机器学习编译
一、机器学习概述
1.1 什么是机器学习编译
将机器学习算法从开发形态通过变换和优化算法使其变成部署形态。即将训练好的机器学习模型应用落地,部署在特定的系统环境之中的过程。
开发形态:开发机器学习模型时使用的形态。Pytorch,TensorFlow等通用框架编写的模型描述,以及与之相关的权重。
部署形态:指执行机器学习应用程序所需的形态。通常涉及机器学习模型的每个步骤的支持代码、管理资源的控制器以及应用程序开发环境的接口。
不用的AI应用对应的部署环境是互不相同的。
在进行机器学习模型部署时,不仅要考虑硬件系统的环境,与此同时也需要考虑软件环境(如操作系统环境、机器学习平台环境等)。
1.2 机器学习编译的目标
机器学习编译的直接目标包括两点:最小化依赖和利用硬件加速。最终目的是实现性能(时间复杂度、空间复杂度)优化。
最小化依赖可以认为是集成的一部分,提取出与应用相关的库(删除与应用无关的库),从而减少应用的大小,达到节省空间的目的。
利用硬件加速指的是利用硬件本身的特性进行加速。可以通过构建调用原生加速库的部署代码或生成利用原生指令的代码来实现。
1.3 为什么要学习机器学习编译
构建机器学习部署的解决方案。
对现有机器学习框架形成更加深刻的理解。
1.4 机器学习编译的核心要素
-
张量(Tensor):是执行中最重要的元素。张量是表示神经网络模型执行的输入、输出和中间结果的多维数组。
-
张量函数(Tensor Function):神经网络的知识被编码在权重和接收张量和输出张量的计算序列中。将这些计算称为张量函数。注意:张量函数不需要对应于神经网络计算的单个步骤。部分计算或者整个端到端的计算也可以看作张量函数。
不仅是单个函数可以认作张量函数,也可以把其中一部分(或者整个整体)看作是张量函数。
举个栗子:
第一个linear层和relu层计算被折叠成一个linear_relu函数(算子融合),这需要特定的linear_relu的详细实现。
def linear_relu(x,w,out):for i in range(1):for j in range(200):out[i,j]=0for k in range(3072):out[i,j]+=w[i,k]+w[j,k]out[i,j]=max(out[i,j],0)1.5 抽象和实现
对同样的目标有不同颗粒度的表示。例如对linear_relu而言,既可以使用左边两个框图进行表示,也可以用右边的循环进行表示。
-
抽象:表示相同张量函数的方式。不同的抽象可能会指定一些细节,而忽略其他实现细节。例如,linear_relu可以使用另外一个不同的for循环来实现。
-
抽象和实现可能是所有计算机系统中最重要的关键字。抽象指定"做什么",实现提供”如何做“。没有具体的界限。根据我们的看法,for循环本身可以被视作一种抽象,可以使用python解释器实现或编译为本地汇编代码,
机器学习编译实际上是在相同或不同抽象下转换和组装张量函数的过程。我们将研究张量函数的不同抽象类型,以及他们如何协同工作以解决机器学习部署中 的挑战。
在后续文章中分别会涉及到四种类型的抽象:
计算图,张量程序,库(运行时),硬件专用指令
二、张量程序抽象
2.1 元张量函数(张量算子)
元张量函数指的是单个单元(最小颗粒度)的张量函数。
以pytorch中的加法为例:
import torch
C = torch.empty((128,), dtype=torch.float32)
a = torch.tensor(np.arange(128, dtype="float32"))
b = torch.tensor(np.ones(128, dtype="float32"))
torch.add(a,b,out=c) # torch.add can be viewed as a primitive tensor function那么torch.add是如何实现的呢?或者在实际部署中,如何将不同的步骤(多个元张量函数)合并在一起?
抽象与实现是本课程的核心概念之一。对于同一个张量算子而言,可以使用不同的方式来实现:

第二种表示是对第一种表示的细化,第三种表示是使用低级语言(C语言,甚至是使用汇编语言)来进行更高效的实现。
许多框架提供的一个最常见的MLC过程是将基本函数的实现(或在运行时分派它们)转换为基于环境的更优化的实现。

例如当前环境可以四个四个读取程序数据,所以可以使用并行化来优化当前代码。
2.1.1 张量算子变换
常见的一种做法是直接把它映射到相应的算子库上。比如在cuda环境中使用cudaAdd。另外一种是更细力度的程序变换。前者直接用符号表示即可,而后者需要表示成循环的形式。
2.2 张量程序抽象
上文提到的张量算子变换包括两种常见的形式。一种是直接映射到对应的算子库上,另一种是进行更细粒度的程序变换。将后者称之为是张量函数抽象。
下图是TVM中的一个样例:

张量函数抽象包括三大关键要素:
1.多维的输入、输出的数据。
2.循环
3.每个循环中进行相应的计算。
涉及到一个问题:为什么我们不直接使用c语言等低级语言进行编写程序。主要在于机器学习编译的核心不仅在于程序员能够完成代码的编写,更重要的事完成张量算子变换,即给定一个张量将它从原始形态变换到更加优化的形态(尝试不同的变换,最终找到一个最为优化的形态)。如果通过程序来探索可能得张量函数对应的等价空间就能够大大提升效率。
2.2.1为什么需要进行张量程序抽象、


在Program-based transformations 中进行了循环拆分,本质上是将单层循环变换为双层循环(循环拆分是比较常见的一种变换),而Transformed Program涉及到了并行化与向量化的操作,其中向量化在这里指的是每一步都以长度为4的单元(批处理)来进行计算。
2.2.2 常见张量变换
1.循环拆分

其中等价替换包括:
x=xo*4+xi

这样简化并行化处理,提高了内存访问效率,便于向量化操作,简化编程模型。
2.循环重排
将两个循环的顺序进行更换

3.线程绑定

如果在GPU上进行并行化,可以把xi和xo对应到GPU的两个线程上。通过绑定GPU的线程得到最终的结果(后续章节中会进行更加深入的讲解)。
在不同的硬件环境上尝试不同的变换组合,然后根据测试在张量函数对应的等价空间中得到最优的变换。需要注意的一点是,在这里进行的变换必须是等价变换。下面举个反例,本质上可以表示成C = A + C ,C会对其他index下的C的结果存在依赖(在xo = 4, xi = 0的情况会对 xo = 0, xi = 1的结果造成依赖, 而如果我们改变了循环顺序之后 xo = 0, xi = 1会先被循环到),如果只是单纯的reorder,循环的顺序会有变化导致依赖关系被打破,会出现等式左边的C计算时等式右边的C还没有结果的情况。所以在这里不能进行循环重排。 即注意变量是否依赖其他变量。
for xo in range(32):for xi in range(4):C[xo * 4 + xi] = A[xo * 4 + xi] + C[max(xo * 4 + xi – 1, 0)]
这里的xi需要依赖于xi-1所以不能进行线程绑定。
2.2.3 张量程序抽象中的其他结构
根据上文所述,我们不能任意地对程序进行变换(比如部分计算会依赖于循环之间的顺序)。但幸运的是我们所感兴趣的大多数元张量函数都具有良好的属性(例如循环迭代之间的独立性)。
张量程序可以将这些额外的信息合并为程序的一部分,可以使得程序更加便利。

其中vi = T.axis.spatial(128, i)不仅等价于vi=i,并且表明vi表示了一个迭代器,并且迭代器中所有的迭代都是独立的。这个信息对于执行这个程序而言并非必要,但会使得我们在变换这个程序时更加方便。在这个例子中,我们知道我们可以安全地并行或者重新排序所有与 vi 有关的循环,只要实际执行中 vi 的值按照从 0 到 128 的顺序变化。
2.3 张量程序变换实践
建议直接使用Colab,可以直接使用pip安装包来安装tvm
1.配置环境
由于 https://mlc.ai/wheels需要代理才能连通。
python3 -m pip install mlc-ai-nightly -f https://mlc.ai/wheels2.构造张量程序
import numpy as np
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
@tvm.script.ir_module
class MyModule:@T.prim_funcdef main(A:T.Buffer[128,"float32"],B:T.Buffer[128,"float32"],C:T.Buffer[128,"float32"]):T.func_attr({"global_symbol":"main","tir.noalias":True})for i in range(128):with T.block("C"):vi=T.axis.spatial(128,i)C[vi]=A[vi]+B[vi]TvmScript是一种我们能以python抽象语法树的形式来表示张量程序的方式。与python语法所对应,并在该语法的基础上增加了能够帮助程序分析与变换的额外结构。
print(type(MyModule))#tvm,ir.module.IRModuleMyModule是IRModule数据结构的一个实例,是一组张量函数的集合。
我们可以通过script函数得到这个IRModule的TVMScript表示,这个函数对于在一步步程序变换间检查IRModule而言很有帮助。
print(MyModule.script())

3.编译与运行
使用build函数将一个IRModule转换为可以执行的函数,其中llvm表示CPU作为硬件执行环境
rt_mod=tvm.build(MyModule,target="llvm")
type(rt_mod) #tvm.driver.build_module.OperatorModule在编译后,mod包含了一组可以执行的函数,我们可以通过这些函数名字拿到对应的函数
func=rt_mod["main"]
func #<tvm.runtime.packed_func.PackedFunc>先构建三个张量,其中c用来接收输出:
a = tvm.nd.array(np.arange(128, dtype="float32"))
b = tvm.nd.array(np.ones(128, dtype="float32"))
c = tvm.nd.empty((128,), dtype="float32")
func(a, b, c)
print(c)[1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127. 128.]4.张量程序变换
一个张量程序可以通过一个辅助的名为调度(schedule)的数据结构得到变换
sch=tvm.tir.Schedule(MyModule)
type(sch) #tvm.tir.schedule.schedule.Schedule拆分循环
# Get block by its name
block_c = sch.get_block("C")
# Get loops surrounding the block,拿到block之外对应的循环
(i,) = sch.get_loops(block_c)
# Tile the loop nesting.
i_0, i_1, i_2 = sch.split(i, factors=[None, 4, 4])
print(sch.mod.script())将for i in tir.serial(128)中的i变换成了i_0, i_1和i_2。另外需要注意的是factors=[None, 4, 4]和tir.grid(8, 4, 4)中之间一一的对应关系以及vi等价于tir.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)。后者是通过三重循环来表示一重循环。

你可以通过这幅图片来了解这个拆分关系

# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:@T.prim_funcdef main(A: T.Buffer((128,), "float32"), B: T.Buffer((128,), "float32"), C: T.Buffer((128,), "float32")):T.func_attr({"tir.noalias": T.bool(True)})# with T.block("root"):for i_0, i_1, i_2 in T.grid(8, 4, 4):with T.block("C"):vi = T.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)T.reads(A[vi], B[vi])T.writes(C[vi])C[vi] = A[vi] + B[vi]循环重排
sch.reorder(i_0,i_2,i_1)
print(sch.mod.script())# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:@T.prim_funcdef main(A: T.Buffer((128,), "float32"), B: T.Buffer((128,), "float32"), C: T.Buffer((128,), "float32")):T.func_attr({"tir.noalias": T.bool(True)})# with T.block("root"):for i_0, i_2, i_1 in T.grid(8, 4, 4):with T.block("C"):vi = T.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)T.reads(A[vi], B[vi])T.writes(C[vi])C[vi] = A[vi] + B[vi]并行化
对最外层循环进行并行操作
sch.parallel(i_0)
print(sch.mod.script())# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:@T.prim_funcdef main(A: T.Buffer((128,), "float32"), B: T.Buffer((128,), "float32"), C: T.Buffer((128,), "float32")):T.func_attr({"tir.noalias": T.bool(True)})# with T.block("root"):for i_0 in T.parallel(8):for i_2, i_1 in T.grid(4, 4):with T.block("C"):vi = T.axis.spatial(128, i_0 * 16 + i_1 * 4 + i_2)T.reads(A[vi], B[vi])T.writes(C[vi])C[vi] = A[vi] + B[vi]一下是张量程序创建->编译->运行

三、张量程序案例 TensorIR
使用张量程序抽象的目的是为了表示循环和相关硬件加速选择,如多线程、特殊硬件指令的使用和内存访问。
3.1 举个例子
使用张量程序抽象,我们可以在较高层的抽象指定一些与特定硬件无关的较通用的IR优化(计算优化)。
比如,对于两个大小为128*128的矩阵A和B,我们进行如下两步的张量计算:

即一个matmul操作和一个relu操作。
-
使用numpy
dtype="float32" a=np.random.rand(128,128).astype(dtype) b=np.random.rand(128,128).astype(dtype) c_mm_relu=np.maximum(a@b,0)dtype="float32" a=np.random.rand(128,128).astype(dtype) b=np.random.rand(128,128).astype(dtype) c_mm_relu=np.maximum(a@b,0) -
在底层,Numpy调用库和它自己在低级C语言中的一些实现来执行这些计算。
def lnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray):Y = np.empty((128, 128), dtype="float32")for i in range(128):for j in range(128):Y[i, j] = 0 # 初始化 Y[i, j] 为 0for k in range(128):Y[i, j] += A[i, k] * B[k, j]for i in range(128):for j in range(128):C[i, j] = max(Y[i, j], 0) -
主程序对比
# 主程序 dtype = "float32" a = np.random.rand(128, 128).astype(dtype) b = np.random.rand(128, 128).astype(dtype) # 使用 NumPy 的矩阵乘法和 ReLU 激活计算正确结果 c_mm_relu = np.maximum(a @ b, 0) # 初始化输出矩阵 c c = np.empty((128, 128), dtype=dtype) # 使用 lnumpy_mm_relu 计算结果 lnumpy_mm_relu(a, b, c) # 使用 np.testing.assert_allclose 验证结果是否一致 np.testing.assert_allclose(c_mm_relu, c, rtol=1e-5, atol=1e-8) print("Validation passed: The results are consistent.")

但第二种实现更接近实际的框架在目标硬件上的调度和计算。这里的抽象展示了我们在实际实现中需要的元素:
-
多维缓冲区(数组)。
-
在数组维度上的循环。
-
在循环下执行的计算语句.
3.2 Tensor IR
Tensor IR是TVM里的Tensor抽象,是最接近硬件的IR
在TVM中可以用一种叫做TVMScript DSL来用python写一些IR优化,比如上面的例子可以写成:
import numpy as np
from tvm.script import tir as T
import tvm
@tvm.script.ir_module
class Module:@T.prim_funcdef mm_relu(A: T.Buffer((128, 128), "float32"),B: T.Buffer((128, 128), "float32"),C: T.Buffer((128, 128), "float32")):T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})Y = T.alloc_buffer((128, 128), dtype="float32")for i, j, k in T.grid(128, 128, 128):with T.block("Y"):vi = T.axis.spatial(128, i)vj = T.axis.spatial(128, j)vk = T.axis.reduce(128, k)with T.init():Y[vi, vj] = T.float32(0)Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]for i, j in T.grid(128, 128):with T.block("C"):vi = T.axis.spatial(128, i)vj = T.axis.spatial(128, j)C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
import numpy as np
from tvm.script import tir as T
import tvm@tvm.script.ir_module
class Module:@T.prim_funcdef mm_relu(A: T.Buffer((128, 128), "float32"),B: T.Buffer((128, 128), "float32"),C: T.Buffer((128, 128), "float32")):T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})Y = T.alloc_buffer((128, 128), dtype="float32")for i, j, k in T.grid(128, 128, 128):with T.block("Y"):vi = T.axis.spatial(128, i)vj = T.axis.spatial(128, j)vk = T.axis.reduce(128, k)with T.init():Y[vi, vj] = T.float32(0)Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]for i, j in T.grid(128, 128):with T.block("C"):vi = T.axis.spatial(128, i)vj = T.axis.spatial(128, j)C[vi, vj] = T.max(Y[vi, vj], T.float32(0))

与numpy指定优化对比:
计算块:
TensorIR 是 TVM 中用于表示张量计算的低级中间表示,它不仅描述了计算的数据流,还描述了计算之间的依赖关系。这些依赖关系对于理解数据如何在计算图中流动以及如何正确地执行计算至关重要。在 TensorIR 中,数据依赖关系体现在各个计算块(block)之间的相互作用上。
对于循环中的变量需要映射到一个块上做计算。
块是TensorIR中的基本计算单位,该块比numpy包含的信息多。一个块包含一组块轴(vi、vj、vk)和围绕他们定义的计算。
块轴绑定的语法糖:在每个块轴直接映射到外部循环迭代器的情况下我们可以使用T.axis.remap在一行中声明所有块轴
# SSR means the properties of each axes are "spatial", "spatial", "reduce"
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
这里就相当于块 vi, vj, vk 分别和循环迭代器 i, j, k 绑定上了,类似 T.grid,只需要一行代码就可以完成多个绑定。
于是上述代码可以写成

3.3 变换
3.3.1 循环拆分
sch=tvm.tir.Schedule(Module)
block_T=sch.get_block("matmul",func_name="mm_relu")
i,j,k=sch.get_loops(block_T)
j0,j1=sch.split(j,factors=[None,4])
print(sch.mod.script())
3.3.2 循环重排
sch.reorder(j0,k,j1)
print(sch.mod.script())
3.3.3 算子融合
将 ReLU 块(block_C)的计算移动到矩阵乘法块(block_T)的 j0 循环中。

作用:
(1)减少内存访问:将Relu的计算移动到矩阵乘法的内层循环中,可以减少对中间缓冲区Y的访问次数,从而提高内存访问效率。
(2)提高计算效率:减少了循环嵌套的层数,降低了循环开销。可以利用CPU或GPU的缓存,减少数据在内存和缓存之间的传输。
3.3.4 规约分解
将规约操作(如矩阵乘法中的累加)分解为多个阶段,从而优化计算过程。
sch.decompose_reduction(block_T,k)
print(sch.mod.script())
3.3.5 优化对比
import numpy as np
# 主程序
dtype = "float32"
a = np.random.rand(128, 128).astype(dtype)
b = np.random.rand(128, 128).astype(dtype)
# 使用 NumPy 的矩阵乘法和 ReLU 激活计算正确结果
c_mm_relu = np.maximum(a @ b, 0)
mod=tvm.build(Module,target="llvm")
func=mod["mm_relu"]
# 初始化输出矩阵 c
c = np.empty((128, 128), dtype="float32")
a_tvm = tvm.nd.array(a)
b_tvm = tvm.nd.array(b)
c_tvm = tvm.nd.array(c)
# 使用 lnumpy_mm_relu 计算结果
func(a_tvm, b_tvm, c_tvm)
np.testing.assert_allclose(c_mm_relu, c_tvm.numpy(), rtol=1e-5, atol=1e-8)
print("Validation passed: The results are consistent.")Validation passed: The results are consistent.
对比优化前后时间差,帮助评估调度优化(如循环分块、规约分解等)对性能的影响。
# 比较计算内存优化前后的运行时间
rt_lib = tvm.build(Module, target='llvm')
a_nd = tvm.nd.array(a)
b_nd = tvm.nd.array(b)
c_nd = tvm.nd.empty((128, 128), dtype='float32')rt_lib_after = tvm.build(sch.mod, target='llvm')
f_time_before = rt_lib.time_evaluator("mm_relu", tvm.cpu())
print(f"Time cost of Mymodule:{f_time_before(a_nd, b_nd, c_nd).mean}")
f_time_after = rt_lib_after.time_evaluator("mm_relu", tvm.cpu())
print(f"Time cost after transform:{f_time_after(a_nd, b_nd, c_nd).mean}")
3.4 分析优化原因
如下图,现代CPU带有多级缓存,需要先将数据提取到缓存当中,然后CPU才能访问它。

数据访问流程
当 CPU 需要访问数据时,它会按照以下顺序查找数据:
-
检查寄存器:首先在最快的寄存器中查找数据。
-
检查 L1 缓存:如果数据不在寄存器中,CPU 会检查 L1 缓存。
-
检查 L2 缓存:如果数据不在 L1 缓存中,CPU 会检查 L2 缓存。
-
访问主内存:如果数据不在任何缓存中,CPU 最后会从主内存(DRAM)中加载数据。
这种层次化的存储结构允许计算机在处理大量数据时保持较高的效率,因为经常使用的数据可以存储在快速的缓存中,从而减少访问较慢的主内存的次数。
缓存一致性和替换策略
-
缓存一致性:确保所有级别的缓存中的数据与主内存中的数据保持一致。
-
替换策略:当缓存满时,决定哪些数据应该被替换出去。常见的策略包括最近最少使用(LRU)等。
访问已经在缓存中的数据要快的多。CPU采用一种策略是获取彼此更接近的数据(局部性原理)。当我们读取内存中的一个元素时,它会尝试将附近的元素(“缓存行”)获取到缓存中。因此,当你读取下一个元素时,它已经在缓存中了。因此具有连续内存访问的代码通常比随机访问内存不同部分的代码更快。
现在让我们看看上面的迭代可视化,分析一下是怎么回事。 在这个分析中,让我们关注最里面的两个循环:k 和 j1。高亮的地方显示了当我们针对 k 的一个特定实例迭代 j1 时迭代触及的 Y、A 和 B 中的相应区域。
我们可以发现,j1 这一迭代产生了对 B 元素的连续访问。具体来说,它意味着在 j1=0 和 j1=1 时我们读取的值彼此相邻。这可以让我们拥有更好的缓存访问行为。此外,我们使 C 的计算更接近 Y,从而实现更好的缓存行为。
改变计算的循环迭代使之更接近 CPU 执行策略是编译器的常见优化手段之一。
相关文章:
机器学习编译
一、机器学习概述 1.1 什么是机器学习编译 将机器学习算法从开发形态通过变换和优化算法使其变成部署形态。即将训练好的机器学习模型应用落地,部署在特定的系统环境之中的过程。 开发形态:开发机器学习模型时使用的形态。Pytorch,TensorFlow等通用框…...

什么是 BotGate 动态防护?
随着网络威胁日益复杂,传统的防护方法逐渐暴露出漏洞。BotGate 动态防护是一种结合机器人网络(Botnet)和动态防护技术的新兴网络安全模式。它利用大量分布式设备(即“僵尸网络”或 Botnet)的实时协作能力,快…...

Linux笔记---自定义shell
目录 前言 1. 程序框架 2. 打印命令行提示符 2.1 获取用户名(GetUserName) 2.2 获取主机名(GetHostName) 2.3 获取工作目录(GetPwd) 3. 获取命令行输入 4. 判断是否有重定向 5. 解析命令行 6. 内建命令 6.1 内建命令的特点 6.2 常见内建命令 6.3 内建命令 vs 外部命…...

大语言模型从理论到实践(第二版)-学习笔记(绪论)
大语言模型的基本概念 1.理解语言是人工智能算法获取知识的前提 2.语言模型的目标就是对自然语言的概率分布建模 3.词汇表 V 上的语言模型,由函数 P(w1w2 wm) 表示,可以形式化地构建为词序列 w1w2 wm 的概率分布,表示词序列 w1w2 wm…...

2025-03-08 学习记录--C/C++-C 语言 判断一个数是否是完全平方数
C 语言 判断一个数是否是完全平方数 使用 sqrt 函数计算平方根,然后判断平方根的整数部分是否与原数相等。 #include <stdio.h> #include <math.h>int isPerfectSquare(int num) {if (num < 0) {return 0; // 负数不是完全平方数}int sqrtNum (int)…...

八、排序算法
一些简单的排序算法 8.1 冒泡排序 void Bubble_sort(int a[] , int len){int i,j,flag,tmp;for(i=0 ; i < len-1 ; i++){flag = 1;for(j=0 ; j < len-1-i ; j++){if(a[j] > a[j+1]){tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;flag = 0;}}if(flag == 1){break;}}…...

计算机网络篇:基础知识总结与基于长期主义的内容更新
基础知识总结 和 MySQL 类似,我同样花了一周左右的时间根据 csview 对计算机网络部分的八股文进行了整理,主要的内容包括:概述、TCP 与 UDP、IP、HTTP,其中我个人认为最重要的是 TCP 这部分的内容。 在此做一篇目录索引…...

nodejs学习——nodejs和npm安装与系统环境变量配置及国内加速
nodejs和npm安装与系统环境变量配置及国内加速 下载node-v22.14.0-x64.msi 建议修改为非C盘文件夹 其它步骤,下一步,下一步,完成。 打开CMD窗口查看安装详情 $ node -v v22.14.0 $ npm -v 10.9.2$ npm config list创建node_global和node_c…...

《打造视频同步字幕播放网页:从0到1的技术指南》
《打造视频同步字幕播放网页:从0到1的技术指南》 为什么要制作视频同步字幕播放网页 在数字化信息飞速传播的当下,视频已然成为内容输出与获取的核心载体,其在教育、娱乐、宣传推广等诸多领域发挥着举足轻重的作用 。制作一个视频同步字幕播…...

清华大学第八弹:《DeepSeek赋能家庭教育》
大家好,我是吾鳴。 之前吾鳴给大家分享过清华大学出版的七份报告,它们分别是: 《DeepSeek从入门到精通》 《DeepSeek如何赋能职场应用》 《普通人如何抓住DeepSeek红利》 《DeepSeekDeepResearch:让科研像聊天一样简单》 《D…...

自我训练模型:通往未来的必经之路?
摘要 在探讨是否唯有通过自我训练模型才能掌握未来的问题时,文章强调了底层技术的重要性。当前,许多人倾向于关注应用层的便捷性,却忽视了支撑这一切的根本——底层技术。将模型简单视为产品是一种短视行为,长远来看,理…...

C++ Primer 交换操作
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...
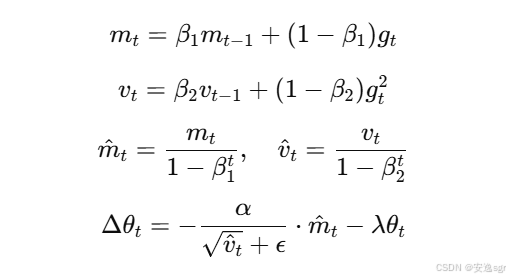
深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)
深度学习模型组件之优化器–自适应学习率优化方法(Adadelta、Adam、AdamW) 文章目录 深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)1. Adadelta1.1 公式1.2 优点1.3 缺点1.4 应用场景 2. Adam (Adaptiv…...

使用jcodec库,访问网络视频提取封面图片上传至oss
注释部分为FFmpeg(确实方便但依赖太大,不想用) package com.zuodou.upload;import com.aliyun.oss.OSS; import com.aliyun.oss.model.ObjectMetadata; import com.aliyun.oss.model.PutObjectRequest; import com.zuodou.oss.OssProperties;…...

新品速递 | 多通道可编程衰减器+矩阵系统,如何破解复杂通信测试难题?
在无线通信技术快速迭代的今天,多通道可编程数字射频衰减器和衰减矩阵已成为测试领域不可或缺的核心工具。它们凭借高精度、灵活配置和强大的多通道协同能力,为5G、物联网、卫星通信等前沿技术的研发与验证提供了关键支持。从基站性能测试到终端设备校准…...

扩展------项目中集成阿里云短信服务
引言 在当今数字化时代,短信服务在各种项目中扮演着重要角色,如用户注册验证、订单通知、营销推广等。阿里云短信服务凭借其稳定、高效和丰富的功能,成为众多开发者和企业的首选。本文将详细介绍如何在项目中集成阿里云短信服务,帮…...

MySQL面试篇——性能优化
MySQL性能优化 在MySQL中,如何定位慢查询 慢查询表象:页面加载过慢、接口压测响应时间过长(超过1s)。造成慢查询的原因通常有:聚合查询、多表查询、表数据量过大查询、深度分页查询 方案一:开源工具 调试工…...

Java EE 进阶:Spring MVC(2)
cookie和session的关系 两者都是在客户端和服务器中进行存储数据和传递信息的工具 cookie和session的区别 Cookie是客⼾端保存⽤⼾信息的⼀种机制. Session是服务器端保存⽤⼾信息的⼀种机制. Cookie和Session之间主要是通过SessionId关联起来的,SessionId是Co…...

ShardingSphere 和 Spring 的动态数据源切换机制的对比以及原理
ShardingSphere 与 Spring 动态数据源切换机制的对比及原理 一、核心定位对比 维度ShardingSphereSpring动态数据源(如 AbstractRoutingDataSource)定位分布式数据库中间件轻量级多数据源路由工具核心目标分库分表、读写分离、分布式事务多数据源动态切…...

基于Django的协同过滤算法养老新闻推荐系统的设计与实现
基于Django的协同过滤算法养老新闻推荐系统(可改成普通新闻推荐系统使用) 开发工具和实现技术 Pycharm,Python,Django框架,mysql8,navicat数据库管理工具,vue,spider爬虫࿰…...

ARM EDPRSR寄存器解析与嵌入式调试实践
1. ARM EDPRSR寄存器深度解析在嵌入式系统开发中,调试功能的重要性不言而喻。作为ARM架构调试系统的核心组件之一,EDPRSR(External Debug Processor Status Register)寄存器为开发者提供了处理器状态监控的关键窗口。这个32位寄存…...

低成本搭建BLE嗅探器:基于nRF52840与Wireshark的物联网协议分析实战
1. 项目概述与核心价值如果你正在开发或调试基于蓝牙低功耗(BLE)的物联网设备,比如智能手环、传感器节点或者任何通过蓝牙通信的小玩意儿,那么你肯定遇到过这样的困境:设备明明发了数据,手机App却没收到&am…...

基于Claude API的视频转录技能开发:从语音识别到AI集成实战
1. 项目概述:一个为Claude设计的视频转录技能最近在折腾AI应用开发,特别是围绕Claude API构建一些实用工具。我发现一个挺有意思的项目,叫Johncli7941/claude-skill-video-transcribe。从名字就能看出来,这是一个为Claude设计的“…...
)
保姆级教程:用Docker部署Jenkins时,如何搞定Agent节点的50000端口映射(附避坑点)
深度解析Docker化Jenkins部署:50000端口映射全攻略与实战避坑指南 Jenkins作为持续集成领域的标杆工具,其容器化部署已成为现代DevOps实践的标配。但当Master节点运行在Docker环境中时,Agent节点连接失败的场景屡见不鲜——其中80%的问题根源…...

Midjourney批量生成工作流终极提速方案:从单图2分钟到百图并发17秒,实测数据驱动的6大优化节点
更多请点击: https://intelliparadigm.com 第一章:Midjourney批量生成工作流的性能瓶颈全景图 在高并发图像生成场景中,Midjourney 的批量工作流常因 API 限流、提示词解析延迟、队列堆积及资源调度失衡而显著降速。其底层依赖 Discord 消息…...

3步轻松解锁QQ音乐加密文件:macOS用户必备的解码工具
3步轻松解锁QQ音乐加密文件:macOS用户必备的解码工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转…...

Task发展历程:从简单任务运行器到现代自动化工具的完整演进史
Task发展历程:从简单任务运行器到现代自动化工具的完整演进史 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task Task是一个快速、跨平台的构建…...
终极指南:从入门到实战的完整教程)
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr 面对复杂多变的空间数据,传统的地理加权回归(GWR)常…...

嵌入式Linux驱动DLP投影:硬件接口、软件栈与实战应用
1. 项目概述:当DLP投影遇上嵌入式Linux如果你正在寻找一个既能玩转嵌入式Linux,又能探索前沿投影显示技术的项目,那么DLP LightCrafter™ Display 2000评估模块(EVM)绝对是一个让你眼前一亮的平台。它不是一个简单的投…...

终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController
终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController 【免费下载链接】SDCAlertView The little alert that could 项目地址: https://gitcode.com/gh_mirrors/sd/SDCAlertView SDCAlertView是一款强大的iOS弹窗解决方案,它为…...