结合PCA降维的DBSCAN聚类方法(附Python代码)
目录
前言介绍:
1、PCA降维:
(1)概念解释:
(2)实现步骤:
(3)优劣相关:
2、DBSCAN聚类:
(1)概念解释:
(2)算法原理:
(3)优劣相关:
代码实现:
0、数据准备:
1、PCA降维:
2、DBSCAN聚类:
3、代码汇总:
实现效果:
1、降维效果:
2、聚类效果:
写在最后:
前言介绍:
1、PCA降维:
(1)概念解释:
PCA,全称Principal Component Analysis,即主成分分析。是一种降维方法,实现途径是提取特征的主要成分,从而在保留主要特征的情况下,将高维数据压缩到低维空间。
在经过PCA处理后得到的低维数据,其实是原本的高维特征数据在某一低维平面上的投影(只要维度较低,都可以视为平面,例如三维相对于四维空间也可以视为一个平面)。虽然降维的数据能够反映原本高维数据的大部分信息,但并不能反映原本高维空间的全部信息,因此要根据实际情况,加以鉴别使用。
(2)实现步骤:
1、标准化(将原始数据进行标准化,一般是去均值,如果特征在不同量级上,还要将矩阵除以标准差)
具体:
其中,E为原始矩阵,Emean为均值矩阵,Enorm为标准化矩阵。
2、协方差(计算标准化数据集的协方差矩阵)
具体:
其中,Cov为协方差矩阵,m为样本的数量,Enorm为均值矩阵。
3、特征值(计算协方差矩阵的特征值和特征向量)
具体:
假设实数λ、n行(原始矩阵E的列数即为n)1列的矩阵X(即n维向量)满足下式:
则λ为Cov的特征值,其中Cov为协方差矩阵。
4、K 特征(保留特征值最大的前K个特征(K是降维后,我们期望达到的维度))
具体:
若有多个特征值,则保留前K个最大的特征值,以满足之后的计算需求。
5、K 向量(找到这K个特征值对应的特征向量)
具体:
通过步骤3中的公式得到每个特征值对应的特征向量。
6、得降维(将标准化数据集乘以该K个特征向量,得到降维后的结果)
具体:
其中,Epca为最后要求得的PCA降维矩阵,Enorm为标准化矩阵,X1、X2、X3、...、Xk为对K个特征值对应的特征向量。
(3)优劣相关:
1.PCA降维之后的各个主成分之间相互正交,可消除原始数据之间相互影响的因素。
2.PCA降维的计算过程并不复杂,因实现起来较简单容易。
3.在保留大部分主要信息的前提下,起到了降维,简便化计算效果。
1.特征主成分的定义具有模糊性,解释性差。
2.PCA降维选取令原数据在新坐标轴上方差最大的主成分的标准,使得一些方差小的特征较易丢失,有损失重要信息的可能性。
2、DBSCAN聚类:
(1)概念解释:
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)就是这样一种聚类算法,该算法基于一组“领域”(neighborhood)参数(ε,MinPts)来刻画样本分布的紧密程度。
(2)算法原理:





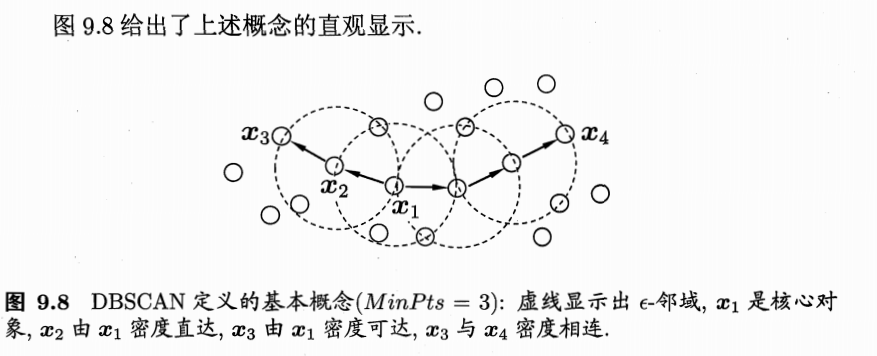

(3)优劣相关:
1、能够识别任意形状的样本。
2、该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。
3、无需指定簇个数,而是由算法自主发现。
1、需要指定最少点个数(MinPts)与半径(ε)。(但其实相对其他聚类算法来说,已经具有较大的自由性。)
2、最少点个数与半径对算法的影响较大,一般需多次调试。
代码实现:
0、数据准备:
pip install scikit-learn
from sklearn.datasets import load_iris
x = load_iris().data
y = load_iris().target1、PCA降维:
import numpy as npdef PCA_DimRed(dataMat,topNfeat): #PCA_DimRed--PCA dimension reduction,PCA降维meanVals = np.mean(dataMat, axis=0)meanRemoved = dataMat - meanVals # 标准化(去均值)covMat = np.cov(meanRemoved, rowvar=False)eigVals, eigVets = np.linalg.eig(np.mat(covMat)) # 计算矩阵的特征值和特征向量eigValInd = np.argsort(eigVals) # 将特征值从小到大排序,返回的是特征值对应的数组里的下标eigValInd = eigValInd[:-(topNfeat + 1):-1] # 保留最大的前K个特征值redEigVects = eigVets[:, eigValInd] # 对应的特征向量lowDDatMat = meanRemoved * redEigVects # 将数据转换到低维新空间# reconMat = (lowDDatMat * redEigVects.T) + meanVals # 还原原始数据return lowDDatMat2、DBSCAN聚类:
import numpy as np
import random
import copydef DBSCAN_cluster(mat,eps,min_Pts): #进行DBSCAN聚类,优点在于不用指定簇数量,而且适用于多种形状类型的簇k = -1neighbor_list = [] # 用来保存每个数据的邻域omega_list = [] # 核心对象集合gama = set([x for x in range(len(mat))]) # 初始时将所有点标记为未访问cluster = [-1 for _ in range(len(mat))] # 聚类for i in range(len(mat)):neighbor_list.append(find_neighbor(mat, i, eps))if len(neighbor_list[-1]) >= min_Pts:omega_list.append(i) # 将样本加入核心对象集合omega_list = set(omega_list) # 转化为集合便于操作while len(omega_list) > 0:gama_old = copy.deepcopy(gama)j = random.choice(list(omega_list)) # 随机选取一个核心对象k = k + 1Q = list()Q.append(j)gama.remove(j)while len(Q) > 0:q = Q[0]Q.remove(q)if len(neighbor_list[q]) >= min_Pts:delta = neighbor_list[q] & gamadeltalist = list(delta)for i in range(len(delta)):Q.append(deltalist[i])gama = gama - deltaCk = gama_old - gamaCklist = list(Ck)for i in range(len(Ck)):cluster[Cklist[i]] = komega_list = omega_list - Ckreturn cluster3、代码汇总:
from sklearn.datasets import load_iris
import numpy as np
import random
import copy
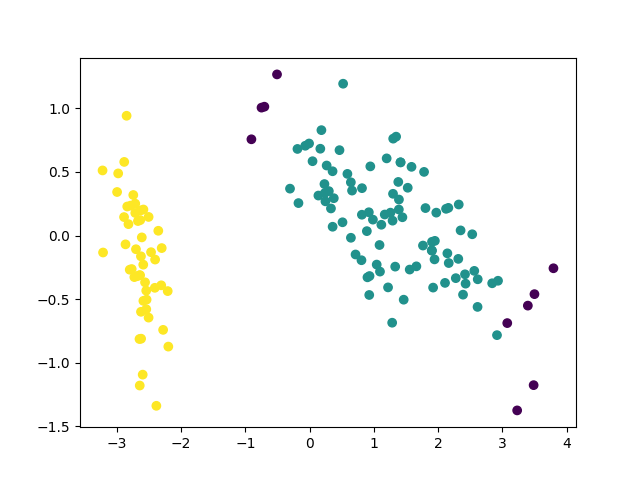
import matplotlib.pyplot as pltdef PCA_DimRed(dataMat,topNfeat): #PCA_DimRed--PCA dimension reduction,PCA降维meanVals = np.mean(dataMat, axis=0)meanRemoved = dataMat - meanVals # 标准化(去均值)covMat = np.cov(meanRemoved, rowvar=False)eigVals, eigVets = np.linalg.eig(np.mat(covMat)) # 计算矩阵的特征值和特征向量eigValInd = np.argsort(eigVals) # 将特征值从小到大排序,返回的是特征值对应的数组里的下标eigValInd = eigValInd[:-(topNfeat + 1):-1] # 保留最大的前K个特征值redEigVects = eigVets[:, eigValInd] # 对应的特征向量lowDDatMat = meanRemoved * redEigVects # 将数据转换到低维新空间# reconMat = (lowDDatMat * redEigVects.T) + meanVals # 还原原始数据return lowDDatMatdef find_neighbor(data,pos,eps): #寻找相邻点函数N = list()temp = np.sum((data-data[pos])**2, axis=1)**0.5N = np.argwhere(temp <= eps).flatten().tolist()return set(N)def DBSCAN_cluster(data,eps,min_Pts): #进行DBSCAN聚类,优点在于不用指定簇数量,而且适用于多种形状类型的簇,如果使用K均值聚类的话,对于这次实验的数据(条状簇)无法得到较好的分类结果k = -1neighbor_list = [] # 用来保存每个数据的邻域omega_list = [] # 核心对象集合gama = set([x for x in range(len(data))]) # 初始时将所有点标记为未访问cluster = [-1 for _ in range(len(data))] # 聚类for i in range(len(data)):neighbor_list.append(find_neighbor(data, i, eps))if len(neighbor_list[-1]) >= min_Pts:omega_list.append(i) # 将样本加入核心对象集合omega_list = set(omega_list) # 转化为集合便于操作while len(omega_list) > 0:gama_old = copy.deepcopy(gama)j = random.choice(list(omega_list)) # 随机选取一个核心对象k = k + 1Q = list()Q.append(j)gama.remove(j)while len(Q) > 0:q = Q[0]Q.remove(q)if len(neighbor_list[q]) >= min_Pts:delta = neighbor_list[q] & gamadeltalist = list(delta)for i in range(len(delta)):Q.append(deltalist[i])gama = gama - deltaCk = gama_old - gamaCklist = list(Ck)for i in range(len(Ck)):cluster[Cklist[i]] = komega_list = omega_list - Ckreturn clusterif __name__ == "__main__":#1、准备数据x = load_iris().datay = load_iris().target#2、PCA降维pro_data = PCA_DimRed(x,2)#3、DBSCAN聚类(此步中要保证数据集类型为数组,以配合find_neighbor函数)pro_array = np.array(pro_data)thecluster = DBSCAN_cluster(pro_array,eps=0.8,min_Pts=30)#4、展示降维效果:print("下面是降维之前的鸢尾花数据集特征集:")print(x)print("下面是降维之后的鸢尾花数据集特征集:")print(pro_data)#5、展示聚类效果:plt.figure()plt.scatter(pro_array[:, 0], pro_array[:, 1], c=thecluster)plt.show()
实现效果:
1、降维效果:
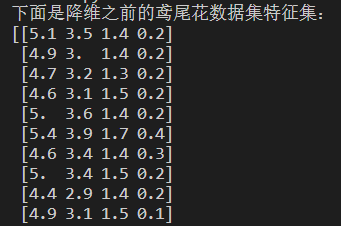

2、聚类效果:
写在最后:
周志华.机器学习[M].北京:清华大学出版社,2016.01
六种常见聚类算法:http://t.csdn.cn/Urhn9
Python PCA(主成分分析法)降维的两种实现:http://t.csdn.cn/NlAeU
DBSCAN聚类算法Python实现:http://t.csdn.cn/lkFhF
PCA降维原理 操作步骤与优缺点:http://t.csdn.cn/QiEJM
好了以上就是所有的内容,希望大家多多关注,点赞,收藏,这对我有很大的帮助。谢谢大家了!

好了,这里是Kamen Black 君。祝国康家安,大家下次再见喽!!!
溜溜球~~

相关文章:
结合PCA降维的DBSCAN聚类方法(附Python代码)
目录 前言介绍: 1、PCA降维: (1)概念解释: (2)实现步骤: (3)优劣相关: 2、DBSCAN聚类: (1)概念解释&a…...
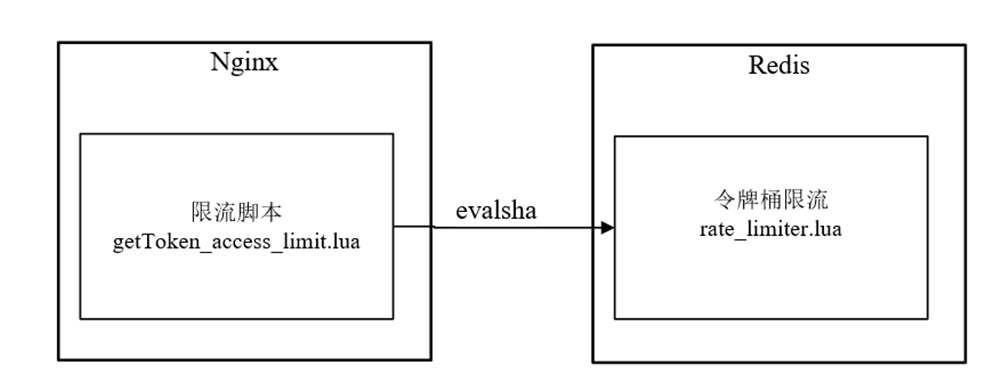
限流:计数器、漏桶、令牌桶 三大算法的原理与实战(史上最全)
限流 限流是面试中的常见的面试题(尤其是大厂面试、高P面试) 注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到文末《技术自由圈》公号获取 为什么要限流 简单来说: 限流在很多场景中用来…...
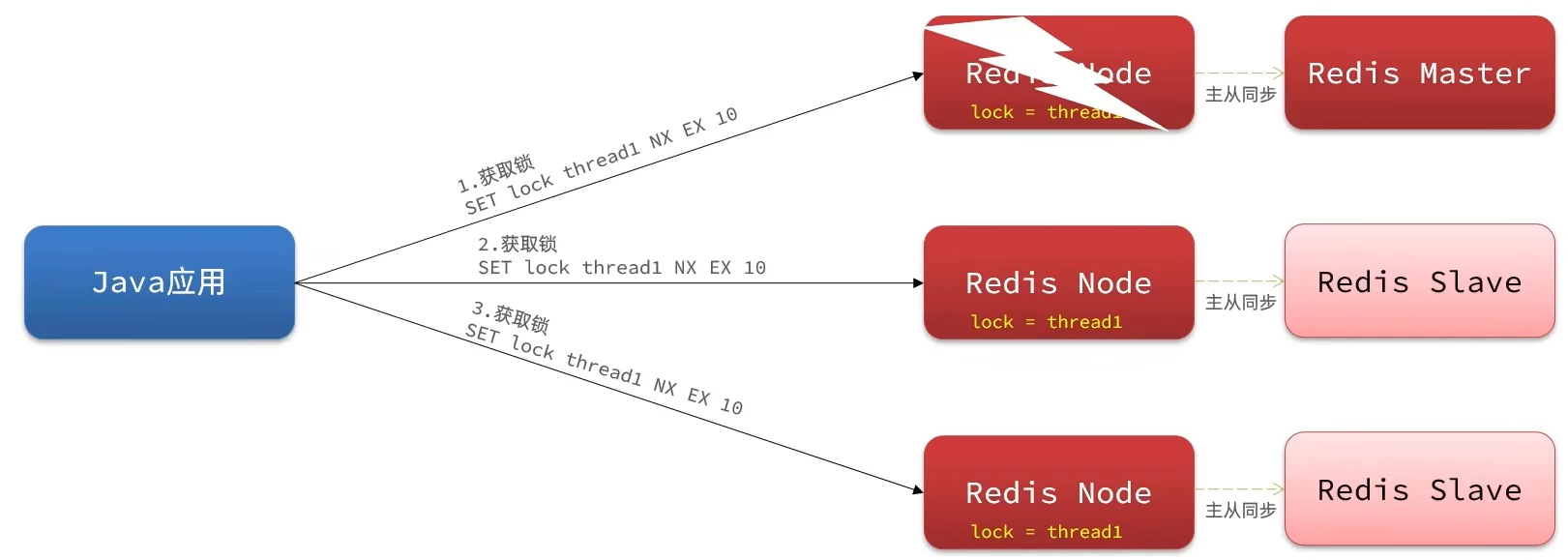
Redis用于全局ID生成器、分布式锁的解决方案
全局ID生成器 每个店铺都可以发布优惠卷 当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增id就存在一些问题: 1.id的规律性太明显 2.受单表数据量的限制 全局ID生成器,是一种在分布式系…...
OpenTex 企业内容管理平台
OpenText 企业内容管理平台 将内容服务与领先应用程序集成,弥合内容孤岛、加快信息流并扩大治理 什么是内容服务集成? 内容服务集成通过将内容管理平台与处于流程核心的独立应用程序和系统连接起来,支持并扩展了 ECM 的传统优势。 最好的内…...

【0基础学爬虫】爬虫基础之数据存储
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...
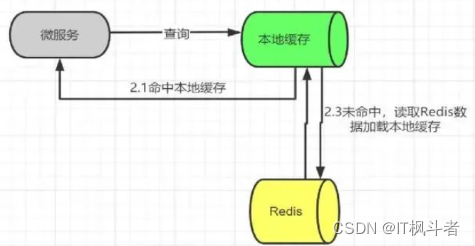
Redis与本地缓存组合使用(IT枫斗者)
Redis与本地缓存组合使用 前言 我们开发中经常用到Redis作为缓存,将高频数据放在Redis中能够提高业务性能,降低MySQL等关系型数据库压力,甚至一些系统使用Redis进行数据持久化,Redis松散的文档结构非常适合业务系统开发…...
手把手教你学习IEC104协议和编程实现 十 故障事件与复位进程
故障事件 目的 在IEC104普遍应用之前,据我了解多个协议,再综合自动化协议中,有这么一个概念叫“事故追忆”,意思是当变电站出现事故的时候,不但要记录事故的时间,还需记录事故前后模拟量的数据,从而能从一定程度上分析事故产生的原因,这个模拟量就是和今天讲解的故障…...

浅析分布式理论的CAP
大家好,我是易安! 今天让我们来聚焦于分布式系统架构中的重要理论——CAP理论。在分布式系统中,可用性和数据一致性是两个至关重要的因素,而CAP理论就是在这两者之间提供了一种权衡的原则,帮助我们在设计分布式系统时进…...

使用 TensorFlow 构建机器学习项目:6~10
原文:Building Machine Learning Projects with TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象&#x…...
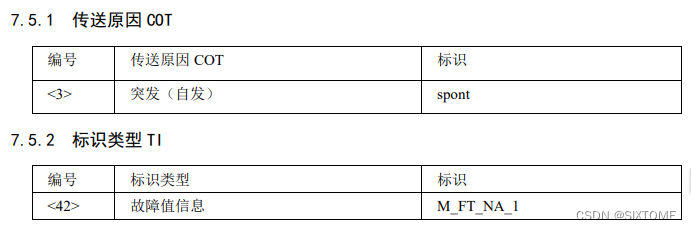
使用 LXCFS 文件系统实现容器资源可见性
使用 LXCFS 文件系统实现容器资源可见性一、基本介绍二、LXCFS 安装与使用1.安装 LXCFS 文件系统2.基于 Docker 实现容器资源可见性3.基于 Kubernetes 实现容器资源可见性前言:Linux 利用 Cgroup 实现了对容器资源的限制,但是当在容器内运行 top 命令时就…...
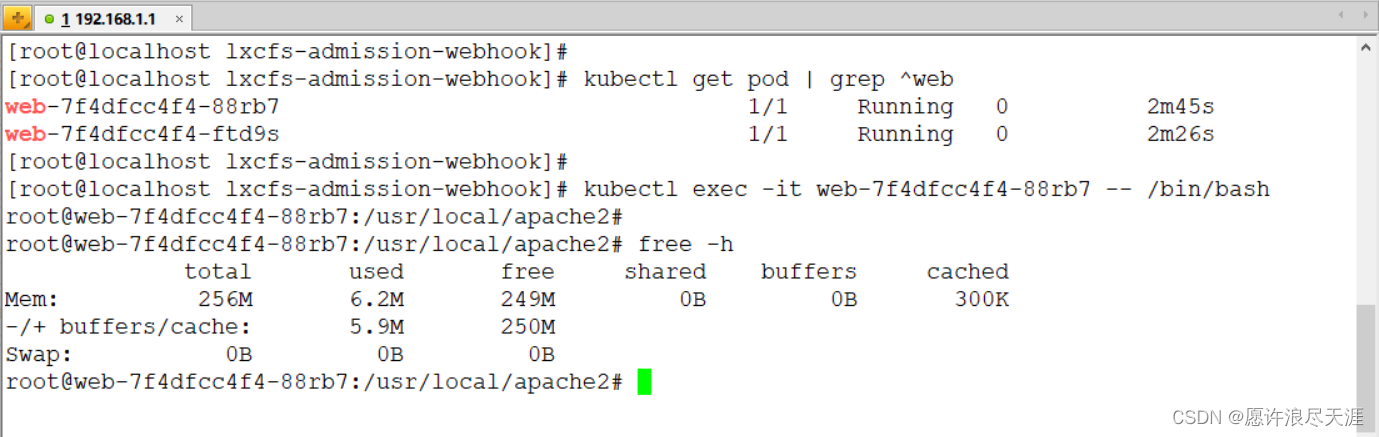
SQL LIMIT
SQL LIMIT SQL LIMIT子句简介 要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。 以下说明了这些子句的语法: SELECT column_list FROMtable1 ORDER BY column_list LIMIT row_count OFFSET offset;在这个语法中, row_count确定将返…...
OpenCV实战之人脸美颜美型(六)——磨皮
1.需求分析 有个词叫做“肤若凝脂”,直译为皮肤像凝固的油脂,形容皮肤洁白且光润,这是对美女的一种通用评价。实际生活中我们的皮肤多少会有一些毛孔、斑点等表现,在观感上与上述的“光润感”相反,因此磨皮也成为美颜算法中的一项基础且重要的功能。让皮肤变得更加光润,就…...

Java技术栈—重装系统后不重新安装也能正常使用的设置方式
声明: 最近在重装电脑,重装完后,开发工具会有些功能使用不了,在这做个记录!这里是 JAVA 技术栈 问题描述: git 右键无菜单 111 git git 右键无菜单 参考文章:注册表修复git右键无菜单 git …...
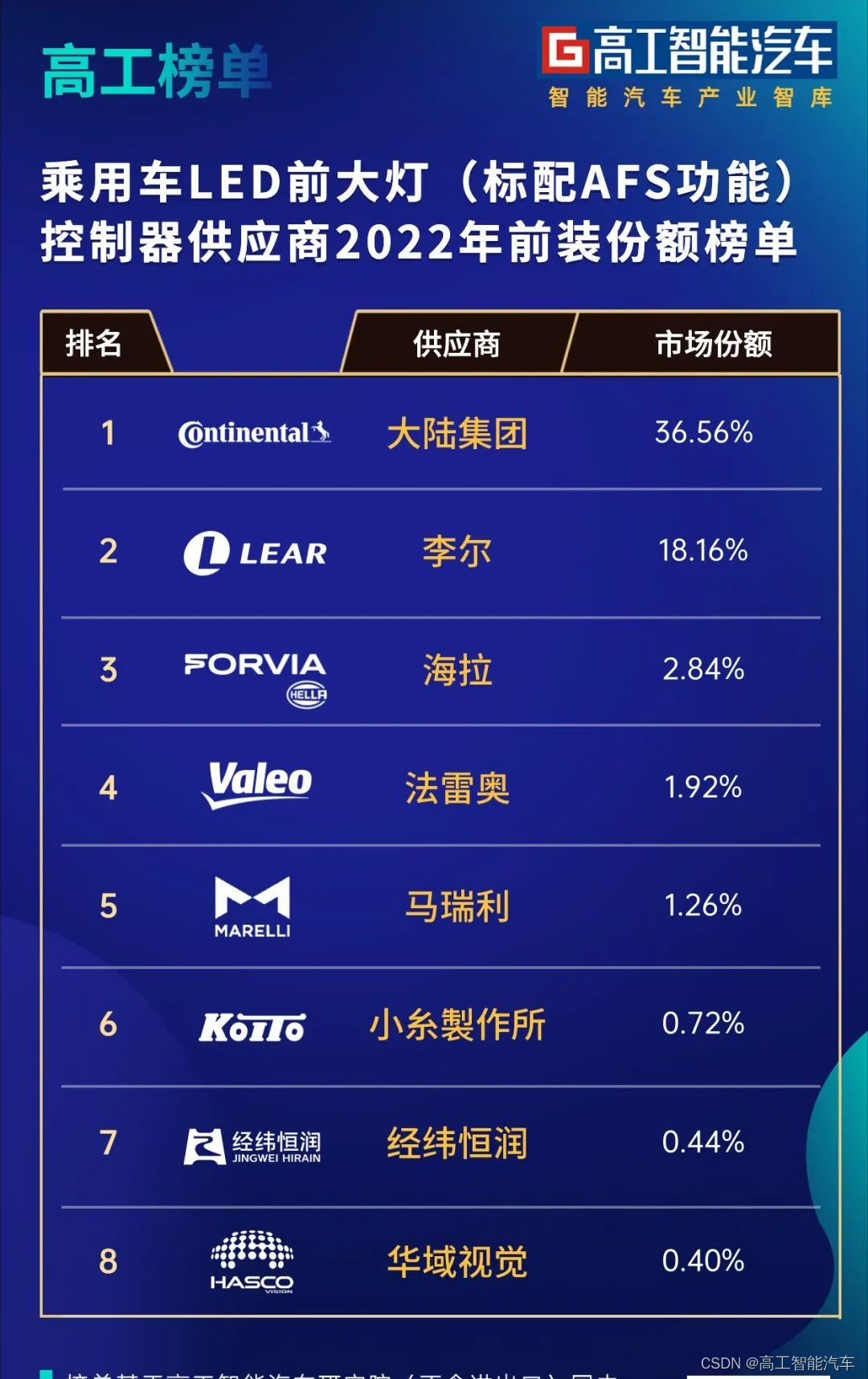
智驾升级!ADB+AFS「起势」
目前,乘用车前大灯已经完成从传统卤素、氙气到LED的转型升级,高工智能汽车研究院监测数据显示,2022年中国市场(不含进出口)乘用车前装标配LED前大灯搭载率达到75.99%,同比2021年提高约7个百分点。 而相比而…...

算法记录 | Day27 回溯算法
39.组合总和 思路: 1.确定回溯函数参数:定义全局遍历存放res集合和单个path,还需要 candidates数组 targetSum(int)目标和。 startIndex(int)为下一层for循环搜索的起始位置。 2.终止条件…...
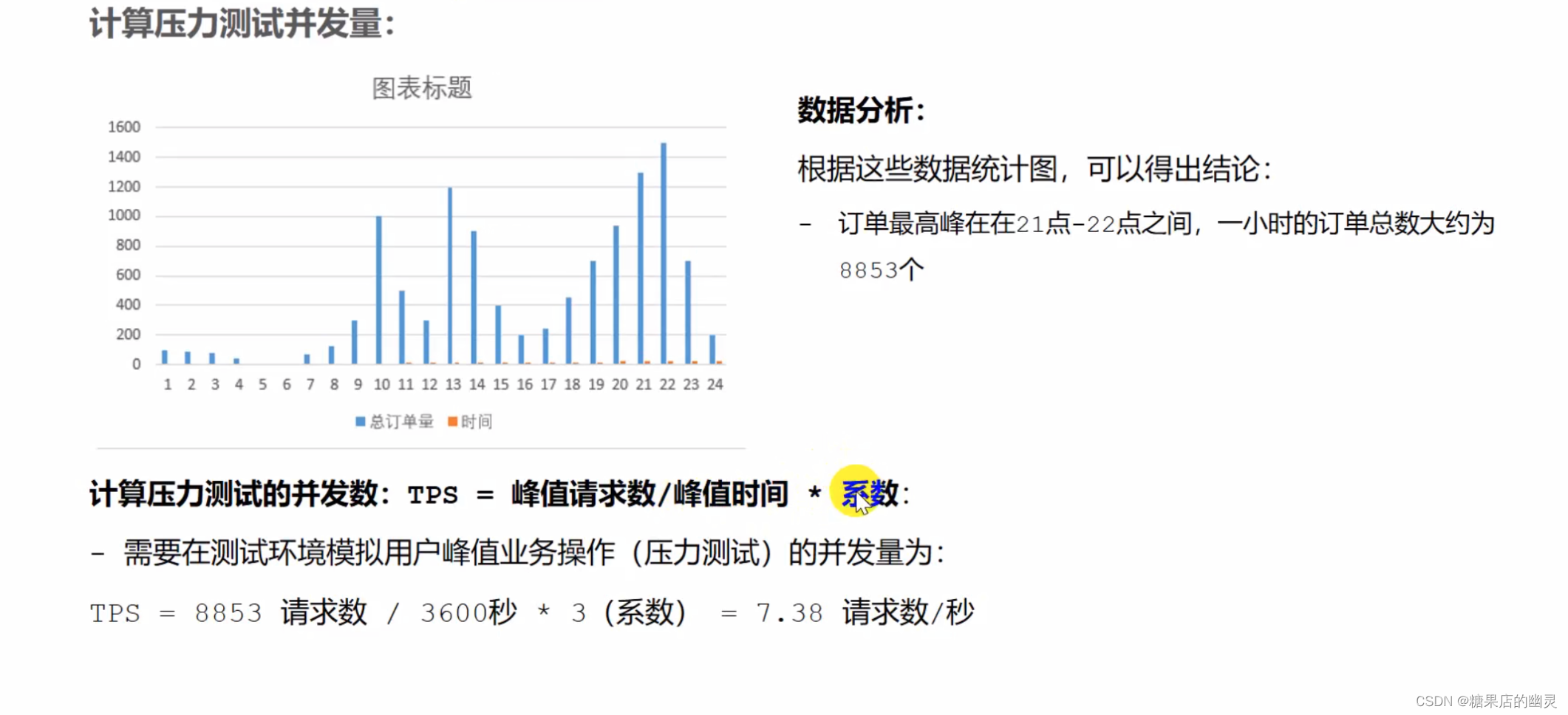
性能测试总结-根据工作经验总结还比较全面
性能测试总结性能测试理论性能测试的策略基准测试负载测试稳定性测试压力测试并发测试性能测试的指标响应时间并发数吞吐量资源指标性能测试流程性能测试工具JMeter基本使用元件构成线程组jmeter的分布式使用jmeter测试报告常用插件性能测试的计算1.根据请求数明细数据计算满足…...

类型断言[as语法 | <> 语法
TypeScript中的类型断言[as语法 | <> 语法] https://huaweicloud.csdn.net/638f0fbbdacf622b8df8e283.html?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2~default~CTRLIST~activity-1-107633405-blog-122438115.2…...
barret reduction原理详解及硬件优化
背景介绍 约减算法,通常应用在硬件领域,因为模运算mod是一个除法运算,在硬件中实现速度会比乘法慢的多,并且还会占用大量资源,因此需要想办法用乘法及其它简单运算来替代模运算。模约减算法可以利用乘法、加法和移位等…...
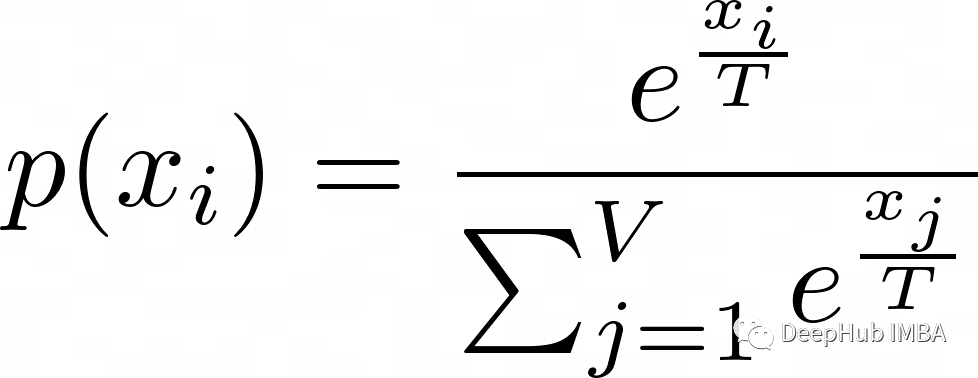
NLP / LLMs中的Temperature 是什么?
ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数 大型语言模型能够根据给定的上下文或提示生成新文本,由于神经网络等深度学习技术的进步,这些模型越来越受欢迎。可用于控制生成语言模型行为的关键参数之一是Temperature …...

c#快速入门~在java基础上,知道C#和JAVA 的不同即可
☺ 观看下文前提:如果你的主语言是java,现在想再学一门新语言C#,下文是在java基础上,对比和java的不同,快速上手C#,当然不是说学C#的前提是需要java,而是下文是从主语言是java的情况下ÿ…...

Mbed OS platform_drivers:嵌入式HAL驱动核心解析
1. 项目概述platform_drivers是 Arm Mbed OS 生态中一组经过严格验证、面向硬件抽象层(HAL)的平台级设备驱动集合,其核心定位并非提供通用外设封装,而是为 Mbed OS 内核及中间件组件提供可移植、可测试、符合 RTOS 语义的底层硬件…...

StructuredTaskScope配置不生效?揭秘ClassLoader隔离、虚拟线程绑定与作用域传播的3层断点排查法
第一章:StructuredTaskScope配置不生效?揭秘ClassLoader隔离、虚拟线程绑定与作用域传播的3层断点排查法当使用 Java 21 的 StructuredTaskScope 时,常见现象是:明明调用了 scope.fork() 并设置了自定义上下文(如 MDC、…...

原神帧率解锁器:告别60帧限制,开启高刷新率游戏新时代
原神帧率解锁器:告别60帧限制,开启高刷新率游戏新时代 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 对于追求极致游戏体验的《原神》玩家来说,60帧的…...

告别版本冲突:利用快马平台高效管理多jdk环境,提升开发效率
作为一名Java开发者,我经常遇到这样的困扰:接手不同项目时,每个项目可能要求使用不同版本的JDK。手动切换环境变量、反复安装卸载JDK版本,不仅浪费时间,还容易出错。最近我发现了一个高效的解决方案——利用InsCode(快…...

Kandinsky-5.0-I2V-Lite-5s Web工具深度解析:非聊天页,专注图生视频的生产级界面
Kandinsky-5.0-I2V-Lite-5s Web工具深度解析:非聊天页,专注图生视频的生产级界面 1. 工具概述 Kandinsky-5.0-I2V-Lite-5s是一款专为图生视频任务设计的轻量级AI模型,它通过简洁直观的Web界面,让用户能够快速将静态图片转化为动…...

百川2-13B模型API调用详解:从Python安装到第一个成功请求
百川2-13B模型API调用详解:从Python安装到第一个成功请求 你是不是也对大模型API调用感到好奇,但一看到那些技术文档就头疼?别担心,今天咱们就来手把手走一遍,从零开始,用最简单的Python代码,完…...

Obsidian表格处理革新:Excel插件的无缝集成方案
Obsidian表格处理革新:Excel插件的无缝集成方案 【免费下载链接】obsidian-excel 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-excel 在知识管理的日常工作中,你是否经常遇到这样的困境:在Obsidian中记录项目数据时&#…...

实战应用:基于编译原理,利用快马AI构建你的首个代码压缩工具
实战应用:基于编译原理,利用快马AI构建你的首个代码压缩工具 最近在学习编译原理,发现这门看似高深的学科其实离我们日常开发很近。比如代码压缩工具,就是编译原理技术的典型应用场景。今天就用InsCode(快马)平台来快速实现一个简…...

利用Cosmos-Reason1-7B进行Java面试题智能解析与答案生成
利用Cosmos-Reason1-7B进行Java面试题智能解析与答案生成 最近在帮朋友准备Java面试,发现一个挺普遍的问题:网上的面试题答案要么太零散,要么太浅显,很难找到一个能讲透原理、还能分析源码的深度解析。自己整理吧,费时…...

继电器触点粘接?手把手教你用NTC热敏电阻搞定大功率负载保护
大功率负载下继电器触点粘接的工程解决方案:NTC热敏电阻实战指南 当你在深夜调试一块电源板时,突然闻到焦糊味——继电器又粘接了。这不是个例,据统计,工业控制系统中约23%的继电器故障源于触点粘接,而大电流场景下这一…...