数学期望和方差
数学期望(Mathematical Expectation)和方差(Variance)是概率论和统计学中两个非常重要的概念。下面将分别对这两个概念进行解释。
数学期望
数学期望是随机变量的平均值,它描述了随机变量的中心位置。对于离散随机变量 (X),其数学期望 (E(X)) 定义为:
[ E(X) = \sum_{i=1}^{\infty} x_i p_i ]
其中 (x_i) 是随机变量 (X) 的可能取值,(p_i) 是 (X) 取值 (x_i) 的概率。
对于连续随机变量 (X),其数学期望 (E(X)) 定义为:
[ E(X) = \int_{-\infty}^{\infty} x f(x) , dx ]
其中 (f(x)) 是随机变量 (X) 的概率密度函数。
方差
方差是衡量随机变量分散程度的指标,它描述了随机变量的值与其数学期望之间的偏离程度。对于离散随机变量 (X),其方差 (Var(X)) 定义为:
[ Var(X) = E[(X - E(X))^2] = \sum_{i=1}^{\infty} (x_i - E(X))^2 p_i ]
对于连续随机变量 (X),其方差 (Var(X)) 定义为:
[ Var(X) = E[(X - E(X))^2] = \int_{-\infty}^{\infty} (x - E(X))^2 f(x) , dx ]
方差的平方根称为标准差(Standard Deviation),它与原随机变量具有相同的量纲,因此在实际应用中更直观。
例子
假设有一个离散随机变量 (X),其可能取值为 1, 2, 3,相应的概率为 0.2, 0.5, 0.3。那么 (X) 的数学期望和方差分别为:
数学期望:
[ E(X) = 1 \times 0.2 + 2 \times 0.5 + 3 \times 0.3 = 0.2 + 1 + 0.9 = 2.1 ]
方差:
[ Var(X) = (1 - 2.1)^2 \times 0.2 + (2 - 2.1)^2 \times 0.5 + (3 - 2.1)^2 \times 0.3 ]
[ = (-1.1)^2 \times 0.2 + (-0.1)^2 \times 0.5 + (0.9)^2 \times 0.3 ]
[ = 1.21 \times 0.2 + 0.01 \times 0.5 + 0.81 \times 0.3 ]
[ = 0.242 + 0.005 + 0.243 = 0.49 ]
标准差:
[ \sigma = \sqrt{Var(X)} = \sqrt{0.49} = 0.7 ]
因此,随机变量 (X) 的数学期望是 2.1,方差是 0.49,标准差是 0.7。
总结
数学期望和方差是描述随机变量特性的两个重要参数。数学期望表示随机变量的平均值,而方差表示随机变量的分散程度。在实际应用中,这两个参数对于理解数据的分布和进行统计分析非常有用。
相关文章:

数学期望和方差
数学期望(Mathematical Expectation)和方差(Variance)是概率论和统计学中两个非常重要的概念。下面将分别对这两个概念进行解释。 数学期望 数学期望是随机变量的平均值,它描述了随机变量的中心位置。对于离散随机变…...

【面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据...本篇介绍Tensor RT 的优化流程。
【面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据…本篇介绍Tensor RT 的优化流程。 【面试AI算法题中的知识点】方向涉及:ML/DL/CV/NLP/大数据…本篇介绍Tensor RT 的优化流程。 文章目录 【面试AI算法题中的知识点】方向涉及:ML/D…...

BLDC无感控制的驱动逻辑
如何知道转子已经到达预定位置,因为我们只有知道了转子到达了预定位置之后才能进行换相,这样电机才能顺滑的运转。转子位置检测常用的有三种方式。 方式一:通过过零检测,三相相电压与电机中性点电压进行比较。过零检测的优点在于…...
BP神经网络的反向传播算法
BP神经网络(Backpropagation Neural Network)是一种常用的多层前馈神经网络,通过反向传播算法进行训练。反向传播算法的核心思想是通过计算损失函数对每个权重的偏导数,从而调整权重,使得网络的预测输出与真实输出之间…...
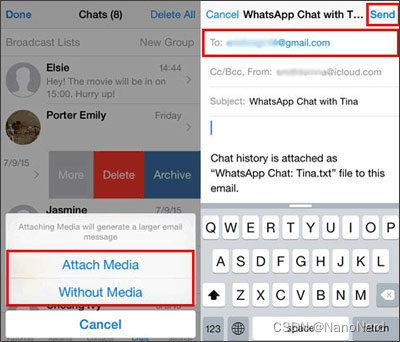
[实用指南]如何将视频从iPhone传输到iPad
概括 将视频从 iPhone 传输到 iPad 时遇到问题?您可能知道一种方法,但不知道如何操作。此外,您要传输的视频越大,完成任务就越困难。那么如何将视频从 iPhone 传输到 iPad,特别是当您需要发送大视频文件时?…...

Linux Snipaste 截图闪屏/闪烁
防 csdn 不能看,Go to juejin Linux Snipaste 截图时窗口元素一闪一闪的无法正常使用。 解决此问题时系统环境为 Manjaro KDE6,不过我在其他发行版与 gnome 上也碰到了。 先放解决办法: # 启动 Snipaste 时去掉缩放参数 env -u QT_SCREEN_…...
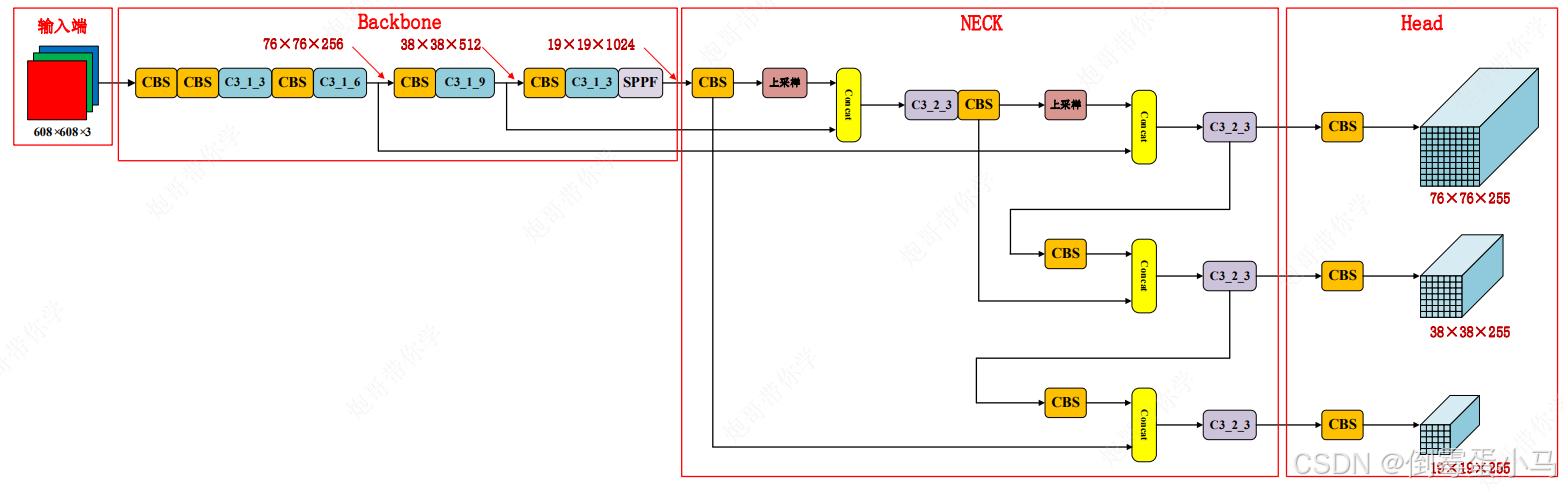
【YOLOv5】源码(common.py)
该文件位于/models/common.py,提供了构建YOLOv5模型的各种基础模块,其中包含了常用的功能模块,如自动填充autopad函数、标准卷积层Conv、瓶颈层Bottleneck、C3、SPPF、Concat层等 参考笔记:【YOLOv3】 源码(common.py…...

Node 如何生成 RSA 公钥私钥对
一、引入crypto模块 crypto 为node 自带模块,无需安装 const crypto require(crypto);二、封装生成方法 async function generateRSAKeyPair() {return new Promise((resolve, reject) > {crypto.generateKeyPair(rsa, {modulusLength: 2048, // 密钥长度为 …...

瑞_Linux中部署配置Java服务并设置开机自启动
文章目录 背景Linux服务配置步骤并设置开机自启动附-Linux服务常用指令 🙊 前言:由于博主在工作时,需要将服务部署到 Linux 服务器上运行,每次通过指令启动服务非常麻烦,所以将 jar 包部署的服务设置开机自启动&#x…...

javaEE-多线程进阶-JUC的常见类
juc:指的是java.util.concurrent包,该包中加载了一些有关的多线程有关的类。 目录 一、Callable接口 FutureTask类 参考代码: 二、ReentrantLock 可重入锁 ReentrantLock和synchronized的区别: 1.ReentantLock还有一个方法:…...

Flume拦截器的实现
Flume conf文件编写 vim file_to_kafka.conf#定义组件 a1.sources r1 a1.channels c1#配置source a1.sources.r1.type TAILDIR a1.sources.r1.filegroups f1 a1.sources.r1.filegroups.f1 /Users/zhangjin/model/project/realtime-flink/applog/log/app.* # 设置断点续传…...
:操作符 Operator)
Swift Combine 学习(四):操作符 Operator
Swift Combine 学习(一):Combine 初印象Swift Combine 学习(二):发布者 PublisherSwift Combine 学习(三):Subscription和 SubscriberSwift Combine 学习(四&…...

leetcode 173.二叉搜索树迭代器栈绝妙思路
以上算法题中一个比较好的实现思路就是利用栈来进行实现,以下方法三就是利用栈来进行实现的,思路很好,很简练。进行next的时候,先是一直拿到左边的子树,直到null为止,这一步比较好思考一点,下一…...
, ‘Buyer‘]).sum())
df.groupby([pd.Grouper(freq=‘1M‘, key=‘Date‘), ‘Buyer‘]).sum()
df.groupby([pd.Grouper(freq1M, keyDate), Buyer]).sum() 用于根据特定的时间频率和买家(Buyer)对 DataFrame 进行分组,然后计算每个分组的总和。下面是对这行代码的逐步解释: df.groupby([...]):这个操作会根据传入的…...

LLM - 使用 LLaMA-Factory 部署大模型 HTTP 多模态服务 (4)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/144881432 大模型的 HTTP 服务,通过网络接口,提供 AI 模型功能的服务,允许通过发送 HTTP 请求,交互…...
icp备案网站个人备案与企业备案的区别
个人备案和企业备案是在进行ICP备案时需要考虑的两种不同情况。个人备案是指个人拥有的网站进行备案,而企业备案则是指企业或组织名下的网站进行备案。这两者在备案过程中有一些明显的区别。 首先,个人备案相对来说流程较为简单。个人备案只需要提供个人…...

如何不修改模型参数来强化大语言模型 (LLM) 能力?
前言 如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 大语言模型 (Large Language Model, LLM, e.g. ChatGPT) 的参数量少则几十亿,多则上千亿,对其的训…...

AF3 AtomAttentionEncoder类的init_pair_repr方法解读
AlphaFold3 的 AtomAttentionEncoder 类中,init_pair_repr 方法方法负责为原子之间的关系计算成对表示(pair representation),这是原子转变器(atom transformer)模型的关键组成部分,直接影响对蛋白质/分子相互作用的建模。 init_pair_repr源代码: def init_pair_repr(…...

DDoS攻击防御方案大全
1. 引言 随着互联网的迅猛发展,DDoS(分布式拒绝服务)攻击成为了网络安全领域中最常见且危害严重的攻击方式之一。DDoS攻击通过向目标网络或服务发送大量流量,导致服务器过载,最终使其无法响应合法用户的请求。本文将深…...

Vue中常用指令
一、内容渲染指令 1.v-text:操作纯文本,用于更新标签包含的文本,但是使用不灵活,无法拼接字符串,会覆盖文本,可以简写为{{}},{{}}支持逻辑运算。 用法示例: //把name对应的值渲染到…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...