【深度学习入门】深度学习知识点总结
一、卷积
(1)什么是卷积
定义:特征图的局部与卷积核做内积的操作。

作用:① 广泛应用于图像处理领域。卷积操作可以提取图片中的特征,低层的卷积层提取局部特征,如:边缘、线条、角。
② 高层的卷积从低层的卷积层中学到更复杂的特征,即局部特征的组合,如前景与背景的组合,从而实现图片的分类和识别。
(2)卷积的特点
主要特点:局部感知和权值共享。
局部感知:卷积的大小远远小于图像,局部的像素联系比较密切,而距离较远的像素相关性较弱。因此,每个特征没必要对全局图像进行感知,只需对局部进行感知,然后在更高层将局部的信息 综合起来得到全局信息。
权值共享:使用相同的卷积核去提取特征,参数可以共享。带来了平移不变性:无论目标物体平移变换到图像中的哪个位置,卷积核都能以相同的方式(卷积核相同)对其进行处理,提取出相同的特征。
(3)卷积和全连接的区别
输入输出的结构:卷积输入输出都是 NCHW (批次大小、通道数、高度、宽度)格式,全连接输入输出都是 NV (批次大小、特征向量维度)结构。
知识点补充:深度学习框架中,数据一般是4D,如NCHW,分别代表 Batch(N)、Channel(C)、Height(H)、Width(W)。如:假设N=2,C=16,H=5,W=4,逻辑上就是如下4D图:

计算机存储上是一维的二进制,因此存取数据的顺序是:①W方向②H方向③C方向④N方向。用上图举例,即(W)000、001、……、(H)004、005、……、019、(C)020、021、……、039、(N)320、……、639。
全连接会把一整个特征图拉成一个向量(V),因此只有NV两个维度。
层之间的连接方式:全连接网络两层之间的神经元是两两相连(两层各任选出一个神经元,这两个神经元是连接的),卷积是部分相连(提取的特征只与卷积核覆盖的局部图像的特征有关)。
全连接不适合做 CV:① 全连接导致参数量过多,提高过拟合风险,即在训练集上表现好,在测试集上表现差,扩展性差。
② 使用Sigmoid激活函数,它的导数值最大为0.25,网络每更深一层,梯度值就会乘上一个不超过0.25的导数,使梯度值越来越小,甚至“梯度消失”。因此,全连接网络存在局限,梯度传播很难超过 3 层。
③ 邻近像素关联性强,距离较远像素关联性弱。全连接网络将每个像素视为独立特征,没有利用像素之间的位置关系信息。
卷积适合做 CV:① 局部连接(卷积核只有局部特征图的大小)、权重共享(使用相同的卷积核)、池化(压缩特征图尺寸,随之使用的卷积核尺寸减小),参数量大大减少。
② 使用Relu激活函数,其在正值区域梯度恒为1,避免了Sigmoid激活函数在极端值处梯度消失的问题,有利于深层网络训练。
③ 局部感知,利用了像素之间的位置关系信息。
(4)卷积的相关计算
卷积结果的长、宽计算公式:
计算结果向下取整。、
表示输入数据的长、宽;
、
表示卷积核的长、宽;P表示边缘填充的宽度,乘以2是因为数据的两边都会填充P的宽度;S为滑动窗口的步长。
卷积层参数量的计算:
表示卷积核的高度,
表示卷积核的宽度,
表示输入的通道数(卷积核的通道数),
表示输出的通道数(卷积核的个数)。结尾再加
,是因为每个卷积核还有一个偏置项。
(5)感受野
定义:输出特征图上的一个特征点对应于原图像素点的映射区域的大小。
来源:VGG网络提出,通过堆叠多层小卷积核(如3*3)代替一层大卷积核(如5*5、7*7),保持了与大卷积核相同的感受野,并增加了其它优势:
① 减少了网络的参数,随之降低了过拟合风险、提高了计算速度。
② 卷积层越多,每层专注于学习更简单的问题,提取的特征越细致。
③ 卷积层越多,加入的非线性变换越多(Relu激活函数),可以表现更复杂的东西。
有效感受野:① 实际上的有效感受野(认为每个像素的贡献不同)远远小于理论感受野(认为每个像素的贡献相同)。并且越靠近感受野中心的特征值,在卷积层中被使用次数越多,即对输出层的特征图点的贡献越大,即越有效,如下图所示:

x表示卷积层的输入,w表示卷积层的权重,o表示卷积层的输出。靠感受野边缘的特征只参与了
的计算,而靠中间的
参与了第一层输出的所有特征值的计算。因此,
只能通过
来影响
,而
能通过
、
、
、
、
、
、
、
、
来影响
,很明显,
比
对
更有效。输出层的特征点的感受野有效性,类高斯分布向边缘递减,如下图所示:

② anchor 应该与有效感受野相匹配。
感受野大小计算公式:
注意:① 第一层卷积层的输出特征图像素的感受野的大小等于滤波器(卷积核)的大小。
② 深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关。
③ 计算感受野大小时,忽略了图像边缘填充的影响,即不考虑 padding 的大小。以下公式,是从输入层开始,逐渐迭代计算到输出层的特征的感受野。
其中 表示第 k-1 层输出的特征图对应的感受野大小;
表示第 k 层的卷积核、或者池化层的池化大小;
表示第 i 层的滑动窗口步长;初始值
为1。用以下的一个例子示范感受野大小的计算:

第一层输出的感受野:
第二层输出的感受野:
第三层输出的感受野:
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
如果使用的是空洞卷积,公式则如下:
其中 表示第 k 层的空洞率。
(6)反卷积(转置卷积)
作用:主要用于上采样,就是扩大输入特征图的尺寸;还可以用来近似重构输入图像、卷积层可视化。
运算步骤:以下的 k 表示卷积核尺寸;s 表示每个像素间的距离,如下图所示:

p 表示初始卷积核可以卷积到图像的尺寸,如下图所示:

① 填充输入特征图:在输入特征图的元素间填充 s-1 长度的行和列,填充值为0;在特征图四周填充 k-p-1 长度的行和列,填充值为0。
② 翻转卷积核:上下、左右翻转。
③ 做普通的卷积运算。
可以看到转置卷积最终还是做普通的卷积,因此,转置卷积是一种特殊的正向卷积。
示例:

动图来源于:GitHub - vdumoulin/conv_arithmetic: A technical report on convolution arithmetic in the context of deep learning
上面动图的蓝色部分是输入特征图,虚线部分是对输入特征图的填充,绿色部分是输出特征图,总的效果是从输入特征图的3*3变为输出特征图的5*5,尺寸变大。假设上图的s=2,p=1,k=3,则元素间距填充:2-1=1;边缘填充:3-1-1=1。在做普通卷积的时候,padding为0,stride为1。
输出特征图的长、宽计算公式:
_
_
如果使用空洞卷积或者做普通卷积的时候padding不为0,那么用如下的公式:
_
_
_
_
其中 表示空洞率,
_
表示做普通卷积时的边缘填充宽度。
转置卷积运算步骤的推导:以下图的普通卷积为例子,步长为1,边缘填充宽度为0,卷积核尺寸为3。

在理论讲述普通卷积的计算时,说都是以滑动窗口的形式计算的,但是这种滑动的方式非常低效,因此,在实际计算时用了下面的一种计算方法:
① 将卷积核转换为跟输入特征图尺寸相同的等效矩阵:

② 将输入特征图展平为行向量:

③ 将所有等效矩阵展平为列向量,并合并为一个矩阵:

④ 最后将输入特征图与卷积核等效矩阵相乘,就能得到输出特征图:

现在有一个问题,如果知道卷积核参数C以及输出矩阵O,那么可以计算输入矩阵I吗?可能会说,在两边都乘以一个C的逆矩阵就行了,但是逆矩阵必须为方阵,而C并不是方阵,因此,这个方法行不通,反卷积不是卷积的逆运算。现在放宽条件,不要求计算原始输入矩阵 I,只要求与原始输入矩阵相同尺寸的矩阵,这样便是可以的,方法如下:

将输出矩阵 O,乘以卷积核等效矩阵的转置 ,得到大小为 1*16 的矩阵 P,可以看到它与输入矩阵 I 的参数不同,但尺寸相同。最终效果是,把一个 2*2 的矩阵上采样,扩展为一个4*4 的矩阵。因此,反卷积操作不能还原出卷积之前的特征图,只能还原出卷积之前特征图的尺寸。
接下来讲述的是反卷积运算步骤是怎么来的:
① 把矩阵 O 还原为 2*2 的矩阵形式,把 的每一列变为 2*2 的等效矩阵形式,再将 O 与每一个等效矩阵在相应位置相乘相加,就能得到矩阵 P :

与之还有一种等效的做法,将下图的绿色矩阵在填充后的矩阵 O 上滑动做卷积,会发现得到的结果与 P 一模一样。下图是将绿色矩阵与第一个滑动窗口相计算:

实际上,绿色矩阵就是一开始用卷积核 kernel 在 4*4 的输入特征图上做普通卷积得到 2*2 的输出特征图中的卷积核的上下、左右的翻转矩阵:

(7)空洞卷积
作用:在保持输出特征图的尺寸与输入特征图的尺寸一致的条件下,扩大输出特征图像素的感受野,并能保证不会因为下采样而丢失信息。通常情况下,为了扩大感受野,会进行下采样,然后用上采样还原到原图的尺寸,但下采样造成的信息丢失,在上采样中是无法弥补的。因此,为了避免因下采样而造成更多的信息丢失,就使用空洞卷积。
为什么扩大了感受野:在空洞卷积中,加入了一个新参数 表示空洞率,空洞率就是卷积核的参数间的间隔,参数间空的部分填充0,扩大了实际上的卷积核尺寸,因此会扩大感受野。如下图的所示,蓝色表示输入,绿色表示输出,深蓝色表示卷积核参数:

在卷积核的参数个数都为9的情况下,传统卷积的感受野是 3*3 ,而空洞卷积的感受野是 5*5。
为什么能保持尺寸不变:上图中的空洞卷积后的特征图尺寸变小,是因为没有对输入图像进行边缘填充。对输入特征图进行边缘填充(padding不为0),输入特征图的信息全保留了下来(不像用池化进行下采样,比如 max-pooling 只保留局部的最大特征值,造成信息丢失),并让输入图像的尺寸变大,再做空洞卷积就能保持输入和输出的尺寸不变。
卷积核尺寸计算:k 为原始卷积核尺寸,r 为空洞率。
存在的问题——网格效应(gridding effect):空洞卷积后得到的像素值对应于原特征图上的感受野范围内,使用到的原特征图上的像数值并不连续,存在间隔,导致丢失部分信息。
假如对一张17*17的特征图(layer1)进行3次卷积核尺寸为3*3,空洞率为2,步长为1的空洞卷积,网络层次结构如下图所示:

下图中有颜色的部分表示做3次空洞卷积后,输出特征图中的一个像素对应于该层的感受野。比如输出特征图 layer4 中的像素 在 layer1 中的感受野范围是 13*13,在 layer2 中的感受野范围是 9*9。


先从 layer1 开始执行第一次空洞卷积,会利用到所有带颜色的像素点,得到 layer2 中所有带颜色的像素点;再执行第二次空洞卷积,会利用 layer2 中所有带颜色的像素点,得到 layer3 中所有带颜色的像素点;执行第三次空洞卷积,只用到了黄色的像素点,得到 layer4 中的像素 。
再反过来看,layer4 中的像素 只利用了 layer3 中黄色的像素点;layer3 中黄色的像素点只利用了 layer2 中黄色的像素点(layer2 中黄色的像素点上的数字表示被
利用的次数);layer2 中黄色的像素点只利用了 layer1 中黄色的像素点。如果计算 layer1 中黄色像素点被
利用的次数, 比如 layer1 上的像素
被 layer2 上的像素
、
、
利用,这3个像素点被
利用的次数分别是 1、2、3,那么
被
利用的次数就是 1+2+3=6。
按照上面的方法计算,最终会得到原特征图中所有被 利用的像素点以及被利用的次数,如下图所示,右边的颜色条表示像素被利用次数的程度:

可以看到经过几层相同空洞率的空洞卷积后,输出特征图的像素对应输入特征图的感受野范围内的像素并不是都被利用到的,造成信息丢失。输入特征图的像素参与运算次数也分布不均,利用次数多的特征可能对分割结果产生更多影响。
如果3次空洞卷积的空洞率改为1、2、3,网络层次如下:

同3个空洞率为2的空洞卷积类似,得到被 layer4 的一个像素利用的像素(黄色)以及被利用的次数,如下图所示:


完整的 layer1 的像素被利用次数:

可以发现分别用空洞率为1、2、3的空洞卷积结果,连续地使用了原特征图的所有特征。因此,设置合适的混合空洞率参数,可以更好地避免信息丢失。
设计膨胀系数的方法——混合空洞卷积(Hybrid Dilated Convolution,HDC):
建议1:假如有 N 层空洞卷积,卷积核尺寸为 K*K,每层的空洞率为 ,
表示第 i 层两个非零元素(被利用到的元素)的最大距离,
的计算公式为:
并且,如果满足条件:
,则空洞率设计合适,否则不合适。
例如:K = 3,r = [1, 2, 5],则,
,满足条件
,因此设计合适。最高层像素利用最低层像素信息情况如下图所示,所有像素都被利用:

又例如:K = 3,r = [1, 2, 9],则,
,不满足条件
,因此设计不合适。最高层像素利用最低层像素信息情况如下图所示,非零像素间最大间隔为3,用公式也可以求得(
),部分信息丢失:

从上面两个例子可以观察到, 都为1,这是因为,如果想要最底层的像素都被利用,那么
应该为1,而
是取
三者的最大值,那么
肯定小于等于
,故
肯定设计为 1。
建议2:将膨胀系数设计为锯齿结构,例如 r = [1, 2, 3, 1, 2, 3],重复给定的 1, 2, 3。
建议3:膨胀系数的公约数不能大于1,例如 r = [2, 4, 8],公约数为2 大于 1,它的最低层像素利用结果如下图所示,可以看到部分像素未被利用:

下面是真实标签、未使用HDC设置方法、使用HDC设计方法的分割效果对比:

可以看到没有使用 HDC设计方法的预测效果存在很多细节上的问题,如上图中第二行,红色线框出来的部分。
缺点:① 局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果中的邻近像素,来自上一 层的独立的子集,没有相互依赖,因此该层的卷积结果之间没有相关性(邻近像素点的集合作为局部信息,应该有相关性,现在却没有了)。例如下图所示:

x1, x2 是第一层卷积结果 layer2 中的两个邻近像素点,x1 由 x3、x5、x7 计算得来,x2 由 x4、x6、x8 计算得来,这两个子集互相独立,导致卷积结果 x1, x2 没有相关性。
② 远距离信息不相关:原本的卷积神经网络在较深层,才会去处理两个间隔较远的像素特征。由于空洞卷积稀疏的采样输入信号,让间隔较远的特征早早地发生了相关运算,使得远距离信息的特征可能提取不好(远距离信息原本不相关,却强行将它们进行相关运算,卷积提取的特征效果就差)。
空洞率过大,适合分割大物体,但小物体的分割效果糟糕。
(8)可分离卷积
可分离卷积分为空间可分离卷积和深度可分离卷积,空间是指 [height, width] 两个维度,深度是指 channel 维度。
① 空间可分离卷积
运算步骤:空间可分离卷积就是将 n * n 的卷积分成 n ∗ 1 和 1 ∗ n 两步计算。比如将一个 3 * 3 的卷积核拆分成一个 3 * 1 的向量和一个 1 * 3 的向量,如下图所示:

优点:节省计算成本。如果做普通卷积,如下图所示,一共要做 9 次卷积,每次卷积要做 9 次乘法,一共要做 9 * 9 = 81 次乘法。

现在把 3 * 3 的卷积核拆分成个向量,分别做卷积,如下图所示:

第一次卷积:一共要做 15 次卷积,每次卷积要做 3 次乘法,一共要做 15 * 3 = 45 次乘法;第二次卷积:一共要做 9 次卷积,每次卷积要做 3 次乘法,一共要做 9 * 3 = 27 次乘法;总共做了 45 + 27 = 72 次乘法。
缺点:这种方法具有局限性,并非所有卷积核都可以分为两个较小的卷积核。如果用空间可分离卷积代替所有传统的卷积,在训练过程中,将限制卷积核的类型,训练结果可能不是最佳的。因此,一般情况下很少用到。
② 深度可分离卷积
运算步骤:将标准卷积操作分为逐深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
对于普通卷积,一张特征图的 3 个通道会分别于卷积核的 3 个通道做卷积,最后将 3 个结果合并作为最终输出,如下图所示(一共有 4 个卷积核):

使用的参数数量:3 * 3 * 3 * 4 = 108 个。
而深度可分离卷积分为了两步。逐深度卷积:卷积核是二维的,个数与特征图的通道数一致,分别卷积后得到 3 张特征图,这一步的目的是特征提取,如下图所示:

使用的参数数量:3 *3 * 3 = 27 个。
逐点卷积:卷积核恢复三维,但大小都是 1 * 1 的。为了对比,卷积核个数与上面的普通卷积中一致,为 4 个,最后得到的特征图数量与卷积核个数一致。这一步的目的是通道间信息交互和合并,如下图示:

使用的参数数量:1* 1 * 3 * 4 = 12 个。两步总共的参数数量:27 + 12 = 39 个。
优点:可大幅度减少卷积的参数。
缺点:在逐深度卷积这一步,卷积核太少,得到特征图太少,获取到的有效信息较少,从而造成精度损失。因此,模型大小可能会显著降低,模型的能力可能会变得不太理想。最近一些研究的解决办法就是,增加第二步逐点卷积的卷积核个数,从而增加输出特征图的通道数。
(9)分组卷积
运算步骤:设原通道为 ,目标通道为
。将输入特征图按通道均分为 g 组,然后对每一组进行常规卷积。分组后,每组输入特征图的通道数为
,所以每个卷积核的通道数也降低到
。一个卷积核可以计算一张特征图,如果每组有 n个卷积核,则目标通道数
,即
和
都是 g 的倍数,如下图所示:

优点:① 减少大量参数,从而减少运算量。若输入特征图大小为 n * n ,卷积核大小为 m * m,相同输入输出大小的情况下,普通卷积使用的参数个数为:,分组卷积使用的参数个数为:
,分组卷积比普通卷积少了 g 倍。
② 隔绝不同组的信息交换。如每个输出与输入的一部分特征图相关联时,分组卷积可以取得比常规卷积更好的性能,如输出通道为2,它们分别只与输入的1,2和3,4通道相关,这时最好使用g=2的分组卷积,相当于直接让模型将不相关的输入通道权重设置为零(不相关的输入通道之间不必再做计算),加快模型收敛。如下图所示:

缺点:对于需要考虑所有输入特征图信息的情况,分组卷积会降低模型的性能。这个问题,常常在两个分组卷积之间加入Channel_Shuffle模块打乱通道顺序,从而实现不同分组间的信息交换。如下图所示:

如果 ,就变成了逐深度卷积;如果
,而且卷积核的 size 等于输入的 size,就变成了全局加权池化,权重是可学习的。
(10)可变形卷积
运算步骤:首先看普通卷积的公式:,
就是当前处理的窗口的中心像素的坐标,如(3, 4),如下图所示:

就是相对于中心像素的窗口内其它像素的相对位置,它们组成矩阵
,
定义了卷积操作的 kernel size 和 dilation。如果 dlilation=2,相对位置就由加减 1 变为加减 2,如下图所示:

就是输入图像中
位置的像素值,
就是卷积核中
位置的权重。而可变形卷积公式加了一个
,表示滑动窗口中每个像素的位置偏移量:
是一个学习到的值,通过普通卷积计算而来,是浮点型数据。假设对输入图像中以第3行,第4列为中心的滑动窗口的右上角像素为例,说明可变形卷积的运算过程:
① 计算 :计算
的普通卷积的输入就是可变形卷积的输入(in_channel = 输入图像的 channel);out_channel = 2 * kernel_size^2;其它的参数,如 kernel_size、stride、padding 都与可变形卷积一样,因此它的输出 size 也与可变形卷积一样。例如,输入图像的 channel 为 3,那么 out_channel = 2*3*3=18,如下图所示:

左边的黄色部分是当前做卷积的窗口,右边的黄色部分是得到的结果,有18个像素值,将它们 reshape 为,如上图所示,每个元素就是
,表示当前处理的滑动窗口中每个像素的位置偏移量(x, y)。滑动窗口中右上角的像素值的
就是(1.6, 3.2)。
② 计算亚像素点位置:,是浮点型数据,(3.6,8.2)临近的4个像素点分别为(3,8)、(3,9)、(4,8)、(4,9),如下图中的紫色部分:

紫色部分中的红色点就是亚像素点,即偏移位置,它的像素值 通过双线性插值法求得。同理求得窗口中其它像素点的偏移后的像素值。
③ 做普通卷积:

优点:通过左右对比可以明显的看出,可变形卷积的采样位置更符合物体本身的形状和尺寸,而标准卷积的形式却不能做到这一点。相比原始的卷积它更能排除背景噪声的干扰,得到更有用的信息。

(11)1 * 1 卷积
起源:在 2014 年 GoogleNet 中首先应用。
作用:

① 实现跨通道的交互和信息整合。比如图中,输入的三个通道会与卷积核的三个通道分别做卷积,然后将三个结果的对应位置相加,即对不同通道上的特征进行线性组合,得到一个通道的特征图。
② 进行卷积核通道数的降维和升维。比如图中,使用两个 1 * 1卷积核,没有改变输入和输出的 size,但 channel 减少,实现降维(3 channel 变为 2 channel)。
③ 可以实现与全连接层等价的效果。比如图中,将输入的 3 个通道分别拉成 [16 * 1] 的向量 1、2、3,作为三个神经元,通过卷积核1的3个通道、卷积核2的3个通道计算得到两个 [16 * 1] 的向量神经元 4、5,它们是全连接的。
④ 加入非线性(卷积后紧跟激活函数层)。
⑤ 减少参数及计算量(MobileNet)。这一想法最早在GoogleNet中被提出,比如说如下两个Inception模块:

情况1,使用 1 * 1 卷积:
1*1卷积部分: 96*32*1*1=3072个;3*3卷积部分 32*48*3*3=13824个;总计16896个训练参数。
情况2,不使用 1 * 1 卷积:
总计 96*48*3*3 = 41472个训练参数。
从实际上来看,带1*1卷积的模型参数量更少,本质原因是因为1*1的卷积对数据的特征向量进行了降维的处理,使得特征通道数目先有了一定的减少(降维导致通道数减少,从而参数量减少)。
(12)3D 卷积
2D卷积,卷积核通道数与输入图像通道数一致:

3D卷积:

3D卷积的卷积核有3个维度,并且卷积核通道数小于特征图通道数,卷积核可在 h,w,c 三个方向移动。
二、池化
(1)池化的作用
池化即下采样。
① 减小特征图的 size,保留主要的特征,从而减少参数和计算量,达到降维的效果。
② 防止过拟合,增强模型泛化性能。
③ 扩大感受野。
④ 实现平移旋转不变性。因为池化不断抽象了区域的特征而不关心位置,所以池化一定程度上增加了平移不变性。比如,用平均池化、最大池化,把窗口内像素点位置改变了,平均值、最大值还是一样的。
(2)池化的分类
① 最大池化:选取池化窗口中的最大值作为输出。
② 平均池化:选取池化窗口中像素的平均值作为输出。
③ 全局平均池化:在 Class Activation Mapping(CAM)中提出,就是对每个通道的整个特征图进行平均池化,生成对应于每个通道的汇聚特征值,最终得到一个汇聚特征向量。一般用于后面的全连接层。
④ 金字塔池化:目前流行的CNN都需要固定 size 和 scale 的输入图片,基本上都是通过剪裁(crop) 和缩放 (wrap),这种处理方式存在弊端:crop 的图片可能不包含整个物体;wrap 导致物体变形;当物体大小改变时,预定义的 scale 可能不适合物体的变化。如下图所示:

CNN网络对于固定输入的要求,主要在全连接的分类器层(输入必须与权重矩阵匹配),而特征提取层可以通过控制卷积核尺寸调节,来接受各种 scale 和 size 的输入,得到固定的特征输出。因此,可以通过一种叫做空间金字塔池化(Spatial Pyramid Pooling, SPP)的方法,将不同尺寸的输入,进行多个尺度的池化,然后展开并拼接出一个固定大小的向量,从而连接到全连接层。
如下图所示,一张任意大小的图片在经过一系列的卷积层后,产生了256个特征图(最后一个卷积层有256个卷积核),大小不固定。将每张特征图都分别分成16, 4, 1份,然后做最大池化。处理完所有的特征图后,将池化结果进行拼接,得到的向量是固定长度的。在这个例子中,这个向量的长度为 (16+4+1) * 256。

SPP 避免 crop 和 warp 操作导致一些信息丢失,多尺度池化有助于捕捉不同规模的特征,总体来说提高了模型准确率。
⑤ 全局加权池化:分组卷积提到。
(3)池化结果 size 的计算公式
同卷积一样,但是是向上取整。
(4)池化能减小特征提取的误差
特征提取的误差主要来自两个方面:
① 邻域大小受限造成的估计值方差增大:进行卷积操作时,卷积核覆盖的区域(即邻域)是有限的,意味着只能基于这一小块区域内的像素来估计整个图像在该位置的特征。因为这个估计基于有限的信息,所以存在不确定性,这种不确定性在统计学上表现为估计值的方差增大。方差增大意味着估计值的波动范围较大,即估计值可能偏离真实值较远,且不确定性增大。
② 卷积层参数误差造成估计均值的偏移:卷积层中的参数,由于训练数据的限制、模型的复杂度以及优化算法的性能等因素,可能会存在误差。这种误差会导致对特征值的估计产生偏移,即估计的均值与真实值之间存在差距。
平均池化能减小第一种误差:因为平均值能够平滑掉一些随机波动,使得估计更加稳定,能更多地保留图像整体或背景信息。因为背景信息通常较为平滑,不易受局部波动影响。
最大池化能减小第二种误差:最大值对邻域内的变化更加敏感,能够捕捉到更为显著的特征,这些特征往往与纹理信息紧密相关。因此,最大池化能够更多地保留图像局部显著特征或纹理信息。
(5)池化的反向传播
原则:把下一层的 1 个像素的梯度传递给上一层的 n * n(池化窗口的 size)个像素,但是需要保证传递的梯度总和不变。
平均池化:将梯度平均分给池化之前的每个像素。
最大池化:将梯度只分给之前最大值的像素,其它的梯度为 0。
三、激活函数
(1)激活函数的作用
如果不用激活函数,每一层输出都是上一层的线性函数,就变成了线性模型,表达能力不够。如果引入非线性激活函数的话,加入了非线性因素,神经网络就能够去逼近任意函数。
(2)Sigmoid
公式:
图像(左为函数图像,右为导数图像):

优点:① 提供非线性能力。
② 因为处处连续,所以可导,这便于计算梯度。
③ 压缩数据,输出范围在0和1之间。
④ 输出值可以解释为概率,可作为分类任务的输出层。
⑤ 适用于二分类。
缺点:① 在输入值接近无穷大或无穷小时,其输出值会接近于0或1(达到饱和状态),此时函数的梯度(导数)会趋近于0。导数最大为 0.25,每传递一层梯度都会减为原来 0.25 倍(甚至更小),这会导致权重更新的梯度非常小,即梯度消失现象,会使得网络在训练过程中学习得非常慢,甚至无法继续学习。
② 非中心对称函数,均值不为 0,网络收敛效果不好。理由如下图所示:

网络结构为 隐层1->激活层1->隐层2->激活层2,现在我们想更新参数 和
,则参数更新公式为:
,其中
为学习率,
为 sigmoid 激活函数。可以看到
、
对于更新
和
来说都是相同的值,唯一不同的是
和
。因此
和
更新方向,完全由对应的输入值
,i=1,2 的符号决定。而激活层1 用的是sigmoid 函数,导致
的值都为正,即
和
更新方向总是相同的(同时增大或者同时减少),如果
最优的更新方向是增加,
最优的更新方向是减少,
和
的合方向将会走 Z 字形逼近最优解,收敛的过程将会非常缓慢,如下图所示(
、
表示最优参数):

③ 函数本身包含指数运算(),且其导函数也比较复杂(
),运算相对耗时。
(3)Softmax
参考链接:http://t.csdnimg.cn/8qNDF。
Sigmoid 和 Softmax指数运算溢出问题:sigmoid 和 softmax 函数在计算中,都会用到指数运算 或
,如果在
中 x 是一个很小的负数,或者在
中 x 是一个很大的正数,这时有溢出(即数值超过计算机能表示的最大浮点数)的风险。
Sigmoid 溢出的解决办法:如果 x>0 ,则 ;如果 x<0 ,则
。
Softmax 溢出的解决办法:取所有 中的最大值M,则计算
这组数的Softmax 等同于计算
这一组数据的 Softmax(即分子分母同时除以
)。这样Softmax改为
,就解决了上溢出的问题,因为
小于等于 0,则
都是小于等于 1 的值。
(4)Tanh
公式:。
图像:

优点:与sigmoid函数不同,tanh函数零中心对称,让模型的收敛速度更快。
缺点:① 在两边还是有梯度饱和(也就是梯度趋近于 0)易造成梯度消失。
② 包含指数运算,运算相对复杂且耗时。
(5)Relu
公式:max (0, x)。
图像:

优点:
① 计算简单(只需要一个阈值判断,x小于0得0,x大于等于0得x),梯度也好求(x小于0为0,x大于0为1)。
② ReLU函数在输入为正数时,其梯度恒为1,梯度不会衰减,减轻梯度消失问题。
③ ReLU函数在输入小于0时,输出为0,使得网络在训练过程中产生大量的稀疏性(指只有少量神经元被激活,对网络的输出产生影响)。稀疏性有两个好处:一是可以减少参数的数量,缓解过拟合问题;二是让网络更加关注重要的特征(激活输出为5的特征比0.5的更突出,都是负值的表示没有明显特征,直接过滤掉为0),提高模型的泛化能力。
④ ReLu的这个三个优点,促进了模型快速收敛。
缺点:① 当ReLU函数的输入值为负时,输出始终为0,并且其一阶导数(梯度)也始终为0。这会导致在反向传播过程中,如果某个神经元的输入始终为负,那么该神经元的权重将永久不会更新,这种现象被称为“神经元死亡”。
比如,当学习率(learning rate)设置得过高时,高学习率意味着在每次参数更新,权重的改变量可能很大,如果更新前参数梯度为正,那么更新前的参数就会被减去一个很大的值,更新后的参数变为负值,这可能导致输入神经元的正值与相应负权重相乘求和后也变为负值输出,再经过 Relu,输出值为0,反向传播的梯度也为0,参数得不到更新就一直为负,从而导致神经元一直为负,永久失活。这些神经元同时“死亡”,从而整个网络中相当大比例(40%)的神经元失效。
解决办法:改用 Relu 的变体 —— 如Leaky ReLU、Parametric ReLU;改用小的学习率。
③ 不会对输入数据进行幅度压缩。正数经过ReLU层后,其输出将保持不变并继续传递给下一层。如果权重矩阵中的某些元素也较大,那么这些较大的输入和权重相乘后,输出可能会变得更大。这种效应在多层网络中会累积,导致数据幅度不断扩张,可能会发生梯度爆炸(如果前向传播中的数据幅度很大,那么计算出的梯度也可能很大,导致权重更新不稳定甚至发散)。
(6)Leaky ReLu
公式:
是自己设置的一个很小的参数,通常是 0.01。
图像:

小于0的输出,不再是0,而是绝对值很小的一个负数;输入小于0的部分,梯度也不再是0,而是 ,从而解决 “Dead ReLu” 问题。
其它的 ReLu 变体:① 随机 Leaky ReLu: 随机取值,
分布服从均值为0、标准差为1的正态分布。
② PReLu(Parametric ReLU): 通过学习而来,跟着模型一起优化。
优点:① 避免神经元死亡。
② 输入为负时梯度不为0,缓解梯度消失问题。
③ 计算速度快。
④ Leaky ReLU 线性、非饱和的形式,在梯度下降中能够快速收敛。
缺点:虽然解决了神经元死亡的问题,但在实践中的效果没有比 ReLU 有明显的提升。
(7)ReLu6
源于Mobile v1,将最大值限制为6。
公式:
图像:黄线为ReLu6,蓝线为ReLu。
函数图

梯度函数图

优点:在移动端float16的低精度的时候,也能有很好的数值分辨率。如果对ReLu的输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。
(8)ELU
公式:
图像:
优点:
一个好的激活函数应该满足:① 单侧饱和(负输入区域饱和,可以过滤掉不重要的特征)。
② 输出值分布在 0 的两侧(相当于0中心对称,可以加快网络的收敛速度)。
Relu只满足了第1个条件,而不满足第2个条件;LeakyReLu、PReLu 满足第2个条件而不满足第1个条件。ELU同时满足2个条件。
满足单侧饱和:指数函数 在 x 趋近于负无穷时趋近于0,因此
会趋近于 -1 。乘以α 后,ELU 的输出将趋近于 -α。因此 ELU 函数在负输入区域具有饱和性,即当输入值足够小时,输出值将不再随输入值的减小而显著减小,而是趋近于一个固定的负值 -a,那么梯度也是一个趋于0的值。
相关文章:
【深度学习入门】深度学习知识点总结
一、卷积 (1)什么是卷积 定义:特征图的局部与卷积核做内积的操作。 作用:① 广泛应用于图像处理领域。卷积操作可以提取图片中的特征,低层的卷积层提取局部特征,如:边缘、线条、角。 ② 高层…...

通过视觉语言模型蒸馏进行 3D 形状零件分割
大家读完觉得有帮助记得关注和点赞!!!对应英文要求比较高,特此说明! Abstract This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models …...

机器学习10-解读CNN代码Pytorch版
机器学习10-解读CNN代码Pytorch版 我个人是Java程序员,关于Python代码的使用过程中的相关代码事项,在此进行记录 文章目录 机器学习10-解读CNN代码Pytorch版1-核心逻辑脉络2-参考网址3-解读CNN代码Pytorch版本1-MNIST数据集读取2-CNN网络的定义1-无注释版…...

微服务学习-Gateway 统一微服务入口
1. 微服务为什么需要 API 网关? 1.1. 在微服务架构中,通常一个系统会被拆分为多个微服务,面对多个微服务客户端应该如何去调用呢? 如果根据每个微服务的地址发起调用,存在如下问题: 客户端多次请求不同的…...

2025寒假备战蓝桥杯02---朴素二分查找升级版本的学习+分别求解左右端点
文章目录 1.朴素二分查找的升级版2.查找左端点3.查找右端点4.代码的编写 1.朴素二分查找的升级版 和之前介绍的这个二分查找相比,我觉得这个区别就是我们的这个二分查找需要找到的是一个区间,而不是这个区间里面的某一个元素的位置; 2.查找…...

PHP语言的软件工程
PHP语言的软件工程 引言 软件工程是计算机科学中的一个重要分支,它涉及软件的规划、开发、测试和维护。在现代开发中,PHP作为一种流行的服务器端脚本语言,广泛应用于网页开发和各种企业应用中。本文将深入探讨PHP语言在软件工程中的应用&am…...

linux-FTP服务配置与应用
也许你对FTP不陌生,但是你是否了解FTP到底是个什么玩意? FTP 是File Transfer Protocol(文件传输协议)的英文简称,而中文简称为 “文传协议” 用于Internet上的控制文件的双向传输。同时,它也是一个应用程序…...

靠右行驶数学建模分析(2014MCM美赛A题)
笔记 题目 要求分析: 比较规则的性能,分为light和heavy两种情况,性能指的是 a.流量与安全 b. 速度限制等分析左侧驾驶分析智能系统 论文 参考论文 两类规则分析 靠右行驶(第一条)2. 无限制(去掉了第一条…...

(1)STM32 USB设备开发-基础知识
开篇感谢: 【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛 单片机学习记录_桃成蹊2.0的博客-CSDN博客 USB_不吃鱼的猫丿的博客-CSDN博客 1、USB鼠标_哔哩哔哩_bilibili usb_冰糖葫的博客-CSDN博客 USB_lqonlylove的博客-CSDN博客 USB …...

Spring中如何动态的创建、监听MQ以及创建Exchange
文章目录 前言动态创建和管理Exchange、Queue动态消费Queue结论 前言 前面我们学习 RabbitMQ 的时候,都是在编译的时候就确定了Exchange、Queue,也就是说我们需要在程序启动之前就创建好需要的Exchange和Queue,但是实际使用的时候࿰…...

中国综合算力指数(2024年)报告汇总PDF洞察(附原数据表)
原文链接: https://tecdat.cn/?p39061 在全球算力因数字化技术发展而竞争加剧,我国积极推进算力发展并将综合算力作为数字经济核心驱动力的背景下,该报告对我国综合算力进行研究。 中国算力大会发布的《中国综合算力指数(2024年…...

【Python项目】小区监控图像拼接系统
【Python项目】小区监控图像拼接系统 技术简介:采用Python技术、B/S框架、MYSQL数据库等实现。 系统简介:小区监控拼接系统,就是为了能够让业主或者安保人员能够在同一时间将不同地方的图像进行拼接。这样一来,可以很大程度的方便…...

常用排序算法之插入排序
目录 前言 一、基本原理 1.算法步骤 2.动画演示 3.插入排序的实现代码 二、插入排序的时间复杂度 1. 时间复杂度 1.最优时间复杂度 2.最差时间复杂度 3.平均时间复杂度 2. 空间复杂度 三、插入排序的优缺点 1.优点 2.缺点 四、插入排序的改进与变种 五、插入排…...
基础查询语法的使用)
Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询) 用于执行全文检索,适合搜索文本字段。 { “query”: { “match”: { “field”: “value” } } } match_phrase:精确匹配短语,适合用于短语搜索。 { “query”: { “match_phrase”: { “field”: “text” }…...

一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】
一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】 一、Milvus 是什么?【程序员猫爪】1、Milvus 是一种高性能、高扩展性的向量数据库…...

前端之移动端
视口 布局视口 layout viewport 视口(viewport)就是浏览器显示页面内容的屏幕区域。 视口可以分为布局视口、视觉视口和理想视口 一般移动设备的浏览器都默认设置了一个布局视口,用于解决早期的PC端页面在手机上显示的问题。 iOS, Androi…...
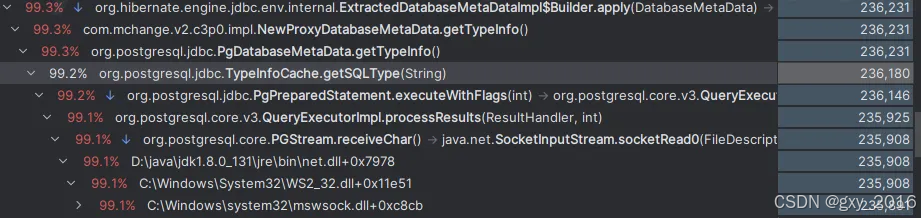
记一次 SpringBoot 启动慢的问题
记一次 SpringBoot 启动慢的问题 背景问题描述分析处理Flame Graph 火焰图Call Tree 调用树关键词检索尝试解决 为什么这样反向检索问题梳理 复盘处理流程为什么 Reference 背景 最近临时接了一个任务,就从一个旧 springboot 项目 copy 出来,临时写个服…...
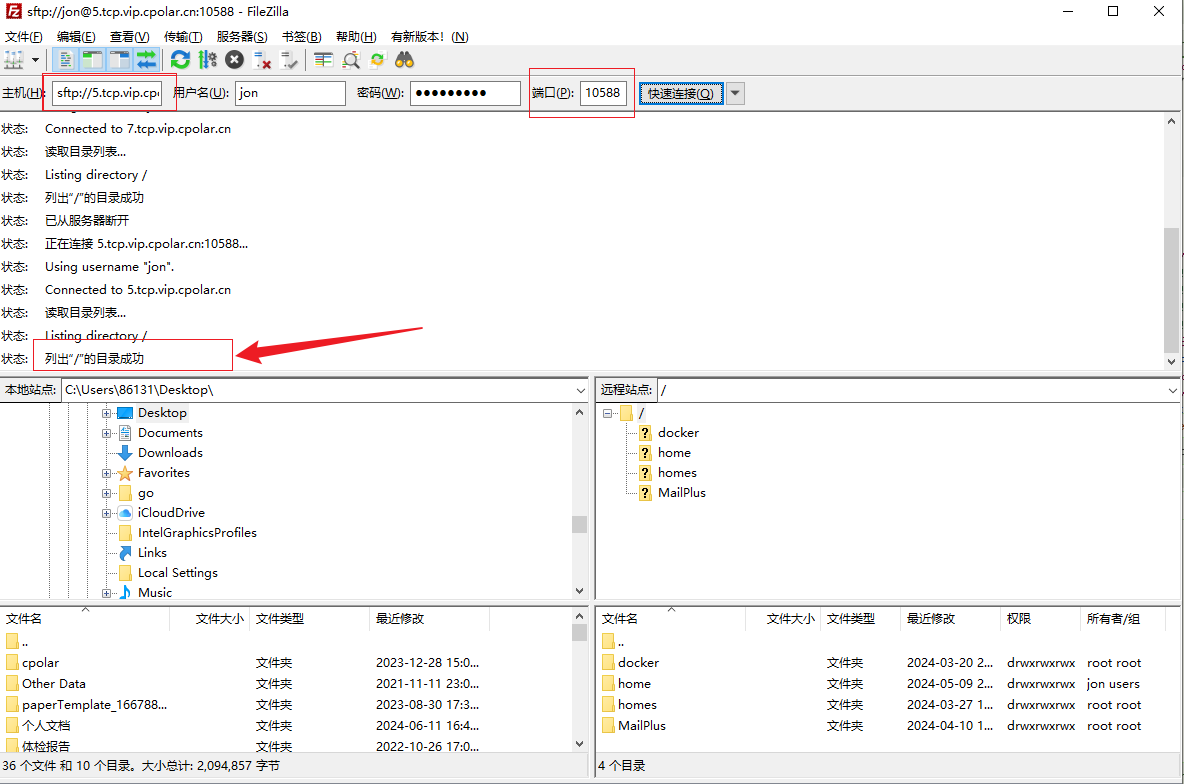
高效安全文件传输新选择!群晖NAS如何实现无公网IP下的SFTP远程连接
文章目录 前言1. 开启群晖SFTP连接2. 群晖安装Cpolar工具3. 创建SFTP公网地址4. 群晖SFTP远程连接5. 固定SFTP公网地址6. SFTP固定地址连接 前言 随着远程办公和数据共享成为新常态,如何高效且安全地管理和传输文件成为了许多人的痛点。如果你正在寻找一个解决方案…...

如何在Python中进行JSON数据的序列化和反序列化?
在Python中,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python内置的json模块提供了简单易用的方法来实现数据的序列化和反序列化。下面将详细介绍如何…...

学习记录-统计记录场景下的Redis写请求合并优化实践
学习记录-使用Redis合并写请求来优化性能 1.业务背景 学习进度的统计功能:为了更精确的记录用户上一次播放的进度,采用的方案是:前端每隔15秒就发起一次请求,将播放记录写入数据库。但问题是,提交播放记录的业务太复杂了&#x…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...