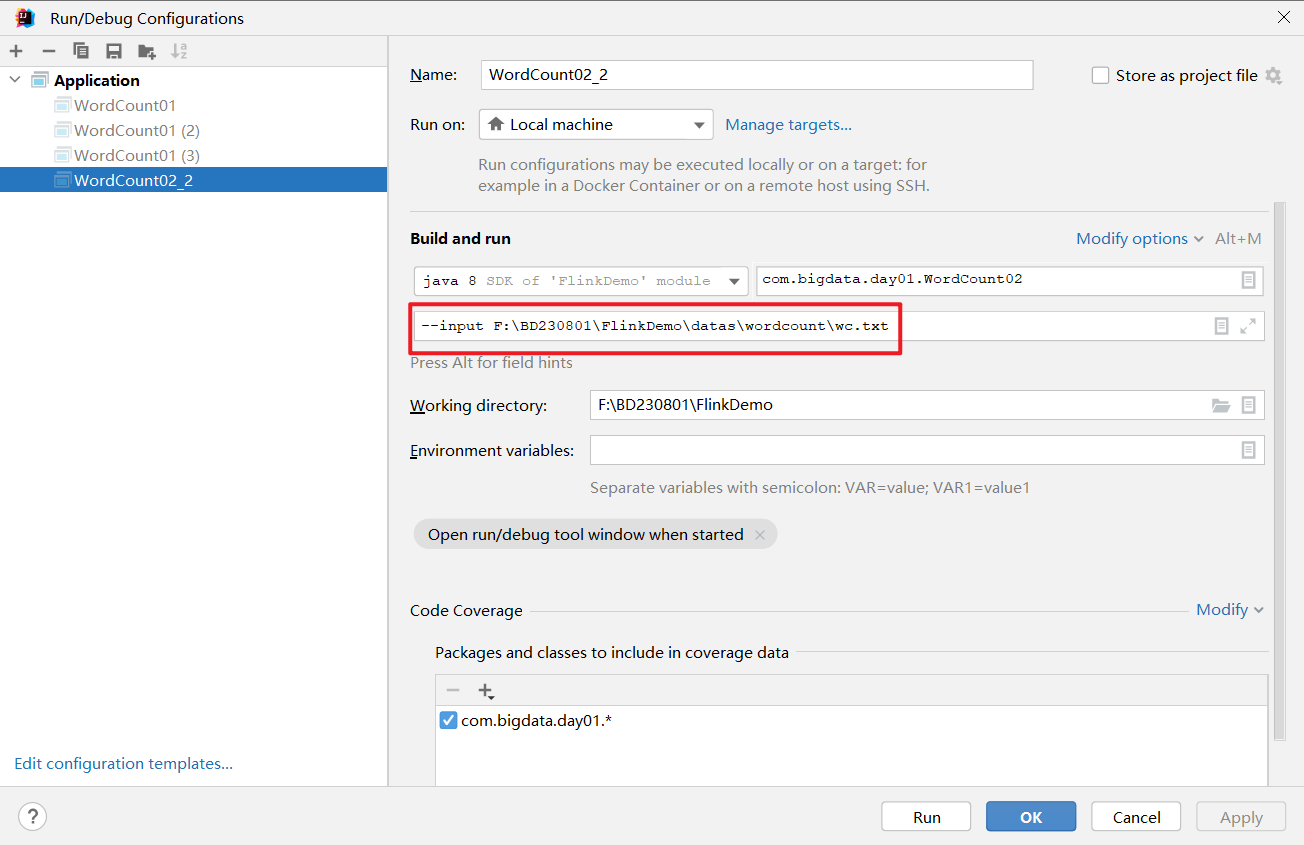
Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下: 1. env-准备环境 2. source-加载数据 3. transformation-数据处理转换 4. sink-数据输出 5. execute-执行 DataStream API开发 //n…...
是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM)
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,也称为拉格朗日乘数法。 例如之前博文写的2月7日 SVM&线性回归&逻辑回归在支持向量机(SVM)中,为了…...

鸿蒙征文|鸿蒙心路旅程:始于杭研所集训营,升华于横店
始于杭研所 在2024年7月,我踏上了一段全新的旅程,前往风景如画的杭州,参加华为杭研所举办的鲲鹏&昇腾集训营。这是一个专门为开发者设计的培训项目,中途深入学习HarmonyOS相关技术。对于我这样一个对技术充满热情的学生来说&…...

c语言数据结构与算法--简单实现线性表(顺序表+链表)的插入与删除
老规矩,点赞评论收藏关注!!! 目录 线性表 其特点是: 算法实现: 运行结果展示 链表 插入元素: 删除元素: 算法实现 运行结果 线性表是由n个数据元素组成的有限序列ÿ…...
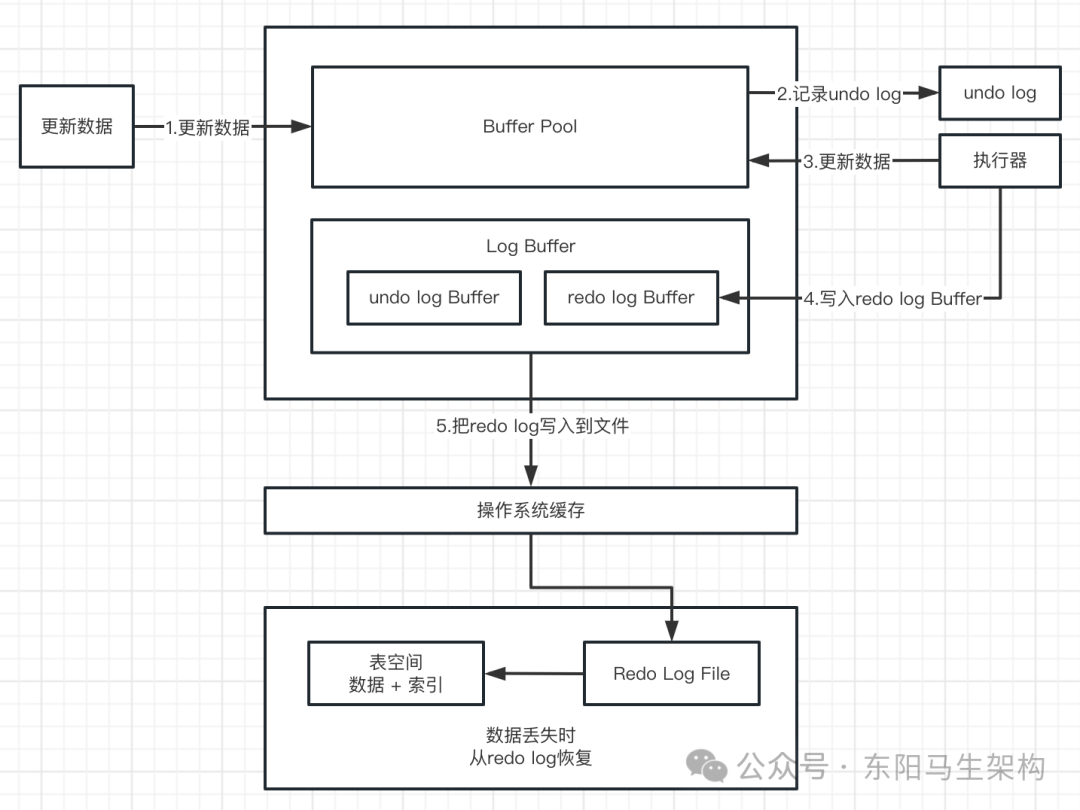
MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...
计算两个日期天数之差)
MySQL:DATEDIFF()计算两个日期天数之差
题目需求: 计算出比前一天温度要高的日期。 select a.id from weather a, weather b where a.temperature > b.temperature and datediff(a.recordDate, b.recordDate) 1; DATEDIFF(date1, date2)函数用于计算两个日期之间的天数差。函数返回date1和date2之…...

StructBERT文本相似度模型在互联网内容治理中的应用:重复与低质内容识别
StructBERT文本相似度模型在互联网内容治理中的应用:重复与低质内容识别 你有没有遇到过这样的情况?打开一个内容平台,满屏都是大同小异的文章,或者点开几篇帖子,发现内容似曾相识,只是换了几个词。对于平…...
:PEI转染效率优化指南【曼博生物】)
细胞转染优化方向(一):PEI转染效率优化指南【曼博生物】
摘要:PEI转染是AAV、慢病毒及重组蛋白生产中的常用方法。本文从培养基、细胞状态、密度及质粒质量等关键因素出发,系统总结影响PEI转染效率的核心参数及优化思路。 关键词:PEI转染、AAV生产、细胞转染优化、细胞密度、培养基选择、质粒质量一…...

10倍加速PDF转HTML:pdf2htmlEX终极优化指南
10倍加速PDF转HTML:pdf2htmlEX终极优化指南 【免费下载链接】pdf2htmlEX Convert PDF to HTML without losing text or format. 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2htmlEX pdf2htmlEX是一款能够将PDF文件转换为HTML格式的强大工具,…...

Kronos创新应用实战指南:从技术原理到跨行业落地
Kronos创新应用实战指南:从技术原理到跨行业落地 【免费下载链接】Kronos Kronos: A Foundation Model for the Language of Financial Markets 项目地址: https://gitcode.com/GitHub_Trending/kronos14/Kronos Kronos作为金融市场的"语言模型"&a…...

CCMusic跨平台部署指南:Windows/Linux/macOS全适配
CCMusic跨平台部署指南:Windows/Linux/macOS全适配 音乐风格识别从未如此简单——无论你用哪种电脑系统 1. 开篇:为什么需要跨平台部署方案 还在为音乐风格分类工具的安装头疼吗?不同的操作系统、不同的环境配置、复杂的依赖关系...这些麻烦…...

YOLO12快速部署教程:无需配置,一键启动Web检测界面
YOLO12快速部署教程:无需配置,一键启动Web检测界面 1. 引言 目标检测技术作为计算机视觉领域的核心任务之一,在安防监控、自动驾驶、工业质检等领域有着广泛应用。YOLO系列模型因其出色的实时性能一直备受关注,而最新发布的YOLO…...

终极指南:3步在3DS上原生运行GBA游戏,告别模拟器延迟!
终极指南:3步在3DS上原生运行GBA游戏,告别模拟器延迟! 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirror…...

Qwen3Guard-Gen-8B真实案例:如何用AI模型自动拦截不当言论
Qwen3Guard-Gen-8B真实案例:如何用AI模型自动拦截不当言论 1. 引言:内容安全的新挑战 在数字内容爆炸式增长的今天,各类平台都面临着内容审核的巨大压力。传统的关键词过滤和规则匹配系统已经难以应对日益复杂的网络环境,特别是…...

Phi-3-vision-128k-instruct创意编程:用JavaScript构建交互式图像故事生成器
Phi-3-vision-128k-instruct创意编程:用JavaScript构建交互式图像故事生成器 1. 引言:当AI创意遇上前端交互 想象这样一个场景:用户上传一张随手拍的照片,通过简单的滑块调整和风格选择,几秒钟后就能获得一个与图片内…...

Navicat重置工具:Mac版Navicat无限试用终极指南
Navicat重置工具:Mac版Navicat无限试用终极指南 【免费下载链接】navicat_reset_mac navicat16 mac版无限重置试用期脚本 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你是否正在为Navicat Premium的14天试用期到期而烦恼?作…...