Elastic Agent 对 Kafka 的新输出:数据收集和流式传输的无限可能性
作者:来 Elastic Valerio Arvizzigno, Geetha Anne 及 Jeremy Hogan

介绍 Elastic Agent 的新功能:原生输出到 Kafka。借助这一最新功能,Elastic® 用户现在可以轻松地将数据路由到 Kafka 集群,从而实现数据流和处理中无与伦比的可扩展性和灵活性。在本文中,我们将深入探讨这种强大集成的优势和用例。
Elasticsearch 和 Kafka:更好的结合用例
在物联网 (IoT)、自动化工厂和汽车或制造业等行业复杂的 IT 架构不断发展的格局中,精确和实时数据至关重要。想象一下高科技汽车工厂的生产线,成千上万的传感器不断监测机器的性能,从机械臂的精确扭矩到关键发动机部件的温度。想想每天有多少分布式设备围绕着我们,需要远程管理、监控和保护,以确保最佳用户体验,同时为企业收集有价值的数据。在这种动态环境中,对高效数据采集、实时处理和强大的数据存储与分析的需求不仅仅是一种偏好,更是绝对必要。
正是在这里,凭借强大的数据流功能,Kafka 成为关键技术,将物联网和分布式系统世界与市场上领先的洞察引擎 Elasticsearch® 无缝连接,从而实现快速决策、预测性维护和增强的运营洞察。
在本文中,我们将探讨 Confluent Kafka 和 Elasticsearch 如何协同使用,通过新的 Elastic Agent 集成提供无与伦比的洞察、弹性和效率。
Elastic Agent 的 Kafka 输出解锁了新可能性
Kafka 通常是高效管理大规模数据场景的首选,许多 Elastic 用户已经在其环境中采用 Kafka,用于 Beats 和 Elasticsearch 集群之间的多种用例。长期以来,Beats 一直集成了原生的 Kafka 输出功能,许多客户对此非常满意。而如今,同样的功能也在 Elastic Agent中得以实现。Elastic Agent 是我们统一的解决方案,用于监控每个托管主机上的指标、收集日志并应对网络威胁。那么,这一 Elastic Agent 新功能为何如此重要?又有哪些理由让你今天就开始使用它?
Elastic Agent 比 Beats 有几个优势:
- 更易于部署和管理:Elastic Agent 是一个单一代理,可下载、配置和管理收集和解析数据所需的任何底层策略或组件。这样就无需部署多个 Beats 并为主机上运行的每个 Beat 管理单独的配置文件。
- 配置更简单:你无需为每个 Beat 定义和管理单独的配置文件,只需定义一个代理策略(agent policy)来指定要使用的集成设置,然后 Elastic Agent 会生成底层工具所需的配置。
- 集中管理:Elastic Agent 可以从 Kibana® 中名为 Fleet 的中心位置进行管理。在 Fleet 中,你可以查看正在运行的 Elastic Agent 的状态,更新代理策略并将其推送到你的主机,甚至触发二进制升级。不再需要 SSH 到你的主机或软件管理工具。
- 端点保护:Elastic Agent 使你能够保护你的端点免受安全威胁。这使客户能够使用他们正在收集的数据上的新安全用例来扩展他们的 Elastic 价值,而无需额外的工具或精力。
有了这些优势和功能,管理和保护你的分布式系统从未如此简单!要为 Fleet 管理的代理注册新的 Kafka 输出,你只需执行以下操作:
- 在 Kibana UI 中打开 Fleet 的 “Settings” 选项卡。
- 在 “Output” 部分,Add output。
- 为新输出命名并选择 Kafka 作为输出 Type。
- 填写你的场景所需的所有相关 Kafka 集群字段,例如 Kafka 代理的 hostname、authentication 详细信息或 SSL 配置。
- Save and apply settings。

你将能够设置分区规则和要发送数据的主题,该主题/topic 是静态定义的。
Kafka 输出将在代理策略创建阶段可用,其中可以为集成和代理监控流设置它,并自动应用于你决定将它们附加到的代理。

你可以在我们的官方文档中探索所有详细信息和选项,也可以通过分步配置指南进行指导。
配置 Elastic Agent 到 Kafka 的新输出
借助此新发布的集成,现有使用 Beats 的 Kafka 用户将能够将其工作负载切换到 Elastic Agent,并从上述所有增强的可观察性和安全性场景中受益。此外,当前的 Elastic Agent 用户将不再有障碍来评估和采用 Kafka 作为其 Elastic 端到端数据流合作伙伴。
架构概述

在上面的整体架构图中,Elastic Agent、Confluent Kafka 和 Elastic Cloud 被显示为数据旅程的主要组件。
Elastic Agent 将通过其原生集成从大量主机和系统收集日志和指标,并与 Confluent Cloud 连接器一起处理来自多个数据源的事件和事务数据,从而产生无限的可能性,以在单一窗格中收集、整合和丰富你的企业数据。
然后,Kafka 将接收这些不同的数据流并对其进行处理并将其分发给相关消费者。对于需要强大转换的高级场景(例如,本机 IP 地理定位、从非结构化数据中获取结构化数据、PII 屏蔽),Logstash® 可以插入 Kafka 和 Elasticsearch 之间,这要归功于其专用的输入和输出插件。对于从 Kafka 到 Elasticsearch 的直接无缝流式传输,最好的选择是利用 Elasticsearch Sink Connector,只需通过 Confluent UI 单击几下即可进行配置。
一旦数据进入 Elastic,数据就会开始发光,借助 Elasticsearch 和 Kibana 的搜索、分析和可视化功能,展现其价值。我们将在以下部分中更详细地介绍这一点。
Confluent Kafka 对 Elastic 工作负载的好处
Confluent 的 Kafka 与 Elasticsearch 集成以处理 Elastic 工作负载时具有多种优势,尤其是在需要实时或近实时处理和分析大量数据的场景中。将 Kafka 与 Elasticsearch 结合使用以处理 Elastic 工作负载的一些主要优势包括:
1. 完全托管服务
Confluent Cloud 是一种完全托管服务,这意味着 Confluent 负责底层基础设施,包括硬件配置、软件维护和集群扩展。这减轻了你团队的运营开销,让你可以专注于构建应用程序和处理数据。
2. 实时数据提取
Kafka 擅长实时收集和提取数据,是将数据流式传输到 Elasticsearch 的理想选择。Confluent 连接器旨在简化从 Kafka 到 Elasticsearch 和从 Elasticsearch 到 Kafka 的流式传输数据的过程,从而更轻松地为各种用例(包括日志和事件数据分析)构建实时数据管道。Confluent Elastic connectors 包括:
- Confluent Elasticsearch Sink 连接器:此连接器用于将数据从 Kafka 主题发送到 Elasticsearch 进行索引和搜索。它允许你指定从哪些 Kafka 主题使用数据以及将数据写入哪些 Elasticsearch 索引。连接器支持多种数据格式,包括 JSON、Avro 等。
- Confluent HTTP Sink 连接器:此连接器从 Kafka 主题使用记录并将其转换为字符串或 JSON,然后将其发送到配置的 API URL(在本例中为 Elastic API 端点)。这在需要完全可自定义的 API 调用的场景中非常有用。
- Confluent Elasticsearch 源连接器:此连接器用于从 Elasticsearch 中提取数据并将其流式传输到 Kafka 主题。它允许你创建主题并将 Elasticsearch 索引映射到 Kafka 主题以进行数据同步。
3. 数据聚合和转换
Kafka 可以充当数据的缓冲区,允许你在将数据索引到 Elasticsearch 之前执行数据聚合和转换。Confluent 开发了 KSQL 和相关数据存储 (ksqlDB),它们是类似 SQL 的查询工具,用于将流数据直接处理到 Kafka 中。这简化了实时数据处理,使用户能够轻松创建应用程序,并为准备要在 Kibana 中搜索和可视化的数据提供帮助。
4. 可扩展性
Kafka 具有高度可扩展性,可以处理高数据吞吐量。它允许你水平和垂直扩展以适应不断增长的数据工作负载。这确保你的 Elastic 工作负载能够跟上不断增长的数据量和处理需求,而 Kafka 是其抵御意外峰值和摄入压力的盾牌。Confluent Cloud 允许你随着数据和工作负载需求的增长无缝扩展 Kafka 集群。你可以轻松调整集群大小、存储和吞吐量以适应数据量和处理需求的变化。
5. 数据源和消费者解耦
Kafka 充当数据源和 Elasticsearch 之间的中介。这种解耦允许你添加或删除数据生产者和消费者,而不会影响整个系统的稳定性。它还可以确保当 Elasticsearch 或连接网络发生故障时数据不会丢失。
6. 优化 Elasticsearch 索引
通过使用 Confluent 的 Kafka 作为中介,你可以优化 Elasticsearch 中的索引过程。数据可以在发送到 Elasticsearch 之前进行批处理和压缩,从而减少 Elasticsearch 集群上的负载。
7. 统一数据集成
Kafka 可以很好地与各种数据源和接收器集成。它可以从各种系统中提取数据,从而更容易将数据集中到 Elasticsearch 中进行全面分析。Elastic Agent 与 Kafka 集成相结合,为你提供了收集和移动数据的无限可能性。
8. 与 Logstash 合作
Kafka 插件允许 Logstash 使用来自 Apache Kafka 主题的数据作为输入,或将数据发送到 Kafka 主题作为输出。这些插件是更广泛的 Logstash 生态系统的一部分,被广泛用于在各种工作流程中将 Logstash 与 Kafka 集成。
- Kafka 输入插件:Kafka 输入插件允许 Logstash 使用来自一个或多个 Kafka 主题的消息并在 Logstash 中处理它们。你可以配置 Kafka 输入插件以订阅特定主题、使用消息,然后应用各种 Logstash 过滤器来根据需要转换和丰富数据。
- Kafka 输出插件:Kafka 输出插件允许 Logstash 将处理后的数据发送到 Kafka 主题。在 Logstash 中处理和丰富数据后,你可以使用此插件将数据发布到特定的 Kafka 主题,使其可供其他应用程序或系统的下游处理。
使用 Elastic Cloud 搜索洞察并检测异常
一旦数据进入 Elastic,就会产生无限可能来从中创造价值。例如,通过 Elasticsearch,预测分析的应用可实现预测性维护。通过利用传感器数据(包括气压、油压、温度、电压、速度、声音、频率以及颜色或照明变化等参数),Elasticsearch 有助于及早发现潜在的设备故障。这种实时数据分析与 Elasticsearch 强大的搜索和查询功能相结合,不仅可以作为预警系统,还可以为数据驱动的决策提供宝贵的洞察。最终结果是降低成本并制定更有效的维护策略,从而实现卓越运营。
此外,Elasticsearch 还使生产管理人员能够根据实时数据和自适应阈值制定个性化的维护计划,从而增强生产管理能力。这种动态方法取代了僵化的维护周期,在僵化的维护周期中,无论组件是否容易发生故障,都会进行更换。 Elasticsearch 的搜索和可视化功能(尤其是在利用 Kibana 功能时)提供了数据趋势和异常值的全面视图,从而有助于制定更有意义且更具成本效益的策略。同样的原则也适用于更高的抽象层,例如本地和云 IT 架构和应用程序,在这些架构和应用程序中,弹性和业务连续性是日益重要的主题,并且通常对制造流程至关重要。
尽管如此,实时分析来自大量传感器、设备和服务的数据并将其与历史事件进行比较的挑战对于人类操作员来说是一项艰巨的任务。这正是 Elasticsearch 的异常检测功能与其机器学习功能相结合发挥作用的地方。借助 Elastic,你可以有效地查明偏差或关联来自多个来源的数据以生成全面的健康评分。这种宝贵的功能使企业能够通过数据驱动的机制领先于潜在问题并主动响应。
除了增强预测性维护和质量控制外,Elasticsearch 在确保分布式架构和主机的安全性方面也发挥着至关重要的作用。 Elastic SIEM 和端点保护解决方案可全面监控、预防、检测和响应安全事件和威胁,确保业务连续性和合规性。
使用 Elasticsearch 和 Kafka,可以从制造厂或 IT 架构内的各种系统(从运行旧软件的传统系统到尖端技术)收集数据并将其转化为业务洞察,这是一个无缝流程。此外,在成本优化和工具整合的时代,没有比这更好的地方可以在单一管理平台中实现所有搜索、可观察性和安全性目标。
探索更多并试用!
了解 BMW 等客户如何利用 Elastic 构建弹性多渠道客户体验,并借助 Confluent Cloud 整合跨多个系统和应用程序的生产和销售数据流。
查看我们的 7 分钟教程或博客文章,详细了解如何通过 Elasticsearch Sink Connector 将 Confluent Cloud 与 Elastic 集成。 是否还想利用 Elastic 来监控 Kafka 集群本身? 通过这篇文章和我们的 Kafka 可观察性集成文档了解更多信息。
将数据从 Confluent Cloud 索引到 Elastic Cloud
亲自尝试一下! 开始使用和探索我们功能的最简单方法之一是使用你自己的免费 Elastic Cloud 试用版和 Confluent Cloud 试用环境,或者通过你最喜欢的云提供商的市场进行订阅。
原文:Elastic Agent’s new output to Kafka: Endless possibilities for data collection and streaming | Elastic Blog
相关文章:
Elastic Agent 对 Kafka 的新输出:数据收集和流式传输的无限可能性
作者:来 Elastic Valerio Arvizzigno, Geetha Anne 及 Jeremy Hogan 介绍 Elastic Agent 的新功能:原生输出到 Kafka。借助这一最新功能,Elastic 用户现在可以轻松地将数据路由到 Kafka 集群,从而实现数据流和处理中无与伦比的可扩…...

论文速读|Is Cosine-Similarity of Embeddings Really About Similarity?WWW24
论文地址: https://arxiv.org/abs/2403.05440 https://dl.acm.org/doi/abs/10.1145/3589335.3651526 bib引用: inproceedings{Steck_2024, series{WWW ’24},title{Is Cosine-Similarity of Embeddings Really About Similarity?},url{http://dx.doi.o…...

Midjourney中的强变化、弱变化、局部重绘的本质区别以及其有多逆天的功能
开篇 Midjourney中有3个图片“微调”,它们分别为: 强变化;弱变化;局部重绘; 在Discord里分别都是用命令唤出的,但如今随着AI技术的发达在类似AI可人一类的纯图形化界面中,我们发觉这样的逆天…...
)
基于 Node.js 的天气查询系统实现(附源码)
项目概述 这是一个基于 Node.js 的全栈应用,前端使用原生 JavaScript 和 CSS,后端使用 Express 框架,通过调用第三方天气 API 实现天气数据的获取和展示。 主要功能 默认显示多个主要城市的天气信息 支持城市天气搜索 响应式布局设计 深色主题界面 优雅的加载动画 技术栈 …...

时序数据库的使用场景
文章目录 前言一、特点二、工作原理三、常见的时序数据库四、使用场景优势总结 前言 时序数据库(Time Series Database, TSDB) 是一种专门设计用于存储和处理时序数据的数据库。时序数据是指按照时间顺序排列的数据,其中每个数据点通常包含时…...

计算机的错误计算(二百二十二)
摘要 利用大模型化简计算 实验表明,虽然结果正确,但是,大模型既绕了弯路,又有数值计算错误。 与前面相同,再利用同一个算式看看另外一个大模型的化简与计算能力。 例1. 化简计算摘要中算式。 下面是与一个大模型的…...

ThinkPHP 8模型与数据的插入、更新、删除
【图书介绍】《ThinkPHP 8高效构建Web应用》-CSDN博客 《2025新书 ThinkPHP 8高效构建Web应用 编程与应用开发丛书 夏磊 清华大学出版社教材书籍 9787302678236 ThinkPHP 8高效构建Web应用》【摘要 书评 试读】- 京东图书 使用VS Code开发ThinkPHP项目-CSDN博客 编程与应用开…...
)
c语言函数(详解)
目录 前言 一、函数的基本概念和作用 二、函数的声明和定义 三、函数参数的传递方式 四、函数的递归 五、函数指针 总结 前言 本文主要讲解了c语言函数方面的内容 函数的定义和调用函数的返回值和参数函数的作用域和生命周期 函数的声明和定义 函数声明和函数定义的区别函数声…...

为AI聊天工具添加一个知识系统 之70 详细设计 之11 维度运动控制的应用:上下文受控的自然语言
本文要点 要点 前面我们 讨论了 “维度”及其运动控制原理 以及 维度控制 如何在中台微服务架构中撑起了“架构师”角色的一片天。下面我们从 “维度”运动控制的一个典型应用场景:受控的自然语言 ”开始讨论。 拼块文字型风格: 维度运动控制下的受控自然语言…...

ios打包:uuid与udid
ios的uuid与udid混乱的网上信息 新人开发ios,发现uuid和udid在网上有很多帖子里是混淆的,比如百度下,就会说: 在iOS中使用UUID(通用唯一识别码)作为永久签名,通常是指生成一个唯一标识…...
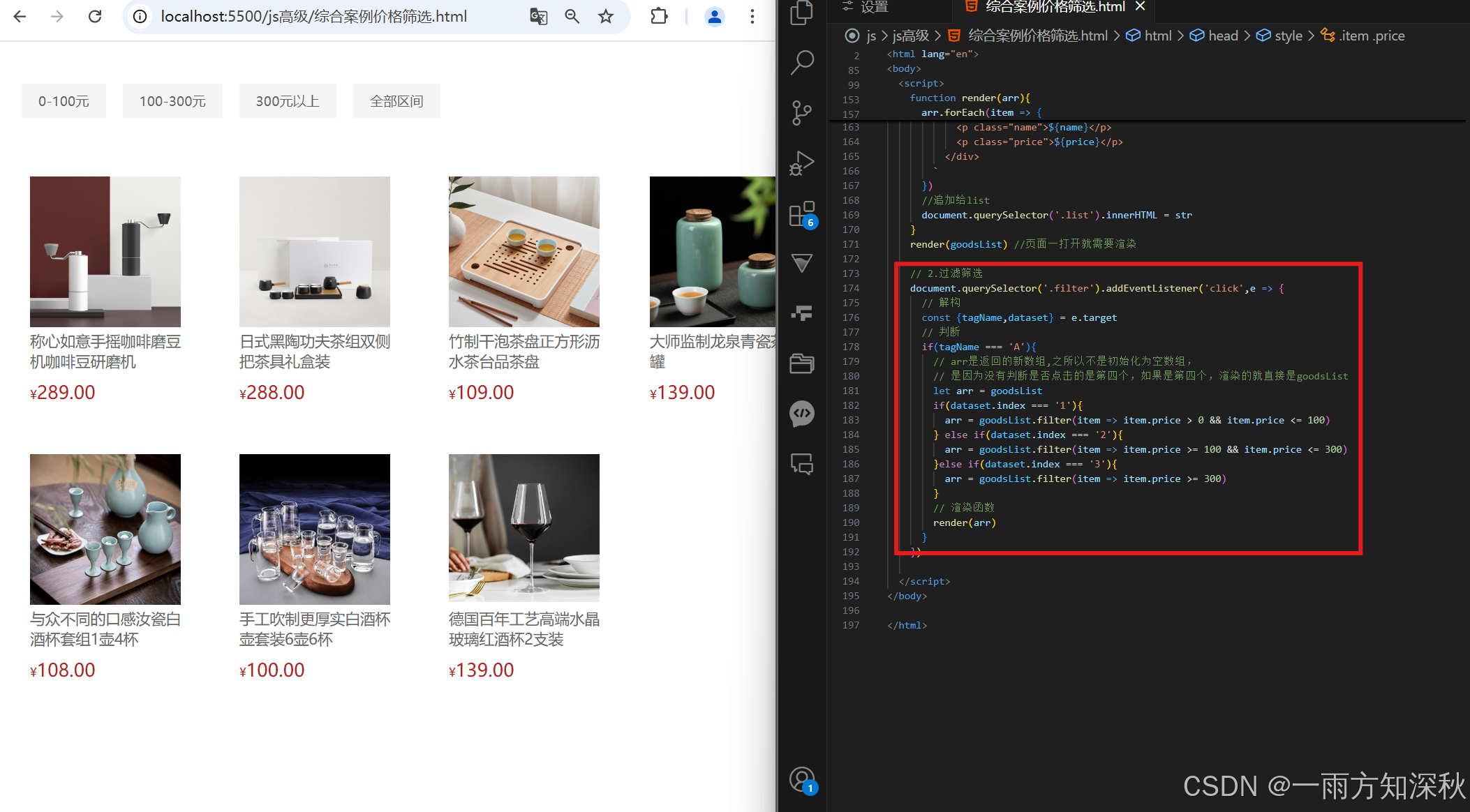
数组,对象解构,forEach方法,filter方法
数组解构 对象结构 遍历数组 forEach方法 筛选数组 filter方法 渲染商品案例 forEach遍历数组,能得到每个数组中的数据,item是对象中的每个元素 将遍历的数组中每个对象 加到 str 中 将 str 字符串中的 8 个 div 添加到 list盒子中 对象解构并渲染 综…...

PSPNet
文章目录 摘要Abstract1. 引言2. 框架2.1 金字塔池化模块2.2 特征提取器的监督2.3 训练细节 3. 创新点和不足3.1 创新点3.2 不足 参考总结 摘要 PSPNet是一个改进了FCN-8s缺点的语义分割模型,它解决了FCN-8s的缺点——分割不够精细以及没有考虑上下文信息。PSPNet的…...
:Understanding Diffusion Models: A Unified Perspective(二):公式46的推导)
论文阅读的附录(七):Understanding Diffusion Models: A Unified Perspective(二):公式46的推导
Understanding Diffusion Models: A Unified Perspective(二):公式46的推导 文章概括要推导的公式1. 条件概率的定义2. 联合分布的分解2.1 联合分布的定义2.2 为什么可以这样分解?2.3 具体意义 3. 分母的分解:边际化规…...

BGP分解实验·12——配置路由反射器
当一个AS包含多个iBGP对等体时,路由反射器(Route-Reflector)非常有用,因为相对于iBGP路由反射器指定的客户端只需要和路由反射器建立邻居关系,从而降低了iBGP全互连的连接数量。路由反射器(RR)和…...

PCIe 个人理解专栏——【2】LTSSM(Link Training and Status State Machine)
前言: 链路训练和状况状态机LTSSM(Link Training and Status State Machine)是整个链路训练和运行中状态的状态转换逻辑关系图,总共有11个状态。 正文: 包括检测(Detect),轮询&…...

cmake 编译QT之JKQtPlotter-4.0.3
cmake 编译 JKQtPlotter-4.0.3 1.下载源码 源码地址:https://github.com/jkriege2/JKQtPlotter 2.编译 mkdir build cd buildDCMAKE_PREFIX_PATH指编译器目录 D:\ProgramFiles\cmake-3.25.0-rc1-windows-i386\bin\cmake.exe -G "Visual Studio 16 2019&qu…...

【C】memory 详解
<memory.h> 是一个 C 标准库头文件,提供了一组内存管理函数,用于分配、释放和操作动态内存。这些函数主要操作的是未初始化的内存块,是早期 C 编程中常用的内存操作工具。 尽管在现代 C 编程中更推荐使用<cstring>或<memory&…...
Python 爬虫 - Selenium 框架
Python 爬虫 - Selenium 框架 安装安装 Selenium安装 WebDriver 操作浏览器打开浏览器普通方式加载配置方式Headless 方式 设置浏览器窗口最大化显示最小化显示自定义大小 前进后退前进后退 元素定位根据 id 定位根据 name 定位根据 class 定位根据标签名定位使用 CSS 定位使用…...

mysql的having语句
MySQL的HAVING语句用于在GROUP BY子句对数据进行分组后,过滤满足特定条件的组。与WHERE子句不同,HAVING子句可以在过滤条件中使用聚合函数,而WHERE子句则不能。通常,HAVING子句与GROUP BY子句一起使用,以实现对分组数据…...

华为数据之道-读书笔记
内容简介 关键字 数字化生产 已经成为普遍的商业模式,其本质是以数据为处理对象,以ICT平台为生产工具,以软件为载体,以服务为目的的生产过程。 信息与通信技术平台(Information and Communication Technology Platf…...

从混淆矩阵到Kappa系数:实战解析土地利用分类精度评估全流程
1. 土地利用分类精度评估入门指南 当你完成了一张精美的土地利用分类图,最常被问到的问题往往是:"这个结果到底有多准?"作为从业多年的GIS分析师,我见过太多人只关注分类过程却忽视精度验证,最后在项目汇报时…...

为什么JavaScript无法访问用户电脑的硬件信息
JavaScript和硬件信息访问:安全和信任的博弈许多人想知道:为什么JavaScript不能访问用户计算机的硬件信息?答案与安全和信任机制密切相关。虽然本地客户端软件可以访问硬件信息,但这是基于用户对软件的信任和授权。浏览器和客户端…...

Ryujinx:C编写的Nintendo Switch模拟器技术解析与应用指南
Ryujinx:C#编写的Nintendo Switch模拟器技术解析与应用指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款用C#编写的实验性Nintendo Switch模拟器ÿ…...

Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择
Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择 【免费下载链接】Mask2Former Code release for "Masked-attention Mask Transformer for Universal Image Segmentation" 项目地址: https://gitcode.com/gh_mirrors/ma/Mask2Former Ma…...

Qt 实时数据可视化工程实践:环形缓冲区实践
目录 前言 一、架构设计 1.1 分层架构图 1.2 数据写入流 1.3 数据刷新流 (定时器驱动 → 视图更新) 1.4 核心设计思想 二、核心实现详解 2.1 RingBuffer:环形缓冲区实现 2.1.1 append函数(线程安全写入) 函数主体实现: …...

单片机IO口驱动能力解析与LED驱动设计
1. 单片机IO口驱动能力基础概念刚接触单片机开发时,很多同学对IO口的驱动能力概念感到困惑。实际上,驱动能力直接决定了单片机引脚能带动多大的负载。以常见的51单片机为例,其IO口在输出低电平时的灌电流能力通常为10-20mA,而输出…...
)
用MQTT协议玩转OneNet物联网:STM32F103+ESP8266实现温湿度监控(附心跳包优化技巧)
STM32F103与ESP8266的物联网实战:MQTT协议深度优化与温湿度监控系统设计 1. 资源受限环境下的物联网通信架构设计 在嵌入式物联网设备开发中,资源优化始终是核心挑战。STM32F103C8T6作为经典的Cortex-M3内核微控制器,仅有64KB Flash和20KB RA…...

智汇云舟亮相2026中关村论坛 联合发起“通智行业大脑”联盟
3月29日,作为中关村论坛年会的重要组成部分,“迈向通用人工智能”平行论坛在中关村国家自主创新示范区展示交易中心隆重举行。本次论坛由北京市科学技术委员会、中关村科技园区管理委员会、北京市海淀区人民政府联合主办,北京通用人工智能研究…...
)
从零理解自然数系统:用Python类模拟皮亚诺公理(含加法乘法实现)
从零构建自然数系统:用Python类实现皮亚诺公理与算术运算 在计算机科学中,自然数系统的构建是一个令人着迷的基础课题。当我们抛开编程语言内置的数字类型,仅用最基本的类和递归概念来重新定义自然数时,会惊讶地发现数学的抽象之美…...

深度解析Synology Photos面部识别补丁:从技术原理到实战部署完整指南
深度解析Synology Photos面部识别补丁:从技术原理到实战部署完整指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch Synology Photos Fa…...