开发场景中Java 集合的最佳选择
在 Java 开发中,集合类是处理数据的核心工具。合理选择集合,不仅可以提高代码效率,还能让代码更简洁。本篇文章将重点探讨 List、Set 和 Map 的适用场景及优缺点,帮助你在实际开发中找到最佳解决方案。
一、List:有序存储的/最佳选择
1. ArrayList:快速查询与动态数组
应用场景:当你需要频繁查询元素,或者存储的元素数目动态变化时,ArrayList 是首选。例如:分页展示用户数据。
代码示例:
List<String> users = new ArrayList<>();
users.add("Alice");
users.add("Bob");
System.out.println(users.get(1)); // 输出 Bob底层结构:ArrayList 使用一个 动态数组 来存储元素。初始时,数组的大小是固定的,当元素超过数组的容量时,会自动扩展数组的大小。
优点:
-
查询效率高:数组支持按索引快速访问元素,时间复杂度为
O(1),因此get()操作非常高效。 -
内存局部性:数组存储在连续的内存空间中,CPU 缓存友好,可以利用 CPU 的缓存机制提高访问效率。
缺点:
-
插入和删除效率低:当插入或删除元素时,尤其是在中间位置时,必须移动数组中的大量元素,时间复杂度为
O(n)。 -
扩容操作代价高:数组扩容时需要分配新的数组并将旧数组元素复制到新数组,操作的时间复杂度为
O(n)。
2. LinkedList:高效增删的双向链表
应用场景:需要频繁在列表中间或首尾插入、删除数据时,例如实现任务队列。
代码示例:
LinkedList<String> tasks = new LinkedList<>();
tasks.addFirst("Task1");
tasks.addLast("Task2");
tasks.removeFirst();底层结构:LinkedList 使用 双向链表,每个元素都有两个指针:一个指向前一个元素,一个指向下一个元素。这样可以在常数时间内插入或删除元素。
优点:
-
插入和删除高效:无论是在链表的头部、中部还是尾部,插入和删除元素的时间复杂度都为
O(1),因为只需要改变相关节点的指针。 -
内存使用灵活:每个元素的内存可以分散存储,不需要连续的内存块。
【比如在中间插入】
假设需要在链表中的某个位置
node前插入新节点newNode:
将
newNode的next指向node,将newNode的prev指向node.prev。更新
node.prev.next为newNode,更新node.prev为newNode。这只涉及 4 次指针操作,与链表的长度无关,因此在已定位到目标节点后,插入操作的时间复杂度为
O(1)。

缺点:
-
查询效率低:为了查找元素,必须从头节点或尾节点开始遍历链表,时间复杂度为
O(n)。 -
内存开销大:每个元素都需要额外存储指向前后元素的指针,相较于数组,占用更多的内存。
二、Set:无重复集合的首选
1. HashSet:高效去重
应用场景:当需要存储一组不允许重复的元素,且对顺序没有要求时,例如用户注册时验证用户名的唯一性。
代码示例
Set<String> usernames = new HashSet<>();
usernames.add("Alice");
usernames.add("Bob");
usernames.add("Alice"); // 重复的元素会被忽略
System.out.println(usernames.size()); // 输出 2底层结构:HashSet 使用 哈希表(HashMap)【哈希表在文末有补充讲解】来存储元素。哈希表通过将元素的哈希码映射到表中的桶来进行存储,确保元素是唯一的。
优点:
-
去重高效:哈希表能够快速判断元素是否已存在,因为它通过哈希值进行查找,时间复杂度为
O(1)。 -
查询效率高:哈希表的查找时间复杂度为
O(1),因此contains()和add()操作非常高效。
缺点:
-
无序存储:哈希表并不维护元素的顺序,因此
HashSet中的元素是无序的。 -
哈希冲突:不同的元素可能具有相同的哈希值,哈希冲突会影响性能,但通常情况下,哈希表的设计会尽量减少冲突的概率。
2. LinkedHashSet:有序去重
应用场景:当需要去重的同时保留插入顺序,例如记录用户最近浏览的商品。
代码示例:
Set<String> products = new LinkedHashSet<>();
products.add("Laptop");
products.add("Phone");
products.add("Laptop"); // 再次添加无效
System.out.println(products); // 输出 [Laptop, Phone]底层结构:LinkedHashSet 使用一个 哈希表 来存储元素,并通过一个 双向链表 来维护元素的插入顺序。
优点:
-
有序存储:由于链表的存在,
LinkedHashSet能够保持元素的插入顺序,访问时能够按照插入的顺序遍历元素。 -
去重高效:与
HashSet一样,哈希表提供了快速的查找和去重机制。
缺点:性能略低于 HashSet,由于还需要维护链表,LinkedHashSet 的操作稍微比 HashSet 慢,但差距通常不大。
3. TreeSet:排序与去重兼备
应用场景:当需要去重的同时对元素进行排序,例如实现排行榜或数据字典。
代码示例:
TreeSet<Integer> scores = new TreeSet<>();
scores.add(50);
scores.add(80);
scores.add(70);
System.out.println(scores); // 输出 [50, 70, 80]底层结构:TreeSet 使用 红黑树 来存储元素。红黑树是一种自平衡的二叉搜索树,能够确保树的深度保持在对数级别。

优点:
-
有序存储:
TreeSet会自动对元素进行排序,默认按自然顺序排序(compareTo(Object obj))或者通过传入Comparator自定义排序)。 -
查找、插入和删除的时间复杂度为
O(log n):由于红黑树的结构特性,所有操作的时间复杂度为对数级别。
缺点:性能较低,相比哈希表,红黑树的插入、删除和查找操作的时间复杂度为 O(log n),因此在大量数据操作时,性能略逊色于 HashSet 和 LinkedHashSet。
三、Map:键值对存储的首选
Map 是存储键值对的集合类,每个键唯一对应一个值。常用于快速查找和关联关系的存储。
1. HashMap:高效的键值映射
应用场景:需要高效查找时,例如存储用户 ID 和用户信息的映射。
代码示例:
Map<Integer, String> userMap = new HashMap<>();
userMap.put(1, "Alice");
userMap.put(2, "Bob");
System.out.println(userMap.get(1)); // 输出 Alice底层结构:HashMap 使用 哈希表 来存储键值对,通过键的哈希码来确定存储位置。
优点:
-
查找和插入高效:查找、插入和删除操作的时间复杂度为
O(1),通过哈希值直接定位位置。 -
支持键值对的存储:每个键对应唯一的值,适合各种映射操作。
缺点:
-
无序存储:哈希表中的元素是无序的,因此遍历时无法保证顺序。
2. LinkedHashMap:有序的键值映射
应用场景:需要既保持插入顺序,又能高效查找,例如实现最近访问页面的缓存。
代码示例:
Map<Integer, String> accessLog = new LinkedHashMap<>();
accessLog.put(1, "HomePage");
accessLog.put(2, "ProfilePage");
accessLog.put(3, "SettingsPage");
System.out.println(accessLog); // 输出 {1=HomePage, 2=ProfilePage, 3=SettingsPage}底层结构:LinkedHashMap 使用 哈希表 存储元素,并通过 双向链表 维护元素的插入顺序。
优点:
-
有序存储:保持了元素的插入顺序,遍历时能够按照插入顺序输出。
-
高效查找:与
HashMap一样,查询和插入操作的时间复杂度为O(1)。
缺点:内存开销较大,需要额外的内存来存储链表指针。
3. TreeMap:有序的键值存储
应用场景:需要按键排序存储键值对,例如实现字典或排行榜。
代码示例:
Map<Integer, String> sortedMap = new TreeMap<>();
sortedMap.put(3, "C");
sortedMap.put(1, "A");
sortedMap.put(2, "B");
System.out.println(sortedMap); // 输出 {1=A, 2=B, 3=C}-
底层结构:
TreeMap使用 红黑树 来存储键值对,按照键的自然顺序(或通过指定的Comparator)进行排序。 -
优点:
-
有序存储:自动对键进行排序,适用于需要顺序访问键值对的场景。
-
高效的查找、插入和删除:操作时间复杂度为
O(log n)。
-
-
缺点:性能略低于
HashMap和LinkedHashMap,由于红黑树需要维护平衡,操作的时间复杂度为对数级别,性能不如哈希表
4. Properties
应用场景
-
Properties常用于管理应用程序的配置信息,如数据库连接信息、语言国际化资源等。 -
它可以方便地加载和存储键值对到
.properties文件中,支持流式操作。
代码示例:
import java.io.*;
import java.util.Properties;
public class PropertiesExample {public static void main(String[] args) throws IOException {Properties properties = new Properties();// 设置键值对properties.setProperty("database.url", "jdbc:mysql://localhost:3306/mydb");properties.setProperty("database.user", "root");properties.setProperty("database.password", "password");
// 保存到文件try (FileOutputStream output = new FileOutputStream("config.properties")) {properties.store(output, "Database Configuration");}
// 从文件加载try (FileInputStream input = new FileInputStream("config.properties")) {properties.load(input);}
// 打印所有属性properties.forEach((key, value) -> System.out.println(key + ": " + value));}
}底层结构
-
Properties的基础是Hashtable:-
底层采用线程安全的哈希表结构。
-
键和值均为字符串类型(
String),以适应配置文件的存储和解析需求。 -
提供了
load()和store()方法,用于流式操作,方便配置文件的读写。
-
优点
-
简单直观:内置方法支持直接操作配置文件,减少手动解析的复杂性;适合存储和管理小规模配置。
-
线程安全:继承自
Hashtable,所有操作均是同步的,适合简单的多线程环境。 -
与文件系统集成良好:提供了流式操作接口,方便将键值对直接保存为
.properties文件或从文件中加载。
缺点
-
性能较低:由于继承自同步的
Hashtable,在现代高并发场景下不推荐使用,性能落后于HashMap。 -
局限性:仅支持
String类型的键值对,若需要存储复杂对象,需额外序列化。 -
不适合大规模配置:适合小型项目或简单模块的配置管理,大型系统建议采用更复杂的配置管理工具(如 Apache Commons Configuration 或 Spring)。
总结
| 集合类 | 底层数据结构 | 主要优点 | 主要缺点 |
|---|---|---|---|
| ArrayList | 动态数组 | 查询效率高,支持随机访问 | 插入删除效率低,扩容代价大 |
| LinkedList | 双向链表 | 插入删除效率高,内存灵活 | 查询效率低,占用内存大 |
| HashSet | 哈希表 | 查询和去重效率高 | 无序存储,受哈希冲突影响 |
| LinkedHashSet | 哈希表 + 双向链表 | 有序存储,去重效率高 | 内存占用较高 |
| TreeSet | 红黑树 | 有序存储,按自然顺序或自定义顺序排序 | 性能略低于哈希表,操作复杂度为 O(log n) |
| HashMap | 哈希表 | 查找和插入效率高,支持键值对映射 | 无序存储,受哈希冲突影响 |
| LinkedHashMap | 哈希表 + 双向链表 | 有序存储,按插入顺序遍历键值对 | 内存开销较高 |
| TreeMap | 红黑树 | 有序存储,按键自然顺序或自定义顺序排序 | 性能略低于哈希表,操作复杂度为 O(log n) |
| Properties | 哈希表(继承自 Hashtable) | 专为存储键值对配置设计,支持读写 .properties 文件 | 性能较低(继承自同步的 Hashtable),不适合高并发 |
知识点补充
1. 什么是哈希表?
哈希表是一种用来存储 键值对 的工具,它能非常快速地找到数据。你可以把它想象成一个 带编号的储物柜,每个柜子都有一个编号(索引),你把东西存进去时,会根据物品的特点计算出一个编号,然后直接放进对应的柜子里。取东西时也用相同的方法计算编号,直接找到对应的柜子打开拿走。
例子:
-
假如你有一本字典,查找某个单词(键)对应的解释(值)。
-
传统查找方法:逐页翻阅,耗时长。
-
使用哈希表:计算单词的编号,直接跳到对应的位置查看解释,速度非常快。
总结类比:
-
键是 “单词”,值是 “解释”。
-
哈希表通过哈希函数快速找到这个单词在哪页。
2. 哈希表是如何存数据的?
哈希表的核心在于 哈希函数。这个函数就像一个计算器,可以把一个键(比如一个字符串)变成一个数字(哈希值)。哈希值用来确定数据存储的位置。
步骤:
-
计算位置:用哈希函数把键变成一个数字,然后对储物柜的总数取模(%),确定放在哪个柜子里。假如储物柜有 10 个,"Alice" 的哈希值是 42,42 % 10 = 2,所以数据放到第 2 个柜子。
-
存储值:把数据放到计算出的柜子里。
相关文章:
开发场景中Java 集合的最佳选择
在 Java 开发中,集合类是处理数据的核心工具。合理选择集合,不仅可以提高代码效率,还能让代码更简洁。本篇文章将重点探讨 List、Set 和 Map 的适用场景及优缺点,帮助你在实际开发中找到最佳解决方案。 一、List:有序存…...

golangci-lint安装与Goland集成
golangci-lint安装与Goland集成 1.golangci-lint概述2.golangci-lint安装3.Goland 中集成 golangci-lint4.golangci-lint 的使用5.排除代码检查 1.golangci-lint概述 golangci-lint是用于go语言的代码静态检查工具集 官网地址:golangci-lint 特性: 快…...

金仓数据库安装-Kingbase v9-centos
在很多年前有个项目用的金仓数据库,上线稳定后就没在这个项目了,只有公司的开发环境还在维护,已经好多年没有安装过了,重温一下金仓数据库安装,体验一下最新版本,也做一个新版本的试验环境; 一、…...

条款6:auto推导若非己愿,使用显式类型初始化惯用法
一、代理类 所谓的代理类就是以模仿和增强一些类型的行为为目的存在的类 class MyArray { public:class MyArraySize{public:MyArraySize(int size) : theSize(size) {}int size() const { return theSize; }operator int() const { return theSize; }private:int theSize;};…...

蓝桥杯物联网开发板硬件组成
第一节 开发板简介 物联网设计与开发竞赛实训平台由蓝桥杯大赛技术支持单位北京四梯科技有限公司设计和生产,该产品可用于参加蓝桥杯物联网设计与开发赛道的竞赛实训或院校相关课程的 实践教学环节。 开发板基于STM32WLE5无线微控制器设计,芯片提供了25…...

视频汇聚融合云平台Liveweb一站式解决视频资源管理痛点
随着5G技术的广泛应用,各领域都在通信技术加持下通过海量终端设备收集了大量视频、图像等物联网数据,并通过人工智能、大数据、视频监控等技术方式来让我们的世界更安全、更高效。然而,随着数字化建设和生产经营管理活动的长期开展࿰…...

(aaai2025) FD2-Net: Frequency-Driven Feature Decomposition Network
论文:FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection 代码:https://github.com/like413/FD2-Net 这个论文核心思想认为:多源融合目标检测方法忽略了频率上的互补特征,如可见光图…...

深度学习之目标检测——RCNN
Selective Search 背景:事先不知道需要检测哪个类别,且候选目标存在层级关系与尺度关系 常规解决方法:穷举法,在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置 弊端:计算量大,且尺度不能兼顾 Selective …...
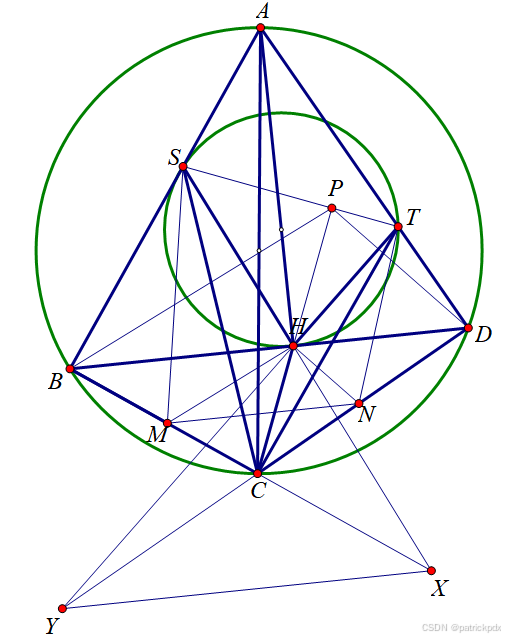
2014年IMO第3题
在凸四边形 A B C D ABCD ABCD 中, ∠ A B C = ∠ A D C = π 2 \angle ABC=\angle ADC=\frac{\pi}{2} ∠ABC=∠ADC=2π, H H H 为 A A A 在 B D BD BD 上的投影, 在边 A B AB AB 上有一点 S S S, ∠ C H S − ∠ C S B = π 2 \angle CHS-\angle CSB=\frac{\pi}{2} …...

国高材服务 | 高分子结晶动力学表征——高低温热台偏光显微镜
众所周知,聚合物制品的实际使用性能(如光学透明性、硬度、模量等)与材料内部的结晶形态、晶粒大小及完善程度有着密切的联系,因此,对聚合物结晶形态等的研究具有重要的理论和实际意义。 随着结晶条件的不用,…...

跨站请求伪造之基本介绍
一.基本概念 1.定义 跨站请求伪造(Cross - Site Request Forgery,缩写为 CSRF)漏洞是一种网络安全漏洞。它是指攻击者通过诱导用户访问一个恶意网站,利用用户在被信任网站(如银行网站、社交网站等)的登录状…...

Hadoop集群(HDFS集群、YARN集群、MapReduce计算框架)
一、 简介 Hadoop主要在分布式环境下集群机器,获取海量数据的处理能力,实现分布式集群下的大数据存储和计算。 其中三大核心组件: HDFS存储分布式文件存储、YARN分布式资源管理、MapReduce分布式计算。 二、工作原理 2.1 HDFS集群 Web访问地址&…...
经验总结(gtest+gmock))
单元测试(UT,C++版)经验总结(gtest+gmock)
最近做了一段测试工作,其中包括单元测试,编程语言是C。这里提供一些基本知识总结,方便入门单元测试。 1.单元测试介绍 单元测试(Unit Testing, 简称UT)是软件测试的一种方法,目的是通过对单个软件组件&am…...
)
Mysql高级部分总结(二)
MySQL的内部日志 binlog记载的是update/delete/insert这样的SQL语句,而redo log记载的是物理修改的内容(xxxx页修改了xxx)。 binlog无论MySQL用什么引擎,都会有,而redo log是MySQL的InnoDB引擎所产生的。 redo log事务开始的时候,就开始记录每次的变更信息,而binlog是在…...

纠正一下网络管理
先找到那个hrStorageType 这里我的值是 后面的值.1.3.6.1.2.1.25.2.1.4代表磁盘 我只有2个盘 C盘和D盘 所以这里只有2个 你们有E盘F盘的话 这里会多 .1.3.6.1.2.1.25.2.1.2 代表内存 .1.3.6.1.2.1.25.2.1.2 前面是 hrStorageType.4 所以 这里面.4后缀是表示内存的 之前…...

homebrew,gem,cocoapod 换源,以及安装依赖
安装homebrew /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 再按照成功提示配置环境变量 ruby 更新ruby到最新 brew install ruby 如果安装了会自动升级 安装完成后根据提示配置环境变量 再执行命令使其生效 s…...

Java字符串的|分隔符转List实现方案
字符串处理 问题背景代码实现代码优化原因分析实现方案 注意事项异常处理Maven未识别异常 问题背景 在项目组对账流程中,接收对方系统的对账文件,数据以|为分隔符,读取文件内容,分条入库。 代码实现 Java中将字符串转给list&am…...

Kafka可视化工具 Offset Explorer (以前叫Kafka Tool)
数据的存储是基于 主题(Topic) 和 分区(Partition) 的 Kafka是一个高可靠性的分布式消息系统,广泛应用于大规模数据处理和实时, 为了更方便地管理和监控Kafka集群,开发人员和运维人员经常需要使用可视化工具…...
DeepWalk 原理详解
概述: DeepWalk 是一种流行的图嵌入方法,用于学习图结构数据中节点的低维表示。它通过将图的节点视作序列数据,利用自然语言处理中的技术(类似于word2vec算法)来捕捉节点间的关系,可以帮助我们理解和利用图…...

GitLab安装|备份数据|迁移数据及使用教程
作者: 宋发元 最后更新时间:2024-12-24 GitLab安装及使用教程 官方教程 https://docs.gitlab.com/ee/install/docker.html Docker安装GitLab 宿主机创建容器持久化目录卷 mkdir -p /docker/gitlab/{config,data,logs}拉取GitLab镜像 docker pull gi…...

React Express渲染模式终极指南:Render Props与自定义Hook的对比分析
React Express渲染模式终极指南:Render Props与自定义Hook的对比分析 【免费下载链接】react-express Learn React through interactive examples 项目地址: https://gitcode.com/gh_mirrors/re/react-express 想要在React中实现组件逻辑复用?Ren…...

工作 8 年才弄明白,原来,这才是JDK推荐的线程关闭方式
JDK在线程的Stop方法时明确不得强行销毁一个线程,要优雅的退出线程。 何谓优雅退出线程,即业务将进行中请求正确被处理,取消待执行请求,执行资源回收,最终Thread Runable run 方法return 结束执行。 首先问为什么要退…...

别再让Pandas数据在Pycharm里‘隐身’了!一个设置搞定DataFrame显示不全
彻底解决Pandas DataFrame在PyCharm中的显示难题:从原理到实战 刚接触数据分析的朋友们,你们是否经常在PyCharm中遇到这样的困扰:当你满怀期待地打印出一个DataFrame,准备仔细查看数据时,却发现屏幕上布满了恼人的省略…...

RWA抵押:稳定币的“硬锚革命”如何撬动十万亿级金融新基建?
——波士顿咨询预言:当国债、房产上链,加密货币将迎来“信用时代”引言:稳定币的“信任危机”与RWA的破局之道2022年,LUNA/UST崩盘事件让全球加密市场陷入恐慌,算法稳定币的“无锚风险”暴露无遗。这场危机揭示了一个核…...

大厂面试真题揭秘:38W-55W年薪,大模型算法工程师核心考点全解析!
面试信息 岗位:大模型应用算法工程师-电商方向 类别:算法类 - 自然语言处理 地点:杭州 bg:普通211 渣硕 薪资情况 薪资构成:16 薪,属于互联网第一梯队。 硕士 总包:38W ~ 55W / 年普通档:38W ~ …...
)
汇川AM402 PLC控制IS620N伺服:手把手教你封装自己的轴控功能块(附完整工程)
汇川AM402 PLC控制IS620N伺服:从零封装轴控功能块的工程实践 在工业自动化项目中,伺服控制是最基础也最频繁使用的功能之一。想象一下,你正在开发一个包装产线控制系统,需要同时管理十几台伺服电机——每台电机都需要重复编写使能…...

基于 LocalClaw 的多 Agent 协作体系实战
基于 LocalClaw 的多 Agent 协作体系实战 ⏱️ 阅读时间:10分钟 | 🏷️ 标签:LocalClaw / 多Agent / AI协作 / 工作流自动化 前言:为什么需要多 Agent 协作? 当我们一个人管理多个平台的内容运营时,往往会…...
)
深入解析C++中的CRTP(奇异递归模板模式)
深入解析C中的CRTP(奇异递归模板模式) 在C的模板编程领域,CRTP(Curiously Recurring Template Pattern)作为一种独特的设计模式,为代码复用和类型安全提供了有效的解决方案。本文将探讨CRTP的基本概念、实现…...
迁移的7个致命陷阱与修复清单)
边缘场景下.NET 9 GC策略终极调优:从Server GC到Single-Object Heap(SOH)迁移的7个致命陷阱与修复清单
第一章:边缘场景下.NET 9 GC演进全景与SOH引入动因在资源受限、低延迟敏感的边缘计算环境中,.NET 运行时面临前所未有的内存管理挑战:设备内存通常仅数百MB,CPU核心数少且无稳定供电,传统GC策略易引发长暂停与内存碎片…...

特征选择实战:用F检验、互信息法搞定Kaggle高维数据,附完整Python代码与避坑指南
特征选择实战:用F检验与互信息法构建高维数据黄金特征集 在Kaggle竞赛和真实业务场景中,我们常常面对成百上千个特征的高维数据集。如何从中筛选出最具预测力的特征子集?本文将带你构建完整的特征选择流水线,从方差过滤到相关性筛…...