最新EFK(Elasticsearch+FileBeat+Kibana)日志收集
文章目录
- 1.EFK介绍
- 2.操作前提
- 3.FileBeat8.15下载&安装
- 4.编写FileBeat配置文件
- 5.启动FileBeat
- 6.模拟实时日志数据生成
- 7.查看索引(数据流)是否创建成功
- 8.创建数据视图:
- 9.查看数据视图
- 10.使用KQL对采集的日志内容进行过滤
- 11.给日志数据配置保留天数(扩展知识)
1.EFK介绍
Kibana参考官方文档:https://www.elastic.co/guide/en/beats/filebeat/8.15/filebeat-overview.html

2.操作前提
需要提前安装Elasticsearch+Kibana。安装过程见我上一个文章:elasticsearch8.15 高可用集群搭建(含认证&Kibana)
3.FileBeat8.15下载&安装
软件下载地址:https://www.elastic.co/downloads/past-releases/filebeat-8-15-0

下载文件后上传至服务器
# 创建目录
mkdir -p /opt/software/
#解压至特定目录
tar -zxvf filebeat-8.15.0-linux-x86_64.tar.gz -C /opt/software/
#切到filebeat安装目录
cd /opt/software/filebeat-8.15.0-linux-x86_64
4.编写FileBeat配置文件
注:FileBeat配置文在FileBeat安装目录下的filebeat.yml。我这里是重新创建一个配置文件,启动FileBeat时指定我自己创建的配置文件。你可以看情况来。
# 创建配置目录
mkdir config
# filebeat_2_es.yml默认是不存在的,编辑保持后,该文件会自动创建
vim config/filebeat_2_es.yml
filebeat_2_es.yml配置文件完整内容如下:
filebeat.inputs: #数据输入相关配置- type: filestream # (必填)数据输入类型是filestreamid: nginx-access-log-1 # (必填)全局唯一即可enabled: true # 启动paths:- /tmp/logs/nginx_access.log* # 当前要监听的文件, *是通配符任意。例如nginx.access.log.1 的文件内容也会被监听到。tags: ["nginx-access-log"] # (可选)这里定义用户自定义值。用于下文的索引条件选择 以及 后续kibana上也可以用该标签做数据过滤fields:my_server_ip: 192.168.25.31 # (可选)这里定义用户自定义属性,后面会出现在采集数据中fields_under_root: true # (可选)让上面Field里面定义的属性出现在采集数据的最外层,而不是嵌套在采集数据的filed字段里面。#exclude_lines: ['^DBG'] # (可选)当前数据行如果以DBG开头,则当前数据行不会被采集#include_lines: ['^ERR', '^WARN'] # (可选)当前数据行以“ERR”或“WAR”开头,采可能会被采集- type: filestreamid: nginx-error-log-1enabled: truepaths:- /tmp/logs/nginx_error.log*tags: ["nginx-error-log"]fields:my_server_ip: 192.168.25.31 fields_under_root: true#exclude_lines: ['^DBG'] #要求当前数据行必须不能以DBG开头include_lines: ['\[error\]'] #要求当前数据行必须以“ERR”或“WAR”开头- type: filestreamid: elasticsearch-log-1enabled: truepaths:- /tmp/logs/elasticsearch.log*tags: ["elasticsearch-log"]fields:my_server_ip: 192.168.25.31 fields_under_root: trueparsers:- multiline: #多行匹配。例如 java异常日志,一般一个异常会占用多行,此时需要把一个异常下的多行日志合成一行日志。参考:https://www.elastic.co/guide/en/beats/filebeat/8.15/multiline-examples.htmltype: patternpattern: '^\[' # 匹配模式。每一行日志是以 "["开头。negate: true # 这个可以固定,参考:https://www.elastic.co/guide/en/beats/filebeat/8.15/multiline-examples.htmlmatch: after # 这个可以固定,参考:https://www.elastic.co/guide/en/beats/filebeat/8.15/multiline-examples.html
#output.console:
# pretty: true
output.elasticsearch:enabled: truehosts: ["http://192.168.25.31:9200", "http://192.168.25.32:9200", "http://192.168.25.33:9200"]username: "elastic"password: "123456"indices:- index: "log-software-nginx-access-%{+yyyy.MM.dd}" when.contains:tags: "nginx-access-log"- index: "log-software-nginx-error-%{+yyyy.MM.dd}" when.contains:tags: "nginx-error-log"- index: "log-software-elasticsearch-%{+yyyy.MM.dd}" when.contains:tags: "elasticsearch-log"
#必须把ilm索引生命周期管理关掉(否则上面的indecis索引条件、以及下面的setup.template.pattern将会生效)
setup.ilm.enabled: false
#默认索引名称是filebeat,如果想上面自定义索引上面,需要设置 模板name和匹配。pattern必须能匹配 上面设置的索引名称
setup.template.name: "log"
setup.template.pattern: "log*"
setup.template.overwrite: false
setup.template.settings:index.number_of_shards: 3 # 索引在ES的分片数index.number_of_replicas: 1 # 每个索引的分片在ES的副本数
5.启动FileBeat
./filebeat -e -c config/filebeat_2_es.yml
小技巧::filebeat可以采集已有文件的数据,也可以采集实时往文件里面写入的数据。文件里的数据一旦被filebeat采集后,后面就不会对应已经采集过的数据内容进行重新采集。如果你想每次启动filebeat的时候,能重新采集已经采集过的文件数据,那么可以在启动前执行rm -rf /opt/software/filebeat-8.15.0-linux-x86_64/data/*”,然后再启动filebeat,执行会重新采集已有文件的数据。这个data目录下记录的是filebeat的已采集过的采集信息,故而删掉后,filebeat获取不到之前的采集记录,故而会重新对已有文件进行重新采集。
6.模拟实时日志数据生成
模拟Nginx access日志
cat > nginx_access.log << 'EOF'
192.168.25.83 - - [31/Jan/2025:21:42:22 +0000] "\x03\x00\x00/*\xE0\x00\x00\x00\x00\x00Cookie: mstshash=Administr" 400 157 "-" "-" "-"
192.168.25.83 - - [01/Feb/2025:11:18:18 +0000] "GET / HTTP/1.1" 400 255 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:130.0) Gecko/20100101 Firefox/130.0" "-"EOF
模拟Nginx error日志
cat > nginx_error.log << 'EOF'
2025/01/13 19:15:52 [error] 8#8: *634461 "/usr/local/nginx/html/index.html" is not found (2: No such file or directory), client: 172.168.110.83, server: localhost, request: "GET / HTTP/1.1", host: "192.168.25.10:80"
2025/01/17 17:37:05 [error] 10#10: *770125 "/usr/local/nginx/html/index.html" is not found (2: No such file or directory), client: 172.168.110.83, server: localhost, request: "GET / HTTP/1.1", host: "192.168.25.10:80"
我不是错误数据日志行,看是否会把我给过滤掉[error]我是错误消息[error]我是错误消息2
EOF
模拟ES日志(含异常:后面验证是否会把异常的多行日志合在一起)
cat > elasticsearch.log << 'EOF'
[2025-02-02T01:20:03,049][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.transaction.1m@template] for index patterns [metrics-apm.transaction.1m-*]
[2025-02-02T01:20:03,113][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.service_destination.60m@template] for index patterns [metrics-apm.service_destination.60m-*]
[2025-02-02T01:20:03,186][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.service_transaction.60m@template] for index patterns [metrics-apm.service_transaction.60m-*]
[2025-02-02T01:20:03,232][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [traces-apm.rum@template] for index patterns [traces-apm.rum-*]
[2025-02-02T01:20:03,319][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.service_destination.10m@template] for index patterns [metrics-apm.service_destination.10m-*]
[2025-02-02T01:20:03,383][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.service_transaction.10m@template] for index patterns [metrics-apm.service_transaction.10m-*]
[2025-02-02T01:20:03,501][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.transaction.60m@template] for index patterns [metrics-apm.transaction.60m-*]
[2025-02-02T01:20:03,582][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.app@template] for index patterns [metrics-apm.app.*-*]
[2025-02-02T01:20:03,677][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [traces-apm@template] for index patterns [traces-apm-*]
[2025-02-02T01:20:03,735][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [logs-apm.app@template] for index patterns [logs-apm.app.*-*]
[2025-02-02T01:20:03,850][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [traces-apm.sampled@template] for index patterns [traces-apm.sampled-*]
[2025-02-02T01:20:03,943][INFO ][o.e.c.m.MetadataIndexTemplateService] [node-2] adding index template [metrics-apm.service_destination.1m@template] for index patterns [metrics-apm.service_destination.1m-*]
[2025-02-02T01:20:04,317][ERROR][o.e.x.c.t.IndexTemplateRegistry] [node-2] error adding ingest pipeline template [ent-search-generic-ingestion] for [enterprise_search]
java.lang.IllegalStateException: Ingest info is emptyat org.elasticsearch.ingest.IngestService.validatePipeline(IngestService.java:648) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.validatePipelineRequest(IngestService.java:465) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.lambda$putPipeline$5(IngestService.java:448) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:202) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:196) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$RunBeforeActionListener.onResponse(ActionListenerImplementations.java:307) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$MappedActionListener.onResponse(ActionListenerImplementations.java:95) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.respondAndRelease(ActionListener.java:367) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$newResponseAsync$2(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.run(ActionListener.java:444) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.newResponseAsync(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction$1.lambda$onCompletion$4(TransportNodesAction.java:166) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$doExecute$0(TransportNodesAction.java:178) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ThreadedActionListener$1.doRun(ThreadedActionListener.java:39) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:984) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) ~[elasticsearch-8.15.0.jar:?]at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) ~[?:?]at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) ~[?:?]at java.lang.Thread.run(Thread.java:1570) ~[?:?]
[2025-02-02T01:20:04,395][ERROR][o.e.x.c.t.IndexTemplateRegistry] [node-2] error adding ingest pipeline template [behavioral_analytics-events-final_pipeline] for [enterprise_search]
java.lang.IllegalStateException: Ingest info is emptyat org.elasticsearch.ingest.IngestService.validatePipeline(IngestService.java:648) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.validatePipelineRequest(IngestService.java:465) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.lambda$putPipeline$5(IngestService.java:448) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:202) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:196) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$RunBeforeActionListener.onResponse(ActionListenerImplementations.java:307) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$MappedActionListener.onResponse(ActionListenerImplementations.java:95) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.respondAndRelease(ActionListener.java:367) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$newResponseAsync$2(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.run(ActionListener.java:444) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.newResponseAsync(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction$1.lambda$onCompletion$4(TransportNodesAction.java:166) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$doExecute$0(TransportNodesAction.java:178) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ThreadedActionListener$1.doRun(ThreadedActionListener.java:39) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:984) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) ~[elasticsearch-8.15.0.jar:?]at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) ~[?:?]at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) ~[?:?]at java.lang.Thread.run(Thread.java:1570) ~[?:?]
[2025-02-02T01:20:04,399][ERROR][o.e.x.c.t.IndexTemplateRegistry] [node-2] error adding ingest pipeline template [search-default-ingestion] for [enterprise_search]
java.lang.IllegalStateException: Ingest info is emptyat org.elasticsearch.ingest.IngestService.validatePipeline(IngestService.java:648) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.validatePipelineRequest(IngestService.java:465) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.ingest.IngestService.lambda$putPipeline$5(IngestService.java:448) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:202) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.tasks.TaskManager$1.onResponse(TaskManager.java:196) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$RunBeforeActionListener.onResponse(ActionListenerImplementations.java:307) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:32) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$MappedActionListener.onResponse(ActionListenerImplementations.java:95) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.respondAndRelease(ActionListener.java:367) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$newResponseAsync$2(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListener.run(ActionListener.java:444) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.newResponseAsync(TransportNodesAction.java:215) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction$1.lambda$onCompletion$4(TransportNodesAction.java:166) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.nodes.TransportNodesAction.lambda$doExecute$0(TransportNodesAction.java:178) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.ActionListenerImplementations$ResponseWrappingActionListener.onResponse(ActionListenerImplementations.java:245) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.action.support.ThreadedActionListener$1.doRun(ThreadedActionListener.java:39) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:984) ~[elasticsearch-8.15.0.jar:?]at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:26) ~[elasticsearch-8.15.0.jar:?]at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) ~[?:?]at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) ~[?:?]at java.lang.Thread.run(Thread.java:1570) ~[?:?]
EOF
7.查看索引(数据流)是否创建成功
登陆进行kibana。登陆地址:http://你的kibana所在服务器IP:5601/
点击左侧菜单的“Stack Management”选项

点击“Stack Management”之下的“索引管理” 之下的“数据流”。
可以看到我们的配置文件中指定的索引,已经变成了 对应的数据流。

8.创建数据视图:
菜单位置:Stack Management --> 数据视图
#创建数据视图时,内容可以填下面这几个。
名称:软件日志
索引模式:log-software*
时间戳字段:@timestamp
注:上面这个索引模式你可以根据实际需求来,例如你也可以填log-software-nginx-access-*。这样创建出来的数据视图就只有nginx-access日志的。上面log-software*匹配的是所有的软件日志,即匹配下图的这三个数据流。

9.查看数据视图
菜单位置:Discover


检查es多行异常是否被合成一行:

效果如下,一个异常的多行内容被合在一行了。

10.使用KQL对采集的日志内容进行过滤
KQL语法:

示例1:过滤出ES日志:
查询条件:
tags : "elasticsearch-log"

示例2:过滤出ES日志,并且过滤出存在error的日志
查询条件:
tags : "elasticsearch-log" and message:error

11.给日志数据配置保留天数(扩展知识)
我们在上面的Filebeat配置文件指定了一个名为“log”的索引模板(setup.template.name),默认通过该索引模板创建出来的索引、数据流 日志数据是永久保留的,故而我们需要更改索引模板里的数据保留天数(界面方式)。
修改索引模板

把索引模板“log”里面的“数据保留时间”进行开启,然后设置对应的数据保留天数,然后一直点下一步即可。

重新把之前自动创建的几个“数据流”给删掉。

在filebeat上执行 rm -rf data/* ,然后启动filebeat重新采集日志文件数据,此时会自动创建 “索引数据流”,记得把filebeat配置文件的“setup.template.overwrite: false”索引模板重写设置为fasle。
重新访问kibana的索引管理,发现自动创建出来的数据流已经有“数据保留时间”了,并且保留时间和我们在索引模板里面指定的保留天数一致。效果如下:

至此,大功告成~~~~
相关文章:
最新EFK(Elasticsearch+FileBeat+Kibana)日志收集
文章目录 1.EFK介绍2.操作前提3.FileBeat8.15下载&安装4.编写FileBeat配置文件5.启动FileBeat6.模拟实时日志数据生成7.查看索引(数据流)是否创建成功8.创建数据视图:9.查看数据视图10.使用KQL对采集的日志内容进行过滤11.给日志数据配置保留天数(扩展知识) 1.E…...

Vue 3 30天精进之旅:Day 15 - 插件和指令
欢迎来到“Vue 3 30天精进之旅”的第15天!今天我们将深入探讨Vue 3中的插件和自定义指令。这两个主题能够帮助我们扩展Vue的功能,使我们的应用更加灵活和强大。 一、插件概述 1. 什么是插件? 在Vue中,插件是一种功能扩展机制。…...

【实战篇】Android安卓本地离线实现视频检测人脸
实战篇Android安卓本地离线实现视频检测人脸 引言项目概述核心代码类介绍人脸检测流程项目地址总结 引言 在当今数字化时代,人脸识别技术已经广泛应用于各个领域,如安防监控、门禁系统、移动支付等。本文将以第三视角详细讲解如何基于bifan-wei-Face/De…...
 》笔记-Chapter3-语言基础)
【JavaScript】《JavaScript高级程序设计 (第4版) 》笔记-Chapter3-语言基础
三、语言基础 ECMAScript 的语法很大程度上借鉴了 C 语言和其他类 C 语言,如 Java 和 Perl。ECMAScript 中一切都区分大小写。无论是变量、函数名还是操作符,都区分大小写。 所谓标识符,就是变量、函数、属性或函数参数的名称。标识符可以由…...
-堆栈溢出-野指针-内存泄露(问题定位))
(dpdk f-stack)-堆栈溢出-野指针-内存泄露(问题定位)
目的:解决堆栈溢出,野指针,内存泄露。 解决方法 [root@ test]# yum install libasan [root@ test]# cat test.c int main() { int array[10]; array[11] = 11; return 0; } [root@ test]# gcc -fsanitize=address -O1 -fno-omit-frame-pointer -g -O0 test.c -o test ./te…...

HTML5 教程之标签(3)
HTML5 <center> 标签 (已废弃) 定义和用法 <center> 标签对其包围的文本进行水平居中处理。HTML5不支持使用<center>标签,因此有关该标签的更多信息,请参考“HTML <center>标签”部分! 示例: <center>这个…...

【蓝桥】动态规划-简单-破损的楼梯
题目 解题思路 完整代码 #include <bits/stdc.h> using namespace std; const int N1e59; const long long p1e97; long long dp[N];//dp[i]表示走到第i级台阶的方案数 bool broken[N];//broken代表破损台阶的数组 int main() {int n,m;cin>>n>>m;for(int …...

如何自定义软件安装路径及Scoop包管理器使用全攻略
如何自定义软件安装路径及Scoop包管理器使用全攻略 一、为什么无法通过WingetUI自定义安装路径? 问题背景: WingetUI是Windows包管理器Winget的图形化工具,但无法直接修改软件的默认安装路径。原因如下: Winget设计限制…...

107,【7】buuctf web [CISCN2019 华北赛区 Day2 Web1]Hack World
这次先不进入靶场 看到红框里面的话就想先看看uuid是啥 定义与概念 UUID 是 Universally Unique Identifier 的缩写,即通用唯一识别码。它是一种由数字和字母组成的 128 位标识符,在理论上可以保证在全球范围内的唯一性。UUID 的设计目的是让分布式系…...

STM32 ADC单通道配置
硬件电路 接线图: ADC基本结构图 代码配置 根据基本结构框图 1.定义结构体变量 //定义结构体变量 GPIO_InitTypeDef GPIO_InitStructure;//定义GPIO结构体变量 ADC_InitTypeDef ADC_InitStructure; //定义ADC结构体变量 2.开启RCC时钟 ADC、GPIO的时钟&#x…...

【技海登峰】Kafka漫谈系列(二)Kafka高可用副本的数据同步与选主机制
【技海登峰】Kafka漫谈系列(二)Kafka高可用副本的数据同步与选主机制 一. 数据同步 在之前的学习中有了副本Replica的概念,解决了数据备份的问题。我们还需要面临一个设计难题即:如何处理分区中Leader与Follwer节点数据同步不匹配问题所带来的风险,这也是保证数据高可用的…...

Spring的三级缓存如何解决循环依赖问题
循环依赖问题是在对象之间存在相互依赖关系,形成一个闭环,导致无法准确的完成对象的创建和初始化,当两个或多个对象彼此之间相互引用,这种相互引用形成一个循环时,就可能出现循环依赖问题。 在 Spring 框架中…...

Ext文件系统
文件内容属性 被打开的文件在内存中,没有被打开的文件在磁盘里文件系统的工作就是根据路径帮我们找到在磁盘上的文件 磁盘(硬件) 磁盘的存储结构 磁头在传动臂的运动下共同进退,向磁盘写入的时候是向柱面批量写入的 OS文件系统访…...

回溯算法---数独问题
回溯算法理论基础 回溯和递归密不可分,有回溯就有递归,所谓回溯就是基于一个叉树,可能是二叉树或者是三叉树,从root节点开始深度优先搜索遍历节点,当遍历到一个子节点时,回溯到上一个根节点选择另外一个子…...
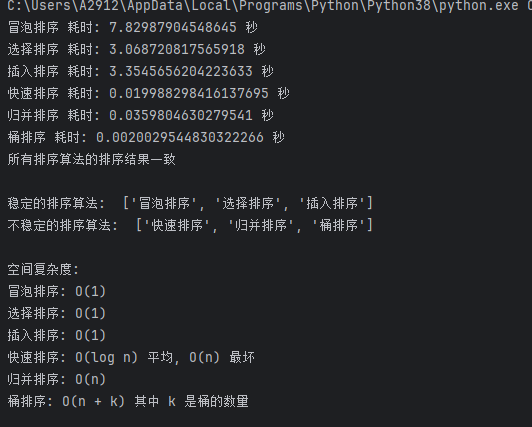
蓝桥杯python基础算法(2-1)——排序
目录 一、排序 二、例题 P3225——宝藏排序Ⅰ 三、各种排序比较 四、例题 P3226——宝藏排序Ⅱ 一、排序 (一)冒泡排序 基本思想:比较相邻的元素,如果顺序错误就把它们交换过来。 (二)选择排序 基本思想…...

【课程笔记】信息隐藏与数字水印
文章总览:YuanDaiMa2048博客文章总览 【课程笔记】信息隐藏与数字水印 信号处理基础知识隐写系统隐写算法性能指标音频信号处理基础数字音频概念人类听觉系统与语音质量评价信息隐藏的原理数字指纹与版权保护盲水印与非盲水印私钥水印与公钥水印信息隐藏的研究层次信息隐藏与数…...

Page Assist实现deepseek离线部署的在线搜索功能
前面文章Mac 基于Ollama 本地部署DeepSeek离线模型 实现了deepseek的离线部署,但是部署完成虽然可以进行问答和交互,也有thinking过程,但是没办法像官方一样进行联网搜索。今天我们介绍一款浏览器插件Page Assist来实现联网搜索,完…...

composeUI中Box 和 Surface的区别
在 Jetpack Compose 中,Box 和 Surface 都是常用的布局组件,但它们的用途和功能有所不同。 Box 组件: 功能:Box 是一个用于将子组件堆叠在一起的布局容器,类似于传统 Android 中的 FrameLayout。用途:适用…...

【LeetCode】5. 贪心算法:买卖股票时机
太久没更了,抽空学习下。 看一道简单题。 class Solution:def maxProfit(self, prices: List[int]) -> int:cost -1profit 0for i in prices:if cost -1:cost icontinueprofit_ i - costif profit_ > profit:profit profit_if cost > i:cost iret…...

MySQL表的CURD
目录 一、Create 1.1单行数据全列插入 1.2多行数据指定列插入 1.3插入否则更新 1.4替换 2.Retrieve 2.1 select列 2.1.1全列查询 2.1.2指定列查询 2.1.3查询字段为表达式 2.1.4为查询结果指定别名 2.1.5结果去重 2.2where条件 2.3结果排序 2.4筛选分页结果 三…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

ElevenLabs匈牙利语音API响应延迟飙升300%?内网穿透+CDN缓存+匈牙利语音素预加载三阶优化方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利文语音API响应延迟飙升300%的现象复现与根因定位 近期多位开发者反馈,ElevenLabs API 在处理匈牙利语(hu-HU)文本转语音请求时,平均端到…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

开源可视化利器:用声明式数据驱动构建交互式技术解释图
1. 项目概述:一个将复杂概念可视化的开源利器最近在整理技术分享材料时,我一直在寻找一种能直观展示复杂系统架构或算法流程的工具。传统的流程图工具要么太笨重,要么定制化程度不够,直到我遇到了nicobailon/visual-explainer这个…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...

本地可控 AI 助手搭建|Windows 一键安装 OpenClaw 操作指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建专属数字员工 前言 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),在 GitHub 收获大量关注,凭借本地运行、零代码操作、自动…...

005 DevEco Studio OHPM同步404报错 解决文档
[cs]005 DevEco Studio OHPM同步404报错 解决文档 文档简介 本文解决鸿蒙开发中新建空白项目自动触发ohpm install时报错:ohos/hypium、ohos/hamock包404找不到、拉取依赖失败问题。 核心原则:不修改项目任何自带文件、不删除系统生成依赖、不改动业务代…...

APK安装器终极指南:3种方法让Windows电脑秒变安卓设备
APK安装器终极指南:3种方法让Windows电脑秒变安卓设备 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows用户设计的安卓应用安装工…...

Java——定时任务
定时任务1、Timer和TimerTask1.1、基本用法1.2、基本示例1.3、基本原理1.4、死循环1.5、异常任务1.6、总结2、ScheduledExecutorService2.1、基本用法2.2、基本示例2.3、基本原理在Java中,主要有两种方式实现定时任务: 使用java.util包中的Timer和Timer…...