基于TPU-MLIR实现UNet模型部署-决赛答辩02
队伍:AP0200023
目录
初赛
一、 模型导出优化
1.1 直接倒出原始模型并转换
1.2 导出模型前处理
1.2.1 导出Resize
1.2.2 导出归一化
1.3导出模型后处理
1.3.1导出 Resize 与
1.3.2导出 ArgMaxout
1.3.3导出特征转RGB
复赛
一、 确定baseline
二、优化模型
复赛结果总结
三、遇到的问题总结
1. ONNX转MLIR
2. MLIR转bmodel
3. MLIR推理代码 BUG 【已经解决了】
四、 一些想法和建议
初赛
一、 模型导出优化
1.1 直接倒出原始模型并转换
报错Pad节点输入问题,修改源码报错解决
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2], mode="constant",
value=0)1.2 导出模型前处理
1.2.1 导出Resize
x = F.interpolate(x, (h // 2, w // 2), mode='bilinear')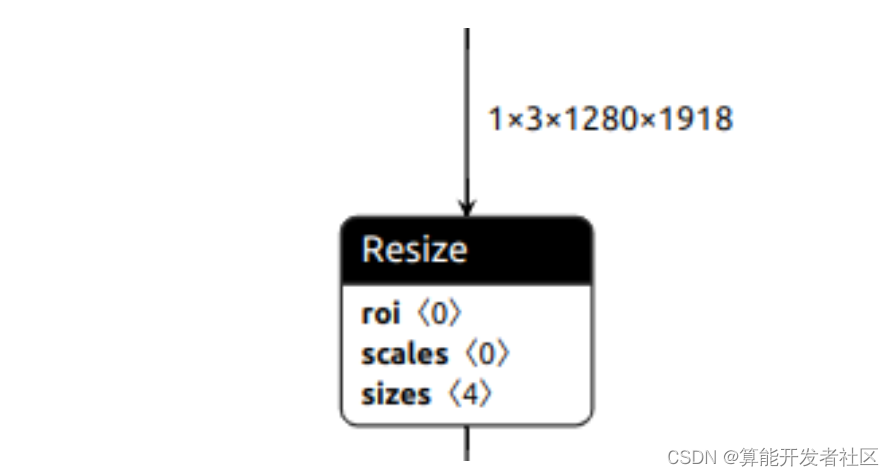
原始Unet在UINT8输入下做Resize,但是这个操作不能直接导出到ONNX,因此测试了FP32 Resize和FP32归一化Resize,还有Resize模式bicubic bilinear。
工具链不支持bicubic。最终使用bilinear结果差距很大。
1.2.2 导出归一化
x = x / 255.0 # 1.导出除法
x = x * (1.0 / 255.0) # 2.导出乘法
param = self.unet.inc.double_conv[0].weight / 255.0
self.unet.inc.double_conv[0].weight = torch.nn.Parameter(param,
requires_grad=False) # 3.首层卷积权重/ 255.0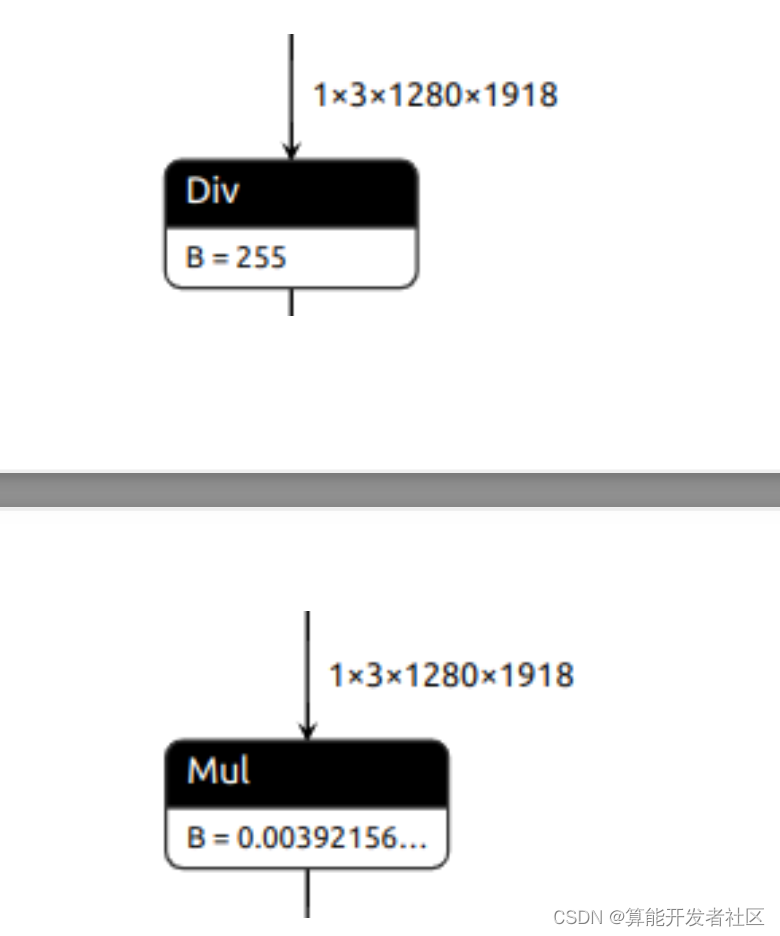
上述三中归一化操作对整体耗时影响很小,第三种方法FP32速度最快,但是可能INT8量化有问题。
1.2.3导出BGR2RGB
经过测试 OpenCV +切片比 PillowSkimage 读图速度快,因此考虑将BGR2RGB转出到 ONNX ,使用 Gather 算子实现。
param = param[:, [2, 1, 0], ...]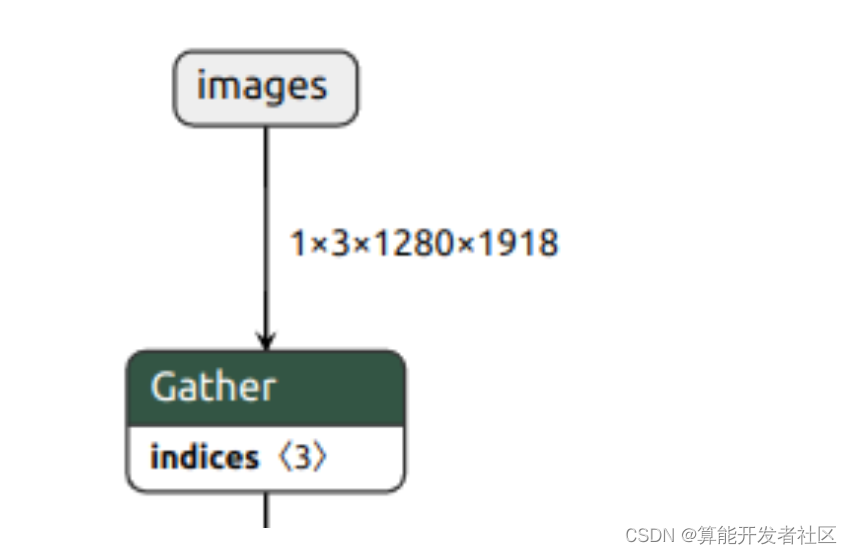
使用 Gather 会造成额外的拷贝,后面又改进成把首层卷积核顺序反转,这样的速度最快,且没有任何负面影响。
1.3导出模型后处理
1.3.1导出 Resize 与
前处理相似。
1.3.2导出 ArgMaxout
out = out.argmax(-1)模型转换报错不支持 ArgMax ,换如下实现:
out = torch.lt(out[0, 0], out[0, 1]) # Gather + Less
out = self.conv(out) > 0 # Conv + Greater
尝试构造 Conv 用来实现两个 Channel 做差, Conv 有可能以INT8运行,速度比较快。
conv = nn.Conv2d(2, 1, kernel_size=1, stride=1, padding=0, bias=False)
conv.weight = nn.Parameter(torch.tensor([-1, 1]).to(conv.weight).reshape(conv.weight.shape),requires_grad=False)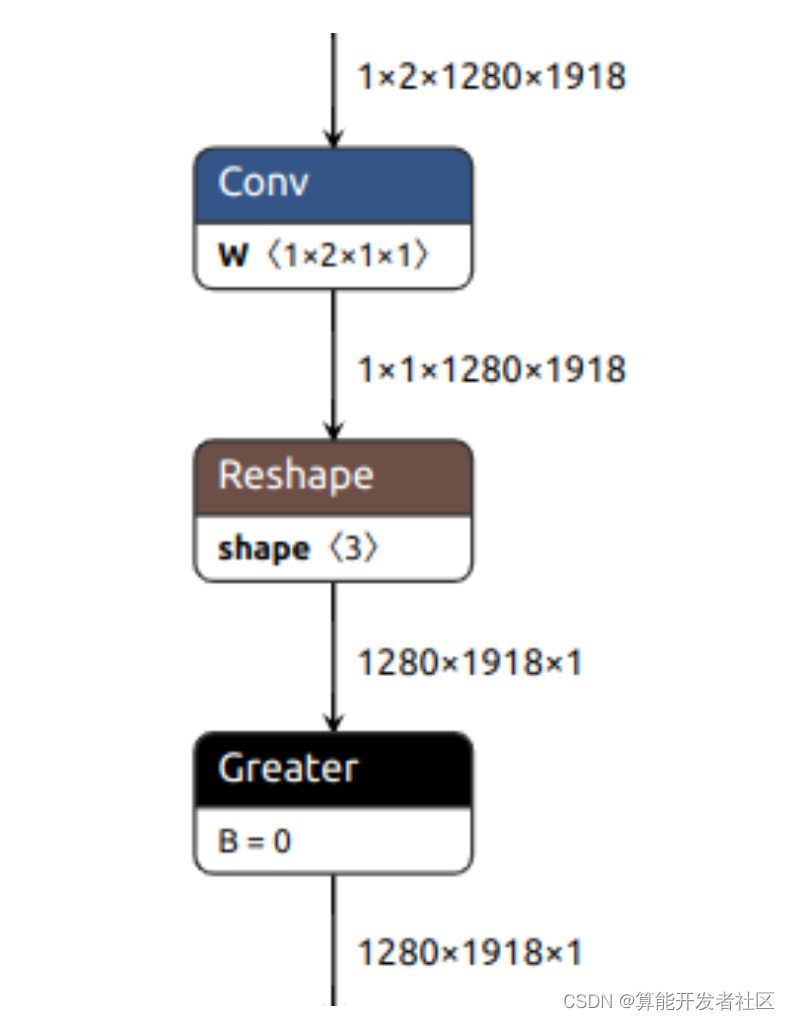
1.3.3导出特征转RGB
out = out.to(torch.uint8) * 255
out = torch.cat([out, out, out], -1)复赛
一、 确定baseline
复赛的比赛说明中以模型运行速度为准,因此初赛的很多工作都用不上了。转而变成了纯 UNET 模型优化。
我使用 UNET -Scale1.0输入1918x1280进行模型转换量化,最终作为 BaseLine ,结果如下:
flops: 3604915801600, runtime: 204.196060ms, ComputationAbility: 17.654188T
195.027445 0.992235 204.196060 1.675526e+09 2023-02-04模型 DICE 分数很高,将该模型预测的结果作为 GT。
二、优化模型
1.经过观察发现模型中下采样16倍导致1918的输入无法整除,造成了额外的 Padding ,所以我尝试输入1920x1280测试模型速度。由于输入图片为1918x1280,如果直接 Resize 会造成失真,我们选择在最下面Padding2个像素,结果如下:
0.992251 199.453278 1.675657e+09 2023-02-06可以看到模型 DICE 分数提升,并且检测速度变快,最终得分200。
2.优化反卷积
同样为了解决下采样16倍产生额外的 Padding 问题,尝试将 Padding 移动到 ConvTranspose 中,查阅 ONNXop 介绍可知 output _ padding 属性可以设置。
0.742231 199.346721 1.675677e+09 2023-02-063.公布第一轮成绩时我发现其他队伍分数很高,模型的 DICE 分数在98-99做有,推理分数30-40左右,最终的得分比我高很多,所以我同样选择降低分辨率。
使用Scale1.0和640x959640x960得到如下结果:
0.776212 42.033154 1.675665e+09 2023-02-06
0.777545 39.177540 1.675695e+09 2023-02-06速度分很好,但是 DICE 分数很低,怀疑是Scale1.0模型导致的,然后使用Scale0.5模型继续测试。
0.990611 41.376142 1.676272e+09 2023-02-13
0.990987 39.177540 1.676293e+09 2023-02-13速度分和精度分都上来了,达到了360分。
4. 继续缩小输入尺寸
为了保证输入宽高比例为3:2同时尽量满足16倍数,我测试了下面几个组合

实验发现当尺寸在560x368附近时,模型尚可保持精度,当尺寸更小的时候精度掉的较多。
5. 改进分割前后处理
比赛最后几天榜单更新,然后为了冲榜继续缩小输入尺寸,最终定为304x208,满足16的倍数和长宽比3:2。
经过本地测评发现精度丢失非常严重,然后开始优化前后处理。
(1) 前处理
由于图片尺寸太小, Resize 方法带来的结果有所不同。

使用 INTER _ CUBICINTER _ LINEARINTER _ NEAREST 得到的结果均类似左图,噪声的面积较大,使用 INTER _ AREA 则如右图,噪声叫小。
(2) 后处理
由于后处理时网络对噪声预测的分数较高使用 ArgMax 后会有一定混淆,因此我使用类似 SoftMax 的操作,对检测数值接近且在一定范围内的预测结果置为背景,代码如下:
bg, qg = out[..., 0], out[..., 1]
diff = bg - qg
flag = diff < 0
mi = np.abs(out).min(axis=2)
new_flag = diff[flag] / mi[flag] < -thres
diff[flag] = -new_flag.astype(np.float32)(3) 去除多余联通域
经过过滤一定范围内的差值,可以减少对噪声的检测。经过多组实验最终确认 thres 为2.2。除此之外,预测的结果存在多余区域,如图:

通过过滤除了最大联通域区域以外的区域可以避免多余区域。
def remove_no_connected_gray(gray):num_labels, labels, stats, centroids =
cv2.connectedComponentsWithStats(gray, connectivity=8)quyuId, pixNums = np.unique(labels, return_counts=True)mask_background = quyuId != 0quyuId, pixNums = quyuId[mask_background], pixNums[mask_background]if quyuId.shape[0] == 1:return np.ones_like(gray)else:maxId = quyuId[pixNums.argmax()]mask = (labels == maxId).astype(np.uint8)return mask(4) 对于边缘不平滑的预测,如图:

使用形态学开运算和高斯滤波可以让边缘平滑,去除突起:
out = cv2.medianBlur(opening, 9)实验多种滤波核大小,3/6/9/11/13发现核较大精度较高,最终选择9达到了较好的分数。
(5) 形态学运算去除其他噪声
经过滤波等操作后的图像仍然存在边缘突出,分割图内部空洞,边缘异常等问题,最终采用形态学运算进行改善。使用腐蚀去除边缘突出,使用膨胀填充图像空洞。

kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (k, k))
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (k, k))
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, 1)同样,滤波核(十字椭圆圆形),滤波核尺寸3/6/9/11/13等通过多组实验确认。
前面有很多超参如 thres 和滤波 kernel 大小形状均是通过本地实验,使用 BaseLine 得到的 GT 计算 dice 分数确定的最优解。最终最后一次提交的结果如下:
391.288683 0.952803 3.991613 1.677598e+09 2023-02-28复赛结果总结
经过几次提交得到的结果可以分析出,在模型 DICE 分数上差距较小,均在95-99分之间,上下浮动不超过5分,但是时间分数上不同尺寸的输入可以带来1-200的差距,因此只能在输入尺寸上下文章。由于前后处理不计算耗时,因此我最终选择304x208输入尺寸,并改进后处理模块实现了本次比赛模型速度最快,总分第4的成绩。
三、遇到的问题总结
1. ONNX转MLIR
1.1在 ONNX 注册了预处理后需要同时改变--mean0,0,0--scale1,1,1- pixel -formatbgr1.2ONNX中的 Resize / ArgMax 在 MLIR 中不支持,更换其他算子1.3ONNX中的 Pad 缺少参数报错,修改 PyTorch 模型1.4不支持UINT8数据格式,这部分生成图片放到 CPU 做。
2. MLIR转bmodel
2.1编译对称量化模型时-- tolerance 设置太高会导致编译失败,降低分数为0.80.42.2编译非对称量化模型时分数很低也会报错,速度提升也很小,放弃了。2.3编译模型时尺寸大的耗时严重,并且推理耗时也很大,最后选择小尺寸。
3. MLIR推理代码 BUG 【已经解决了】
比赛初始阶段提供的 MLIR 推理代码有问题,导致有一次提交没结果,后来官方修改更新的代码正常了。
四、 一些想法和建议
1.希望 model _ transform 工具实现 TPU 支持的常用的数据预处理 OP ,如果归一化和通道转换,作为单独的 OP ,这样就不需要写 CPU 的实现了。
2.希望 model _ transform 在遇到报错的 OP 能给出 OP 名字等信息,方便定位问题,报错能够详细一点。
3.希望 run _ calibration 和 model _ deploy 工具可以充分利用多核 CPU 的优势,在使用上述工具时某些阶段 CPU 利用率很高,某些阶段只有一个核心在用,猜测这部分是 Python 代码受到了 GIL 限制,可以尝试Pybind11改进一下。
4.希望编译后的模型可以把 fusion 和 pass 再反向生成一个 tpuop 的 onnx ,用于可视化模型结构。
5.希望 CPU 模拟 TPU 推理时也可以充分利用多核,大尺寸图像推理耗时太严重了,几个小时起步。
6.希望测试 bmodel 得到的 profile 文件可以通过网页或者其他形式可视化出结果,目前分析只能一行行的看。
7.希望未来复赛能像初赛一样可以自定义很多 trick ,复赛太单调了,并且用处也不太大。
相关文章:
基于TPU-MLIR实现UNet模型部署-决赛答辩02
队伍:AP0200023 目录 初赛 一、 模型导出优化 1.1 直接倒出原始模型并转换 1.2 导出模型前处理 1.2.1 导出Resize 1.2.2 导出归一化 1.3导出模型后处理 1.3.1导出 Resize 与 1.3.2导出 ArgMaxout 1.3.3导出特征转RGB 复赛 一、 确定baseline 二、优化模…...

Maven高级-分模块开发依赖管理
Maven高级-分模块开发&依赖管理1,分模块开发1.1 分模块开发设计1.2 分模块开发实现1.2.1 环境准备1.2.2 抽取domain层步骤1:创建新模块步骤2:项目中创建domain包步骤3:删除原项目中的domain包步骤4:建立依赖关系步骤5:编译maven_02_ssm项目步骤6:将项目安装本地…...
《安富莱嵌入式周报》第308期:开源带软硬件安全认证的PLC设计,开源功率计,可靠PID实现,PR2机器人设计文件全开源,智能手表设计WASP-OS
周报汇总地址:嵌入式周报 - uCOS & uCGUI & emWin & embOS & TouchGFX & ThreadX - 硬汉嵌入式论坛 - Powered by Discuz! 视频版: https://www.bilibili.com/video/BV1F24y157QE 《安富莱嵌入式周报》第308期:开源带软…...
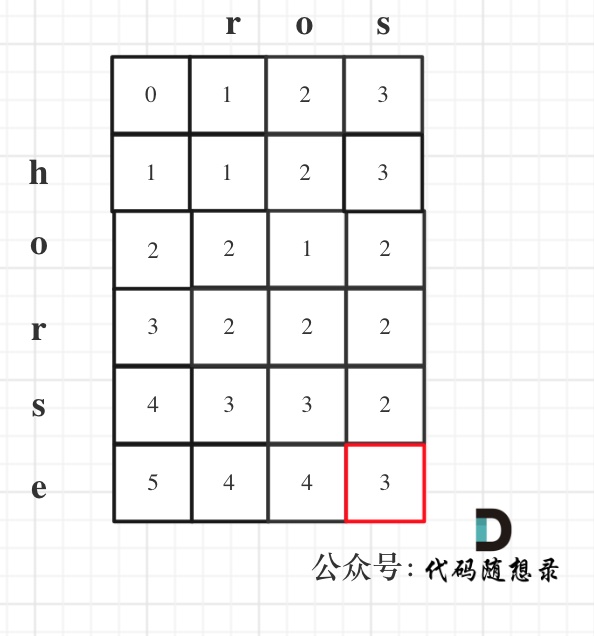
代码随想录算法训练营第五十六天 | 583. 两个字符串的删除操作、72. 编辑距离、编辑距离总结
583. 两个字符串的删除操作 动规五部曲 1、确定dp数组(dp table)以及下标的含义 dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。 2、确定递推…...
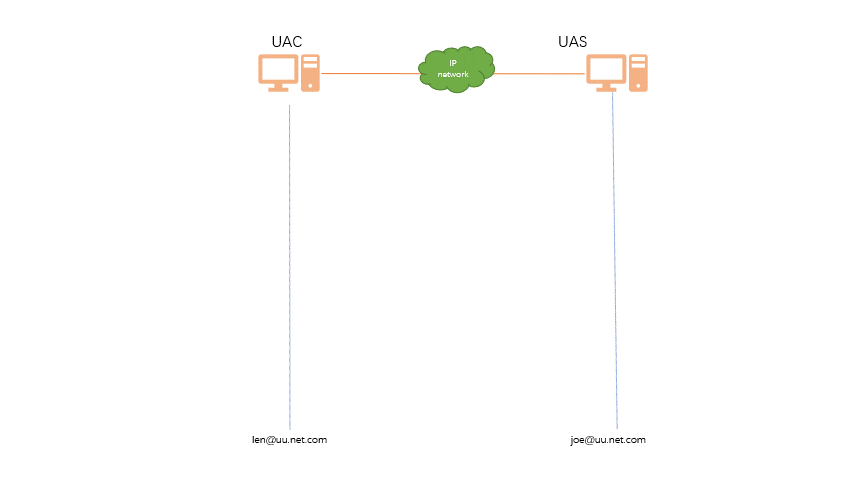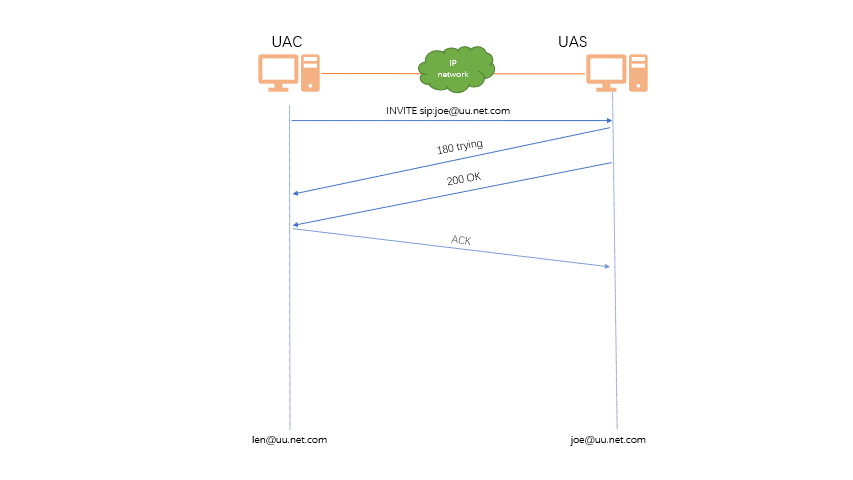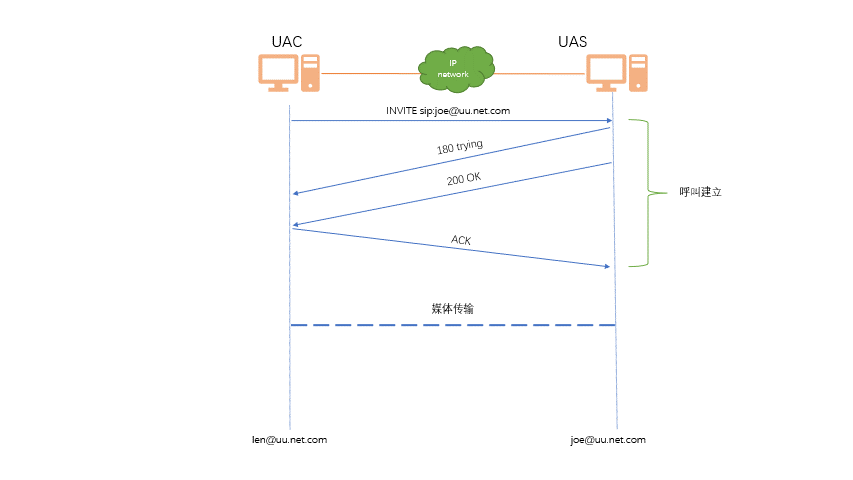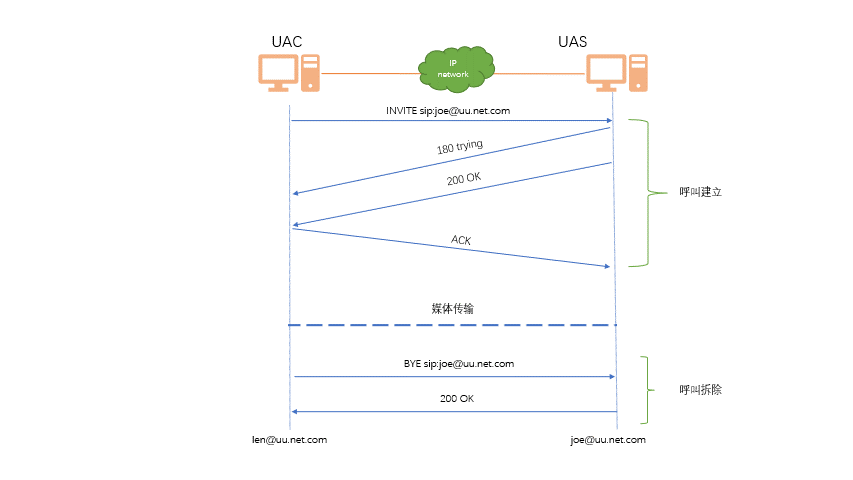
Sip协议
简介 SIP(Session Initiation Protocol,会话初始协议)是一个用于建立、更改和终止多媒体会话的应用 层控制协议,其中的会话可以是 IP 电话、多媒体会话或多媒体会议。SIP 是 IETF 多媒体数据和控 制体系结构的核心协议࿰…...

RandomAccessFile类 断点续传
文章目录学习链接RandomAccessFile构造方法实现的接口DataOutputDataInputAutoCloseable重要的方法多线程读写同一个文件(多线程复制文件)代码1代码2断点续传FileUtils学习链接 RandomAccessFile详解 Java IO——RandomAccessFile类详解 java多线程-断点…...

SpringCloud微服务技术栈的注册中心Eureka
文章目录SpringCloud微服务技术栈的注册中心Eureka简介Eureka特点操作步骤环境准备创建Eureka Server注册服务提供方调用服务消费方总结SpringCloud微服务技术栈的注册中心Eureka 简介 在微服务架构中,服务的数量庞大,而且每个服务可能会有多个实例。此…...

Unity最新热更新框架 hybridclr_addressable
GitHub:YMoonRiver/hybridclr_addressable: 开箱即用的商业游戏框架,集成了主流的开发工具。将主流的GameFramework修改,支持Addressable和AssetBundle,已完善打包工具和流程。 (github.com) # 新增GameFramework Addressables 开箱即用 # 新…...
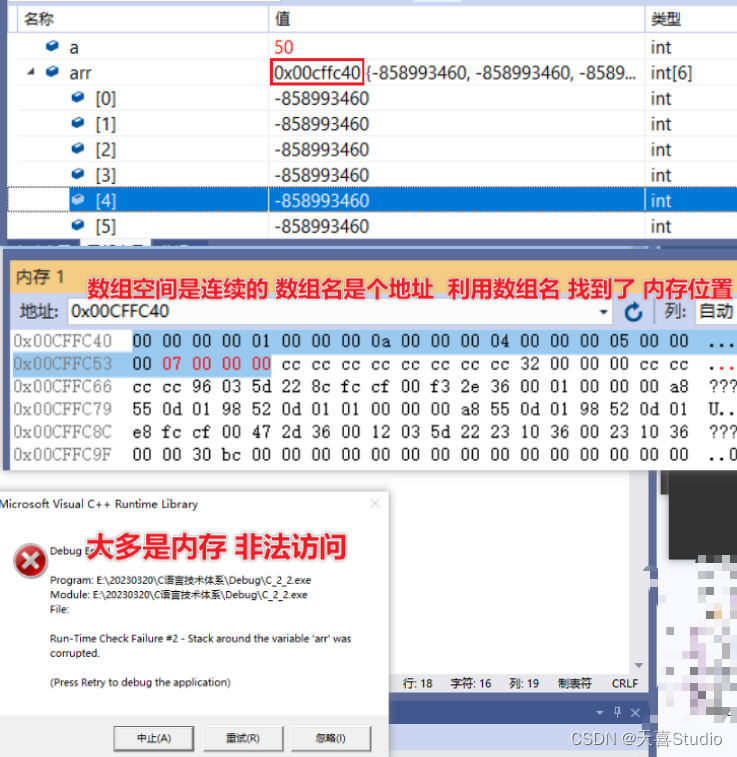
【c语言】一维数组***特性、存储原理
创作不易,本篇文章如果帮助到了你,还请点赞支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ…...
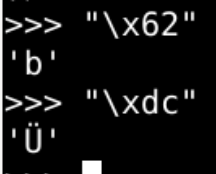
[oeasy]python0133_[趣味拓展]好玩的unicode字符_另类字符_上下颠倒英文字符
另类字符 回忆上次内容 上次再次输出了大红心♥ 找到了红心对应的编码黑红梅方都对应有编码 原来的编码叫做 ascii️ \u这种新的编码方式叫unicode包括了 中日韩字符集等 各书写系统的字符集 除了这些常规字符之外 还有什么好玩的东西呢? 颠倒字符 这个网站可以…...

找凶手,定名次,字符串旋转,杨氏矩阵
1.找凶手问题: //题目名称: //猜凶手 //题目内容: //日本某地发生了一件谋杀案,警察通过排查确定凶手必为4个嫌疑犯的一个。 //以下为4个嫌疑犯的供词: //A说:不是我 //B说:是C //C说ÿ…...

Python 进阶指南(编程轻松进阶):十四、实践项目
原文:http://inventwithpython.com/beyond/chapter14.html 到目前为止,这本书已经教会了你编写可读的 Python 风格代码的技巧。让我们通过查看两个命令行游戏的源代码来实践这些技术:汉诺塔和四人一排。 这些项目很短,并且基于文…...

Redis的五种数据类型及应用场景
Redis是一个开源的key-value数据库。 五种数据类型 String,List, Set,SortedSet,Hash List类型可以存储多个String。 Set类型可以存储不同的String。 SortedSet可以存储String的排序。 Hash可以存储多个key-value对。 String …...

c++List的详细介绍
cList详细使用 write in front 作者: 不进大厂不改名 专栏: c 作者简介:大一学生 希望能向其他大佬和同学学习! 本篇博客简介:本文主要讲述了一种新容器list的使用方法,相信你在学了后,能够加深…...
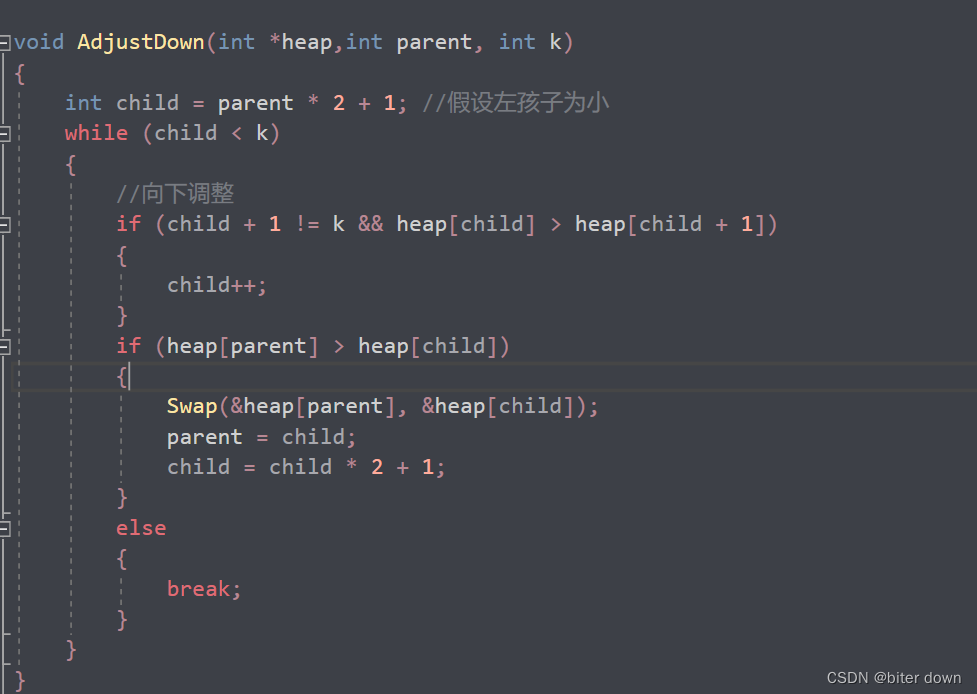
Heap堆的升序排序
在heap堆中,大根堆是一种特殊的堆,它满足下列性质:对于任意一个非叶子节点i,其左右子节点的值均小于等于它本身的值。 在大根堆中,堆顶元素永远是值最大的元素,所以将堆顶元素不断取出来,就相当…...
小程序开发收费价目表
小程序作为一种新兴应用形式,正在逐渐成为企业和个人推广、运营的重要手段。然而,小程序开发的价格因项目规模和复杂程度差异较大,令不少人望而却步。本文将从小程序开发的相关因素入手,探讨小程序开发的价格范围和算法。 一、小…...

Dubbo服务暴露步骤详解
文章目录Dubbo服务暴露步骤详解背景介绍理论知识讲解什么是服务暴露?Dubbo 服务暴露的基本原理操作步骤具体实现环境准备实现服务接口实现服务提供者配置 Dubbo 服务提供者启动服务提供者实现服务消费者配置 Dubbo 服务消费者测试总结Dubbo服务暴露步骤详解 背景介…...

第十四届蓝桥杯编程题部分代码题解
C. 冶炼金属 最大值就是取 a/ba / ba/b 的最小值,最小值就是二分找到满足 mid∗(bi1)≥aimid * (b_i 1) ≥ a_imid∗(bi1)≥ai 的最小值 #include<bits/stdc.h> #define int long long #define x first #define y second using namespace std;void sol…...
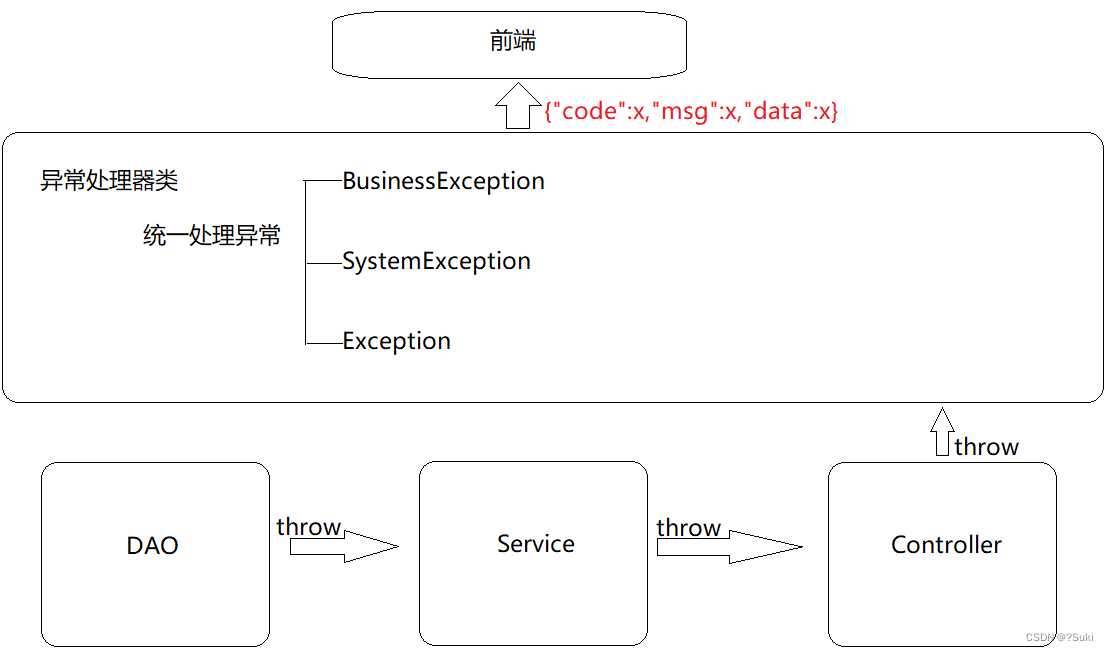
统一结果封装异常处理
统一结果封装&异常处理2,统一结果封装2.1 表现层与前端数据传输协议定义2.2 表现层与前端数据传输协议实现2.2.1 环境准备2.2.2 结果封装步骤1:创建Result类步骤2:定义返回码Code类步骤3:修改Controller类的返回值步骤4:启动服务测试3,统一异常处理3…...

数字藏品平台的发展趋势是什么?
1、数字藏品平台具体内容生产模式将在PGC(专业生产制造具体内容)方式向PUGC(技术专业用户生产内容)方式变化。 目前,中国热门的数字藏品平台都在PGC模式中持续发展的,而国外流行NFT平台则比较多选用UGC&am…...
)
What Are You Talking About(HDU- P1075)
伊格纳修斯真是走了狗屎运,昨天居然遇到了火星人!可惜他完全听不懂火星人的语言。临走时,火星人给了他一本火星历史书和一本词典。现在伊格纳修斯想把这本历史书翻译成英语,你能帮帮他吗?输入本题只有一组测试数据&…...

峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验
峡谷焕新:用R3nzSkin解锁英雄联盟个性化游戏体验 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 在英雄联盟的召唤师峡谷中,每一…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...
)
手把手教你用GDB/LLDB调试器观察寄存器状态(附实战案例)
深入掌握GDB/LLDB寄存器调试:从原理到实战 在软件开发的世界里,调试器就像外科医生的手术刀,而寄存器则是CPU的脉搏。当你面对一个段错误(Segmentation Fault)或者难以捉摸的内存越界问题时,能够直接观察CP…...

Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器?
Scroll Reverser:为什么你的Mac需要这款滚动方向控制神器? 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 作为一名设计师,李华每天在MacBook…...
)
告别CodeBlocks!在VScode里用CMake+MinGW搞定LVGL模拟器(附SDL2配置避坑指南)
从CodeBlocks到VScode:打造LVGL模拟器的现代化开发体验 在嵌入式GUI开发领域,LVGL以其轻量级和丰富的功能组件赢得了众多开发者的青睐。然而,官方推荐的CodeBlocks开发环境却让不少习惯了现代IDE的开发者感到不适——界面陈旧、插件生态有限、…...

Solopreneur 7×24 Agent 工作流:从 ARIS 论文里抠出 5 个可落地步骤
论文:ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration arXiv:2605.03042(2026.5.4 上海交大) 适合人群:独立开发者 / Solopreneur / 想搭"睡眠工作流"的人 一、先讲一个我自己的故事 我做独立开…...

insert_order 报单类型怎么选:限价、FAK 与 FOK 期货场景
前言 在天勤量化里,insert_order 是程序化下单的核心接口。报单类型选错,常见后果是撤单狂增、部分成交后敞口裸露,或回测里假设能成交而实盘挂在板上。下面按期货里常用的限价、FAK、FOK 等说明适用场景,并给出最小调用片段。 …...

从医院PACS到你的Python脚本:手把手教你用pydicom库读写和修改DICOM文件
从医院PACS到Python脚本:pydicom实战医学影像处理指南 医学影像数据正以每年30%的速度增长,而DICOM作为医疗影像存储与传输的国际标准,承载着CT、MRI等设备产生的海量数据。在临床研究、AI模型训练和医疗信息化建设中,开发者经常需…...

利用Taotoken的Token Plan套餐为团队项目节省大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的Token Plan套餐为团队项目节省大模型调用成本 对于中小型技术团队而言,在项目开发中引入大模型能力已成…...