通过视觉语言模型蒸馏进行 3D 形状零件分割
大家读完觉得有帮助记得关注和点赞!!!对应英文要求比较高,特此说明!
Abstract
This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major challenges in this task: the lack of 3D segmentation in invisible or undetected regions in the 2D projections, inconsistent 2D predictions by VLMs, and the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bi-directional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartNetE datasets, by more than 15% and 12% higher mIoU scores, respectively. The code for this work is available at https://github.com/ardianumam/PartDistill.
1Introduction
3D shape part segmentation is essential to various 3D vision applications, such as shape editing [23, 45], stylization [29], and augmentation [40]. Despite its significance, acquiring part annotations for 3D data, such as point clouds or mesh shapes, is labor-intensive and time-consuming.
Zero-shot learning [41, 8] generalizes a model to unseen categories without annotations and has been notably uplifted by recent advances in vision-language models (VLMs) [37, 22, 46, 21]. By learning on large-scale image-text data pairs, VLMs show promising generalization abilities on various 2D recognition tasks. Recent research efforts [48, 52, 24, 1] have been made to utilize VLMs for zero-shot 3D part segmentation, where a 3D shape is projected into multi-view 2D images, and a VLM is applied to these images for 2D prediction acquisition. Specifically, PointCLIP [48] and PointCLIPv2 [52] produce 3D point-wise semantic segmentation by averaging their corresponding 2D pixel-wise predictions. Meanwhile, PartSLIP [24] and SATR [1] present a designated weighting mechanism to aggregate multi-view bounding box predictions.

Figure 1: We present a distillation method that carries out zero-shot 3D shape part segmentation with a 2D vision-language model. After projecting an input 3D point cloud into multi-view 2D images, the 2D teacher (2D-T) and the 3D student (3D-S) networks are applied to the 2D images and 3D point cloud, respectively. Instead of direct transfer, our method carries bi-directional distillations, including forward and backward distillations, and yields better 3D part segmentation than the existing method.
The key step of zero-shot 3D part segmentation with 2D VLMs, e.g., [48, 52, 24, 1], lies in the transfer from 2D pixel-wise or bounding-box-wise predictions to 3D point segmentation. This step is challenging due to three major issues. First (𝓘𝟏), some 3D regions lack corresponding 2D predictions in multi-view images, which are caused by occlusion or not being covered by any bounding boxes, illustrated with black and gray points, respectively, in Fig. 1. This issue is considered a limitation in the previous work [48, 52, 24, 1]. Second (𝓘𝟐), there exists potential inconsistency among 2D predictions in multi-view images caused by inaccurate VLM predictions. Third (𝓘𝟑), existing work [48, 52, 24, 1] directly transfers 2D predictions to segmentation of a single 3D shape. The 2D predictions yielded based on appearance features are not optimal for 3D geometric shape segmentation, while geometric evidence given across different 3D shapes is not explored.
To alleviate the three issues 𝓘𝟏∼𝓘𝟑, unlike existing methods [48, 52, 24, 1] directly transferring 2D predictions to 3D segmentation, we propose a cross-modal distillation framework with a teacher-student model. Specifically, a VLM is utilized as a 2D teacher network, accepting multi-view images of a single 3D shape. The VLM is pre-trained on large-scale image-text pairs and can exploit appearance features to make 2D predictions. The student network is developed based on a point cloud backbone. It is derived from multiple, unlabeled 3D shapes and can extract point-specific geometric features. The proposed distillation method, PartDistill, leverages the strengths of both networks, hence improving zero-shot 3D part segmentation.
The student network learns from not only the 2D teacher network but also 3D shapes. It can extract point-wise features and segment 3D regions uncovered by 2D predictions, hence tackling issue 𝓘𝟏. As a distillation-based method, PartDistill tolerates inconsistent predictions between the teacher and student networks, which alleviates issue 𝓘𝟐 of negative transfer caused by wrong VLM predictions. The student network considers both appearance and geometric features. Thus, it can better predict 3D geometric data and mitigate issue 𝓘𝟑. As shown in Fig. 1, the student network can correctly predict the undetected arm of the chair (see the black arrows) by learning from other chairs.
PartDistill carries out a bi-directional distillation. It first forward distills the 2D knowledge to the student network. We observe that after the student integrates the 2D knowledge, we can jointly refer both teacher and student knowledge to perform backward distillation which re-scores the 2D knowledge based on its quality. Those of low quality will be suppressed with lower scores, such as from 0.6 to 0.1 for the falsely detected arm box in Fig. 1, and vice versa. Finally, this re-scored knowledge is utilized by the student network to seek better 3D segmentation.
The main contributions of this work are summarized as follows. First, we introduce PartDistill, a cross-modal distillation framework that transfers 2D knowledge from VLMs to facilitate 3D part segmentation. PartDistill addresses three identified issues present in existing methods and generalizes to both VLM with bounding-box predictions (B-VLM) and pixel-wise predictions (P-VLM). Second, we propose a bi-directional distillation, which involves enhancing the quality of 2D knowledge and subsequently improving the 3D predictions. Third, PartDistill can leverage existing generative models [31, 33] to enrich knowledge sources for distillation. Extensive experiments demonstrate that PartDistill surpasses existing methods by substantial margins on widely used benchmark datasets, ShapeNetPart [44] and PartNetE [24], with more than 15% and 12% higher mIoU scores, respectively. PartDistill consistently outperforms competing methods in zero-shot and few-shot scenarios on 3D data in point clouds or mesh shapes.

Figure 2:Overview of the proposed method. (a) The overall pipeline where the knowledge extracted from a vision-language model (VLM) is distilled to carry out 3D shape part segmentation by teaching a 3D student network. Within the pipeline, backward distillation is introduced to re-score the teacher’s knowledge based on its quality and subsequently improve the final 3D part prediction. (b) (c) Knowledge is extracted by back-projection when we adopt (b) a bounding-box VLM (B-VLM) or (c) a pixel-wise VLM (P-VLM), where &Γ and ℂ denote 2D-to-3D back-projection and connected component labeling [3], respectively.
2Related Work
Vision-language models.
Based on learning granularity, vision-language models (VLMs) can be grouped into three categories, including the image-level [37, 15], pixel-level [21, 27, 53], and object-level [22, 46, 25] categories. The second and the third categories make pixel-level and bounding box predictions, respectively, while the first category produces image-level predictions. Recent research efforts on VLMs have been made for cross-level predictions. For example, pixel-level predictions can be derived from an image-level VLM via up-sampling the 2D features into the image dimensions, as shown in PointCLIPv2 [52]. In this work, we propose a cross-modal distillation framework that learns and transfers knowledge from a VLM in the 2D domain to 3D shape part segmentation.
3D part segmentation using vision-language models.
State-of-the-art zero-shot 3D part segmentation [24, 52, 1] is developed by utilizing a VLM and transferring its knowledge in the 2D domain to the 3D space. The pioneering work PointCLIP [48] utilizes CLIP [37]. PointCLIPv2 [52] extends PointCLIP by making the projected multi-view images more realistic and proposing LLM-assisted text prompts [4], hence producing more reliable CLIP outputs for 3D part segmentation.
Both PointCLIP and PointCLIPv2 rely on individual pixel predictions in 2D views to get the predictions of the corresponding 3D points, but individual pixel predictions are less unreliable. PartSLIP [24] suggests to extract superpoints [20] from the input point cloud. Therefore, 3D segmentation is estimated for each superpoint by referring to a set of relevant pixels in 2D views. PartSLIP uses GLIP [22] to output bounding boxes and further proposes a weighting mechanism to aggregate multi-view bounding box predictions to yield 3D superpoint predictions. SATR [1] shares a similar idea with PartSLIP but handles 3D mesh shapes instead of point clouds.
Existing methods [24, 52, 48, 1] directly transfer VLM predictions from 2D images into 3D spaces and pose three issues: (𝓘𝟏) uncovered 3D points, (𝓘𝟐) negative transfer, and (𝓘𝟑) cross-modality predictions, as discussed before. We present a distillation-based method to address all three issues and make substantial performance improvements.
2D to 3D distillation.
Seminal work of knowledge distillation [5, 14] aims at transferring knowledge from a large model to a small one. Subsequent research efforts [39, 28, 50, 26, 43] adopt this idea of transferring knowledge from a 2D model for 3D understanding. However, these methods require further fine-tuning with labeled data. OpenScene [34] and CLIP2Scene [7] require no fine-tuning and share a similar concept with our method of distilling VLMs for 3D understanding, with ours designed for part segmentation and theirs for indoor/outdoor scene segmentation. The major difference is that our method can enhance the knowledge sources in the 2D modality via the proposed backward distillation. Moreover, our method is generalizable to both P-VLM (pixel-wise VLM) and B-VLM (bounding-box VLM), while their methods are only applicable to P-VLM.
3Proposed Method
3.1Overview
Given a set of 3D shapes, this work aims to segment each one into R semantic parts without training with any part annotations. To this end, we propose a cross-modal bi-directional distillation framework, PartDistill, which transfers 2D knowledge from a VLM to facilitate 3D shape part segmentation. As illustrated in Fig. 2, our framework takes triplet data as input, including the point cloud of the shape with N 3D points, multi-view rendered images from the shape in V different poses, and R text prompts with each describing the target semantic parts within the 3D shapes.
For the 2D modality, the V multi-view images and the text prompts are fed into a Bounding-box VLM (B-VLM) or Pixel-wise VLM (P-VLM). For each view v, a B-VLM produces a set of bounding boxes, Bv={bi}i=1β while a P-VLM generates pixel-wise predictions Sv. We then perform knowledge extraction (Sec 3.2) for each Bv or Sv; Namely, we transfer the 2D predictions into the 3D space through back-projection for a B-VLM or connected-component labeling [3] followed by back-projection for a P-VLM, as shown in Fig. 2 (b) and Fig. 2 (c), respectively. Subsequently, a set of D teacher knowledge units, 𝒦={k}d=1D={Yd,Md}d=1D, is obtained by aggregating from all V multi-view images. Each unit d comprises point-wise part probabilities, Yd∈ℝN×R, from the teacher VLM network, accompanied with a mask, Md∈{0,1}N, identifying the points included in this knowledge unit.
For the 3D modality, the point cloud is passed into the 3D student network with a 3D encoder and a distillation head, producing point-wise part predictions, Y~∈ℝN×R. With the proposed bi-directional distillation framework, we first forward distill teacher’s 2D knowledge by aligning Y~ with 𝒦 via minimizing the proposed loss, ℒdistill, specified in Sec 3.2. The 3D student network integrates 2D knowledge from the teacher through optimization. The integrated student knowledge Y~′ and the teacher knowledge 𝒦 are then jointly referred to perform backward distillation from 3D to 2D, detailed in Sec. 3.3, which re-scores each knowledge unit kd based on its qualities, as shown in Fig. 2. Finally, the re-scored knowledge 𝒦′ is used to refine the student knowledge to get final part segmentation predictions Y~f by assigning each point to the part with the highest probability.
3.2Forward distillation: 2D to 3D
Our method extracts the teacher’s knowledge in the 2D modality and distills it in the 3D space. In the 2D modality, V multi-view images {Iv∈ℝH×W}v=1V are rendered from the 3D shape, e.g., using the projection method in [52]. These V multi-view images together with the text prompts T of R parts are passed to the VLM to get the knowledge in 2D spaces. For a B-VLM, a set of β bounding boxes, Bv={bi}i=1β, is obtained from the v-th image, with bi∈ℝ4+R encoding the box coordinates and the probabilities of the R parts. For a P-VLM, a pixel-wise prediction map Sv∈ℝH×W×R is acquired from the v-th image. We apply knowledge extraction to each Bv and each Sv to obtain a readily distillable knowledge 𝒦 in the 3D space, as illustrated in Fig. 2 (b) and Fig. 2 (c), respectively.
For a B-VLM, bounding boxes can directly be treated as the teacher knowledge. For a P-VLM, knowledge extraction starts by applying connected-component labeling [3] to Sv to get a set of ρ segmentation components, {si∈ℝH×W×R}i=1ρ, indicating if the r-th part is with the highest probability in each pixel. We summarize the process when applying a VLM to a rendered image and the part text prompts as
| VLM(Iv,T)={Bv={bi}i=1β,for B-VLM,ℂ(Sv)={si}i=1ρ,for P-VLM, | (1) |
where ℂ denotes connected-component labeling.
We then back-project each box bi or each prediction map si to the 3D space, i.e.,
| ki=(Yi,Mi)={Γ(bi),for B-VLM,Γ(si),for P-VLM, | (2) |
where Γ denotes the back-projection operation with the camera parameters [49] used for multi-view image rendering, Yi∈ℝN×R is the point-specific part probabilities, and Mi∈{0,1}N is the mask indicating which 3D points are covered by bi or si in the 2D space. The pair (Yi,Mi) yields a knowledge unit, ki, upon which the knowledge re-scoring is performed in the backward distillation.
For the 3D modality, a 3D encoder, e.g., Point-M2AE [47], is applied to the point cloud and obtains per-point features, O∈ℝN×E, capturing local and global geometrical information. We then estimate point-wise part prediction, Y~∈RN×R, by feeding the point features O into the distillation head. The cross-modal distillation is performed by teaching the student network to align the part probability from the 3D modality Y~ to their 2D counterparts Y via minimizing our designated distillation loss.
Distillation loss.
Via Eq. 1 and Eq. 2, we assume that D knowledge units, 𝒦={kd}d=1D={Yd,Md}d=1D, are obtained from the multi-view images. The knowledge 𝒦 exploits 2D appearance features and is incomplete as several 3D points are not covered by any 2D predictions, i.e., issue 𝓘𝟏. To distill this incomplete knowledge, we utilize a masked cross-entropy loss defined as
| ℒdistill=−∑d=1D1|Md|∑n=1N∑r=1RMndCndZn,rdlog(Y~n,r), | (3) |
where Cnd=max𝑟(Ynd(r)) is the confidence score of kd on point n. Zn,rd takes value 1 if part r receives the highest probability on kd, and 0 otherwise. |Md| is the area covered by the mask Md.
By minimizing Eq. 3, we teach the student network to align its prediction Y~ to the distilled prediction Y by considering the points covered by the mask and using the confidence scores as weights. Despite learning from incomplete knowledge, the student network extracts point features that capture geometrical information of the shape, thus enabling it to reasonably segment the points that are not covered by 2D predictions, hence addressing issue 𝓘𝟏. This can be regarded as interpolating the learned part probability in the feature spaces by the distillation head.
As a distillation-based method, our method allows partial inconsistency among the extracted knowledge 𝒦={kd}d=1D caused by inaccurate VLM predictions, thereby alleviating issue 𝓘𝟐 of negative transfer. In our method, the teacher network works on 2D appearance features, while the student network extracts 3D geometric features. After distillation via Eq. 3, the student network can exploit both appearance and geometric features from multiple shapes, hence mitigating issue 𝓘𝟑 of cross-modal transfer. It is worth noting that unlike the conventional teacher-student models [14, 11, 13] which solely establish a one-to-one correspondence, we further re-score each knowledge unit kd based on its quality (Sec. 3.3), and improve distillation by suppressing low-quality knowledge units.
3.3Backward distillation: 3D to 2D
In Eq. 3, we consider all knowledge units {kd}d=1D, weighted by their confidence scores. However, due to the potential VLM mispredictions, not all knowledge units are reliable. Hence, we refine the knowledge units by assigning higher scores to those of high quality and suppressing the low-quality ones. We observe that once the student network has thoroughly integrated the knowledge from the teacher, we can jointly refer both teacher and integrated student knowledge Y~′ to achieve the goal, by re-scoring the confidence score Cd to Cbdd as:
| Cbdd=|Md(argmax(Yd)⇔argmax(Y~′))||Md|, | (4) |
where ⇔ denotes the element-wise equality (comparison) operation. In this way, each knowledge unit kd is re-scored: Those with high consensus between teacher 𝒦 and integrated student knowledge Y~′ have higher scores, such as those on the chair legs shown in Fig. 3, and those with low consensus are suppressed by the reduced scores, such as those on the chair arm (B-VLM) and back (P-VLM) in Fig. 3. Note that for simplicity, we only display two scores in each shape of Fig. 3 and show the average pixel-wise scores in P-VLM. To justify that the student network has thoroughly integrated the teacher’s knowledge, from initial knowledge Y~ to integrated knowledge Y~′, we track the moving average of the loss value for every epoch and see if the value in a subsequent epoch is lower than a specified threshold τ. Afterward, the student network continues to learn with the re-scored knowledge 𝒦′ by minimizing the loss in Eq. 3 with C being replaced by Cbd, and produces the final part segmentation predictions Y~f.

Figure 3:Given the VLM output of view v, Bv or Sv, we display the confidence scores before (C) and after (Cbd) performing backward distillation via Eq. 4, with Y and M obtained via Eq. 2. With backward distillation, inaccurate VLM predictions have lower scores, such as the arm box in B-VLM with the score reduced from 0.7 to 0.1, and vice versa.
3.4Test-time alignment
In general, our method performs the alignment with a shape collection before the student network is utilized to carry the 3D shape part segmentation. If such a pre-alignment is not preferred, we provide a special case of our method, test-time alignment (TTA), where the alignment is performed for every single shape in test time. To maintain the practicability, TTA needs to achieve a near-instantaneous completion. To that end, TTA employs a readily used 3D encoder, e.g., pre-trained Point-M2AE [47], freezes its weights, and only updates the learnable parameters in the distillation head, which significantly fastens the TTA completion.
3.5Implementation Details
The proposed framework is implemented in PyTorch [32] and is optimized for 25 epochs via Adam optimizer [19] with a learning rate and batch size of 0.001 and 16, respectively. Unless further specified, the student network employs Point-M2AE [47] pre-trained in a self-supervised way on the ShapeNet55 dataset [6] as the 3D extractor, freezes its weights, and only updates the learnable parameters in the distillation head. A multi-layer perceptron consisting of 4 layers, with ReLU activation [2], is adopted for the distillation head. To fairly compare with the competing methods [48, 52, 24, 1], we follow their respective settings, including the used text prompts and the 2D rendering. Their methods render each shape into 10 multi-view images, either from a sparse point cloud [48, 52], a dense point cloud [24], or a mesh shape [1]. Lastly, we follow [18, 38] to specify a small threshold value, τ=0.01 in our backward distillation, and apply class-balance weighting [9] during the alignment, based on the VLM predictions in the zero-shot setting, with additional few-shot labels in the few-shot setting.
Table 1:Zero-shot segmentation on the ShapeNetPart dataset, reported in mIoU (%).*
| VLM | Data type | Method | Airplane | Bag | Cap | Chair | Earphone | Guitar | Knife | Laptop | Mug | Table | Overall |
| CLIP [37] | point cloud | PointCLIP [48] | 22.0 | 44.8 | 13.4 | 18.7 | 28.3 | 22.7 | 24.8 | 22.9 | 48.6 | 45.4 | 31.0 |
| PointCLIPv2 [52] | 35.7 | 53.3 | 53.1 | 51.9 | 48.1 | 59.1 | 66.7 | 61.8 | 45.5 | 49.8 | 48.4 | ||
| OpenScene [34] | 34.4 | 63.8 | 56.1 | 59.8 | 62.6 | 69.3 | 70.1 | 65.4 | 51.0 | 60.4 | 52.9 | ||
| Ours (TTA) | 37.5 | 62.6 | 55.5 | 56.4 | 55.6 | 71.7 | 76.9 | 67.4 | 53.5 | 62.9 | 53.8 | ||
| Ours (Pre) | 40.6 | 75.6 | 67.2 | 65.0 | 66.3 | 85.8 | 79.8 | 92.6 | 83.1 | 68.7 | 63.9 | ||
| GLIP [22] | point cloud | Ours (TTA) | 57.3 | 62.7 | 56.2 | 74.2 | 45.8 | 60.6 | 78.5 | 85.7 | 82.5 | 62.9 | 54.7 |
| Ours (Pre) | 69.3 | 70.1 | 67.9 | 86.5 | 51.2 | 76.8 | 85.7 | 91.9 | 85.6 | 79.6 | 64.1 | ||
| mesh | SATR [1] | 32.2 | 32.1 | 21.8 | 25.2 | 19.4 | 37.7 | 40.1 | 50.4 | 76.4 | 22.4 | 32.3 | |
| Ours (TTA) | 53.2 | 61.8 | 44.9 | 66.4 | 43.0 | 50.7 | 66.3 | 68.3 | 83.9 | 58.8 | 49.5 | ||
| Ours (Pre) | 64.8 | 64.4 | 51.0 | 67.4 | 48.3 | 64.8 | 70.0 | 83.1 | 86.5 | 79.3 | 56.3 |
*Results for other categories, including those of Table 2 and Table 3, can be seen in the supplementary material.
Table 2:Zero-shot segmentation on the PartNetE dataset, reported in mIoU (%).
| VLM | Data type | Method | Bottle | Cart | Chair | Display | Kettle | Knife | Lamp | Oven | Suitcase | Table | Overall |
| GLIP [22] | point cloud | PartSLIP [24] | 76.3 | 87.7 | 60.7 | 43.8 | 20.8 | 46.8 | 37.1 | 33.0 | 40.2 | 47.7 | 27.3 |
| Ours (TTA) | 77.4 | 88.5 | 74.1 | 50.5 | 24.2 | 59.2 | 58.8 | 34.2 | 43.2 | 50.2 | 39.9 |
4Experiments
4.1Dataset and evaluation metric
We evaluate the effectiveness of our method on two main benchmark datasets, ShapeNetPart [44] and PartNetE [24]. While ShapeNetPart dataset contains 16 categories with a total of 31,963 shapes, PartNetE contains 2,266 shapes, covering 45 categories. The mean intersection over union (mIoU) [30] is adopted to evaluate the segmentation results on the test-set data, measured against the ground truth label.
4.2Zero-shot segmentation
To compare with the competing methods [48, 52, 1, 24], we adopt each of their settings and report their mIoU performances from their respective papers. Specifically, for P-VLM, we follow PointCLIP [48] and PointCLIPv2 [52] to utilize CLIP [37] with ViT-B/32 [10] backbone and use their pipeline to obtain the pixel-wise predictions from CLIP. For B-VLM, a GLIP-Large model [22] is employed in our method to compare with PartSLIP and SATR which also use the same model. While most competing methods report their performances on the ShapeNetPart dataset, PartSLIP evaluates its method on the PartNetE dataset. In addition, we compare with OpenScene [34] by extending it for 3D part segmentation and use the same Point-M2AE [47] backbone and VLM CLIP for a fair comparison.
Accordingly, we carry out the comparison separately to ensure fairness, based on the employed VLM model and the shape data type, i.e., point cloud or mesh data, as shown in Tables 1 and 2. In Table 1, we provide two versions of our method, including test-time alignment (TTA) and pre-alignment (Pre) with a collection of shapes from the train-set data. Note that in the Pre version, our method does not use any labels (only unlabeled shape data are utilized).
First, we compare our method to PointCLIP and PointCLIPv2 (both utilize CLIP) on the zero-shot segmentation for the ShapeNetPart dataset, as can be seen in the first part of Table 1. It is evident that our method for both TTA and pre-alignment versions achieves substantial improvements in all categories. For the overall mIoU, calculated by averaging the mIoUs from all categories, our method attains 5.4% and 15.5% higher mIoU for TTA and pre-alignment versions, respectively, compared to the best mIoU from the other methods. Such results reveal that our method which simultaneously exploits appearance and geometric features can better aggregate the 2D predictions for 3D part segmentation than directly averaging the corresponding 2D predictions as in the competing methods, where geometric evidence is not explored. We further compare with OpenScene [34] under the same setting as ours (Pre) and our method substantially outperforms it. One major reason is that our method can handle the inconsistency of VLM predictions (issue 𝓘2) better by backward distillation.
Next, as shown in the last three rows of Table 1, we compare our method to SATR [1] that works on mesh data shapes. To obtain the mesh face predictions, we propagate the point predictions via a nearest neighbors approach as in [17], where each face is voted from its five nearest points. Our method achieves 17.2% and 24% higher overall mIoU than SATR for TTA and pre-alignment versions, respectively. Then, we compare our method with PartSLIP [24] in Table 2 wherein only results from TTA are provided since the PartNetE dataset does not provide train-set data. One can see that our method consistently obtains better segmentations, with 12.6% higher overall mIoU than PartSLIP.
In PartSLIP and SATR, as GLIP is utilized, the uncovered 3D regions (issue 𝓘𝟏) could be intensified by possible undetected areas, and the negative transfer (issue 𝓘𝟐) may also be escalated due to semantic leaking, where the box predictions cover pixels from other semantics. On the other hand, our method can better alleviate these issues, thereby achieving substantially higher mIoU scores. In our method, the pre-alignment version achieves better segmentation results than TTA. This is expected since in the pre-alignment version, the student network can distill the knowledge from a collection of shapes, instead of individual shape.

Figure 4:Visualization of the zero-shot segmentation results, drawn in different colors, on the ShapeNetPart dataset. We render PartSLIP results on the ShapeNetPart data to have the same visualization of shape inputs. While occluded and undetected regions (issue 𝓘𝟏) are shown with black and gray colors, respectively, the blue and red arrows highlight several cases of issues 𝓘𝟐 and 𝓘𝟑.
Besides foregoing quantitative comparisons, a qualitative comparison of the segmentation results is presented in Fig. 4. It is readily observed that the competing methods suffer from the lack of 3D segmentation for the uncovered regions (issue 𝓘𝟏) caused by either occlusion or not being covered by any bounding box, drawn with black and gray colors, respectively. Moreover, these methods may also encounter negative transfers caused by inaccurate VLM outputs (issue 𝓘𝟐), such as those pointed by blue arrows, with notably degraded outcomes in SATR due to semantic leaking. Nonetheless, our method performs cross-modal distillation and alleviates these two issues, as can be seen in Fig. 4. In addition, due to a direct transfer of 2D predictions to 3D space which relies on each independent shape as in the competing methods, erroneous 2D predictions will just remain as incorrect 3D segmentation (issue 𝓘𝟑), such as the missed detected chair arms and guitar heads pointed by red arrows. Our method also addresses this issue, by exploiting geometrical features across multiple shapes.
Table 3:Few-shot segmentation on the PartNetE dataset, reported in mIoU (%).
| Method | Bottle | Cart | Chair | Display | Kettle | Knife | Lamp | Oven | Suitcase | Table | Overall | |
| Non-VLM-based | PointNet++ [35] | 27.0 | 11.6 | 42.2 | 30.2 | 28.6 | 22.2 | 10.5 | 19.4 | 3.3 | 7.3 | 20.4 |
| PointNext [36] | 67.6 | 47.7 | 65.1 | 53.7 | 60.6 | 59.7 | 55.4 | 36.8 | 14.5 | 22.1 | 40.6 | |
| ACD [12] | 22.4 | 31.5 | 39.0 | 29.2 | 40.2 | 39.6 | 13.7 | 8.9 | 13.2 | 13.5 | 23.2 | |
| Prototype [51] | 60.1 | 36.8 | 70.8 | 67.3 | 62.7 | 50.4 | 38.2 | 36.5 | 35.5 | 25.7 | 44.3 | |
| Point-M2AE [47] | 72.4 | 74.5 | 83.4 | 74.3 | 64.3 | 68.0 | 57.6 | 53.3 | 57.5 | 33.6 | 56.4 | |
| VLM-based(GLIP [22]) | PartSLIP [24] | 83.4 | 88.1 | 85.3 | 84.8 | 77.0 | 65.2 | 60.0 | 73.5 | 70.4 | 42.4 | 59.4 |
| Ours | 84.6 | 90.1 | 88.4 | 87.4 | 78.6 | 71.4 | 69.2 | 72.8 | 73.4 | 63.3 | 65.9 | |
4.3Few-shot segmentation
We further demonstrate the effectiveness of our method in a few-shot scenario by following the setting used in PartSLIP [24]. Specifically, we employ the fine-tuned GLIP model [22] provided by PartSLIP via 8-shot labeled shapes of the PartNetE dataset [44] for each category. In addition to the alignment via Eq. 3, we ask the student network to learn parameters that minimize both Eq. 3 and a standard cross-entropy loss for segmentation on the 8 labeled shapes.
As shown in Table 3, the methods dedicated to few-shot 3D segmentation, ACD [12] and Prototype [51], are adapted to PointNet++ [51] and PointNext [36] backbones, respectively, and can improve the performances (on average) of these backbones. PartSLIP, on the other hand, leverages multi-view GLIP predictions for 3D segmentation and further improves the mIoU, but there are still substantial performance gaps compared to our method which distills the GLIP predictions instead. We also present the results from fine-tuning Point-M2AE with the few-shot labels, which shows lower performances than ours, highlighting the significant contribution of our distillation framework. For more qualitative results, see the supplementary materials.
4.4Leveraging generated data
Since only unlabeled 3D shape data are required for our method to perform cross-modal distillation, existing generative models [31, 33] can facilitate an effortless generation of 3D shapes, and the generated data can be smoothly incorporated into our method. Specifically, we first adopt DiT-3D [31] which is pre-trained on the ShapeNet55 dataset [6] to generate point clouds of shapes, 500 shapes for each category, and further employ SAP [33] to transform the generated point clouds into mesh shapes. These generated mesh shapes can then be utilized in our method for distillation. Table 4 shows the results evaluated on the test-set data of ShapeNetPart [44] and COSEG [42] datasets for several shape categories, using GLIP as the VLM.
One can see that with distilling from the generated alone, our method already achieves competitive results on the ShapeNetPart dataset compared to distilling from the train-set data. Since the generated data via DiT-3D is pre-trained on the ShapeNet55 dataset which contains the ShapeNetPart data, we also evaluate its performance on the COSEG dataset to show that such results can be well transferred to shapes from another dataset. Finally, Table 4 (the last row) reveals that using generated data as a supplementary knowledge source can further increase the mIoU performance. Such results suggest that if a collection of shapes is available, generated data can be employed as supplementary knowledge sources, which can improve the performance. On the other hand, if a collection of shapes does not exist, generative models can be employed for shape creation and subsequently used in our method as the knowledge source.
4.5Ablation studies
Proposed components.
We perform ablation studies on the proposed components, and the mIoU scores in 2D11Calculated between the VLM predictions and their corresponding 2D ground truths projected from 3D, and weighted by the confidence scores. See supplementary material for the details. and 3D spaces on three categories of the ShapeNetPart dataset are shown in (1) to (9) of Table 5. In (1), only GLIP box predictions are utilized to get 3D segmentations, i.e., part labels are assigned by voting from all visible points within the multi-view box predictions. These numbers serve as baselines and are subject to issues 𝓘𝟏∼𝓘𝟑. In (2) and (3), 3D segmentations are achieved via forward distillation from the GLIP predictions to the student network using Eq. 3, for test-time alignment (TTA) and pre-alignment (Pre) versions, resulting in significant improvements compared to the baselines, with more than 10% and 14% higher mIoUs, respectively. Such results demonstrate that the proposed cross-modal distillation can better utilize the 2D multi-view predictions for 3D part segmentation, alleviating 𝓘𝟏∼𝓘𝟑.
Table 4:Segmentation mIoU (%) by leveraging generated data.
| Distilled data | ShapeNetPart [44] | COSEG [42] | |||
| Airplane | Chair | Guitar | Chair | Guitar | |
| Train-set (baseline) | 69.3 | 86.2 | 76.8 | 96.4 | 68.0 |
| Gen. data | 69.0 | 85.3 | 75.6 | 96.1 | 67.5 |
| Gen. data & train-set | 70.8 | 88.4 | 78.3 | 97.4 | 70.2 |
Table 5:Ablation study on the proposed method.
| No | VLM | Pre | BD | Studentnetwork | Airplane | Chair | Knife | |||
| 2D | 3D | 2D | 3D | 2D | 3D | |||||
| (1) | GLIP[22] | 42.8 | 40.2 | 60.2 | 60.1 | 53.6 | 57.2 | |||
| (2) | ✓ | 42.8 | 56.2 | 60.2 | 73.5 | 53.6 | 77.6 | |||
| (3) | ✓ | ✓ | 42.8 | 64.3 | 60.2 | 84.2 | 53.6 | 84.5 | ||
| (4) | ✓ | ✓ | 44.3 | 57.3 | 61.7 | 74.2 | 54.8 | 78.5 | ||
| (5) | ✓ | ✓ | ✓ | 48.2 | 69.3 | 63.2 | 86.5 | 55.0 | 85.7 | |
| (6) | ✓ | ✓ | exclude 𝓘𝟏 | 48.2 | 62.5 | 63.2 | 80.4 | 55.0 | 81.2 | |
| (7) | ✓ | ✓ | w/o pretrain | 48.2 | 69.1 | 63.2 | 86.7 | 55.0 | 85.3 | |
| (8) | CLIP[37] | ✓ | ✓ | 34.6 | 38.4 | 50.4 | 63.6 | 66.8 | 77.4 | |
| (9) | ✓ | ✓ | ✓ | 37.8 | 40.6 | 54.2 | 65.0 | 68.4 | 78.9 | |
We further add backward distillation (BD) in (4) and (5), which substantially improves the knowledge source in 2D, e.g., from 42.8% to 48.2% for the airplane category in the pre-alignment version, and subsequently enhances the 3D segmentation. We observe a higher impact (improvement) on the pre-alignment compared to TTA versions, i.e., in (4) and (5), as the student network of the former can better integrate the knowledge from a collection of shapes. A similar trend of improvement can be observed for a similar ablation performed with CLIP [37] used as the VLM (in (8) and (9)).
In (6), we exclude our method’s predictions for those uncovered points to simulate issue 𝓘𝟏, and the reduced mIoUs compared to (5), e.g., from 86.5% to 80.4% for the chair category, reveal that our method can effectively alleviate issue 𝓘𝟏. Finally, instead of using pre-trained weights of Point-M2AE [47] and freezing them as the 3D decoder as in (5), we initialize these weights (by default PyTorch [32] initialization) and set them to be learnable as in (7). Both settings produce comparable results (within 0.4%). The main purpose of using the pre-trained weights and freezing them is for faster convergence, especially for the test-time alignment purpose. Please refer to the supplementary material for the comparison of convergence curves.
Number of views.
We render V=10 multi-view images for each shape input in our main experiment, and Fig. 5 (left) shows the mIoU scores with different values of V. A substantial drop is observed when utilizing V<6, and small increases are obtained when a larger V is used.
Various shape types for 2D multi-view rendering.
We render 10 multi-view images from various shape data types, i.e., (i) gray mesh, (ii) colored mesh, (iii) dense colored point cloud (∼300k points) as used in PartSLIP [24], and (iv) sparse gray point cloud (2,048 points) using PyTroch3D [16] and the rendering method in [52] to render (i)-(iii) and (iv), respectively. Fig. 5 (right) summarizes such results on the ShapeNetPart dataset, with GLIP used as the VLM. Note that the first three shape types produce comparable mIoUs with slightly higher scores when colored mesh or dense colored point cloud is utilized. When sparse gray point cloud data type is used, a mild mIoU decrease is observed. Please refer to the supplementary material to see more results for (i)-(iv).

Figure 5:Ablation study on number of views and various shape types for 2D multiview rendering on the ShapeNetPart dataset.
Limitation.
The main limitation of our method is that the segmentation results are impacted by the quality of the VLM predictions, where VLMs are generally pre-trained to recognize object- or sample-level categories (not part-level of object categories). For instance, GLIP can satisfactorily locate part semantics for the chair category but with lower qualities for the earphone category, while CLIP can favorably locate part semantics for the earphone category but with less favorable results for the airplane category. Hence, exploiting multiple VLMs can be a potential future work. Nonetheless, the proposed method which currently employs a single VLM model can already boost the segmentation results significantly compared to the existing methods.
5Conclusion
We present a cross-modal distillation framework that transfers 2D knowledge from a vision-language model (VLM) to facilitate 3D shape part segmentation, which generalizes well to both VLM with bounding-box and pixel-wise predictions. In the proposed method, backward distillation is introduced to enhance the quality of 2D predictions and subsequently improve the 3D segmentation. The proposed approach can also leverage existing generative models for shape creation and can be smoothly incorporated into the method for distillation. With extensive experiments, the proposed method is compared with existing methods on widely used benchmark datasets, including ShapeNetPart and PartNetE, and consistently outperforms existing methods with substantial margins both in zero-shot and few-shot scenarios on 3D data in point clouds or mesh shapes.
Acknowledgment.
This work was supported in part by the National Science and Technology Council (NSTC) under grants 112-2221-E-A49-090-MY3, 111-2628-E-A49-025-MY3, 112-2634-F-006-002 and 112-2634-F-A49-007. This work was funded in part by MediaTek and NVIDIA.
Supplementary Material
Table 6:Zero-shot segmentation on all 16 categories of the ShapeNetPart dataset [44], reported mIoU (%). In this table, TTA and Pre denote the test-time alignment and pre-alignment versions of our method, while VLM stands for vision-language model (see main paper for details).
| Category | VLM - CLIP [37] | VLM - GLIP [22] | |||||||
| point cloud input | point cloud input | mesh input | |||||||
| PointCLIP [48] | PointCLIP v2 [52] | Ours (TTA) | Ours (Pre) | Ours (TTA) | Ours (Pre) | SATR [1] | Ours (TTA) | Ours (Pre) | |
| Airplane | 22.0 | 35.7 | 37.5 | 40.6 | 57.3 | 69.3 | 32.2 | 53.2 | 64.8 |
| Bag | 44.8 | 53.3 | 62.6 | 75.6 | 62.7 | 70.1 | 32.1 | 61.8 | 64.4 |
| Cap | 13.4 | 53.1 | 55.5 | 67.2 | 56.2 | 67.9 | 21.8 | 44.9 | 51.0 |
| Car | 30.4 | 34.5 | 36.4 | 41.2 | 32.4 | 39.2 | 22.3 | 30.2 | 32.3 |
| Chair | 18.7 | 51.9 | 56.4 | 65.0 | 74.2 | 86.5 | 25.2 | 66.4 | 67.4 |
| Earphone | 28.3 | 48.1 | 55.6 | 66.3 | 45.8 | 51.2 | 19.4 | 43.0 | 48.3 |
| Guitar | 22.7 | 59.1 | 71.7 | 85.8 | 60.6 | 76.8 | 37.7 | 50.7 | 64.8 |
| Knife | 24.8 | 66.7 | 76.9 | 79.8 | 78.5 | 85.7 | 40.1 | 66.3 | 70.0 |
| Lamp | 39.6 | 44.7 | 45.8 | 63.1 | 34.5 | 43.5 | 21.6 | 30.5 | 35.2 |
| Laptop | 22.9 | 61.8 | 67.4 | 92.6 | 85.7 | 91.9 | 50.4 | 68.3 | 83.1 |
| Motorbike | 26.3 | 31.4 | 33.4 | 38.2 | 30.6 | 37.8 | 25.4 | 28.8 | 32.5 |
| Mug | 48.6 | 45.5 | 53.5 | 83.1 | 82.5 | 85.6 | 76.4 | 83.9 | 86.5 |
| Pistol | 42.6 | 46.1 | 48.2 | 55.8 | 39.6 | 48.5 | 34.1 | 37.4 | 40.9 |
| Rocket | 22.7 | 46.7 | 49.3 | 49.5 | 36.8 | 48.9 | 33.2 | 41.1 | 45.3 |
| Skateboard | 42.7 | 45.8 | 47.7 | 49.2 | 34.2 | 43.5 | 22.3 | 26.2 | 34.5 |
| Table | 45.4 | 49.8 | 62.9 | 68.7 | 62.9 | 79.6 | 22.4 | 58.8 | 79.3 |
| Overall | 31.0 | 48.4 | 53.8 | 63.9 | 54.7 | 64.1 | 32.3 | 49.5 | 56.3 |
Table 7:Segmentation on all 45 categories of the PartE dataset [24], reported in mIoU (%). In this table, TTA denotes our method with test-time alignment (see main paper for details).
| Category | Zero-shot | Few-shot | ||
| PartSLIP [24] | Ours (TTA) | PartSLIP [24] | Ours | |
| Bottle | 76.3 | 77.4 | 83.4 | 84.6 |
| Box | 57.5 | 69.7 | 84.5 | 87.9 |
| Bucket | 2.0 | 16.8 | 36.5 | 50.7 |
| Camera | 21.4 | 29.4 | 58.3 | 60.1 |
| Cart | 87.7 | 88.5 | 88.1 | 90.1 |
| Chair | 60.7 | 74.1 | 85.3 | 88.4 |
| Clock | 26.7 | 23.6 | 37.6 | 37.2 |
| Coffee machine | 25.4 | 26.8 | 37.8 | 40.2 |
| Dishwasher | 10.3 | 18.6 | 62.5 | 60.2 |
| Dispenser | 16.5 | 11.4 | 73.8 | 74.7 |
| Display | 43.8 | 50.5 | 84.8 | 87.4 |
| Door | 2.7 | 41.1 | 40.8 | 55.5 |
| Eyeglasses | 1.8 | 59.7 | 88.3 | 91.1 |
| Faucet | 6.8 | 33.3 | 71.4 | 73.5 |
| Folding chair | 91.7 | 89.7 | 86.3 | 90.7 |
| Globe | 34.8 | 90.0 | 95.7 | 97.4 |
| Kettle | 20.8 | 24.2 | 77.0 | 78.6 |
| Keyboard | 37.3 | 38.5 | 53.6 | 70.8 |
| Kitchenpot | 4.7 | 36.8 | 69.6 | 69.7 |
| Knife | 46.8 | 59.2 | 65.2 | 71.4 |
| Lamp | 37.1 | 58.8 | 66.1 | 69.2 |
| Laptop | 27.0 | 37.1 | 29.7 | 40.0 |
| Lighter | 35.4 | 37.3 | 64.7 | 64.9 |
| Microwave | 16.6 | 23.2 | 42.7 | 43.8 |
| Mouse | 27.0 | 18.6 | 44.0 | 46.9 |
| Oven | 33.0 | 34.2 | 73.5 | 72.8 |
| Pen | 14.6 | 15.7 | 71.5 | 74.4 |
| Phone | 36.1 | 37.3 | 48.4 | 50.8 |
| Pliers | 5.4 | 51.9 | 33.2 | 90.4 |
| Printer | 0.8 | 3.3 | 4.3 | 6.3 |
| Refrigerator | 20.2 | 25.2 | 55.8 | 58.1 |
| Remote | 11.5 | 13.2 | 38.3 | 40.7 |
| Safe | 22.4 | 18.2 | 32.2 | 58.6 |
| Scissors | 21.8 | 64.4 | 60.3 | 68.8 |
| Stapler | 20.9 | 65.1 | 84.8 | 86.3 |
| Storage furniture | 29.5 | 30.6 | 53.6 | 56.5 |
| Suitcase | 40.2 | 43.2 | 70.4 | 73.4 |
| Switch | 9.5 | 30.3 | 59.4 | 60.7 |
| Table | 47.7 | 50.2 | 42.5 | 63.3 |
| Toaster | 13.8 | 11.4 | 60.0 | 58.7 |
| Toilet | 20.6 | 22.5 | 53.8 | 55.0 |
| Trash can | 30.1 | 49.3 | 22.3 | 70.0 |
| Usb | 10.9 | 39.1 | 54.4 | 64.3 |
| Washing machine | 12.5 | 12.9 | 53.5 | 55.1 |
| Window | 5.2 | 45.3 | 75.4 | 78.1 |
| Overall | 27.3 | 39.9 | 59.4 | 65.9 |
63D segmentation scores for full categories
We provide 3D segmentation scores, reported in mIoU, for full categories of the ShapeNetPart [44] and PartE [24] datasets in Tables 6 and 7, respectively. Table 6 is associated with Table 1 in the main paper, while Table 7 is associated with Tables 2 and 3. In Table 6, 16 categories of the ShapeNetPart dataset are reported, while 45 categories of the PartE dataset are presented in Table 7. For the tables, it is readily observed that the proposed method, PartDistill, attains substantial improvements compared to the competing methods [48, 52, 1, 24] in most categories.
7Evaluating 2D predictions
In the ablation studies of our method’s components presented in Table 5, we provide mIoU scores in 2D space, mIoU2D, to evaluate the quality of the 2D predictions measured against the 2D ground truths before and after performing backward distillation which re-scores the confidence scores of each knowledge unit. Here, the 2D ground truths are obtained by projecting the 3D mesh (faces) part segmentation labels to 2D space using the camera parameters utilized when performing 2D multi-view rendering.
We first explain how to calculate the mIoU2D if a vision-language model (VLM) which outputs pixel-wise predictions (P-VLM) is used in our method and later explain if a VLM which outputs bounding-box predictions (B-VLM) is employed. In each view, let {si}iρ be the prediction maps (see Eq. 1 in the main paper) of P-VLM with Ci denoting the confidence score of si and 𝒢 be the corresponding 2D ground truth. We first calculate the IoU2D for each semantic part r as,
| IoU2D(r)=ℐ(r)ℐ(r)+λ(r)+γ(r) | (5) |
where
| ℐ(r)=∑i∈ϕ(r)Avg(Ci)(si∩𝒢r), | (6) |
| λ(r)=Avg(Cϕ(r))((⋃i∈ϕ(r)si)∉𝒢r), | (7) |
and
| γ(r)=𝒢r∉⋃i∈ϕ(r)si, | (8) |
with ϕ(r) denoting a function returning indices of {si}i=1ρ that predict part r, “Avg” denoting an averaging operation and 𝒢r indicating the ground truth of part r.
While Eq. 6 represents the intersection of the pixels between the 2D predictions and the corresponding ground truths, weighted by their confidence scores, Eq. 7 tells the union of the 2D predictions pixels that do not intersect with the corresponding ground truths, which is weighted by the average of all confidence scores associated with part r. As for Eq. 8, it tells the ground truth pixels that do not intersect with the corresponding 2D predictions union. We then calculate the IoU2D score for each semantic part r in every v view and compute the mean of them as mIoU2D.
Note that we involve the confidence scores as weights to calculate the mIoU2D. This allows us to compare the quality of the 2D predictions before and after applying backward distillation, using the confidence scores before and after this process. To compute the mIoU2D scores when a B-VLM is used in our method, we can use Eq. 5 with si in Eq. 6∼ Eq. 8 being replaced by ℱ(bi), where ℱ denotes an operation excluding the background pixels covered in bi.
8Additional visualizations
8.1Visualization of few-shot segmentation

Figure 6:Visualization of few-shot segmentation results derived using our method on the PartE dataset [24]. Each semantic part is drawn in different colors.
In Figure 6, we present several visualizations for few-shot segmentation obtained via our method, associated with Table 3 in the main paper. Following the prior work [24], 8-shot labeled shapes are utilized to carry the few-shot segmentation. From the figure, it is evident that our method successfully achieves satisfactory segmentation results.
8.2Convergence curves
In the ablation studies presented in Table 5, we compare two approaches used in the 3D encoder of our student network. First, we employ a pre-trained PointM2AE [47] backbone, freeze the weights and only update the learnable parameters in the student network’s distillation head. Second, we utilize a PointM2AE backbone with its weights initialized by PyTorch [32] default initialization and set them to be learnable, together with the parameters in the distillation head. From the table, we observe comparable results between both settings (see rows (5) and (7) for the first and second approaches respectively).
We then visualize the convergence curves in both settings, as depicted in Figure 7. From the figure, it can be seen that the loss in the first approach converges significantly faster than in the second approach. As a result, the first approach also starts to perform backward distillation in a substantially earlier epoch than the second one.

Figure 7:Convergence curves of our method’s losses during optimization epochs. While the first approach employs a pre-trained PointM2AE [47] model and freezes its weights, the second approach initializes the Point2MAE’s weights from scratch and sets them to be learnable.
8.32D rendering from various shape types
We present several 2D rendering images from various shape types, including (i) gray mesh, (ii) colored mesh, (iii) dense colored point cloud, and (iv) sparse gray point cloud, which can be seen in Figure 8. While PartSLIP [24] renders the multi-view images using type (iii), SATR [1] uses type (i). As for PointCLIP [48] and PointCLIPv2 [52], they use type (iv) to render their multi-view images.

相关文章:
通过视觉语言模型蒸馏进行 3D 形状零件分割
大家读完觉得有帮助记得关注和点赞!!!对应英文要求比较高,特此说明! Abstract This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models …...

机器学习10-解读CNN代码Pytorch版
机器学习10-解读CNN代码Pytorch版 我个人是Java程序员,关于Python代码的使用过程中的相关代码事项,在此进行记录 文章目录 机器学习10-解读CNN代码Pytorch版1-核心逻辑脉络2-参考网址3-解读CNN代码Pytorch版本1-MNIST数据集读取2-CNN网络的定义1-无注释版…...

微服务学习-Gateway 统一微服务入口
1. 微服务为什么需要 API 网关? 1.1. 在微服务架构中,通常一个系统会被拆分为多个微服务,面对多个微服务客户端应该如何去调用呢? 如果根据每个微服务的地址发起调用,存在如下问题: 客户端多次请求不同的…...

2025寒假备战蓝桥杯02---朴素二分查找升级版本的学习+分别求解左右端点
文章目录 1.朴素二分查找的升级版2.查找左端点3.查找右端点4.代码的编写 1.朴素二分查找的升级版 和之前介绍的这个二分查找相比,我觉得这个区别就是我们的这个二分查找需要找到的是一个区间,而不是这个区间里面的某一个元素的位置; 2.查找…...

PHP语言的软件工程
PHP语言的软件工程 引言 软件工程是计算机科学中的一个重要分支,它涉及软件的规划、开发、测试和维护。在现代开发中,PHP作为一种流行的服务器端脚本语言,广泛应用于网页开发和各种企业应用中。本文将深入探讨PHP语言在软件工程中的应用&am…...

linux-FTP服务配置与应用
也许你对FTP不陌生,但是你是否了解FTP到底是个什么玩意? FTP 是File Transfer Protocol(文件传输协议)的英文简称,而中文简称为 “文传协议” 用于Internet上的控制文件的双向传输。同时,它也是一个应用程序…...

靠右行驶数学建模分析(2014MCM美赛A题)
笔记 题目 要求分析: 比较规则的性能,分为light和heavy两种情况,性能指的是 a.流量与安全 b. 速度限制等分析左侧驾驶分析智能系统 论文 参考论文 两类规则分析 靠右行驶(第一条)2. 无限制(去掉了第一条…...

(1)STM32 USB设备开发-基础知识
开篇感谢: 【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛 单片机学习记录_桃成蹊2.0的博客-CSDN博客 USB_不吃鱼的猫丿的博客-CSDN博客 1、USB鼠标_哔哩哔哩_bilibili usb_冰糖葫的博客-CSDN博客 USB_lqonlylove的博客-CSDN博客 USB …...

Spring中如何动态的创建、监听MQ以及创建Exchange
文章目录 前言动态创建和管理Exchange、Queue动态消费Queue结论 前言 前面我们学习 RabbitMQ 的时候,都是在编译的时候就确定了Exchange、Queue,也就是说我们需要在程序启动之前就创建好需要的Exchange和Queue,但是实际使用的时候࿰…...

中国综合算力指数(2024年)报告汇总PDF洞察(附原数据表)
原文链接: https://tecdat.cn/?p39061 在全球算力因数字化技术发展而竞争加剧,我国积极推进算力发展并将综合算力作为数字经济核心驱动力的背景下,该报告对我国综合算力进行研究。 中国算力大会发布的《中国综合算力指数(2024年…...

【Python项目】小区监控图像拼接系统
【Python项目】小区监控图像拼接系统 技术简介:采用Python技术、B/S框架、MYSQL数据库等实现。 系统简介:小区监控拼接系统,就是为了能够让业主或者安保人员能够在同一时间将不同地方的图像进行拼接。这样一来,可以很大程度的方便…...

常用排序算法之插入排序
目录 前言 一、基本原理 1.算法步骤 2.动画演示 3.插入排序的实现代码 二、插入排序的时间复杂度 1. 时间复杂度 1.最优时间复杂度 2.最差时间复杂度 3.平均时间复杂度 2. 空间复杂度 三、插入排序的优缺点 1.优点 2.缺点 四、插入排序的改进与变种 五、插入排…...
基础查询语法的使用)
Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询) 用于执行全文检索,适合搜索文本字段。 { “query”: { “match”: { “field”: “value” } } } match_phrase:精确匹配短语,适合用于短语搜索。 { “query”: { “match_phrase”: { “field”: “text” }…...

一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】
一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】 一、Milvus 是什么?【程序员猫爪】1、Milvus 是一种高性能、高扩展性的向量数据库…...

前端之移动端
视口 布局视口 layout viewport 视口(viewport)就是浏览器显示页面内容的屏幕区域。 视口可以分为布局视口、视觉视口和理想视口 一般移动设备的浏览器都默认设置了一个布局视口,用于解决早期的PC端页面在手机上显示的问题。 iOS, Androi…...
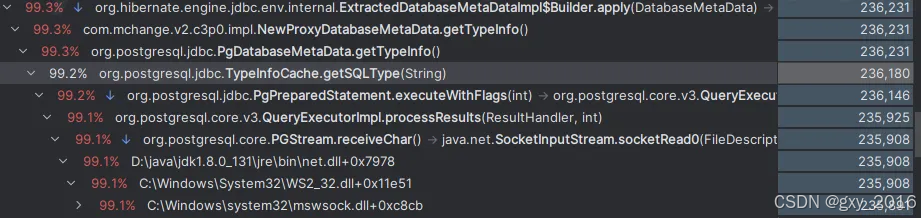
记一次 SpringBoot 启动慢的问题
记一次 SpringBoot 启动慢的问题 背景问题描述分析处理Flame Graph 火焰图Call Tree 调用树关键词检索尝试解决 为什么这样反向检索问题梳理 复盘处理流程为什么 Reference 背景 最近临时接了一个任务,就从一个旧 springboot 项目 copy 出来,临时写个服…...
高效安全文件传输新选择!群晖NAS如何实现无公网IP下的SFTP远程连接
文章目录 前言1. 开启群晖SFTP连接2. 群晖安装Cpolar工具3. 创建SFTP公网地址4. 群晖SFTP远程连接5. 固定SFTP公网地址6. SFTP固定地址连接 前言 随着远程办公和数据共享成为新常态,如何高效且安全地管理和传输文件成为了许多人的痛点。如果你正在寻找一个解决方案…...

如何在Python中进行JSON数据的序列化和反序列化?
在Python中,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python内置的json模块提供了简单易用的方法来实现数据的序列化和反序列化。下面将详细介绍如何…...

学习记录-统计记录场景下的Redis写请求合并优化实践
学习记录-使用Redis合并写请求来优化性能 1.业务背景 学习进度的统计功能:为了更精确的记录用户上一次播放的进度,采用的方案是:前端每隔15秒就发起一次请求,将播放记录写入数据库。但问题是,提交播放记录的业务太复杂了&#x…...

网站HTTP改成HTTPS
您不仅需要知道如何将HTTP转换为HTTPS,还必须在不妨碍您的网站自成立以来建立的任何搜索排名权限的情况下进行切换。 为什么应该从HTTP转换为HTTPS? 与非安全HTTP于不同,安全域使用SSL(安全套接字层)服务器上的加密代…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...