基于飞桨实现的特定领域知识图谱融合方案:ERNIE-Gram文本匹配算法

文本匹配任务在自然语言处理领域中是非常重要的基础任务,一般用于研究两段文本之间的关系。文本匹配任务存在很多应用场景,如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
而在知识融合过程中的关键技术是实体对齐,又被称为实体匹配,其旨在推断来自不同数据集合中的不同实体是否映射到物理世界中同一对象的处理过程。实体对齐的终极目标是将多源知识库中的实体建立映射关系,也正因如此,文本匹配算法可以在知识融合过程中针对非结构化文本进行较好的语义对齐,建立映射关系,具体方案如下图所示。
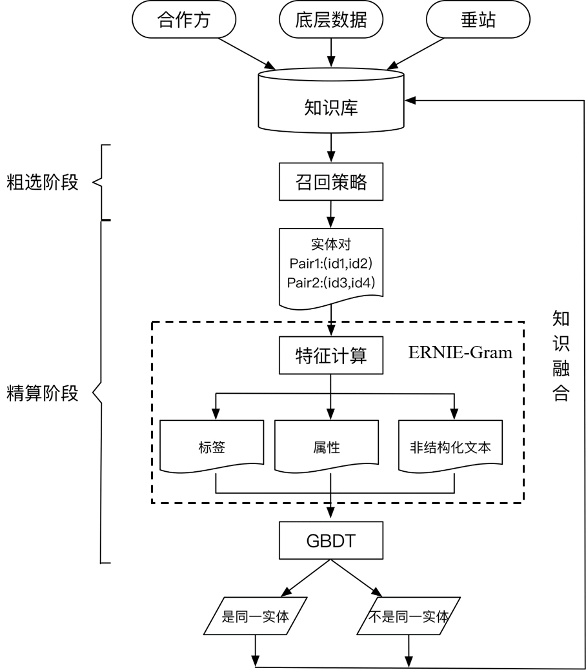
在粗选阶段,我们需要根据知识库寻找相似实体对,通过精准匹配和部分匹配的方式进行实体簇的粗选。其中,精准匹配主要采用同名召回、同音召回、别名召回三类策略。部分匹配主要采用jaccard距离等方法构建倒排,根据阈值进行挑选。
在精排阶段,我们根据粗选出来的实体对,构建Pair-wise类特征,进行精细算分。根据特征的种类,可以划分为标签、属性、非结构化文本三类特征。在实际对齐任务中,头尾部的实体经常缺失各种关键属性,难以判断实体是否可以对齐,此时就利用非结构化文本提供关键信息,这里就可以通过使用飞桨ERNIE-Gram模型将根据计算的三类特征进行实体对齐。由于各领域的schema不同,涉及到的属性类特征也不尽相同。故根据对数据的分析,为schema相差较大的领域设计不同的GBDT模型,最终完成对齐。
本文主要讲解精排阶段的文本匹配算法,更多方案和技术细节请参考下述项目。
-
项目链接
https://aistudio.baidu.com/aistudio/projectdetail/5456683?channelType=0&channel=0
-
项目合集
https://aistudio.baidu.com/aistudio/projectdetail/5427356?contributionType=1
01 融合方案操作步骤
Part-1 环境版本要求
环境安装需根据Python和飞桨框架的版本要求进行选择。
Python3 版本要求
python3.7及以上版本,参考
https://www.python.org/
飞桨框架版本要求
飞桨框架2.0+版本,参考
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/pip/macos-pip.html
飞桨环境的安装
需首先保证Python和pip是64bit,且处理器架构为x86_64(或称作x64、Intel 64、AMD64)。目前飞桨暂不支持arm64架构(mac M1除外,飞桨已支持Mac M1 芯片)。
Part-2 数据集简介
LCQMC[1]是百度知道领域的中文问题匹配数据集,以解决中文领域大规模问题匹配。该数据集从百度知道的不同领域用户问题中抽取构建数据。部分数据集展示如下:
西安下雪了?是不是很冷啊? 西安的天气怎么样啊?还在下雪吗? 0
第一次去见女朋友父母该如何表现? 第一次去见家长该怎么做 0
猪的护心肉怎么切 猪的护心肉怎么吃 0
显卡驱动安装不了,为什么? 显卡驱动安装不了怎么回事 1
一只蜜蜂落在日历上(打一成语) 一只蜜蜂停在日历上(猜一成语) 1
Part-3 模型情况
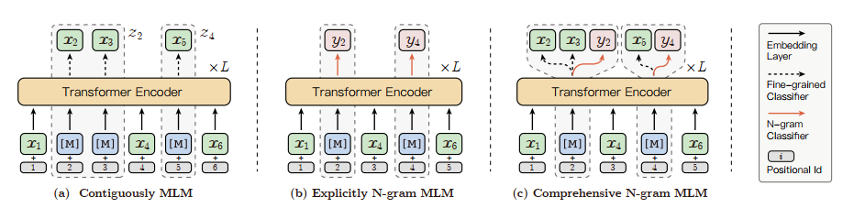
在ERNIE-Gram模型[2]发布以前,学界工作主要集中在将BERT的掩码语言建模(MLM)的目标从Mask单个标记扩展到N个标记的连续序列,但这种连续屏蔽方法忽略了对粗粒度语言信息的内部依赖性和相互关系的建模。作为一种改进方法ERNIE-Gram采用了一种显式n-gram掩码方法,以加强对预训练中粗粒度信息的整合。在ERNIE-Gram中,n-grams被Mask并直接使用明确的n-gram序列号而不是n个标记的连续序列进行预测。此外,ERNIE-Gram采用了一个生成器模型,对可信的n-gram序列号进行采样,作为可选的n-gram掩码,并以粗粒度和细粒度的方式进行预测,以实现全面的n-gram预测和关系建模。在论文中实验表明,ERNIE-Gram在很大程度上优于XLNet和RoBERTa等预训练模型。其中掩码的流程见下图所示。
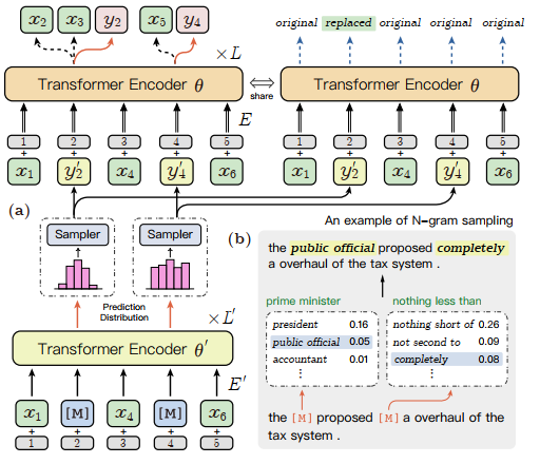
ERNIE-Gram模型充分地将粗粒度语言信息纳入预训练,进行了全面的n-gram预测和关系建模,消除之前连续掩蔽策略的局限性,进一步增强了语义n-gram的学习。n-gram关系建模的详细架构如下图所示,子图(b)中是一个n-gram抽样的例子,其中虚线框代表抽样模块,绿色的文本是原始n-gram,蓝色的斜体文本是抽样的n-gram。本文不一一展开,更多算法原理和技术细节请参考原论文。
为让同学们快速上手,本项目使用语义匹配数据集LCQMC作为训练集,基于ERNIE-Gram预训练模型训练了单塔Point-wise语义匹配模型,用户可以直接基于这个模型对文本对进行语义匹配的二分类任务。(在文本匹配任务数据的每一个样本通常由两个文本组成query和title。类别形式为0或1,0表示query与title不匹配,1表示匹配。)同时考虑到在不同应用场景下的需求,下面也将简单讲解一下不同类型的语义匹配模型和应用场景。
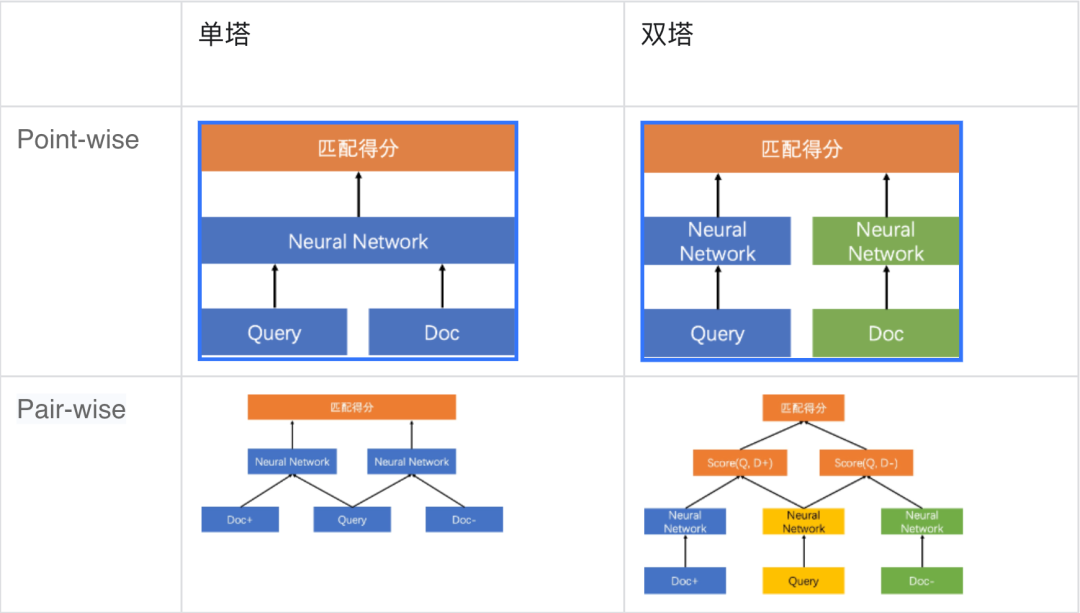
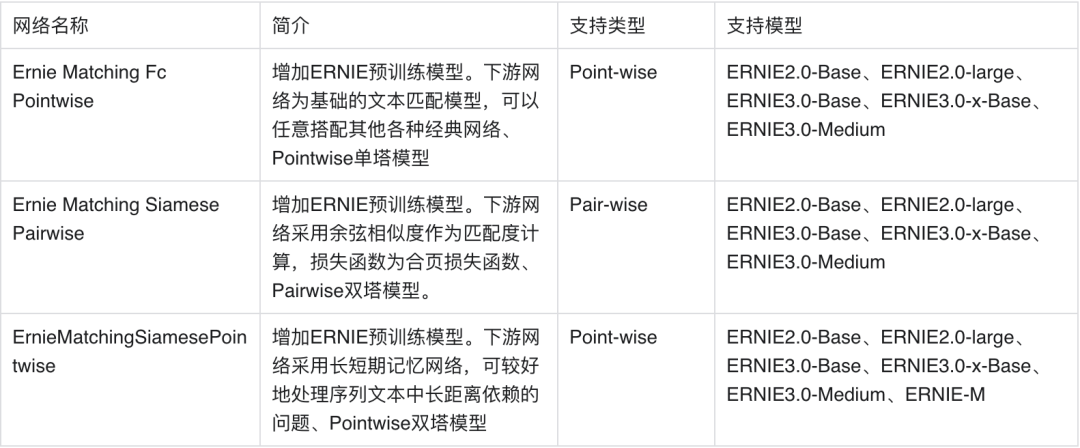
基于单塔Point-wise范式的语义匹配模型Ernie_Matching模型精度高、计算复杂度高, 适合直接进行语义匹配二分类的应用场景。基于单塔Pair-wise范式的语义匹配模型Ernie_Matching模型精度高、计算复杂度高,对文本相似度大小的序关系建模能力更强,适合将相似度特征作为上层排序模块输入特征的应用场景。基于双塔Point-Wise范式的语义匹配模型计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。
Part-4 模型训练与预测
以中文文本匹配公开数据集LCQMC为示例数据集,可在训练集(train.tsv)上进行单塔 Point-wise 模型训练,并在开发集(dev.tsv)验证。
模型训练
%cd ERNIE_Gram
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" train_pointwise.py \--device gpu \--save_dir ./checkpoints \--batch_size 32 \--learning_rate 2E-5\--save_step 1000 \--eval_step 200 \--epochs 3# save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。
# max_seq_length:可选,ERNIE-Gram 模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。
# batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
# learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。
# weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。
# epochs: 训练轮次,默认为3。
# warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
# init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。
# seed:可选,随机种子,默认为1000.
# device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。预测结果部分展示。
global step 3920, epoch: 1, batch: 3920, loss: 0.13577, accu: 0.92109, speed: 22.31 step/s
global step 3930, epoch: 1, batch: 3930, loss: 0.15333, accu: 0.91971, speed: 18.52 step/s
global step 3940, epoch: 1, batch: 3940, loss: 0.10362, accu: 0.92031, speed: 21.68 step/s
global step 3950, epoch: 1, batch: 3950, loss: 0.14692, accu: 0.92146, speed: 21.74 step/s
global step 3960, epoch: 1, batch: 3960, loss: 0.17472, accu: 0.92168, speed: 19.54 step/s
global step 3970, epoch: 1, batch: 3970, loss: 0.31994, accu: 0.91967, speed: 21.06 step/s
global step 3980, epoch: 1, batch: 3980, loss: 0.17073, accu: 0.91875, speed: 21.22 step/s
global step 3990, epoch: 1, batch: 3990, loss: 0.14955, accu: 0.91891, speed: 21.51 step/s
global step 4000, epoch: 1, batch: 4000, loss: 0.13987, accu: 0.91922, speed: 21.74 step/s
eval dev loss: 0.30795, accu: 0.87253如果想要使用其他预训练模型如ERNIE、BERT、RoBERTa等,只需更换model和tokenizer即可。
# 使用 ERNIE-3.0-medium-zh 预训练模型
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')# 使用 ERNIE 预训练模型
# ernie-1.0
#model = AutoModel.from_pretrained('ernie-1.0-base-zh'))
#tokenizer = AutoTokenizer.from_pretrained('ernie-1.0-base-zh')# ernie-tiny
# model = AutoModel.from_pretrained('ernie-tiny'))
# tokenizer = AutoTokenizer.from_pretrained('ernie-tiny')# 使用 BERT 预训练模型
# bert-base-chinese
# model = AutoModel.from_pretrained('bert-base-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')# bert-wwm-chinese
# model = AutoModel.from_pretrained('bert-wwm-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-wwm-chinese')# bert-wwm-ext-chinese
# model = AutoModel.from_pretrained('bert-wwm-ext-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-wwm-ext-chinese')# 使用 RoBERTa 预训练模型
# roberta-wwm-ext
# model = AutoModel.from_pretrained('roberta-wwm-ext')
# tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext')# roberta-wwm-ext
# model = AutoModel.from_pretrained('roberta-wwm-ext-large')
# tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext-large')NOTE:如需恢复模型训练,则可以设置init_from_ckpt,如
init_from_ckpt=checkpoints/model_100/model_state.pdparams。如需使用ernie-tiny模型,则需提前先安装sentencepiece依赖,如pip install sentencepiece。
模型预测
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" \predict_pointwise.py \--device gpu \--params_path "./checkpoints/model_4000/model_state.pdparams"\--batch_size 128 \--max_seq_length 64 \--input_file '/home/aistudio/LCQMC/test.tsv'预测结果部分展示:
{'query': '这张图是哪儿', 'title': '这张图谁有', 'pred_label': 0}
{'query': '这是什么水果?', 'title': '这是什么水果。怎么吃?', 'pred_label': 1}
{'query': '下巴长痘痘疼是什么原因', 'title': '下巴长痘痘是什么原因?', 'pred_label': 1}
{'query': '北京的市花是什么?', 'title': '北京的市花是什么花?', 'pred_label': 1}
{'query': '这个小男孩叫什么?', 'title': '什么的捡鱼的小男孩', 'pred_label': 0}
{'query': '蓝牙耳机什么牌子最好的?', 'title': '什么牌子的蓝牙耳机最好用', 'pred_label': 1}
{'query': '湖南卫视我们约会吧中间的歌曲是什么', 'title': '我们约会吧约会成功歌曲是什么', 'pred_label': 0}
{'query': '什么鞋子比较好', 'title': '配什么鞋子比较好…', 'pred_label': 1}
{'query': '怎么把词典下载到手机上啊', 'title': '怎么把牛津高阶英汉双解词典下载到手机词典上啊', 'pred_label': 0}
{'query': '话费充值哪里便宜', 'title': '哪里充值(话费)最便宜?', 'pred_label': 1}
{'query': '怎样下载歌曲到手机', 'title': '怎么往手机上下载歌曲', 'pred_label': 1}
{'query': '苹果手机丢了如何找回?', 'title': '苹果手机掉了怎么找回', 'pred_label': 1}
{'query': '考试怎么考高分?', 'title': '考试如何考高分', 'pred_label': 1}在深度学习模型构建上,飞桨框架支持动态图编程和静态图编程两种方式,两种方式下代码编写和执行方式均存在差异。动态图编程体验更佳、更易调试,但是因为采用Python实时执行的方式,开销较大,在性能方面与 C++ 有一定差距。静态图调试难度大,但是将前端Python编写的神经网络预定义为Program描述,转到C++端重新解析执行,从而脱离了对Python的依赖,往往执行性能更佳,并且预先拥有完整网络结构也更利于全局优化。
同时,你可以进行基于静态图的部署预测和模型导出。使用动态图训练结束之后,可以使用静态图导出工具export_model.py将动态图参数导出成静态图参数。实现方式可参考如下指令:
!python export_model.py --params_pathcheckpoints/model_4000/model_state.pdparams --output_path=./output
# 其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。# 预测部署
# 导出静态图模型之后,可以基于静态图模型进行预测,deploy/python/predict.py 文件提供了静态图预测示例。执行如下命令:
!python deploy/predict.py --model_dir ./output02 结论
Part-1 项目小结
该项目中还涉及部分对无监督模型以及有监督模型的对比内容,如下图所示。
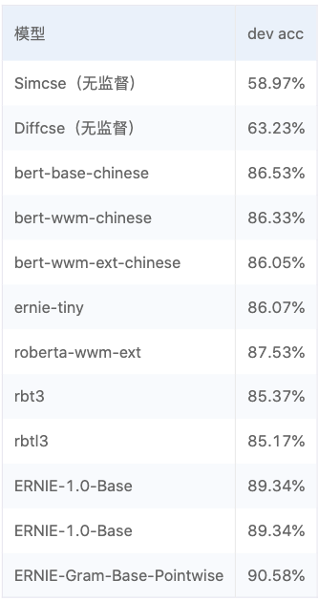
结论如下:
-
SimCSE模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
相比于SimCSE模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE模型同样适合缺乏监督数据又有大量无监督数据的匹配和检索场景。
-
明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀。
受篇幅限制影响,这里不详细展开模型的对比详情,感兴趣的同学可以点击下方链接详细了解。同时欢迎同学们在飞桨AI Studio平台发挥自己的创造力和想象力。
-
项目链接
https://aistudio.baidu.com/aistudio/projectdetail/5456683?channelType=0&channel=0
-
项目合集
https://aistudio.baidu.com/aistudio/projectdetail/5427356?contributionType=1
Part-2 未来展望
本项目主要围绕着特定领域知识图谱(Domain-specific Knowledge Graph,DKG)融合方案中的一环讲解了基于ERNIE-Garm的文本匹配算法。希望看到这篇项目的开发者们,能够在此基础上共同努力共建知识图谱领域,走通知识抽取、知识融合、知识推理和质量评估的完整流程。
参考文献
[1] Xin Liu, Qingcai Chen, Chong Deng, Huajun Zeng, Jing Chen, Dongfang Li, Buzhou Tang, LCQMC: A Large-scale Chinese Question Matching Corpus,COLING2018.
[2] Xiao, Dongling, Yu-Kun Li, Han Zhang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. “ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding.”ArXiv:2010.12148 [Cs].
相关文章:
基于飞桨实现的特定领域知识图谱融合方案:ERNIE-Gram文本匹配算法
文本匹配任务在自然语言处理领域中是非常重要的基础任务,一般用于研究两段文本之间的关系。文本匹配任务存在很多应用场景,如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等&…...
前端基础复习
1.什么叫HTML5?和原本的所说的HTML有什么区别? 本质上html和html5是一样的的。区别有: 1. 在文档类型声明上 HTML4.0 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loos…...

Vue2 API-源码解析
目录 Vue.extend(option) delimiters functional Vue.component(id, Function | Object) Vue.directive( id, [definition] ) Vue.filter( id, function) Vue.nextTick() Vue.set() Vue.delete(target, index/key) Vue.compile(template) Vue.observable(object) …...
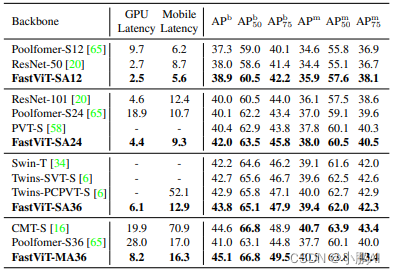
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization 论文地址:https://arxiv.org/pdf/2303.14189.pdf 概述 本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型 移动设备和 ImageNet 数据集上的精度相同的前提下…...

C/C++文档阅读笔记-A Simple Makefile Tutorial解析
Makefile文件可以使得程序编译变得简单。本博文并不是很系统的讲解makefile,本博文的目标是让读者快速编写自己的makefile文件并能应用到中小项目中。 简单实例 举个例子有下面3个文件,分别是hellomake.c,hellofunc.c,hellomake.…...

GraphSAGE的基础理论
文章目录GraphSAGE原理(理解用)GraphSAGE工作流程GraphSAGE的实用基础理论(编代码用)1. GraphSAGE的底层实现(pytorch)PyG中NeighorSampler实现节点维度的mini-batch GraphSAGE样例PyG中的SAGEConv实现2. …...

Windows 安装 GDAL C++库
Windows 安装 GDAL C库1. 方法1:下载配置网友编译的GDAL版本1.1 下载1.2 配置1.3 测试1.4 缺点2. 方法2:自己编译3. 参考1. 方法1:下载配置网友编译的GDAL版本 1.1 下载 CSDN: GDAL,geos联合编译的库,版本为1.8.0&am…...

二叉树基础概念
1.二叉树种类 1.1 满二叉树 满二叉树:如果一棵二叉树只有度为 0 0 0 的结点和度为 2 2 2 的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 如图所示: 这棵二叉树为满二叉树,也可以说深度为 k k k&…...

【MySQL】(1)数据库基础,库与表的增删查改,数据库的备份与还原
文章目录服务器,数据库,表关系MySQL 数据存储逻辑SQL 分类存储引擎库的操作查看数据库创建数据库查看创建语句删除数据库选择(切换)数据库查看当前选择的数据库修改数据库字符集和排序规则表的操作创建表查询表查询表结构插入数据…...

Python基础-01 变量
注释 注释的分类 在Python中,支持单行及多行注释 单行注释 使用#对代码进行说明,#右边的所有内容就是注释的内容,起辅助说明作用 # #右边的都是注释,解析器会忽略 print(hello world) #在控制台里打印一段话多行注释 多行注释中,允许换行,使用三个单引号开始,三个单引号结…...
springcloud2.1.0整合seata1.5.2+nacos2.10(附源码)
springcloud2.1.0整合seata1.5.2nacos2.10(附源码) 1.创建springboot2.2.2springcloud2.1.0的maven父子工程如下,不过多描述: 搭建过程中也出现很多问题,主要包括: 1.seataServer.properties配置文件的组…...

map原理
map源码结构体: type hmap struct {count int // 元素的个数B uint8 // buckets 数组的长度就是 2^B 个overflow uint16 // 溢出桶的数量buckets unsafe.Pointer // 2^B个桶对应的数组指针oldbuckets unsafe.Pointer // 发生扩容时࿰…...
概览)
[Ext JS]3.6 Ext JS 表格(Grid)概览
Grid, 翻译过来是网格, 也就是表格。 Grid 的基本构成 面板 :Ext.grid.Panel表格视图 :Ext.view.Table。 不直接使用, 通过面板的viewConfig配置项进行配置。比如可以用来配置表格中行是否跳色显示列: Ext.grid.column.Column。 表格中的列定义store , 表格的数据示例代码…...
关于使用云渲染的五大优势
在不影响质量或性能的情况下节省时间、金钱和资源,对于需要在通常较短且严格的期限内创建高质量 3D 内容的专业人士来说,云渲染都是最好的选择!云渲染作为数字媒体生产的最新趋势,与传统的渲染农场和机器相比具有许多优势…...

CSS基础样式
1.高度和宽度 .c1{height:300px;width:500px; } 注意事项: 宽度,支持百分比 行内标签:默认无效 块级标签:默认有效(右侧区域就算是空白,也不给占用) 2.块级和行内标签 css样式:标签…...

第03章_流程控制语句
第03章_流程控制语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模…...
配电网电压调节及通信联系研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

stegano(图片隐写、摩斯密码)
附件是PDF,我们在选择内容时发现光标溢出了文本 说明这里还存在一些我们看不到的内容 直接CtrlA全选,CtrlC复制后新建一个纯文本文件 将复制的东西粘贴过去 粘贴后发现果然多出来了一些东西,提取出来 BABA BBB BA BBA ABA AB B AAB ABAA A…...
wsl安装torch_geometric
在官网选择需要的版本 选择安装途径,选择runfile 执行第一行,会下载一个文件到目录下 需要降低C的版本,否则 执行sudo sh cuda_11.1.0_455.23.05_linux.run,会出现 查看对应的文件,会有 可以加上override参数之后,…...
ASP.NET Core - 依赖注入(二)
2,NET Core 依赖注入的基本用法 话接上篇,这一章介绍 .NET Core 框架自带的轻量级 Ioc 容器下服务使用的一些知识点,大家可以先看看上一篇文章 [ASP.NET Core - 依赖注入(一)] 2.3 服务解析 通过 IServiceCollection 注册了服务之后…...

EC35编码器驱动踩坑实录:从波形分析到稳定读取,我的GD32调试笔记
EC35编码器驱动踩坑实录:从波形分析到稳定读取的GD32调试笔记 1. 问题初现:那些让人抓狂的"玄学"现象 第一次把EC35编码器接到GD32F303开发板上时,我天真地以为这不过是个简单的GPIO中断应用。按照常规思路配置了三个引脚的中断&am…...

Obsidian i18n终极指南:3步实现插件界面中文化,告别英文困扰
Obsidian i18n终极指南:3步实现插件界面中文化,告别英文困扰 【免费下载链接】obsidian-i18n 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-i18n 你是否曾经因为Obsidian插件全是英文界面而感到困惑?每次打开设置页面&…...

BMS通信CAN收发芯片
BMS中一个很重要的功能是通信,获取电池数据,将BMU和BCM的数据上传给整车或上级控制单元,并根据整车或上级控制单元的指令执行相应动作。这个数据传输最常用的是CAN通信,今天介绍一款我们在使用的成熟可靠的CAN收发芯片。SIT1050&a…...

RAG夺命10连问,你能抗住第几问?
前言最近金三银四,很多小伙伴在准备大厂面试,几乎每个人都被问到了同一个技术点——RAG(检索增强生成)。从阿里到字节,从腾讯到美团,RAG已经成为大模型应用方向必考的“压轴题”。但是,很多求职…...

C语言变量与运算符详解:从内存管理到高效编程实践
1. 从零到一:为什么C语言是程序员的“内功心法”?如果你刚看完系列的第一篇,对C语言有了一个模糊的印象,觉得它古老、复杂,甚至有点“过时”,那太正常了。我刚开始接触编程时,也这么想。为什么放…...

5分钟快速上手:使用免费在线EPUB编辑器制作专业电子书
5分钟快速上手:使用免费在线EPUB编辑器制作专业电子书 【免费下载链接】EPubBuilder 一款在线的epub格式书籍编辑器 项目地址: https://gitcode.com/gh_mirrors/ep/EPubBuilder 你是否梦想过出版自己的电子书,却被复杂的EPUB格式和技术门槛吓退&a…...

NewJob智能识别插件:求职时间管理的终极解决方案
NewJob智能识别插件:求职时间管理的终极解决方案 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending/ne/NewJob 在…...

Perplexity搜索响应延迟超800ms?揭秘底层向量重排序瓶颈及4种实时优化方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索响应延迟超800ms?揭秘底层向量重排序瓶颈及4种实时优化方案 当Perplexity类RAG系统在高并发场景下出现端到端响应延迟突破800ms时,性能剖析常指向一个被低估的环节…...

好想来万店扩张背后的数据新底座
在中国量贩零食行业的版图上,好想来正以雷霆之势重塑市场格局。作为万辰集团旗下的头部品牌,好想来已在全国布局超过 1.5 万家门店,注册会员超过 1.5 亿,年营收突破 365 亿元,成为名副其实的零售巨擘。这些令人瞩目的数…...

告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡
告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡 在手机摄影普及的今天,我们常常会遇到这样的困扰:夜间拍摄的照片要么噪点明显,要么经过降噪处理后变得模糊不清,丢失了细节…...