BeautifulSoup 与 XPath 用法详解与对比
BeautifulSoup(bs4) 和 XPath 是学习python爬虫过程中常常用到的库,本文将详细介绍它们的功能、使用方法、优缺点以及实际应用中的区别和选择建议。
1. BeautifulSoup 用法详解
1.1 什么是 BeautifulSoup?
BeautifulSoup 是 Python 中用于解析 HTML 和 XML 的库。它提供了简单易用的接口,可以高效地提取网页中的标签、内容以及属性。常配合 requests 库使用,用于静态网页的数据爬取。
安装
pip install beautifulsoup4 lxml
加载 HTML 文档
from bs4 import BeautifulSoup
import requestsurl = "https://example.com"
response = requests.get(url)
page_text = response.text# 使用 lxml 解析器加载 HTML
soup = BeautifulSoup(page_text, 'lxml')
1.2 定位元素
BeautifulSoup 提供多种方式来定位 HTML 文档中的元素。
1.2.1 标签定位
根据标签名和属性查找元素:
# 找到第一个符合条件的 div 标签
tag = soup.find('div', class_='example')# 找到所有符合条件的 div 标签
tags = soup.find_all('div', class_='example')# 查找特定属性的标签
tag = soup.find('meta', attrs={'name': 'description'})
1.2.2 CSS 选择器定位
通过 CSS 选择器查找元素:
# 根据 ID 定位
tag = soup.select('#header')# 根据类名定位
tags = soup.select('.menu-item')# 层级关系
tags = soup.select('div > p') # 直接子元素
tags = soup.select('div p') # 所有子孙元素
1.3 提取内容与属性
提取标签中的文本内容或属性值:
-
提取文本内容:
tag.string:提取当前标签的直系文本。tag.text:提取当前标签及其子标签的所有文本。
-
提取属性值:
- 使用
tag['属性名']获取属性值。
- 使用
tag = soup.find('img', class_='image')
# 提取文本
text = tag.text
# 提取图片链接
src = tag['src']
2. XPath 用法详解
2.1 什么是 XPath?
XPath 是一种基于路径的语言,用于在 HTML 和 XML 中定位节点或提取数据。它更适合复杂的结构化页面,能够高效处理多条件的筛选和属性提取。
安装
XPath 通常通过 lxml 实现:
pip install lxml
加载 HTML 文档
from lxml import etree
import requestsurl = "https://example.com"
response = requests.get(url)
page_text = response.text# 使用 lxml 构建 HTML 树
tree = etree.HTML(page_text)
2.2 定位元素
XPath 提供基于路径的定位方式,支持多种表达式。
2.2.1 标签定位
使用标签名称定位:
# 定位 class 为 'example' 的 div 标签
tag = tree.xpath('//div[@class="example"]')# 定位第一个 p 标签
tag = tree.xpath('//p[1]')
2.2.2 层级关系
//:匹配所有子孙节点。/:匹配直接子节点。
# 定位 ul 标签下的所有 li 标签
tags = tree.xpath('//ul/li')# 定位第一个 ul 标签下的第2个 li 元素
tag = tree.xpath('//ul[1]/li[2]')
2.2.3 多条件组合
通过逻辑运算符组合条件:
# 定位 class 为 'item' 且包含子标签 a 的 div
tags = tree.xpath('//div[@class="item" and .//a]')
2.3 提取内容与属性
提取节点中的文本内容或属性值:
-
提取文本内容:
/text():获取直系文本。//text():获取所有文本(包括子节点)。
-
提取属性值:
/@属性名:获取属性值。
# 提取 h1 标签中的文本
title = tree.xpath('//h1/text()')# 提取 img 标签中的 src 属性
images = tree.xpath('//img/@src')
3. BeautifulSoup 与 XPath 的对比
| 功能 | BeautifulSoup | XPath |
|---|---|---|
| 定位方式 | 标签名、类名、CSS 选择器 | 路径表达式 |
| 复杂定位 | 支持层级选择,但多条件较繁琐 | 支持复杂路径、条件组合 |
| 速度 | 适合中小规模数据提取 | 速度更快,适合大规模数据处理 |
| 学习曲线 | 简单直观,适合初学者 | 需掌握路径表达式 |
| 灵活性 | 灵活但较依赖 HTML 结构 | 更强大,适合多样化需求 |
4. 实际应用场景
4.1 BeautifulSoup 的适用场景
- 页面结构简单,数据提取需求不复杂。
- 初学者快速实现爬取任务。
- 配合 Selenium 处理动态页面。
4.2 XPath 的适用场景
- 数据结构复杂,需求多样化。
- 需要高效处理大量数据。
- 更适合嵌套结构的深层次提取。
5. 综合选择建议
-
BeautifulSoup:
- 优先适用于结构简单的静态页面。
- 学习成本低,适合快速开发。
-
XPath:
- 更适合复杂、嵌套结构的网页。
- 在大规模数据处理中的效率较高。
-
结合使用:
- 可以先用 XPath 定位大范围节点,再用 BeautifulSoup 提取具体内容。
6. 示例代码:两者结合使用
以下是使用 BeautifulSoup 和 XPath 的综合示例:
from bs4 import BeautifulSoup
from lxml import etree
import requestsurl = "https://example.com"
response = requests.get(url)
page_text = response.text# 使用 XPath 定位大范围节点
tree = etree.HTML(page_text)
items = tree.xpath('//div[@class="item"]')# 使用 BeautifulSoup 细化提取内容
for item in items:soup_item = BeautifulSoup(etree.tostring(item), 'lxml')title = soup_item.select_one('h2').textlink = soup_item.select_one('a')['href']print(title, link)
以上内容完整介绍了 BeautifulSoup 和 XPath 的用法及对比,希望对你的爬虫开发有帮助!
相关文章:

BeautifulSoup 与 XPath 用法详解与对比
BeautifulSoup(bs4) 和 XPath 是学习python爬虫过程中常常用到的库,本文将详细介绍它们的功能、使用方法、优缺点以及实际应用中的区别和选择建议。 1. BeautifulSoup 用法详解 1.1 什么是 BeautifulSoup? BeautifulSoup 是 Pyt…...
——elisp 数字类型)
Emacs 折腾日记(五)——elisp 数字类型
本文是参考 emacs lisp 简明教程 写的,很多东西都是照搬里面的内容,如果各位读者觉得本文没有这篇教程优秀或者有抄袭嫌疑、又或者觉得我更新比较慢、再或者其他什么原因,请直接阅读上述链接中的教程。 上一篇我们讲了elisp中的流程控制结构相…...

重拾设计模式--外观模式
文章目录 外观模式(Facade Pattern)概述定义 外观模式UML图作用 外观模式的结构C 代码示例1C代码示例2总结 外观模式(Facade Pattern)概述 定义 外观模式是一种结构型设计模式,它为子系统中的一组接口提供了一个统一…...

源码编译llama.cpp for android
源码编译llama.cpp for android 我这有已经编译好的版本,直接下载使用: https://github.com/turingevo/llama.cpp-build/releases/tag/b4331 准备 android-ndk 已下载: /media/wmx/ws1/software/qtAndroid/Sdk/ndk/23.1.7779620版本 &am…...

StarRocks 排查单副本表
文章目录 StarRocks 排查单副本表方式1 查询元数据,检查分区级的副本数方式2 SHOW PARTITIONS命令查看 ReplicationNum修改副本数命令 StarRocks 排查单副本表 方式1 查询元数据,检查分区级的副本数 # 方式一 查询元数据,检查分区级的副本数…...

Windows11 家庭版安装配置 Docker
1. 安装WSL WSL 是什么: WSL 是一个在 Windows 上运行 Linux 环境的轻量级工具,它可以让用户在 Windows 系统中运行 Linux 工具和应用程序。Docker 为什么需要 WSL: Docker 依赖 Linux 内核功能,WSL 2 提供了一个高性能、轻量级的…...

线程知识总结(二)
本篇文章以线程同步的相关内容为主。线程的同步机制主要用来解决线程安全问题,主要方式有同步代码块、同步方法等。首先来了解何为线程安全问题。 1、线程安全问题 卖票示例,4 个窗口卖 100 张票: class Ticket implements Runnable {priv…...

解决vscode ssh远程连接服务器一直卡在下载 vscode server问题
目录 方法1:使用科学上网 方法2:手动下载 方法3 在使用vscode使用ssh远程连接服务器时,一直卡在下载"vscode 服务器"阶段,但MobaXterm可以正常连接服务器,大概率是网络问题,解决方法如下: 方…...

【Cadence射频仿真学习笔记】IC设计中电感的分析、建模与绘制(EMX电磁仿真,RFIC-GPT生成无源器件及与cadence的交互)
一、理论讲解 1. 电感设计的两个角度 电感的设计可以从两个角度考虑,一个是外部特性,一个是内部特性。外部特性就是把电感视为一个黑盒子,带有两个端子,如果带有抽头的电感就有三个端子,需要去考虑其电感值、Q值和自…...

Definition of Done
Definition of Done English Version The team agrees on, a checklist of criteria which must be met before a product increment “often a user story” is considered “done”. Failure to meet these criteria at the end of a sprint normally implies that the work …...

【漏洞复现】CVE-2023-37461 Arbitrary File Writing
漏洞信息 NVD - cve-2023-37461 Metersphere is an opensource testing framework. Files uploaded to Metersphere may define a belongType value with a relative path like ../../../../ which may cause metersphere to attempt to overwrite an existing file in the d…...

简单工厂模式和策略模式的异同
文章目录 简单工厂模式和策略模式的异同相同点:不同点:目的:结构: C 代码示例简单工厂模式示例(以创建图形对象为例)策略模式示例(以计算价格折扣策略为例)UML区别 简单工厂模式和策…...

HuggingFace datasets - 下载数据
文章目录 下载数据修改默认保存地址 TRANSFORMERS_CACHE保存到本地 & 本地加载保存加载 读取 .arrow 数据 下载数据 1、Python 代码下载 from datasets import load_dataset imdb load_dataset("imdb") # name参数为full或mini,full表示下载全部数…...
和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语)
梯度(Gradient)和 雅各比矩阵(Jacobian Matrix)的区别和联系:中英双语
雅各比矩阵与梯度:区别与联系 在数学与机器学习中,梯度(Gradient) 和 雅各比矩阵(Jacobian Matrix) 是两个核心概念。虽然它们都描述了函数的变化率,但应用场景和具体形式有所不同。本文将通过…...

Vscode搭建C语言多文件开发环境
一、文章内容简介 本文介绍了 “Vscode搭建C语言多文件开发环境”需要用到的软件,以及vscode必备插件,最后多文件编译时tasks.json文件和launch.json文件的配置。即目录顺序。由于内容较多,建议大家在阅读时使用电脑阅读,按照目录…...

自定义 C++ 编译器的调用与管理
在 C 项目中,常常需要自动化地管理编译流程,例如使用 MinGW 或 Visual Studio 编译器进行代码的编译和链接。为了方便管理不同编译器和简化编译流程,我们开发了一个 CompilerManager 类,用于抽象编译器的查找、命令生成以及执行。…...
时间管理系统|Java|SSM|JSP|
【技术栈】 1⃣️:架构: B/S、MVC 2⃣️:系统环境:Windowsh/Mac 3⃣️:开发环境:IDEA、JDK1.8、Maven、Mysql5.7 4⃣️:技术栈:Java、Mysql、SSM、Mybatis-Plus、JSP、jquery,html 5⃣️数据库可…...

用SparkSQL和PySpark完成按时间字段顺序将字符串字段中的值组合在一起分组显示
用SparkSQL和PySpark完成以下数据转换。 源数据: userid,page_name,visit_time 1,A,2021-2-1 2,B,2024-1-1 1,C,2020-5-4 2,D,2028-9-1 目的数据: user_id,page_name_path 1,C->A 2,B->D PySpark: from pyspark.sql import SparkSes…...
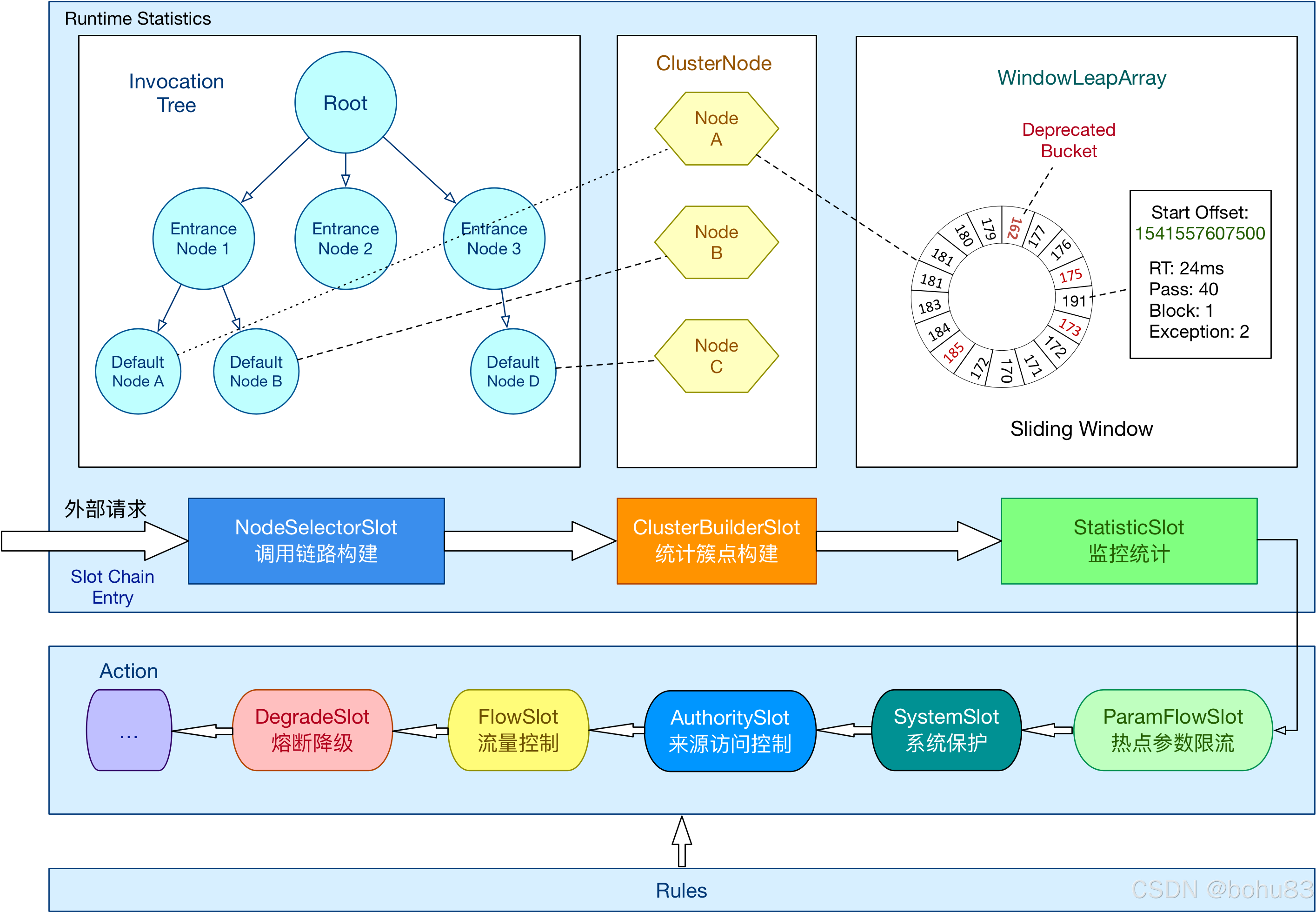
Sentinel 学习笔记3-责任链与工作流程
本文属于sentinel学习笔记系列。网上看到吴就业老师的专栏,原文地址如下: https://blog.csdn.net/baidu_28523317/category_10400605.html 上一篇梳理了概念与核心类:Sentinel 学习笔记2- 概念与核心类介绍-CSDN博客 补一个点:…...

Latex 转换为 Word(使用GrindEQ )(英文转中文,毕业论文)
效果预览 第一步: 告诉chatgpt: 将latex格式中的英文翻译为中文(符号和公式不要动),给出latex格式第二步: Latex 转换为 Word(使用GrindEQ ) 视频 https://www.bilibili.com/video/BV1f242…...

Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具
Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug 还在为…...
)
ElevenLabs湖北话语音合成:从零部署到商用级TTS的7大避坑步骤(附武汉/宜昌/襄阳三方言测试数据)
更多请点击: https://kaifayun.com 第一章:ElevenLabs湖北话语音合成的技术定位与方言价值 ElevenLabs 作为全球领先的AI语音生成平台,其核心能力聚焦于高保真、情感化、多语言的文本到语音(TTS)合成。尽管官方尚未正…...

MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案
MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案 【免费下载链接】Awesome-MCP-ZH MCP 资源精选, MCP指南,Claude MCP,MCP Servers, MCP Clients 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-MCP-ZH MC…...

在Taotoken模型广场根据任务需求与预算快速选型实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求与预算快速选型实践 面对众多大模型,如何为自己的项目选择一个既满足需求又符合预算的…...

课堂教室学生行为识别分割数据集labelme格式1420张4类别
注意数据集中有增强图片主要是亮度对比度增强,此外图片并不是十分清晰,具体看图片数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件)图片数量(jpg文件个数):1420标注数量(json文件个数)&#x…...
)
收藏!程序员转AI工程师的3条死路+3条真路(内含2026年最新就业方向)
本文揭示了2026年程序员转AI工程师的3条死路和3条真路。死路包括从零学ML训练想做研究员、靠Prompt工程当主修、装AI App做评测自媒体,这些路径因入门方向被误导而难以成功。真路则包括用现有领域跳板转AI应用工程、AI Infra/MLOps方向、AI Agent工程师方向…...

Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程
Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程 【免费下载链接】nginx-rtmp-win32 Nginx-rtmp-module Windows builds. 项目地址: https://gitcode.com/gh_mirrors/ng/nginx-rtmp-win32 想要在Windows系统上快速搭建自己的RTMP直播服务器…...

STM32F427 平替方案全面解析:从性能到成本的最优选择
文章摘要STM32F427 作为意法半导体 (ST) 旗下高性能 Cortex-M4 内核 MCU 的代表产品,凭借其 180MHz 主频、丰富的外设接口和出色的浮点运算能力,长期占据工业控制、医疗设备、智能仪表等中高端嵌入式市场的核心地位。然而近年来,全球芯片供应…...

不只是驱动问题!深挖华硕飞行堡垒风扇控制逻辑:ATK、热键服务与系统电源管理的三角关系
华硕飞行堡垒风扇控制逻辑深度解析:ATK、热键服务与系统电源管理的协同机制 当你的华硕飞行堡垒笔记本按下FNF5组合键却毫无反应时,多数教程会告诉你"重装驱动就能解决"。但作为技术爱好者,我们更关心的是:为什么驱动安…...
)
别再只用yum了!手把手教你用RPM包在CentOS 7.9上安装最新版LibreOffice 7.5.4(含中文包)
告别老旧版本:CentOS 7.9手动安装LibreOffice 7.5.4全攻略 在开源办公软件领域,LibreOffice无疑是当前最活跃、功能最全面的选择之一。然而许多CentOS用户发现,通过系统默认的yum仓库安装的LibreOffice版本往往落后官方最新版数年之久。以Cen…...