Elasticsearch:在 HNSW 中提前终止以实现更快的近似 KNN 搜索
作者:来自 Elastic Tommaso Teofili

了解如何使用智能提前终止策略让 HNSW 加快 KNN 搜索速度。
在高维空间中高效地找到最近邻的挑战是向量搜索中最重要的挑战之一,特别是当数据集规模增长时。正如我们之前的博客文章中所讨论的,当数据集规模有限时,强力(brute force)最近邻搜索可能是最佳选择。另一方面,随着向量数据集规模的增加,切换到近似最近邻搜索有助于在不牺牲准确性的情况下保持查询速度。
Elasticsearch 通过分层可导航小世界算法(Hierarchical Navigable Small World algorithm)实现近似最近邻搜索。HNSW 提供了一种有效的向量空间导航方法,降低了计算成本,同时仍保持了较高的搜索准确性。特别是,它的分层结构使得能够访问候选邻居并决定是否将它们包含在最终结果集中,同时减少向量距离计算。
然而,尽管 HNSW 算法有其优势,但它可以进一步优化以适应大规模向量搜索。提高 HNSW 性能的一种有效方法是找到在特定情况下停止访问图的方法,这称为提前终止。这篇博文探讨了 HNSW 的提前终止概念以及它们如何优化查询执行。
HNSW 中的冗余
HNSW 是一种近似最近邻算法,它构建一个分层图,其中节点表示向量,边表示向量空间中向量之间的接近度。每层都包含越来越多的图节点。查询时,搜索会遍历此图,从随机入口点开始,然后通过各层导航到最近的邻居。
搜索过程是迭代的,随着检查更多节点和向量而扩展。速度和准确性之间的平衡是 HNSW 的核心,但它仍然会导致冗余计算,尤其是在涉及大型数据集时。
在 HNSW 中,冗余计算主要发生在算法继续评估新节点或候选节点时,这些节点或候选节点在查找查询的实际邻居方面几乎没有任何改进。发生这种情况的原因是,在标准 HNSW 遍历中,算法逐层进行,探索和扩展候选节点,直到所有可能的路径都用尽。
具体来说,当数据集包含高度相似或重复的向量、具有密集簇内连接的簇或具有很少内在结构的高维空间中的向量时,可能会出现这种冗余。这种冗余会导致访问不必要的边,增加内存使用量,并可能降低搜索性能而不会提高准确性。在相似度得分快速衰减的高维空间中,一些边(edges)通常无法在图中提供有意义的捷径,从而导致导航路径效率低下。
因此,如果在遍历图时可以执行大量不必要的计算,则可以尝试改进 HNSW 算法以缓解此问题。
提前终止 FTW
导航解决方案空间是优化和搜索算法中的一个基本概念,其目标是在一组可能的解决方案中找到最佳解决方案。解决方案空间代表给定问题的所有潜在解决方案,导航它涉及系统地探索这些可能性。这个过程可以可视化为通过一个图移动,其中每个节点代表一个不同的解决方案,目标是确定最符合问题标准的节点。了解如何有效地导航解决方案空间对于解决具有大量解决方案的复杂问题至关重要。提前终止是一种通用的优化策略,可以应用于任何此类算法,以在特定情况下做出何时停止搜索解决方案的明智决定。
如果任何解决方案被认为 “足够好” 以满足期望的标准,则可以停止搜索,并且该解决方案可以被视为良好候选或最佳解决方案。这意味着一些潜在的更好的解决方案可能仍未被探索,因此很难在最终解决方案的效率和质量之间找到完美的折衷方案。

HNSW 中的提前终止
在 HNSW 中,提前终止可用于在完全评估所有潜在候选节点(向量)之前停止搜索过程。评估候选节点意味着计算查询向量与正在处理的图中节点对应的向量之间的实际相似度;因此,在遍历每一层时跳过一堆这样的操作,可以大大降低查询的计算成本。
另一方面,跳过原本会产生真正最近邻居的候选节点肯定会影响搜索结果的质量,可能会遗漏一些接近查询向量的候选向量。
因此,效率收益和准确度损失之间的权衡需要谨慎处理。提前终止在以下情况下很有用:
- 次线性效率(Sublinear Efficiency):你希望优化性能以换取略低的召回率。
- 高吞吐量系统(High-Throughput Systems):更快的响应时间比最高的准确度更有价值。
- 资源限制(Resource Constraints):计算或内存限制使得无法完全遍历 HNSW 图。
在 HNSW 的上下文中,有多种选项可用于实施提前终止策略。
- 固定候选池大小:最简单的提前终止策略之一是限制候选池的大小(例如,搜索期间评估的节点数)。在 HNSW 中,搜索过程是迭代的,随着搜索的进行,会扩展到更多节点。通过设置考虑的候选数限制,我们可以提前终止搜索并仅根据整个图的子集返回结果。当然,这可以以分层方式实现,也可以考虑整个图中的所有节点。
- 基于距离阈值的终止:另一种可能有效的提前终止策略是根据查询向量与对应于 HNSW 节点的向量之间的距离计算做出明智的决策。可以根据查询向量与当前最近向量之间的距离设置阈值。如果发现距离低于指定阈值的向量,则可以提前停止搜索,假设进一步探索不太可能产生更好的结果。这与对节点以智能顺序访问的事实的限制相辅相成,以避免遗漏可能相关的邻居。
- 基于质量估计的动态提前终止:一种更复杂的方法是根据每次搜索查询期间发现的结果的 “质量” 动态调整终止标准。如果搜索过程快速收敛到高质量邻居(例如,距离非常近的邻居),算法可以提前终止,即使没有达到预定义的阈值。
前两种策略属于 “固定配置” 提前终止策略类别,即搜索根据固定约束条件终止,而不考虑特定查询的复杂性。实际上,并非所有查询的难度都是相同的。例如,当向量分布不均衡时,一些查询需要访问更多候选项。一些查询向量可能落入向量空间中的密集区域,因此它们拥有更多的候选最近邻;而另一些查询可能落入“稀疏区域”,这使得找到其真正的最近邻更加困难。
由于这种情况,能够适应向量空间密度(从而适应 HNSW 图的连通性)的提前终止策略似乎更适合实际场景。因此,确定停止搜索每个查询的最佳点更有可能在不影响准确性的情况下大幅减少延迟。这种类型的提前终止策略被称为自适应策略,因为它们会适应每个查询实例来决定何时终止搜索过程。
例如,自适应提前终止策略可以利用机器学习模型来预测给定查询需要多少搜索工作才能达到所需的准确性。这样的模型会根据单个查询的特征和中间搜索结果动态调整要探索的图的范围。
说到中间搜索结果,它们通常是进一步搜索的有力预测因素。如果初始结果已经接近查询,则可能很快就会找到最近的邻居,从而允许提前终止。相反,较差的初始结果表明需要进行更广泛的探索(参见本文)。
Lucene 可以通过 KnnCollector 接口实现 HNSW 的提前终止,该接口公开了 earlyTerminated() 方法,但它还为 HNSW 提供了几个固定配置的提前终止策略:
- TimeLimitingKnnCollector 可以在达到特定时间阈值时停止 HNSW 图遍历。
- AbstractKnnCollector 是一个基本的 KnnCollector 实现,一旦访问了固定数量的图节点,它就会停止图遍历。
作为另一个示例,为了实现基于距离阈值的终止,我们可以依赖 Lucene 在 HNSW 遍历期间记录的最小竞争相似性(用于确保只探索竞争节点),并在其低于给定阈值时提前退出。
public class MCSEarlyExitCollector implements KnnCollector {private final KnnCollector delegate;private final double mcsThreshold;public MCSEarlyExitCollector(KnnCollector delegate, double mcsThreshold) {this.delegate = delegate;this.mcsThreshold = mcsThreshold;}@Overridepublic boolean earlyTerminated() {return delegate.earlyTerminated() || minCompetitiveSimilarity() < mcsThreshold;}...
}结论
如果正确实施,近似 KNN 的提前终止策略可以显著提高速度,同时保持良好的准确性。固定策略更容易实施,但它们可能需要更多调整,并且在不同的查询中效果不佳。另一方面,动态/自适应策略更难实施,但具有能够更好地适应不同搜索查询的优势。
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Early termination in HNSW for faster approximate KNN search - Elasticsearch Labs
相关文章:
Elasticsearch:在 HNSW 中提前终止以实现更快的近似 KNN 搜索
作者:来自 Elastic Tommaso Teofili 了解如何使用智能提前终止策略让 HNSW 加快 KNN 搜索速度。 在高维空间中高效地找到最近邻的挑战是向量搜索中最重要的挑战之一,特别是当数据集规模增长时。正如我们之前的博客文章中所讨论的,当数据集规模…...

unittest VS pytest
以下是 unittest 和 pytest 框架的对比表格: 特性unittestpytest设计理念基于类的设计,类似于 Java 的 JUnit更简洁,基于函数式编程设计,支持类和函数两种方式测试编写需要继承 unittest.TestCase 类,方法以 test_ 开…...
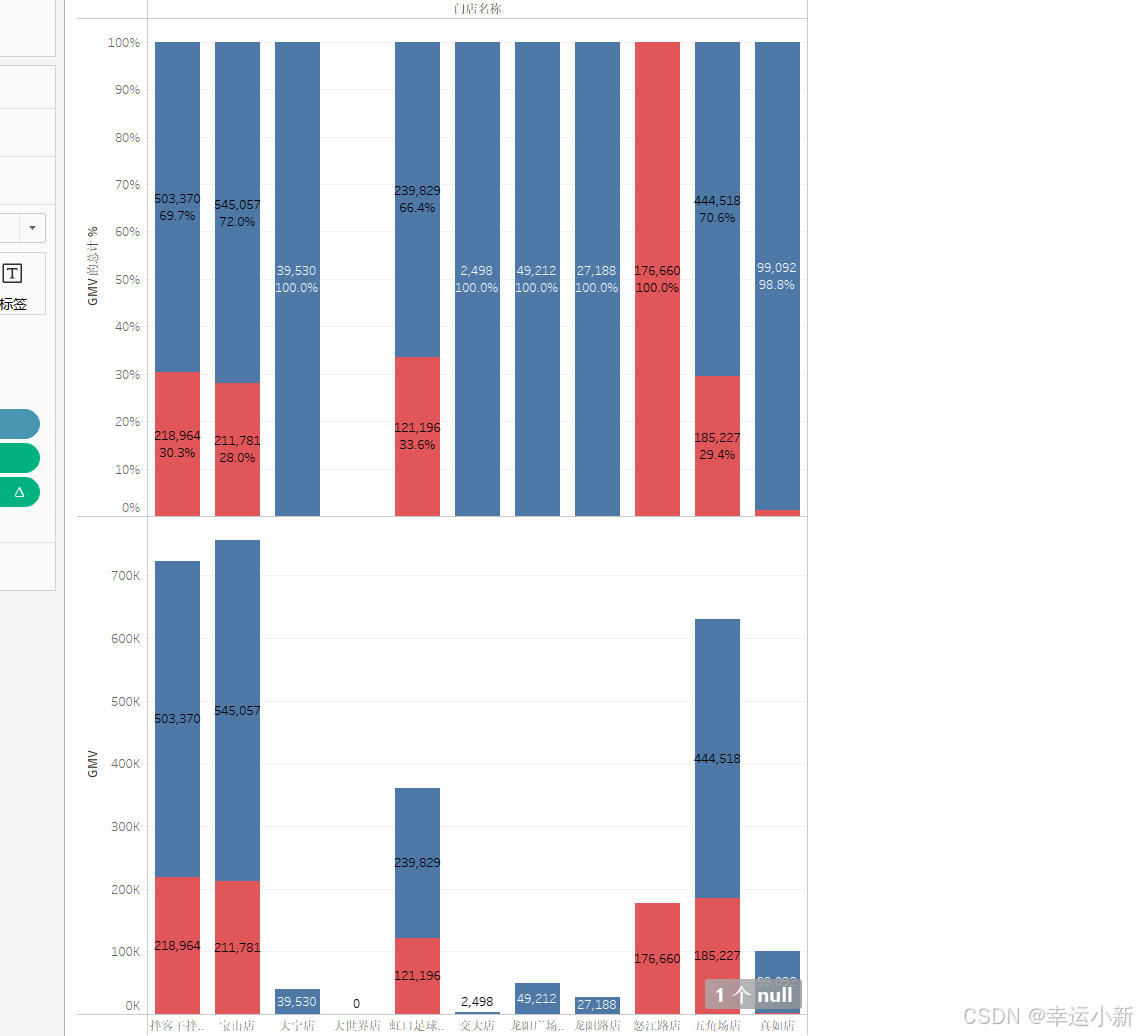
Tableau数据可视化与仪表盘搭建-基础图表制作
目录 对比分析:比大小 柱状图 条形图 数据钻取 筛选器 热力图 气泡图 变化分析:看趋势 折线图 预测 面积图 关系分布:看位置 散点图 直方图 地图 构成分析:看占比 饼图 树地图 堆积图 对比分析:比大…...

Center Loss 和 ArcFace Loss 笔记
一、Center Loss 1. 定义 Center Loss 旨在最小化类内特征的离散程度,通过约束样本特征与其类别中心之间的距离,提高类内特征的聚合性。 2. 公式 对于样本 xi 和其类别yi,Center Loss 的公式为: xi: 当前样本的特征向量&…...

3125: 【入门】求1/1+1/2+2/3+3/5+5/8+8/13+13/21……的前n项的和
文章目录 题目描述输入输出样例输入样例输出 题目描述 求1/11/22/33/55/88/1313/2121/34……的前n项的和。 输入 第1行:一个整数n(1 < n < 30 )。 输出 一行:一个小数,即前n项之和(保留3位小数&…...

如何确保获取的淘宝详情页数据的准确性和时效性?
要确保获取的淘宝详情页数据的准确性和时效性,可从以下几个方面着手: 合法合规获取数据 遵守平台规则:在获取淘宝详情页数据之前,务必仔细阅读并严格遵守淘宝平台的使用协议和相关规定。明确哪些数据可以获取、以何种方式获取以及…...

云计算是如何帮助企业实现高可用性的
想象一下,你正在享受一个悠闲的周末,突然接到同事的电话:公司的核心系统宕机了!这个场景对很多IT从业者来说并不陌生。但在云计算时代,这样的噩梦正在逐渐远去。 一位前辈告诉我:"在技术世界里&#…...

143.《python中使用pymongo》
文章目录 pymongo安装pymongo连接数据库mongodb操作创建数据库判断数据库是否存在创建集合判断集合是否已经存在插入集合插入一条多条插入 查询数据查询一条数据查询所有数据查询指定字段的数据统计查询统计所有记录数按条件统计记录数分页列表查询比较查询$eq$gt$gte$in$lt$lt…...

Babylon.js 的 Mesh 与 Unity 的 GameObject:深入对比与分析
在 3D 开发领域,Babylon.js 和 Unity 是两款极具影响力的引擎,分别在 Web 平台和游戏开发领域占据重要地位。要深入理解这两款引擎的异同,从其核心对象——Babylon.js 的 Mesh 和 Unity 的 GameObject ——入手进行对比,是…...
MySQL安装,配置教程
一、Linux在线yum仓库安装 打开MySQL官方首页,链接为:https://www.mysql.com/ 界面如下: 在该页面中找到【DOWNOADS】选项卡,点击进入下载页面。 在下载界面中,可以看到不同版本的下载链接,这里选择【My…...
)
Android折叠屏适配(权宜之计)
现在折叠屏手机出了也有一段时间了,但是除了大厂app,其他app适配折叠屏还是比较少,如果真的想做好折叠屏完全适配,那这个文章可能并不适合,这里只是一个简单适配的思路。 如果原先你的app已经适配了平板,那…...

Spark是什么?Flink和Spark区别
Spark是什么?Flink和Spark区别 一、Spark二、Spark和Flink区别三、总结 一、Spark Apache Spark 是一个开源的大数据处理框架,主要用于大规模数据处理和分析。它支持多种数据处理模式,包括批处理、流处理、SQL 查询、机器学习和图处理等。 核…...

Cocos Creator 3.8 修改纹理像素值
修改的代码: import { _decorator, Component, RenderTexture, Sprite, Texture2D, ImageAsset, SpriteFrame, Vec2, gfx, director, log, math, v2 } from cc;const { ccclass, property } _decorator;ccclass(GradientTransparency) export class GradientTrans…...

如何评价deepseek-V3 VS OpenAI o1 自然语言处理成Sql的能力
DeepSeek-V3 介绍 在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。 准备工作: 笔者只演示实例o1 VS DeepSeek-V3两个模型,大家可以自行验证结果或者实验更多场景,同时…...

SQL左连接的两种不同情况示例和外连接示例
Oracle;有2个表如下; 执行下图选中的左连接; 左表10条记录,右表3条记录,结果是10条记录; 执行下图的左连接, 老师表为左表,学生表为右表,结果会显示每个老师,…...

【渗透测试术语总结】
Top 渗透测试常用专业术语 相信大家和我一样,搞不清这些专业名词的区别,所以我来整理一下。 1. POC、EXP、Payload与Shellcode POC:全称 Proof of Concept ,中文 概念验证 ,常指一段漏洞证明的代码。 EXP…...

Unity2D初级背包设计后篇 拓展举例与不足分析
Unity2D初级背包设计中篇 MVC分层撰写(万字详解)-CSDN博客、 如果你已经搞懂了中篇,那么对这个背包的拓展将极为简单,我就在这里举个例子吧 目录 1.添加物品描述信息 2.拓展思路与不足分析 1.没有删除只有丢弃功能,所以可以添加垃圾桶 2.格…...

Kafka优势剖析-幂等性和事务
目录 1. 幂等性(Idempotence) 1.1 什么是幂等性? 1.2 幂等性的实现 1.2.1 生产者 ID 和序列号 1.2.2 重复消息检测 1.2.3 幂等性的优势 1.3 幂等性的配置 2. 事务支持(Transactions) 2.1 什么是事务支持&…...

MyBatis深入了解
目录 xml 映射文件中,除了常见的select、insert、update、delete 标签之外,还有哪些标签? Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗? MyBatis 是如何进行分页的?分页插件的原理是什么? 简述 …...
语音技术与人工智能:智能语音交互的多场景应用探索
引言 近年来,智能语音技术取得了飞速发展,逐渐渗透到日常生活和各行各业中。从语音助手到智能家居控制,再到企业客服和教育辅导,语音交互正以前所未有的速度改变着人机沟通的方式。这一变革背后,人工智能技术无疑是关键…...

关联查询,左连接,inner join笔记,BNL,NLJ
文章目录left join的最大值和最小值3个表的inner join关联查询时的is_del处理cross join(full join)NLJ 性能高BNL 性能低blj会导致什么问题?left join的最大值和最小值 假设左表m条,右表n条 最小值是m: 当一条也匹配不到右表时,或者右表中…...
 failed (SSL: error:8000000D:system library::Permission denied:calling fo)
server.crt“: BIO_new_file() failed (SSL: error:8000000D:system library::Permission denied:calling fo
server.crt": BIO_new_file() failed (SSL: error:8000000D:system library::Permission denied:calling fopen(/ Nginx更换ssl证书报错。 解决方案:关闭selinux 在Linux系统中,SELinux(Security-Enhanced Linux)是一种安全模…...
)
Dubbo学习笔记(快速入门)
一、分布式基础1.1 软件架构四大演变演变顺序:单体 → 垂直 → 分布式 → 微服务解释:架构进化本质:为了解决流量变大、代码变多、维护困难。1)单体架构所有模块一个工程,一个jar包,全部本地调用࿱…...

猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源
猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan详细方法汇总
2026年京东云OpenClaw/Hermes Agent配置Token Plan详细方法汇总。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

传奇3手游网站下载 元素搭配攻略 新手快速上手复古服
官方出版资质:传奇3光通版手游由传奇3G原班人马打造,出版单位华东师范大学电子音像出版社有限公司,审批文号新广出审〔2016〕2183号,出版物号ISBN978-7-7979-0843-6,运营主体安徽游昕网络科技有限公司,官网…...

大模型上下文窗口管理技巧:突破长度限制的艺术
大模型上下文窗口管理技巧:突破长度限制的艺术 前言 大模型的上下文窗口(Context Window)是指模型能够处理的最大输入长度。目前主流模型的上下文窗口从 4K 到 128K 不等,GPT-4 Turbo 甚至达到了 128K tokens。然而,随…...
完整38页pdf)
Anthropic《创始人手册:打造AI原生创业公司》Claude(中文精读版)完整38页pdf
Anthropic 在2026年5月发布的官方手册,聚焦 AI 原生创业的全生命周期,拆解从创意、MVP、上线到扩张的四大核心阶段,重构 AI 时代的创业逻辑。 手册核心围绕 “AI 重塑创业模式” 展开,指出 2026 年 AI 已打破技术门槛,…...
和内存映射(mmap)到底有啥区别?)
别再傻傻分不清了!Linux下共享内存(shm)和内存映射(mmap)到底有啥区别?
Linux下共享内存(shm)与内存映射(mmap)的本质区别与工程实践 在Linux系统编程中,当我们需要在进程间高效传递数据时,共享内存(shm)和内存映射(mmap)这两个概念常常让开发者感到困惑。它们看似都能实现内存共…...
)
从“玄学”到科学:手把手教你用Python/SciPy设计有源巴特沃斯滤波器(告别手动解方程)
从“玄学”到科学:手把手教你用Python/SciPy设计有源巴特沃斯滤波器(告别手动解方程) 在电子工程领域,滤波器设计一直被视为兼具艺术与科学的复杂技艺。传统设计流程中,工程师需要反复查阅归一化表格、手动解算多项式方…...