从零安装 LLaMA-Factory 微调 Qwen 大模型成功及所有的坑
文章目录
- 从零安装 LLaMA-Factory 微调 Qwen 大模型成功及所有的坑
- 一 参考
- 二 安装
- 三 启动
- 准备大模型文件
- 四 数据集(关键)!
- 4.1 Alapaca格式
- 4.2 sharegpt
- 4.3 在 dataset_info.json 中注册
- 4.4 官方 alpaca_zh_demo 例子 999条数据, 本机微调 5分钟
- 4.5 我的数据(关键)
- 4.6 微调成功但是新模块问答都失败(巨坑)
- 小数据微调参数!!!
- 巨坑 数据集的内容,要差异够大!!!
- TODO 扩展阅读,
- 五 TODO LLaMaFactory 参数详解
从零安装 LLaMA-Factory 微调 Qwen 大模型成功及所有的坑
2025-1-22
老规矩,感谢所有参考文章的作者。少走很多弯路。
一 参考
【1】llama-factory使用教程
这里有各种依赖的版本。 似乎不用。直接安装,一键成功。
【2】学大模型必看!手把手带你从零微调大模型
微调 零一 大模型。
【3】【Qwen2微调实战】LLaMA-Factory框架对Qwen2-7B模型的微调实践
流程主参考文章
【4】LLaMA-Factory QuickStart
【5】官网 gitcode 镜像
【6】LLaMa-Factory部署及llamafactory-cli webui命令无法打开ui界面问题解决记录
私链转公链
二 安装
- 前置条件
N卡 在 WSL2 Ubuntu22.04 环境下装 cuda toolkit 见这篇文章
WSL2 Ubuntu22.04 部署配置Xinference和所有的坑
- 安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
> 参数‘--depth 1’, 只clone 最近一次 commit后的所有仓库。就是不需要之前的 commit 历史记录。或者下载代码zip 包,解压到本地。
unzip archive.zip -d /path/to/destinationconda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'Attempting uninstall: datasets
Found existing installation: datasets 3.2.0
Uninstalling datasets-3.2.0:
Successfully uninstalled datasets-3.2.0
Successfully installed accelerate-1.0.1 contourpy-1.3.1 cycler-0.12.1 datasets-3.1.0 docstring-parser-0.16 fire-0.7.0 fonttools-4.55.3 jieba-0.42.1 joblib-1.4.2 kiwisolver-1.4.8 llamafactory-0.9.2.dev0 matplotlib-3.10.0 nltk-3.9.1 peft-0.12.0 pyparsing-3.2.1 rouge-chinese-1.0.3 shtab-1.7.1 tokenizers-0.20.3 transformers-4.46.1 trl-0.9.6 tyro-0.8.14
一次成功。
- 验证
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__>>> torch.cuda.get_device_name(0)
'NVIDIA GeForce RTX 4070 SUPER'
>>> torch.__version__
'2.5.1+cu124'
llamafactory-cli train -h(mypy310) rainbow@zy-pc-01:~/LLaMA-Factory-main$ llamafactory-cli train -h
usage: llamafactory-cli [-h] [--ray_run_name RAY_RUN_NAME] [--ray_num_workers RAY_NUM_WORKERS][--resources_per_worker RESOURCES_PER_WORKER][--placement_strategy {SPREAD,PACK,STRICT_SPREAD,STRICT_PACK}]options:-h, --help show this help message and exit
三 启动
cd /home/***/LLaMA-Factory-main
llamafactory-cli webui注意:在刚才安装的conda环境下启动
切换到 LLaMA-Factory-main 目录,因为需要识别数据集文件夹
准备大模型文件
下载略
因为我通过 Xinference 已经下载了, 只需要提供路径即可。
Qwen1.5-1.8B
/home/xinference/modelscope/hub/qwen/Qwen1___5-1___8B-Chat/
大模型路径, 设置ok。 就可以 chat。
- 坑 wsl 下 Ubuntu 浏览器中文乱码
sudo apt-get remove firefox
sudo apt-get remove --purge firefox
卸载 Ubuntu的浏览器, 用 windows 的浏览器就ok。
LLama Factory 运行界面报错问题解决方法-DJT
export GRADIO_ROOT_PATH=xxx
这是解决云端部署中文乱码的。
- 坑 Failed to create DBus proxy for org.a11y.Bus: Could not connect: No such file or directory
没解决, 是个warning, 貌似没有任何影响。后续微调成功,chat也成功。
四 数据集(关键)!
官网文档
llama_factory/data
这里默认是llama-factory中的data文件夹中的数据,在使用自己的数据集的时候,可以把数据集文件直接放到data文件夹下。
注意,无论是否放到data文件夹下,记得在dataset_info.json 中添加你要用的数据集信息,包括名称和路径,否则在页面中是加载不出来的。
必须! 如果有自定义数据, 必须在dataset_info.json中注册。
【04】LLaMA-Factory微调大模型——数据准备
一、数据格式
LLaMA-Factory支持 alpaca 格式和 sharegpt 格式的数据集。
4.1 Alapaca格式
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
官方自带例子
alpaca_zh_demo.json
[{"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。","input": "","output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"},{"instruction": "输入三支篮球队的名称并生成一个适当的口号。","input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。","output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""}
]
- instruction 和 input
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,
即人类指令为 instruction\n input。
而 output 列对应的内容为模型回答。
所以, 上面篮球队的例子中。 AI拿到的输入如下
“输入三支篮球队的名称并生成一个适当的口号。输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。”
-
system
如果指定,system 对应的内容将被作为系统提示词。 -
history
history 是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。
注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
4.2 sharegpt
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,
例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
sharegpt 格式如下:
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "function_call","value": "工具参数"},{"from": "observation","value": "工具结果"},{"from": "gpt","value": "模型回答"}],"system": "系统提示词(选填)","tools": "工具描述(选填)"}
]
4.3 在 dataset_info.json 中注册
LLaMA-Factory/data 目录中的 dataset_info.json 文件中包含了所有可用的数据集。
如果使用自定义数据集,首先需要在 dataset_info.json 文件中添加数据集描述,
"数据集名称": {"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)","ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)","script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)","file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)","formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)","ranking": "是否为偏好数据集(可选,默认:False)","subset": "数据集子集的名称(可选,默认:None)","split": "所使用的数据集切分(可选,默认:train)","folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)","num_samples": "该数据集所使用的样本数量。(可选,默认:None)","columns(可选)": {"prompt": "数据集代表提示词的表头名称(默认:instruction)","query": "数据集代表请求的表头名称(默认:input)","response": "数据集代表回答的表头名称(默认:output)","history": "数据集代表历史对话的表头名称(默认:None)","messages": "数据集代表消息列表的表头名称(默认:conversations)","system": "数据集代表系统提示的表头名称(默认:None)","tools": "数据集代表工具描述的表头名称(默认:None)","images": "数据集代表图像输入的表头名称(默认:None)","chosen": "数据集代表更优回答的表头名称(默认:None)","rejected": "数据集代表更差回答的表头名称(默认:None)","kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"},"tags(可选,用于 sharegpt 格式)": {"role_tag": "消息中代表发送者身份的键名(默认:from)","content_tag": "消息中代表文本内容的键名(默认:value)","user_tag": "消息中代表用户的 role_tag(默认:human)","assistant_tag": "消息中代表助手的 role_tag(默认:gpt)","observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)","function_tag": "消息中代表工具调用的 role_tag(默认:function_call)","system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"}
}
对于alpaca 格式的数据,dataset_info.json 中的数据集注册描述应为:
"<your dataset name>": {"file_name": "<your dataset file.json>","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}如上面例子中 alpaca_zh_demo 在dataset_info.json中的注册信息如下。
{"identity": {"file_name": "identity.json"},"alpaca_en_demo": {"file_name": "alpaca_en_demo.json"},"alpaca_zh_demo": {"file_name": "alpaca_zh_demo.json"},
}
数据集注册方便, 大多数参数用默认就好,
最简注册,只需要“数据集名字”和“数据集文件的名字”
4.4 官方 alpaca_zh_demo 例子 999条数据, 本机微调 5分钟
输入三支篮球队的名称并生成一个适当的口号。
俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队
微调之前
俄克拉荷马城雷霆队口号:“Thunderbolts Rule the City!”
芝加哥公牛队口号:“Bulls on the Rise #Bulls #Rise”
布鲁克林网队口号:“The Nets are Here to Stay #Nets #Stay”
微调之后 5分钟 4070
“雷霆猛兽,公牛铁血,网球队员,勇往直前。”
4.5 我的数据(关键)
学校成绩
你是python程序员。编写一段完整的python 程序。要求
- 按照下面个格式生成 n个同学的数据, 并保存为 alpaca_zh_my_demo.json
- 学号从1 到 n, 默认998
- 姓名按中国人姓名随机生成,分男女
- 性别,男女各一半
- 考试时间, 默认10月
- 数学,物理,化学的成绩从1到100
-
[{"instruction": "红星小学学号1成绩","input": "","output": "姓名:张三, 性别:男, 学号:1, 考试时间:10月, 数学:49, 物理:9, 化学:13"},{"instruction": "红星小学学号2成绩","input": "","output": "姓名:李四, 性别:女, 学号:1, 考试时间:10月, 数学:69, 物理:59, 化学:93"}
]以下是一个完整的Python程序,用于生成指定格式的JSON数据并保存为文件。程序会随机生成998个学生的成绩数据,姓名随机生成,男女各占一半,考试时间为10月,成绩随机生成。
Python复制略文件复制到 data 目录
cp /mnt/e/Tec/LLama-Factory/alpaca_zh_my_demo.json /home/LLaMA-Factory-main/data/
cat /home/LLaMA-Factory-main/data/alpaca_zh_my_demo.json
注册
/home/LLaMA-Factory-main/data/dataset_info.json
{"identity": {"file_name": "identity.json"},"alpaca_en_demo": {"file_name": "alpaca_en_demo.json"},"alpaca_zh_demo": {"file_name": "alpaca_zh_demo.json"},"alpaca_zh_my_demo": {"file_name": "alpaca_zh_my_demo.json","columns": {"prompt": "instruction","query": "input","response": "output"}},
4.6 微调成功但是新模块问答都失败(巨坑)
微调数据
{"instruction": "红星小学张三10月考试成绩是多少?","input": "","output": "姓名:张三, 性别:男, 学号:1, 考试时间:10月, 数学:66, 物理:66, 化学:66"
}
当提问 “红星小学张三10月考试成绩是多少?”
期望回答, “姓名:张三, 性别:男, 学号:1, 考试时间:10月, 数学:66, 物理:66, 化学:66”
刚开始怀疑是数据量的问题。
结果数据 9条,199条,999条数据,都微调失败。
小数据微调参数!!!
基于LLaMA-Factory微调llama3成为一个角色扮演大模型
如果训练的文件小,训练配置调大一点:
学习率: 2e-3(默认5e-5) 训练论数:10.0(默认3.0) 最大样本数:1000(默认1W)
特别感谢,这位作者提供的微调参数。
如果有知道原因的同学,能告诉我的话就更好了,我来更新。
只把张三的一条数据,添加到官方例子 “alpaca_zh_demo.json”, 让数据集中的每条数据各不相同。
设置如上参数。微调成功。

巨坑 数据集的内容,要差异够大!!!
{"instruction": "红星小学张三10月考试成绩是多少?","input": "","output": "姓名:张三, 性别:男, 学号:1, 考试时间:10月, 数学:66, 物理:66, 化学:66"},{"instruction": "红星小学冯超10月考试成绩是多少?","input": "","output": "姓名:冯超, 性别:男, 学号:2, 考试时间:10月, 数学:47, 物理:63, 化学:69"},{"instruction": "红星小学孙波10月考试成绩是多少?","input": "","output": "姓名:孙波, 性别:男, 学号:3, 考试时间:10月, 数学:98, 物理:96, 化学:98"}
如果是10条类似的成绩数据,提示词只有姓名不同,同样的参数,微调后,问答还是失败。
如果是10个学生成绩这种的数据,因为提示词只有姓名的不同, 微调不出来!!!
TODO 扩展阅读,
魔搭社区数据集
从Llama Factory数据集看模型微调和训练
微调数据集的准备
自我认知数据集
特定任务数据集
通用任务数据集
理解怎样设置数据集。如果是学生成绩这种,怎样配置数据集?
五 TODO LLaMaFactory 参数详解
从0学习LLaMaFactory参数解释说明
Finetuning method
Checkpoint path
Quantization bit/Enable quantization (QLoRA).
Quantization method
Chat template
RoPE scaling
Booster
Train tab
Stage
Data dir
Dataset
Learning rate (学习率, 关键参数!!!)
Epochs
Maximum gradient norm
Max samples
Compute type
Cutoff length
Batch size
Gradient accumulation
Val size
LR scheduler
Data dir
Dataset
相关文章:
从零安装 LLaMA-Factory 微调 Qwen 大模型成功及所有的坑
文章目录 从零安装 LLaMA-Factory 微调 Qwen 大模型成功及所有的坑一 参考二 安装三 启动准备大模型文件 四 数据集(关键)!4.1 Alapaca格式4.2 sharegpt4.3 在 dataset_info.json 中注册4.4 官方 alpaca_zh_demo 例子 999条数据, 本机微调 5分…...

SQL-leetcode—1164. 指定日期的产品价格
1164. 指定日期的产品价格 产品数据表: Products ---------------------- | Column Name | Type | ---------------------- | product_id | int | | new_price | int | | change_date | date | ---------------------- (product_id, change_date) 是此表的主键(具…...

[Day 15]54.螺旋矩阵(简单易懂 有画图)
今天我们来看这道螺旋矩阵,和昨天发的题很类似。没有技巧,全是循环。小白也能懂~ 力扣54.螺旋矩阵 题目描述: 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: …...
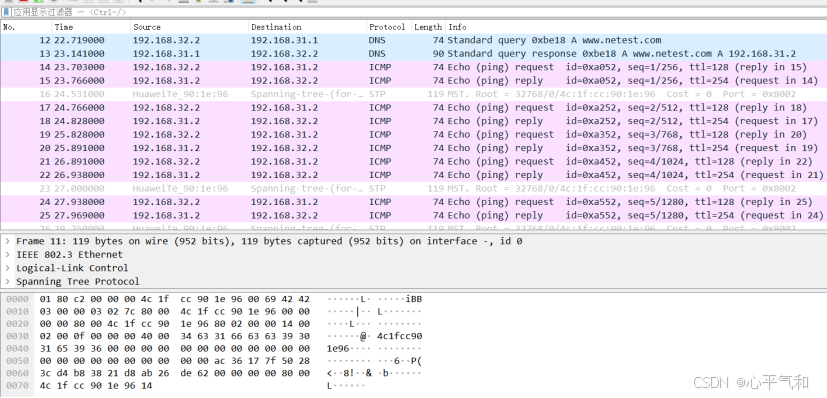
HTTP 配置与应用(不同网段)
想做一个自己学习的有关的csdn账号,努力奋斗......会更新我计算机网络实验课程的所有内容,还有其他的学习知识^_^,为自己巩固一下所学知识,下次更新校园网设计。 我是一个萌新小白,有误地方请大家指正,谢谢…...

Quartus:开发使用及 Tips 总结
Quartus是Altera(现已被Intel收购)推出的一款针对其FPGA产品的综合性开发环境,用于设计、仿真和调试数字电路。以下是使用Quartus的一些总结和技巧(Tips),帮助更高效地进行FPGA项目开发: 这里写目录标题 使用总结TIPS…...

VSCode下EIDE插件开发STM32
VSCode下STM32开发环境搭建 本STM32教程使用vscode的EIDE插件的开发环境,完全免费,有管理代码文件的界面,不需要其它IDE。 视频教程见本人的 VSCodeEIDE开发STM32 安装EIDE插件 Embedded IDE 嵌入式IDE 这个插件可以帮我们管理代码文件&am…...

Golang并发机制及CSP并发模型
Golang 并发机制及 CSP 并发模型 Golang 是一门为并发而生的语言,其并发机制基于 CSP(Communicating Sequential Processes,通信顺序过程) 模型。CSP 是一种描述并发系统中交互模式的正式语言,强调通过通信来共享内存…...

HTML 文本格式化详解
在网页开发中,文本内容的呈现方式直接影响用户的阅读体验。HTML 提供了多种文本格式化元素,可以帮助我们更好地控制文本的显示效果。本文将详细介绍 HTML 中的文本格式化元素及其使用方法,帮助你轻松实现网页文本的美化。 什么是 HTML 文本格…...

我谈《概率论与数理统计》的知识体系
学习《概率论与数理统计》二十多年后,在廖老师的指导下,才厘清了各章之间的关系。首先,这是两个学科综合的一门课程,这一门课程中还有术语冲突的问题。这一门课程一条线两个分支,脉络很清晰。 概率论与统计学 概率论…...

五、华为 RSTP
RSTP(Rapid Spanning Tree Protocol,快速生成树协议)是 STP 的优化版本,能实现网络拓扑的快速收敛。 一、RSTP 原理 快速收敛机制:RSTP 通过引入边缘端口、P/A(Proposal/Agreement)机制等&…...

基于Java Web的网上房屋租售网站
内容摘要 本毕业设计题目为《基于Java Web的网上房屋租售网站》,是在信息化时代下充分利用互联网对传统房屋租售方式进行创新,在互联网上进行房屋租售突破了传统方式的局限性。对于房屋租售的当事人都提供了极大的便利。本稳针对了实际用户需求…...

Pyside6(PyQT5)中的QTableView与QSqlQueryModel、QSqlTableModel的联合使用
QTableView 是QT的一个强大的表视图部件,可以与模型结合使用以显示和编辑数据。QSqlQueryModel、QSqlTableModel 都是用于与 SQL 数据库交互的模型,将二者与QTableView结合使用可以轻松地展示和编辑数据库的数据。 QSqlQueryModel的简单应用 import sys from PySid…...

git常用命令学习
目录 文章目录 目录第一章 git简介1.Git 与SVN2.Git 工作区、暂存区和版本库 第二章 git常用命令学习1.ssh设置2.设置用户信息3.常用命令设置1.初始化本地仓库init2.克隆clone3.查看状态 git status4.添加add命令5.添加评论6.分支操作1.创建分支2.查看分支3.切换分支4.删除分支…...

【优选算法】7----三数之和
来了来了,他来了,又是学习算法的一天~ 今天的嘉宾是中等难度的算法题----三数之和! ------------------------------------------begin------------------------------------ 题目解析: 哇趣!又是给了一个数组&#…...
分子动力学模拟里的术语:leap-frog蛙跳算法和Velocity-Verlet算法
分子动力学模拟(Molecular Dynamics Simulation,简称MD)是一种基于经典力学原理的计算物理方法,用于模拟原子和分子在给定时间内的运动和相互作用。以下是关于分子动力学模拟的一些核心术语和概念: 定义系统&am…...

2025年数学建模美赛:A题分析(1)Testing Time: The Constant Wear On Stairs
2025年数学建模美赛 A题分析(1)Testing Time: The Constant Wear On Stairs 2025年数学建模美赛 A题分析(2)楼梯磨损分析模型 2025年数学建模美赛 A题分析(3)楼梯使用方向偏好模型 2025年数学建模美赛 A题分…...

利用 SoybeanAdmin 实现前后端分离的企业级管理系统
引言 随着前后端分离架构的普及,越来越多的企业级应用开始采用这种方式来开发。前后端分离不仅提升了开发效率,还让前端和后端开发可以并行进行,减少了相互之间的耦合度。SoybeanAdmin 是一款基于 Spring Boot 和 MyBatis-Plus 的后台管理系…...
996引擎 - 前期准备-配置开发环境
996引擎 - 前期准备 官网搭建服务端、客户端单机搭建 开发环境配置后端开发环境配置环境 前端开发环境配置环境 后端简介前端简介GUILayoutGUIExport 官网 996传奇引擎官网 所有资料从官网首页开始,多探索。 文档: 996M2-服务端Lua 996M2-客户端Lua 搭…...

Tensor 基本操作4 理解 indexing,加减乘除和 broadcasting 运算 | PyTorch 深度学习实战
前一篇文章,Tensor 基本操作3 理解 shape, stride, storage, view,is_contiguous 和 reshape 操作 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started Tensor 基本使用 索引 indexing示例代码 加减…...

【Uniapp-Vue3】request各种不同类型的参数详解
一、参数携带 我们调用该接口的时候需要传入type参数。 第一种 路径名称?参数名1参数值1&参数名2参数值2 第二种 uni.request({ url:"请求路径", data:{ 参数名:参数值 } }) 二、请求方式 常用的有get,post和put 三种,默认是get请求。…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...