DeepSeek r1本地安装全指南

环境基本要求
硬件配置
需要本地跑模型,兼顾质量、性能、速度以及满足日常开发需要,我们需要准备以下硬件:
- CPU:I9
- 内存:128GB
- 硬盘:3-4TB 最新SSD,C盘确保有400GB,其它都可划成D盘;
- GPU:4080S即可(有条件的上4090D或者双卡),但是4080S已经足足够用了;
- 风扇:华硕七彩,10个 + 大功能水冷;
- 机箱:别用什么海景房,什么火山岩,不实用,太小,建议直接就是买那种大号的半透明机箱一个就行了,又大散热又好,什么海景房火山岩都不如搞7彩风扇好看;


软件配置
- 操作系统:Win11/Linux CentOS8.2/Ubuntu 24+
- 安装nvidia驱动,安装nvidia cuda核心,安装nvidia cudnn
- python 3.10+
- chatbox(用于作GUI聊天对话界面用)
确保nvidia的驱动在安装后你还必须要有nvidia cuda核心
一般互联网开发人员不知道这是什么,我们这样来装它。
先打开你的nvidia驱动装完后右下角的nvidia control panel找到以下这样的一个界面

一般4080s+以上都是12.6.65及以上,我们记成12.6.0。
于是打开以下网址下载nvidia cuda核心:
https://developer.nvidia.com/cuda-12-6-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exe_local

在此下载cuda 12.6。
确保nvidia CUDNN被安装
一定要先装完了cuda核心后,再要装cudnn。
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse897-120
我们进入nvidia开发者中心里下载它。
cuDNN下载完成后,是一个压缩包,解压完成后。请严格按照下面步骤去做,它解压后包含bin,include,lib三个目录。
-
把cuda\bin\cudnn64_7.dll复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin 目录下.
-
把\cuda\ include\cudnn.h复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include 目录下.
-
把\cuda\lib\x64\cudnn.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64 目录下.
安装Ollama
接着我们下载Ollama,https://ollama.com/。
下载完后直接安装它。
安装完后右下角会有这么一个图标。
![]()
安装完后即启动了,你也可以设置成开机不启动。
配置ollama
我我们使用ollama安装deek seek前,一定要先做配置,如果不配置,它会在安装时把很多模型文件一股脑的装到你的:
- Windows 目录:
C:\Users%username%.ollama\models - MacOS 目录:
~/.ollama/models - Linux 目录:
/usr/share/ollama/.ollama/models
这样的话你的C盘或者是启动盘就吃紧了,到时麻烦可就大了。
必配参数与解释
OLLAMA_MODELS
模型文件存放目录,默认目录为当前用户目录我们把它指向了D盘的d:\ollama_models。
OLLAMA_HOST
Ollama 服务监听的网络地址,默认为127.0.0.1,如果允许其他电脑访问 Ollama(如:局域网中的其他电脑),建议设置成0.0.0.0,从而允许其他网络访问
OLLAMA_PORT
Ollama 服务监听的默认端口,默认为11434,如果端口有冲突,可以修改设置成其他端口(如:8080等)
OLLAMA_ORIGINS
HTTP 客户端请求来源,半角逗号分隔列表,若本地使用无严格要求,可以设置成星号,代表不受限制
OLLAMA_KEEP_ALIVE
大模型加载到内存中后的存活时间,默认为5m即 5 分钟(如:纯数字如 300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活);我们可设置成24h,即模型在内存中保持 24 小时,提高访问速度
OLLAMA_NUM_PARALLEL
请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
OLLAMA_MAX_QUEUE
请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
OLLAMA_DEBUG
输出 Debug 日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
OLLAMA_MAX_LOADED_MODELS
最多同时加载到内存中模型的数量,默认为1,即只能有 1 个模型在内存中
配置完成后,启动一个terminal或者是命令行,然后以下几条常用ollama命令供参考
Ollama常用命令
列出当前系统装了哪些模型
ollama listNAME ID SIZE MODIFIED
gemma2:9b c19987e1e6e2 5.4 GB 7 days ago
qwen2:7b e0d4e1163c58 4.4 GB 10 days ago
安装和运行一个模型
ollama run deepseek-r1:14b如果这个模型不存在,它就会先下载这个模型至ollama_models指向的那个目录并作下载,如上条命令就是安装和运行deep seek r1 14b的。
查看己安装的模型
ollama ps删除一个模型
ollama rm 如:
ollama rm gemma2:9b安装完后Deek Seek使用ChatBox来做验证
下载网址
https://chatboxai.app/zh
建议安装1.9.6版。
配置

我们使用了一个生产的复杂场景,3层推理分别试了让GPT3.5 TURBO16K以及GPT4O,还有QWEN2 7B以及Deep Seek r1 14b分别作了回答。
无论是从GPU性能开销、回答正确性来看,Deep Seek秒杀了Gpt4O,不得不说Deep Seek是我们的国产之光。
这下,我们实现了AI自由了。
附、其它ollama支持的模型
| 模型 | 参数 | 大小 | 使用命令 |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| qwen2 | 7B | 4.4GB | ollama run qwen2 |
| qwen2 | 72B | 41GB | ollama run qwen2:72b |
| glm4 | 9B | 5.5GB | ollama run glm4 |
相关文章:
DeepSeek r1本地安装全指南
环境基本要求 硬件配置 需要本地跑模型,兼顾质量、性能、速度以及满足日常开发需要,我们需要准备以下硬件: CPU:I9内存:128GB硬盘:3-4TB 最新SSD,C盘确保有400GB,其它都可划成D盘…...

LitGPT - 20多个高性能LLM,具有预训练、微调和大规模部署的recipes
文章目录 一、关于 LitGPT二、快速启动安装LitGPT高级安装选项 从20多个LLM中进行选择 三、工作流程1、所有工作流程2、微调LLM3、部署LLM4、评估LLM5、测试LLM6、预训练LLM7、继续预训练LLM 四、最先进的功能五、训练方法示例 六、项目亮点教程 一、关于 LitGPT LitGPT 用于 …...

deepseek R1 14b显存占用
RTX2080ti 11G显卡,模型7b速度挺快,试试14B也不错。 7B显存使用5.6G,14B显存刚好够,出文字速度差不多。 打算自己写个移动宽带的IPTV播放器,不知道怎么下手,就先问他了。...

无用知识研究:对std::common_type以及问号表达式类型的理解
先说结论: 如果问号表达式能编译通过,那么std::common_type就能通过。因为common_type的底层依赖的就是?: common_type的实现里,利用了问号表达式:ternary conditional operator (?:) https://stackoverflow.com/questions/14…...
MapReduce概述
目录 1. MapReduce概述2. MapReduce的功能2.1 数据划分和计算任务调度2.2 数据/代码互定位2.3 系统优化2.4 出错检测和恢复 3. MapReduce处理流程4. MapReduce编程基础参考 1. MapReduce概述 MapReduce是面向大数据并行处理的计算模型、框架和平台: 1. 基于集群的高性能并行…...

循环神经网络(RNN)+pytorch实现情感分析
目录 一、背景引入 二、网络介绍 2.1 输入层 2.2 循环层 2.3 输出层 2.4 举例 2.5 深层网络 三、网络的训练 3.1 训练过程举例 1)输出层 2)循环层 3.2 BPTT 算法 1)输出层 2)循环层 3)算法流程 四、循…...
Mac cursor设置jdk、Maven版本
基本配置 – Cursor 使用文档 首先是系统用户级别的设置参数,运行cursor,按下ctrlshiftp,输入Open User Settings(JSON),在弹出的下拉菜单中选中下面这样的: 在打开的json编辑器中追加下面的内容: {"…...
WPS数据分析000005
目录 一、数据录入技巧 二、一维表 三、填充柄 向下自动填充 自动填充选项 日期填充 星期自定义 自定义序列 1-10000序列 四、智能填充 五、数据有效性 出错警告 输入信息 下拉列表 六、记录单 七、导入数据 编辑 八、查找录入 会员功能 Xlookup函数 VL…...

CTF从入门到精通
文章目录 背景知识CTF赛制 背景知识 CTF赛制 1.web安全:通过浏览器访问题目服务器上的网站,寻找网站漏洞(sql注入,xss(钓鱼链接),文件上传,包含漏洞,xxe,ssrf,命令执行,…...
Flutter使用Flavor实现切换环境和多渠道打包
在Android开发中通常我们使用flavor进行多渠道打包,flutter开发中同样有这种方式,不过需要在原生中配置 具体方案其实flutter官网个了相关示例(https://docs.flutter.dev/deployment/flavors),我这里记录一下自己的操作 Android …...

Springboot如何使用面向切面编程AOP?
Springboot如何使用面向切面编程AOP? 在 Spring Boot 中使用面向切面编程(AOP)非常简单,Spring Boot 提供了对 AOP 的自动配置支持。以下是详细的步骤和示例,帮助你快速上手 Spring Boot 中的 AOP。 1. 添加依赖 首先ÿ…...

51单片机(STC89C52)开发:点亮一个小灯
软件安装: 安装开发板CH340驱动。 安装KEILC51开发软件:C51V901.exe。 下载软件:PZ-ISP.exe 创建项目: 新建main.c 将main.c加入至项目中: main.c:点亮一个小灯 #include "reg52.h"sbit LED1P2^0; //P2的…...
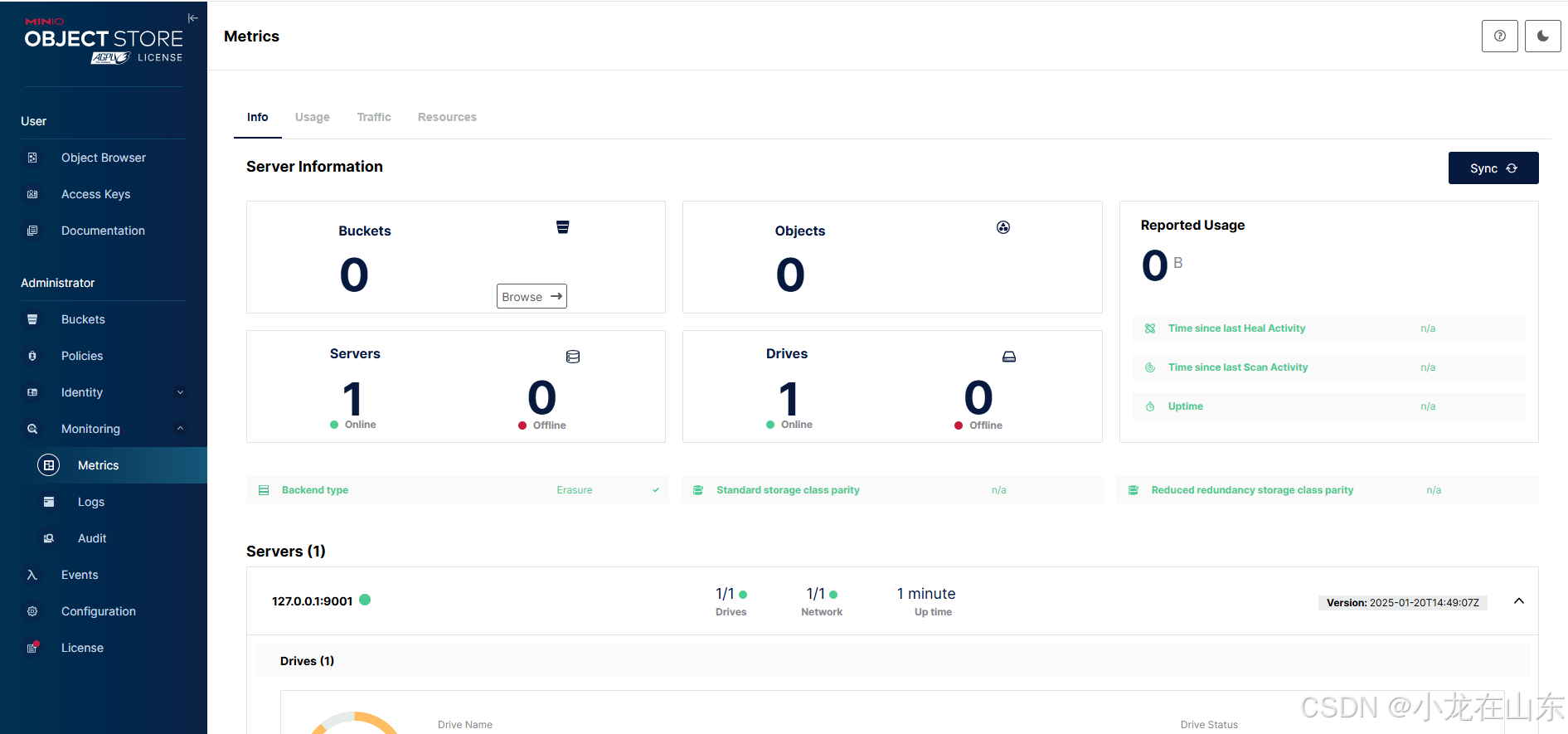
基于MinIO的对象存储增删改查
MinIO是一个高性能的分布式对象存储服务。Python的minio库可操作MinIO,包括创建/列出存储桶、上传/下载/删除文件及列出文件。 查看帮助信息 minio.exe --help minio.exe server --help …...
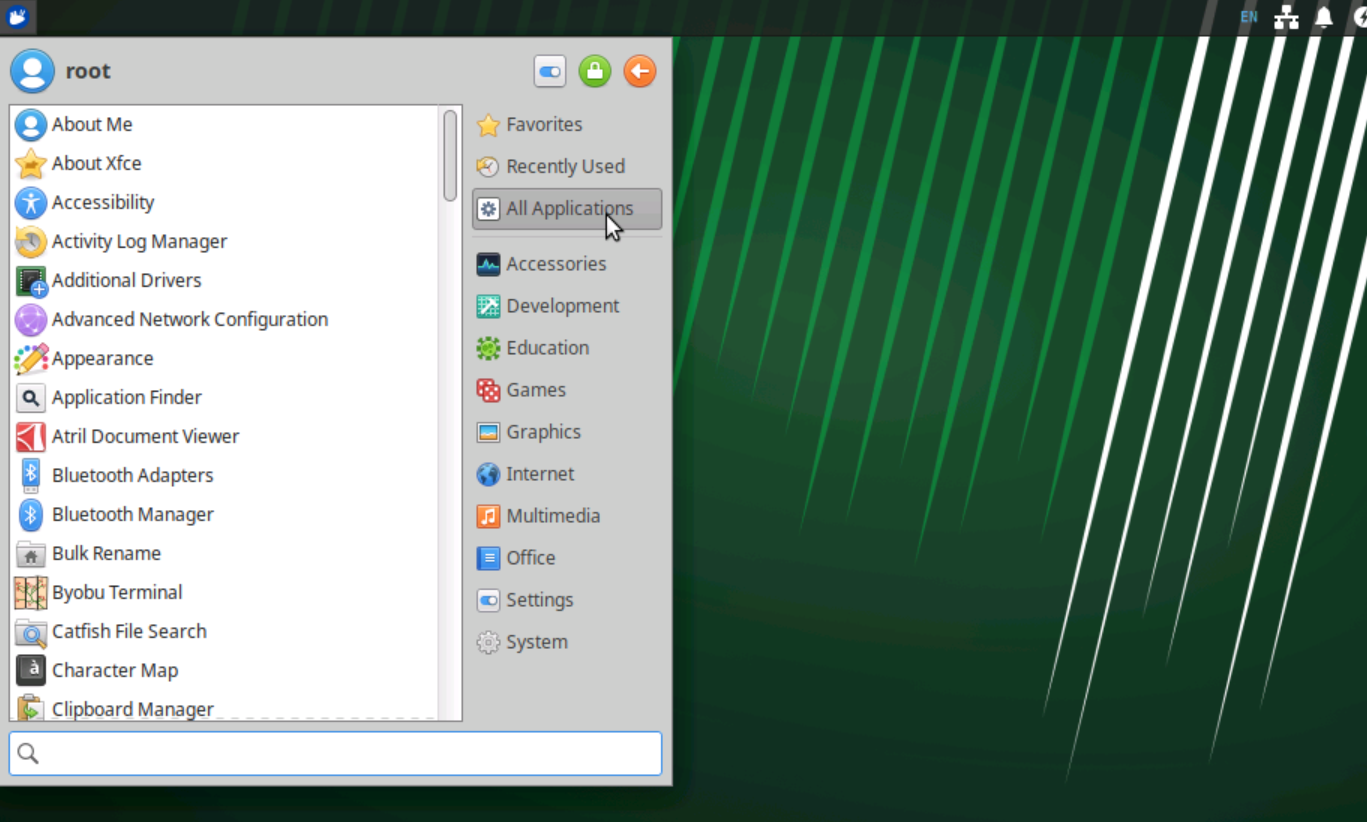
Ubuntu Server 安装 XFCE4桌面
Ubuntu Server没有桌面环境,一些软件有桌面环境使用起来才更加方便,所以我尝试安装桌面环境。常用的桌面环境有:GNOME、KDE Plasma、XFCE4等。这里我选择安装XFCE4桌面环境,主要因为它是一个极轻量级的桌面环境,适合内…...

MySQL 存储函数:数据库的自定义函数
在数据库开发中,存储函数(Stored Function)是一种非常有用的工具。它允许我们创建自定义的函数,这些函数可以在 SQL 查询中像内置函数一样使用,用于实现特定的逻辑和计算。本文将深入探讨 MySQL 存储函数的概念、与存储…...
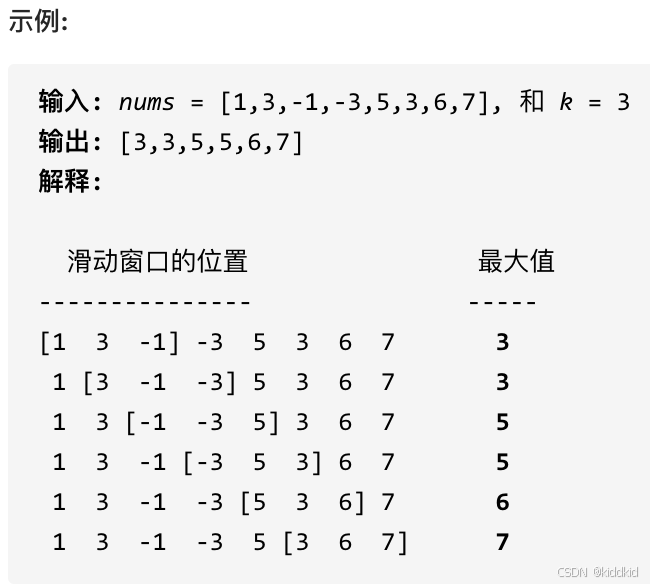
代码随想录_栈与队列
栈与队列 232.用栈实现队列 232. 用栈实现队列 使用栈实现队列的下列操作: push(x) – 将一个元素放入队列的尾部。 pop() – 从队列首部移除元素。 peek() – 返回队列首部的元素。 empty() – 返回队列是否为空。 思路: 定义两个栈: 入队栈, 出队栈, 控制出入…...

【微服务与分布式实践】探索 Sentinel
参数设置 熔断时长 、最小请求数、最大RT ms、比例阈值、异常数 熔断策略 慢调⽤⽐例 当单位统计时⻓内请求数⽬⼤于设置的最⼩请求数⽬,并且慢调⽤的⽐例⼤于阈值,则接下来的熔断时⻓内请求会⾃动被熔断 异常⽐例 当单位统计时⻓内请求数⽬⼤于设置…...
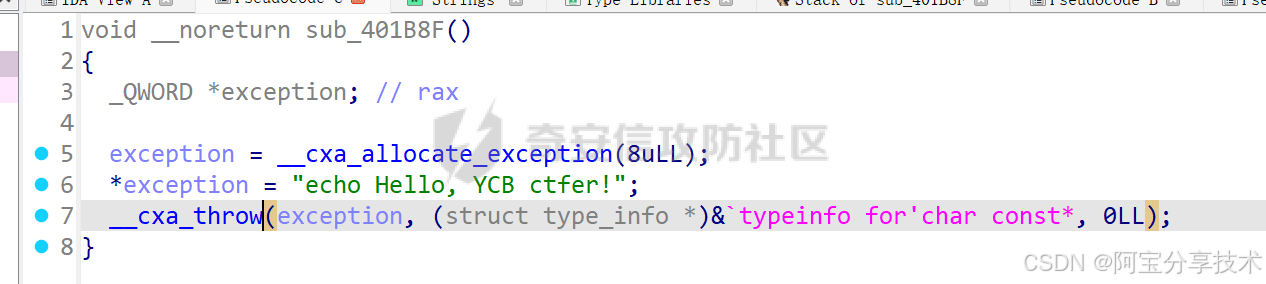
深入研究异常处理机制
一、原理探究 C异常处理 本节内容针对 Linux 下的 C 异常处理机制,重点在于研究如何在异常处理流程中利用溢出漏洞,所以不对异常处理及 unwind 的过程做详细分析,只做简单介绍 异常机制中主要的三个关键字:throw 抛出异常&#x…...

【memgpt】letta 课程4:基于latta框架构建MemGpt代理并与之交互
Lab 3: Building Agents with memory 基于latta框架构建MemGpt代理并与之交互理解代理状态,例如作为系统提示符、工具和agent的内存查看和编辑代理存档内存MemGPT 代理是有状态的 agents的设计思路 每个步骤都要定义代理行为 Letta agents persist information over time and…...

讯飞智作 AI 配音技术浅析(二):深度学习与神经网络
讯飞智作 AI 配音技术依赖于深度学习与神经网络,特别是 Tacotron、WaveNet 和 Transformer-TTS 模型。这些模型通过复杂的神经网络架构和数学公式,实现了从文本到自然语音的高效转换。 一、Tacotron 模型 Tacotron 是一种端到端的语音合成模型ÿ…...

用过才敢说!盘点2026年备受喜爱的的AI论文平台
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂、实测能大幅提速的AI论文平台,覆盖选题构思、文献整理、内容生成、降重润色等核心场景,帮你高效搞定论文,告别熬夜赶稿! 一、全流程王者:一站式搞定论文全链路…...

PyTorch分布式训练:原理与实践
PyTorch分布式训练:原理与实践 1. 背景与意义 随着深度学习模型的不断增大和数据集规模的持续增长,单GPU训练已经无法满足需求。分布式训练成为训练大型模型的必要手段,它可以显著缩短训练时间,提高模型性能。PyTorch提供了强大的…...

SEO工作规划需要制定哪些KPI指标
<h2>SEO工作规划需要制定哪些KPI指标</h2> <p>在当前竞争激烈的网络环境中,SEO(搜索引擎优化)已经成为企业获取流量和提升品牌知名度的关键手段。单靠SEO的理念和方法,往往难以达到预期的效果。因此,…...

2步实现格式自由:Save Image as Type让网页图片转换体验升级10倍
2步实现格式自由:Save Image as Type让网页图片转换体验升级10倍 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors…...

BoltDB vs Redis 读性能对比:实测表现与原理差异
一、前言 BoltDB(bbolt)与 Redis 都是高并发场景下常见的键值存储,但存储架构、存储介质、并发模型完全不同,导致两者在读性能、延迟、并发扩展性上呈现巨大差异。 本文从原理、延迟、并发读能力、资源开销四个维度对比两者的读性…...

3步解锁无线投屏自由:MiracleCast让多设备互联从此无束缚
3步解锁无线投屏自由:MiracleCast让多设备互联从此无束缚 【免费下载链接】miraclecast Connect external monitors to your system via Wifi-Display specification also known as Miracast 项目地址: https://gitcode.com/gh_mirrors/mi/miraclecast &…...

永磁同步电机全速域无位置传感器控制探索之旅
永磁同步电机全速域无位置传感器控制(高频注入改进滑膜控制方法,PMSM矢量控制仿真) 永磁同步电机-PMSM的仿真-原理-算法-复现 1)关于PMSM控制算法的文章复现、matlab编程仿真等均可,Matlab/Simulink仿真建模 分析建模 …...

Steam创意工坊模组下载终极指南:告别平台限制,轻松获取海量游戏内容
Steam创意工坊模组下载终极指南:告别平台限制,轻松获取海量游戏内容 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为跨平台游戏无法下载Steam创意…...

GsonFormat深度解析:如何高效处理复杂JSON数据结构
GsonFormat深度解析:如何高效处理复杂JSON数据结构 【免费下载链接】GsonFormat 根据Gson库使用的要求,将JSONObject格式的String 解析成实体 项目地址: https://gitcode.com/gh_mirrors/gs/GsonFormat GsonFormat是一款专为Android Studio和IntelliJ IDEA设…...

语音识别模型Conformer实战:如何用夹心饼干结构提升ASR效果
Conformer模型实战:用"夹心饼干"架构打造工业级语音识别系统 语音识别技术正在经历从传统DNN-HMM到端到端深度学习的范式转移,而Conformer凭借其创新的"CNNTransformer"混合架构,正在成为新一代ASR系统的标配。这种被开发…...