MySQL运维10-MySQL数据的导入导出
文章目录
- 0、概述
- 1、mysqldump导出数据+mysql导入数据
- 1.1、使用mysqldump导出数据
- 1.1.1、使用--tables导出指定表
- 1.1.2、使用--tab选项将表定义文件和数据文件分开导出
- 1.1.3、使用--fields-terminated-by选项定义数据分隔符
- 1.1.4、使用--databases选项导出整个库或多个库
- 1.1.5、使用--all-databases选项导出所有数据库
- 1.1.6、使用--xml选项实现导出格式为XML
- 1.1.7、使用--ignore-table选项实现导出时忽略指定表
- 1.1.8、使用mysql客户端配合mysqldump实现通配符匹配表名的导出
- 1.1.9、使用mysqldump导出数据的优化方式
- 1.2、使用mysql导入数据
- 1.2.1、基本导入方法
- 1.2.2、乱码问题
- 2、SELECT INTO OUTFILE导出数据+LOAD DATA或mysqlimport导入数据
- 2.1、使用SELECT INTO OUTFILE导出数据
- 2.2、使用LOAD DATA导入数据
- 2.2.1、使用LOAD DATA导入数据的基本导出方法
- 2.2.2、导出导入csv格式文件
- 2.2.3、SELECT INTO OUTFILE导出+LOAD DATA导入方案的优势
- 2.2.4、LOAD DATA的优化
- 2.3、使用mysqlimport导入数据
- 3、使用mysql程序的批处理模式导出数据
- 4、使用Linux的split切割文件,加速导入数据
- 5、总结
0、概述
MySQL数据的导入导出方案通常是配套的,例如:
方案一:使用mysqldump导出数据,再使用mysql客户端导入数据
方案二:使用SELECT INTO OUTFILE命令导出数据,再使用LOAD DATA或mysqlimport导入数据
方案三:使用mysql程序的批处理模式导出数据,再使用LOAD DATA或mysqlimport导入数据
1、mysqldump导出数据+mysql导入数据
1.1、使用mysqldump导出数据
1.1.1、使用–tables导出指定表
# 语法
mysqldump db_name --tables tb1_name tb2_name > filemname.sql
# 实例
mysqldump mytest --tables t1 t2 > t1_t2.sql
1.1.2、使用–tab选项将表定义文件和数据文件分开导出
# 语法
mysqldump db_name --tab=dir
# 实例
mysqldump mytest1 --tab=/home/mysql/__test

1.1.3、使用–fields-terminated-by选项定义数据分隔符
以下导出时,数据值以逗号分隔
mysqldump mytest1 --tab=/home/mysql/__test --fields-terminated-by=','
1.1.4、使用–databases选项导出整个库或多个库
参数说明如下:
- –complete-insert:导出的dump文件里,每条INSERT语句都包含列名。
- –force:即使出现错误,也要继续执行导出操作,会打印出错误。
- –insert-ignore:生成的INSERT语句是INSERT IGNORE的形式,如果导入此文件,即使出错了也仍然可以继续导入数据(当作警告)。
- –databases:类似–tables,后面可以跟多个值,即多个数据库名
- –compatible=name:导出的文件和其他数据库更兼容(但不确保),name的值可以是ANSI、MYSQL323、MYSQL40、POSTGRESQL、ORACLE、MSSQL、DB2、MAXDB、NO_KEY_OPTIONS、NO_TABLE_OPTIONS或NO_FIELD_OPTIONS。
mysqldump --complete-insert --force --add-drop-database --insert-ignore --hex-blob --databases mytest > mytest_db.sql
1.1.5、使用–all-databases选项导出所有数据库
mysqldump --all-databases --add-drop-database > db.sql
1.1.6、使用–xml选项实现导出格式为XML
mysqldump --xml mytest1 > /tmp/mytest1.xml
1.1.7、使用–ignore-table选项实现导出时忽略指定表
导出时可以选择忽略哪些表,即不导出哪些表,只需加上参数–ignore-table=db_name.tbl_name1、–ignore-table=db_name.tbl_name2。
mysqldump --databases=mytest,mytest1 --ignore-table=mytest.tb1,mytest1.tb2
1.1.8、使用mysql客户端配合mysqldump实现通配符匹配表名的导出
mysqldump不支持直接利用通配符导出多个表,但可以先用SELECT加通配符查询要导出的多张表的表名,将表名写到文件中,然后再用mysqldump读出表名再导出这些表。
# 1. 获得表名,写入文件
mysql -N information_schema -e "select table_name from tables where table_name like 'prefix_%' " > tbs.txt
# 2. 读取包含表名的文件,导出表
mysqldump db 'cat tbs.txt' > dump.sql
1.1.9、使用mysqldump导出数据的优化方式
- 选择MySQL服务器的I/O活动低的时候导出数据。
- I/O分离(数据盘和备份盘I/O分离)。
- 输出到管道压缩(gzip)。
- –quick跳过内存缓冲(–opt默认启用)。
- 从数据保留策略上想办法,把不需要修改的大量数据放到历史表中,而不是每次都备份。
1.2、使用mysql导入数据
1.2.1、基本导入方法
- mysqldump导出的SQL转储文件,可以用如下的形式将数据导入到数据库中:
mysql db_name < db_name.sql
1.2.2、乱码问题
- 字符集问题:转储文件(dump文件)里面一般指定了set names utf8,所以我们在导入的时候不再需要指定特殊的字符集。例外的情况是,有一些特殊的场合,SQL文件是以其他的字符集导出的,这个时候导入要注意保持文件的字符集、客户端字符集和连接的字符集的一致性。–default-character-set的意思是,客户端和连接都默认使用charset_name字符集。
# 语法
mysql --default-character-set=charset_name database_name < import_table.sql
# 示例
mysql --default-character-set=gbk < import_table.sql
- 如果mysql客户端输出的数据是乱码,那么请检查下客户端、连接的字符集配置。例如,我们使用SSH工具securecrt登录主机,然后使用mysql命令行工具连接MySQL服务器,mysql连接的默认配置可能是latin1,那么此时显示utf8的数据将会是乱码。这种情况下,可以在客户端运行set names utf8,并确认securecrt的字符编码是UTF-8,这样就可以正常显示utf8字符集的数据了。
2、SELECT INTO OUTFILE导出数据+LOAD DATA或mysqlimport导入数据
2.1、使用SELECT INTO OUTFILE导出数据
- 如果想要进行SQL级别的表备份,可以使用SELECT INTO OUTFILE命令语句。对于SELECT INTO OUTFILE,输出的文件不能先于输出存在。
SELECT * INTO OUTFILE '/tmp/testfile.txt' FROM t1;
SELECT * INTO OUTFILE '/tmp/t1.txt' FIELDS TERMINATED BY ':' OPTIONALLY ENCLOSED BY '+' ESCAPED BY '!' FROM t1;
2.2、使用LOAD DATA导入数据
2.2.1、使用LOAD DATA导入数据的基本导出方法
- 一般来说,只要导出导入操作中使用的选项完全一致,用SELECT…INTO OUTFILE命令导出的文本文件就可以用LOAD DATA命令导入到数据表里去,不会发生任何变化。
- SELECT…INTO OUTFILE可以筛选记录,导出表数据到一个文件中,而LOAD DATA INFILE则是相反的操作,是读取这个文件导入表中。
- 如果LOAD DATA命令导入的文件不在MySQL服务器上,而是想导入客户端所在的本地文件系统的文件时,则需要使用语法变体LOAD DATA…LOCAL INFILE…,也就是说,如果指定LOCAL关键词,则表明从客户主机读文件。如果没指定LOCAL,那么文件必须位于MySQL服务器上。
mysql> load data infile '/tmp/t2.txt' into table t2;
2.2.2、导出导入csv格式文件
- 导出导入csv格式的文本文件。csv格式的文件,即逗号分隔的数据文件。
# 生成csv文件
mysql> select field_list from table_name into outfile '/home/garychen/tmp/table_name_2.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\n';
# 导入文件
mysql> load data local infile '/home/garychen/tmp/table_name_2.csv' into table table_name fields terminated by ',' lines terminated by '\n'(field1,field2,field3);
2.2.3、SELECT INTO OUTFILE导出+LOAD DATA导入方案的优势
- 相较于普通的mysql命令,LOAD DATA执行SQL文件导入的方式要快得多,一般可以达到每秒几万条记录的插入速度。
- 如果有很多表,那么使用mysqldump会更简单。如果是导入个别大表,而且对于时间有很高的要求,那么LOAD DATA未尝不可。mysqldump默认的导出文件,其实已经包含了一些优化了,会有禁用key、启用key的操作,而且是一条INSERT语句包括多行记录的。
2.2.4、LOAD DATA的优化
- 将innodb_buf fer_pool_size设置得更大些。
- 将innodb_log_file_size设置得更大些,如256MB。
- 设置忽略二级索引的唯一性约束,SET UNIQUE_CHECKS=0。
- 设置忽略外键约束,SET FOREIGN_KEY_CHECKS=0。
- 设置不记录二进制日志,SET sql_log_bin=0。
- 按主键顺序导入数据。由于InnoDB使用了聚集索引,如果是顺序自增ID的导入,那么导入将会更快,我们可以把要导入的文件按照主键顺序先排好序再导入。
- 对于InnoDB引擎的表,可以在导入前,先设置autocommit=0
- 可以将大的数据文件切割为更小的多个文件,例如使用操作系统命令split切割文件,然后再并行导入数据。
- 由于唯一索引(约束)对于我们导入数据的影响比较大,尤其对于大表导入,我们需要留意这一点。不要在大表上创建太多的唯一索引,主键、唯一索引不要包含太多列,否则导入数据将会很慢。
2.3、使用mysqlimport导入数据
- mysqlimport命令的语法格式如下:
# 语法
mysqlimport databasename tablename.txt
# 实例
mysqlimport mytest /tmp/t2.txt
3、使用mysql程序的批处理模式导出数据
使用mysql程序的批处理模式,支持比较灵活的导出数据,因为可以利用SQL语句。
- 可以基于mysql的批处理模式,做语句级别的导出,以下两种方式等价:
# 方式一,-e选项
mysql --batch --default-character-set=utf8 -e "SELECT * FROM t2;" mytest > t2.txt
# 方式二,--execute
mysql --batch --default-character-set=utf8 "--execute=SELECT * FROM t2;" mytest > t3.txt
- vertical选项,将查询结果按纵向导出:
mysql --batch --default-character-set=utf8 --vertical -e "SELECT * FROM t2;" mytest > t2.txt
- html选项:将查询结果按html格式导出:
mysql --batch --default-character-set=utf8 --html -e "SELECT * FROM t2;" mytest > t2.txt
- xml选项,将查询结果按xml格式导出:
mysql --batch --default-character-set=utf8 --xml -e "SELECT * FROM t2;" mytest > t2.txt
4、使用Linux的split切割文件,加速导入数据
- split命令的作用是切割文件,如果不加入任何参数,默认情况下是以1000行的大小来分割的。
split [OPTION] [INPUT [PREFIX]]
- 以下以每个文件10000行记录进行切割,生成的文件名以test_spl i t_sub_为前缀,因为文件有15万多条记录,最后且分为16个文件
split -l 10000 /tmp/t1.txt t1_split_sub_

5、总结
MySQL导出导入数据(即数据转储)主要有以下三种方式:
- mysqldump导出+mysql导入:这种方式下导出的是SQL语句而非数据本身,所以导入时效率相对较低,但是胜在可以整库甚至多个库、多个表一起导出,适合整库的转储。
- SELECT INTO OUTFILE导出+LOAD DATA或mysqlimport导入:这种方式下导出的是纯数据,所以导入时效率会很高。适合单个大表的转储。
- mysql批处理模式导出+LOAD DATA或mysqlimport导入:这种方式下导出的也是纯数据,所以导入时效率会很高。优点除了导入效率高,由于是用SQL语句选择数据,所以很灵活,缺点则是使用门槛高。
相关文章:
MySQL运维10-MySQL数据的导入导出
文章目录0、概述1、mysqldump导出数据mysql导入数据1.1、使用mysqldump导出数据1.1.1、使用--tables导出指定表1.1.2、使用--tab选项将表定义文件和数据文件分开导出1.1.3、使用--fields-terminated-by选项定义数据分隔符1.1.4、使用--databases选项导出整个库或多个库1.1.5、使…...
全国计算机等级考试——二级JAVA完整大题题库【五十三道】
全国计算机等级考试二级 JAVA 题目内容 编写于2023.04.10 分为40道选择题和3道大题(大题是程序填空类型) 其中选择题只能进去做一次,一旦退出来则不可再进(注意!)。大题可以重复进入,重复做。…...
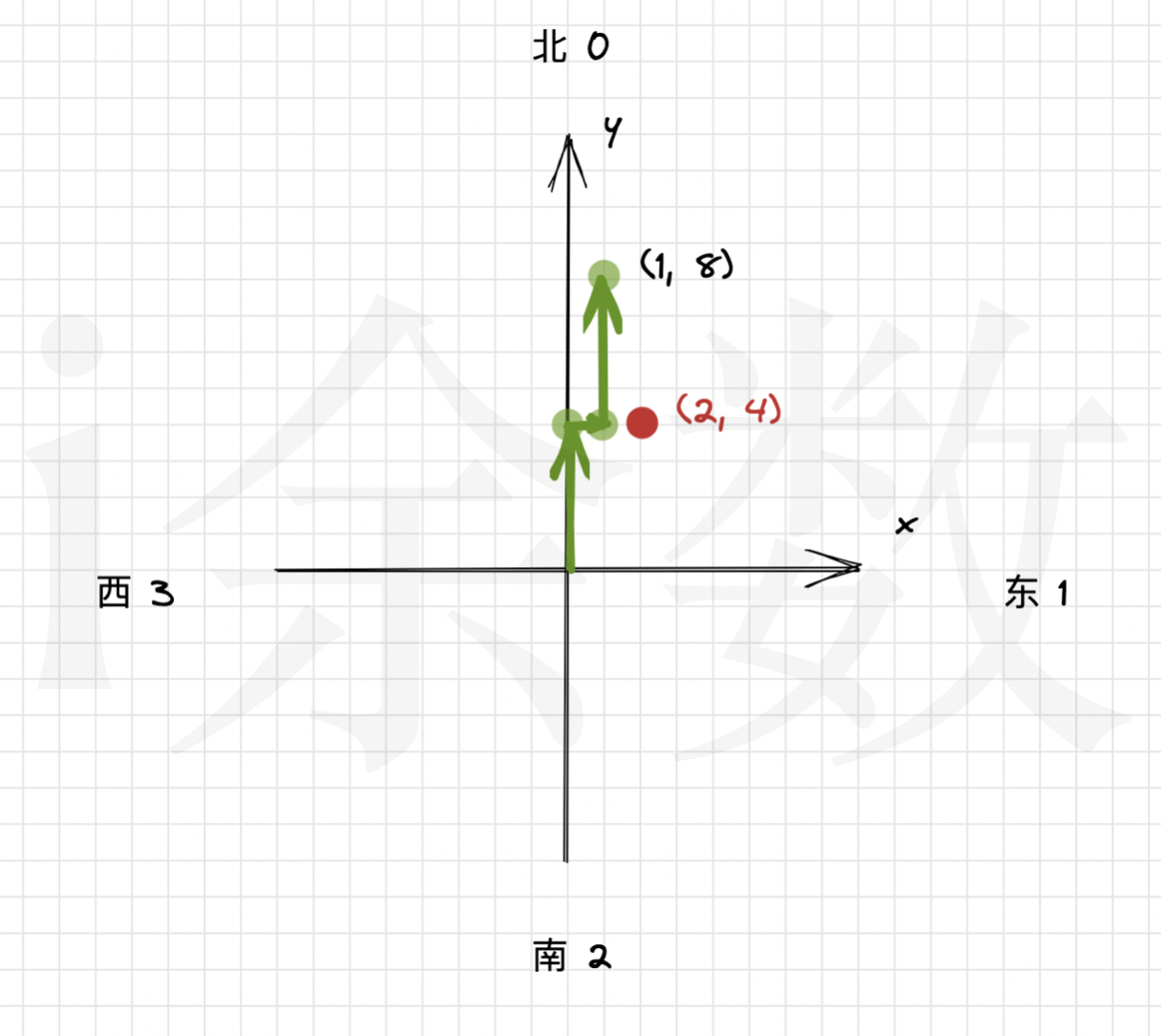
【算法题解】24. 模拟机器人行走
这是一道 中等难度 的题 https://leetcode.cn/problems/walking-robot-simulation/description/ 题目 机器人在一个无限大小的 XY 网格平面上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令 commands : -2 &am…...
PyTorch 深度学习实战 |用 TensorFlow 训练神经网络
为了更好地理解神经网络如何解决现实世界中的问题,同时也为了熟悉 TensorFlow 的 API,本篇我们将会做一个有关如何训练神经网络的练习,并以此为例,训练一个类似的神经网络。我们即将看到的神经网络,是一个预训练好的用…...

【进阶C语言】静态版通讯录的实现(详细讲解+全部源码)
前言 📕作者简介:热爱跑步的恒川,正在学习C/C、Java、Python等。 📗本文收录于C语言进阶系列,本专栏主要内容为数据的存储、指针的进阶、字符串和内存函数的介绍、自定义类型结构、动态内存管理、文件操作等࿰…...

【JavaWeb】后端(Maven+SpringBoot+HTTP+Tomcat)
目录一、Maven1.什么是Maven?2.Maven的作用?3.介绍4.安装5.IDEA集成Maven6.IDEA创建Maven项目7.IDEA导入Maven项目8.依赖配置9.依赖传递10.依赖范围11.生命周期二、SpringBoot1.Spring2.SpringBoot3.SpringBootWeb快速入门二、HTTP1.HTTP-概述2.HTTP-请求协议3.HTTP-响应协议…...

面试官:准备了一些springboot相关的面试题,快来看看吧
文章目录摘要Spring Boot 中的注解 RestController 和 Controller 有什么区别?Spring Boot 中如何处理异常?使用 ExceptionHandler 注解处理特定类型的异常:使用 ExceptionHandler 注解可以将特定类型的异常映射到一个处理方法上,…...
原子的波尔模型、能量量子化、光电效应、光谱实验、量子态、角动量
一. 卢瑟福模型 1908年,卢瑟福用α粒子继续轰击金箔,发现有极少数粒子,发生了非常大的偏移。而这对于当时主流的葡萄干面包模型理论分析是相悖的。 原子可看成由带正电的原子核和围绕核运动的一些电子组成,原子中心的原子核带正…...

【如何使用Arduino控制WS2812B可单独寻址的LED】
【如何使用Arduino控制WS2812B可单独寻址的LED】 1. 概述2. WS2812B 发光二极管的工作原理3. Arduino 和 WS2812B LED 示例3.1 例 13.2 例 24. 使用 WS2812B LED 的交互式 LED 咖啡桌4.1 原理图4.2 源代码在本教程中,我们将学习如何使用 Arduino 控制可单独寻址的 RGB LED 或 …...
)
计算机基本知识扫盲(持续更)
计算机基本知识扫盲Q:硬盘和磁盘有什么区别?A:硬盘和磁盘都是存储数据的设备。磁盘指的是存储数据的圆形或者是方形的光盘,但是硬盘则是指机械式硬盘和固态硬盘。磁盘一般用于存储少量数据,例如软件安装文件、音乐和电…...

学习大数据需要什么语言基础
Python易学,人人都可以掌握,如果零基础入门数据开发行业的小伙伴,可以从Python语言入手。 Python语言简单易懂,适合零基础入门,在编程语言排名上升最快,能完成数据挖掘、机器学习、实时计算在内的各种大数…...
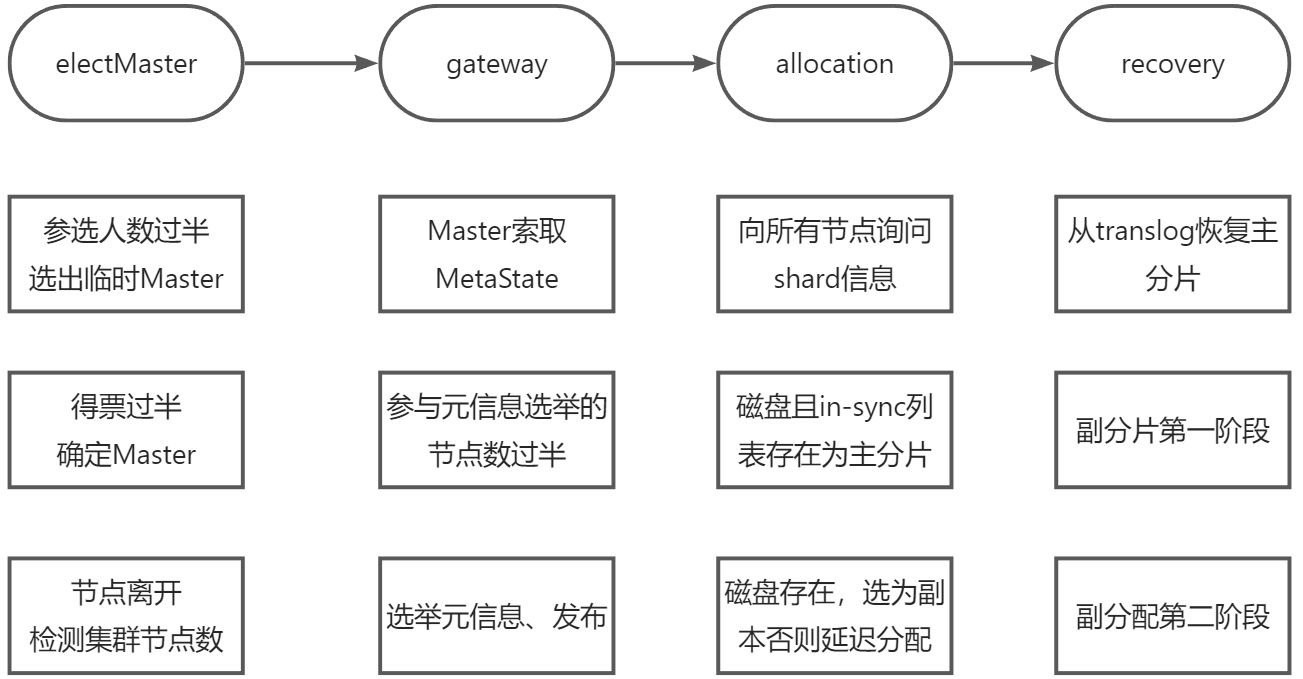
ElasticSearch——详细看看ES集群的启动流程
参考:一起看看ES集群的启动流程 本文主要从流程上介绍整个集群是如何启动的,集群状态如何从Red变成Green,然后分析其他模块的流程。 这里的集群启动过程指集群完全重启时的启动过程,期间要经历选举主节点、主分片、数据恢复等重…...

【教学类-30-01】5以内加法题不重复(一页两份)(包含1以内、2以内、3以内、4以内、5以内加法,抽取最大不重复数量)
作品样式: 背景需求: 虽然学前阶段就对幼儿训练加减法列式题遭到诟病,但是从不少幼儿(特别是二胎)在家中已经开始适应加减法题型了。 结合中班年龄特点,我从5以内的不重复加法题开始实验(雪花…...
写博客8年与人生第一个502万
题记:我们并非生来强大,但依然可以不负青春。 原本想好好写一下如何制定一个目标并通过一点一滴的努力去实现,这三年反思发现其实写自己的经历并不重要。 很多人都听过一句话:榜样的力量是无穷的。 更现实和实际的情况是&#x…...
)
【华为OD机试真题】日志采集系统(javapython)
日志采集系统 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 日志采集是运维系统的的核心组件。日志是按行生成,每行记做一条,由采集系统分 批上报。 如果上报太频繁,会对服务端造成压力;如果上报太晚,会降低用户的体验;如果一 次上报的条数太多,会导致超时…...

epoll源码剖析
文章目录1.前言2.应用层的体现3.两个重要结构(1)eventpoll(2)epitem4.四个函数(1)epoll_create源码(2)epoll_ctl源码(3)epoll_wait的源码(4)epoll_event_callback()5.水平触发和边缘触发1.状态变化2.LT模式3.ET模式1.前言 好久好久没有更新博客了,最近一直在实习&a…...
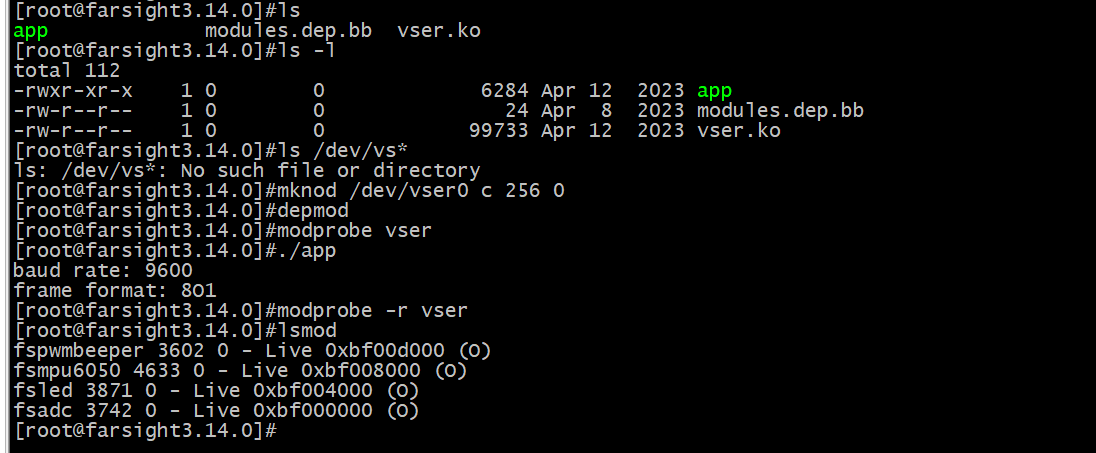
Linux驱动开发——高级I/O操作(一)
一个设备除了能通过读写操作来收发数据或返回、保存数据,还应该有很多其他的操作。比如一个串口设备还应该具备波特率获取和设置、帧格式获取和设置的操作;一个LED设备甚至不应该有读写操作,而应该具备点灯和灭灯的操作。硬件设备是如此众多,…...

适配器模式:C++设计模式中的瑞士军刀
适配器模式揭秘:C设计模式中的瑞士军刀引言设计模式的重要性适配器模式简介与应用场景适配器模式在现代软件设计中的地位与价值适配器模式基本概念适配器模式的定义与核心思想类适配器与对象适配器的比较设计原则与适配器模式的关系类适配器实现类适配器模式的UML图…...

【三十天精通Vue 3】 第三天 Vue 3的组件详解
✅创作者:陈书予 🎉个人主页:陈书予的个人主页 🍁陈书予的个人社区,欢迎你的加入: 陈书予的社区 🌟专栏地址: 三十天精通 Vue 3 文章目录引言一、Vue 3 组件的概述1. Vue 3 的组件系统2. Vue 3 组件的特点…...

SqlServer实用系统视图,你了解多少?
SqlServer实用系统视图,你了解多少?前言master..spt_valuessysdatabasessysprocesses一套组合拳sysobjectssys.all_objectssyscolumnssystypessyscommentssysindexes结束语前言 在使用任何数据库软件的时候,该软件都会提供一些可能不是那么公…...

Vivado XADC IP核 配置与接口实战解析
1. XADC IP核基础入门 XADC(Xilinx Analog-to-Digital Converter)是Xilinx FPGA芯片内置的高精度模拟数字转换模块,它能实时监测芯片内部的电压、温度以及外部模拟信号。在Vivado开发环境中,我们可以通过XADC Wizard IP核快速配置…...

RAG系统评估实战:使用renumics-rag进行量化分析与性能优化
1. 项目概述:一个为RAG应用量身定制的开源评估工具如果你正在构建或优化一个基于检索增强生成(RAG)的系统,那么你大概率会遇到一个核心痛点:如何科学、量化地评估它的好坏?是看它回答得“像不像人”&#x…...

低延时RS译码器优化设计【附代码】
✨ 长期致力于RS码、低延时、功耗优化、译码器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)改进型RiBM迭代展开算法加速关键方程求解: …...

[特殊字符] CSS 图片变黑变暗的 3 种方案,总有一款适合你!
最近在做项目的时候,遇到一个很常见的需求:如何让图片颜色更黑一点,或者加一层黑色透明度遮罩? 很多人第一反应是用 filter: brightness(0%),但其实这个方法有不少坑。今天就来聊聊 3 种靠谱的 CSS 方案,从…...

基于RAG与向量数据库的智能代码搜索工具设计与实现
1. 项目概述:一个面向开发者的智能代码搜索与理解工具 最近在GitHub上看到一个挺有意思的项目,叫 holasoymalva/perplexity-code 。乍一看这个标题,可能会有点困惑——“perplexity”在机器学习里通常指“困惑度”,是衡量语言模…...

Python模板引擎批量生成文章:Jinja2与Pandas实战指南
1. 项目概述:一个能帮你批量生成文章的自动化工具 如果你也经常需要处理大量内容创作任务,比如运营多个自媒体账号、管理企业博客矩阵,或者为产品生成海量描述性文案,那你一定对“重复劳动”这个词深恶痛绝。手动一篇篇地写&#…...

别再被VS2019的CMake报错劝退!从‘RC命令失败’看Windows C++开发环境那些坑
破解Windows C开发环境迷局:从CMake报错到系统级解决方案 当你在Visual Studio 2019中满怀期待地点击"生成解决方案",却看到控制台突然弹出"RC命令失败"的红色错误时,那种挫败感每个C开发者都深有体会。这不仅仅是一个简…...

3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南
3步解放暗黑2存档:Diablo Edit2角色编辑器完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾因暗黑破坏神2角色build失误而懊恼?是否厌倦了数百小时刷装备却…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...

TarsCpp协程实现原理:从用户态上下文切换看高性能RPC框架设计
1. 从线程到协程:为什么TarsCpp要拥抱协程?在分布式微服务架构里,我们每天都在和RPC、网络IO、并发处理打交道。传统的多线程模型,一个请求一个线程,逻辑清晰,但线程创建、上下文切换的开销,以及…...