日志收集Day005
1.filebeat的input类型之filestream实战案例:
在7.16版本中已经弃用log类型,之后需要使用filebeat,与log不同,filebeat的message无需设置就是顶级字段
1.1简单使用:
filebeat.inputs:
- type: filestreamenabled: truepaths:- /tmp/myfilestream01.log
output.console:pretty: true
1.2解析json格式数据
filebeat.inputs:# 指定类型为filestream,在7.16版本中已经弃用log类型
- type: filestreamenabled: truepaths:- /tmp/myfilestream02.logparsers:# 配置json格式解析- ndjson:# 将错误消息记录到error字段中add_error_key: true# 如果解析的json格式字段和filebeat内置的顶级字段冲突,则覆盖,默认是不覆盖的。overwrite_keys: true# 将message解析的字段放入一个自定义的字段下。若不指定该字段,则默认解析的键值对会在顶级字段.target: readjsonoutput.console:pretty: true1.3多行合并案例
filebeat.inputs:# 指定类型为filestream,在7.16版本中已经弃用log类型
- type: filestreamenabled: truepaths:- /tmp/myfilestream02.logparsers:- multiline:type: countcount_lines: 4- ndjson:add_error_key: trueoverwrite_keys: truetarget: readjsonoutput.console:pretty: true2.写入数据到es集群
filebeat.inputs:
- type: filestreamenabled: truepaths:- /tmp/shopping.jsonparsers:- multiline:type: countcount_lines: 7- ndjson:add_error_key: trueoverwrite_keys: true# 将日志输出到ES集群
output.elasticsearch:# 指定ES集群地址hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]# 指定索引index: "shopping-%{+yyyy.MM.dd}-output"# 禁用索引声明管理周期,若不禁用则自动忽略自定义索引名称
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lxc-shopping"
# 指定索引模板的匹配模式
setup.template.pattern: "lxc-shopping-*"
# 是否覆盖原有的索引模板
setup.template.overwrite: true
# 设置索引模板
setup.template.settings:# 指定分片数量为8index.number_of_shards: 8# 指定副本数量为0index.number_of_replicas: 0
3.多数据源写入es集群不同索引
filebeat.inputs:- type: filestreamenabled: truetags: "json"paths:- /tmp/ceshi.jsonparsers:- ndjson:add_error_key: true#overwrite_keys: true- type: filestreamenabled: truetags: "log"paths:- /tmp/ceshi.logparsers:- multiline:type: countcount_lines: 3- type: filestreamenabled: truetags: "shopping"paths:- /tmp/shopping.jsonparsers:- multiline:type: countcount_lines: 7- ndjson:add_error_key: trueoverwrite_keys: truetarget: shoppingoutput.elasticsearch:hosts: - "http://10.0.0.101:9200"- "http://10.0.0.102:9200"- "http://10.0.0.103:9200"indices:- index: "filebeate-14-json-docker-%{+yyyy.MM.dd}"when.contains:tags: "json"- index: "filebeate-14-log-%{+yyyy.MM.dd}"when.contains:tags: "log"- index: "filebeate-14-shopping-%{+yyyy.MM.dd}"when.contains:tags: "shopping"setup.ilm.enabled: false
setup.template.name: "filebeate-14"
setup.template.pattern: "filebeate-14-*"
setup.template.overwrite: true
setup.template.settings:index.number_of_shards: 4index.number_of_replicas: 1
解析:这个配置是针对有多个数据源采集到es集群的一个例子。三个type分别代表三个数据源,output.elasticsearch.hosts设置了es集群的ip,includes下三个index分别包含上面的三个type,注意这里的index名称需要和下面设置的setup.template.pattern匹配,否则索引模板不生效。可以通过curl 10.0.0.101:9200/filebeate-14-shopping-2025.01.23/_search,检验数据是否成功写入,详见之前文档,这里不多赘述。另外,值得注意的是,副本分片数量应该小于节点数量(可写入节点)。
4.logstash的安装
二进制安装:
1.解压安装包:tar xf logstash-7.17.5-linux-x86_64.tar.gz -C /app/softwares/
2.创建软链接:ln -svf /app/softwares/logstash-7.17.5/bin/logstash /usr/local/sbin/
3.验证logstash版本:logstash -V
4.基于命令行启动logstash实例:logstash -e "input { stdin { type => stdin } } output { stdout {} }"
5.编写第一个logstash
[root@elk101.lxcedu.com ~]# vim config/01-stdin-to-stdout.conf
input {stdin { type => stdin }
}output {stdout {}
}6.logstash搭配filebeat实战案例
1.编写logstash配置文件并启动(输入为filebeat的输入,输出到es集群)
vim 02-beats-to-stdout.conf
input {# 指定输入的类型是一个beatsbeats {# 指定监听的端口号port => 8888}
}output {# 将数据写入ES集群elasticsearch {# 指定ES主机地址hosts => ["http://localhost:9200"]# 指定索引名称index => "my-logstash01"}
}logstash -rf 02-beats-to-stdout.conf
2.启动filebeat实例并写入数据
[root@elk101.lxcedu.com /app/softwares/filebeat-7.17.5-linux-x86_64/config]# vim 18-nginx-to-logstash.yaml
filebeat -e -c 18-nginx-to-logstash.yaml
filebeat.inputs:
- type: logpaths:- /var/log/nginx/access.log*# 将数据输出到logstash中
output.logstash:# 指定logstash的主机和端口hosts: ["10.0.0.101:8888"]
7.logstash的过滤插件之geoip实战案例:
1.logstash配置文件
vim config03-beats-geoip-es.conf
input { # 指定输入的类型是一个beatsbeats {# 指定监听的端口号port => 8888}
} filter {# 根据IP地址分析客户端的经纬度,国家,城市信息等。geoip {source => "clientip"remove_field => [ "agent","log","input","host","ecs","tags" ]}}output { # 将数据写入ES集群elasticsearch {# 指定ES主机地址hosts => ["http://localhost:9200"]# 指定索引名称index => "geoip-logstash"}
}logstash -rf config/03-beats-geoip-es.conf
(2)filebeat采集数据到logstash
filebeat.inputs:
- type: logpaths:- /var/log/nginx/access.log*json.keys_under_root: truejson.add_error_key: true# 将数据输出到logstash中
output.logstash:# 指定logstash的主机和端口hosts: ["10.0.0.101:8888"]
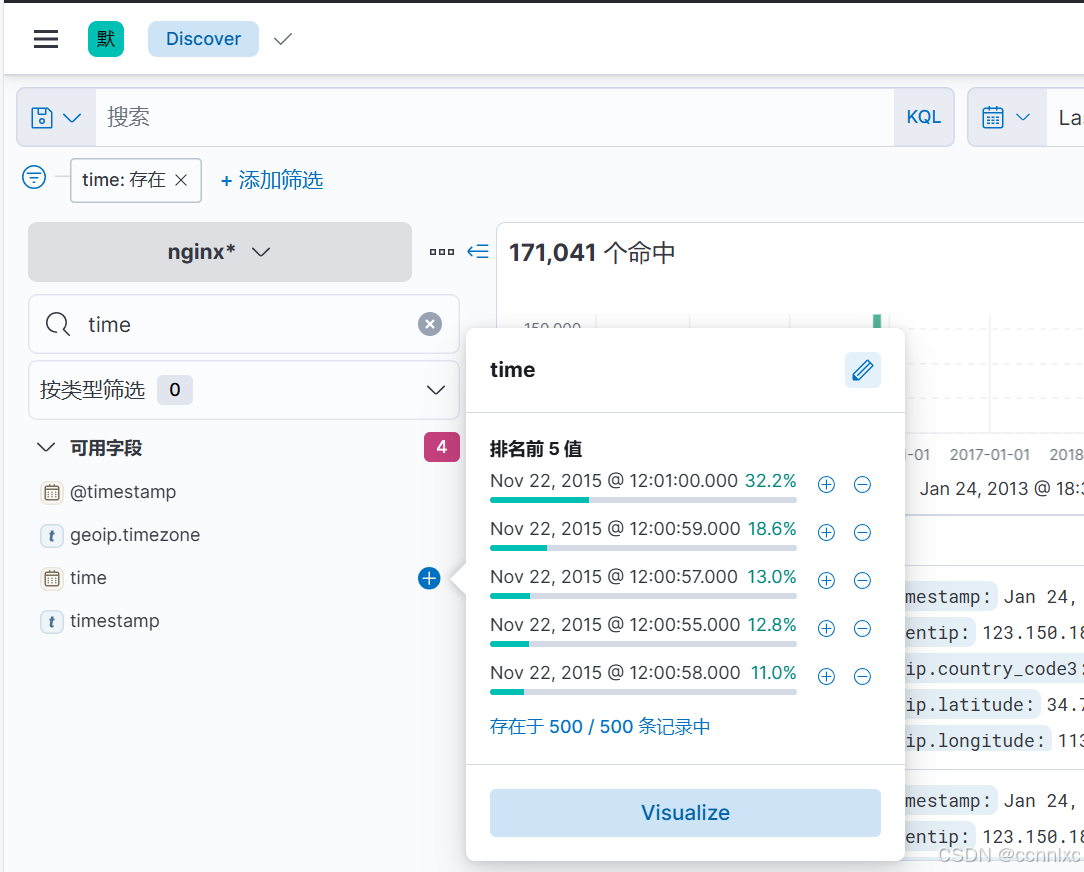
此时在kibana创建索引模式,

之后便可在Discover筛选出需要的值,进行查看

8.logstash解析nginx原生日志,并分析IP地址实战和修改日期字段数据类型
最好先创建索引模板,规划好分片和副本数量
1.logstash配置文件
vim config/04-beats-grok_geoip-es.conf
input { beats {port => 8888}
} filter {#使用%%{HTTPD_COMBINEDLOG}解析日志grok {match => { "message" => "%{HTTPD_COMBINEDLOG}" }remove_field => [ "agent","log","input","host","ecs","tags" ]}geoip {source => "clientip"}date {# 匹配时间字符串字段并格式化# "22/Nov/2015:11:57:34 +0800",默认timestamp是keyword类型,不格式化无法在kbina分析match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]# 匹配时区,可省略timezone => "Asia/Shanghai"# 将转后的日期替换为指定字段,若不指定,则默认值为"@timestamp"target => "time"}}output { #stdout {} elasticsearch {hosts => ["http://localhost:9200"]index => "nginx-logstash"}
}
启动:logstash -rf config/04-beats-grok_geoip-es.conf
2.filebeat采集数据到logstash
filebeat.inputs:
- type: logpaths:- /tmp/access.log# 将数据输出到logstash中
output.logstash:# 指定logstash的主机和端口hosts: ["10.0.0.101:8888"]
启动:filebeat -e -c 19-nginx-to-logstash.yaml
如下图kibana采集到的数据,可以看出上述对时间字段的修改生效
以上参考官方文档:
Logstash Introduction | Logstash Reference [7.17] | Elastic
grok正则匹配参考:
Grok filter plugin | Logstash Reference [7.17] | Elastic
相关文章:
日志收集Day005
1.filebeat的input类型之filestream实战案例: 在7.16版本中已经弃用log类型,之后需要使用filebeat,与log不同,filebeat的message无需设置就是顶级字段 1.1简单使用: filebeat.inputs: - type: filestreamenabled: truepaths:- /tmp/myfilestream01.lo…...

代码随想录 二叉树 test 2
二叉树的非递归遍历 先序 方法一: 先保存根节点,用来之后找到右子树(利用栈来回溯到根,进而找到右子树) class Solution { public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res; //存遍历序列stack<TreeNode*…...

浏览器默认语言与页面访问统计问题二三则
文章目录 前言网站默认语言问题网站访问统计问题Error: Empty components are self-closingError: A space is required before closing bracket 总结 前言 看标题大概能猜到这是一篇杂合体的总结,是这两天处理网站遇到的小问题,怕过段时间再忘了所以总…...

用Python绘制一只懒羊羊
目录 一、准备工作 二、Turtle库简介 三、绘制懒羊羊的步骤 1. 导入Turtle库并设置画布 2. 绘制头部 3. 绘制眼睛 4. 绘制嘴巴 5. 绘制身体 6. 绘制四肢 7. 完成绘制 五、运行代码与结果展示 六、总结 在这个趣味盎然的技术实践中,我们将使用Python和Turtle图形…...

虹科分享 | 汽车NVH小课堂之听音辨故障
随着车主开始关注汽车抖动异响问题,如何根据故障现象快速诊断异响来源,成了汽修人的必修课。 一个比较常用的方法就是靠“听”——“听音辨故障”。那今天,虹科Pico也整理了几个不同类型的异响声音,一起来听听看你能答对几个吧 汽…...

论文速读|SigLIP:Sigmoid Loss for Language Image Pre-Training.ICCV23
论文地址:https://arxiv.org/abs/2303.15343v4 代码地址:https://github.com/google-research/big_vision bib引用: misc{zhai2023sigmoidlosslanguageimage,title{Sigmoid Loss for Language Image Pre-Training}, author{Xiaohua Zhai and…...
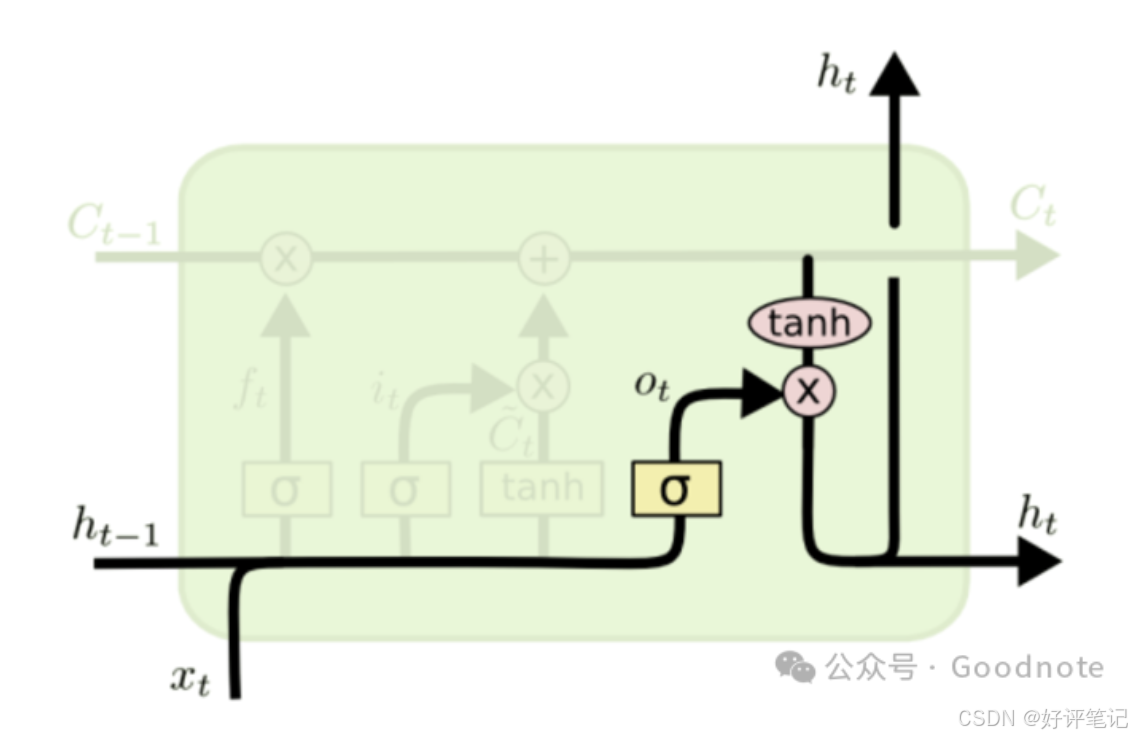
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...
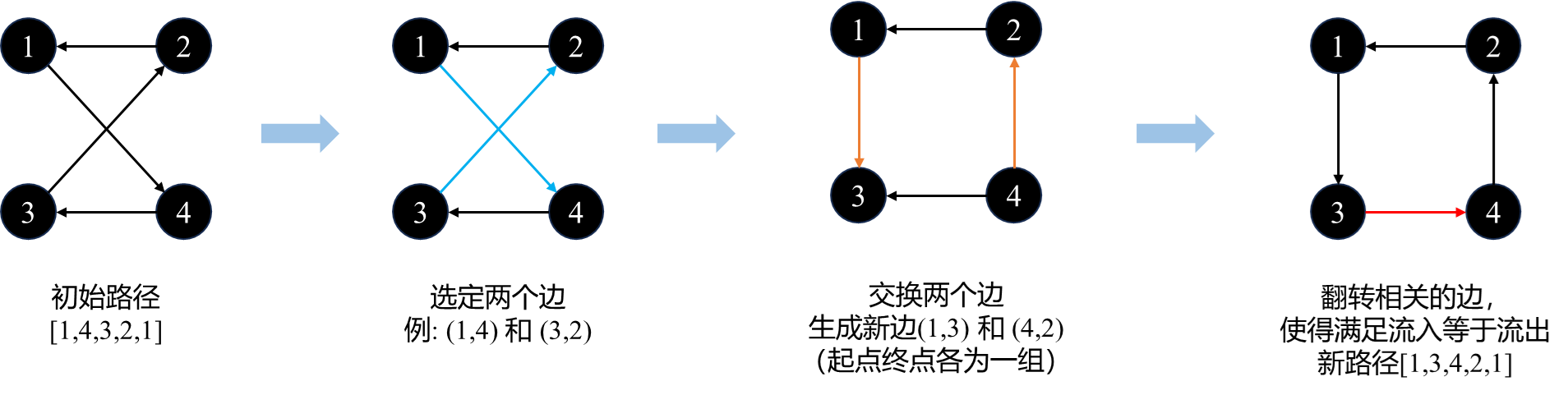
算法整理:2-opt求解旅行商(Python代码)
文章目录 算法思想算法步骤代码1纯函数代码2纯函数数据可视化 算法思想 通过交换边进行寻优。 算法步骤 把初始解作为当前解 通过交换边生成新解 如果新解优于历史最优解,则更新当前解为新解 重复2,3,直到当前解交换了所有的边均不能改…...

状态模式
在软件开发过程中,我们经常会遇到这样的情况:一个对象的行为会随着其内部状态的改变而发生变化。例如,一个手机在不同状态下(开机、关机、静音等)对相同的操作(如来电)会有不同的反应。传统的解…...

RoHS 简介
RoHS(Restriction of Hazardous Substances Directive,限制有害物质指令)是欧盟制定的一项环保法规,旨在限制电气和电子设备中某些有害物质的使用,以减少这些产品对环境和人体健康的危害。 RoHS限制的有害物质及其限量…...

【Vim Masterclass 笔记26】S11L46:Vim 插件的安装、使用与日常管理
文章目录 Section 11:Vim PluginsS11L46 Managing Vim Plugins1 第三方插件管理工具2 安装插件使用的搜索引擎3 Vim 插件的安装方法4 存放 Vim 插件包的路径格式5 示例一:插件 NERDTree 的安装6 示例二:插件 ctrlp.vim 的安装7 示例三&#x…...

深度学习原理与Pytorch实战
深度学习原理与Pytorch实战 第2版 强化学习人工智能神经网络书籍 python动手学深度学习框架书 TransformerBERT图神经网络: 技术讲解 编辑推荐 1.基于PyTorch新版本,涵盖深度学习基础知识和前沿技术,由浅入深,通俗易懂…...

ELK环境搭建
文章目录 1.ElasticSearch安装1.安装的版本选择1.SpringBoot版本:2.4.2 找到依赖的spring-data-elasticsearch的版本2.spring-data-elasticsearch版本:4.1.3 找到依赖的elasticsearch版本3.elasticsearch版本:7.9.3 2.安装1.官方文档2.下载压…...
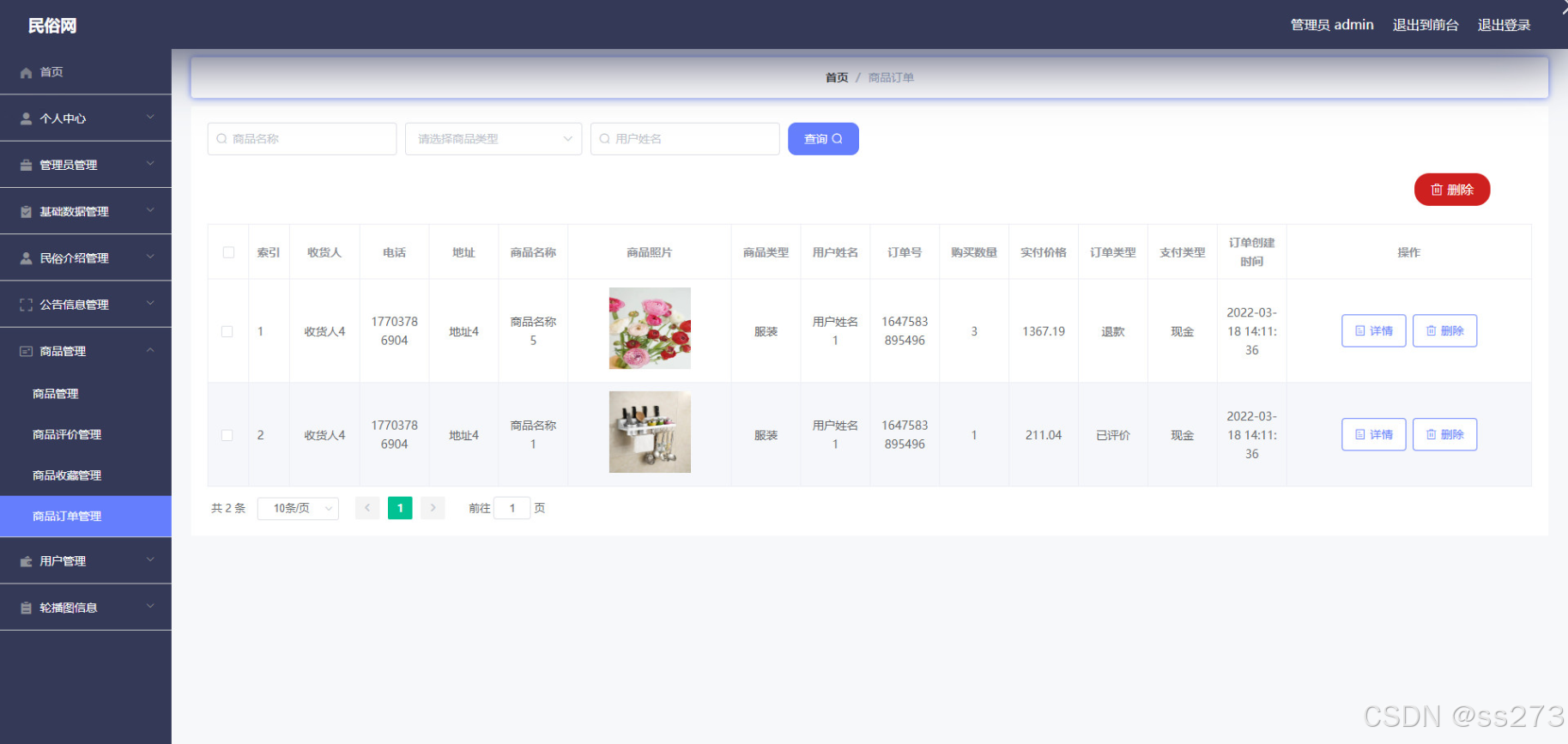
基于Springboot + vue实现的民俗网
“前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:人工智能学习网站” 💖学习知识需费心, 📕整理归纳更费神。 🎉源码免费人人喜…...
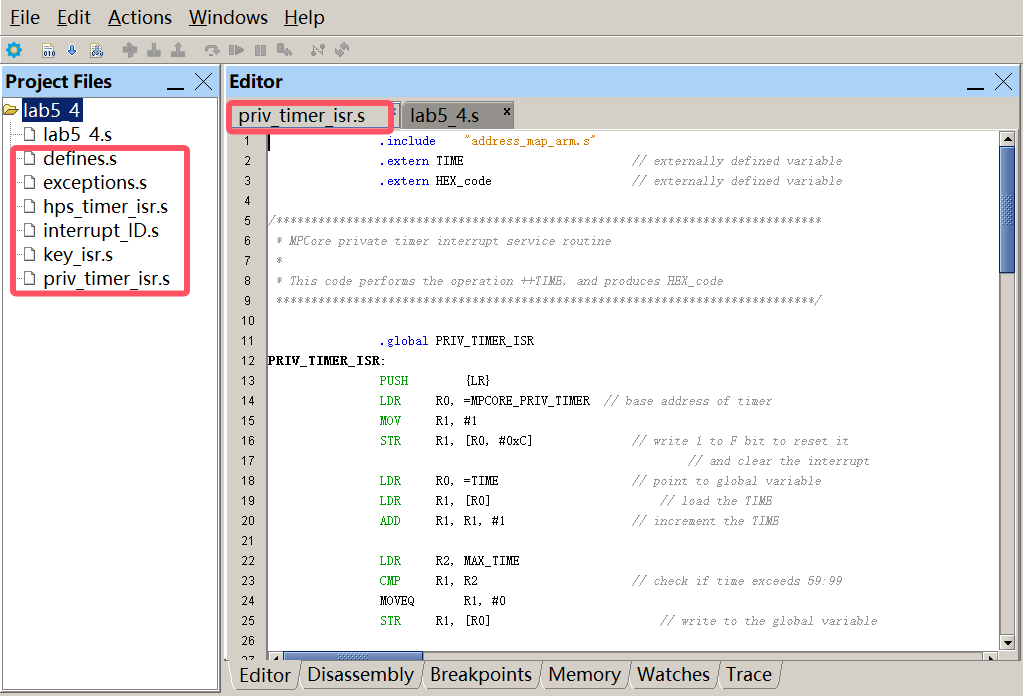
第24篇 基于ARM A9处理器用汇编语言实现中断<六>
Q:怎样设计ARM处理器汇编语言程序使用定时器中断实现实时时钟? A:此前我们曾使用轮询定时器I/O的方式实现实时时钟,而在本实验中将采用定时器中断的方式。新增第三个中断源A9 Private Timer,对该定时器进行配置&#…...
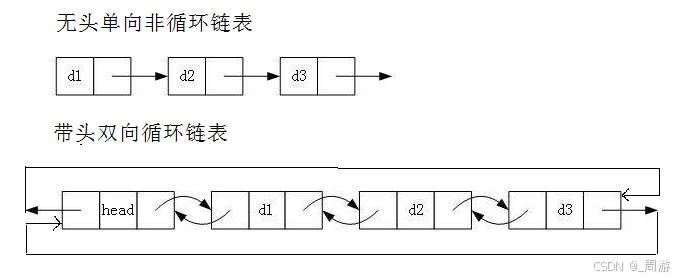
【数据结构】_不带头非循环单向链表
目录 1. 链表的概念及结构 2. 链表的分类 3. 单链表的实现 3.1 SList.h头文件 3.2 SList.c源文件 3.3 Test_SList.c测试文件 关于线性表,已介绍顺序表,详见下文: 【数据结构】_顺序表-CSDN博客 本文介绍链表; 基于顺序表…...

golang 使用双向链表作为container/heap的载体
MyHeap:container/heap的数据载体,需要实现以下方法: Len:堆中数据个数 Less:第i个元素 是否必 第j个元素 值小 Swap:交换第i个元素和 第j个元素 Push:向堆中追加元素 Pop:从堆…...

C#集合操作优化:高效实现批量添加与删除
在C#中,对集合进行批量操作(如批量添加或删除元素)通常涉及使用集合类型提供的方法和特性,以及可能的循环或LINQ查询来高效地处理大量数据。以下是一些常见的方法和技巧: 批量添加元素 使用集合的AddRange方法&#x…...

142.WEB渗透测试-信息收集-小程序、app(13)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于: 易锦网校会员专享课 上一个内容:141.WEB渗透测试-信息收集-小程序、app(12) 软件用法,…...

24.日常算法
1. 数组中两元素的最大乘积 题目来源 给你一个整数数组 nums,请你选择数组的两个不同下标 i 和 j,使 (nums[i]-1)*(nums[j]-1) 取得最大值。请你计算并返回该式的最大值。 示例 1: 输入:nums [3,4,5,2] 输出:12 解释…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...