10-Agent循环分析新闻并输出总结报告
目录
关键词
摘要
速览
自动新闻总结与行业分析报告生成流程
创建深度行业分析报告的工作流
测试用例执行与调试
业务逻辑与循环处理任务
演示如何在循环体中添加链接读取工具
使用大模型处理和分析新闻信息
构建循环分析新闻并生成综合报告的流程
分析和优化慢速循环的执行效率
演示如何使用循环生成新闻总结
测试和发布工作流及修改循环输出
思维导图
总结
要点回顾
我们接下来要做什么?
这个过程中,机器会如何自主完成任务呢?
在搜索和分析过程中,是否需要人工参与?
如何配置机器进行详细的新闻内容获取和分析?如何设置工作流来实现这些功能?
在测试过程中,如何验证机器执行正确性?
在执行某个节点时,如何设计输出以获取信息?
如何处理搜索结果不完整的情况以及如何获取多个新闻数据?如何配置循环逻辑并应用到多个新闻数据处理中?
如何遍历数组并处理每个元素?
在处理每一篇新闻时,如何通过中间变量来汇总信息?
如何在循环体内添加节点以实现对新闻内容的处理?
在使用大模型时,如何设置其输入和输出?
在大模型中,如何处理循环中的中间变量,例如在分析新闻时的累计结果?大模型在分析过程中是如何根据输入变量进行工作的?
如何在循环中记录并利用大模型的分析结果?
如何利用大模型进行多轮新闻分析,并将结果串联起来?
在演示中,您首先展示了什么内容?您在处理第二篇新闻时,如何利用之前的结果?
在最终输出的内容中,有哪些关键信息被提取出来?
关键词
总结 行业分析报告 深度分析报告 插件 API接口
摘要
用户计划构建一个自动化系统,旨在自动检索新闻并生成行业分析报告。最初目标为简化为自动搜集新闻并提炼摘要,随后要求提升至能独立搜寻新闻、获取全文并基于内容进行行业分析,追求全流程自动化,减少人为介入,且能整合多来源新闻逐条分析,最后产出综合深度分析报告。用户详细阐述了配置工作流的方法,涉及添加任务节点、实现循环处理、利用插件抓取文章内容及运用大型语言模型进行分析等步骤。同时,强调通过设定变量和消息输出确保系统按照预定流程运行,最终实现所需分析报告的自动生成。
速览
自动新闻总结与行业分析报告生成流程
如何通过自动化流程获取和总结网络新闻,并进一步进行行业分析报告的自动生成。该流程包括自动上网搜索新闻、访问新闻链接获取详细内容、对每条新闻进行分析以及最终生成全面的行业分析报告。整个过程尽量减少了人工参与,通过预设的模板和插件实现自动化处理。
创建深度行业分析报告的工作流
对话围绕创建一个用于深度行业分析的自动化工作流展开,包括命名工作流、设定抓取热门新闻事件内容和URL的步骤,以及如何分析和总结抓取的信息。

打开工作流程-在开始插件新增title字段

在添加节点-添加插件-添加新闻搜索插件
测试用例执行与调试
测试用例的执行与调试过程,包括响应结果的检查、字段的引用与调整、查询输出的优化,以及如何通过循环处理多个新闻数据来完善信息获取流程。
业务逻辑与循环处理任务
在业务逻辑中处理第二轮投资情况和重复任务的方法,特别是通过循环和中间变量来高效处理多篇新闻和邮件。解释了循环数组的概念,以及如何在循环中处理不同数量的对象,如新闻或邮件。此外,通过实例说明了中间变量的作用,即在处理多个任务时不断填充和更新最终报告或总结,以实现数据的汇总和整合。
演示如何在循环体中添加链接读取工具
在操作演示中,强调了在循环体中添加节点的关键步骤,特别是添加链接读取工具以从新闻链接中提取主要内容的过程。

添加节点-添加循环-画布中自动添加循环和循环体
使用大模型处理和分析新闻信息
对话围绕如何利用循环和大模型处理及分析新闻信息展开。首先,通过循环遍历每个新闻item,读取其中的特定字段(如URL)以获取所需信息。接着,将读取到的信息作为输入传递给大模型,通过定制的系统提示词,让大模型对新闻内容进行总结和分析。分析框架根据不同类型的新闻事件(如突发事件、政策解读等)进行调整,以确保分析的专业性和可读性。最终,大模型将生成符合要求的分析报告。

首先在选中循环体-点击添加节点-加入“LinkReaderPlugin”插件

设置查找url插件参数

构建循环分析新闻并生成综合报告的流程
如何通过循环读取多篇新闻链接,分析内容并逐步构建一个综合的行业分析报告。流程中,每次循环分析一篇新闻并将结果存储在中间变量中,以便后续循环时能够累积先前的分析结果,最终生成一个完整的报告。
分析和优化慢速循环的执行效率
对话围绕一个运行缓慢的循环展开,其执行效率低下的原因,即循环包含大量操作导致执行时间较长。参与者通过观察水晶球节点的运行过程,分析了循环的具体执行情况,并展示了通过插件读取链接内容以寻找特定结果的过程。最后,提到了进一步分析和展示大模型结构图的计划。
演示如何使用循环生成新闻总结
通过一个插件读取新闻内容,并利用大模型的提示词,根据当前新闻内容总结。在处理第二篇新闻时,将第一篇新闻的总结结果作为输入,以实现对两篇新闻内容的连续总结和补全,最终生成一个完整的报告。
测试和发布工作流及修改循环输出
关于发布和测试一个工作流的过程,包括添加新的技能、修改调用名称以及在循环中添加输出消息以监控执行状态。讨论者在测试过程中不断调整和优化,以确保工作流能够正确处理和反馈信息。
思维导图

总结
建立一个简易系统以实现新闻获取、总结和行业分析报告自动化的全过程。介绍了如何通过自动化手段增强系统功能,包括自动抓取新闻、分析新闻内容,以及生成深度的行业分析报告。在自动化处理方面,他强调了利用插件处理链接信息、应用大型语言模型进行内容分析,以及通过循环结构整合多篇新闻分析结果至最终报告的重要性。他还提及了系统的灵活性,允许用户根据需求定制分析框架和报告内容。整体而言,他的讨论重点在于如何有效利用现有技术和工具,以实现对新闻内容的自动化处理和深度分析。
要点回顾
我们接下来要做什么?
我们将演示如何让机器自己去上网搜索新闻、分析事件的前因后果,并根据分析结果生成一个深度分析报告。
这个过程中,机器会如何自主完成任务呢?
机器首先会自行上网搜索相关事件信息,不仅获取概要内容,还会访问链接以获取详细信息。之后,它会逐条分析这些信息,并在完成一定数量的记录分析后,生成一份行业分析报告。
在搜索和分析过程中,是否需要人工参与?
我们设计的目标是尽可能让机器全流程自主完成,用户无需过多参与。
如何配置机器进行详细的新闻内容获取和分析?如何设置工作流来实现这些功能?
我们将在工作中添加一个名为“查内容,抓URL”的工作流,它会根据阅读信息抓取内容、查询链接,并进行进一步的分析和总结。我们会在开始部分设置工作流,让机器查找热门新闻内容,并连接相应的插件来完成对新闻链接中详细内容的抓取和分析。后续会根据测试结果调整参数,确保机器能够准确高效地完成任务。
在测试过程中,如何验证机器执行正确性?
在配置好工作流后,我们会进行测试运行,查看机器输出的结果是否符合预期,例如新闻标题、链接等信息是否准确无误,并根据测试反馈进一步优化机器的搜索和分析策略。
在执行某个节点时,如何设计输出以获取信息?
在节点执行过程中,可以在技术环节设计输出,通过设置变量引用并打印出来,这样在执行过程中就能打印出相关的信息,便于观察和调试。
如何处理搜索结果不完整的情况以及如何获取多个新闻数据?如何配置循环逻辑并应用到多个新闻数据处理中?
当搜索结果不全时,可以通过配插件根据链接获取完整信息;若需处理多个新闻数据,应设计循环结构,一次性抓取所有新闻,并对每一篇新闻进行单独处理。配置循环逻辑时,首先要确定循环数组(可编辑区域),然后在循环体内选择适合的遍历方式,将循环变量传入相应对象,重复处理每个元素直至所有元素遍历完毕。
如何遍历数组并处理每个元素?
在流程设计中,可以设置循环数组,选择循环遍历每个元素。例如,如果有三篇新闻,就遍历三次,每处理一篇新闻就完成一个邮件回复,形成循环体内的具体处理逻辑。
在处理每一篇新闻时,如何通过中间变量来汇总信息?
在处理每一篇新闻时,我要求他在做一件事时不断往中间变量填充内容。例如,在制作生产总结表时,一开始表格是空的,随着操作的进行,每次都会在中间变量里写入新的信息,最终汇总成一个完整的报告表。
如何在循环体内添加节点以实现对新闻内容的处理?
在循环体内,首先需要打开循环体并点击“添加节点”,然后选择相应的工具,如“链接读取工具”,用来获取网页链接中的标题和内容。接着,在循环中遍历每个新闻项(item),使用其中的链接字段作为输入,通过链接读取工具提取文字信息,并将这些信息传递给后续的大模型进行处理。
在使用大模型时,如何设置其输入和输出?
在读取到新闻页面全部信息后,用大模型作为输入进行进一步处理。在大模型的配置中,会引用前面工具读取到的内容,并根据业务需求和理解,编写特定的分析框架和总结模板。例如,对于突发事件、政策解读或社会民生新闻,可以设定不同的分析框架和核心关注点,确保输出的专业性和可读性。
在大模型中,如何处理循环中的中间变量,例如在分析新闻时的累计结果?大模型在分析过程中是如何根据输入变量进行工作的?
在大模型中,可以设定一个中间变量(如Summer),在每次循环迭代中根据当前新闻的内容以及之前新闻的总结结果来生成深度行业分析报告。例如,在第一次迭代时,Summer为空,只能根据输入的首篇新闻内容进行总结。但在第二次迭代时,Summer会带着第一次的结果和当前新闻的内容进行分析和总结,形成连续性的分析报告。大模型根据输入变量(如input)进行深度分析,生成行业报告。例如,当有一个名为toot的引用变量作为输入时,大模型会基于这个变量所代表的音符进行总结,并进一步生成分析报告。
如何在循环中记录并利用大模型的分析结果?
在循环中,通过设定变量(如Sarah)来记录大模型每次执行后的结果。例如,在第一次循环迭代中,Sarah为空,但在第二次循环迭代时,Sarah将存储第一次循环的结果,这样在后续循环中就可以利用这个已有的结果,结合新的新闻内容进行更新和深化分析。
如何利用大模型进行多轮新闻分析,并将结果串联起来?
通过设定循环,在每轮循环中让大模型读取链接、分析新闻并生成报告。每次循环结束时,将大模型的输出结果赋值给中间变量(如Summer),这样在下一次循环时,Summer就包含了所有之前新闻的分析结果和当前新闻的分析结果,实现了多轮新闻分析的串联。
在演示中,您首先展示了什么内容?您在处理第二篇新闻时,如何利用之前的结果?
首先,我展示了一个插件读取的新闻内容,并说明了当前的“提交”状态为空,即只有当前新闻的信息。然后演示了根据这个新闻和大模型的提示词来总结广告的过程。在处理第二篇新闻时,就会将第一篇新闻的总结结果作为当前输入的一部分,这样在总结第二篇新闻时就可以参考之前的结果进行补充和整合。
在最终输出的内容中,有哪些关键信息被提取出来?
最终输出的内容中,包含了时间线的分析结果以及线性代数在社会民生领域的应用焦点,系统对新闻内容进行了深度分析和时间轴的总结。
相关文章:
10-Agent循环分析新闻并输出总结报告
目录 关键词 摘要 速览 自动新闻总结与行业分析报告生成流程 创建深度行业分析报告的工作流 测试用例执行与调试 业务逻辑与循环处理任务 演示如何在循环体中添加链接读取工具 使用大模型处理和分析新闻信息 构建循环分析新闻并生成综合报告的流程 分析和优化慢速循…...
详解:原理、搭建、数据分片与读写分离)
十二、Redis Cluster(集群)详解:原理、搭建、数据分片与读写分离
Redis Cluster(集群)详解:原理、搭建、数据分片与读写分离 Redis Cluster 是 Redis 官方提供的分布式存储方案,通过数据分片(Sharding)实现 水平扩展(scalability),并提供 高可用性(HA) 和 故障自动转移(failover) 能力,解决了单机 Redis 内存受限、主从复制故障…...

贪心算法解题框架+经典反例分析,效率提升300%
贪心算法是一种在每一步选择中都采取当前状态下的最优决策,从而希望最终达到全局最优解的算法策略。以下从其定义、特点、一般步骤、应用场景及实例等方面进行讲解: 定义与基本思想 • 贪心算法在对问题求解时,总是做出在当前看来是最好的选…...

策略设计模式-下单
1、定义一个下单context类 通过这类来判断具体使用哪个实现类,可以通过一些枚举或者条件来判断 import com.alibaba.fastjson.JSON; import com.tc.common.exception.BusinessException; import com.tc.common.user.YjkUserDetails; import com.tc.institution.cons…...

Go加spy++隐藏窗口
最近发现有些软件的窗口就像狗皮膏药一样,关也关不掉,一点就要登录,属实是有点不爽了。 窗口的进程不能杀死,但是窗口我不想要。思路很简单,用 spy 找到要隐藏的窗口的句柄,然后调用 Windows 的 ShowWindo…...

React基础之tsx语法
tsx在jsx的基础上添加了新的类型,除此之外没有任何区别 事件绑定 function App() { const handleClick()>{ console.log(button被点击了); } return( <div className"App"> <button onClick{handleClick}>click me</button> </di…...

一体机:DeepSeek性能的“隐形枷锁”!
一体机是DeepSeek交付的最佳方式吗? 恰恰相反,一体机是阻碍DeepSeek提升推理性能的最大绊脚石。 为啥? 只因DeepSeek这个模型有点特殊,它是个高稀疏度的MoE模型。 MoE这种混合专家模型,设计的初衷是通过“激活一堆专…...
)
ALBEF的动量蒸馏(Momentum distillation)
简单记录学习~ 一、传统 ITC Loss 的局限性 One-Hot Label 的缺陷 传统对比学习依赖严格对齐的图文对,通过交叉熵损失(如 softmax 归一化的相似度矩阵)强制模型将匹配的图文对相似度拉高,非匹配对相似度压低11。但 one…...

浏览器WEB播放RTSP
注意:浏览器不能直接播放RTSP,必须转换后都能播放。这一点所有的播放都是如此。 参考 https://github.com/kyriesent/node-rtsp-stream GitHub - phoboslab/jsmpeg: MPEG1 Video Decoder in JavaScript 相关文件方便下载 https://download.csdn.net…...

将PDF转为Word的在线工具
参考视频:外文翻译 文章目录 一、迅捷PDF转换器二、Smallpdf 一、迅捷PDF转换器 二、Smallpdf...
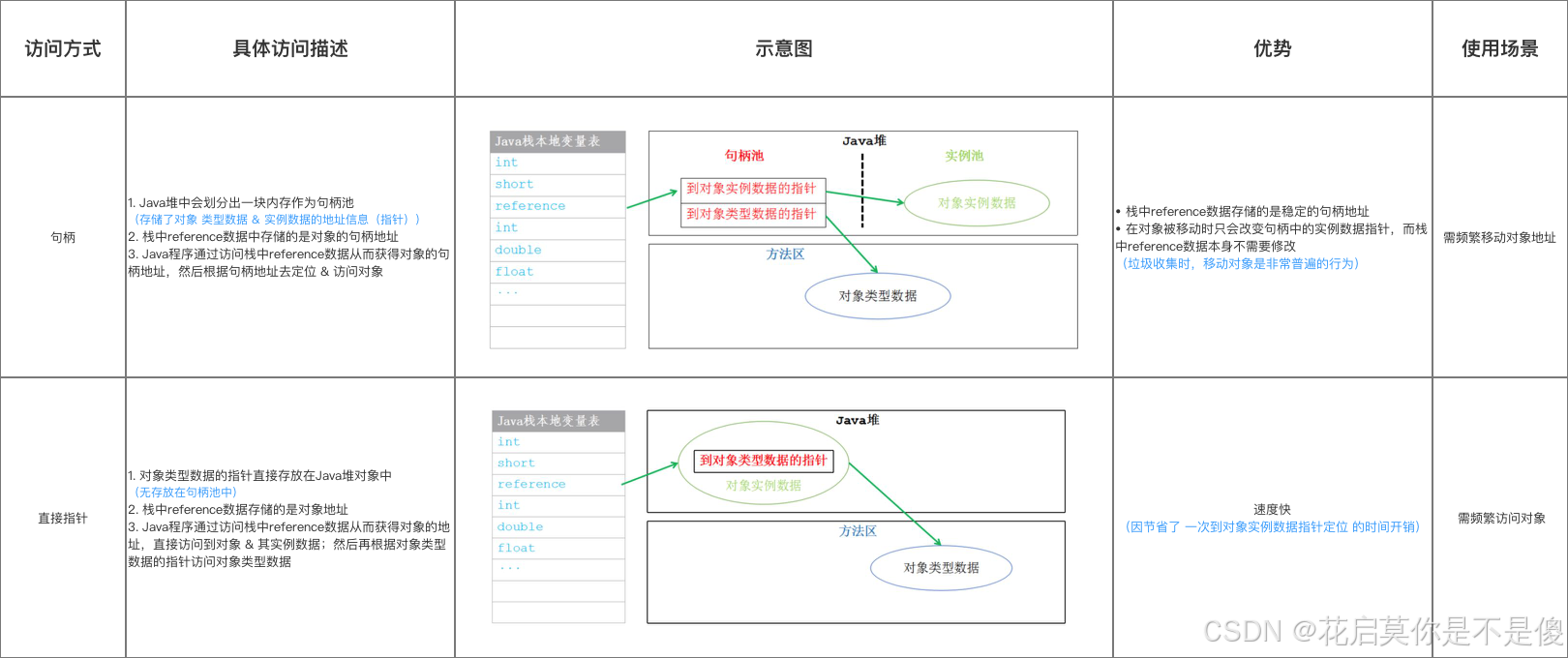
03. 对象的创建,存储和访问原理
文章目录 01. 对象创建1.1 创建过程概览1.2 类加载检查1.3 为对象分配内存1.4 将内存空间初始化为零值1.5 设置对象的必要信息1.6 总结 02. 对象的内存布局2.1 对象头区域2.2 实例数据区域2.3 对齐填充区域2.4 总结 03. 对象的访问定位其他介绍01.关于我的博客 注:读…...

机器学习-GBDT算法
目录 一. GBDT 核心思想 二. GBDT 工作原理 **(1) 损失函数优化** **(2) 负梯度拟合** **(3) 模型更新** 三. GBDT 的关键步骤 四. GBDT 的核心优势 **(1) 高精度与鲁棒性** **(2) 处理缺失值** **(3) 特征重要性分析** 五. GBDT 的缺点 **(1) 训练…...

redis基础结构
title: redis基础结构 date: 2025-03-04 08:39:12 tags: redis categories: redis笔记 Redis入门 (NoSQL, Not Only SQL) 非关系型数据库 关系型数据库:以 表格 的形式存在,以 行和列 的形式存取数据,一系列的行和列被…...

【keil】一种将STM32的armcc例程转换为armclang的方式
【keil】一种将所有armcc例程转换为armclang的方式 改的原因第一步下载最新arm6第二步编译成功 第三步去除一些warning编译成功 我这边用armclang去编译的话,主要是freertos中的portmacro.h和port.c会报错 改的原因 我真的服了,现在大部分的单片机例程都…...

计算机视觉算法实战——表面缺陷检测(表面缺陷检测)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 引言 表面缺陷检测是计算机视觉领域中的一个重要研究方向,旨在通过图像处理和机器学习技术自动检测产品表面的缺陷&…...

window下的docker内使用gpu
Windows 上使用 Docker GPU需要进行一系列的配置和步骤。这是因为 Docker 在 Windows 上的运行环境与 Linux 有所不同,需要借助 WSL 2(Windows Subsystem for Linux 2)和 NVIDIA Container Toolkit 来实现 GPU 的支持。以下是详细的流程: 一、环境准备 1.系统要求 Window…...
)
Modbus协议(TCP)
从今开始,会详细且陆续整理各类的通信协议,以便在需要且自身忘记的情况下,迅速复习。如有错误之处,还请批评指正。 一、Modbus协议的简述 Modbus协议作为应用层协议,基于主从设备模型,主设备负责请求消息&…...
虚拟系统配置实验报告
一、实验拓扑图 二、实验配置 要求一: 虚拟系统: 设置管理: 进行信息配置 R1配置 虚拟系统配置 a: b: c: 测试 a–>b: 检测...

Agentic系统:负载均衡与Redis缓存优化
摘要 本文在前文Agentic系统的基础上,新增负载均衡(动态调整线程数以避免API限流)和缓存机制(使用Redis存储搜索结果,减少API调用)。通过这些优化,系统在高并发场景下更加稳定高效。代码完整可…...

28-文本左右对齐
给定一个单词数组 words 和一个长度 maxWidth ,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。 你应该使用 “贪心算法” 来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可…...

SMARC嵌入式模块规范解析:从标准化接口到硬件设计实战
1. 项目概述:从“黑盒子”到标准化接口的进化在嵌入式系统开发领域,尤其是工业控制、边缘计算和物联网设备中,我们经常会遇到一个核心矛盾:如何平衡设计的灵活性与开发效率?早些年,很多项目都是从零开始&am…...

从零搭建到日常调试:一份给新手的 Kafka 命令行操作全流程指南
从零搭建到日常调试:一份给新手的 Kafka 命令行操作全流程指南 第一次接触 Kafka 时,我被它那些晦涩的概念和复杂的命令行参数搞得晕头转向。作为一个从 MySQL 和 Redis 这类传统数据库转过来的开发者,Kafka 的分布式消息队列模型确实需要一些…...

尝试Taotoken不同模型节点对生成速度的细微影响感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 尝试Taotoken不同模型节点对生成速度的细微影响感受 1. 测试背景与动机 在日常使用大模型进行开发或内容创作时,除了模…...

对比直接使用厂商API,Taotoken在账单清晰度上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在账单清晰度上的优势 在集成多个大语言模型到业务中时,开发者或团队通常会面…...

如何通过League Akari获得终极英雄联盟游戏体验:你的智能游戏助手完整指南
如何通过League Akari获得终极英雄联盟游戏体验:你的智能游戏助手完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英…...

情绪语音落地难?ElevenLabs新版本上线首周,92%开发者忽略的3个TTS情感对齐关键阈值,你踩雷了吗?
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs正式情绪语音发布全景与行业意义 ElevenLabs 于2024年第三季度正式推出「Emotion Voice API」,标志着AI语音合成从“可听”迈向“可感”的关键跃迁。该能力支持在TTS输出中动态注…...

BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面
BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面 【免费下载链接】BepInEx.ConfigurationManager Plugin configuration manager for BepInEx 项目地址: https://gitcode.com/gh_mirrors/be/BepInEx.ConfigurationManager 你是否曾为Unity游戏…...

终极指南:5分钟掌握Blender四边形网格重构神器QRemeshify
终极指南:5分钟掌握Blender四边形网格重构神器QRemeshify 【免费下载链接】QRemeshify A Blender extension for an easy-to-use remesher that outputs good-quality quad topology 项目地址: https://gitcode.com/gh_mirrors/qr/QRemeshify 你是否曾在Blen…...

Python网络编程利器:pincer中间件框架的设计原理与应用实践
1. 项目概述与核心价值最近在折腾一个游戏服务器的网络通信模块,偶然间在GitHub上看到了一个名为“pincer”的项目,作者是TheOneWhoAlwaysWatches。这个项目名挺有意思,直译过来是“钳子”或“夹子”,在计算机领域,尤其…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...