利用Python高效处理大规模词汇数据
在本篇博客中,我们将探讨如何使用Python及其强大的库来处理和分析大规模的词汇数据。我们将介绍如何从多个.pkl文件中读取数据,并应用一系列算法来筛选和扩展一个核心词汇列表。这个过程涉及到使用Pandas、Polars以及tqdm等库来实现高效的数据处理。
引言
词汇数据的处理是自然语言处理(NLP)领域中的一个常见任务。无论是构建词典、进行文本分类还是情感分析,都需要对大量的词汇数据进行预处理和分析。本文将演示一种方法,该方法不仅能够有效地管理词汇数据,还能够在处理过程中保持数据的一致性和准确性。
数据准备
首先,我们需要加载初始的词汇数据集,这些数据以.pkl格式存储,并且包含了词汇及其出现的频率。我们选择了一个名为voc_26B.pkl的文件,它包含了所有需要处理的词汇信息。
import os
import pandas as pd
from glob import glob
import polars as pl
from tqdm import tqdm# 加载并排序词汇数据
voc = pd.read_pickle("voc_26B.pkl")
voc = voc.sort_values("count", ascending=False)
voc = voc["voc"].values.tolist()
接下来,我们收集所有需要分析的路径,这里假设所有的.pkl文件都位于E:/voc_voc/目录下。
# 获取所有路径
paths = glob("E:/voc_voc/*.pkl")
new_voc = set()
数据处理与优化
在这个阶段,我们将遍历每个词汇项,并根据其前缀匹配规则,查找并合并相关的词汇条目。为了确保效率,我们采用了tqdm库来显示进度条,这对于我们了解程序执行进度非常有帮助。
for voc_data in tqdm(voc):if voc_data in new_voc:continuenew_voc.update(set([voc_data]))idex = 0data = ""# 循环查找直到找到非空数据while len(data) == 0:data = pd.read_pickle(paths[idex], compression="zip")data1 = pl.DataFrame({"voc": data.keys(), "value": data.values()})data = {k: v for k, v in data.items() if voc_data == k[:len(voc_data)]}idex += 1# 转换为DataFrame并排序data = pd.DataFrame({"voc": data.keys(), "value": data.values()})data = data.sort_values("value", ascending=False).head()# 更新词汇集合data = data["voc"].str[len(voc_data) + 1:].values.tolist()if voc_data in data:data.remove(voc_data)new_voc.update(set(data))# 进一步扩展词汇data3 = []for i in tqdm(set(data)):data2 = [k[len(i) + 1:] for k, v indata1.filter(data1["voc"].str.contains(i + "_")).sort("value", descending=True).to_numpy() ifi == k[:len(i)]][:5]new_voc.update(set(data2))data3 += data2# 深度扩展词汇for i in tqdm(set(data3)):try:data2 = [k[len(i) + 1:] for k, v indata1.filter(data1["voc"].str.contains(i + "_")).sort("value", descending=True).to_numpy() ifi == k[:len(i)]][:5]new_voc.update(set(data2))except:pass# 当词汇数量达到一定规模时保存结果if len(new_voc) > 8192:pd.to_pickle(new_voc, "voc_{}_voc.pkl".format(len(new_voc)))
结果保存
最后,当整个词汇扩展过程完成后,我们将最终的词汇集合保存到一个新的.pkl文件中。
pd.to_pickle(new_voc, "voc_{}_voc.pkl".format(len(new_voc)))
总结
通过上述步骤,我们可以看到,Python及其丰富的库使得处理大规模词汇数据变得既简单又高效。特别是tqdm的进步条功能,极大地提升了用户体验,让用户可以直观地了解数据处理的进度。同时,结合使用Pandas和Polars,可以在保证数据处理速度的同时,也确保了代码的简洁性和可读性。
希望这篇博客能为您提供有价值的参考,并激发您在自己的项目中尝试类似的解决方案。如果您有任何问题或想要分享您的经验,请随时留言讨论!
相关文章:

利用Python高效处理大规模词汇数据
在本篇博客中,我们将探讨如何使用Python及其强大的库来处理和分析大规模的词汇数据。我们将介绍如何从多个.pkl文件中读取数据,并应用一系列算法来筛选和扩展一个核心词汇列表。这个过程涉及到使用Pandas、Polars以及tqdm等库来实现高效的数据处理。 引…...

【PyQt】超级超级笨的pyqt计算器案例
计算器 1.QT Designer设计外观 1.pushButton2.textEdit3.groupBox4.布局设计 2.加载ui文件 导入模块: sys:用于处理命令行参数。 QApplication:PyQt5 应用程序类。 QWidget:窗口基类。 uic:用于加载 .ui 文件。…...

Git 的起源与发展
序章:版本控制的前世今生 在软件开发的漫长旅程中,版本控制犹如一位忠诚的伙伴,始终陪伴着开发者们。它的存在,解决了软件开发过程中代码管理的诸多难题,让团队协作更加高效,代码的演进更加有序。 简单来…...

预防和应对DDoS的方法
DDoS发起者通过大量的网络流量来中断服务器、服务或网络的正常运行,通常由多个受感染的计算机或联网设备(包括物联网设备)发起。 换种通俗的说法,可以将其想象成高速公路上的一次突然的大规模交通堵塞,阻止了正常的通勤…...

51单片机开发:独立按键实验
实验目的:按下键盘1时,点亮LED灯1。 键盘原理图如下图所示,可见,由于接GND,当键盘按下时,P3相应的端口为低电平。 键盘按下时会出现抖动,时间通常为5-10ms,代码中通过延时函数delay…...

02.04 数据类型
请写出以下几个数据的类型: 整数 a ----->int a的地址 ----->int* 存放a的数组b ----->int[] 存放a的地址的数组c ----->int*[] b的地址 ----->int* c的地址 ----->int** 指向printf函数的指针d ----->int (*)(const char*, ...) …...

FPGA学习篇——开篇之作
今天正式开始学FPGA啦,接下来将会编写FPGA学习篇来记录自己学习FPGA 的过程! 今天是大年初六,简单学一下FPGA的相关概念叭叭叭! 一:数字系统设计流程 一个数字系统的设计分为前端设计和后端设计。在我看来࿰…...

【Cadence仿真技巧学习笔记】求解65nm库晶体管参数un, e0, Cox
在设计放大器的第一步就是确定好晶体管参数和直流工作点的选取。通过阅读文献,我了解到L波段低噪声放大器的mos器件最优宽度计算公式为 W o p t . p 3 2 1 ω L C o x R s Q s p W_{opt.p}\frac{3}{2}\frac{1}{\omega LC_{ox}R_{s}Q_{sp}} Wopt.p23ωLCoxRs…...

【RocketMQ】RocketMq之IndexFile深入研究
一:RocketMq 整体文件存储介绍 存储⽂件主要分为三个部分: CommitLog:存储消息的元数据。所有消息都会顺序存⼊到CommitLog⽂件当中。CommitLog由多个⽂件组成,每个⽂件固定⼤⼩1G。以第⼀条消 息的偏移量为⽂件名。 ConsumerQue…...

小白零基础--CPP多线程
进程 进程就是运行中的程序线程进程中的进程 1、C11 Thread线程库基础 #include <iostream> #include <thread> #include<string>void printthread(std::string msg){std::cout<<msg<<std::endl;for (int i 0; i < 1000; i){std::cout<…...

利用deepseek参与软件测试 基本架构如何 又该在什么环节接入deepseek
利用DeepSeek参与软件测试,可以考虑以下基本架构和接入环节: ### 基本架构 - **数据层** - **测试数据存储**:用于存放各种测试数据,包括正常输入数据、边界值数据、异常数据等,这些数据可以作为DeepSeek的输入&…...
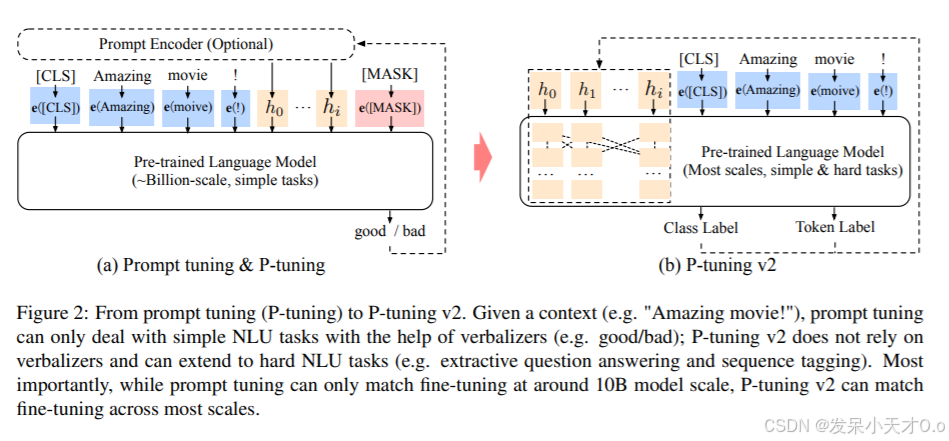
大模型微调技术总结及使用GPU对VisualGLM-6B进行高效微调
1. 概述 在深度学习中,微调(Fine-tuning)是一种重要的技术,用于改进预训练模型的性能。在预训练模型的基础上,针对特定任务(如文本分类、机器翻译、情感分析等),使用相对较小的有监…...

WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器
WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器 一、前言二、WPF 样式基础2.1 什么是样式2.2 样式的定义2.3 样式的应用 三、WPF 模板基础3.1 什么是模板3.2 控件模板3.3 数据模板 四、样式与模板的高级应用4.1 样式继承4.2 模板绑定4.3 资源字典 五、实际应用…...

Java 大视界 -- Java 大数据在自动驾驶中的数据处理与决策支持(68)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
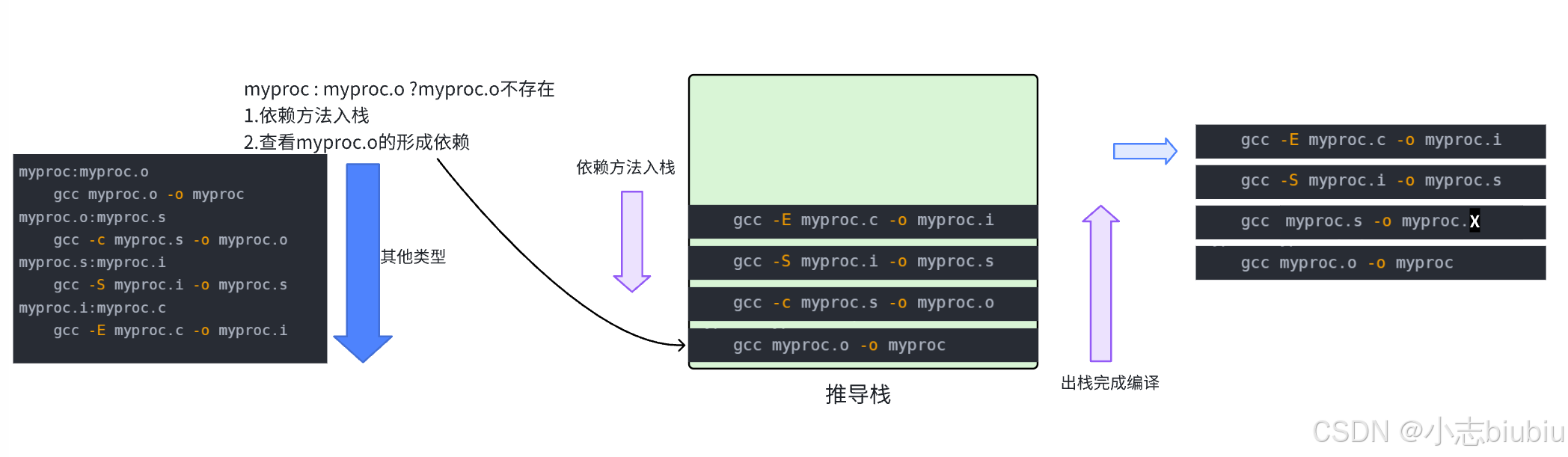
自动化构建-make/Makefile 【Linux基础开发工具】
文章目录 一、背景二、Makefile编译过程三、变量四、变量赋值1、""是最普通的等号2、“:” 表示直接赋值3、“?” 表示如果该变量没有被赋值,4、""和写代码是一样的, 五、预定义变量六、函数**通配符** 七、伪目标 .PHONY八、其他常…...

python学opencv|读取图像(五十二)使用cv.matchTemplate()函数实现最佳图像匹配
【1】引言 前序学习了图像的常规读取和基本按位操作技巧,相关文章包括且不限于: python学opencv|读取图像-CSDN博客 python学opencv|读取图像(四十九)原理探究:使用cv2.bitwise()系列函数实现图像按位运算-CSDN博客…...
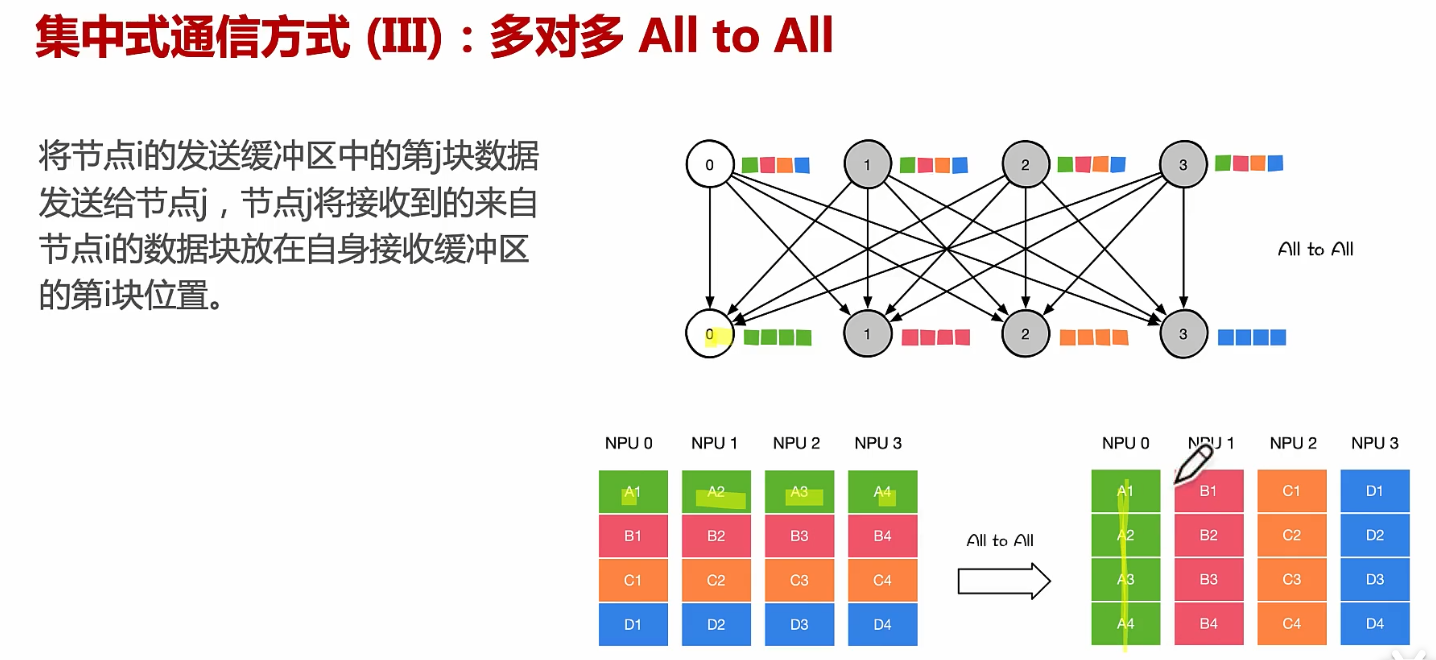
通信方式、点对点通信、集合通信
文章目录 从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!通信实现方式:机器内通信、机器间通信通信实现方式:通讯协调通信实现方式:机器内通信:PCIe通信实现方式:机器内通信:NVLink通信实现…...

TCP编程
1.socket函数 int socket(int domain, int type, int protocol); 头文件:include<sys/types.h>,include<sys/socket.h> 参数 int domain AF_INET: IPv4 Internet protocols AF_INET6: IPv6 Internet protocols AF_UNIX, AF_LOCAL : Local…...

OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询了解如何获取数据库结构信息并与 OpenAI 结合使用 实操步骤 1. 创建 SQLite 数据库示例 创建数据库及表结构: import sqlite3# 连接 SQLite 数据库(如果不存在则创建) conn sq…...

Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。 Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照…...

支持多渠道的语音机器人 2026 企业选型攻略:智能核心引擎
在客户体验驱动业务增长的时代,企业热线早已不是“有人接电话”那么简单。随着大模型技术与通信系统的深度融合,多渠道语音机器人正从传统的“按键导航”进化为能够理解情绪、动态决策的智能客服专家。2026年,如何选择一款真正适配业务场景、…...

S32K3 FlexCAN实战:从MCAL配置到DMA接收,手把手教你避开那些手册里没写的坑
S32K3 FlexCAN深度实战:从寄存器配置到DMA优化全链路解析 在车载电子架构快速迭代的今天,S32K3系列MCU凭借其强大的FlexCAN模块成为汽车电子开发者的首选。但官方文档往往只勾勒出理想状态下的功能框架,当工程师真正着手实现CAN FD通信时&…...

让老旧PL-2303串口设备在Windows 10/11重获新生的终极指南
让老旧PL-2303串口设备在Windows 10/11重获新生的终极指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10或Windows 11系统上无法使用老旧的PL-2303串…...

零代码部署 OpenClaw:Win11 一键安装与使用教程
OpenClaw(小龙虾)Windows 11 一键部署教程 2026 最新版 零代码免配置解压即用适用系统:Windows 11 专业版 / 家庭版 / 正式版(全版本兼容) 项目介绍:OpenClaw 是 GitHub 星标 28W 的开源本地 AI 智能体&am…...

实战指南 | Vivado自定义IP核在IP Catalog中“隐身”与“灰显”的排查与修复
1. 自定义IP核"隐身"与"灰显"问题全景解析 第一次在Vivado中封装自己的IP核时,那种成就感简直无法形容。但当兴冲冲地想在另一个工程中调用这个"宝贝"时,却发现它在IP Catalog中要么完全消失不见,要么像个害羞…...

Ubuntu服务器性能检测工具NetData安装
1. NetData安装 打开Ubuntu终端并输入以下指令: $ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)中途会提示安装文件将为占用磁盘空间,是否继续(Y/N),输入Y即可,安装完成后的截图如下…...

初创团队如何利用Token Plan套餐控制大模型API开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Token Plan套餐控制大模型API开发成本 对于初创团队而言,在原型开发和产品迭代阶段,技术选…...

Goodable桌面AI工作台:为超级个体打造的本地智能体操作系统
1. 项目概述:一个为超级个体量身打造的桌面AI工作台如果你是一个内容创作者、自媒体运营者,或者是一个需要同时处理行政、财务、客服等多种角色的“超级个体”,那么你肯定对“时间不够用”和“重复性劳动”这两个词深有感触。每天在电脑上&am…...

Llama-MoE架构解析:混合专家系统如何实现大模型高效训练与推理
1. 项目概述:当MoE遇见Llama,一个面向系统优化的高效大模型架构最近在开源社区里,一个名为pjlab-sys4nlp/llama-moe的项目引起了我的注意。这个项目名直译过来就是“鹏城实验室-面向自然语言处理的系统研究组”开源的“Llama-MoE”模型。如果…...

通过Taotoken CLI工具一键配置团队开发环境与统一API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队开发环境与统一API密钥 基础教程类,介绍如何利用Taotoken提供的命令行工具ÿ…...