【机器学习实战入门】基于深度学习的乳腺癌分类

什么是深度学习?
作为对机器学习的一种深入方法,深度学习受到了人类大脑和其生物神经网络的启发。它包括深层神经网络、递归神经网络、卷积神经网络和深度信念网络等架构,这些架构由多层组成,数据必须通过这些层才能最终产生输出。深度学习旨在改进人工智能并使许多应用成为可能;它被应用于计算机视觉、语音识别、自然语言处理、音频识别和药物设计等多个领域。
什么是 Keras?
Keras 是一个用 Python 编写的开源神经网络库。它是一个高级 API,并可以在 TensorFlow、CNTK 和 Theano 上运行。Keras 专注于支持快速实验和原型设计,同时在 CPU 和 GPU 上无缝运行。它用户友好、模块化且可扩展。
乳腺癌分类 – 目标
我们将在一个 IDC 数据集上构建一个乳腺癌分类器,可以准确地将组织学图像分类为良性或恶性。
关于 Python 项目 – 乳腺癌分类
在这个 Python 项目中,我们将构建一个分类器,以 80% 的乳腺癌组织学图像数据集进行训练。其中,我们将保留 10% 的数据用于验证。使用 Keras,我们将定义一个 CNN(卷积神经网络),并将其命名为 CancerNet,然后在我们的图像上进行训练。最后,我们将构建一个混淆矩阵来分析模型的性能。
IDC 是浸润性导管癌;这是一种在乳管中开始并在管外侵犯乳腺纤维或脂肪组织的癌症;它是最常见的乳腺癌形式,占所有乳腺癌诊断的 80%。而组织学是研究组织微观结构的学科。
数据集
我们将使用来自 Kaggle 的 IDC_regular 数据集(乳腺癌组织学图像数据集)。这个数据集包含从 162 份乳腺癌整体装片扫描图像中提取的 277524 个 50x50 尺寸的图像块。其中有 198738 个测试结果为 IDC 阴性,78786 个测试结果为 IDC 阳性。数据集公开发布,你可以在这里下载。为此,你需要至少 3.02GB 的磁盘空间。
此数据集中的文件名如下:
8863_idx5_x451_y1451_class0
这里,8863_idx5 是患者编号,451 和 1451 是裁剪图像的 x 和 y 坐标,0 是类别标签(0 表示 IDC 缺失)。
链接: 基于深度学习的乳腺癌分类 源代码与数据集
前提条件
你需要安装一些 Python 包才能运行这个高级 Python 项目。你可以使用 pip 安装:
pip install numpy opencv-python pillow tensorflow keras imutils scikit-learn matplotlib
高级 Python 项目 – 乳腺癌分类的步骤
- 下载压缩包。在你选择的位置解压缩它,并进入该位置。

乳腺癌检测 Python 项目
- 现在,在内部的 breast-cancer-classification 目录中,创建目录 datasets- 在此目录下,创建目录 original:
mkdir datasets
mkdir datasets\original
-
下载数据集。
-
在 original 目录中解压缩数据集。为了观察该目录的结构,我们将使用 tree 命令:

cd breast-cancer-classification\breast-cancer-classification\datasets\original
tree
项目中的原始结构
我们为每个患者编号有一个目录。在每个这样的目录中,我们有存放良性和恶性图像的 0 和 1 目录。
config.py:
这里包含了一些我们构建数据集和训练模型时所需的配置。你可以在 cancernet 目录中找到它。
import os
INPUT_DATASET = "datasets/original"
BASE_PATH = "datasets/idc"
TRAIN_PATH = os.path.sep.join([BASE_PATH, "training"])
VAL_PATH = os.path.sep.join([BASE_PATH, "validation"])
TEST_PATH = os.path.sep.join([BASE_PATH, "testing"])
TRAIN_SPLIT = 0.8
VAL_SPLIT = 0.1

在这里,我们声明了原始数据集的路径(datasets/original),新目录的路径(datasets/idc),以及使用基本路径声明的训练、验证和测试目录的路径。我们还声明 80% 的整个数据集将用于训练,而其中的 10% 将用于验证。
build_dataset.py:
此脚本将根据上述比例将数据集分割为训练集、验证集和测试集- 80% 用于训练(其中 10% 用于验证),20% 用于测试。使用 Keras 的 ImageDataGenerator,我们将提取图像批处理,以避免一次性将整个数据集加载到内存中。
from cancernet import config
from imutils import paths
import random, shutil, os
originalPaths=list(paths.list_images(config.INPUT_DATASET))
random.seed(7)
random.shuffle(originalPaths)
index=int(len(originalPaths)*config.TRAIN_SPLIT)
trainPaths=originalPaths[:index]
testPaths=originalPaths[index:]
index=int(len(trainPaths)*config.VAL_SPLIT)
valPaths=trainPaths[:index]
trainPaths=trainPaths[index:]
datasets=[("training", trainPaths, config.TRAIN_PATH),("validation", valPaths, config.VAL_PATH),("testing", testPaths, config.TEST_PATH)
]
for (setType, originalPaths, basePath) in datasets:print(f'Building {setType} set')if not os.path.exists(basePath):print(f'Building directory {basePath}')os.makedirs(basePath)for path in originalPaths:file=path.split(os.path.sep)[-1]label=file[-5:-4]labelPath=os.path.sep.join([basePath,label])if not os.path.exists(labelPath):print(f'Building directory {labelPath}')os.makedirs(labelPath)newPath=os.path.sep.join([labelPath, file])shutil.copy2(path, newPath)

机器学习 Python 项目
在此脚本中,我们将从 config、imutils、random、shutil 和 os 导入。我们构建一个原始图像路径的列表,然后将列表打乱。接着,我们通过将列表长度乘以 0.8 来计算索引,以便可以截取该列表以创建训练和测试数据集的子列表。然后,我们进一步计算索引,将训练数据集的 10% 用于验证,剩下的用于训练自己。
现在,datasets 是一个包含训练集、验证集和测试集信息的列表。这些信息包括路径和基本路径。对于此列表中的每个 set 类型、路径和基本路径,我们将打印如‘构建测试集’。如果基本路径不存在,我们将创建目录。对于 originalPaths 中的每个路径,我们将提取文件名和类别标签。然后,我们将构建标签目录(0 或 1)的路径-如果它还不存在,我们将明确创建该目录。现在,我们将构建目标图像的路径并将其复制到这里-它所属的位置。
- 运行脚本 build_dataset.py:
py build_dataset.py

构建数据集
cancernet.py:
我们将构建的网络是一个 CNN(卷积神经网络),并命名为 CancerNet。该网络执行以下操作:
- 使用 3x3 CONV 滤波器
- 将这些滤波器堆叠在一起
- 执行最大池化
- 使用深度分离卷积(更高效,占用较少内存)
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import SeparableConv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
class CancerNet:@staticmethoddef build(width,height,depth,classes):model=Sequential()shape=(height,width,depth)channelDim=-1if K.image_data_format()=="channels_first":shape=(depth,height,width)channelDim=1model.add(SeparableConv2D(32, (3,3), padding="same",input_shape=shape))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Dropout(0.25))model.add(SeparableConv2D(64, (3,3), padding="same"))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(SeparableConv2D(64, (3,3), padding="same"))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Dropout(0.25))model.add(SeparableConv2D(128, (3,3), padding="same"))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(SeparableConv2D(128, (3,3), padding="same"))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(SeparableConv2D(128, (3,3), padding="same"))model.add(Activation("relu"))model.add(BatchNormalization(axis=channelDim))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(256))model.add(Activation("relu"))model.add(BatchNormalization())model.add(Dropout(0.5))model.add(Dense(classes))model.add(Activation("softmax"))return model


在本脚本中,我们使用 Sequential API 构建 CancerNet,并使用 SeparableConv2D 实现深度卷积。CancerNet 类有一个静态方法 build,它接受四个参数- 图像的宽度和高度、深度(每个图像的颜色通道数)以及网络将在其间预测的类别数,对于我们来说,这一数字为 2(0 和 1)。
在此方法中,我们初始化 model 和 shape。使用 channels_first 时,我们更新 shape 和通道维度。
现在,我们将定义三个 DEPTHWISE_CONV => RELU => POOL 层;每一层都有更高的堆叠和更多的滤波器。softmax 分类器输出每个类别的预测百分比。最后,我们返回模型。
train_model.py:
此脚本用于训练和评估我们的模型。在这里,我们将从 keras、sklearn、cancernet、config、imutils、matplotlib、numpy 和 os 导入。
import matplotlib
matplotlib.use("Agg")
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler
from keras.optimizers import Adagrad
from keras.utils import np_utils
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from cancernet.cancernet import CancerNet
from cancernet import config
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import os
NUM_EPOCHS=40; INIT_LR=1e-2; BS=32
trainPaths=list(paths.list_images(config.TRAIN_PATH))
lenTrain=len(trainPaths)
lenVal=len(list(paths.list_images(config.VAL_PATH)))
lenTest=len(list(paths.list_images(config.TEST_PATH)))
trainLabels=[int(p.split(os.path.sep)[-2]) for p in trainPaths]
trainLabels=np_utils.to_categorical(trainLabels)
classTotals=trainLabels.sum(axis=0)
classWeight=classTotals.max()/classTotals
trainAug = ImageDataGenerator(rescale=1/255.0,rotation_range=20,zoom_range=0.05,width_shift_range=0.1,height_shift_range=0.1,shear_range=0.05,horizontal_flip=True,vertical_flip=True,fill_mode="nearest")
valAug=ImageDataGenerator(rescale=1 / 255.0)
trainGen = trainAug.flow_from_directory(config.TRAIN_PATH,class_mode="categorical",target_size=(48,48),color_mode="rgb",shuffle=True,batch_size=BS)
valGen = valAug.flow_from_directory(config.VAL_PATH,class_mode="categorical",target_size=(48,48),color_mode="rgb",shuffle=False,batch_size=BS)
testGen = valAug.flow_from_directory(config.TEST_PATH,class_mode="categorical",target_size=(48,48),color_mode="rgb",shuffle=False,batch_size=BS)
model=CancerNet.build(width=48,height=48,depth=3,classes=2)
opt=Adagrad(lr=INIT_LR,decay=INIT_LR/NUM_EPOCHS)
model.compile(loss="binary_crossentropy",optimizer=opt,metrics=["accuracy"])
M=model.fit_generator(trainGen,steps_per_epoch=lenTrain//BS,validation_data=valGen,validation_steps=lenVal//BS,class_weight=classWeight,epochs=NUM_EPOCHS)
print("Now evaluating the model")
testGen.reset()
pred_indices=model.predict_generator(testGen,steps=(lenTest//BS)+1)
pred_indices=np.argmax(pred_indices,axis=1)
print(classification_report(testGen.classes, pred_indices, target_names=testGen.class_indices.keys()))
cm=confusion_matrix(testGen.classes,pred_indices)
total=sum(sum(cm))
accuracy=(cm[0,0]+cm[1,1])/total
specificity=cm[1,1]/(cm[1,0]+cm[1,1])
sensitivity=cm[0,0]/(cm[0,0]+cm[0,1])
print(cm)
print(f'Accuracy: {accuracy}')
print(f'Specificity: {specificity}')
print(f'Sensitivity: {sensitivity}')
N = NUM_EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0,N), M.history["loss"], label="train_loss")
plt.plot(np.arange(0,N), M.history["val_loss"], label="val_loss")
plt.plot(np.arange(0,N), M.history["acc"], label="train_acc")
plt.plot(np.arange(0,N), M.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on the IDC Dataset")
plt.xlabel("Epoch No.")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig('plot.png')






总结
在这个 Python 项目中,我们学习了如何使用 IDC 数据集(浸润性导管癌的组织学图像)构建一个乳腺癌分类器,并为此创建了 CancerNet 网络。我们使用 Keras 实现了这一点。希望你喜欢这个 Python 项目。
参考资料
| 资料名称 | 链接 |
|---|---|
| Kaggle IDC 数据集 | 链接 |
| Keras 文档 | 链接 |
| TensorFlow 官方文档 | 链接 |
| Python for Data Science Handbook | 链接 |
| PyImageSearch 深度学习教程 | 链接 |
| 《深度学习》 - Ian Goodfellow | 链接 |
| Medium 深度学习文章 | 链接 |
| DataFlair Python 项目 | 链接 |
| 《利用深度学习对抗癌症》 -.scalatest | 链接 |
| 维基百科 - 乳腺癌 | 链接 |
| 中国深度学习社区 | 链接 |
| 深度学习读书会 | 链接 |
| Deep Learning Book by Yoshua Bengio | 链接 |
关于数据集
背景
浸润性导管癌(IDC)是所有乳腺癌中最常见的亚型。为了对整个组织样本进行侵袭性分级,病理学家通常专注于包含 IDC 的区域。因此,自动侵袭性分级的常见预处理步骤之一是划定整个组织切片中 IDC 的确切区域。
内容
原始数据集包含 162 张乳腺癌(BCa)标本的整个组织切片图像,扫描倍率为 40 倍。从中提取了 277,524 个大小为 50 x 50 的 patches(198,738 个 IDC 阴性,78,786 个 IDC 阳性)。每个 patch 的文件名格式为:u_xX_yY_classC.png —— 例如 10253_idx5_x1351_y1101_class0.png。其中,u 是患者 ID(10253_idx5),X 是该 patch 裁剪位置的 x 坐标,Y 是该 patch 裁剪位置的 y 坐标,C 表示类别,0 为非 IDC,1 为 IDC。
致谢
原始文件位于:http://gleason.case.edu/webdata/jpi-dl-tutorial/IDC_regular_ps50_idx5.zip
引用文献:https://www.ncbi.nlm.nih.gov/pubmed/27563488 和 http://spie.org/Publications/Proceedings/Paper/10.1117/12.2043872
启发
乳腺癌是女性中最常见的癌症形式,而浸润性导管癌(IDC)是乳腺癌中最常见的类型。准确识别和分类乳腺癌亚型是一项重要的临床任务,自动化方法可用于节省时间并减少错误。
相关文章:
【机器学习实战入门】基于深度学习的乳腺癌分类
什么是深度学习? 作为对机器学习的一种深入方法,深度学习受到了人类大脑和其生物神经网络的启发。它包括深层神经网络、递归神经网络、卷积神经网络和深度信念网络等架构,这些架构由多层组成,数据必须通过这些层才能最终产生输出。…...

Flowable 管理各业务流程:流程设计器 (获取流程模型 XML)、流程部署、启动流程、流程审批、流程挂起和激活、任务分配
文章目录 引言I 表结构主要表前缀及其用途核心表II 流程设计器(Flowable BPMN模型编辑器插件)Flowable-UIvue插件III 流程部署部署步骤例子:根据流程模型ID部署IV 启动流程启动步骤ACT_RE_PROCDEF:流程定义相关信息例子:根据流程 ID 启动流程V 流程审批审批步骤Flowable 审…...

Kafka 日志存储 — 日志索引
每个日志分段文件对应两个索引文件:偏移量索引文件用来建立消息偏移量到物理地址之间的映射;时间戳索引文件根据指定的时间戳来查找对应的偏移量信息。 1 日志索引 Kafka的索引文件以稀疏索引的方式构造消息的索引。它并不保证每个消息在索引文件中都有…...

【大模型】ChatGPT 高效处理图片技巧使用详解
目录 一、前言 二、ChatGPT 4 图片处理介绍 2.1 ChatGPT 4 图片处理概述 2.1.1 图像识别与分类 2.1.2 图像搜索 2.1.3 图像生成 2.1.4 多模态理解 2.1.5 细粒度图像识别 2.1.6 生成式图像任务处理 2.1.7 图像与文本互动 2.2 ChatGPT 4 图片处理应用场景 三、文生图操…...

OceanBase 社区年度之星专访:北控水务纪晓东,社区铁杆开发者
编者按:作为开源数据库,社区的发展和持续进步,来自于每一位贡献者的智慧与支持。2024年度,OceanBase社区特别设立了“年度之星”奖,以表彰和感谢在过去一年中,为社区发展作出突出贡献的朋友。 今日&#x…...
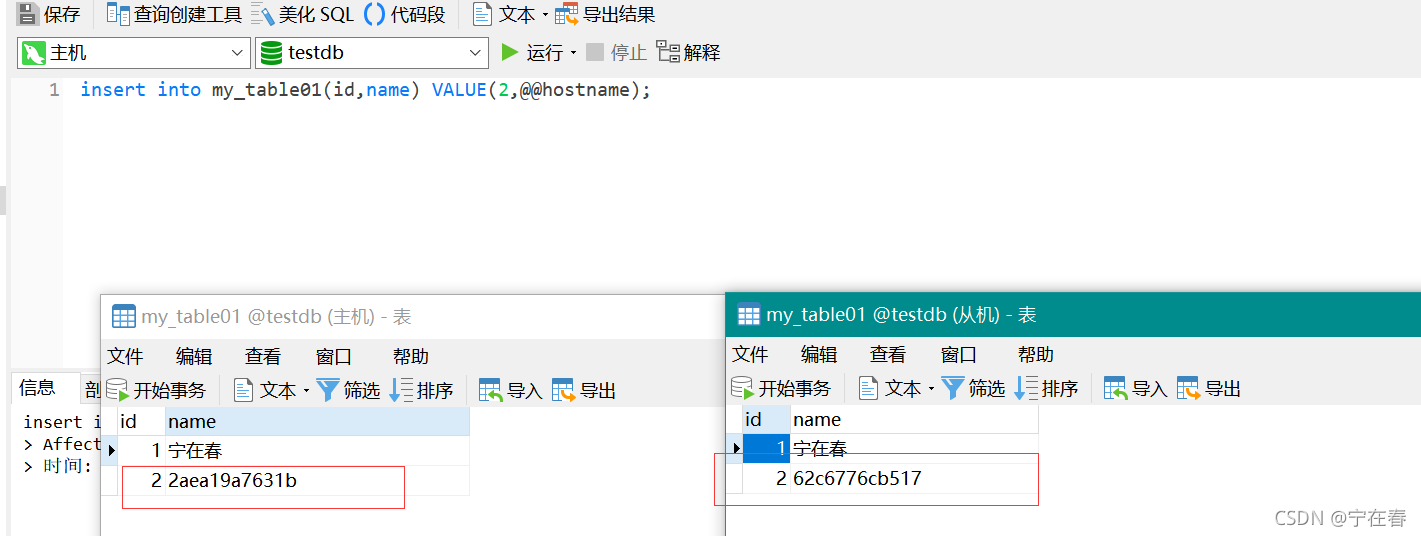
Docker 实现MySQL 主从复制
一、拉取镜像 docker pull mysql:5.7相关命令: 查看镜像:docker images 二、启动镜像 启动mysql01、02容器: docker run -d -p 3310:3306 -v /root/mysql/node-1/config:/etc/mysql/ -v /root/mysql/node-1/data:/var/lib/mysql -e MYS…...

农业农村大数据应用场景|珈和科技“数字乡村一张图”解决方案
近年来,珈和科技持续深耕农业领域,聚焦时空数据服务智慧农业。 珈和利用遥感大数据、云计算、移动互联网、物联网、人工智能等先进技术,搭建“天空地一体化”监测体系,并创新建设了150的全球领先算法模型,广泛应用于高…...

doris 2.1 Queries Acceleration-Hints 学习笔记
1 Hint Classification 1.1 Leading Hint:Specifies the join order according to the order provided in the leading hint. 1.2 Ordered Hint:A specific type of leading hint that specifies the join order as the original text sequence. 1.3 Distribute Hint:Speci…...

STM32 FreeRTOS 任务挂起和恢复---实验
实验目标 学会vTaskSuspend( )、vTaskResume( ) 任务挂起与恢复相关API函数使用: start_task:用来创建其他的三个任务。 task1:实现LED1每500ms闪烁一次。 task2:实现LED2每500ms闪烁一次。 task3:判断按键按下逻辑,KE…...

Ubuntu 24.04 LTS 通过 docker desktop 安装 seafile 搭建个人网盘
准备 Ubuntu 24.04 LTSUbuntu 空闲硬盘挂载Ubuntu 安装 Docker Desktop [我的Ubuntu服务器折腾集](https://blog.csdn.net/jh1513/article/details/145222679。 安装 seafile 参考资料 Docker安装 Seafile OnlyOffice 并配置OnlyOffice到Seafile,实现在线编辑…...

Open3D 最小二乘拟合平面(直接求解法)【2025最新版】
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 博客长期更新,本文最近更新时间为:2025年1月18日。 一、算法原理 平面方程的一般表达式为:...

【CC2640R2F】香瓜CC2640R2F之SPI读写W25Q80
本文最后修改时间:2022年01月08日 10:45 一、本节简介 本节以simple_peripheral工程为例,介绍如何使用SPI读写W25Q80(外部flash)。 二、实验平台 1)CC2640R2F平台 ①协议栈版本:CC2640R2 SDK v1.40.00.4…...

探秘Shortest与Stagehand:开启高效测试与自动化新篇
探秘Shortest与Stagehand:开启高效测试与自动化新篇 在数字化浪潮的推动下,网页自动化工具如同繁星般涌现,为众多行业带来了效率的变革。在这些工具中,Shortest和Stagehand凭借其出色的表现,成为了众多开发者、测试人…...

llama 3 笔记
0.简介 llama 3 是在 15 万亿个 Token 上预训练的语言模型,具有 8B 和 70B 两种参数规模,可以支持广泛的用户场景,在各种行业基准上取得了最先进的性能,并提供了一些新功能,包括改进的推理能力。 1.改进亮点 参数规模与模型架构:Llama 3提供了8B和70B两种参数规模的模…...

写作利器:如何用 PicGo + GitHub 图床提高创作效率
你好呀,欢迎来到 Dong雨 的技术小栈 🌱 在这里,我们一同探索代码的奥秘,感受技术的魅力 ✨。 👉 我的小世界:Dong雨 📌 分享我的学习旅程 🛠️ 提供贴心的实用工具 💡 记…...
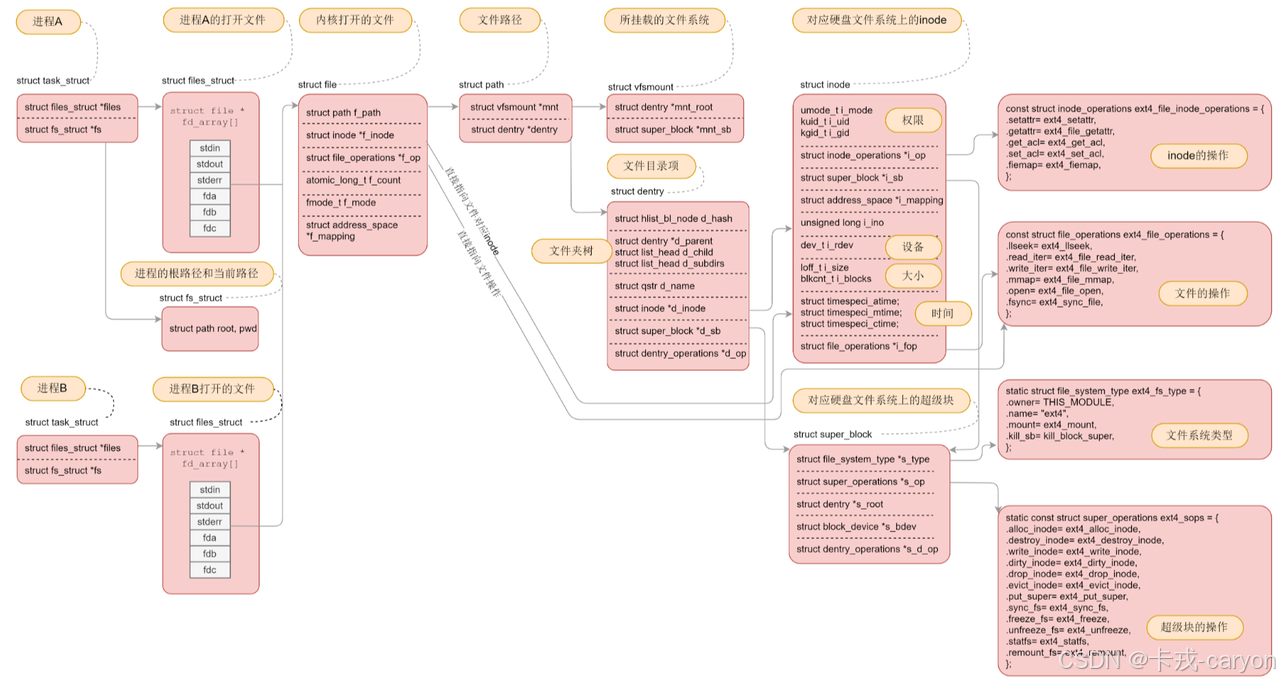
【文件篇】11.磁盘文件系统
上一篇博客中我们介绍到如果我们要访问文件首先需要打开这个文件,而文件是在磁盘上存储的,也就是说需要在磁盘上找到这个文件的路径。但是磁盘上有很多文件,这些文件都有自己的路径的,这些文件还有内容和属性,它们都是…...

嵌入式产品级-超小尺寸热成像相机(从0到1 硬件-软件-外壳)
Thermal_Imaging_Camera This is a small thermal imaging camera that includes everything from hardware and software. 小尺寸热成像相机-Pico-LVGL-RTOS 基于RP2040 Pico主控与RTOS,榨干双核性能实现LVGL和成图任务并行。ST7789驱动240280屏,CST8…...

三维扫描赋能文化:蔡司3D扫描仪让木质文化遗产焕发新生-沪敖3D
挪威文化历史博物馆在其修复工作中融入现代3D扫描技术,让数百年的历史焕发新生。 文化历史博物馆的工作 文化历史博物馆是奥斯陆大学的一个院系。凭借其在文化历史管理、研究和传播方面的丰富专业知识,该博物馆被誉为挪威博物馆研究领域的领先机构。馆…...
《自动驾驶与机器人中的SLAM技术》ch8:基于预积分和图优化的紧耦合 LIO 系统
目录 1 预积分 LIO 系统的经验 2 预积分图优化的顶点 3 预积分图优化的边 3.1 NDT 残差边(观测值维度为 3 维的单元边) 4 基于预积分和图优化 LIO 系统的实现 4.1 IMU 静止初始化 4.2 使用预积分预测 4.3 使用 IMU 预测位姿进行运动补偿 4.4 位姿配准部…...

Linux下PostgreSQL-12.0安装部署详细步骤
一、安装环境 postgresql-12.0 CentOS-7.6 注意:确认linux系统可以正常连接网络,因为在后面需要添加依赖包。 二、pg数据库安装包下载 下载地址:PostgreSQL: File Browser 选择要安装的版本进行下载: 三、安装依赖包 在要安…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...