5、大模型的记忆与缓存
文章目录
- 本节内容介绍
- 记忆
- Mem0
- 使用 mem0 实现长期记忆
- 缓存
- LangChain 中的缓存
- 语义缓存
本节内容介绍
本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义缓存还可以使用一些rag的检索库进行替代
记忆
所谓记忆,是表现得像大模型能够记住一些事情。在之前的课程里,我们说过,大模型的 API 是无状态的,所以,大模型本质上是没有记忆的。大模型记忆的实现是通过在提示词中传递更多的内容实现的。
讨论 Agent 系统实现的时候,我们谈到了记忆组件,它包括两个部分,短期记忆和长期记忆。其中,短期记忆我们在讨论聊天机器人时已经谈到了,实现记忆的方案就是将聊天历史放到提示词中,这是一个通用的做法。但是,正如我们那一讲里所说的,能放到提示词的聊天历史是有限的,所以,它只能记住“近期”的事,这也是这种方案被称为短期记忆的原因。
长期记忆要解决的就是短期记忆未能解决的问题,希望我们的 AI 应用能够记住更久远的聊天历史。如果能够拥有长期记忆,事情就会变得更有趣,一个聊天机器人就会变得像你的一个老朋友,它会对你的偏好有更多的了解,如果是一个 Agent,它就可以更好地针对你的特点,为你提供服务。
为什么长期记忆是一个问题?从本质上说,这是大模型上下文大小有限造成的问题。前面说过,几乎每个模型的上下文窗口都是有限的。如果上下文窗口是无限的,我们完全可以用短期记忆的解决方案,也就是把所有的聊天历史都发送给大模型,让大模型“记住”所有的东西。
该如何解决长期记忆问题呢?很遗憾,长期记忆的实现在业界还没有统一的方案。但值得欣慰的是,有很多人在尝试。
常见的一个思路是,把需要记忆的内容存放到向量数据库中,采用类似于 RAG 的方案,在生成的时候,先到向量数据库中进行索引,把索引到内容放到提示词里面。当然,在具体的实现里,什么样的内容是需要记忆的内容、怎样提取怎样的内容等等,都是需要解决的问题,更有甚者,有的实现还要实现深度的挖掘,找到不同事物之间的关系。
尽管没有哪个方案取得主导的地位,但长期记忆在这个领域里确实是非常重要的一个组成部分。所以,这一讲,我还是会选择一个项目来重点学习,这个项目就是 mem0:github地址。
Mem0
根据 mem0 的自我介绍,它是为大模型应用提供的一个能够自我改进的记忆层。
这个项目甫一开源就受到了极大的关注,其中固然有这个项目本身的魅力,还有一个很重要的原因就是,它是由之前的一个项目改造而来。前一个项目叫 embedchain,是一个 RAG 框架,可以通过配置实现一个 RAG 应用。在研发过程中,研发团队发现一个长期记忆的项目是比 RAG 框架更有价值,于是,mem0 替代了 embedchain。
选择 mem0 作为长期记忆的实现方案作为我们的学习对象,固然是因为它很强大,能够满足介绍长期记忆的需要。还有一点是,它的 API 设计得很简洁,相对于其它一些方案,mem0 的 API 更容易理解。
我自己使用opena的环境配置:
import os# 设置环境变量
os.environ['http_proxy'] = 'http://127.0.0.1:7890'
os.environ['https_proxy'] = 'http://127.0.0.1:7890'
os.environ['all_proxy'] = 'http://127.0.0.1:7890'# export HTTP_PROXY=http://127.0.0.1:7890; #换成你自己的代理地址
# export HTTPS_PROXY=http://127.0.0.1:7890; #换成你自己的代理地址
# export ALL_PROXY=socks5://127.0.0.1:7890#换成你自己的代理地址from openai import OpenAI
import os
os.environ["OPENAI_API_KEY"] = 'sk-openaikey'DEFAULT_MODEL = "gpt-4o-mini"
client = OpenAI()
下面就是一个例子的具体代码:
## 要使用mem0,需要安装包:pip install mem0aifrom mem0 import Memoryconfig = {"version": "v1.1","llm": {"provider": "openai","config": {"model": "gpt-4o-mini","temperature": 0,"max_tokens": 1500,}},"embedder": {"provider": "openai","config": {"model": "text-embedding-ada-002"}},"vector_store": {"provider": "chroma","config": {"collection_name": "mem0db","path": "mem0db",}},"history_db_path": "history.db",
}m = Memory.from_config(config)m.add("我喜欢读书", user_id="dreamhead", metadata={"category": "hobbies"})
m.add("我喜欢编程", user_id="dreamhead", metadata={"category": "hobbies"})related_memories = m.search(query="dreamhead有哪些爱好?", user_id="dreamhead")
print(' '.join([mem["memory"] for mem in related_memories['results']]))
抛开配置部分,这里我调用了 add 向 Memory 中添加了我的信息。然后,调用 search 查找相关的信息:
喜欢读书 喜欢编程
如果查看 mem0 的文档,你会发现它的 API 相当简单,无非是常见的增删改查。如果不是知道它的作用,我们甚至以为自己看到的是一个数据库的接口。这就是这个 API 设计好的地方:我们把长期记忆看作一个数据库,对长期记忆的处理相当于对数据库的访问,而复杂的细节隐藏在了简洁的接口之下。所以,从理解的角度看,它对我们几乎没有什么负担。
我们再来看配置。我们配置了大模型、Embedding 模型,还有向量数据库。对于长期记忆的搜索需要基于语义,所以,这里配置 Embedding 模型和向量数据库是很容易理解的。
但为什么还要配置大模型呢?因为 mem0 并不是把数据直接存到向量数据库里的。调用 add 时,mem0 会先把内容发送给大模型,让大模型从内容中提取出一些事实(fact),真正存放到向量数据库里的实际上是这些事实。
使用 mem0 实现长期记忆
到这里,你已经对 mem0 有了一个初步的印象,那怎样使用 mem0 实现长期记忆呢?接下来,我们就结合具体的代码,看看在一个大模型应用中可以怎样使用 mem0。有一点需要说明的是,目前 mem0 并没有提供一个专门的 LangChain 集成,下面的代码只能说是利用了 LangChain 的一些基础抽象完成:
# mem0 配置如上例所示
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplatemem0 = Memory.from_config(config)llm = ChatOpenAI(model="gpt-4o-mini")
prompt = ChatPromptTemplate.from_messages([("system", """"你现在是一名法律专家的角色,尽量按照律师的风格回复。利用提供的上下文进行个性化回复,并记住用户的偏好和以往的交互行为。上下文:{context}"""),("user", "{input}")
])
chain = prompt | llmdef retrieve_context(query: str, user_id: str) -> str:memories = mem0.search(query, user_id=user_id)return ' '.join([mem["memory"] for mem in memories['results']])def save_interaction(user_id: str, user_input: str, assistant_response: str):interaction = [{"role": "user","content": user_input},{"role": "assistant","content": assistant_response}]mem0.add(interaction, user_id=user_id)def invoke(user_input: str, user_id: str) -> str:context = retrieve_context(user_input, user_id)response = chain.invoke({"context": context,"input": user_input})content = response.contentsave_interaction(user_id, user_input, content)return contentuser_id = "dreamhead"while True:user_input = input("You:> ")if user_input.lower() == 'exit':breakresponse = invoke(user_input, user_id)print(response)
前面我们已经了解过 LangChain 和 mem0 的基本用法,所以,这段代码看起来就非常容易理解了。这段代码的关键就是在 invoke 里:调用大模型前先取得相关的上下文信息,调用大模型之后,再把聊天历史存到 mem0 里。
下面是我的一次调用结果,这里因为用了上个例子的配置,所以,它对我的喜好也有所了解:

结合这段代码,我们就能理解 mem0 是怎样做长期记忆的。在会话过程中,我们只要把会话历史交给 mem0,包括用户的提问和大模型的回答,mem0 可以从这些内容中提取出相关的事实,存放到向量数据库。
在下一次对话时,我们会先根据用户消息在向量数据库里搜索,找到所需的上下文,拼装成一个完整的消息发给大模型。因为这里采用了向量数据库,能够存放的信息趋近于无限,我们与大模型之间会话的核心内容就都得到了记录,这样就实现了长期记忆的效果。
理解了 mem0 是怎样工作的,你会发现,有了 mem0 实现的长期记忆,我们似乎就不再需要短期记忆了。因为我们会在拼装消息时,把相关上下文中从长期记忆中找出来。
再进一步,如果我们不只是把聊天历史放到 mem0 里,而是把我们的一些业务资料也放到 mem0,它就可以起到 RAG 的效果。所以,你现在应该明白了,mem0 要做的不只是一个长期记忆的组件,而是要做一个统一的记忆层解决方案,包括各种业务信息。虽然它的野心不小,但真的要用它替代 RAG,还需要大量工程方面的工作去完成,毕竟,现在已经有了不少更完整的 RAG 方案。
说了这么多 mem0 的优点,如果你真的选型时考虑它,也需要知道它的一些问题。作为一个起步时间不长的项目,它尚在剧烈的开发过程之中,变动会比较大,比如,在 1.1 版本中,mem0 引入了对图(Graph)的支持,发掘事物之间的关系。目前的 mem0 实现在每次添加信息时,都会调用大模型,这也就意味着成本的增加,这也是我们在选型时必须要考虑的。
另外,mem0 在细节上也有很多问题,比如,存放聊天历史时,除了向量数据库,mem0 还会把聊天历史存到关系数据库里,目前这个方案只支持了 SQLite;代码里还有一些监控的代码,会把一些操作的内容上报到一个云平台等等。当然,这些问题是在我写下课程的时候存在,如果你发现这些问题并不存在,那就说明 mem0 对此做了修改。
缓存
稍有经验的程序员对缓存都不陌生,在任何一个正式的工程项目上都少不了缓存的身影。硬件里面有缓存,软件里面也有缓存,缓存已经成了程序员的必修课。
我们为什么要使用缓存呢?主要就是为了减少访问低速服务的次数,提高访问速度。大模型显然就是一个低速服务,甚至比普通的服务还要慢。
为了改善大模型的使用体验,人们已经做出了一些努力,比如采用流式响应,提升第一个字出现在用户面前的速度。缓存,显然是另外一个可以解决大模型响应慢的办法。
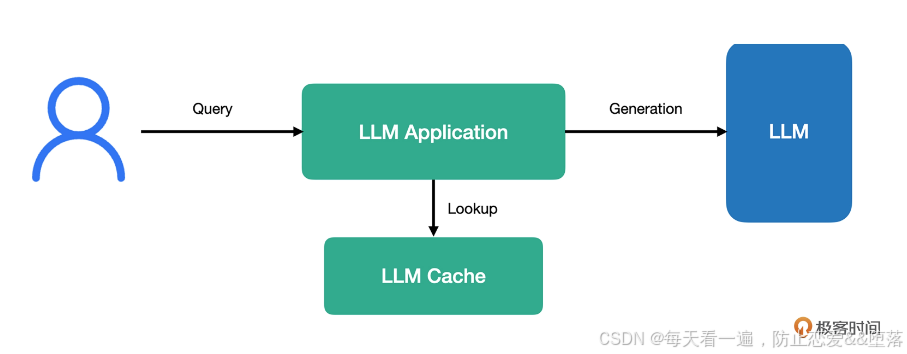
一个使用了缓存的大模型应用在接受到用户请求之后,会先到缓存中进行查询,如果命中缓存,则直接将内容返回给用户,如果没有命中,再去请求大模型生成相应的回答。
在这个架构中,关键点就是如果缓存命中,就直接将内容返回给用户,也就说明,在这种情况下无需访问大模型。无论我们使用在线请求还是本地部署的大模型,都能省出一定的成本。
。
LangChain 中的缓存
因为缓存在大模型应用开发中是一个普遍的需求,所以,LangChain 也为它提供了基础抽象。下面就是一段使用了缓存的代码:
from time import timefrom langchain.globals import set_llm_cache
from langchain_core.caches import InMemoryCache
from langchain_openai import ChatOpenAIset_llm_cache(InMemoryCache())model = ChatOpenAI(model="gpt-4o-mini")start_time = time()
response = model.invoke("给我讲个一句话笑话")
end_time = time()
print(response.content)
print(f"第一次调用耗时: {end_time - start_time}秒")start_time = time()
response = model.invoke("给我讲个一句话笑话")
end_time = time()
print(response.content)
print(f"第二次调用耗时: {end_time - start_time}秒")
这段代码里只有一句是重点,就是设置大模型的缓存:
set_llm_cache(InMemoryCache())
下面是一次执行的结果,从结果上看,因为有缓存,第二次明显比第一次快得多。
为什么数学书总是很忧伤?因为它有太多的问题!
第一次调用耗时: 2.353677272796631秒
为什么数学书总是很忧伤?因为它有太多的问题!
第二次调用耗时: 0.00018215179443359375秒
在 LangChain 里,缓存是一个全局选项,只要设置了缓存,所有的大模型都可以使用它。如果某个特定的大模型不需要缓存,可以在设置的时候关掉缓存:
model = ChatOpenAI(model="gpt-4o-mini", cache=False)
当然,如果你不想缓存成为一个全局选项,只想针对某个特定进行设置也是可以的:
model = ChatOpenAI(model="gpt-4o-mini", cache=InMemoryCache())
LangChain 里的缓存是一个统一的接口,其核心能力就是把生成的内容插入缓存以及根据提示词进行查找。LangChain 社区提供了很多缓存实现,像我们在前面例子里用到的内存缓存,还有基于数据库的缓存,当然,也有我们最熟悉的 Redis 缓存。
虽然 LangChain 提供了许多缓存实现,但本质上说,只有两类缓存——精确缓存和语义缓存。精确缓存,只是在提示词完全相同的情况下才能命中缓存,它和我们理解的传统缓存是一致的,我们前面用来演示的内存缓存就是精确缓存。
语义缓存
但大模型应用的特点就决定了精确缓存往往是失效的。因为大模型应用通常采用的是自然语言交互,以自然语言为提示词,就很难做到完全相同。像前面我展示的那个例子,实际上是我特意构建的,才能保证精确匹配。所以,语义匹配就成了更好的选择。
语义匹配我们并不陌生,LangChain 社区提供了许多语义缓存的实现,在各种语义缓存中,我们最熟悉的应该是 Redis。
在大部分人眼中,Redis 应该属于精确匹配的缓存。Redis 这么多年也在不断地发展,有很多新功能不断地拓展出来,最典型的就是 Redis Stack,它就是在原本开源 Redis 基础上扩展了其它的一些能力。
比如,对 JSON 支持(RedisJSON),对全文搜索的支持(RediSearch),对时序数据的支持(RedisTimeSeries),对概率结构的支持(RedisBloom)。其中,支持全文搜索的 RediSearch 就可以用来实现基于语义的搜索。全文搜索,本质上也是语义搜索,而这个能力刚好就是我们在语义缓存中需要的。
你现在知道了,Redis 对于语义缓存的支持是基于 RediSearch 的。所以,要想使用语义缓存,我们需要使用安装了 RediSearch 的 Redis,一种方式是使用 Redis Stack:
docker run -p 6379:6379 redis/redis-stack-server:latest
下面是一个使用 Redis 语义缓存的例子:
from langchain.globals import set_llm_cache
from langchain_community.cache import RedisSemanticCache
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from typing import Any, Sequence, Optional
from langchain_core.caches import BaseCache
from langchain.schema import Generation # 确保 Generation 类型正确
import json
from time import timeRETURN_VAL_TYPE = Sequence[Generation]def prompt_key(prompt: str) -> str:messages = json.loads(prompt)last_content = len(messages)print(messages[last_content - 1]['kwargs']['content'])return messages[last_content - 1]['kwargs']['content']class FixedSemanticCache(BaseCache):def __init__(self, cache: BaseCache):self.cache = cachedef lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:key = prompt_key(prompt)print(f"🔍 Cache Lookup: Key = {key}") # Debug: 打印 Keyprint(f"llm_string = {llm_string}")result = self.cache.lookup(key, llm_string)if result:print(f"✅ Cache Hit: {result}") # Debug: 如果命中缓存else:print("❌ Cache Miss") # Debug: 如果没有命中缓存return resultdef update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:key = prompt_key(prompt)return self.cache.update(key, llm_string, return_val)def clear(self, **kwargs: Any) -> None:return self.cache.clear(**kwargs)redis_url = "redis://localhost:6379"
set_llm_cache(FixedSemanticCache(RedisSemanticCache(redis_url=redis_url,embedding=OpenAIEmbeddings()))
)model = ChatOpenAI(model="gpt-4o-mini")start_time = time()
response = model.invoke("""请给我讲一个一句话笑话""")
end_time = time()
print(response.content)
print(f"第一次调用耗时: {end_time - start_time}秒")start_time = time()
response = model.invoke("""你能不能给我讲一个一句话笑话""")
end_time = time()
print(response.content)
print(f"第二次调用耗时: {end_time - start_time}秒")
我们先把注意力放在后面的核心代码上,在调用模型时,我们给出了两句并不完全相同的提示词。作为普通人,我们很容易看出,这两句话的意图是一样的。如果采用精确匹配,显然是无法命中的,但如果是语义匹配,则应该是可以命中的。
这里的语义缓存,我们采用了 RedisSemanticCache。在配置中,我们指定了 Redis 的地址和 Embedding 模型。LangChain 支持的 Redis 缓存有精确缓存和语义缓存两种,RedisCache 对应的是精确缓存,RedisSemanticCache 对应的是语义缓存。
最后说一下 FixedSemanticCache,其实,它是不应该存在的,它是为了解决 LangChain 实现中的一个问题而写的。LangChain 在实现缓存机制的时候,会先把消息做字符串化处理,然后,再交给缓存去查找。
在转化成字符串的过程中,LangChain 目前的实现是把它转换成一个 JSON 字符串,这个 JSON 字符串里除了提示词本身外,还会有很多额外信息,也就是消息对象本身的信息。当提示词本身很小的时候,这个生成的字符串信噪比就很低,正是因为噪声过大,结果就是不同的提示词都能匹配到相同的内容上,所以,总是能够命中缓存。
这段代码是写在框架内部的,不论采用什么样的缓存实现都有这个问题。只不过,因为精确缓存要完全匹配得上,这个实现的问题不会暴露出来,但对于语义缓存来说,就是一个非常严重的问题了。
在 LangChain 还没有修复这个问题之前,FixedSemanticCache 就是一个临时解决方案。思路也很简单,既然信噪比太低,就把信息提取出来,在这个实现里,把提示词和消息类型从字符串中提取出来,作为存储到 Redis 里的键值。如果后续 LangChain 解决了这个问题,FixedSemanticCache 就可以去掉了。
下面是一次执行的结果,从结果上看,第二次比第一次快了很多,这说明缓存起了作用:
请给我讲一个一句话笑话
🔍 Cache Lookup: Key = 请给我讲一个一句话笑话
llm_string = {"id": ["langchain", "chat_models", "openai", "ChatOpenAI"], "kwargs": {"model_name": "gpt-4o-mini", "openai_api_key": {"id": ["OPENAI_API_KEY"], "lc": 1, "type": "secret"}}, "lc": 1, "name": "ChatOpenAI", "type": "constructor"}---[('stop', None)]
❌ Cache Miss
请给我讲一个一句话笑话
为什么鸡要过马路?因为它想去对面找“咯咯”乐!
第一次调用耗时: 3.9416537284851074秒
你能不能给我讲一个一句话笑话
🔍 Cache Lookup: Key = 你能不能给我讲一个一句话笑话
llm_string = {"id": ["langchain", "chat_models", "openai", "ChatOpenAI"], "kwargs": {"model_name": "gpt-4o-mini", "openai_api_key": {"id": ["OPENAI_API_KEY"], "lc": 1, "type": "secret"}}, "lc": 1, "name": "ChatOpenAI", "type": "constructor"}---[('stop', None)]
✅ Cache Hit: [ChatGeneration(text='为什么鸡要过马路?因为它想去对面找“咯咯”乐!', generation_info={'finish_reason': 'stop', 'logprobs': None}, message=AIMessage(content='为什么鸡要过马路?因为它想去对面找“咯咯”乐!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 16, 'total_tokens': 39, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_72ed7ab54c', 'finish_reason': 'stop', 'logprobs': None}, id='run-4865bf61-9978-4670-b112-330762b1abfa-0', usage_metadata={'input_tokens': 16, 'output_tokens': 23, 'total_tokens': 39, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}))]
为什么鸡要过马路?因为它想去对面找“咯咯”乐!
第二次调用耗时: 1.609710454940796秒
正如你在这里看到的,我们把 Redis 当作语义缓存,它起到了和我们之前讲到的向量存储类似的作用。实际上,LangChain 社区确实已经有了实现 VectorStore 接口的 Redis,也就是说,我们完全可以用 Redis 替换之前讲过的向量存储。事实上,这里的语义缓存底层就是用了这个实现了 VectorStore 接口的 Redis。
顺便说一下,Redis 社区在向量的支持上也在继续努力,有一个项目 RedisVL(Redis Vector Library)就是把 Redis 当作向量数据库,有兴趣的话你可以了解一下。
实际上,LangChain 社区已经集成了大量的缓存实现,其中,有我们已经耳熟能详的,比如基于 SQL 和 NoSQL 的实现,也有基于 Elasticsearch 这样搜索项目的实现,这些都是基于传统项目实现的,还有一些项目就是针对大模型应用设计的缓存项目,这其中最典型的当属 GPTCache。总之,如果需要在项目上采用缓存,不妨先去了解一下不同的缓存项目。
langchain缓存的使用链接如下:https://python.langchain.com.cn/docs/ecosystem/integrations/redis
相关文章:
5、大模型的记忆与缓存
文章目录 本节内容介绍记忆Mem0使用 mem0 实现长期记忆 缓存LangChain 中的缓存语义缓存 本节内容介绍 本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义…...
Windows下AMD显卡在本地运行大语言模型(deepseek-r1)
Windows下AMD显卡在本地运行大语言模型 本人电脑配置第一步先在官网确认自己的 AMD 显卡是否支持 ROCm下载Ollama安装程序模型下载位置更改下载 ROCmLibs先确认自己显卡的gfx型号下载解压 替换替换rocblas.dll替换library文件夹下的所有 重启Ollama下载模型运行效果 本人电脑配…...

代码随想录day09
151.反转字符串中的单词,需二刷 //先去除多余空格,再反转所有字符,再反转单词,即可反转字符串中的单词 void removeWhiteSpace(string& s){int slowIndex 0;for(int fastIndex 0; fastIndex < s.size(); fastIndex){if(…...

Racecar Gym 总结
1.Racecar Gym 简介 Racecar Gym 是一个基于 PyBullet 物理引擎 的自动驾驶仿真平台,提供 Gymnasium(OpenAI Gym) 接口,主要用于强化学习(Reinforcement Learning, RL)、多智能体竞速(Multi-Ag…...

【C++高并发服务器WebServer】-15:poll、epoll详解及实现
本文目录 一、poll二、epoll2.1 相对poll和select的优点2.2 epoll的api2.3 epoll的demo实现2.5 epoll的工作模式 一、poll poll是对select的一个改进,我们先来看看select的缺点。 我们来看看poll的实现。 struct pollfd {int fd; /* 委托内核检测的文件描述符 */s…...

Visual Studio 2022 中使用 Google Test
要在 Visual Studio 2022 中使用 Google Test (gtest),可以按照以下步骤进行: 安装 Google Test:确保你已经安装了 Google Test。如果没有安装,可以通过 Visual Studio Installer 安装。在安装程序中,找到并选择 Googl…...

Office/WPS接入DeepSeek等多个AI工具,开启办公新模式!
在现代职场中,Office办公套件已成为工作和学习的必备工具,其功能强大但复杂,熟练掌握需要系统的学习。为了简化操作,使每个人都能轻松使用各种功能,市场上涌现出各类办公插件。这些插件不仅提升了用户体验,…...

Meta AI 最近推出了一款全新的机器学习框架ParetoQ,专门用于大型语言模型的4-bit 以下量化
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

操作系统—进程与线程
补充知识 PSW程序状态字寄存器PC程序计数器:存放下一条指令的地址IR指令寄存器:存放当前正在执行的指令通用寄存器:存放其他一些必要信息 进程 进程:进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单位…...

团队:前端开发工期参考 / 防止工期不足、过足、工期打架
一、前端开发工期参考 序号功能 / 模块 / 页面 / 描述pc端(数值为比例)小程序端(数值为比例)1简单页面 / 常规页面1:12复杂页面(功能复杂 / 逻辑复杂)1:1.5 / 1:2 / …...

APL语言的云计算
APL语言的云计算:一种灵活而高效的编程方式 引言 随着信息技术的迅猛发展,云计算已经成为现代计算的重要组成部分。云计算不仅带来了计算资源的高效利用,也引发了新一轮的技术革命。在这个背景下,APL(A Programming …...

idea启动报错# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00007ffccf76e433
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc0x00007ffccf76e433, pid17288, tid6696 # # JRE version: (11.0.248) (build ) # Java VM: OpenJDK 64-Bit Server VM (11.0.248-LTS, mixed mode, sharing, tiered, compressed oops, g1 gc, windows-amd64) 不知道为什么…...

C++拷贝构造函数与运算符重载应该注意的一个问题?
看下面的例子: class TestClass { public:char* _pdata;size_t _nLength;public:TestClass(const TestClass& other) {_nLength other._nLength;_pdata new char[_nLength];memcpy((void*)_pdata,other._pdata, _nLength 1);}TestClass(const char* pstr) {…...

[7] 游戏机项目说明
[7] 游戏机项目说明 在这节课中,我们将学习如何基于FreeRTOS开发一个简单的游戏项目。我们会使用一个开源项目nwatch,它是一个基于STM32的开源手表,包含了三个游戏。我们的目标是将这个游戏移植到我们的开发板上,并逐步使用FreeR…...
C++17)
“深入浅出”系列之C++:(20)C++17
C17的新拓展 并行算法: C17引入了并行STL算法,允许使用多个线程并行处理元素,提高了在多核系统上的性能。 示例代码:std::sort(std::execution::par, v.begin(), v.end()); 类模板参数推导(CTAD)&#…...

.net一些知识点5
1.dot Net带out的参数如何使用 string name;//假设这个参数带out TestMethod(1,out name);//一定要有out 方法体中,一定要有out参数的赋值,并且能输出 2.参数的传递方式有哪些 a.值传递 b.引用传递 ref c.输出传递 out 3.设计模式知道哪些 3.us…...

(七)QT——消息事件机制&绘图&文件
目录 前言 消息事件机制 (Event System) 绘图 (Graphics & Drawing) 绘图设备 Qt 提供的主要绘图设备 Qt 主要绘图设备的特点 各个绘图设备的详细介绍 文件处理 (File Handling) 总结 前言 QT 是一个非常强大的图形用户界面(GUI)开发框架&…...

【虚幻引擎UE】AOI算法介绍与实现案例
【虚幻引擎UE】AOI算法介绍与实现 一、AOI算法介绍AOI算法的典型应用场景二、AOI相关算法1. 边界框法(Bounding Box Method)2. 动态AOI算法3. 布尔运算(Boolean Operations)4. 四叉树(Quadtree)5. R树(R-Tree)6. 圆形AOI算法7. 网格分割(Grid Partitioning)8. 多边形…...

python学opencv|读取图像(六十)先后使用cv2.erode()函数和cv2.dilate()函数实现图像处理
【1】引言 前序学习进程中,先后了解了使用cv2.erode()函数和cv2.dilate()函数实现图像腐蚀和膨胀处理的效果,相关文章链接为: python学opencv|读取图像(五十八)使用cv2.erode()函数实现图像腐蚀处理-CSDN博客 pytho…...
AI能帮谷歌SEO做什么?
现在没用过AI写内容的人,应该不多了,用ChatGPT写文章,用MidJourney画图,用各种工具做调研,AI已经成为SEO玩家的“标配”。但AI到底能帮SEO做到什么?省钱?省时间?还是更重要的东西&am…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

终极AMD Ryzen调试指南:为什么你需要SMUDebugTool这个免费神器?
终极AMD Ryzen调试指南:为什么你需要SMUDebugTool这个免费神器? 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. …...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...