Spark Shuffle介绍
文章目录
- 1. 简介
- 2. Hash Shuffle和Sort Shuffle
- 2.1 Hash Shuffle
- 2.1.1 未经优化的hashShuffleManager
- 2.1.2 经优化的hashShuffleManager
- 2.1.3 优化前后磁盘文件数对比
- 2.2 Srot Shuffle Manager
- 3. Shuffle配置选项
1. 简介
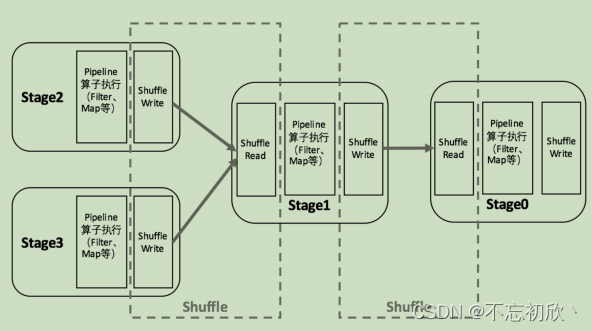
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
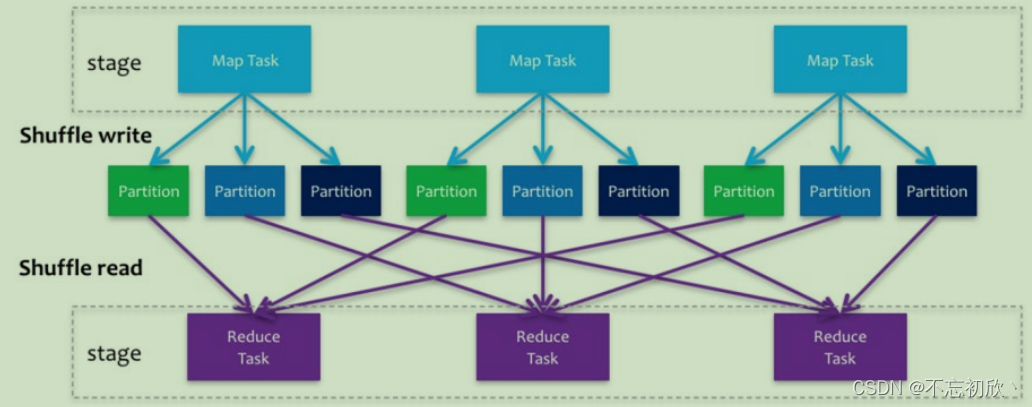
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。
执行Shuffle的主体是Stage中的并发任务,这些任务分ShuffleMapTask和ResultTask两种,ShuffleMapTask要进行Shuffle,ResultTask负责返回计算结果,一个Job中只有最后的Stage采用ResultTask,其他的均为ShuffleMapTask。如果要按照map端和reduce端来分析的话,ShuffleMapTask可以即是map端任务,又是reduce端任务,因为Spark中的Shuffle是可以串行的;ResultTask则只能充当reduce端任务的角色。
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考Hadoop MapReduce的实现开始引入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到的2.0版本,Hash Shuffle已被删除,所有
Shuffle方式全部统一到Sort Shuffle一个实现中。
2. Hash Shuffle和Sort Shuffle
在Spark的中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。ShuffleManager随着Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort
Shuffle两种。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉
取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
2.1 Hash Shuffle
Shuffle阶段划分:
shuffle write:mapper阶段,上一个stage得到最后的结果写出shuffle read:reduce阶段,下一个stage拉取上一个stage进行合并
2.1.1 未经优化的hashShuffleManager
HashShuffle是根据task的计算结果的key值的hashcode%ReduceTask来决定放入哪一个区分,这样保证相同的数据一定放入一个分区。
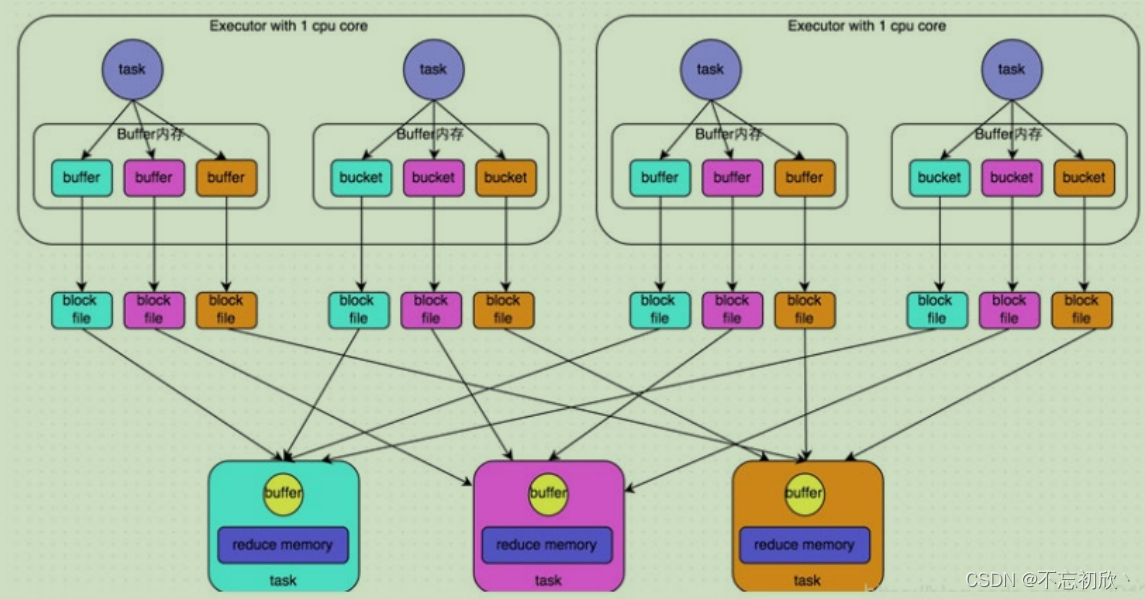
上图是Hash Shuffle的过程,根据下游的task决定生成几个文件,先生成缓冲区文件在写入磁盘文件,再将block文件进行合并。未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
2.1.2 经优化的hashShuffleManager
在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,每一个Group磁盘文件的数量与下游stage的task数量是相同的。
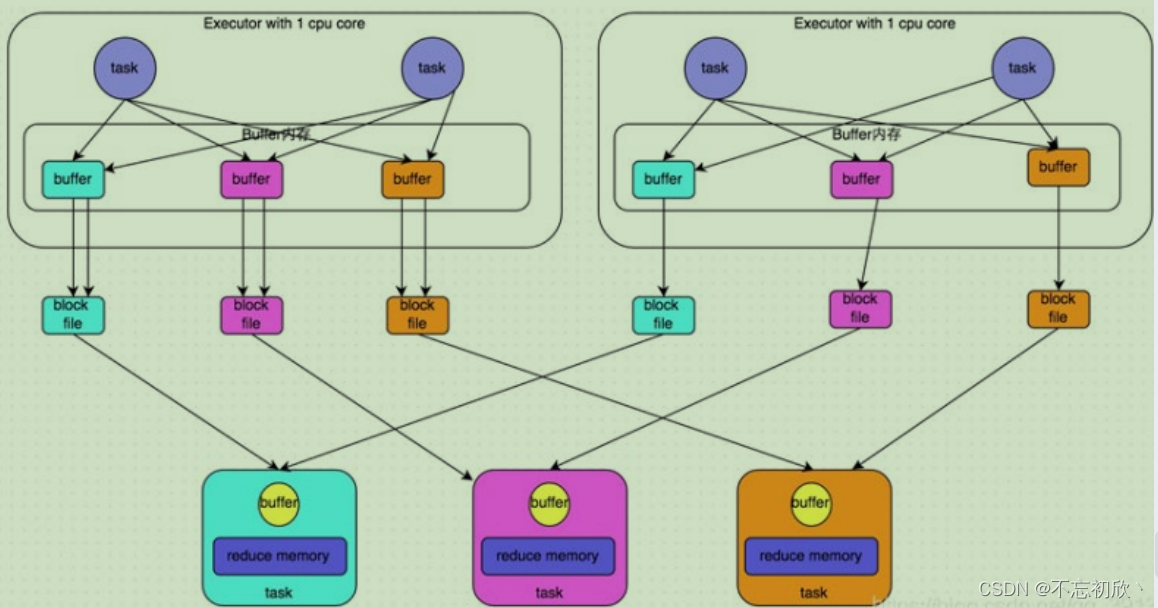
2.1.3 优化前后磁盘文件数对比
未经优化:
上游的task数量:m
下游的task数量:n
上游的executor数量:k (m>=k)
总共的磁盘文件:m*n
优化之后的:
上游的task数量:m
下游的task数量:n
上游的executor数量:k (m>=k)
总共的磁盘文件:k*n
2.2 Srot Shuffle Manager
SortShuffle对比HashShuffle可以减少很多的磁盘文件,以节省网络IO的开销。
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle write task的数量小于等spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
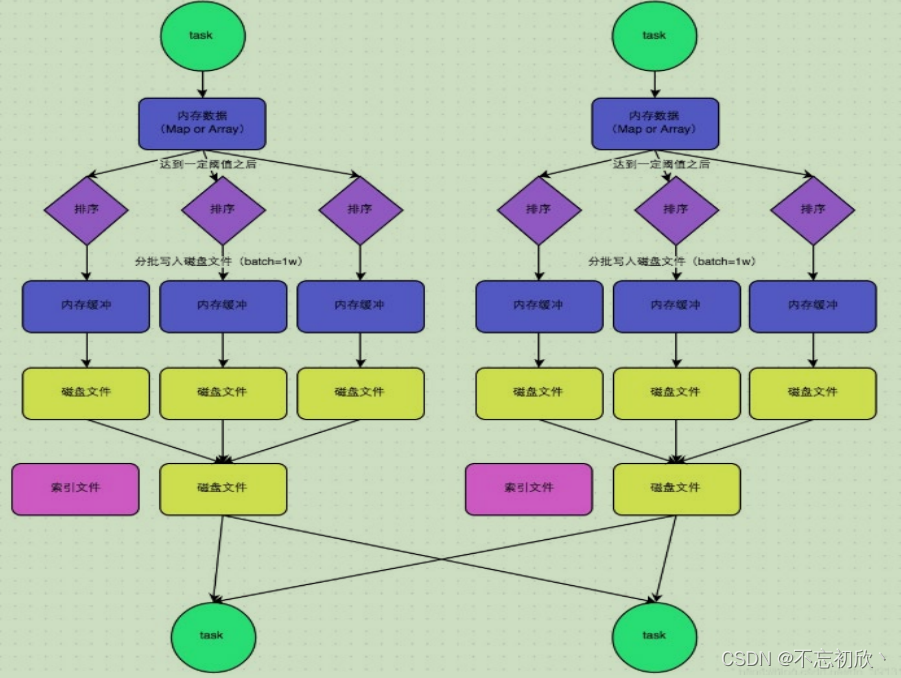
(1)该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。
(2)接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
(3)排序
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。
(4)溢写
排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。
(5)merge
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并成1个磁盘文件,这就是merge过程。由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
Sort Shuffle bypass运行机制
运行条件:
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
- 不是map combine聚合的shuffle算子(比如reduceByKey有map combie)。
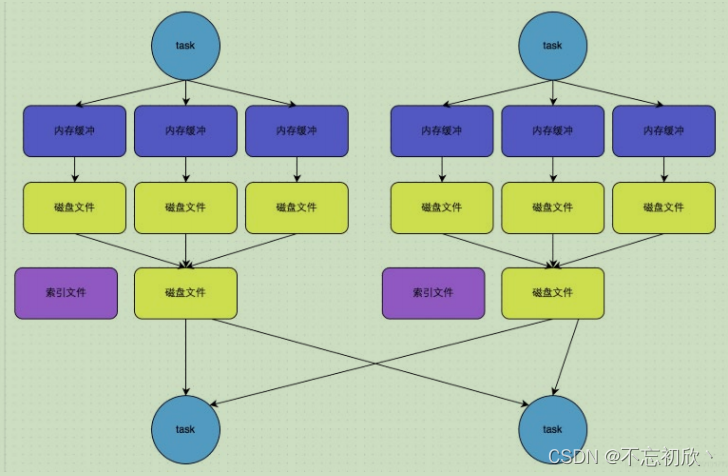
- 此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
- 该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
bypass运行机制和SortShuffleManager运行机制区别:
- 磁盘写机制不同;
- 不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,
也就节省掉了这部分的性能开销。
总结:
- SortShuffle也分为普通机制和bypass机制
- 普通机制在内存数据结构(默认为5M)完成排序,会产生2M个磁盘小文件。
- 而当shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。或者算子不是聚合类的shuffle算子(比如reduceByKey)的时候会触发SortShuffle的bypass机制,SortShuffle的bypass机制不会进行排序,极大的提高了其性能。
SortShuffle主要是对磁盘文件进行合并来进行文件数量的减少,同时两类Shuffle都需要经过内存缓冲区溢写磁盘的场景。所以可以得知,尽管Spark是内存迭代计算框架,但是内存迭代主要在窄依赖中。 在宽依赖(Shuffle)中磁盘交互还是一个无可避免的情况。所以,我们要尽量减少Shuffle的出现,不要进行无意义的Shuffle计算。
3. Shuffle配置选项
spark 的shuffle调优:主要是调整缓冲的大小,拉取次数重试重试次数与等待时间,内存比例分配,是否进行排序操作等等
Shuffle阶段划分:
shuffle write:mapper阶段,上一个stage得到最后的结果写出shuffle read:reduce阶段,下一个stage拉取上一个stage进行合并
spark.shuffle.file.buffer
- 参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
- 参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。(默认48M)
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries and spark.shuffle.io.retryWait
spark.shuffle.io.maxRetries:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)spark.shuffle.io.retryWait:该参数代表了每次重试拉取数据的等待间隔。(默认为5s)- 调优建议:一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction
- 参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作内存比例。
spark.shuffle.manager
- 参数说明:该参数用于设置shufflemanager的类型(默认为sort)。Spark1.5x以后有三个可选项:Hash:spark1.x版本的默认值,HashShuffleManager;Sort:spark2.x版本的默认值,普通机制,当shuffle read task 的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数,自动开启bypass 机制。
spark.shuffle.sort.bypassMergeThreshold
- 参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作。
- 调优建议:当使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
相关文章:
Spark Shuffle介绍
文章目录1. 简介2. Hash Shuffle和Sort Shuffle2.1 Hash Shuffle2.1.1 未经优化的hashShuffleManager2.1.2 经优化的hashShuffleManager2.1.3 优化前后磁盘文件数对比2.2 Srot Shuffle Manager3. Shuffle配置选项1. 简介 Spark在DAG调度阶段会将一个Job划分为多个Stage&#x…...

【数据库原理 • 三】关系数据库标准语言SQL
前言 数据库技术是计算机科学技术中发展最快,应用最广的技术之一,它是专门研究如何科学的组织和存储数据,如何高效地获取和处理数据的技术。它已成为各行各业存储数据、管理信息、共享资源和决策支持的最先进,最常用的技术。 当前…...

ThreeJS-战争导弹飞行演示(三十四)
关键代码: function animate() { requestAnimationFrame(animate); // 使用渲染器渲染相机看这个场景的内容渲染出来 renderer.render(scene, camera); // controls.update(); // 获取delay时间 const delay clock.getDelta(); // 获取总共耗时 const time clock.…...
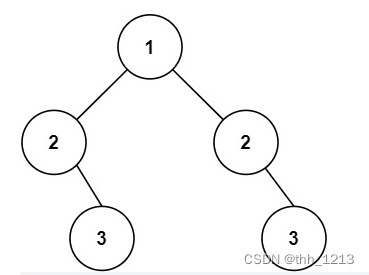
代码随想录_226翻转二叉树、101对称二叉树
leetcode 226. 翻转二叉树 226. 翻转二叉树 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]示例 2: 输入:r…...

Docker 容器日志查看
1、容器日志查看命令 Usage: docker logs [OPTIONS] CONTAINERFetch the logs of a containerOptions:--details Show extra details provided to logs-f, --follow Follow log output--since string Show logs since timestamp (e.g. 2013-01-02T13:23:37Z…...
【Maven】1—Maven概述下载配置
⭐⭐⭐⭐⭐⭐ Github主页👉https://github.com/A-BigTree 笔记链接👉https://github.com/A-BigTree/Code_Learning ⭐⭐⭐⭐⭐⭐ 如果可以,麻烦各位看官顺手点个star~😊 如果文章对你有所帮助,可以点赞👍…...
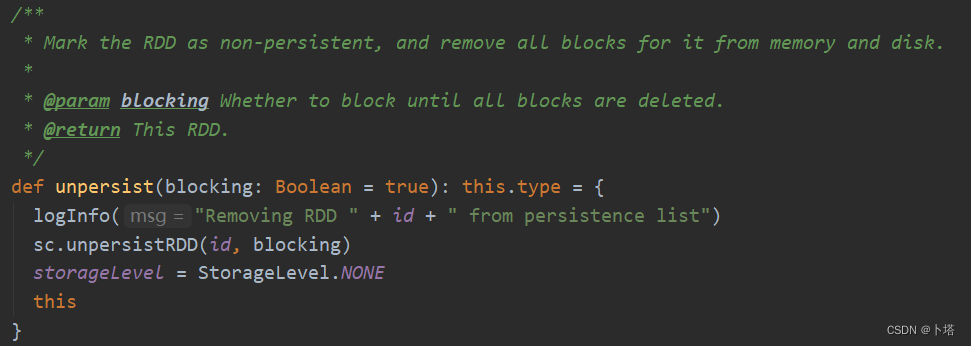
【Spark】RDD缓存机制
1. RDD缓存机制是什么? 把RDD的数据缓存起来,其他job可以从缓存中获取RDD数据而无需重复加工。 2. 如何对RDD进行缓存? 有两种方式,分别调用RDD的两个方法:persist 或 cache。 注意:调用这两个方法后并不…...

学成在线:第六天(p94-p102)
1、面试:为什么要用 Freemarker 静态化?如何做的? 页面静态化是指使用模板引擎技术将一个动态网页生成 html 静态页面。 满足下边的条件可以考虑使用静态化: 1、该页面被访问频率高,比如:商品信息展示、专家介绍页面等…...

读懂AUTOSAR:PduR模块--使用FIFO
简介: 现在的汽车越来越智能化和复杂化,这得益于汽车软件和电子控制系统的发展。为了帮助汽车制造商和供应商更好地开发和管理汽车软件,全球性的汽车软件开发标准——AUTOSAR(AUTomotive Open System ARchitecture)应…...
对象的比较(数据结构系列12)
目录 前言: 1.PriorityQueue 1.1PriorityQueue的特性 1.2PriorityQueue的构造器 1.3大根堆的创建 1.4PriorityQueue中函数的说明 2.java中对象的比较 2.1基本类型的比较 2.2对象的比较 2.2.1覆写基类的equals 2.2.2基于Comparable接口类的比较 2.2.3基于…...

31.下一个排列
1. 题目 整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。 例如,arr [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。 整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地&…...

ToBeWritten之理解嵌入式Web HTTP协议
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

顶级程序员的成长之路1
本文关注的问题是程序员的水平究竟应该按照什么样的不同层级而逐渐提高?或者说,在学习编程的过程中,每一个阶段究竟应当设定什么样的目标才比较合理?本文的内容主要借鉴了周伟明先生的专栏文章《程序员的十层楼》[86]。注意本文讨…...

第三代api自动化测试框架使用教程(pytest+allure+sql+yaml)
使用教程一、配置1、环境配置2、框架配置3、启动入口二、用例编写1、用例模板2、参数依赖写法2、函数(方法插件)写法3、接口上传文件和表单参数4、接口上传json参数5、接口无数据填写6、code断言7、body断言7、json断言8、sql断言9、完整断言写法&#x…...

Qt——实现一个获取本机网络信息的界面
效果展现 代码实现 networkinformation.h: #ifndef NETWORKINFORMATION_H #define NETWORKINFORMATION_H#include <QMainWindow> #include <QLabel> #include <QLineEdit> #include <QPushButton>class NetworkInformation : public QMai…...
全面深入了解接口自动化,看完还不会我报地址
一、自动化分类 (1)接口自动化 python/javarequestsunittest框架来实现 python/javaRF(RobotFramework)框架来实现——对于编程要求不高 (2)Web UI功能自动化 python/javaseleniumunittestddtPO框架来实…...

Python 小型项目大全 61~65
六十一、ROT13 密码 原文:http://inventwithpython.com/bigbookpython/project61.html ROT13 密码是最简单的加密算法之一,代表“旋转 13 个空格”密码将字母A到Z表示为数字 0 到 25,加密后的字母距离明文字母 13 个空格: A变成N&…...
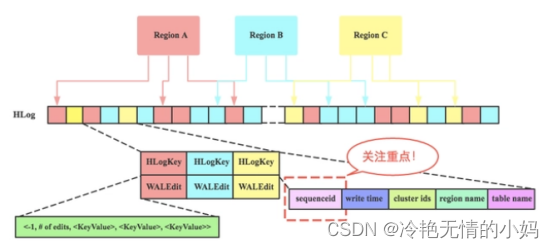
Hlog
Hlog 简介 Hlog是Hbase实现WAL(Write ahead log )方式产生的日志信息 , 内部是一个简单的顺序日志。每个RegionServer对应1个Hlog(备注:1.X版本的可以开启MultiWAL功能,允许对应多个Hlog),所有对于该RegionServer的写入都会被记录到Hlog中。H…...

学编程应该选择什么操作系统?
今天来聊一个老生常谈的问题,学编程时到底选择什么操作系统?Mac、Windows,还是别的什么。。 作为一个每种操作系统都用过很多年的程序员,我会结合我自己的经历来给大家一些参考和建议。 接下来先分别聊聊每种操作系统的优点和不…...
Oracle基础部分二(伪列/表、单个函数、空值处理、行列转换、分析函数、集合运算)
Oracle基础部分二(伪列/表、单个函数、空值处理、行列转换、分析函数、集合运算)1 伪列、伪表1.1 伪列1.2 伪表2 单个函数2.1 常用字符串函数2.1.1 length() 询指定字符的长度2.1.2 substr() 用于截取字符串2.1.3 concat() 用于字符串拼接2.2 常用数值函…...

原神帧率解锁终极指南:免费突破60FPS限制的完整教程
原神帧率解锁终极指南:免费突破60FPS限制的完整教程 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 原神帧率解锁工具(genshin-fps-unlock)是一款开源…...

S32K324双核M7实战:如何利用192KB TCM提升关键代码性能
S32K324双核M7实战:如何利用192KB TCM提升关键代码性能 在嵌入式系统开发中,实时性往往是决定产品成败的关键因素。当您面对电机控制、信号处理等高实时性需求场景时,处理器与内存之间的数据通路可能成为性能瓶颈的隐形杀手。S32K324芯片内置…...

TegraRcmGUI:Switch RCM注入工具新手完全指南
TegraRcmGUI:Switch RCM注入工具新手完全指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switch设计的图形化…...

两个日期到底差几天?
两个日期到底差几天? 网上搜「两个日期相差几天」,底下问题五花八门:合同从签字日到到期日算不算头尾、请假单跨了周末怎么填、租房从 3 月 1 住到 6 月 30 一共多少天、项目里程碑隔了几年 2 月会不会踩闰年……本质都是一件事:…...

WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题
WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经遇到过这样的场景:…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

AI Agent Harness Engineering 产品经理指南:如何定义智能体的“人设”与能力边界?
AI Agent Harness Engineering 产品经理指南:如何定义智能体的「人设」与能力边界 关键词:AI Agent、智能体管控工程(Harness Engineering)、产品经理、人设对齐、能力边界、智能体治理、生成式AI落地 摘要 随着生成式AI技术的成熟,AI Agent已经从概念验证阶段进入大规…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...