内存中的缓存区
在 Java 的 I/O 流设计中,BufferedInputStream 和 BufferedOutputStream 的“缓冲区”是 内存中的缓存区(具体是 JVM 堆内存的一部分),但它们的作用是优化数据的传输效率,并不是直接操作硬盘和内存之间的缓存。以下是详细解释:
1. 缓冲流的工作原理
(1) BufferedInputStream
-
作用:从底层输入流(如
FileInputStream)读取数据时,批量读取数据到内存缓冲区,减少直接访问硬盘的次数。 -
数据流向:
硬盘 → 操作系统内核缓冲区 → JVM 堆内存缓冲区 → 应用程序内存(变量、对象)-
缓冲区的数据由 JVM 管理,应用程序通过
read()方法从缓冲区读取。
-
(2) BufferedOutputStream
-
作用:将数据先写入内存缓冲区,缓冲区满后批量写入底层输出流(如
FileOutputStream),减少直接写硬盘的次数。 -
数据流向:
应用程序内存(变量、对象) → JVM 堆内存缓冲区 → 操作系统内核缓冲区 → 硬盘-
调用
flush()或关闭流时,强制将缓冲区数据写入底层流。
-
2. 内存缓存区与内存之间的关系
(1) 内存缓存区的位置
-
缓冲区本身就在内存中:无论是
BufferedInputStream还是BufferedOutputStream,它们的缓冲区都是 JVM 堆内存的一部分。 -
应用程序内存:开发者通过代码操作的变量、对象,也位于 JVM 堆内存中。
(2) 数据在内存中的流动
-
BufferedInputStream的流程:
硬盘数据 → 操作系统内核缓冲区 → JVM 堆内存缓冲区 → 应用程序变量(如byte[]或String)。-
例如:
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("data.txt")); byte[] buffer = new byte[1024]; bis.read(buffer); // 从 JVM 缓冲区读取到应用程序的 buffer 数组
-
-
BufferedOutputStream的流程:
应用程序变量 → JVM 堆内存缓冲区 → 操作系统内核缓冲区 → 硬盘。-
例如:
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("data.txt")); bos.write("Hello".getBytes()); // 数据先写入 JVM 缓冲区 bos.flush(); // 强制将缓冲区数据写入底层流
-
(3) 内存之间的数据传输
-
JVM 堆内存缓冲区 ↔ 应用程序内存:通过 Java 代码直接操作(如
read()或write()方法)。 -
操作系统内核缓冲区 ↔ JVM 堆内存:由底层系统调用(如
read()、write())自动完成,开发者无需干预。
3. 为什么需要缓冲区?
减少磁盘 I/O 次数:
直接读写硬盘速度慢,缓冲区通过批量操作减少对底层资源的访问次数。
例如:
BufferedInputStream一次性读取 8KB 数据到内存,后续read()直接从内存取数据。降低系统调用开销:
每次读写硬盘都需要系统调用(内核态切换),缓冲区减少系统调用次数。
提升程序性能:
内存操作速度远高于磁盘操作,缓冲区充当数据的“中转站”。
4. 缓冲区的默认大小
-
BufferedInputStream/BufferedOutputStream:默认缓冲区大小为 8KB(8192 字节)。 -
自定义缓冲区大小:
// 设置缓冲区大小为 16KB BufferedInputStream bis = new BufferedInputStream(new FileInputStream("data.txt"), 16384);
5. 缓冲流与其他缓存的关系
(1) 操作系统内核缓冲区
-
位置:由操作系统管理的内存区域,不属于 JVM 堆内存。
-
作用:缓存磁盘数据,加速对硬盘的读写操作。
-
对开发者透明:无法通过 Java 代码直接操作。
(2) JVM 堆内存缓冲区
-
位置:JVM 堆内存的一部分,由 Java 程序管理。
-
作用:
BufferedInputStream/BufferedOutputStream使用的缓冲区。
(3) 磁盘缓存(硬件级缓存)
-
位置:硬盘控制器或磁盘驱动器的硬件缓存。
-
作用:临时存储读写数据,减少磁头移动次数。
6. 总结
| 组件 | 作用 |
|---|---|
BufferedInputStream | 通过内存缓冲区减少硬盘读取次数,提升读取效率。 |
BufferedOutputStream | 通过内存缓冲区减少硬盘写入次数,提升写入效率。 |
| JVM 堆内存缓冲区 | 缓冲流的实际存储位置,数据在内存中批量处理。 |
| 操作系统内核缓冲区 | 由操作系统管理的磁盘缓存,对开发者透明。 |
关键结论:
-
缓冲流的“缓冲区”是 JVM 堆内存的一部分,数据在 硬盘 ↔ 内核缓冲区 ↔ JVM 缓冲区 ↔ 应用程序内存 之间流动。
-
开发者只需通过
read()/write()操作数据,底层细节由 JVM 和操作系统处理。
相关文章:

内存中的缓存区
在 Java 的 I/O 流设计中,BufferedInputStream 和 BufferedOutputStream 的“缓冲区”是 内存中的缓存区(具体是 JVM 堆内存的一部分),但它们的作用是优化数据的传输效率,并不是直接操作硬盘和内存之间的缓存。以下是详…...

基于 Spring Boot 的 +Vue“宠物咖啡馆平台” 系统的设计与实现
大家好,今天要和大家聊的是一款基于 Spring Boot 的 “宠物咖啡馆平台” 系统的设计与实现。项目源码以及部署相关事宜请联系我,文末附上联系方式。 项目简介 基于 Spring Boot 的 “宠物咖啡馆平台” 系统设计与实现的主要使用者分为 管理员、用户 和…...

LeetCode 解题思路 7(Hot 100)
解题思路: 初始化窗口元素: 遍历前 k 个元素,构建初始单调队列。若当前索引对应值大于等于队尾索引对应值,移除队尾索引,将当前索引加入队尾。遍历结束时当前队头索引即为当前窗口最大值,将其存入结果数组…...

linux-Dockerfile及docker-compose.yml相关字段用途
文章目录 计算机系统5G云计算LINUX Dockerfile及docker-conpose.yml相关字段用途一、Dockerfile1、基础指令2、.高级指令3、多阶段构建指令 二、Docker-Compose.yml1、服务定义(services)2、高级服务配置3、网络配置 (networks)4、卷配置 (volumes)5、扩…...

deepseek部署:ELK + Filebeat + Zookeeper + Kafka
## 1. 概述 本文档旨在指导如何在7台机器上部署ELK(Elasticsearch, Logstash, Kibana)堆栈、Filebeat、Zookeeper和Kafka。该部署方案适用于日志收集、处理和可视化场景。 ## 2. 环境准备 ### 2.1 机器分配 | 机器编号 | 主机名 | IP地址 | 部署组件 |-…...
微软Office 2016-2024 x86直装版 v16.0.18324 32位
微软 Office 是一款由微软公司开发的办公软件套装,能满足各种办公需求。包含 Word、Excel、PowerPoint、Outlook 和 OneNote 等软件。Word 有强大文档编辑功能和多人协作;Excel 可处理分析大量数据及支持宏编程;PowerPoint 用于制作演示文稿且…...

CMake宏定义管理:如何优雅处理第三方库的宏冲突
在C/C项目开发中,我们常常会遇到这样的困境: 当引入一个功能强大的第三方库时,却发现它定义的某个宏与我们的项目产生冲突。比如: 库定义了 BUFFER_SIZE 1024,而我们需要 BUFFER_SIZE 2048库内部使用 DEBUG 宏控制日志…...

【SpringCloud】Gateway
目录 一、网关路由 1.1.认识网关 1.2.快速入门? 1.2.1.引入依赖 1.2.2.配置路由 二、网关登录校验 2.1.Gateway工作原理 ?2.2.自定义过滤器 2.3.登录校验 2.4.微服务获取用户 2.4.1.保存用户信息到请求头 2.4.2.拦截器获取用户? ?2.5.OpenFeign传递用户 三、…...

Maven入门教程
一、Maven简介 Maven 是一个基于项目对象模型(Project Object Model)的构建工具,用于管理 Java 项目的依赖、构建流程和文档生成。它的核心功能包括: 依赖管理(Dependency Management):自动下载和管理第三方库&#x…...

大数据与金融科技:革新金融行业的动力引擎
大数据与金融科技:革新金融行业的动力引擎 在今天的金融行业,大数据与金融科技的结合正在以惊人的速度推动着金融服务的创新与变革。通过精准的数据分析与智能化决策,金融机构能够更高效地进行风险管理、客户服务、资产管理等一系列关键操作…...

Autosar RTE配置-Port Update配置及使用-基于ETAS工具
文章目录 前言Autosar Rte中enableUpdate参数定义ETAS工具中的配置生成代码分析总结前言 在E2E校验中,需要对Counter进行自增,但每个报文周期不一样,导致自增的周期不一样。且Counter应该在收到报文之后才进行自增。基于这些需求,本文介绍使用RTE Port中的参数enableUpdat…...

【AVRCP】深入理解蓝牙音频 / 视频远程控制规范:从基础到应用
AVRCP(Audio/Video Remote Control Profile)作为蓝牙音频 / 视频控制领域的重要规范,通过其完善的协议架构、丰富的功能分类以及对用户需求的深入考量,为我们带来了便捷、高效的音频 / 视频设备控制体验。无论是在日常生活中的音乐…...

AWS SQS跨账户访问失败排查指南
引言 在使用AWS SQS(Simple Queue Service)时,跨账户访问是常见的业务场景。例如,账户A的应用程序向队列发送消息,账户B的消费者从队列拉取消息。尽管AWS官方文档明确支持此类配置,但在实际应用中,由于权限模型的复杂性,开发者和运维人员常会遇到“策略已配置但无法接…...
二刷第三十八天 | 1143. 最长公共子序列、1035. 不相交的线、53. 最大子数组和、392. 判断子序列)
算法训练(leetcode)二刷第三十八天 | 1143. 最长公共子序列、1035. 不相交的线、53. 最大子数组和、392. 判断子序列
刷题记录 1143. 最长公共子序列1035. 不相交的线53. 最大子数组和动态规划优化版 392. 判断子序列 1143. 最长公共子序列 leetcode题目地址 本题和300. 最长递增子序列相似(题解)。 使用动态规划: dp数组含义:dp[i][j]表示 以…...

【JavaWeb学习Day20】
Tlias智能学习系统 员工登录 三层架构: Controller:1.接收请求参数(用户名,密码)2.调用Service方法3.响应结果 具体实现: /*** 登录*/ PostMapping("/login") public Result login(Reque…...
等级考试试卷(二级)真题 + 答案)
2024年12月中国电子学会青少年软件编程(Python)等级考试试卷(二级)真题 + 答案
青少年软件编程(Python)等级考试试卷(二级) ↓↓↓↓↓↓ 模拟 分数:100 题数:37 一、单选题(共25题,共50分) 1. 已知字典如下 dic1 = { name: Ming, age:20, grade: A, Tel:6666666 } 以下哪个代码运行结果为20?( ) A. dic1(age) B. dic1[1] C. dic1(20) D. dic1[ag…...

一、对iic类模块分析与使用
bmp280驱动代码 说明: 1、该模块用于获取气压,温度,海拔等数据。 vcc,gnd接电源 sda ,scl 接iic通信引脚 2、该模块使用iic通信,通过iic发送请求相关类的寄存器值,芯片获取对应寄存器返回的数据…...
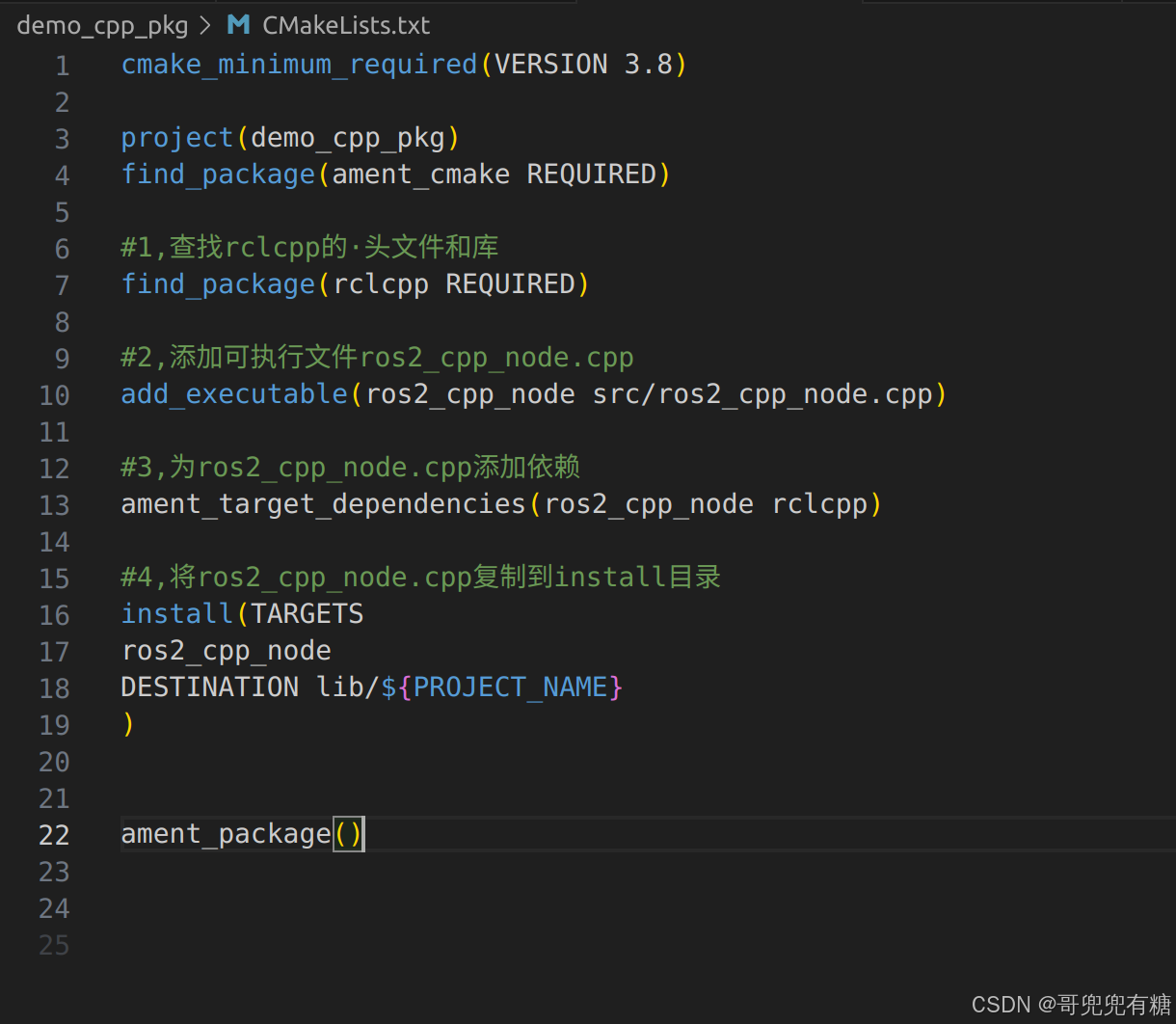
ROS 2机器人开发--CMakeLists.txt 文件详解
很多小白宝宝不懂CMakeLists.txt 究竟是干什么的,本文对CMakeLists.txt 文件进行详解 CMakeLists.txt 是 CMake 的核心文件,用户通过这个文件告诉 CMake 如何构建项目。这个文件通常包括设置项目名称、版本号、语言标准、编译器选项、查找依赖包、添加可…...

kan与小波,和不知所云的画图
文章目录 小波应用范围与pde小波的名字 画图图(a):数值解向量 \( u \)图(b):数值解向量 \( v \)结论图4 小波 在你提供的代码中,小波变换(Wavelet Transform)被用于 KANLinear 类中。具体来说,小波变换在 …...

使用DeepSeek实现自动化编程:类的自动生成
目录 简述 1. 通过注释生成C类 1.1 模糊生成 1.2 把控细节,让结果更精准 1.3 让DeepSeek自动生成代码 2. 验证DeepSeek自动生成的代码 2.1 安装SQLite命令行工具 2.2 验证DeepSeek代码 3. 测试代码下载 简述 在现代软件开发中,自动化编程工具如…...

如何用roop-unleashed实现零门槛AI换脸:三分钟制作专业级视频的完整指南
如何用roop-unleashed实现零门槛AI换脸:三分钟制作专业级视频的完整指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要制作令人惊艳的AI换…...

ONNX模型‘解剖’指南:用Netron和Python代码查看、编辑与调试模型结构
ONNX模型‘解剖’指南:用Netron和Python代码查看、编辑与调试模型结构当你面对一个推理结果异常的ONNX模型,或是需要对其进行定制化修改时,仅仅使用Netron进行可视化查看是远远不够的。本文将带你深入ONNX模型的内部结构,通过编程…...

不确定性量化神经网络:从海平面预测到状态依赖可预测性物理机制挖掘
1. 项目概述:用不确定性量化神经网络“透视”海平面预测的奥秘在气候与海洋研究的前沿,预测未来几天到几个月内的海平面变化,一直是个让人又爱又恨的难题。爱的是,准确的预测能直接服务于沿海城市的防洪预警、港口运营和生态保护&…...

量子机器学习分类器性能杀手:数据诱导随机性与类间隔理论解析
1. 项目概述 量子机器学习(QML)这几年挺火的,大家都想看看量子计算能不能在机器学习任务上带来点新东西。但说实话,很多早期的实验和理论分析都指向一个挺让人头疼的问题:模型动不动就“学废了”。表现就是,…...

Agent 状态持久化:基于 Redis 的多轮交互上下文存储方案
一、 引言 (Introduction) 1.1 钩子:从 Siri 答非所问到 AI Agent 的「失忆症噩梦」 你有没有遇到过这种令人血压升高的场景: 早上起床,对着家里的智能音箱(假设它搭载了最新的「多轮对话」AI Agent)说:“嘿…...

从准确率到社会福利:机器学习在社会资源分配中的范式演进
1. 从预测到分配:为什么准确率不再是社会场景下机器学习的唯一目标 在过去的十几年里,我亲眼见证了机器学习从一个学术概念,成长为驱动我们数字生活乃至部分现实决策的核心引擎。从最初在实验室里调参,看着模型在MNIST数据集上的准…...
性能实测:可解释机器学习如何兼顾精度与透明度)
广义可加模型(GAMs)性能实测:可解释机器学习如何兼顾精度与透明度
1. 项目概述:当可解释性成为硬通货,GAMs如何破局? 在医疗诊断、信贷审批、司法风险评估这些“高风险”领域,一个预测模型如果只告诉你“结果是A”,却无法解释“为什么是A”,那它几乎毫无价值。决策者需要的…...

智慧医院边缘计算架构:QoS驱动的低延迟医疗物联网实践
1. 项目概述:当智慧医院遇上边缘计算在智慧医院的日常运营中,我们正面临一个日益尖锐的矛盾:一边是海量医疗物联网设备产生的实时数据洪流,另一边是云端数据中心在处理这些数据时难以逾越的延迟与带宽瓶颈。想象一下,一…...

Edge Impulse:一站式TinyML MLOps平台,破解嵌入式AI开发难题
1. 项目概述:为什么我们需要一个面向TinyML的MLOps平台?如果你尝试过在Arduino、树莓派Pico或者ESP32这类微控制器上跑一个简单的图像分类模型,你大概会立刻理解那种“寸土寸金”的感觉。内存以KB计,算力以MHz计,存储空…...

心脏数字孪生:计算建模与机器学习融合重塑精准医疗
1. 项目概述:当计算心脏遇见数据智能在心血管医学的前沿,一场静默的革命正在进行。我们不再仅仅依赖传统的临床试验和群体统计数据来理解疾病、测试药物或规划手术。取而代之的,是一个融合了计算物理学、生物学和人工智能的崭新范式ÿ…...