【Python】Python中的列表,元组,字典
文章目录
- 列表
- 创建列表
- 获取元素
- 修改元素
- 添加元素
- 查找元素
- 删除元素
- 列表拼接
- 遍历列表
- 切片操作
- 元组
- 创建元组
- 元组中的操作
- 字典
- 创建字典
- 添加/修改元素
- 删除元素
- 查找
- 字典的遍历
- 合法的key类型
列表
列表是一种批量保存数据的方式,列表使用[]表示
创建列表
- 创建两个空列表
a = []
print(type(a))
b = list()
print(type(b))

- 还可以在创建列表时,给定一些初始值
a = [1, 2, 3]
- 列表中存放的元素可以是不同类型的
b = [1, 'hello', True, 3.14, [1, 2, 3]]
- 可以直接使用print函数打印列表
b = [1, 'hello', True, 3.14, [1, 2, 3]]
print(b)
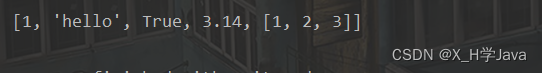
获取元素
- 可以通过下标的方式来获取指定位置元素,下标访问符
[]
a = [1, 2, 3]
print(a[1])

注意:下标是从0开始的,也就是0对应第一个元素,1对应第二个元素
- 如果下标越界,会抛出下标越界异常
a = [1, 2, 3]
print(a[10])

- 可以使用
len函数获取列表元素的个数
a = [1, 2, 3, 4]
print(len(a))
- 下标可以是负数,表示倒数第几个元素
a = [1, 2, 3, 4]
# 倒数第一个元素是4
print(a[-1])
修改元素
通过下标的方式可以修改值
a = [1, 2, 3, 4]
# 将倒数第一个元素修改为5
a[-1] = 5
print(a)

添加元素
- 使用
append方法进行尾插
a = [1, 2, 3, 4, 5]
a.append(6)
a.append(7)
print(a)
b = list()
b.append(1)
b.append(2)
print(b)

- 使用
insert方法向任意位置插入,这里的位置也是下标
a = [1, 2, 3]
# 向下标1插入hello,列表变为1,hello,2,3
a.insert(1, 'hello')
print(a)
查找元素
- 使用
in来判断元素是否在列表中
a = [1, 2, 'hello']
print(1 in a)
print(3 in a)
print('hello' in a)
print('world' in a)

- 使用
index函数,查找元素在列表中的下标,如果元素不存在,则会抛异常
a = [1, 2, 'hello']
print(a.index('hello'))
print(a.index(2))

元素不存在则抛出异常
a = [1, 2, 'hello']
print(a.index(3))

删除元素
- 使用
pop函数可以进行尾删
a = [1, 2, 'hello']
a.pop()
print(a)
a.pop()
print(a)

- 也可以为pop函数传入下标,按照下标删除
a = [1, 2, 3, 'hello']
a.pop(3)
print(a)

- 使用
remove函数,按照值删除
a = [1, 2, 3, 'hello']
a.remove(3)
a.remove('hello')
print(a)

列表拼接
- 使用
+可以拼接两个列表,使用+拼接,返回的是一个新列表,即原列表不受影响
a = [1, 2, 3]
b = [4, 5, 6]
print(a + b)

- 使用
extend方法把一个列表拼接到另一个列表后面,此时会改变拼接的列表
a = [1, 2, 3]
b = [4, 5, 6]
a.extend(b)
print(a)
print(b)
说明:将b列表拼接在a列表后面,即a列表发生变化,b列表不变

遍历列表
遍历列表就是从头往后依次获取列表中的每一个元素
- 使用for循环遍历
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for e in a:print(e)
- 使用for循环加下标
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for i in range(0,len(a)):print(a[i])
- 使用while循环遍历
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
i = 0
while i < len(a):print(a[i])i += 1
切片操作
通过下标是一次只能取出一个元素,而通过切片操作一次可取出一组连续的元素
- 使用
[:]进行切片操作
a = [1, 2, 3, 4, 5]
print(a[1:3])

说明:[1:3]表示由下标组成为[1,3)区间的下标集合,包含的下标有1,2,不包含3
切片操作也可以省略前后边界
- 省略后边界,表示获取到列表尾部
a = [1, 2, 3, 4, 5]
print(a[1:])

- 省略前边界,表示从列表头开始获取
a = [1, 2, 3, 4, 5]
# 从头开始直到倒数第一个(不包含倒数第一个)
print(a[:-1])

- 前后边界都省略,表示获取整个列表
a = [1, 2, 3, 4, 5]
print(a[:])

- 切片操作还可以指定步长,表示访问一个元素,下标增加几步
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 从下标1开始直到8(不包含8),每隔两个长度打印
print(a[1:8:2])

- 切片操作的步长还可以是负数,表示从后往前取元素
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 此时下标范围为[8,1)(从后往前)
print(a[8:1:-2])

- 如果切片操作中的数字越界了,不会有负面影响,会尽可能把满足条件的元素获取到
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[8:100])

元组
元组和列表相似,只是列表中的元素可以被修改,而元组中的元素不可修改,也就是元组一旦确定,就只能进行读操作,不可以进行修改操作,元组使用
()表示
创建元组
# 创建两个空元组
a = ()
b = tuple()
在创建元组时进行初始化
a = (1, 2, 'hello', 3.14, True)
元组中的操作
元组与列表类似,只是元组一旦定义则不能修改其中的元素
- 像读操作,比如切片操作,遍历,in,index,+等,元组是支持的
- 像写操作,比如添加元素,删除元素,修改元素,extend等,元组是不支持的
对于读之类的操作,和上述列表操作类似,此处不过多介绍,具体操作参照上述列表操作
- 元组在Python中很多时候是默认的集合类型,如函数返回多个值时
def method():return 10, 20
ret = method()
print(type(ret))

有了列表,为什么还需要元组?
- 你有一个列表,现在需要调用一个函数进行一些处理,但是你有不是特别确认这个函数是否会
把你的列表数据弄乱,那么这时候传一个元组就安全很多 - 马上要介绍的字典,是一个键值对结构,要求字典的键必须是 “可hash对象” (字典本质上也
是一个hash表),而一个可hash对象的前提就是不可变,因此元组可以作为字典的键,但是列表
不行
字典
字典是一个存储键值对
key: value的结构,字典用{}表示
创建字典
键值对:键:值,多个键值对用,分割
# 创建两个空字典
a = {}
b = dict()
可以在创建的时候指定初始值,也可以使用print打印字典
a = {'name': '张三','gender': 'm','age': 20
}
print(a)

添加/修改元素
使用[]可以根据key来增加元素或者修改元素
- 如果key不存在,则为新增键值对
a = {'name': '张三','gender': 'm','age': 20
}
# class不存在,则为新增
a['class'] = 3
print(a)

- 如果key存在,则为修改
a = {'name': '张三','gender': 'm','age': 20
}
a['name'] = '李四'
print(a)

删除元素
使用pop方法根据key删除键值对
a = {'name': '张三','gender': 'm','age': 20
}
a.pop('name')
print(a)

查找
- 使用
in可以判断key是否在字典中存在
a = {'name': '张三','gender': 'm','age': 20
}
print('name' in a)
print('class' in a)

- 基于
[]使用key来获取value的值
a = {'name': '张三','gender': 'm','age': 20
}
print(a['name'])
print(a['age'])

- 如果key在字典中不存在,则会抛异常
a = {'name': '张三','gender': 'm','age': 20
}
print(a['class'])

字典的遍历
- 使用for循环获取到key,再通过key获取到value
a = {'name': '张三','gender': 'm','age': 20
}
for key in a:print(key, a[key])

- 使用keys方法可以获取字典中所有的key
a = {'name': '张三','gender': 'm','age': 20
}
print(a.keys())

说明:dict_keys是一个特殊的类型,专门用来表示字典所有的key
- 使用values方法可以获取字典中所有的value
a = {'name': '张三','gender': 'm','age': 20
}
print(a.values())

说明:dict_values和dict_keys类似,专门用来表示字典中所有的value
- 使用items方法可以获取到字典中所有的键值对
a = {'name': '张三','gender': 'm','age': 20
}
print(a.items())

说明:dict_items和dict_keys类似,专门用来表示字典中所有的键值对
合法的key类型
字典本质上是一个哈希表,而哈希表的key值是要求是“可哈希的”,也就是可以通过这个key计算出哈希值
- 可以使用hash函数计算出哈希值
- 可以计算出哈希值的类型就可以作为key
- int,float,str,bool,元组类型的走可以计算出哈希值,可以作为key
print(hash(3))
print(hash('hello'))
print(hash(True))
print(hash((1, 2, 3)))

- 列表不可以计算哈希值,不可以作为key
print(hash([1, 2, 3]))

- 字典不可以计算哈希值,无法作为key
print(hash({'name': 'zs', 'age': 10}))

相关文章:
【Python】Python中的列表,元组,字典
文章目录 列表创建列表获取元素修改元素添加元素查找元素删除元素列表拼接遍历列表切片操作 元组创建元组元组中的操作 字典创建字典添加/修改元素删除元素查找字典的遍历合法的key类型 列表 列表是一种批量保存数据的方式,列表使用[]表示 创建列表 创建两个空列…...
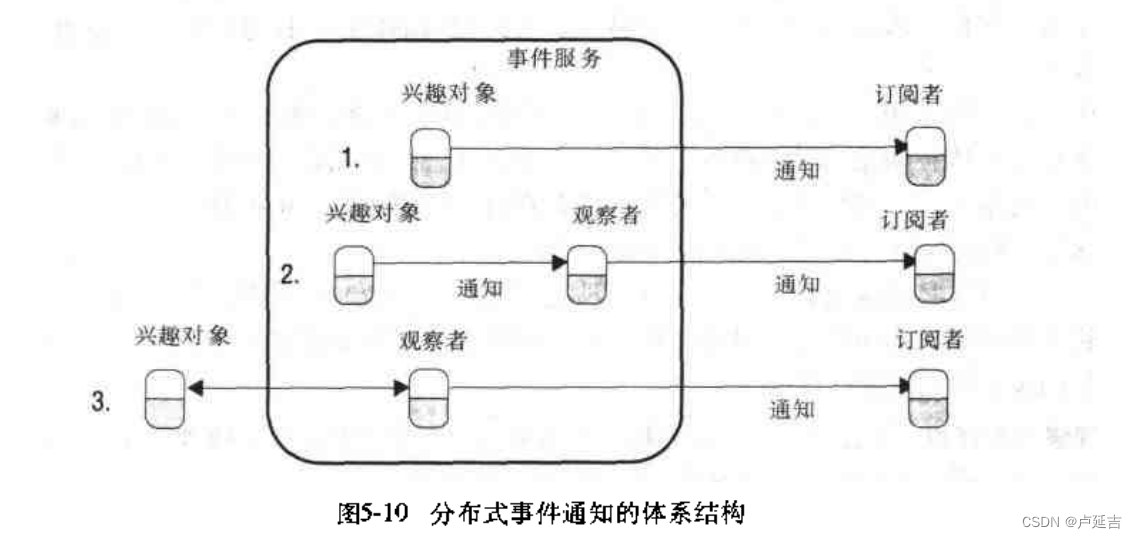
分布式系统概念和设计-分布式对象和远程调用
分布式系统概念和设计 分布式对象和远程调用 能够接收远程方法调用的对象称为远程对象,远程对象实现一个远程接口。 调用者和被调用对象分别存在不同的失败可能性,RMI和本地调用有不同的语义。 中间件 在进程和消息传递等基本构造模块之上提供编程模型的…...

11-FastDFS
一 为什么要使用分布式文件系统 单机时代 初创时期由于时间紧迫,在各种资源有限的情况下,通常就直接在项目目录下建立静态文件夹,用于用户存放项目中的文件资源。如果按不同类型再细分,可以在项目目录下再建立不同的子目录来区分…...

Word这样用,提高效率不加班
Word这样用,提高效率不加班 今天给大家分享23条Word文档的应用小技巧。对于大家来说,掌握些技巧能够效率百倍,何乐不为? 这些技巧是本人通过整理一直在用并且使用频率较高的,也希望能帮到大家。有兴趣的小伙伴可以自己…...

【Linux】调试器---gdb的使用
文章目录 一.背景知识二.安装gdb三.gdb的用法使用须知gdb的常用指令1.进入调试2.退出调试操作3.显示源代码4.设置断点breakPoint5.查看断点信息/禁用断点/开启断点/删除断点6.运行程序,开始调试run7.查看变量8.其它重要命令 一.背景知识 程序的发布方式有两种&…...
MySQL数据库之表的增删改查(进阶)
目录 1. 数据库约束1.1 约束类型1.2 NULL约束1.3 UNIQUE:唯一约束1.4 DEFAULT:默认值约束1.5 PRIMARY KEY:主键约束1.6 FOREIGN KEY:外键约束1.7 CHECK约束 2 表之间的关系2.1 一对一2.2 一对多2.3 多对多 3 新增4 查询4.1 聚合查…...

Nginx从开始到结束,简单到小白都能懂哦
绪论 大家好,很高兴能够为大家带来这篇关于Nginx配置的新手指南。在这篇博客中,我们将通过简单明了的图文教程,帮助大家快速上手Nginx配置,解锁Nginx的各种神奇功能! 一、Nginx简介 Nginx是一款功能强大的web服务器…...
)
Qt——Qt控件之按钮-QDialogButtonBox对话框按钮盒子控件的使用总结(例程:自定义按钮)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实战》...

数据库学习-常用的SQL语句
背景: 汇整一下自己学习数据库过程中常见的题目及语句。 一.实例分析题 二.简单SQL查询: 1):统计每个部门员工的数目select dept,count(*) from employee group by dept;2):统计每个部门员工的数目大于一个的记录se…...

5种获取JavaScript时间戳函数的方法
5种获取JavaScript时间戳函数的方法 一、JavasCRIPT时间转时间戳方法一:Date.now()方法二:Date.parse()方法三:valueOf()方法四:getTime()方法五:Number 二、js时间戳转时间方法一:生成2022/1/18 上午10:09…...

图的宽度优先遍历
文章目录 图的宽度优先遍历程序设计程序分析图的宽度优先遍历 【问题描述】根据输入图的邻接矩阵A,给出图的宽度优先遍历序列; 【输入形式】第一行为图的结点个数n,第二行输入顶点的信息,每个顶点用一个字符表示,接下来的n行为图的邻接矩阵A。其中A[i][j]=1表示两个结点邻…...
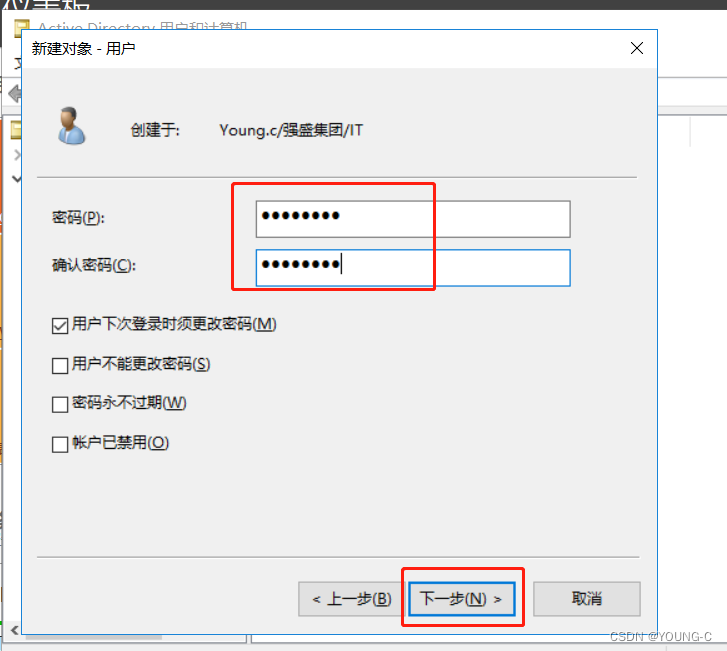
企业AD域(域控服务器)的安装和配置详细教程
一、环境以及工具准备 软件:VMWare Workstation 2016 ( 下载链接:https://pan.baidu.com/s/1iX1VRilerYPGbGvX4pvaKw 提取码:75R6 ) 镜像:Windows Server 2016 ( 下载地址ÿ…...

面试官:一千万的数据,你是怎么查询的?
面试官:一千万的数据,你是怎么查询的? 1 先给结论 对于1千万的数据查询,主要关注分页查询过程中的性能 针对偏移量大导致查询速度慢: 先对查询的字段创建唯一索引 根据业务需求,先定位查询范围(…...
IntelliJ 上 Azure Event Hubs 全新支持来了!
大家好,欢迎来到 Java on Azure Tooling 的3月更新。在这次更新中,我们将介绍 Azure Event Hubs 支持、Azure Functions 的模板增强,以及在 IntelliJ IDEA 中部署 Azure Spring Apps 时的日志流改进。要使用这些新功能,请下载并安…...
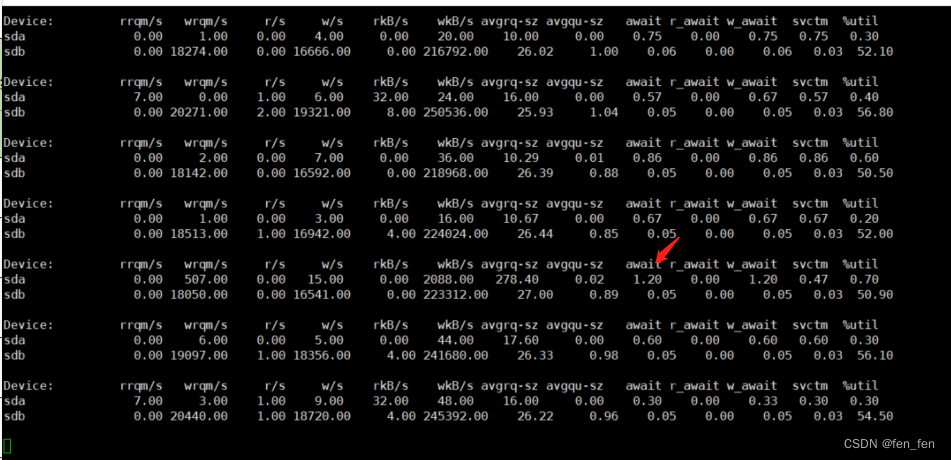
性能测试,监控磁盘读写iostat
性能测试,监控磁盘读写iostat iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出 CPU使用情况。同vmstat一样,ios…...

steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解
steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解 大家好,我是童话姐姐,今天继续来聊Steam搬砖项目。 Steam搬砖项目也叫CSGO搬砖项目,它并不是什么刚面世的新项目,是已经存在至少七八年的一个资深老牌项目。这个项目…...

协同运力、算力、存力,加速迈向智能世界
2023年4月20日,华为在HAS2023期间举办“迈向智能世界”主题论坛,吸引了来自全球的分析师、专家学者及媒体与会。会上,华为ICT战略与Marketing总裁彭松发表了“持续技术创新,加速迈向智能世界”的主题演讲。 华为ICT战略与Marketin…...

被裁员了,要求公司足额补缴全部公积金,一次补了二十多万!网友兴奋了,该怎么操作?...
被裁员后,能要求公司补缴公积金吗? 一位网友问: 被裁员了,要求公司把历史公积金全部足额缴纳,现在月薪2.3万,但公司每个月只给自己缴纳300元公积金,结果一次补了二十多万,一次性取出…...
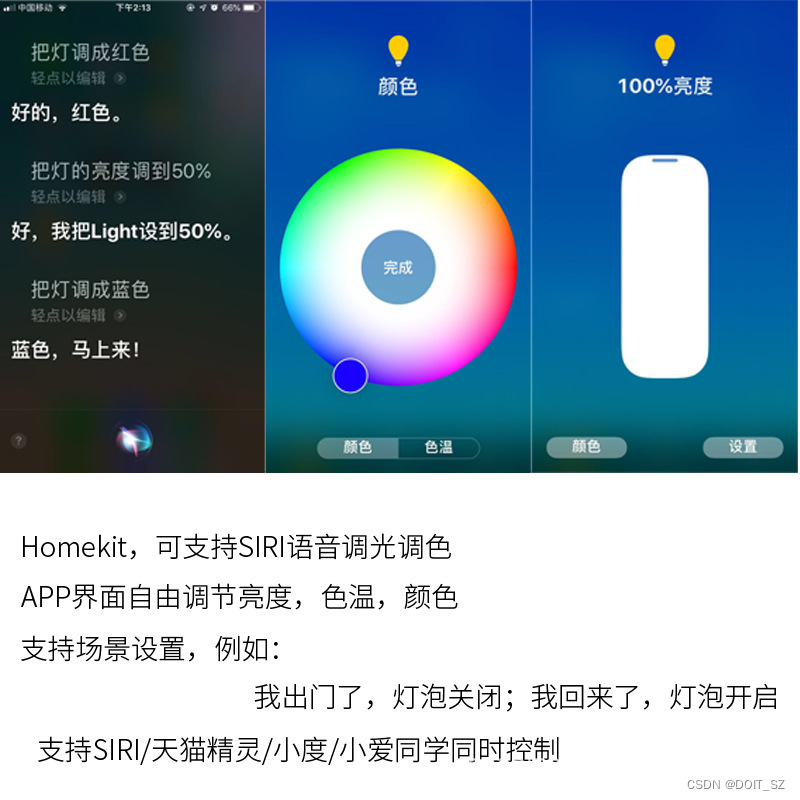
家庭智能插座一Homekit智能
传统的灯泡是通过手动打开和关闭开关来工作。有时,它们可以通过声控、触控、红外等方式进行控制,或者带有调光开关,让用户调暗或调亮灯光。 智能灯泡内置有芯片和通信模块,可与手机、家庭智能助手、或其他智能硬件进行通信&#x…...
什么是雪花算法?啥原理?
1、SnowFlake核心思想 SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的…...

基于LabVIEW与麦克风阵列的实时噪声源定位系统设计与实践
1. 项目概述:从“听见”到“看见”噪声在工业现场、产品研发或环境监测中,我们常常遇到一个棘手的问题:噪声到底是从哪里来的?传统的单点声压级测量只能告诉我们“这里有多吵”,却无法回答“是谁在吵”以及“它在哪里吵…...

5种高效集成方案:Bilibili视频解析API的终极实用指南
5种高效集成方案:Bilibili视频解析API的终极实用指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款基于PHP实现的B站视频解析API工具,通过简洁优雅的技…...

使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点 基础教程类,面向团队技术负责人,介绍如何通过…...

Mission Planner地面站保姆级教程:给Pixhawk刷固件、校准传感器到成功解锁起飞
Mission Planner地面站全流程实战:从固件刷写到安全起飞的终极指南 当第一次拿到Pixhawk飞控时,许多爱好者都会面临同样的困惑——如何将这块电路板变成可靠的飞行大脑?本文将用工程师视角拆解整个配置流程,分享那些官方手册没写清…...

如何构建基于UNet的眼底血管图像分割系统
如何构建基于UNet的眼底血管图像分割系统 文章目录1. 数据预处理2. 定义UNet模型3. 训练过程4. 测试过程5. 日志记录1构建一个基于UNet的眼底血管图像分割系统涉及多个步骤,包括数据预处理、模型定义、训练过程、测试过程以及日志记录。下面是一个完整的指南&#x…...

基于改进型PCNN的不规则图像自适应分割算法研究
基于改进型PCNN的不规则图像自适应分割算法研究根据论文中的相关内容,以下是使用不同方法解决图像分割问题并进行改进的研究:冯登超等人提出了基于改进型脉冲耦合神经网络(PCNN)的自适应分割算法。他们在原有PCNN模型的基础上对神…...

KVQuant:突破LLM推理显存瓶颈的KV Cache量化技术详解
1. 项目概述:KVQuant是什么,以及它为何重要如果你最近在折腾大语言模型(LLM)的本地部署、微调或者推理优化,大概率已经对“KV Cache”这个名词不陌生了。随着模型参数规模从几十亿飙升到上千亿,推理过程中的…...

别再被Windows Defender误报了!手把手教你用PowerShell自制证书给EXE签名
别再被Windows Defender误报了!手把手教你用PowerShell自制证书给EXE签名 当你在深夜终于完成了一个自研小工具的编译,迫不及待地双击运行时,那个熟悉的红色警告框又弹了出来——"Windows Defender已阻止此程序运行"。作为开发者&…...

Minimax算法在技能学习中的应用:构建抗风险技术成长路径
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫justl9169/minimax-skills。光看名字,你可能会联想到“最小化-最大化”算法,也就是博弈论里那个经典的Minimax。没错,这个项目的核心灵感确实来源于此,但…...
动态加载)
PyQt5开发避坑:别再手动编译.ui文件了,试试uic.loadUi()动态加载
PyQt5高效开发:uic.loadUi()动态加载技术深度解析 在快速迭代的GUI开发过程中,PyQt5开发者常陷入一个效率陷阱——每次修改界面后都需要手动执行pyuic编译命令。这种重复性操作不仅打断开发流状态,还会在频繁调整阶段浪费大量时间。本文将揭示…...