深度学习之超分辨率算法——FRCNN
– 对之前SRCNN算法的改进
-
- 输出层采用转置卷积层放大尺寸,这样可以直接将低分辨率图片输入模型中,解决了输入尺度问题。
- 改变特征维数,使用更小的卷积核和使用更多的映射层。卷积核更小,加入了更多的激活层。
- 共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要修改最后的反卷积层大小,就可以训练出不同尺寸的图片。
- 模型实现

import math
from torch import nnclass FSRCNN(nn.Module):def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):super(FSRCNN, self).__init__()self.first_part = nn.Sequential(nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),nn.PReLU(d))# 添加入多个激活层和小卷积核self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]for _ in range(m):self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])self.mid_part = nn.Sequential(*self.mid_part)# 最后输出self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,output_padding=scale_factor-1)self._initialize_weights()def _initialize_weights(self):# 初始化for m in self.first_part:if isinstance(m, nn.Conv2d):nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))nn.init.zeros_(m.bias.data)for m in self.mid_part:if isinstance(m, nn.Conv2d):nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))nn.init.zeros_(m.bias.data)nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)nn.init.zeros_(self.last_part.bias.data)def forward(self, x):x = self.first_part(x)x = self.mid_part(x)x = self.last_part(x)return x以上代码中,如起初所说,将SRCNN中给的输出修改为转置卷积,并且在中间添加了多个11卷积核和多个线性激活层。且应用了权重初始化,解决协变量偏移问题。
备注:11卷积核虽然在通道的像素层面上,针对一个像素进行卷积,貌似没有什么作用,但是卷积神经网络的特性,我们在利用多个卷积核对特征图进行扫描时,单个卷积核扫描后的为sum©,那么就是尽管在像素层面上无用,但是在通道层面上进行了融合,并且进一步加深了层数,使网络层数增加,网络能力增强。
- 上代码
- train.py
训练脚本
import argparse
import os
import copyimport torch
from torch import nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
from tqdm import tqdmfrom models import FSRCNN
from datasets import TrainDataset, EvalDataset
from utils import AverageMeter, calc_psnrif __name__ == '__main__':parser = argparse.ArgumentParser()# 训练文件parser.add_argument('--train-file', type=str,help="the dir of train data",default="./Train/91-image_x4.h5")# 测试集文件parser.add_argument('--eval-file', type=str,help="thr dir of test data ",default="./Test/Set5_x4.h5")# 输出的文件夹parser.add_argument('--outputs-dir',help="the output dir", type=str,default="./outputs")parser.add_argument('--weights-file', type=str)parser.add_argument('--scale', type=int, default=2)parser.add_argument('--lr', type=float, default=1e-3)parser.add_argument('--batch-size', type=int, default=16)parser.add_argument('--num-epochs', type=int, default=20)parser.add_argument('--num-workers', type=int, default=8)parser.add_argument('--seed', type=int, default=123)args = parser.parse_args()args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))if not os.path.exists(args.outputs_dir):os.makedirs(args.outputs_dir)cudnn.benchmark = Truedevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')torch.manual_seed(args.seed)model = FSRCNN(scale_factor=args.scale).to(device)criterion = nn.MSELoss()optimizer = optim.Adam([{'params': model.first_part.parameters()},{'params': model.mid_part.parameters()},{'params': model.last_part.parameters(), 'lr': args.lr * 0.1}], lr=args.lr)train_dataset = TrainDataset(args.train_file)train_dataloader = DataLoader(dataset=train_dataset,batch_size=args.batch_size,shuffle=True,num_workers=args.num_workers,pin_memory=True)eval_dataset = EvalDataset(args.eval_file)eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)best_weights = copy.deepcopy(model.state_dict())best_epoch = 0best_psnr = 0.0for epoch in range(args.num_epochs):model.train()epoch_losses = AverageMeter()with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size), ncols=80) as t:t.set_description('epoch: {}/{}'.format(epoch, args.num_epochs - 1))for data in train_dataloader:inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)preds = model(inputs)loss = criterion(preds, labels)epoch_losses.update(loss.item(), len(inputs))optimizer.zero_grad()loss.backward()optimizer.step()t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))t.update(len(inputs))torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))model.eval()epoch_psnr = AverageMeter()for data in eval_dataloader:inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)with torch.no_grad():preds = model(inputs).clamp(0.0, 1.0)epoch_psnr.update(calc_psnr(preds, labels), len(inputs))print('eval psnr: {:.2f}'.format(epoch_psnr.avg))if epoch_psnr.avg > best_psnr:best_epoch = epochbest_psnr = epoch_psnr.avgbest_weights = copy.deepcopy(model.state_dict())print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
test.py 测试脚本
import argparseimport torch
import torch.backends.cudnn as cudnn
import numpy as np
import PIL.Image as pil_imagefrom models import FSRCNN
from utils import convert_ycbcr_to_rgb, preprocess, calc_psnrif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights-file', type=str, required=True)parser.add_argument('--image-file', type=str, required=True)parser.add_argument('--scale', type=int, default=3)args = parser.parse_args()cudnn.benchmark = Truedevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')model = FSRCNN(scale_factor=args.scale).to(device)state_dict = model.state_dict()for n, p in torch.load(args.weights_file, map_location=lambda storage, loc: storage).items():if n in state_dict.keys():state_dict[n].copy_(p)else:raise KeyError(n)model.eval()image = pil_image.open(args.image_file).convert('RGB')image_width = (image.width // args.scale) * args.scaleimage_height = (image.height // args.scale) * args.scalehr = image.resize((image_width, image_height), resample=pil_image.BICUBIC)lr = hr.resize((hr.width // args.scale, hr.height // args.scale), resample=pil_image.BICUBIC)bicubic = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)bicubic.save(args.image_file.replace('.', '_bicubic_x{}.'.format(args.scale)))lr, _ = preprocess(lr, device)hr, _ = preprocess(hr, device)_, ycbcr = preprocess(bicubic, device)with torch.no_grad():preds = model(lr).clamp(0.0, 1.0)psnr = calc_psnr(hr, preds)print('PSNR: {:.2f}'.format(psnr))preds = preds.mul(255.0).cpu().numpy().squeeze(0).squeeze(0)output = np.array([preds, ycbcr[..., 1], ycbcr[..., 2]]).transpose([1, 2, 0])output = np.clip(convert_ycbcr_to_rgb(output), 0.0, 255.0).astype(np.uint8)output = pil_image.fromarray(output)# 保存图片output.save(args.image_file.replace('.', '_fsrcnn_x{}.'.format(args.scale)))
datasets.py
数据集的读取
import h5py
import numpy as np
from torch.utils.data import Datasetclass TrainDataset(Dataset):def __init__(self, h5_file):super(TrainDataset, self).__init__()self.h5_file = h5_filedef __getitem__(self, idx):with h5py.File(self.h5_file, 'r') as f:return np.expand_dims(f['lr'][idx] / 255., 0), np.expand_dims(f['hr'][idx] / 255., 0)def __len__(self):with h5py.File(self.h5_file, 'r') as f:return len(f['lr'])class EvalDataset(Dataset):def __init__(self, h5_file):super(EvalDataset, self).__init__()self.h5_file = h5_filedef __getitem__(self, idx):with h5py.File(self.h5_file, 'r') as f:return np.expand_dims(f['lr'][str(idx)][:, :] / 255., 0), np.expand_dims(f['hr'][str(idx)][:, :] / 255., 0)def __len__(self):with h5py.File(self.h5_file, 'r') as f:return len(f['lr'])工具文件utils.py
- 主要用来测试psnr指数,图片的格式转换(悄悄说一句,opencv有直接实现~~~)
import torch
import numpy as npdef calc_patch_size(func):def wrapper(args):if args.scale == 2:args.patch_size = 10elif args.scale == 3:args.patch_size = 7elif args.scale == 4:args.patch_size = 6else:raise Exception('Scale Error', args.scale)return func(args)return wrapperdef convert_rgb_to_y(img, dim_order='hwc'):if dim_order == 'hwc':return 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.else:return 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.def convert_rgb_to_ycbcr(img, dim_order='hwc'):if dim_order == 'hwc':y = 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.cb = 128. + (-37.945 * img[..., 0] - 74.494 * img[..., 1] + 112.439 * img[..., 2]) / 256.cr = 128. + (112.439 * img[..., 0] - 94.154 * img[..., 1] - 18.285 * img[..., 2]) / 256.else:y = 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.cb = 128. + (-37.945 * img[0] - 74.494 * img[1] + 112.439 * img[2]) / 256.cr = 128. + (112.439 * img[0] - 94.154 * img[1] - 18.285 * img[2]) / 256.return np.array([y, cb, cr]).transpose([1, 2, 0])def convert_ycbcr_to_rgb(img, dim_order='hwc'):if dim_order == 'hwc':r = 298.082 * img[..., 0] / 256. + 408.583 * img[..., 2] / 256. - 222.921g = 298.082 * img[..., 0] / 256. - 100.291 * img[..., 1] / 256. - 208.120 * img[..., 2] / 256. + 135.576b = 298.082 * img[..., 0] / 256. + 516.412 * img[..., 1] / 256. - 276.836else:r = 298.082 * img[0] / 256. + 408.583 * img[2] / 256. - 222.921g = 298.082 * img[0] / 256. - 100.291 * img[1] / 256. - 208.120 * img[2] / 256. + 135.576b = 298.082 * img[0] / 256. + 516.412 * img[1] / 256. - 276.836return np.array([r, g, b]).transpose([1, 2, 0])def preprocess(img, device):img = np.array(img).astype(np.float32)ycbcr = convert_rgb_to_ycbcr(img)x = ycbcr[..., 0]x /= 255.x = torch.from_numpy(x).to(device)x = x.unsqueeze(0).unsqueeze(0)return x, ycbcrdef calc_psnr(img1, img2):return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))class AverageMeter(object):def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.count先跑他个几十轮~

相关文章:
深度学习之超分辨率算法——FRCNN
– 对之前SRCNN算法的改进 输出层采用转置卷积层放大尺寸,这样可以直接将低分辨率图片输入模型中,解决了输入尺度问题。改变特征维数,使用更小的卷积核和使用更多的映射层。卷积核更小,加入了更多的激活层。共享其中的映射层&…...

软件测试之压力测试【详解】
压力测试 压力测试是一种软件测试,用于验证软件应用程序的稳定性和可靠性。压力测试的目标是在极其沉重的负载条件下测量软件的健壮性和错误处理能力,并确保软件在危急情况下不会崩溃。它甚至可以测试超出正常工作点的测试,并评估软件在极端…...

电脑出现 0x0000007f 蓝屏问题怎么办,参考以下方法尝试解决
电脑蓝屏是让许多用户头疼的问题,其中出现 “0x0000007f” 错误代码更是较为常见且棘手。了解其背后成因并掌握修复方法,能帮我们快速恢复电脑正常运行。 一、可能的硬件原因 内存问题 内存条长时间使用可能出现物理损坏,如金手指氧化、芯片…...

分布式系统架构:限流设计模式
1.为什么要限流? 任何一个系统的运算、存储、网络资源都不是无限的,当系统资源不足以支撑外部超过预期的突发流量时,就应该要有取舍,建立面对超额流量自我保护的机制,而这个机制就是微服务中常说的“限流” 2.四种限流…...

G口带宽服务器与1G独享带宽服务器:深度剖析其差异
在数据洪流涌动的数字化时代,服务器作为数据处理的核心,其性能表现直接关系到业务的流畅度和用户体验的优劣。随着技术的飞速发展,G口带宽服务器与1G独享带宽服务器已成为众多企业的优选方案。然而,这两者之间究竟有何细微差别&am…...

Flamingo:少样本多模态大模型
Flamingo:少样本多模态大模型 论文大纲理解1. 确认目标2. 分析过程(目标-手段分析)3. 实现步骤4. 效果展示5. 金手指 解法拆解全流程核心模式提问Flamingo为什么选择使用"固定数量的64个视觉tokens"这个特定数字?这个数字的选择背…...

推荐一款免费且好用的 国产 NAS 系统 ——FnOS
一、系统基础信息 开发基础:基于最新的Linux内核(Debian发行版)深度开发,兼容主流x86硬件(ARM还没适配),自由组装NAS,灵活扩展外部存储。 使用情况:官方支持功能较多&am…...

2025系统架构师(一考就过):案例题之一:嵌入式架构、大数据架构、ISA
一、嵌入式系统架构 软件脆弱性是软件中存在的弱点(或缺陷),利用它可以危害系统安全策略,导致信息丢失、系统价值和可用性降低。嵌入式系统软件架构通常采用分层架构,它可以将问题分解为一系列相对独立的子问题,局部化在每一层中…...

开机存活脚本
vim datastadard_alive.sh #!/bin/bashPORT18086 # 替换为你想要检查的端口号 dt$(date %Y-%m-%d)# 使用netstat检查端口是否存在 if netstat -tuln | grep -q ":$PORT"; thenecho "$dt Port $PORT is in use" > /opt/datastadard/logs/alive.log# 如…...

车载网关性能 --- GW ECU报文(message)处理机制的技术解析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所谓鸡汤,要么蛊惑你认命,要么怂恿你拼命,但都是回避问题的根源,以现象替代逻辑,以情绪代替思考,把消极接受现实的懦弱,伪装成乐观面对不幸的…...

CosyVoice安装过程详解
CosyVoice安装过程详解 安装过程参考官方文档 前情提要 环境:Windows子系统WSL下安装的Ubunt22.4python环境管理:MiniConda3git 1. Clone代码 $ git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git # 若是submodule下载失败&…...

传统网络架构与SDN架构对比
传统网络采用分布式控制,每台设备独立控制且管理耗时耗力,扩展困难,按 OSI 模型分层,成本高、业务部署慢、安全性欠佳且开放性不足。而 SDN 架构将控制平面集中到控制器,数据转发由交换机负责,可统一管理提…...

如何打造用户友好的维护页面:6个创意提升WordPress网站体验
在网站运营中,无论是个人博主还是大型企业网站的管理员,难免会遇到需要维护的情况。无论是服务器迁移、插件更新,还是突发的技术故障,都可能导致网站短暂无法访问。这时,设计维护页面能很好的缓解用户的不满࿰…...

【hackmyvm】Zday靶机wp
HMVrbash绕过no_root_squash静态编译fogproject 1. 基本信息^toc 这里写目录标题 1. 基本信息^toc2. 信息收集2.1. 端口扫描2.2. 目录扫描 3. fog project Rce3.1. ssh绕过限制 4. NFS no_root_squash5. bash运行不了怎么办 靶机链接 https://hackmyvm.eu/machines/machine.ph…...

redis使用注意哪些事项
1. 数据类型选择: • Redis支持多种数据类型,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等。在选择…...

步进电机位置速度双环控制实现
步进电机位置速度双环控制实现 野火stm32电机教学 提高部分-第11讲 步进电机位置速度双环控制实现(1)_哔哩哔哩_bilibili PID模型 位置环作为外环,速度环作为内环。设定目标位置和实际转轴位置的位置偏差,经过位置PID获得位置期望,然后讲位置期望(位置变化反映了转轴的速…...

优化程序中的数据:从数组到代数
前言 我们往往都希望优化我们的程序,使之达到一个更好的效果,程序优化的一个重点就是速度,加快速度的一个好办法就是使用并行技术,但是,并行时我们要考虑必须串行执行的任务,也就是有依赖关系的任务&#…...

【电商搜索】CRM: 具有可控条件的检索模型
【电商搜索】CRM: 具有可控条件的检索模型 目录 文章目录 【电商搜索】CRM: 具有可控条件的检索模型目录文章信息摘要研究背景问题与挑战如何解决核心创新点算法模型实验效果(包含重要数据与结论)相关工作后续优化方向 后记 https://arxiv.org/pdf/2412.…...

使用 ffmpeg 拼接合并视频文件
按顺序拼接多个视频文件 1、创建文件清单 创建一个文本文件 filelist.txt,列出所有要合并的视频文件。 格式如下: file path/to/video1.mp4 file path/to/video2.mp4 file path/to/video3.mp42、合并文件 下载FFmpeg,然后使用FFmpeg进行…...
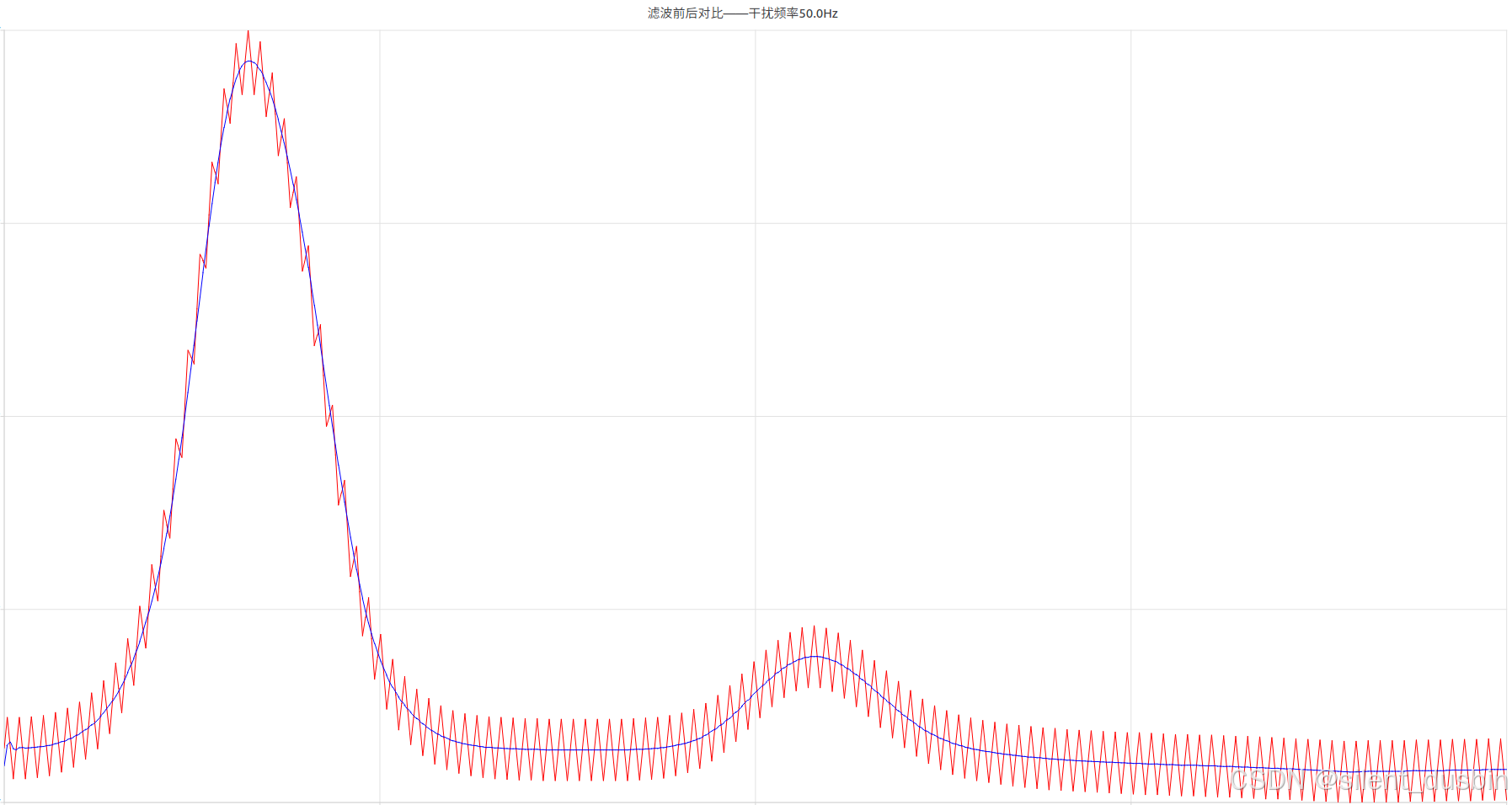
【信号滤波 (上)】傅里叶变换和滤波算法去除ADC采样中的噪声(Matlab/C++)
目录 一、ADC采样的噪声简介1.1 常见的ADC噪声来源 二、信号的时域到频域转换2.1 傅里叶变换巧记傅里叶变换 三、傅里叶变换和滤波算法工程实现3.1 使用Matlab计算信号时域到频域的变换3.2 使用Matlab去除特定频点噪声寻找峰值算噪声频率构建陷波滤波器滤除噪声频点陷波滤波器与…...
)
Verilator 5.008 + GTKWave 搭建指南:从安装到流水灯实战(附避坑清单)
Verilator 5.008 GTKWave 全流程实战指南:从环境搭建到流水灯仿真 在数字电路设计领域,仿真工具链的搭建往往是初学者面临的第一道门槛。Verilator作为当前最高效的开源Verilog仿真器之一,配合GTKWave波形查看工具,能够构建完整的…...

手把手教学:用CYBER-VISION为智能眼镜添加实时路径分割功能
手把手教学:用CYBER-VISION为智能眼镜添加实时路径分割功能 你有没有想过,如果智能眼镜能像科幻电影里那样,实时“看懂”眼前的世界,为视障朋友勾勒出一条清晰的安全路径,那该多酷?传统的导盲设备大多依赖…...

Gemma-3-12B-IT一文详解:指令微调模型在WebUI中支持多语言问答实测
Gemma-3-12B-IT一文详解:指令微调模型在WebUI中支持多语言问答实测 1. 开篇:当大模型有了“图形化”界面 想象一下,你有一个能力超强的AI助手,它知识渊博,能写代码、能回答问题、能帮你创作。但每次和它交流…...

【限时解禁|SITS2026未公开演讲PPT】:大模型量化压缩的“最后一公里”——如何让KV Cache压缩不掉F1、Attention稀疏不降BLEU?
第一章:SITS2026分享:大模型量化压缩技术 2026奇点智能技术大会(https://ml-summit.org) 大模型量化压缩已成为部署百亿参数级语言模型至边缘设备与推理服务集群的关键路径。在SITS2026现场,来自Meta、DeepMind及国内头部AI基础设施团队的工…...

Z-Image-GGUF文生图模型实战:电商海报、社交配图一键生成教程
Z-Image-GGUF文生图模型实战:电商海报、社交配图一键生成教程 1. 快速开始:30秒生成你的第一张AI图片 你是不是也好奇,那些精美的AI生成图片是怎么做出来的?今天,我就带你用Z-Image-GGUF这个开源模型,30秒…...

EVA-02文本重建终端Python爬虫实战:自动化数据采集与智能处理
EVA-02文本重建终端Python爬虫实战:自动化数据采集与智能处理 1. 引言 你有没有遇到过这样的情况?需要从几十个网站上收集产品信息,手动复制粘贴到手软,好不容易整理成表格,却发现格式乱七八糟,关键信息还…...

Phi-4-Reasoning-Vision高算力适配:双卡4090显存利用率提升至92%实测
Phi-4-Reasoning-Vision高算力适配:双卡4090显存利用率提升至92%实测 1. 项目概述 Phi-4-Reasoning-Vision是一款基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具。该工具专为双卡RTX 4090环境优化,通过多项技术创新实现了92%的显…...

STM32开发效率翻倍:在Clion里集成DeepSeek Cline插件实现智能代码补全与调试
STM32开发效率翻倍:在CLion中集成DeepSeek Cline实现智能编码革命 嵌入式开发领域正在经历一场由AI驱动的生产力变革。对于使用STM32系列芯片的中高级开发者来说,将DeepSeek Cline插件集成到CLion开发环境中,可以显著提升HAL库和标准库开发的…...

Python的__get__描述符中设置属性值在数据描述符中的优先级规则
Python描述符协议中的优先级规则揭秘 在Python面向对象编程中,描述符是实现属性访问控制的核心机制。数据描述符通过__get__和__set__方法拦截属性操作,但其优先级规则常让开发者困惑。本文将深入解析数据描述符中属性赋值的优先级逻辑,帮助…...

Qwen2_5_VLProcessor架构解析:多模态处理器的设计与实现
1. Qwen2_5_VLProcessor架构概览 Qwen2_5_VLProcessor是一个专门设计用于处理多模态数据的处理器,它能够同时处理文本、图像和视频输入。这个处理器的核心思想是将不同类型的数据统一到一个框架下进行处理,使得模型能够更好地理解和生成包含多种模态的内…...