保姆级教程Docker部署KRaft模式的Kafka官方镜像
目录
一、安装Docker及可视化工具
二、单节点部署
1、创建挂载目录
2、运行Kafka容器
3、Compose运行Kafka容器
4、查看Kafka运行状态
三、集群部署
四、部署可视化工具
1、创建挂载目录
2、运行Kafka-ui容器
3、Compose运行Kafka-ui容器
4、查看Kafka-ui运行状态
在Kafka2.8版本之前,Kafka是强依赖于Zookeeper中间件的,这本身就很不合理,中间件依赖另一个中间件,搭建起来实在麻烦。所幸Kafka2.8之后推出了KRaft模式,即抛弃Zookeeper,由Kafka节点自己做Controller来选举Leader。本篇文章内容就是介绍如何在Docker中搭建Kafka KRaft环境。
一、安装Docker及可视化工具
Docker及可视化工具的安装可参考:Ubuntu上安装 Docker及可视化管理工具
二、单节点部署
在进行单节点部署并以KRaft模式运行时,该节点通常是混合节点的类型
1、创建挂载目录
# 创建宿主机kafka挂载目录
sudo mkdir -p /data/docker/kafka2、运行Kafka容器
# 拉取镜像
sudo docker pull apache/kafka:3.9.0# 运行容器
sudo docker run --privileged=true \
--net=bridge \
-d --name=kafka \
-v /data/docker/kafka/data:/var/lib/kafka/data \
-v /data/docker/kafka/config:/mnt/shared/config \
-v /data/docker/kafka/secrets:/etc/kafka/secrets \
-p 9092:9092 -p 9093:9093 \
-e LANG=C.UTF-8 \
-e KAFKA_NODE_ID=1 \
-e CLUSTER_ID=kafka-cluster \
-e KAFKA_PROCESS_ROLES=broker,controller \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.3.9:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093 \
apache/kafka:3.9.0参数解析如下:
| 参数 | 参数说明 |
| docker run | 运行 Docker 容器 |
| -d | 容器将在后台运行,而不是占用当前的终端会话 |
| --privileged=true | Docker会赋予容器几乎与宿主机相同的权限 |
| --net=bridge | 网络模式配置,默认是bridge,bridge表示使用容器内部配置网络 |
| --name kafka | 给容器命名为 kafka,以便于管理和引用该容器 |
| -p 9092:9092 -p 9093:9093 | 映射 kafka 的客户端通信端口和控制器端口 |
| -e KAFKA_NODE_ID=1 | 节点ID,用于标识每个集群中的节点,需要是不小于1的整数,同一个集群中的节点ID不可重复 |
| -e CLUSTER_ID=kafka-cluster | 集群ID,可以自定义任何字符串作为集群ID,同一个集群中所有节点的集群ID必须配置为一样 |
| -e KAFKA_PROCESS_ROLES=broker,controller | 节点类型,broker,controller表示该节点是混合节点,通常单机部署时需要配置为混合节点 |
| -e KAFKA_INTER_BROKER_LISTENER_NAME= PLAINTEXT | Kafka的Broker地址前缀名称,固定为PLAINTEXT即可 |
| -e KAFKA_CONTROLLER_LISTENER_NAMES= CONTROLLER | Kafka的Controller地址前缀名称,固定为CONTROLLER即可 |
| -e KAFKA_LISTENERS= PLAINTEXT://:9092,CONTROLLER://:9093 | 表示Kafka要监听哪些端口,PLAINTEXT://:9092,CONTROLLER://:9093表示本节点作为混合节点,监听本机所有可用网卡的9092和9093端口,其中9092作为客户端通信端口,9093作为控制器端口 |
| -e KAFKA_ADVERTISED_LISTENERS= PLAINTEXT://192.168.3.9:9092 | 配置Kafka的外网地址,需要是PLAINTEXT://外网地址:端口的形式,当客户端连接Kafka服务端时,Kafka会将这个外网地址广播给客户端,然后客户端再通过这个外网地址连接,除此之外集群之间交换数据时也是通过这个配置项得到集群中每个节点的地址的,这样集群中节点才能进行交互。需要修改为对应的Kafka的外网地址。 |
| -e KAFKA_CONTROLLER_QUORUM_VOTERS= 1@localhost:9093 | 投票节点列表,通常配置为集群中所有的Controller节点,格式为节点id@节点外网地址:节点Controller端口,多个节点使用逗号,隔开,由于是混合节点,因此配置自己就行了 |
| -v /data/docker/kafka/data:/var/lib/kafka/data | 持久化数据文件夹,如果运行出现问题可以清空该数据卷文件重启再试 |
| -v /data/docker/kafka/config:/mnt/shared/config | 持久化配置文件目录 |
| -v /data/docker/kafka/secrets:/etc/kafka/secrets | 持久化秘钥相关文件夹 |
容器运行参数详解参考:Docker容器运行常用参数详解-CSDN博客
3、Compose运行Kafka容器
创建docker-compose.yml文件
sudo touch /data/docker/kafka/docker-compose.yml文件内容如下:
version: '3'services:kafka:image: apache/kafka:3.9.0container_name: kafkaports:- "9092:9092"- "9093:9093"environment:- LANG=C.UTF-8- KAFKA_NODE_ID=1- CLUSTER_ID=kafka-cluster- KAFKA_PROCESS_ROLES=broker,controller- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT- KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER- KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.3.9:9092- KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093volumes:- /data/docker/kafka/data:/var/lib/kafka/data- /data/docker/kafka/config:/mnt/shared/config- /data/docker/kafka/secrets:/etc/kafka/secretsprivileged: truenetwork_mode: "bridge"运行容器
#-f:调用文件,-d:开启守护进程
sudo docker compose -f /data/docker/kafka/docker-compose.yml up -d4、查看Kafka运行状态

三、集群部署
采用Broker + Controller集群,这是推荐的生产环境的集群部署方式,集群中不存在混合节点,每个节点要么是Broker类型,要么是Controller类型。
通过下列命令在服务器上部署:
# 定义域名
# 这是fish shell的变量定义语法
# 使用bash请替换为:kafka_host="192.168.3.9"
set kafka_host "192.168.3.9"# 节点1-Controller
sudo docker run -id --privileged=true \--net=bridge --name=kafka-1 \-p 10001:9093 \-v /data/docker/kafka-1/config:/mnt/shared/config \-v /data/docker/kafka-1/data:/var/lib/kafka/data \-v /data/docker/kafka-1/secrets:/etc/kafka/secrets \-e LANG=C.UTF-8 \-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \-e CLUSTER_ID=kafka-cluster \-e KAFKA_NODE_ID=1 \-e KAFKA_PROCESS_ROLES=controller \-e KAFKA_CONTROLLER_QUORUM_VOTERS="1@$kafka_host:10001" \-e KAFKA_LISTENERS="CONTROLLER://:9093" \apache/kafka:3.9.0# 节点2-Broker
sudo docker run -id --privileged=true \--net=bridge --name=kafka-2 \-p 9002:9092 \-v /data/docker/kafka-2/config:/mnt/shared/config \-v /data/docker/kafka-2/data:/var/lib/kafka/data \-v /data/docker/kafka-2/secrets:/etc/kafka/secrets \-e LANG=C.UTF-8 \-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \-e CLUSTER_ID=kafka-cluster \-e KAFKA_NODE_ID=2 \-e KAFKA_PROCESS_ROLES=broker \-e KAFKA_CONTROLLER_QUORUM_VOTERS="1@$kafka_host:10001" \-e KAFKA_LISTENERS="PLAINTEXT://:9092" \-e KAFKA_ADVERTISED_LISTENERS="PLAINTEXT://$kafka_host:9002" \apache/kafka:3.9.0# 节点3-Broker
sudo docker run -id --privileged=true \--net=bridge --name=kafka-3 \-p 9003:9092 \-v /data/docker/kafka-3/config:/mnt/shared/config \-v /data/docker/kafka-3/data:/var/lib/kafka/data \-v /data/docker/kafka-3/secrets:/etc/kafka/secrets \-e LANG=C.UTF-8 \-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \-e CLUSTER_ID=kafka-cluster \-e KAFKA_NODE_ID=3 \-e KAFKA_PROCESS_ROLES=broker \-e KAFKA_CONTROLLER_QUORUM_VOTERS="1@$kafka_host:10001" \-e KAFKA_LISTENERS="PLAINTEXT://:9092" \-e KAFKA_ADVERTISED_LISTENERS="PLAINTEXT://$kafka_host:9003" \apache/kafka:3.9.0这样,我们就部署了一个由1个Controller节点和2个Broker节点构成的集群,需要注意的是:
- Broker节点无需暴露9093端口,Controller节点无需暴露9092端口
- Broker节点需指定KAFKA_PROCESS_ROLES为broker,同样的Controller需要指定为controller
- KAFKA_CONTROLLER_QUORUM_VOTERS配置只需要写集群中所有的Controller节点的地址端口列表
- 对于KAFKA_LISTENERS配置项:Broker节点需要配置为PLAINTEXT://:9092,表示本节点作为Broker节点;Controller节点需要配置为CONTROLLER://:9093,表示本节点作为Controller节点
- 对于KAFKA_ADVERTISED_LISTENERS配置项:Controller节点不能指定该配置;Broker节点需要指定为自己的外网地址和端口
四、部署可视化工具
在早期使用Kafka时,通常会选择Kafka Tool或Kafka Eagle进行管理。Kafka Tool是一款桌面应用程序,而Kafka Eagle则基于浏览器运行。尽管这两款工具在用户体验上表现平平,但它们基本能满足日常需求。
然而,自Kafka 3.3.1版本起,Kafka正式弃用了Zookeeper,转而采用自有的仲裁机制,即kraft模式。遗憾的是,上述两款工具似乎未能及时跟进这一更新,仍然要求用户输入Zookeeper地址才能连接,导致它们在新版本Kafka中无法正常使用。为了解决这一问题,我发现了一款轻量且易于使用的替代工具——kafka-ui,它能够更好地适配新版Kafka。
1、创建挂载目录
# 创建宿主机kafka-ui挂载目录
sudo mkdir -p /data/docker/kafka-ui/config# 创建挂载的配置文件
sudo touch /data/docker/kafka-ui/config/dynamic_config.yaml2、运行Kafka-ui容器
# 拉取镜像
sudo docker pull provectuslabs/kafka-ui:v0.7.2# 运行容器
sudo docker run --privileged=true \
--net=bridge \
-d --name=kafka-ui \
-p 18080:8080 \
-v /data/docker/kafka-ui/config/dynamic_config.yaml:/etc/kafkaui/dynamic_config.yaml
-e KAFKA_CLUSTERS_0_NAME=kafka-cluster \
-e KAFKA_CLUSTERS_0_BOOTSTRAP_SERVERS=192.168.3.9:9092 \
-e SERVER_SERVLET_CONTEXT_PATH=/ \
-e AUTH_TYPE=LOGIN_FORM \
-e SPRING_SECURITY_USER_NAME=admin \
-e SPRING_SECURITY_USER_PASSWORD=admin \
-e TZ=Asia/Shanghai \
-e LANG=C.UTF-8 \
provectuslabs/kafka-ui:v0.7.2参数解析如下:
| 参数 | 参数说明 |
| docker run | 运行 Docker 容器 |
| -d | 容器将在后台运行,而不是占用当前的终端会话 |
| --privileged=true | Docker会赋予容器几乎与宿主机相同的权限 |
| --net=bridge | 网络模式配置,默认是bridge,bridge表示使用容器内部配置网络 |
| --name kafka-ui | 给容器命名为 kafka-ui,以便于管理和引用该容器 |
| -p 18080:8080 | 映射 kafka-ui 的web端口 |
| -v /data/docker/kafka-ui/config/dynamic_config.yaml: /etc/kafkaui/dynamic_config.yaml | 挂载配置文件,确保config/dynamic_config.yaml文件存在 |
| -e SERVER_SERVLET_CONTEXT_PATH=/ | 默认kafka-ui是免登录的,为了防止所有人都可以登录产生误操作问题,在docker部署的时候可以添加如下四个环境变量配置用户的登录密码。 |
| -e AUTH_TYPE=LOGIN_FORM | |
| -e SPRING_SECURITY_USER_NAME=admin | |
| -e SPRING_SECURITY_USER_PASSWORD=admin | |
| -e KAFKA_CLUSTERS_0_NAME=kafka-cluster | 自定义集群名称 |
| -e KAFKA_CLUSTERS_0_BOOTSTRAP_SERVERS= 192.168.3.9:9092 | 集群地址,如有多个地址逗号分隔;需要修改为对应的Kafka的外网地址。 |
3、Compose运行Kafka-ui容器
创建docker-compose.yml文件
sudo touch /data/docker/kafka-ui/docker-compose.yml文件内容如下:
version: '3'services:kafka:image: provectuslabs/kafka-ui:v0.7.2container_name: kafka-uiports:- "18080:8080"environment:- TZ=Asia/Shanghai- LANG=C.UTF-8- DYNAMIC_CONFIG_ENABLED=true- KAFKA_CLUSTERS_0_NAME=kafka-cluster- KAFKA_CLUSTERS_0_BOOTSTRAP_SERVERS=192.168.3.9:9092- SERVER_SERVLET_CONTEXT_PATH=/- AUTH_TYPE=LOGIN_FORM- SPRING_SECURITY_USER_NAME=admin- SPRING_SECURITY_USER_PASSWORD=adminvolumes:- /data/docker/kafka-ui/config/dynamic_config.yaml:/etc/kafkaui/dynamic_config.yamlprivileged: truenetwork_mode: "bridge"运行容器
#-f:调用文件,-d:开启守护进程
sudo docker compose -f /data/docker/kafka-ui/docker-compose.yml up -d4、查看Kafka-ui运行状态
http://192.168.3.9:18080/auth
账号和密码 都是admin

相关文章:
保姆级教程Docker部署KRaft模式的Kafka官方镜像
目录 一、安装Docker及可视化工具 二、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 三、集群部署 四、部署可视化工具 1、创建挂载目录 2、运行Kafka-ui容器 3、Compose运行Kafka-ui容器 4、查看Kafka-ui运行状态 …...

ChatGPT提问技巧:行业热门应用提示词案例--咨询法律知识
ChatGPT除了可以协助办公,写作文案和生成短视频脚本外,和还可以做为一个法律工具,当用户面临一些法律知识盲点时,可以向ChatGPT咨询获得解答。赋予ChatGPT专家的身份,用户能够得到较为满意的解答。 1.咨询法律知识 举…...

openRv1126 AI算法部署实战之——Tensorflow模型部署实战
在RV1126开发板上部署Tensorflow算法,实时目标检测RTSP传输。视频演示地址 rv1126 yolov5 实时目标检测 rtsp传输_哔哩哔哩_bilibili 一、准备工作 从官网下载tensorflow模型和数据集 手动在线下载: https://github.com/tensorflow/models/b…...

STM32 TIM定时器配置
TIM简介 TIM(Timer)定时器 定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断 16位计数器、预分频器、自动重装寄存器的时基单元,在72MHz计数时钟下可以实现最大59.65s的定时 不仅具备基本的定时中断功能ÿ…...

51单片机 05 矩阵键盘
嘻嘻,LCD在RC板子上可以勉强装上,会有一点歪。 一、矩阵键盘 在键盘中按键数量较多时,为了减少I/O口的占用,通常将按键排列成矩阵形式;采用逐行或逐列的“扫描”,就可以读出任何位置按键的状态。…...

SSRF 漏洞利用 Redis 实战全解析:原理、攻击与防范
目录 前言 SSRF 漏洞深度剖析 Redis:强大的内存数据库 Redis 产生漏洞的原因 SSRF 漏洞利用 Redis 实战步骤 准备环境 下载安装 Redis 配置漏洞环境 启动 Redis 攻击机远程连接 Redis 利用 Redis 写 Webshell 防范措施 前言 在网络安全领域࿰…...

kubernetes学习-配置管理(九)
一、ConfigMap (1)通过指定目录,创建configmap # 创建一个config目录 [rootk8s-master k8s]# mkdir config[rootk8s-master k8s]# cd config/ [rootk8s-master config]# mkdir test [rootk8s-master config]# cd test [rootk8s-master test…...

python 语音识别
目录 一、语音识别 二、代码实践 2.1 使用vosk三方库 2.2 使用SpeechRecognition 2.3 使用Whisper 一、语音识别 今天识别了别人做的这个app,觉得虽然是个日记app 但是用来学英语也挺好的,能进行语音识别,然后矫正语法,自己说的时候 ,实在不知道怎么说可以先乱说,然…...

一文速览DeepSeek-R1的本地部署——可联网、可实现本地知识库问答:包括671B满血版和各个蒸馏版的部署
前言 自从deepseek R1发布之后「详见《一文速览DeepSeek R1:如何通过纯RL训练大模型的推理能力以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》」,deepseek便爆火 爆火以后便应了“人红是非多”那句话,不但遭受各种大规模攻击,即便…...

[mmdetection]fast-rcnn模型训练自己的数据集的详细教程
本篇博客是由本人亲自调试成功后的学习笔记。使用了mmdetection项目包进行fast-rcnn模型的训练,数据集是自制图像数据。废话不多说,下面进入训练步骤教程。 注:本人使用linux服务器进行展示,Windows环境大差不差。另外࿰…...

1. Kubernetes组成及常用命令
Pods(k8s最小操作单元)ReplicaSet & Label(k8s副本集和标签)Deployments(声明式配置)Services(服务)k8s常用命令Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。自2014年发布以来,K8s迅速成为容器编排领域的行业标准,被…...

linux下ollama更换模型路径
Linux下更换Ollama模型下载路径指南 在使用Ollama进行AI模型管理时,有时需要根据实际需求更改模型文件的存储路径。本文将详细介绍如何在Linux系统中更改Ollama模型的下载路径。 一、关闭Ollama服务 在更改模型路径之前,需要先停止Ollama服务。…...

本地Ollama部署DeepSeek R1模型接入Word
目录 1.本地部署DeepSeek-R1模型 2.接入Word 3.效果演示 4.问题反馈 上一篇文章办公新利器:DeepSeekWord,让你的工作更高效-CSDN博客https://blog.csdn.net/qq_63708623/article/details/145418457?spm1001.2014.3001.5501https://blog.csdn.net/qq…...

【自学笔记】Git的重点知识点-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Git基础知识Git高级操作与概念Git常用命令 总结 Git基础知识 Git简介 Git是一种分布式版本控制系统,用于记录文件内容的改动,便于开发者追踪…...

[EAI-028] Diffusion-VLA,能够进行多模态推理和机器人动作预测的VLA模型
Paper Card 论文标题:Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression 论文作者:Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chao…...

实现数组的扁平化
文章目录 1 实现数组的扁平化1.1 递归1.2 reduce1.3 扩展运算符1.4 split和toString1.5 flat1.6 正则表达式和JSON 1 实现数组的扁平化 1.1 递归 通过循环递归的方式,遍历数组的每一项,如果该项还是一个数组,那么就继续递归遍历,…...
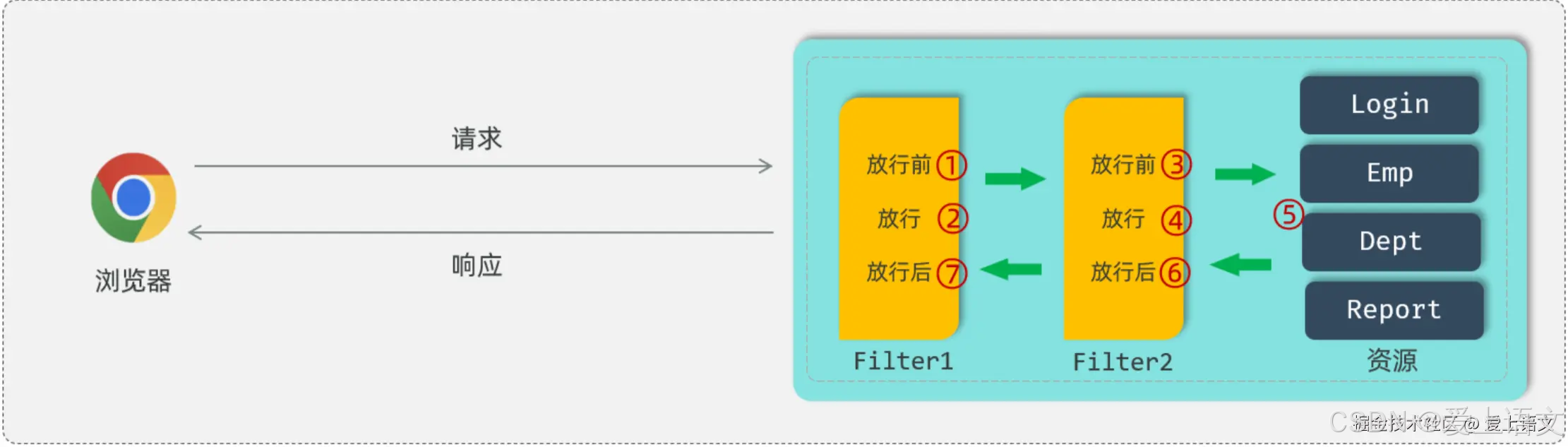
登录认证(5):过滤器:Filter
统一拦截 上文我们提到(登录认证(4):令牌技术),现在大部分项目都使用JWT令牌来进行会话跟踪,来完成登录功能。有了JWT令牌可以标识用户的登录状态,但是完整的登录逻辑如图所示&…...

pytorch实现门控循环单元 (GRU)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 特性GRULSTM计算效率更快,参数更少相对较慢,参数更多结构复杂度只有两个门(更新门和重置门)三个门(输入门、遗忘门、输出门)处理长时依赖一般适…...

Word List 2
词汇颜色标识解释 词汇表中的生词 词汇表中的词组成的搭配、派生词 例句中的生词 我自己写的生词(用于区分易混淆的词,无颜色标识) 不认识的单词或句式 单词的主要汉语意思 不太理解的句子语法和结构 Word List 2 英文音标中文regi…...

机器学习常用包numpy篇(四)函数运算
目录 前言 一、三角函数 二、双曲函数 三、数值修约 四、 求和、求积与差分 五、 指数与对数 六、算术运算 七、 矩阵与向量运算 八、代数运算 九、 其他数学工具 总结 前言 Python 的原生运算符可实现基础数学运算(加减乘除、取余、取整、幂运算&#…...
)
Gemini在Android Automotive OS上的首次深度集成(车规级低延迟通信协议逆向分析+CAN总线AI指令映射表)
更多请点击: https://intelliparadigm.com 第一章:Gemini在Android Automotive OS上的首次深度集成(车规级低延迟通信协议逆向分析CAN总线AI指令映射表) Google Gemini模型通过定制化Android Automotive OS(AAOS&…...

浏览器扩展开发实战:深入解析Markdown Viewer架构设计与实现
浏览器扩展开发实战:深入解析Markdown Viewer架构设计与实现 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 在现代Web开发工作流中,Markdown文档的即时预…...

【DL】信息注入
在多模态生成(如文生图、3D生成)和视觉语言模型(VLM/VLA)的架构设计中,如何将外部条件(如文本、音频、时间步、控制信号)优雅且高效地“注入”到主干网络(Backbone)中,是决定模型性能的核心。 以下是深度整合了底层张量维度差异的 5 大类主流信息注入方法全景指南:…...

联想IdeaPad 310S老本升级记:手把手教你加内存、换固态、装Win10+Ubuntu双系统
联想IdeaPad 310S性能重生指南:从硬件升级到双系统实战 每次打开这台2016年购入的联想IdeaPad 310S,风扇的嘶吼和系统卡顿都让人抓狂。作为一款定位入门级的笔记本,它搭载的i3-6006U处理器和4GB内存早已跟不上现代应用的需求。但直接换新机又…...

46页可编辑PPT | 企业数字化转型总体规划与实践汇报方案
很多企业在数字化转型过程中会遇到一些共同的痛点。比如,数据孤岛问题,不同部门的数据互不相通,导致信息共享困难;业务流程繁琐,效率低下,难以快速响应市场变化;技术更新换代快,现有…...

117.YOLOv5/v8数学原理+CSPDarknet架构,CUDA117环境一键部署
摘要 YOLO(You Only Look Once)系列算法是目标检测领域最主流的实时检测框架,其核心思想是将目标检测任务转化为一个端到端的回归问题。 本文从数学原理出发,系统阐述YOLOv5/v8的架构演进与核心机制,并提供一个从数据准备、模型训练到ONNX部署的完整可运行案例。 文章所有…...

HoRain云--PHP包含文件全解析
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

插入排序:原理与优化全解析
一、核心原理把数组分为 已排序区间 和 未排序区间从头开始,依次把未排序区间的第一个元素,向前插入到已排序区间的合适位置。类比:打牌摸牌,摸到一张往手里有序牌堆里插。二、算法流程默认第 0 个元素是已排序区间;从…...

NLTK数据包高效部署与下载加速实战
1. NLTK数据包下载慢?这些方法让你效率翻倍 第一次用NLTK跑自然语言处理项目时,我在数据包下载环节卡了整整三小时。看着进度条像蜗牛爬行,我甚至怀疑是不是网络断了。后来才发现,这是所有NLTK初学者都会遇到的经典问题——由于默…...
)
ESP32-CAM上传图片总失败?排查HTTP POST到巴法云的5个常见坑(WiFi、电源、引脚)
ESP32-CAM图片上传失败排查指南:从硬件到平台的5大关键点 当你满怀期待地将ESP32-CAM对准拍摄对象,却发现图片始终无法上传到巴法云时,那种挫败感我深有体会。这不是一个简单的"复制粘贴代码就能运行"的项目,而是一个需…...