<论文>DeepSeek-R1:通过强化学习激励大语言模型的推理能力(深度思考)
一、摘要
本文跟大家来一起阅读DeepSeek团队发表于2025年1月的一篇论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning | Papers With Code》,新鲜的DeepSeek-R1推理模型,作者规模属实庞大。如果你正在使用DeepSeek,你会发现输入框下方有个“深度思考(R1)”的功能,实际上就是在使用这篇文章所提出来的DeepSeek-R1大模型。

译文:
我们推出了第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练而成的模型,在初步阶段没有进行有监督的微调(SFT),它展示出了卓越的推理能力。通过强化学习,DeepSeek-R1-Zero 自然地呈现出许多强大而有趣的推理行为。然而,它也面临着一些挑战,如可读性差和语言混合。为了解决这些问题并进一步提高推理性能,我们推出了 DeepSeek-R1,它在强化学习之前结合了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。为了支持研究社区,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及六个从 DeepSeek-R1 基于 Qwen 和 Llama 提炼出的密集模型(1.5B、7B、8B、14B、32B、70B)。
二、核心创新点
论文指出,以往的工作严重依赖大量的有监督数据来提升模型性能,而作者在这篇论文中证明了即使不使用有监督微调SFT作为冷启动,通过大规模的强化学习RL也能显著提升模型的推理能力。此外,加入少量冷启动数据可以进一步提升性能。论文介绍了两个推理模型,一个是DeepSeek-R1-Zero,这是直接将RL应用于基础模型,不使用任何SFT数据的模型;另一个是DeepSeek-R1,该模型从一个用数千个长思维链样例微调过的checkpoint开始应用RL。
1、DeepSeek-R1-Zero训练策略
1.1 强化学习策略Group Relative Policy Optimization(GRPO)
为了节省强化学习的成本,作者使用了GRPO技术。该技术舍弃了通常与策略模型大小相同的critic模型,取而代之的是从Group分数中来评估baseline。具体来说,对于每个问题q,GRPO从旧策略中采样一组输出
,接着通过最大化以下目标来优化策略模型
:

其中,和
是超参数,
是优势,使用与每个组内的输出相对应的一组奖励
来计算:
1.2 奖励模型
奖励是训练信号的来源,决定了强化学习的优化方向。为了训练DeepSeek-R1-Zero,作者采用了一个基于规则的奖励系统,由两种类型的奖励构成:
- 准确率奖励:准确率奖励模型评估响应是否正确。例如对于具有确定性结果的数学问题,模型需要以指定格式提供最终答案。
- 格式奖励:格式奖励模型强制受训练的模型将其思考过程放在“<think>”和“</think>”标签之间。
作者指出,在开发DeepSeek-R1-Zero时不应用结果或者过程神经奖励模型是因为神经奖励模型在大规模强化学习的过程中可能会受到奖励黑客攻击。
1.3 训练模板
作者设计了一个简单的模板来引导基础模型遵循指定的指令。这个模板要求模型先生成推理过程,然后给出最终答案。

2、DeepSeek-R1
在对DeepSeek-R1-Zero的训练过程中,出现了两个自然的问题:一个是通过加入少量高质量数据作为冷启动,推理性能能否进一步提高?另一个是如何训练一个用户友好的模型,该模型不仅能够产生清晰连贯的思维链,还能展示出强大的通用能力?由此,作者设计了一个用于训练DeepSeek-R1的pipeline。
2.1 冷启动
与DeepSeek-R1-Zero不同,为了防止基础模型中强化学习训练的早期不稳定冷启动阶段,对于DeepSeek-R1,作者构建并收集少量的长思维链数据,以微调模型作为初始的强化学习actor。这里,作者收集了数千个冷启动数据,以微调DeepSeek-V3-Base作为RL的起点。与DeepSeek-R1-Zero相比,冷启动数据的优势在于:
- 可读性:DeepSeek-R1-Zero的一个关键限制是其内容通常不适合阅读。回复可能会混合多种语言或缺乏Markdown格式来突出显示给用户的答案。相比之下,在为DeepSeek-R1创建冷启动数据时,作者设计了一种可读的模式,即在每个回复的末尾包含一个摘要,并过滤掉不便于读者阅读的回复。在这里,作者将输出格式定义为:|特殊标记|<推理过程>|特殊标记|<摘要>,其中推理过程是查询的思维链,而摘要用于总结推理结果。
- 潜力:通过使用人类先验仔细设计冷启动数据的模式,DeepSeek-R1-Zero的性能更好。
2.2 面向推理的强化学习
在对DeepSeek-V3-Base在冷启动数据上进行微调后,作者应用与DeepSeek-R1-Zero相同的大规模强化学习训练过程。这个阶段侧重于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中。
在训练过程中,思维链(CoT)经常出现语言混合,特别是当强化学习提示涉及多种语言时。为了缓解语言混合问题,作者在强化学习训练期间引入了语言一致性奖励,该奖励通过统计思维链中目标语言单词的比例来计算。尽管消融实验表明这种对齐会导致模型性能略有下降,但作者认为这种奖励符合人类偏好,使其更具可读性。最后,作者将推理任务的准确性和语言一致性奖励直接相加,形成最终奖励。然后,在微调后的模型上应用强化学习训练,直到模型在推理任务上达到收敛。
2.3 抑制采样和有监督微调
当以推理为导向的强化学习收敛时,作者利用得到的checkpoint为下一轮收集有监督微调数据。与最初主要侧重于推理的冷启动数据不同,这个阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。具体来说,按照以下方式生成数据并微调模型:
- 推理数据:作者整理了推理提示,并通过从上述强化学习训练的checkpoint进行抑制采样来生成推理轨迹。在这个阶段合并了额外的数据来扩展数据集,其中一些数据通过将真实结果和模型预测输入到DeepSeek-V3中进行判断来使用生成式奖励模型。最后,作者收集了大约 60 万个与推理相关的训练样本。
- 非推理数据:对于非推理数据,如写作、事实性问答、自我认知和翻译,作者采用DeepSeek-V3 的pipeline,并复用DeepSeek-V3的SFT数据集的部分内容。对于某些非推理任务,作者通过提示调用DeepSeek-V3在回答问题之前生成一个潜在的思维链。然而,对于更简单的查询,如“你好”,则在响应中不提供思维链。最后,收集了总共约 20 万个与推理无关的训练样本。
2.4 通用化
为了进一步使模型与人类偏好保持一致,作者还实施了一个二级强化学习阶段,旨在提高模型的有用性和无害性,同时改进其推理能力。具体来说,使用奖励信号和多样化提示分布的组合来训练模型。对于推理数据,遵循DeepSeek-R1-Zero中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,作者采用奖励模型来捕捉复杂和微妙场景中的人类偏好。以DeepSeek-V3 pipeline为基础,并采用类似的偏好对和训练提示分布。
对于有用性,作者仅关注最终总结,确保评估强调响应对用户的实用性和相关性,同时最大限度地减少对底层推理过程的干扰。对于无害性,作者评估模型的整个响应,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏差或有害内容。最终,奖励信号和多样化数据分布的整合使作者能够训练出在推理方面表现出色的模型,同时优先考虑有用性和无害性。
相关文章:
<论文>DeepSeek-R1:通过强化学习激励大语言模型的推理能力(深度思考)
一、摘要 本文跟大家来一起阅读DeepSeek团队发表于2025年1月的一篇论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning | Papers With Code》,新鲜的DeepSeek-R1推理模型,作者规模属实庞大。如果你正在使用Deep…...

公司配置内网穿透方法笔记
一、目的 公司内部有局域网,局域网上有ftp服务器,有windows桌面服务器; 在内网环境下,是可以访问ftp服务器以及用远程桌面登录windows桌面服务器的; 现在想居家办公时,也能访问到公司内网的ftp服务器和win…...
python爬虫--简单登录
1,使用flask框架搭建一个简易网站 后端代码app.py from flask import Flask, render_template, request, redirect, url_for, sessionapp Flask(__name__) app.secret_key 123456789 # 用于加密会话数据# 模拟用户数据库 users {user1: {password: password1}…...

人工智能浪潮下脑力劳动的变革与重塑:挑战、机遇与应对策略
一、引言 1.1 研究背景与意义 近年来,人工智能技术发展迅猛,已成为全球科技领域的焦点。从图像识别、语音识别到自然语言处理,从智能家居、智能交通到智能医疗,人工智能技术的应用几乎涵盖了我们生活的方方面面,给人…...

ESP32-S3驱动步进电机以及梯形加减速库调用
一、硬件连接说明 电机与驱动器连接: 42BYGH39-401A步进电机有4根引线,分别连接到驱动器(如TB6600)的电机接口上。 电机引脚A、A-、B、B-分别连接到驱动器对应的电机接口。 驱动器与ESP32-S3连接: ESP32-S3的GPIO引脚…...
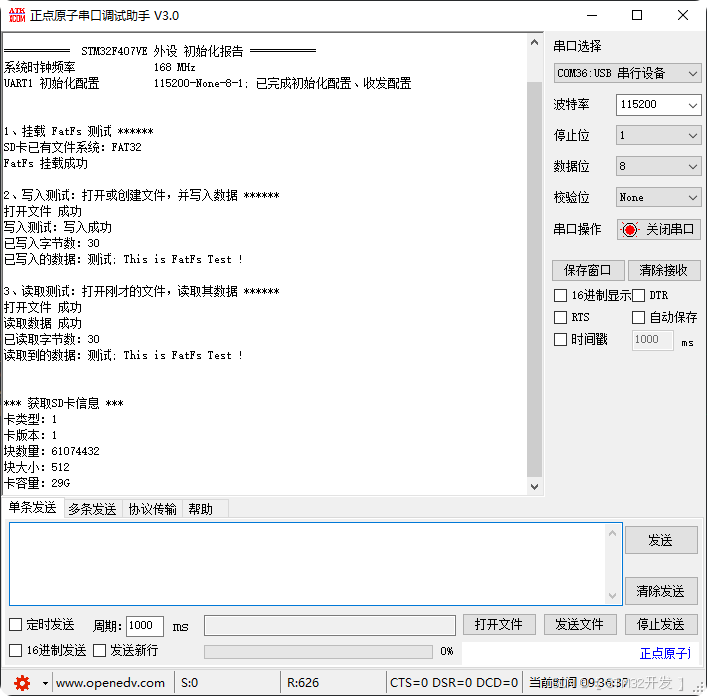
【CubeMX+STM32】SD卡 文件系统读写 FatFs+SDIO+DMA
本篇,将使用CubeMXKeil,创建一个SD卡的 FatFSSDIODMA 文件系统读写工程。 目录 一、简述 二、CubeMX 配置 FatFSSDIO DMA 三、Keil 编辑代码 四、实验效果 实现效果,如下图: 一、简述 上两篇,已循序渐进讲解了SD、…...
if、when)
Kotlin 2.1.0 入门教程(十)if、when
if 表达式 if 是一个表达式,它会返回一个值。 不存在三元运算符(condition ? then : else),因为 if 在这种场景下完全可以胜任。 var max aif (a < b) max bif (a > b) {max a } else {max b }max if (a > b) a…...
AJAX项目——数据管理平台
黑马程序员视频地址: 黑马程序员——数据管理平台 前言 功能: 1.登录和权限判断 2.查看文章内容列表(筛选,分页) 3.编辑文章(数据回显) 4.删除文章 5.发布文章(图片上传࿰…...
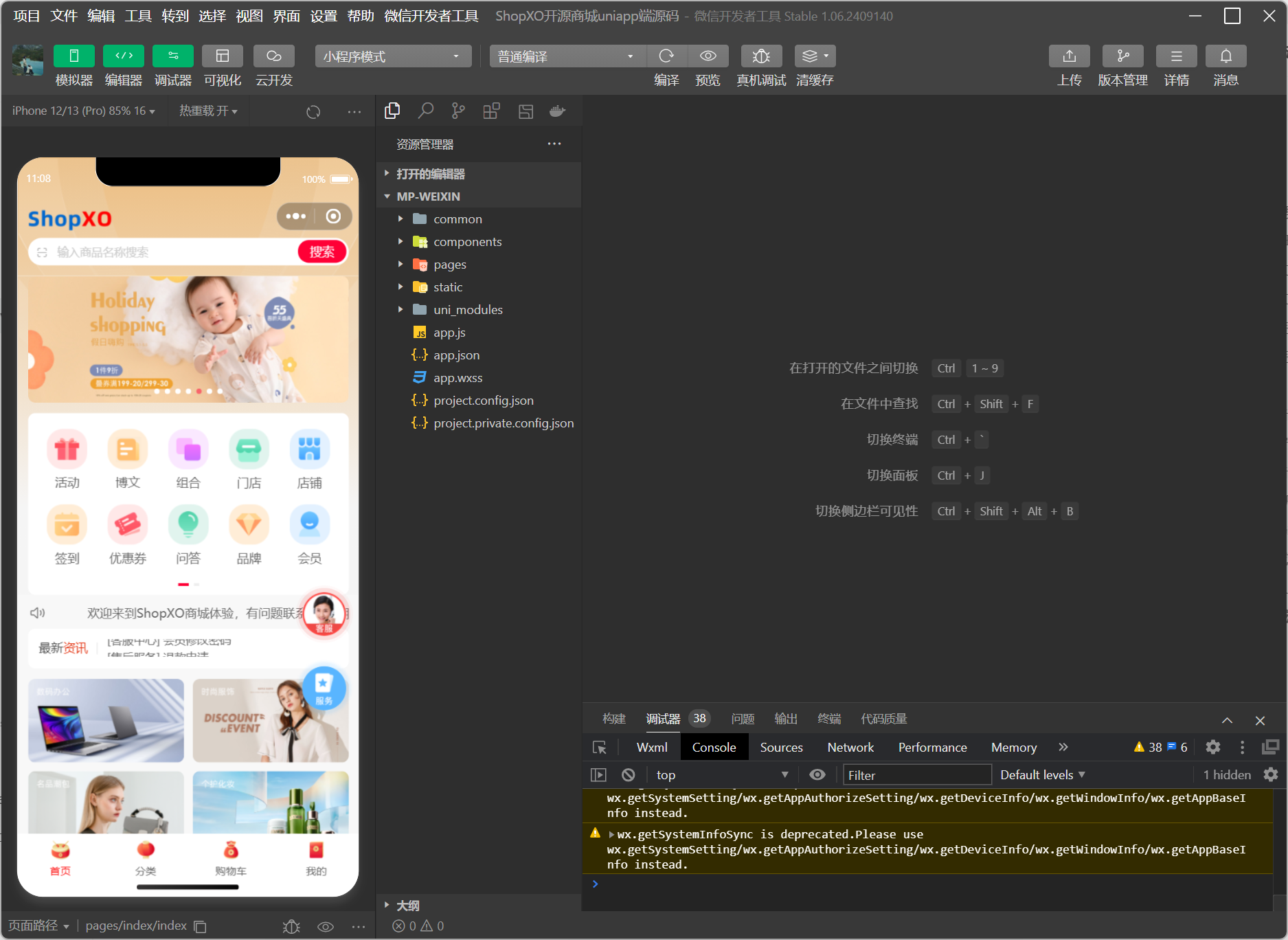
华为云搭建微信小程序商城后台
目录 安装宝塔界面 配置运行环境 1. 修改默认用户名密码 2. 修改默认端口号 3. 安装依赖软件 4. 安装商城 配置商城 1. 点击下一步进行商城环境检测 2. 将安装ShopXO成功后的弹窗信息填写到配置界面 3. 点击安装 发布小程序 源代码地址 1. 下载HBuilderX 2. 导入插…...
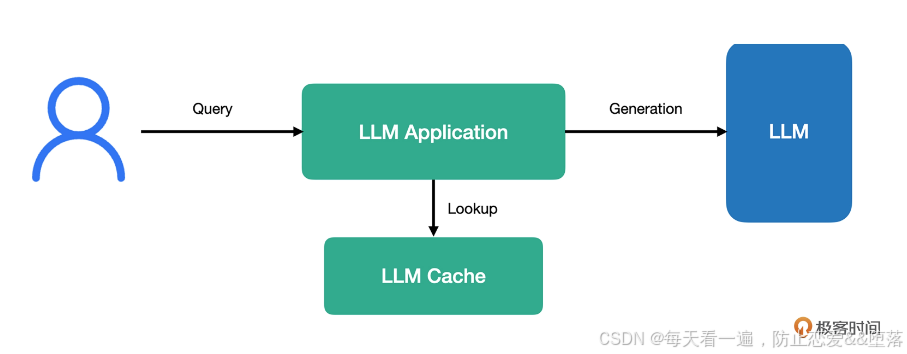
5、大模型的记忆与缓存
文章目录 本节内容介绍记忆Mem0使用 mem0 实现长期记忆 缓存LangChain 中的缓存语义缓存 本节内容介绍 本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义…...
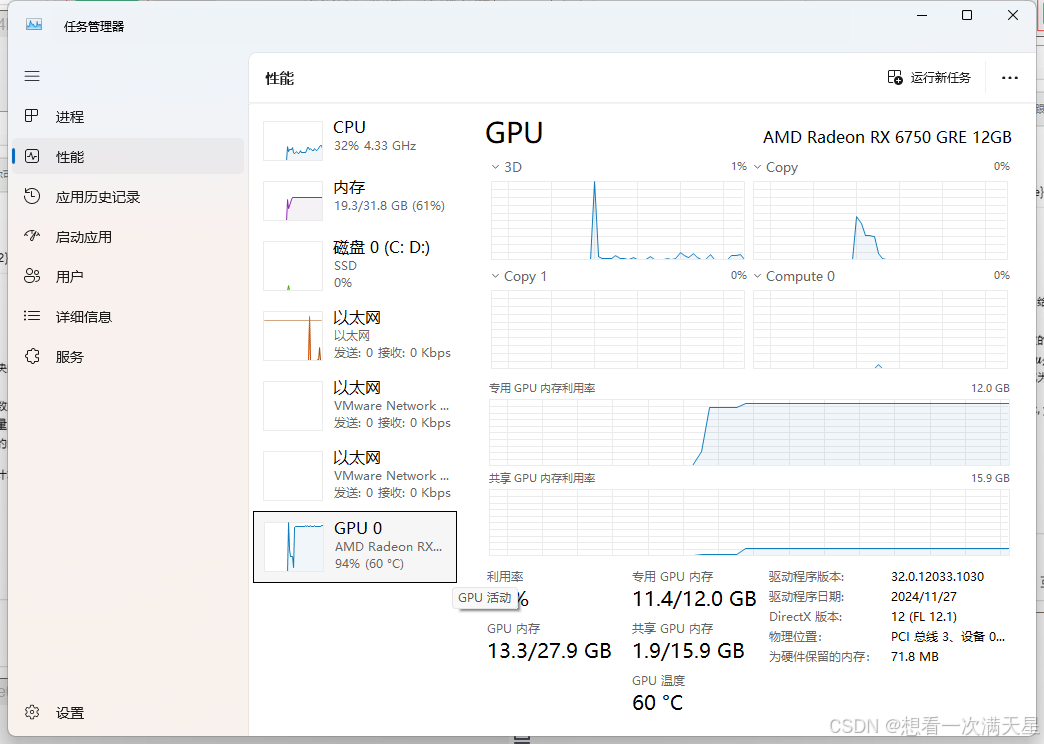
Windows下AMD显卡在本地运行大语言模型(deepseek-r1)
Windows下AMD显卡在本地运行大语言模型 本人电脑配置第一步先在官网确认自己的 AMD 显卡是否支持 ROCm下载Ollama安装程序模型下载位置更改下载 ROCmLibs先确认自己显卡的gfx型号下载解压 替换替换rocblas.dll替换library文件夹下的所有 重启Ollama下载模型运行效果 本人电脑配…...

代码随想录day09
151.反转字符串中的单词,需二刷 //先去除多余空格,再反转所有字符,再反转单词,即可反转字符串中的单词 void removeWhiteSpace(string& s){int slowIndex 0;for(int fastIndex 0; fastIndex < s.size(); fastIndex){if(…...

Racecar Gym 总结
1.Racecar Gym 简介 Racecar Gym 是一个基于 PyBullet 物理引擎 的自动驾驶仿真平台,提供 Gymnasium(OpenAI Gym) 接口,主要用于强化学习(Reinforcement Learning, RL)、多智能体竞速(Multi-Ag…...

【C++高并发服务器WebServer】-15:poll、epoll详解及实现
本文目录 一、poll二、epoll2.1 相对poll和select的优点2.2 epoll的api2.3 epoll的demo实现2.5 epoll的工作模式 一、poll poll是对select的一个改进,我们先来看看select的缺点。 我们来看看poll的实现。 struct pollfd {int fd; /* 委托内核检测的文件描述符 */s…...

Visual Studio 2022 中使用 Google Test
要在 Visual Studio 2022 中使用 Google Test (gtest),可以按照以下步骤进行: 安装 Google Test:确保你已经安装了 Google Test。如果没有安装,可以通过 Visual Studio Installer 安装。在安装程序中,找到并选择 Googl…...

Office/WPS接入DeepSeek等多个AI工具,开启办公新模式!
在现代职场中,Office办公套件已成为工作和学习的必备工具,其功能强大但复杂,熟练掌握需要系统的学习。为了简化操作,使每个人都能轻松使用各种功能,市场上涌现出各类办公插件。这些插件不仅提升了用户体验,…...

Meta AI 最近推出了一款全新的机器学习框架ParetoQ,专门用于大型语言模型的4-bit 以下量化
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

操作系统—进程与线程
补充知识 PSW程序状态字寄存器PC程序计数器:存放下一条指令的地址IR指令寄存器:存放当前正在执行的指令通用寄存器:存放其他一些必要信息 进程 进程:进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单位…...

团队:前端开发工期参考 / 防止工期不足、过足、工期打架
一、前端开发工期参考 序号功能 / 模块 / 页面 / 描述pc端(数值为比例)小程序端(数值为比例)1简单页面 / 常规页面1:12复杂页面(功能复杂 / 逻辑复杂)1:1.5 / 1:2 / …...

APL语言的云计算
APL语言的云计算:一种灵活而高效的编程方式 引言 随着信息技术的迅猛发展,云计算已经成为现代计算的重要组成部分。云计算不仅带来了计算资源的高效利用,也引发了新一轮的技术革命。在这个背景下,APL(A Programming …...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...