Scala模式匹配
Scala中有一个非常强大的模式匹配机制,应用也非常广泛, 例如:
-
判断固定值
-
类型查询
-
快速获取数据
简单模式匹配
一个模式匹配包含了一系列备选项,每个备选项都开始于关键字 case。且每个备选项都包含了一个模式及一到多个表达式。箭头符号 => 隔开了模式和表达式。
格式:
变量 match {case "常量 1 " => 表达式 1case "常量 2 " => 表达式 2case "常量 3 " => 表达式 3case _ => 表达式 4 // 默认匹配项}执行流程
-
先执行第一个case, 看变量值和该case对应的常量值是否一致.
-
如果一致, 则执行该case对应的表达式.
-
如果不一致, 则往后执行下一个case, 看变量值和该case对应的常量值是否一致.
-
以此类推, 如果所有的case都不匹配, 则执行case _对应的表达式.
需求:
-
提示用户录入一个单词并接收.
-
判断该单词是否能够匹配以下单词,如果能匹配,返回一句话
-
打印结果.
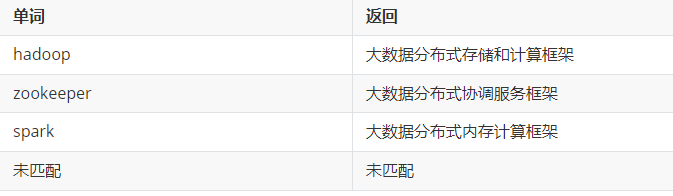
代码示例:
package test11import scala.io.StdInobject Test2 {def main(args: Array[String]): Unit = {println("请输入一个字符串")val str = StdIn.readLine()val result = str match {case "hadoop" => "大数据分布式存储和计算框架"case "zookeeper" => "大数据分布式协调服务框架"case "spark" => "大数据分布式内存计算框架"case _ => "未匹配"}println(result)//简写形式val result2 = str match {case "hadoop" => println("大数据分布式存储和计算框架")case "zookeeper" => println("大数据分布式协调服务框架")case "spark" => println("大数据分布式内存计算框架")case _ => println("未匹配")}}}
匹配类型
除了匹配数据之外, match表达式还可以进行类型匹配。如果我们要根据不同的数据类型,来执行不同的逻辑,也可以使用match表达式来实现。
格式:
对象名 match {case 变量名 1 : 类型 1 => 表达式 1case 变量名 2 : 类型 2 => 表达式 2case 变量名 3 : 类型 3 => 表达式 3...case _ => 表达式 4
}需求
-
定义一个变量为Any类型,然后分别给其赋值为"hadoop"、 1 、1.0
-
定义模式匹配,然后分别打印类型的名称
代码示例:
package test11object Test3 {def main(args: Array[String]): Unit = {// val a: Any = 1.0// val a: Any = "hello"val a: Any = 1val result = a match {case x: String => s"$x 是String类型的数据"case x: Double => s"$x 是Double类型的数据"case x: Int => s"$x 是Int类型的数据"case _ => "未匹配"}println(result)// 4. 优化版, 如果在case校验的时候, 变量没有被使用, 则可以用_替代.val result1 = a match {case _: String => "String"case _: Int => "Int"case _: Double => "Double"case _ => "未匹配"}println(result1)}
}
守卫
所谓的守卫指的是在case语句中添加if条件判断, 这样可以让我们的代码更简洁, 更优雅.
格式
变量 match {case 变量名 if条件 1 => 表达式 1case 变量名 if条件 2 => 表达式 2case 变量名 if条件 3 => 表达式 3...case _ => 表达式 4}需求
-
从控制台读入一个数字a(使用StdIn.readInt)
-
如果 a >= 0 而且 a <= 3,打印[0-3]
-
如果 a >= 4 而且 a <= 8,打印[4,8]
-
否则,打印未匹配
package test11import scala.io.StdInobject Test4 {def main(args: Array[String]): Unit = {println("请输入一个整数:")val num = StdIn.readInt()num match {case a if a >= 0 && a <= 3 => println("[0 - 3]")case a if a >= 4 && a <= 8 => println("[4 - 8]")case _ => println("不匹配")}}
}
匹配样例类
Scala中可以使用模式匹配来匹配样例类,从而实现可以快速获取样例类中的成员数据。后续,我们在开发Akka案例时,还会经常用到。
格式
对象名 match {case 样例类型 1 (字段 1 , 字段 2 , 字段n) => 表达式 1case 样例类型 2 (字段 1 , 字段 2 , 字段n) => 表达式 2case 样例类型 3 (字段 1 , 字段 2 , 字段n) => 表达式 3...case _ => 表达式 4}注意:
-
样例类型后的小括号中, 编写的字段个数要和该样例类的字段个数保持一致.
-
通过match进行模式匹配的时候, 要匹配的对象必须声明为: Any类型.
需求
-
创建两个样例类Customer(包含姓名, 年龄字段), Order(包含id字段)
-
分别定义两个样例类的对象,并指定为Any类型
-
使用模式匹配这两个对象,并分别打印它们的成员变量值
代码示例:
package test11object Test5 {case class Customer(var name: String, var age: Int)case class Order(id: Int)def main(args: Array[String]): Unit = {val c: Any = Customer("Tom", 23)val o: Any = Order(123)val arr: Any = Array(0, 1)c match {case Customer(a, b) => println(s"Customer类型的对象,name=$a,age=$b")case Order(c) => println(s"Order类型,id=$c")case _ => println("未匹配")}o match {case Customer(a, b) => println(s"Customer类型的对象,name=$a,age=$b")case Order(c) => println(s"Order类型,id=$c")case _ => println("未匹配")}arr match {case Customer(a, b) => println(s"Customer类型的对象,name=$a,age=$b")case Order(c) => println(s"Order类型,id=$c")case _ => println("未匹配")}}
}
匹配集合
除了上述功能之外, Scala中的模式匹配,还能用来匹配数组, 元组, 集合(列表, 集, 映射)等。
匹配数组
package test11object Test6 {def main(args: Array[String]): Unit = {val arr1 = Array(1, 2, 3)val arr2 = Array(0)val arr3 = Array(1, 2, 4, 5, 6, 7)arr1 match {case Array(1, x, y) => println(s"匹配长度为 3 , 首元素为 1 , 后两个元素是: $x, $y")case Array(0) => println("匹配只有一个0元素的数组")case Array(1, _*) => println("匹配:第一个元素是1,后边的元素随意")case _ => println("未匹配")}arr2 match {case Array(1, x, y) => println(s"匹配长度为 3 , 首元素为 1 , 后两个元素是: $x, $y")case Array(0) => println("匹配只有一个0元素的数组")case Array(1, _*) => println("匹配:第一个元素是1,后边的元素随意")case _ => println("未匹配")}arr3 match {case Array(1, x, y) => println(s"匹配长度为 3 , 首元素为 1 , 后两个元素是: $x, $y")case Array(0) => println("匹配只有一个0元素的数组")case Array(1, _*) => println("匹配:第一个元素是1,后边的元素随意")case _ => println("未匹配")}}
}
匹配列表
package test11object Test7 {def main(args: Array[String]): Unit = {val list1 = List(0)val list2 = List(0, 1, 2, 3, 4, 5)val list3 = List(1, 2)list1 match {case List(0) => println("匹配: 只有一个0元素的列表")case List(0, _*) => println("匹配: 0开头,后边元素无所谓的列表")case List(x, y) => println(s"匹配:只有俩个元素的列表,元素为:$x,$y")case _ => println("未匹配")}//思路二: 采用关键字优化 Nil, taillist1 match {case 0 :: Nil => println("匹配: 只有一个 0 元素的列表")case 0 :: tail => println("匹配: 0 开头, 后边元素无所谓的列表")case x :: y :: Nil => println(s"匹配: 只有两个元素的列表, 元素为: $x, $y")case _ => println("未匹配")}list2 match {case List(0) => println("匹配: 只有一个0元素的列表")case List(0, _*) => println("匹配: 0开头,后边元素无所谓的列表")case List(x, y) => println(s"匹配:只有俩个元素的列表,元素为:$x,$y")case _ => println("未匹配")}list3 match {case List(0) => println("匹配: 只有一个0元素的列表")case List(0, _*) => println("匹配: 0开头,后边元素无所谓的列表")case List(x, y) => println(s"匹配:只有俩个元素的列表,元素为:$x,$y")case _ => println("未匹配")}}
}
匹配元组
package test11object Test8 {def main(args: Array[String]): Unit = {val a = (1, 2, 3)val b = (3, 4, 5)val c = (3, 4)a match {case (1, x, y) => println(s"匹配:长度为3,以1开头,后面俩个元素随意的元组,这里的后俩个元素是:$x,$y")case (x, y, 5) => println(s"匹配:长度为3,以5结尾,前边俩个元素随意的元组,这里的前俩个元素是:$x,$y")case _ => println("未匹配")}}
}
变量声明中的模式匹配
在定义变量时,可以使用模式匹配快速获取数据. 例如: 快速从数组,列表中获取数据.
package test11object Test9 {def main(args: Array[String]): Unit = {val arr = (0 to 10).toArray//使用模式匹配分别获取第二个、第三个、第四个元素val Array(_, x, y, z, _*) = arrprintln(x, y, z)val list = (0 to 10).toList// 使用模式匹配分别获取第一个、第二个元素val List(a, b, _*) = list// 使用模式匹配分别获取第一个、第二个元素val c :: d :: tail = listprintln(a, b)println(c, d)}}
匹配for表达式
Scala中还可以使用模式匹配来匹配for表达式,从而实现快速获取指定数据, 让我们的代码看起来更简洁, 更优雅.
需求
-
定义变量记录学生的姓名和年龄, 例如: "张三" -> 23, "李四" -> 24, "王五" -> 23, "赵六" -> 26
-
获取所有年龄为 23 的学生信息, 并打印结果.
package test11object Test10 {def main(args: Array[String]): Unit = {val map1 = Map("张三" -> 23, "李四" -> 24, "王五" -> 23, "赵六" -> 26)for ((k, v) <- map1 if v == 23) println(s"$k = $v")println("-" * 15)for ((k, 23) <- map1) println(k + " = 23")}
}
相关文章:
Scala模式匹配
Scala中有一个非常强大的模式匹配机制,应用也非常广泛, 例如: 判断固定值 类型查询 快速获取数据 简单模式匹配 一个模式匹配包含了一系列备选项,每个备选项都开始于关键字 case。且每个备选项都包含了一个模式及一到多个表达式。箭头符号 > 隔开…...

银行数仓分层架构
一、为什么要对数仓分层 实现好分层架构,有以下好处: 1清晰数据结构: 每一个数据分层都有对应的作用域,在使用数据的时候能更方便的定位和理解。 2数据血缘追踪: 提供给业务人员或下游系统的数据服务时都是目标数据&…...

Go并发编程的学习代码示例:生产者消费者模型
文章目录 前言代码仓库核心概念main.go(有详细注释)结果总结参考资料作者的话 前言 Go并发编程学习的简单代码示例:生产者消费者模型。 代码仓库 yezhening/Programming-examples: 编程实例 (github.com)Programming-examples: 编程实例 (g…...

求a的n次幂
文章目录 求a的n次幂程序设计程序分析求a的n次幂 【问题描述】要求利用书上介绍的从左至右二进制幂算法求a的n次幂; 【输入形式】输入两个正整数,一个是a,一个是n,中间用空格分开 【输出形式】输出一个整数 【样例输入】2 10 【样例输出】1024 【样例输入】3 4 【样例输出】…...

word脚标【格式:第X页(共X页)】
不得不吐槽一下这个论文,真的我好头疼啊。我又菜又不想改。但是还是得爬起来改 (是谁大半夜不能睡觉加班加点改格式啊) 如何插入页码。 格式、要求如下: 操作步骤: ①双击页脚,填好格式,宋体小四和居中都…...
Linux --- 软件安装、项目部署
一、软件安装 1.1、软件安装方式 在Linux系统中,安装软件的方式主要有四种,这四种安装方式的特点如下: 1.2、安装JDK 上述我们介绍了Linux系统软件安装的四种形式,接下来我们就通过第一种(二进制发布包)形式来安装 JDK。 JDK…...

MATLAB应用笔记
其他 1、NaN值 MATLAB判断数据是否为NaN可以直接使用函数:isnan() 三、数据分析 1、相关性 均值、方差、协方差、标准差、相关系数 mean() %均值 nanmean()%去除NAN值求均值 var() %方差 cov() %协方差 std() %标准差 corrcoef(B,b) %R 相关系数plot()…...

ERTEC200P-2 PROFINET设备完全开发手册(6-2)
6.2 诊断与报警实验 首先确认固件为 App1_STANDARD, 将宏定义改为: #define EXAMPL_DEV_CONFIG_VERSION 1 参照第6节的内容,编译和调试固件,并在TIA Portal 中建立RT项目。启动固件后,TIA Portal 切换到在线,可以看…...

算法套路八——二叉树深度优先遍历(前、中、后序遍历)
算法套路八——二叉树深度优先遍历(前、中、后序遍历) 算法示例:LeetCode98:验证二叉搜索树 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只…...
视频批量剪辑:如何给视频添加上下黑边并压缩视频容量。
视频太多了,要如何进行给视频添加上下黑边并压缩视频容量?今天就由小编来教教大家要如何进行操作,感兴趣的小伙伴们可以来看看。 首先,我们要进入视频剪辑高手主页面,并在上方板块栏里选择“批量剪辑视频”板块&#…...

那些你需要知道的互联网广告投放知识
作为一个合格的跨境电商卖家,我们除了有好的产品之外,还要知道怎么去营销我们自己的产品。没有好的推广,即使你的产品有多好别人也是很难看得到的。今天龙哥就打算出一期基础的互联网广告投放科普,希望可以帮到各位增加多一点相关…...
【hello Linux】进程程序替换
目录 1. 程序替换的原因 2. 程序替换原理 3. 替换函数 4. 函数解释 5. 命名理解 6.简陋版shell的制作 补充: Linux🌷 1. 程序替换的原因 进程自创建后只能执行该进程对应的程序代码,那么我们若想让该进程执行另一个“全新的程序”这 便要用…...
【网络应用开发】实验4——会话管理
目录 会话管理预习报告 一、实验目的 二、实验原理 三、实验预习内容 1. 什么是会话,一个会话的生产周期从什么时候,到什么时候结束? 2. 服务器是如何识别管理属于某一个特定客户的会话的? 3. 什么是Cookie,它的…...
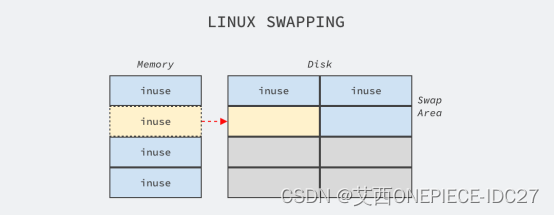
Linux服务器怎么分区
Linux服务器怎么分区 我是艾西,linux系统除了从业某个行业经常要用到的程序员比较熟悉,对于小白或只会用Windows系统的小伙伴还是会比较难上手的。今天艾西简单的跟大家聊聊linux系统怎么分区,让身为小白的你也能一眼看懂直接上手操作感受程序…...

传统机器学习(四)聚类算法DBSCAN
传统机器学习(四)聚类算法DBSCAN 1.1 算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在…...
)
“华为杯”研究生数学建模竞赛2020年-【华为杯】A题:ASIC 芯片上的载波恢复 DSP 算法设计与实现(附获奖论文及matlab代码实现)
目录 摘 要: 1.问题重述 1.1 问题背景 1.2 问题提出 1.3 研究基础 2.模型假设和已知...

1043.分隔数组以得到最大和
题目: 给你一个整数数组 arr,请你将该数组分隔为长度 最多 为 k 的一些(连续)子数组。分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值。 返回将数组分隔变换后能够得到的元素最大和。本题所用到的测试…...
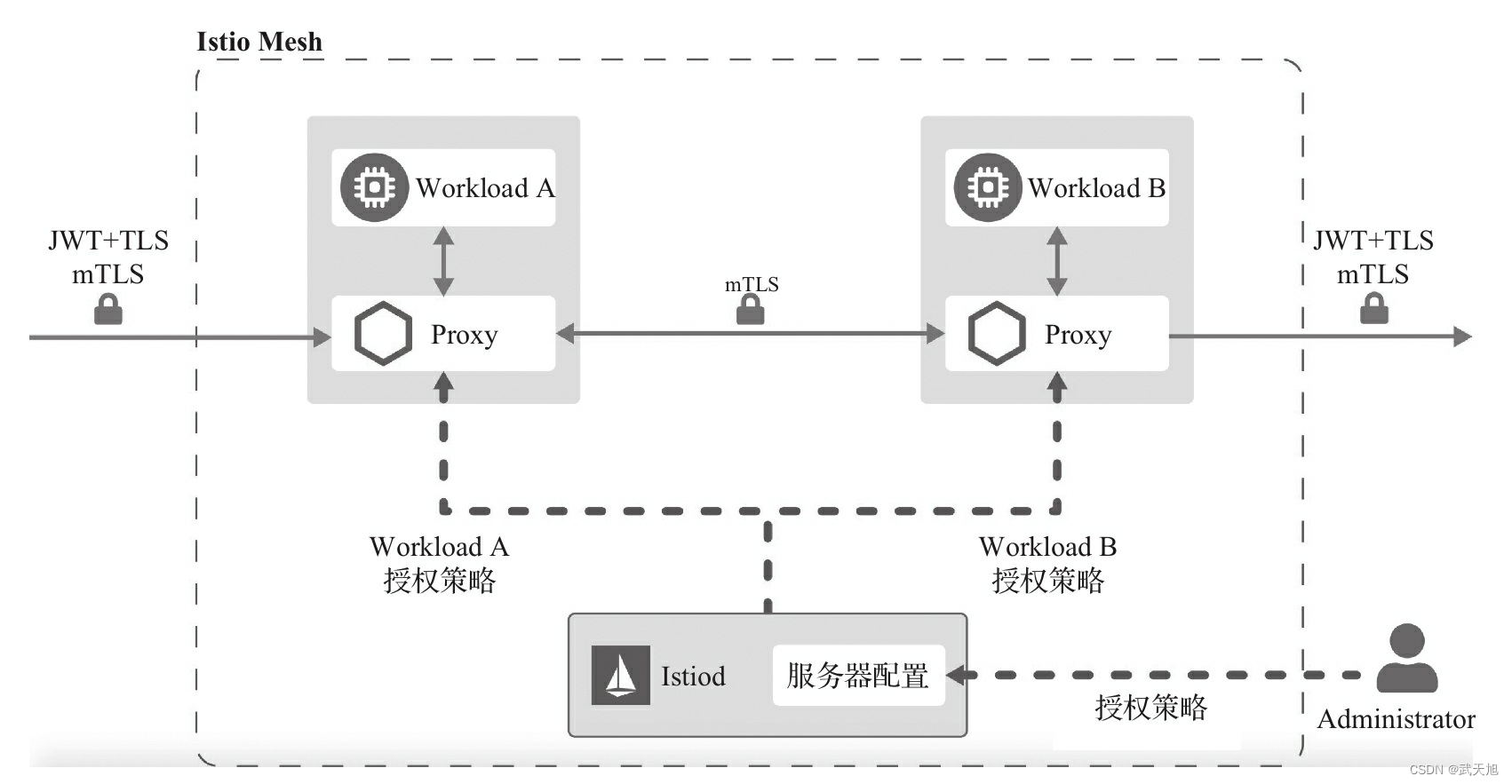
微服务治理框架(Istio)的认证服务与访问控制
本博客地址:https://security.blog.csdn.net/article/details/130152887 一、认证服务 1.1、基于JWT的认证 在微服务架构下,每个服务是无状态的,由于服务端需要存储客户端的登录状态,因此传统的session认证方式在微服务中不再适…...
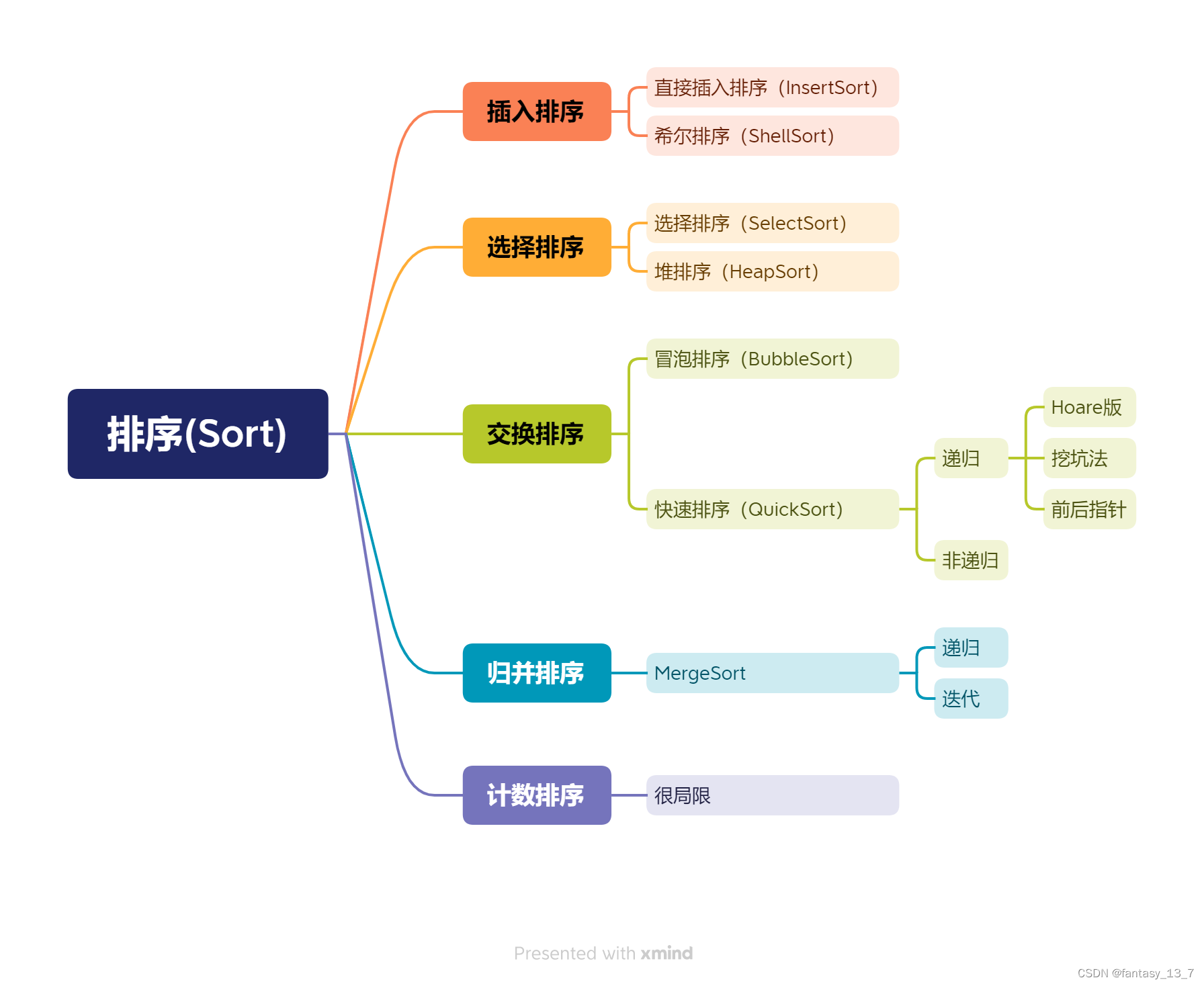
数据结构 | 排序 - 总结
排序的方式 排序的稳定性 什么是排序的稳定性? 不改变相同数据的相对顺序 排序的稳定性有什么意义? 假定一个场景: 一组成绩:100,88,98,98,78,100(按交卷顺序…...
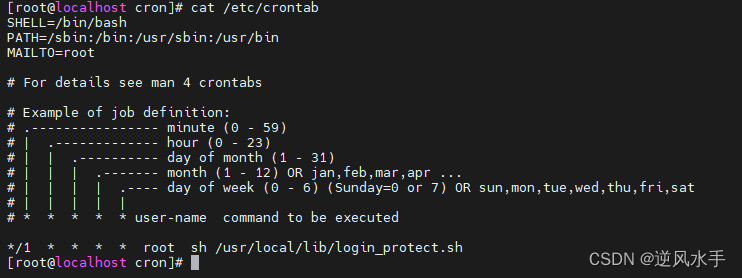
crontab -e 系统定时任务
crontab -e解释 crontab 是由 “cron” 和 “table” 两个单词组成的缩写。其中,“cron” 是一个在 Linux 和类 Unix 操作系统中用于定时执行任务的守护进程,而 “table” 则是指一个表格或者列表,因此 crontab 就是一个用于配置和管理定时任…...

word删除空白页
行距固定值,1磅...

从信息网络到能源网络:聊聊2012年那篇关于‘能源路由器’的论文,它今天还有哪些启发?
能源路由器的十年回望:从TCP/IP隐喻到虚拟电厂的现实启示 十二年前那篇将能源网络类比TCP/IP协议的论文,在今天看来更像是一封来自过去的预言书。当我们在2023年讨论虚拟电厂和分布式能源交易时,会发现那些曾被视作天马行空的构想——能源操作…...

为初创团队构建AI应用时如何利用Taotoken控制初期成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为初创团队构建AI应用时如何利用Taotoken控制初期成本 对于资源有限的初创团队而言,在开发AI功能原型时,最…...

Claude Code用户如何通过Taotoken解决封号与Token不足的困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户如何通过Taotoken解决封号与Token不足的困扰 1. 理解Claude Code的接入限制与Taotoken的解决方案 Claude Code作为…...
)
【新手向】:OpenClaw 本地 AI 智能体 Windows 部署教程(包含安装包)
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),凭借本地运行 零代码操作 自动执行任务的核心优势,成为实用型本地 …...

字节会师何恺明!开源连续扩散语言模型Cola DLM
一水 发自 凹非寺量子位 | 公众号 QbitAI大语言模型真的只能走“预测下一个token”的路子吗?继何恺明之后,字节也给出了同样的回答:NO。并且,两边都不约而同地盯上了同一个方向——在连续语义空间中建模语言。更关键的是ÿ…...

5分钟快速上手:OBS实时字幕插件终极配置指南
5分钟快速上手:OBS实时字幕插件终极配置指南 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 想要为你的直播或录播内容添加专业的实…...
)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例) 在嵌入式开发领域,HAL库因其跨平台兼容性和易用性广受欢迎,但对于追求极致性能和精简代码的开发者而言,标准库往往能带来更直接的硬件控制…...

【亲测免费】 Unity WebGL中文输入插件——为WebGL游戏开启无缝中文输入新时代!
Unity WebGL中文输入插件——为WebGL游戏开启无缝中文输入新时代! 【下载地址】UnityWebGL中文输入插件 本仓库提供了一个Unity WebGL中文输入插件,该插件支持输入法跟随和全屏功能。通过使用此插件,开发者可以在WebGL平台上实现中文输入&…...

LRC Maker终极指南:3分钟学会制作专业滚动歌词的免费神器
LRC Maker终极指南:3分钟学会制作专业滚动歌词的免费神器 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为歌词与音乐不同步而烦恼吗?想…...