Elasticsearch的经典面试题及详细解答
以下是一些Elasticsearch的经典面试题及详细解答:
一、基础概念与原理
-
什么是Elasticsearch?
回答:
Elasticsearch是一个基于Lucene的分布式搜索引擎,提供了RESTful API,支持多租户能力。它能够快速、近实时地存储、搜索和分析海量数据,每个字段都被索引并可被搜索。Elasticsearch广泛用于全文搜索、日志分析、实时监控等领域。
-
解释Elasticsearch的基本概念,如索引、文档、字段、分片和副本。
回答:
- 索引(Index):类似于关系型数据库中的数据库,是Elasticsearch中存储相关数据的地方,包含了一组具有相似结构的文档数据。
- 文档(Document):是Elasticsearch中的最小数据单元,类似于关系型数据库中的一行记录。每个文档是JSON格式的,可以有不同的字段,但通用字段应具有相同的数据类型。
- 字段(Field):是Elasticsearch中的最小数据单位,一个文档中包含多个字段。
- 分片(Shard):Elasticsearch将索引中的数据切分成多个分片,每个分片是一个Lucene索引的实例,可以分布在不同的服务器上存储。分片允许Elasticsearch横向扩展,提升存储和搜索性能。
- 副本(Replica):Elasticsearch为每个分片创建副本,副本可以在分片故障时提供备用服务,保证数据不丢失,并提升搜索操作的吞吐量和性能。
-
什么是倒排索引?
回答:
倒排索引是Elasticsearch实现快速搜索的关键技术。在搜索引擎中,每个文档经过分词处理后,会形成一系列关键词。倒排索引就是这些关键词到文档ID的映射,记录了每个关键词在哪些文档中出现过。查询时,根据倒排索引可以快速定位到包含查询关键词的文档,极大提高了检索效率。
-
Elasticsearch中的DocValues是什么?
回答:
DocValues是Elasticsearch在构建倒排索引的同时,为正排索引构建的一种数据结构。它保存了文档ID到各个字段值的映射,以文档为维度,支持高效的排序、分组和聚合操作。DocValues存储在操作系统的磁盘中,当数据量巨大时,可以从操作系统页缓存中加载或弹出,避免内存溢出,提高访问速度。
-
Elasticsearch中的text和keyword类型有什么区别?
回答:
- text类型:在Elasticsearch中,text类型的字段会被全文检索。存储时,text类型的字段会被分词器处理,根据分词后的内容建立倒排索引。查询时,支持模糊匹配、部分匹配等。
- keyword类型:keyword类型的字段不会被分词,直接根据字符串内容建立倒排索引。查询时,支持精确值匹配,适用于过滤、排序、聚合等操作。
-
Elasticsearch如何选举Master节点?
回答:
Elasticsearch的Master节点选举由ZenDiscovery模块负责。选举流程如下:
- 确认候选主节点数达标:Elasticsearch通过配置文件中
discovery.zen.minimum_master_nodes参数,确定选举过程中需要的最小候选主节点数,以防止脑裂现象。 - 节点排序:对所有可以成为Master的节点(
node.master: true)根据节点ID(第一次启动时生成的随机字符串)进行字典排序。 - 选举Master节点:每个节点都把自己所知道的节点排一次序,然后选出第一个节点作为暂时的Master节点。如果这个节点获得了超过
n/2+1(n为候选主节点数)的节点投票,并且它自己也选举自己,则它成为正式的Master节点。否则,重新选举,直到满足条件。
- 确认候选主节点数达标:Elasticsearch通过配置文件中
二、索引设计与优化
-
描述如何设计Elasticsearch索引以支持高效的全文搜索和聚合操作?
回答:
- 索引模板:使用基于时间的索引模板,结合rollover API滚动创建新索引,保持单个索引的大小适中,避免索引过大导致的性能问题。
- 分片与副本:根据数据量和查询性能需求,合理配置索引的分片数和副本数。通常,每个索引的主分片数在创建时确定,副本数可以随时调整。
- 字段映射:在索引创建时,为不同字段设置合适的映射类型。对于需要全文检索的字段,使用text类型;对于需要精确值匹配的字段,使用keyword类型。
- 分词器:为需要分词的字段选择合适的分词器,以提高搜索的准确性和效率。
-
在数据建模过程中,如何决定使用嵌套类型还是平面结构?
回答:
- 平面结构:如果能使用平面宽表存储数据,推荐使用平面结构。空间换时间的方式是非常有效的数据建模方式。
- 嵌套类型:在子文档更新不频繁的场景下,推荐使用nested类型。nested类型允许对嵌套对象进行复杂的查询和聚合操作。
- Join类型:在子文档更新频繁的场景下,推荐使用join类型。join类型通过父子关系连接不同类型的文档,支持复杂的关联查询。
-
Elasticsearch如何处理分布式环境下的数据一致性问题?
回答:
- 跨集群复制(CCR):Elasticsearch提供了CCR功能,允许将一个集群中的索引复制到另一个远程集群。这种方式适用于地理分布式的环境,可以在本地读取数据的同时保持与远端数据同步。
- X-Pack安全插件:通过启用X-Pack的安全特性,可以为跨集群通信设置认证和授权机制,保障数据传输的安全性。同时,可以配置SSL/TLS加密连接,防止中间人攻击。
- 脑裂预防:正确配置
discovery.seed_hosts和cluster.initial_master_nodes参数,确保有足够的候选主节点参与选举过程。设置适当的minimum_master_nodes值,以防止小部分节点形成孤立的子集群。
三、性能优化与运维
-
如何在高并发写入场景下优化Elasticsearch性能?
回答:
- 索引设计:采用基于时间的索引模板,结合rollover API滚动创建新索引,保持单个索引的大小适中。
- 写入策略:使用bulk批量API进行写入,减少网络开销。在大批量写入前,暂时将副本数量设置为0,并在完成后再恢复。关闭自动刷新(
refresh_interval设置为-1),手动控制刷新频率,避免频繁刷新导致性能下降。 - 集群配置:合理分配节点角色,如分离主节点和数据节点,确保主节点专注于集群管理和选举。根据硬件资源调整JVM堆内存大小,通常不超过32GB,以避免压缩指针带来的额外开销。禁用交换分区(swap),防止因内存不足触发交换而影响性能。设置较大的文件句柄限制和线程池大小,满足高并发需求。
-
如何实现Elasticsearch中的冷热数据架构?
回答:
- 索引生命周期管理(ILM):利用Elasticsearch的ILM特性,定义索引从“热”到“温”再到“冷”的转换规则。例如,新创建的索引默认放在SSD硬盘上的热节点上,经过一段时间后迁移到HDD硬盘上的温节点,最终归档或删除。
- 分片分配过滤:通过设置
index.routing.allocation.*参数,控制不同阶段的索引只能分配给特定类型的节点。例如,使用include._tier_preference=data_hot让热数据仅存放在热节点上。 - 索引模板:为不同阶段的索引定义不同的模板,指定相应的分片数、副本数和其他设置。热索引可能需要更多的分片和副本以保证可用性,而冷索引则可以减少这些配置以节省资源。
- 缩放操作:对于不再更新的老索引,可以通过_shrink API将其缩小为更少的分片,进一步降低存储空间占用。
-
描述Elasticsearch的写入流程。
回答:
Elasticsearch的写入流程如下:
- 客户端发送请求:客户端选择一个节点(协调节点)发送写入请求。
- 协调节点路由:协调节点根据文档ID计算目标分片,将请求转发到对应的主分片节点。
- 主分片处理:主分片节点在内存中处理写入请求,将文档添加到索引的数据结构中。
- 同步到副本分片:主分片节点将写入操作同步到所有副本分片节点,确保数据的一致性。
- 响应客户端:所有副本分片节点都执行成功后,协调节点向客户端返回写入成功的响应。
-
Elasticsearch在高并发下如何保证读写一致性?
回答:
Elasticsearch通过以下机制保证高并发下的读写一致性:
- 版本号控制:Elasticsearch为每个文档维护一个版本号,在更新或删除文档时,通过版本号确保操作的原子性。
- 乐观并发控制:Elasticsearch采用乐观并发控制策略,默认情况下,假设冲突不会发生。当冲突发生时(例如,两个并发写入操作试图更新同一个文档),后发生的写入操作会失败,客户端需要处理冲突并重新尝试写入。
- 事务日志(Translog):Elasticsearch在写入数据到内存的同时,也会将操作记录到Translog中。在节点故障或重启时,可以通过Translog恢复数据,保证数据的一致性。
-
Elasticsearch集群脑裂现象是什么?如何避免?
回答:
- 脑裂现象:脑裂现象是指由于网络分区
相关文章:

Elasticsearch的经典面试题及详细解答
以下是一些Elasticsearch的经典面试题及详细解答: 一、基础概念与原理 什么是Elasticsearch? 回答: Elasticsearch是一个基于Lucene的分布式搜索引擎,提供了RESTful API,支持多租户能力。它能够快速、近实时地存储、搜…...

Linux-arm(1)ATF启动流程
Linux-arm(1)ATF启动流量 Author:Once Day Date:2025年1月22日 漫漫长路有人对你微笑过嘛… 全系列文章可查看专栏: Linux实践记录_Once_day的博客-CSDN博客 参考文档: ARM Trusted Firmware分析——启动、PSCI、OP-TEE接口 Arnold Lu 博…...

C#编程:List.ForEach与foreach循环的深度对比
在C#中,List<T>.ForEach 方法和传统的 foreach 循环都用于遍历列表中的元素并对每个元素执行操作,但它们之间有一些关键的区别。 List<T>.ForEach 方法 方法签名:public void ForEach(Action<T> action)类型:…...

C语言文件操作:标准库与系统调用实践
目录 1、C语言标准库文件操作 1.1.题目要求: 1.2.函数讲解: fopen 函数原型 参数 常用的打开模式 返回值 fwrite函数 函数原型 参数 返回值 注意事项 fseek函数 函数原型 参数 返回值 fread函数 函数原型 参数 返回值 fclose 函数…...

代码随想录 栈与队列 test 7
347. 前 K 个高频元素 - 力扣(LeetCode) 首先想到哈希,用key来存元素,value来存出现次数,最后进行排序,时间复杂度约为o(nlogn)。由于只需求前k个,因此可以进行优化,利用堆来维护这…...

C语言练习(21)
有一行电文,已按下面规律译成密码: A→Za→Z B→Yb→y C→Xc→X 即第1个字母变成第26个字母,第2个字母变成第25个字母,第i个字母变成第(26-i十1)个字母。非字母字符不变。假如已知道密码是Umtorhs&…...

智能手机“混战”2025:谁将倒下而谁又将突围?
【潮汐商业评论原创】 “去年做手机比较艰难,几乎每个品牌都在调价、压货,像华为这种以前都不给我们分货的厂商,也开始成为我的主要库存。不过今年开头比较好,20号国补一开始,店里的人流和手机销量就明显涨了不少&…...

计算机图形学:实验一 OpenGL基本绘制
1.OpenGL的环境配置: 集成开发环境Visual Studio Community 2019的安装: 在Windows一栏选择使用C的桌面开发;再转到“单个组件”界面,在“编译器、生成工具和运行时”一栏选择用于“Windows的C CMake工具”;然后转到…...

二分查找题目:快照数组
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:快照数组 出处:1146. 快照数组 难度 7 级 题目描述 要求 实现支持下列接口的快照数组: SnapshotArray(int length) \textt…...

深度学习|表示学习|卷积神经网络|参数共享是什么?|07
如是我闻: Parameter Sharing(参数共享)是卷积神经网络(CNN)的一个重要特性,帮助它高效地处理数据。参数共享的本质就是参数“本来也没有变过”。换句话说,在卷积层中,卷积核的参数&…...

基于相机内参推导的透视投影矩阵
基于相机内参推导透视投影矩阵(splatam): M c a m [ 2 ⋅ f x w 0.0 ( w − 2 ⋅ c x ) w 0.0 0.0 2 ⋅ f y h ( h − 2 ⋅ c y ) h 0.0 0 0 f a r n e a r n e a r − f a r 2 f a r ⋅ n e a r n e a r − f a r 0.0 0.0 − 1.0 0.0 ] M_…...

浅析Dubbo 原理:架构、通信与调用流程
一、Dubbo 简介 Dubbo 是阿里巴巴开源的高性能、轻量级的 Java RPC(Remote Procedure Call,远程过程调用)框架,旨在实现不同服务之间的远程通信和调用。在分布式系统中,不同服务可能部署在不同的服务器上,D…...

03垃圾回收篇(D3_垃圾收集器的选择及相关参数)
目录 学习前言 一、收集器的选择 二、GC日志参数 三、垃圾收集相关的常用参数 四、内存分配与回收策略 1. 对象优先在Eden分配 2. 大对象直接进入老年代 3. 长期存活的对象将进入老年代 4. 动态对象年龄判定 5. 空间分配担保 学习前言 本章主要学习垃圾收集器的选择及…...

一、引论,《组合数学(第4版)》卢开澄 卢华明
零、前言 发现自己数数题做的很烂,重新学一遍组合数学吧。 参考卢开澄 卢华明 编著的《组合数学(第4版)》,只打算学前四章。 通过几个经典问题来了解组合数学所研究的内容。 一、幻方问题 据说大禹治水之前,河里冒出来一只乌龟,…...

Vue3+TS 实现批量拖拽文件夹上传图片组件封装
1、html 代码: 代码中的表格引入了 vxe-table 插件 <Tag /> 是自己封装的说明组件 表格列表这块我使用了插槽来增加扩展性,可根据自己需求,在组件外部做调整 <template><div class"dragUpload"><el-dialo…...
)
二叉树的所有路径(力扣257)
因为题目要求路径是从上到下的,所以最好采用前序遍历。这样可以保证按从上到下的顺序将节点的值存入一个路径数组中。另外,此题还有一个难点就是如何求得所有路径。为了解决这个问题,我们需要用到回溯。回溯和递归不分家,每递归一…...
缓存)
Python OrderedDict 实现 Least Recently used(LRU)缓存
OrderedDict 实现 Least Recently used(LRU)缓存 引言正文 引言 LRU 缓存是一种缓存替换策略,当缓存空间不足时,会移除最久未使用的数据以腾出空间存放新的数据。LRU 缓存的特点: 有限容量:缓存拥有固定的…...

LabVIEW项目中的工控机与普通电脑选择
工控机(Industrial PC)与普通电脑在硬件设计、性能要求、稳定性、环境适应性等方面存在显著差异。了解这些区别对于在LabVIEW项目中选择合适的硬件至关重要。下面将详细分析这两种设备的主要差异,并为LabVIEW项目中的选择提供指导。 硬件设…...
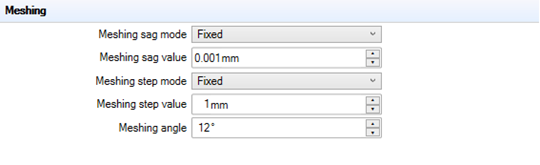
Ansys Speos | Speos Meshing 网格最佳实践
概述 网格划分是在各种计算应用中处理3D几何的基本步骤: 表面和体积:网格允许通过将复杂的表面和体积分解成更简单的几何元素(如三角形、四边形、四面体或六面体)来表示复杂的表面和体积。 模拟和渲染:网格是创建离散…...

elasticsearch segment数量对读写性能的影响
index.merge.policy.segments_per_tier 是一个配置选项,用于控制 Elasticsearch 中段(segment)合并策略的行为。它定义了在每一层的段合并过程中,允许存在的最大段数量。调整这个参数可以优化索引性能和资源使用。 假设你有一个索…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...