面试官:一千万的数据,你是怎么查询的?
面试官:一千万的数据,你是怎么查询的?
1 先给结论
对于1千万的数据查询,主要关注分页查询过程中的性能
针对偏移量大导致查询速度慢:
先对查询的字段创建唯一索引
根据业务需求,先定位查询范围(对应主键id的范围,比如大于多少、小于多少、IN)
查询时,将第2步确定的范围作为查询条件
针对查询数据量大的导致查询速度慢:
查询时,减少不需要的列,查询效率也可以得到明显提升 一次尽可能按需查询较少的数据条数 借助nosql缓存数据等来减轻mysql数据库的压力
2 准备数据
2.1 创建表
CREATE TABLE `user_operation_log` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`ip` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`op_data` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr3` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr4` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr5` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr6` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr7` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr8` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr9` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr10` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr11` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`attr12` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;2.2 造数据脚本
采用批量插入,效率会快很多,而且每1000条数就commit,数据量太大,也会导致批量插入效率慢
DELIMITER ;;CREATE DEFINER=`root`@`%` PROCEDURE `batch_insert_log`()BEGINDECLARE i INT DEFAULT 1;DECLARE userId INT DEFAULT 10000000;set @execSql = 'INSERT INTO `big_data`.`user_operation_log`(`user_id`, `ip`, `op_data`, `attr1`, `attr2`, `attr3`, `attr4`, `attr5`, `attr6`, `attr7`, `attr8`, `attr9`, `attr10`, `attr11`, `attr12`) VALUES';set @execData = '';WHILE i<=10000000 DOset @attr = "rand_string(50)";set @execData = concat(@execData, "(", userId + i, ", '110.20.169.111', '用户登录操作'", ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ",", @attr, ")");if i % 1000 = 0thenset @stmtSql = concat(@execSql, @execData,";");prepare stmt from @stmtSql;execute stmt;DEALLOCATE prepare stmt;commit;set @execData = "";elseset @execData = concat(@execData, ",");end if;SET i=i+1;END WHILE;ENDDELIMITER ;
delimiter $$create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';declare chars_str varchar(100) default'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));set i = i + 1;end while;return return_str;end $$
2.3 执行存储过程函数
因为模拟数据流量是1000W,我这电脑配置不高,耗费了不少时间,应该个把小时吧
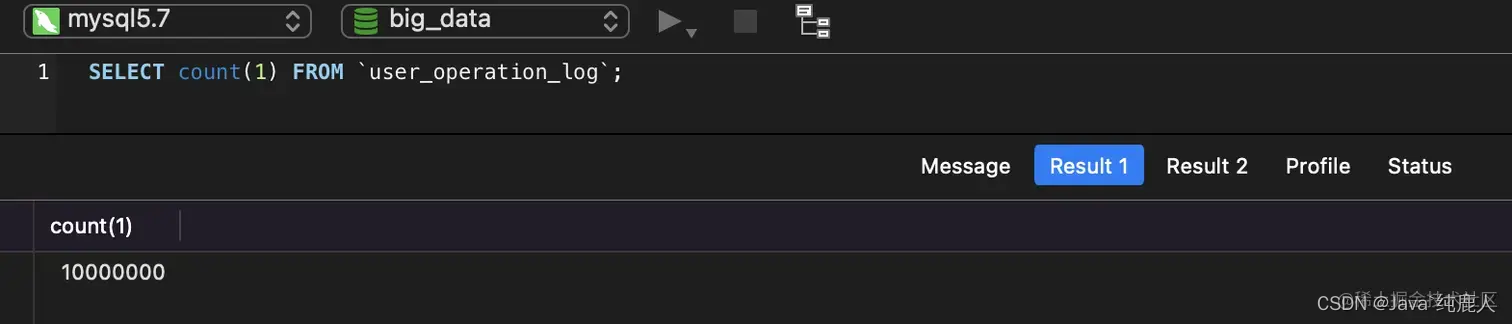
SELECT count(1) FROM `user_operation_log`;
2.4 普通分页查询
MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
MySQL分页查询语法如下:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
下面我们开始测试查询结果:
SELECT * FROM `user_operation_log` LIMIT 10000, 10;
查询3次时间分别为:
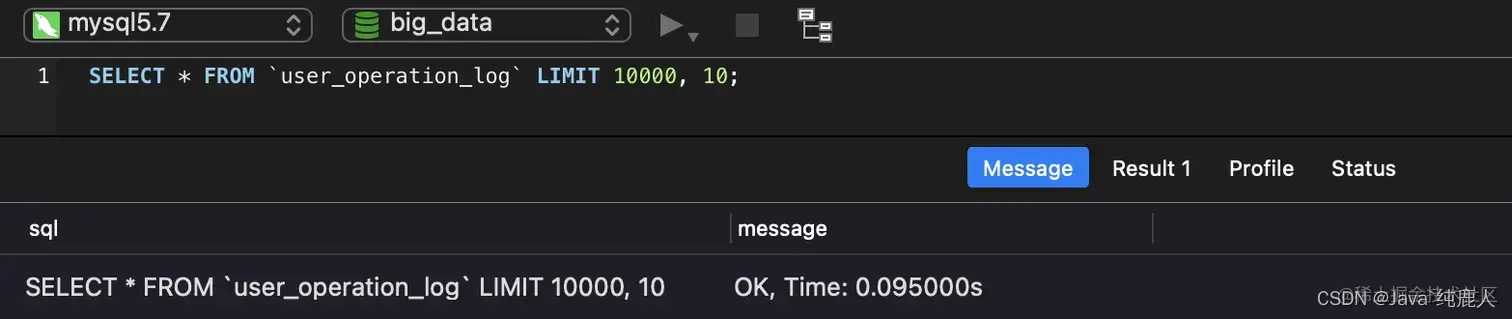


这样看起来速度还行,不过是本地数据库,速度自然快点。
换个角度来测试
相同偏移量,不同数据量
SELECT * FROM `user_operation_log` LIMIT 10000, 10;SELECT * FROM `user_operation_log` LIMIT 10000, 100;SELECT * FROM `user_operation_log` LIMIT 10000, 1000;SELECT * FROM `user_operation_log` LIMIT 10000, 10000;SELECT * FROM `user_operation_log` LIMIT 10000, 100000;SELECT * FROM `user_operation_log` LIMIT 10000, 1000000;
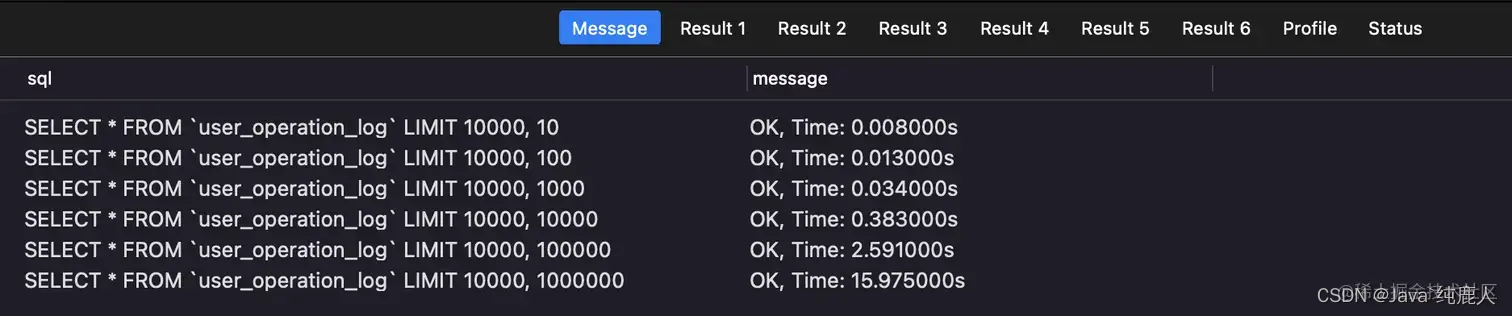
从上面结果可以得出结束:数据量越大,花费时间越长(这不是废话吗?)
相同数据量,不同偏移量
SELECT * FROM `user_operation_log` LIMIT 100, 100;SELECT * FROM `user_operation_log` LIMIT 1000, 100;SELECT * FROM `user_operation_log` LIMIT 10000, 100;SELECT * FROM `user_operation_log` LIMIT 100000, 100;SELECT * FROM `user_operation_log` LIMIT 1000000, 100;

从上面结果可以得出结束:偏移量越大,花费时间越长
3 如何优化
既然我们经过上面一番的折腾,也得出了结论,针对上面两个问题:偏移大、数据量大,我们分别着手优化
3.1 优化数据量大的问题
SELECT * FROM `user_operation_log` LIMIT 1, 1000000
SELECT id FROM `user_operation_log` LIMIT 1, 1000000
SELECT id, user_id, ip, op_data, attr1, attr2, attr3, attr4, attr5, attr6, attr7, attr8, attr9, attr10, attr11, attr12 FROM `user_operation_log` LIMIT 1, 1000000
查询结果如下:

上面模拟的是从1000W条数据表中 ,一次查询出100W条数据,看起来性能不佳,但是我们常规业务中,很少有一次性从mysql中查询出这么多条数据量的场景。可以结合nosql缓存数据等等来减轻mysql数据库的压力。
因此,针对查询数据量大的问题:
查询时,减少不需要的列,查询效率也可以得到明显提升 一次尽可能按需查询较少的数据条数 借助nosql缓存数据等来减轻mysql数据库的压力
第一条和第三条查询速度差不多,这时候你肯定会吐槽,那我还写那么多字段干啥呢,直接 * 不就完事了
注意本人的 MySQL 服务器和客户端是在同一台机器上,所以查询数据相差不多,有条件的同学可以测测客户端与MySQL分开
SELECT * 它不香吗?
在这里顺便补充一下为什么要禁止 SELECT *。难道简单无脑,它不香吗?
主要两点:
- 用 "SELECT * " 数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
- 增大网络开销,* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。特别是MySQL和应用程序不在同一台机器,这种开销非常明显。
3.2 优化偏移量大的问题
3.2.1 采用子查询方式
我们可以先定位偏移位置的 id,然后再查询数据
SELECT id FROM `user_operation_log` LIMIT 1000000, 1;
SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1) LIMIT 10;
查询结果如下:

这种查询效率不理想啊!!!奇怪,id是主键,主键索引不应当查询这么慢啊???
先EXPLAIN分析下sql语句:
EXPLAIN SELECT id FROM `user_operation_log` LIMIT 1000000, 1;
EXPLAIN SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1) LIMIT 10;
奇怪,走了索引啊,而且是主键索引,如下


带着十万个为什么和千万个不甘心,尝试给主键再加一层唯一索引
ALTER TABLE `big_data`.`user_operation_log`
ADD UNIQUE INDEX `idx_id`(`id`) USING BTREE;
由于数据量有1000W,所以,加索引需要等待一会儿,毕竟创建1000W条数据的索引,一般机器没那么快。
然后再次执行上面的查询,结果如下:
 天啊,这查询效率的差距不止十倍!!!
天啊,这查询效率的差距不止十倍!!!
再次EXPLAIN分析一下:


命中的索引不一样,命中唯一索引的查询,效率高出不止十倍。
结论:
对于大表查询,不要太相信主键索引能够带来多少的性能提升,老老实实根据查询字段,添加相应索引吧!!!
但是上面的方法只适用于id是递增的情况,如果id不是递增的,比如雪花算法生成的id,得按照下面的方式:
注意:
- 某些 mysql 版本不支持在 in 子句中使用 limit,所以采用了多个嵌套select
- 但这种缺点是分页查询只能放在子查询里面
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t);
查询所花费时间如下:

EXPLAIN一下
EXPLAIN SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t);

3.2.2 采用 id 限定方式
这种方法要求更高些,id必须是连续递增(注意是连续递增,不仅仅是递增哦),而且还得计算id的范围,然后使用 between,sql如下
SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100 LIMIT 100;
SELECT * FROM `user_operation_log` WHERE id >= 1000000 LIMIT 100;

可以看出,查询效率是相当不错的
注意:这里的 LIMIT 是限制了条数,没有采用偏移量
还是EXPLAIN分析一下
EXPLAIN SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100 LIMIT 100;
EXPLAIN SELECT * FROM `user_operation_log` WHERE id >= 1000000 LIMIT 100;


因此,针对分页查询,偏移量大导致查询慢的问题:
先对查询的字段创建唯一索引 根据业务需求,先定位查询范围(对应主键id的范围,比如大于多少、小于多少、IN) 查询时,将第2步确定的范围作为查询条件
相关文章:
面试官:一千万的数据,你是怎么查询的?
面试官:一千万的数据,你是怎么查询的? 1 先给结论 对于1千万的数据查询,主要关注分页查询过程中的性能 针对偏移量大导致查询速度慢: 先对查询的字段创建唯一索引 根据业务需求,先定位查询范围(…...
IntelliJ 上 Azure Event Hubs 全新支持来了!
大家好,欢迎来到 Java on Azure Tooling 的3月更新。在这次更新中,我们将介绍 Azure Event Hubs 支持、Azure Functions 的模板增强,以及在 IntelliJ IDEA 中部署 Azure Spring Apps 时的日志流改进。要使用这些新功能,请下载并安…...
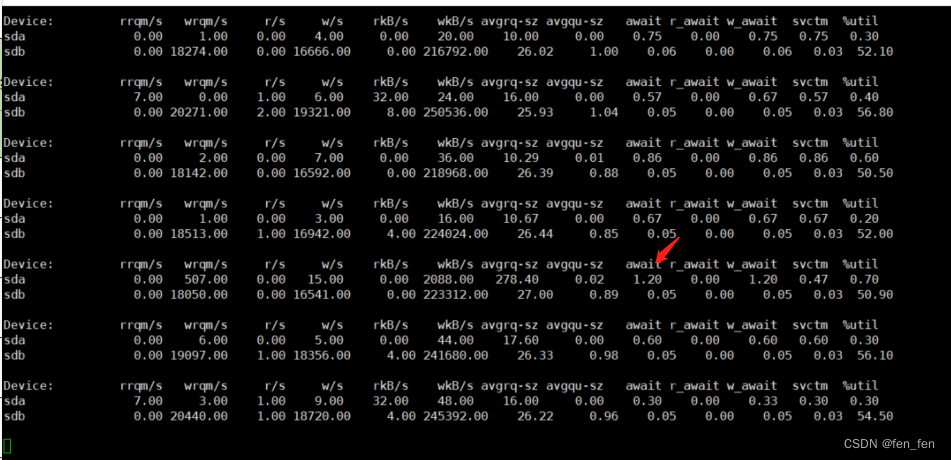
性能测试,监控磁盘读写iostat
性能测试,监控磁盘读写iostat iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出 CPU使用情况。同vmstat一样,ios…...

steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解
steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解 大家好,我是童话姐姐,今天继续来聊Steam搬砖项目。 Steam搬砖项目也叫CSGO搬砖项目,它并不是什么刚面世的新项目,是已经存在至少七八年的一个资深老牌项目。这个项目…...

协同运力、算力、存力,加速迈向智能世界
2023年4月20日,华为在HAS2023期间举办“迈向智能世界”主题论坛,吸引了来自全球的分析师、专家学者及媒体与会。会上,华为ICT战略与Marketing总裁彭松发表了“持续技术创新,加速迈向智能世界”的主题演讲。 华为ICT战略与Marketin…...

被裁员了,要求公司足额补缴全部公积金,一次补了二十多万!网友兴奋了,该怎么操作?...
被裁员后,能要求公司补缴公积金吗? 一位网友问: 被裁员了,要求公司把历史公积金全部足额缴纳,现在月薪2.3万,但公司每个月只给自己缴纳300元公积金,结果一次补了二十多万,一次性取出…...
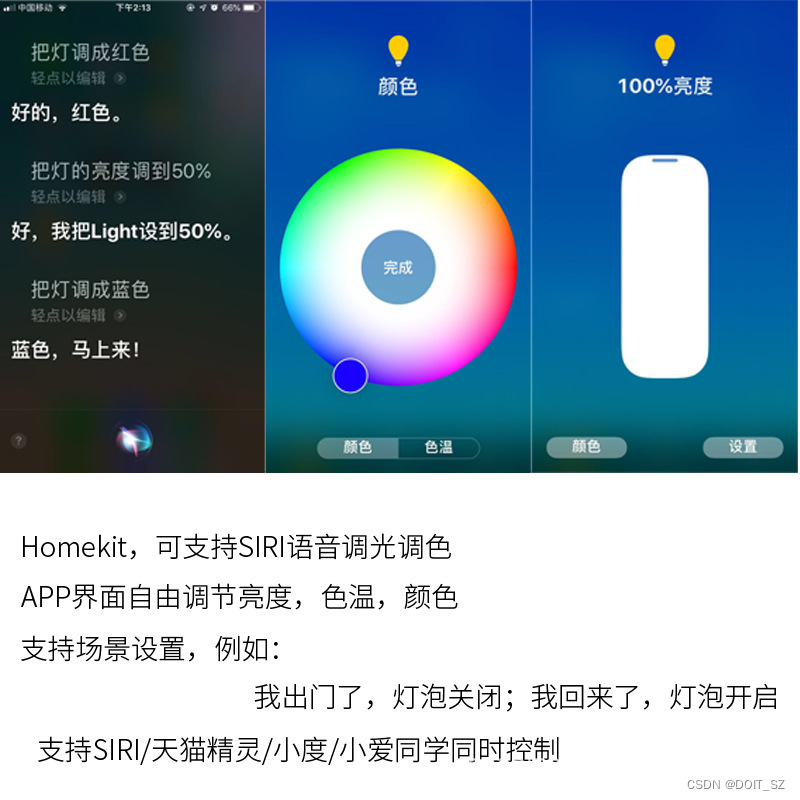
家庭智能插座一Homekit智能
传统的灯泡是通过手动打开和关闭开关来工作。有时,它们可以通过声控、触控、红外等方式进行控制,或者带有调光开关,让用户调暗或调亮灯光。 智能灯泡内置有芯片和通信模块,可与手机、家庭智能助手、或其他智能硬件进行通信&#x…...
什么是雪花算法?啥原理?
1、SnowFlake核心思想 SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的…...
)
【华为OD机试真题】 统计差异值大于相似值二元组个数(javapython)
统计差异值大于相似值二元组个数 知识点数组进制转换Q整数范围循环 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 题目描述:对于任意两个正整数A和B,定义它们之间的差异值和相似值: 差异值:A、B转换成二进制后,对于二进制的每一位,对应位置的bit值不相同则为…...

【cmake篇】选择编译器及设置编译参数
实际开发的过程中,可能有多个版本的编译器,不同功能可能需要设置不同的编译参数。 参考文章链接:选择编译器及设置编译器选项 目录 一、选择编译器 1、查看系统中已有的编译器 2、选择编译器的两种方式 二、设置编译参数 1、add_compil…...
MySQL having关键字详解、与where的区别
1、having关键字概览 1.1、作用 对查询的数据进行筛选 1.2、having关键字产生的原因 使用where对查询的数据进行筛选时,where子句中无法使用聚合函数,所以引出having关键字 1.3、having使用语法 having单独使用(不与group by一起使用&a…...

CSS中相对定位与绝对定位的区别及作用
CSS中相对定位与绝对定位的区别及作用 场景复现核心干货相对定位绝对定位子绝父相🔥🔥定位总结绝对定位与相对定位的区别 场景复现 在学习前端开发的过程中,熟练掌握页面布局和定位是非常重要的,因此近期计划出一个专栏ÿ…...

7.1 基本运放电路(1)
集成运放的应用首先表现在它能构成各种运算电路上,并因此而得名。在运算电路中,以输入电压作为自变量,以输出电压作为函数;当输入电压变化时,输出电压将按一定的数学规律变化,即输出电压反映输入电压某种运…...
交友项目【首页推荐,今日佳人,佳人信息】
目录 1:首页推荐 1.1:接口地址 1.2:流程分析 1.3:代码实现 2:今日佳人 1.1:接口地址 1.2:流程分析 1.3:代码实现 3:佳人信息 1.1:接口地址 1.2&am…...
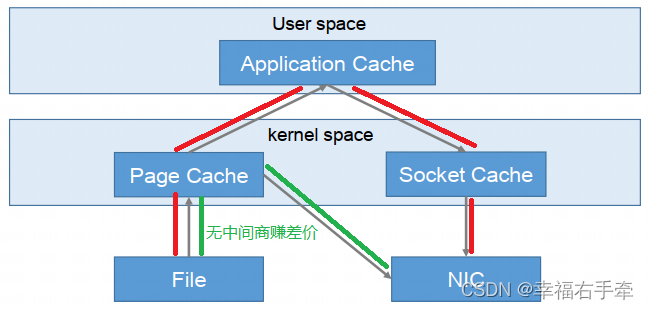
kafka-5 kafka的高吞吐量和高可用性
kafka的高吞吐量和高可用性 6.1 高吞吐量6.2 高可用(HA) 6.1 高吞吐量 kafka的高吞吐量主要是由4方面保证的: (1)顺序读写磁盘 Kafka是将消息持久化到本地磁盘中的,一般人会认为磁盘读写性能差ÿ…...
Jmeter前置处理器和后置处理器
1. 后置处理器(Post Processor) 本质上是⼀种对sampler发出请求后接受到的响应数据进⾏处理 (后处理)的⽅法 正则表达式后置处理器 (1)引⽤名称:下⼀个请求要引⽤的参数名称,如填写title,则可…...

手把手带你了解《线程池》
文章目录 线程池的概念池的目的线程池的优势为什么从池子里拿线程更高效?构造方法参数讲解线程拒绝策略模拟实现线程池一个线程池设置多少线程合适? 线程池的概念 线程池:提前把线程准备好,创建线程不是直接从系统申请࿰…...
idea中使用git工具
目录 一、IDEA中配置git二、git操作将项目设置成git仓库 一、IDEA中配置git 打开idea,点击File–>Settings 点击版本控制,然后点击git 将你的git.exe安装目录填到下面位置 点击test可以看到显示了版本,说明配置成功 二、git操作 将项目设…...
的使用方法)
剖析DLL(动态链接库)的使用方法
为了更好地理解和应用dll,我们首先需要了解dll的概念和原理。 一、dll(Dynamic Link Library)的概念 dll是一种动态链接库,它是在Windows操作系统中广泛使用的一种机制,它允许程序在运行时调用动态链接库中的函数。d…...

第二章 设计模式七大原则
文章目录 前言一、单一职责 🍧1、单一职责原则注意事项和细节2、代码实现2、1 错误示例2、2 正确示例但有缺陷2、3 最终形态 二、接口隔离原则 🥩1、代码示例 三、依赖倒转原则 🥥1、代码示例2、依赖关系传递的三种方式 四、里氏替换原则 &am…...

黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题
黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool 还在为黑苹果的显卡驱动、音频输出和USB识别问题而…...

Unity问题记录
一个物体在Scene窗口看不见,Game窗口能看见。选中它时,打开Gizmos也看不见身上碰撞体的线框。也无法被射线检测到。换成其他Mesh:Open Asset In Context正常显示:把它Revert回预制体,还是不显示。Ctrl D复制一个&#…...

Next.js全栈开发最佳实践:从零搭建现代化Web应用
1. 项目概述:一个现代Web开发的“瑞士军刀”如果你和我一样,在过去几年里频繁地使用Next.js、TypeScript和Tailwind CSS来构建前端应用,那么你肯定也经历过无数次重复的“项目初始化”工作。从安装依赖、配置TypeScript和ESLint,到…...

MIMO AONN架构:量子干涉实现超低功耗光学神经网络
1. MIMO AONN架构的核心价值光学神经网络(AONN)正在突破传统电子计算的物理极限。在传统电子神经网络中,非线性激活函数需要消耗大量能量进行电子-光子转换,而基于量子干涉的光学非线性机制可以直接在光域实现这一关键操作。我们实…...

英雄联盟国服换肤终极指南:R3nzSkin免费体验全皮肤
英雄联盟国服换肤终极指南:R3nzSkin免费体验全皮肤 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 厌倦了英雄联盟国服中单调的默认皮肤&am…...

收藏!小白程序员必看:读懂AI岗位JD,精准投递不陪跑
本文针对AI岗位认知模糊、JD理解困难等问题,为读者提供六步解析法,包括明确岗位性质、了解公司类型、评估薪资水平、硬性条件筛选、分析岗位职责和技能匹配。通过这些步骤,帮助读者精准定位适合自己的AI岗位,避免盲目投递。同时&a…...

中小企业如何通过Taotoken的Token Plan套餐控制AI集成成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小企业如何通过Taotoken的Token Plan套餐控制AI集成成本 应用场景类,中小企业在为官网或CRM系统集成AI功能时&#x…...

Hanime1Plugin终极指南:打造纯净Android动漫观影体验的免费神器
Hanime1Plugin终极指南:打造纯净Android动漫观影体验的免费神器 【免费下载链接】Hanime1Plugin Android插件(https://hanime1.me) (NSFW) 项目地址: https://gitcode.com/gh_mirrors/ha/Hanime1Plugin 你是否厌倦了在Android设备上看动漫时被各种广告打断&a…...

突破百度网盘下载限速:macOS逆向工程实践指南
突破百度网盘下载限速:macOS逆向工程实践指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于macOS用户而言,百度网盘的下载…...

Claude Code 沙箱系统全解析:Seatbelt、Bubblewrap、AI Agent 安全隔离、权限治理与企业级防护
一、开篇:AI Agent 越能干,越需要一堵真正的墙过去很多人谈 AI 编码工具,最关心的是模型聪不聪明、能不能读懂项目、能不能自动改文件、能不能跑命令。但当一个 Agent 真正拥有终端执行能力之后,问题就变了:它不只是一…...