Python NumPy(8):NumPy 位运算、NumPy 字符串函数
1 NumPy 位运算
位运算是一种在二进制数字的位级别上进行操作的一类运算,它们直接操作二进制数字的各个位,而不考虑数字的整体值。NumPy 提供了一系列位运算函数,允许对数组中的元素进行逐位操作,这些操作与 Python 的位运算符类似,但作用于 NumPy 数组,支持矢量化处理,性能更高。
位运算在计算机科学中广泛应用于优化和处理底层数据。NumPy bitwise_ 开头的函数是位运算函数。NumPy 位运算包括以下几个函数:
| 操作 | 函数/运算符 | 描述 |
|---|---|---|
| 按位与 | numpy.bitwise_and(x1, x2) | 对数组的每个元素执行逐位与操作。 |
| 按位或 | numpy.bitwise_or(x1, x2) | 对数组的每个元素执行逐位或操作。 |
| 按位异或 | numpy.bitwise_xor(x1, x2) | 对数组的每个元素执行逐位异或操作。 |
| 按位取反 | numpy.invert(x) | 对数组的每个元素执行逐位取反(按位非)。 |
| 左移 | numpy.left_shift(x1, x2) | 将数组的每个元素左移指定的位数。 |
| 右移 | numpy.right_shift(x1, x2) | 将数组的每个元素右移指定的位数。 |
import numpy as nparr1 = np.array([True, False, True], dtype=bool)
arr2 = np.array([False, True, False], dtype=bool)result_and = np.bitwise_and(arr1, arr2)
result_or = np.bitwise_or(arr1, arr2)
result_xor = np.bitwise_xor(arr1, arr2)
result_not = np.bitwise_not(arr1)print("AND:", result_and) # [False, False, False]
print("OR:", result_or) # [True, True, True]
print("XOR:", result_xor) # [True, True, True]
print("NOT:", result_not) # [False, True, False]# 按位取反
arr_invert = np.invert(np.array([1, 2], dtype=np.int8))
print("Invert:", arr_invert) # [-2, -3]# 左移位运算
arr_left_shift = np.left_shift(5, 2)
print("Left Shift:", arr_left_shift) # 20# 右移位运算
arr_right_shift = np.right_shift(10, 1)
print("Right Shift:", arr_right_shift) # 5

也可以使用 "&"、 "~"、 "|" 和 "^" 等操作符进行计算:
- 与运算(&): 对应位上的两个数字都为1时,结果为1;否则,结果为0。
- 例如:1010 & 1100 = 1000
- 或运算(|): 对应位上的两个数字有一个为1时,结果为1;否则,结果为0。
- 例如:1010 | 1100 = 1110
- 异或运算(^): 对应位上的两个数字相异时,结果为1;相同时,结果为0。
- 例如:1010 ^ 1100 = 0110
- 取反运算(~): 对数字的每个位取反,即0变为1,1变为0。
- 例如:~1010 = 0101
- 左移运算(<<): 将数字的所有位向左移动指定的位数,右侧用0填充。
- 例如:1010 << 2 = 101000
- 右移运算(>>): 将数字的所有位向右移动指定的位数,左侧根据符号位或补零。
- 例如:1010 >> 2 = 0010
1.1 bitwise_and
bitwise_and() 函数对数组中整数的二进制形式执行位与运算。
import numpy as np print ('13 和 17 的二进制形式:')
a,b = 13,17
print (bin(a), bin(b))
print ('\n')print ('13 和 17 的位与:')
print (np.bitwise_and(13, 17))
以上实例可以用下表来说明:
| 1 | 1 | 0 | 1 | ||
|---|---|---|---|---|---|
| AND | |||||
| 1 | 0 | 0 | 0 | 1 | |
| 运算结果 | 0 | 0 | 0 | 0 | 1 |
位与操作运算规律如下:
| A | B | AND |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
1.2 bitwise_or
bitwise_or()函数对数组中整数的二进制形式执行位或运算。
import numpy as npa, b = 13, 17
print('13 和 17 的二进制形式:')
print(bin(a), bin(b))print('13 和 17 的位或:')
print(np.bitwise_or(13, 17))

以上实例可以用下表来说明:
| 1 | 1 | 0 | 1 | ||
|---|---|---|---|---|---|
| OR | |||||
| 1 | 0 | 0 | 0 | 1 | |
| 运算结果 | 1 | 1 | 1 | 0 | 1 |
位或操作运算规律如下:
| A | B | OR |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
1.3 invert
invert() 函数对数组中整数进行位取反运算,即 0 变成 1,1 变成 0。对于有符号整数,取该二进制数的补码,然后 +1。二进制数,最高位为0表示正数,最高位为 1 表示负数。看看 ~1 的计算步骤:
- 将
1(这里叫:原码)转二进制 =00000001 - 按位取反 =
11111110 - 发现符号位(即最高位)为
1(表示负数),将除符号位之外的其他数字取反 =10000001 - 末位加1取其补码 =
10000010 - 转换回十进制 =
-2
| 表达式 | 二进制值(2 的补数) | 十进制值 |
|---|---|---|
| 5 | 00000000 00000000 00000000 00000101 | 5 |
| ~5 | 11111111 11111111 11111111 11111010 | -6 |
import numpy as npprint('13 的位反转,其中 ndarray 的 dtype 是 uint8:')
print(np.invert(np.array([13], dtype=np.uint8)))
print('\n')
# 比较 13 和 242 的二进制表示,我们发现了位的反转print('13 的二进制表示:')
print(np.binary_repr(13, width=8))
print('\n')print('242 的二进制表示:')
print(np.binary_repr(242, width=8))

1.4 left_shift
left_shift() 函数将数组元素的二进制形式向左移动到指定位置,右侧附加相等数量的 0。
import numpy as npprint('将 10 左移两位:')
print(np.left_shift(10, 2))
print('\n')print('10 的二进制表示:')
print(np.binary_repr(10, width=8))
print('\n')print('40 的二进制表示:')
print(np.binary_repr(40, width=8))
# '00001010' 中的两位移动到了左边,并在右边添加了两个 0。

1.5 right_shift
right_shift() 函数将数组元素的二进制形式向右移动到指定位置,左侧附加相等数量的 0。
import numpy as npprint('将 40 右移两位:')
print(np.right_shift(40, 2))
print('\n')print('40 的二进制表示:')
print(np.binary_repr(40, width=8))
print('\n')print('10 的二进制表示:')
print(np.binary_repr(10, width=8))
# '00001010' 中的两位移动到了右边,并在左边添加了两个 0。

2 NumPy 字符串函数
以下函数用于对 dtype 为 numpy.string_ 或 numpy.unicode_ 的数组执行向量化字符串操作。 它们基于 Python 内置库中的标准字符串函数。这些函数在字符数组类(numpy.char)中定义。
| 数 | 描述 |
|---|---|
add() | 对两个数组的逐个字符串元素进行连接 |
| multiply() | 返回按元素多重连接后的字符串 |
center() | 居中字符串 |
capitalize() | 将字符串第一个字母转换为大写 |
title() | 将字符串的每个单词的第一个字母转换为大写 |
lower() | 数组元素转换为小写 |
upper() | 数组元素转换为大写 |
split() | 指定分隔符对字符串进行分割,并返回数组列表 |
splitlines() | 返回元素中的行列表,以换行符分割 |
strip() | 移除元素开头或者结尾处的特定字符 |
join() | 通过指定分隔符来连接数组中的元素 |
replace() | 使用新字符串替换字符串中的所有子字符串 |
decode() | 数组元素依次调用str.decode |
encode() | 数组元素依次调用str.encode |
2.1 numpy.char.add()
numpy.char.add() 函数依次对两个数组的元素进行字符串连接。
import numpy as npprint('连接两个字符串:')
print(np.char.add(['hello'], [' xyz']))
print('\n')print('连接示例:')
print(np.char.add(['hello', 'hi'], [' abc', ' xyz']))

2.2 numpy.char.multiply()
numpy.char.multiply() 函数执行多重连接。
import numpy as npprint(np.char.multiply('ywz ', 3))

2.3 numpy.char.center()
numpy.char.center() 函数用于将字符串居中,并使用指定字符在左侧和右侧进行填充。
import numpy as np# np.char.center(str , width,fillchar) :
# str: 字符串,width: 长度,fillchar: 填充字符
print(np.char.center('ywz', 20, fillchar='*'))

2.4 numpy.char.capitalize()
numpy.char.capitalize() 函数将字符串的第一个字母转换为大写:
import numpy as npprint(np.char.capitalize('ywz'))

2.5 numpy.char.title()
numpy.char.title() 函数将字符串的每个单词的第一个字母转换为大写:
import numpy as npprint (np.char.title('i like apple'))
2.6 numpy.char.lower()
numpy.char.lower() 函数对数组的每个元素转换为小写。它对每个元素调用 str.lower。
import numpy as np# 操作数组
print(np.char.lower(['YWZ', 'GOOGLE']))# 操作字符串
print(np.char.lower('YWZ'))

2.7 numpy.char.upper()
numpy.char.upper() 函数对数组的每个元素转换为大写。它对每个元素调用 str.upper。
import numpy as np# 操作数组
print(np.char.upper(['ywz', 'google']))# 操作字符串
print(np.char.upper('ywz'))

2.8 numpy.char.split()
numpy.char.split() 通过指定分隔符对字符串进行分割,并返回数组。默认情况下,分隔符为空格。
import numpy as np# 分隔符默认为空格
print(np.char.split('i like apple?'))
# 分隔符为 .
print(np.char.split('blog.csdn.net', sep='.'))

2.9 numpy.char.splitlines()
numpy.char.splitlines() 函数以换行符作为分隔符来分割字符串,并返回数组。\n,\r,\r\n 都可用作换行符。
import numpy as np# 换行符 \n
print(np.char.splitlines('i\nlike apple?'))

2.10 numpy.char.strip()
numpy.char.strip() 函数用于移除开头或结尾处的特定字符。
import numpy as np# 移除字符串头尾的 a 字符
print(np.char.strip('ashok aywza', 'a'))# 移除数组元素头尾的 a 字符
print(np.char.strip(['aywza', 'admin', 'java'], 'a'))

2.11 numpy.char.join()
numpy.char.join() 函数通过指定分隔符来连接数组中的元素或字符串
import numpy as np# 操作字符串
print(np.char.join(':', 'ywz'))# 指定多个分隔符操作数组元素
print(np.char.join([':', '-'], ['ywz', 'google']))

2.12 numpy.char.replace()
numpy.char.replace() 函数使用新字符串替换字符串中的所有子字符串。
import numpy as npprint(np.char.replace('i like apple', 'pp', 'cc'))

2.13 numpy.char.encode()
numpy.char.encode() 函数对数组中的每个元素调用 str.encode 函数。 默认编码是 utf-8,可以使用标准 Python 库中的编解码器。
import numpy as npa = np.char.encode('ywz', 'cp500')
print(a)

2.14 numpy.char.decode()
numpy.char.decode() 函数对编码的元素进行 str.decode() 解码。
import numpy as npa = np.char.encode('ywz', 'cp500')
print(a)
print(np.char.decode(a, 'cp500'))

相关文章:
Python NumPy(8):NumPy 位运算、NumPy 字符串函数
1 NumPy 位运算 位运算是一种在二进制数字的位级别上进行操作的一类运算,它们直接操作二进制数字的各个位,而不考虑数字的整体值。NumPy 提供了一系列位运算函数,允许对数组中的元素进行逐位操作,这些操作与 Python 的位运算符类似…...

日志2025.1.30
日志2025.1.30 1.简略地做了一下交互系统 public class Interactable : MonoBehaviour { private MeshRenderer renderer; private Material defaultMaterial; public Material highlightMaterial; private void Awake() { renderer GetComponentInChildren<Me…...

实战:如何快速让新网站被百度收录?
本文来自:百万收录网 原文链接:https://www.baiwanshoulu.com/22.html 要让新网站快速被百度收录,可以采取以下实战策略: 一、网站基础优化 网站结构清晰:确保网站的结构简洁清晰,符合百度的抓取规则。主…...

PhotoShop中JSX编辑器安装
1.使用ExtendScript Tookit CC编辑 1.安装 打开CEP Resource链接: CEP-Resources/ExtendScript-Toolkit at master Adobe-CEP/CEP-Resources (github.com) 将文件clone到本地或者下载到本地 点击AdobeExtendScriptToolKit_4_Ls22.exe安装,根据弹出的…...

01-时间与管理
时间与效率 一丶番茄时钟步骤好处 二丶86400s的财富利用时间的方法每天坚持写下一天计划 自我管理体系计划-行动-评价-回顾 一丶番茄时钟 一个计时器 一份任务清单,任务 步骤 每一个25分钟是一个番茄时钟 将工作时间划分为若干个25分钟的工作单元期间只专注于当前任务,遇到…...

MiniMax-01技术报告解读
刚刚MiniMax发布了MiniMax-01,简单测试了效果,感觉不错。于是又把它的技术报告看了一下。这种报告看多了,就会多一个毛病,越来越觉得自己也能搞一个。 这篇文章我觉得最有意思的一句是对数据质量的强调“低质量数据在训练超过两个…...
:让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路)
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新——从DeepSeek看下一代语言模型的高效之路
多头潜在注意力(MLA):让大模型“轻装上阵”的技术革新 ——从DeepSeek看下一代语言模型的高效之路 大模型的“内存焦虑” 当ChatGPT等大语言模型(LLM)惊艳世界时,很少有人意识到它们背后隐藏的“内存焦虑”…...

哈希表实现
目录 1. 哈希概念 1.1 直接定址法 1.2 哈希冲突 1.3 负载因子 1.4 将关键字转为整型 1.5 哈希函数 1.5.1 除法散列法/除留余数法 1.5.2 乘法散列法 1.5.3 全域散列法 1.5.4 其他方法 1.6 处理哈希冲突 1.6.1 开放定址法 1.6.1.1 线性探测 1.6.1.2 二次探测 1.6.…...
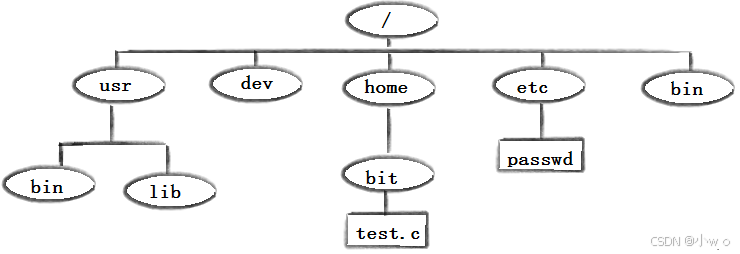
Linux的常用指令的用法
目录 Linux下基本指令 whoami ls指令: 文件: touch clear pwd cd mkdir rmdir指令 && rm 指令 man指令 cp mv cat more less head tail 管道和重定向 1. 重定向(Redirection) 2. 管道(Pipes&a…...

Ubuntu安装VMware17
安装 下载本文的附件,之后执行 sudo chmod x VMware-Workstation-Full-17.5.2-23775571.x86_64.bundle sudo ./VMware-Workstation-Full-17.5.2-23775571.x86_64.bundle安装注意事项: 跳过账户登录的办法:断开网络 可能出现的问题以及解决…...
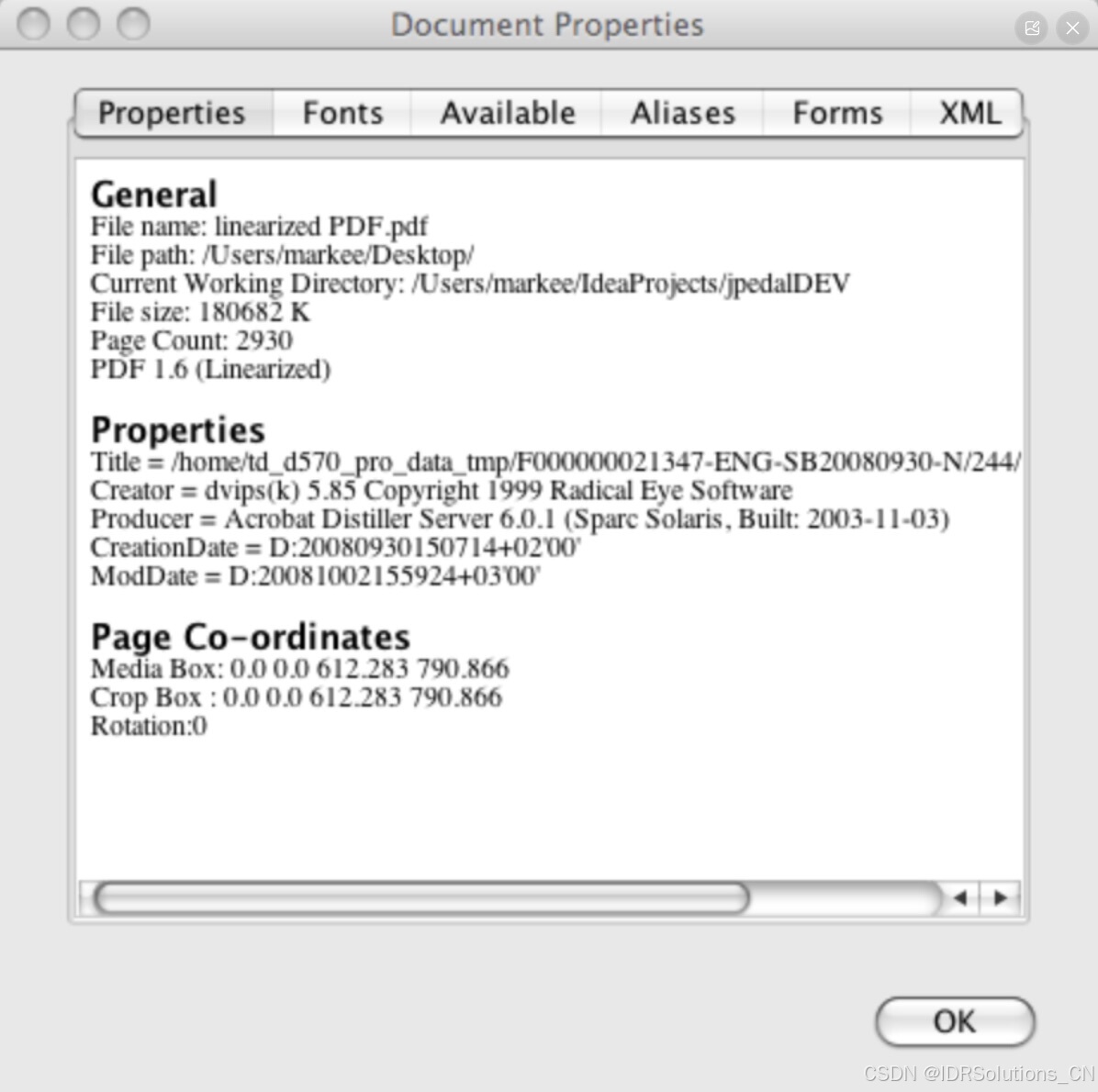
什么是线性化PDF?
线性化PDF是一种特殊的PDF文件组织方式。 总体而言,PDF是一种极为优雅且设计精良的格式。PDF由大量PDF对象构成,这些对象用于创建页面。相关信息存储在一棵二叉树中,该二叉树同时记录文件中每个对象的位置。因此,打开文件时只需加…...
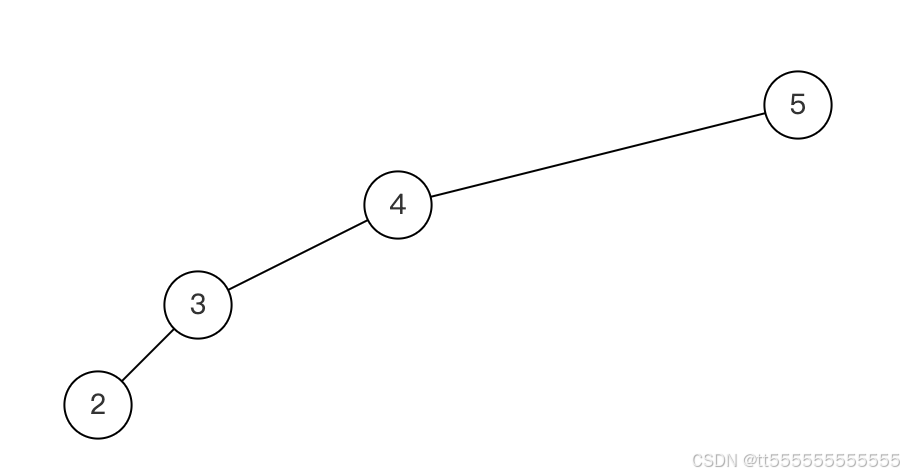
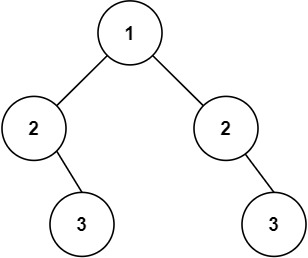
每日一题——序列化二叉树
序列化二叉树 BM39 序列化二叉树题目描述序列化反序列化 示例示例1示例2 解题思路序列化过程反序列化过程 代码实现代码说明复杂度分析总结 BM39 序列化二叉树 题目描述 请实现两个函数,分别用来序列化和反序列化二叉树。二叉树的序列化是将二叉树按照某种遍历方式…...
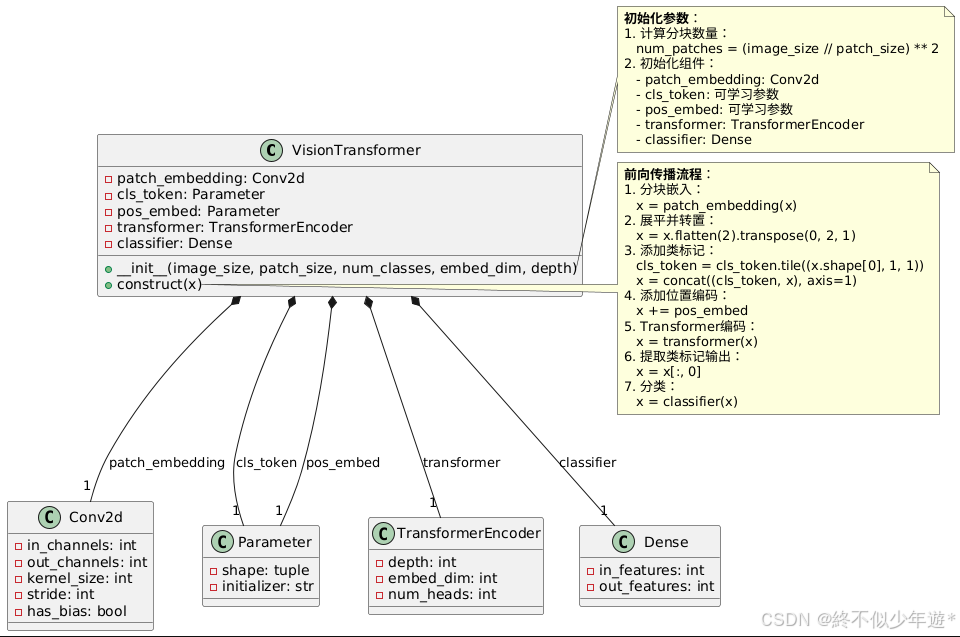
Transformer+vit原理分析
目录 一、Transformer的核心思想 1. 自注意力机制(Self-Attention) 2. 多头注意力(Multi-Head Attention) 二、Transformer的架构 1. 整体结构 2. 编码器层(Encoder Layer) 3. 解码器层(Decoder…...
「AI学习笔记」深度学习的起源与发展:从神经网络到大数据(二)
深度学习(DL)是现代人工智能(AI)的核心之一,但它并不是一夜之间出现的技术。从最初的理论提出到如今的广泛应用,深度学习经历了几乎一个世纪的不断探索与发展。今天,我们一起回顾深度学习的历史…...
【漫话机器学习系列】069.哈达马乘积(Hadamard Product)
哈达马乘积(Hadamard Product) 哈达马乘积(Hadamard Product)是两个矩阵之间的一种元素级操作,也称为逐元素乘积(Element-wise Product)。它以矩阵的对应元素相乘为规则,生成一个新…...

2025一区新风口:小波变换+KAN!速占!
今天给大家分享一个能让审稿人眼前一亮,好发一区的idea:小波变换KAN! 一方面:KAN刚中稿ICLR25,正是风口上,与小波变换的结合还处于起步阶段,正是红利期,创新空间广阔。 另一方面&a…...
相同的树及延伸题型(C语言详解版)
从LeetCode 100和101看二叉树的比较与对称性判断 今天要讲的是leetcode100.相同的树,并且本文章还会讲到延伸题型leetcode101.对称二叉树。本文章编写用的是C语言,大家主要是学习思路,学习过后可以自己点击链接测试,并且做一些对…...

【Redis】 String 类型的介绍和常用命令
1. 介绍 Redis 中的 key 都是字符串类型Redis 中存储字符串是完全按照二进制流的形式保存的,所以 Redis 是不处理字符集编码的问题,客户端传入的命令中使用的是什么编码就采用什么编码,使得 Redis 能够处理各种类型的数据,包括文…...
 教程(5))
LLM - 大模型 ScallingLaws 的设计 100B 预训练方案(PLM) 教程(5)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145356022 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Scaling Laws (缩放法则) 是大模型领域中,用于描述 模型性能(Loss) 与…...
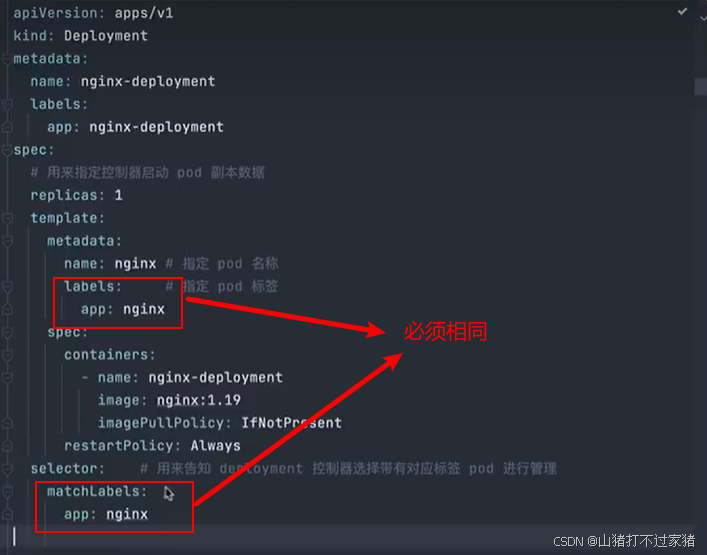
Docker/K8S
文章目录 项目地址一、Docker1.1 创建一个Node服务image1.2 volume1.3 网络1.4 docker compose 二、K8S2.1 集群组成2.2 Pod1. 如何使用Pod(1) 运行一个pod(2) 运行多个pod 2.3 pod的生命周期2.4 pod中的容器1. 容器的生命周期2. 生命周期的回调3. 容器重启策略4. 自定义容器启…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

【C语言】printf格式化输出:你真的理解“四舍五入”的陷阱吗?
1. 从printf的"四舍五入"陷阱说起 那天我在调试一个财务计算程序时,发现金额显示总差那么几分钱。比如3.145元应该显示为3.15,但程序输出却是3.14。这让我想起刚学C语言时踩过的坑——printf的格式化输出并不像数学课教的四舍五入那样简单。 先…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...