什么是雪花算法?啥原理?
1、SnowFlake核心思想
SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。
其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。
这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 ID,12 bit 作为序列号。

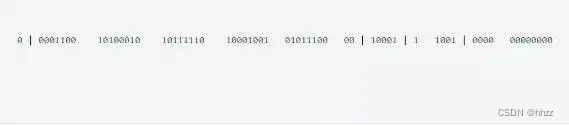
给大家举个例子吧,比如下面那个 64 bit 的 long 型数字:
第一个部分是 1 个 bit:0,这个是无意义的。
第二个部分是 41 个 bit:表示的是时间戳。
第三个部分是 5 个 bit:表示的是机房 ID,10001。
第四个部分是 5 个 bit:表示的是机器 ID,1 1001。
第五个部分是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号,0000 00000000。
1 bit:是不用的,为啥呢?
因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 ID 都是正数,所以第一个 bit 统一都是 0。
41 bit:表示的是时间戳,单位是毫秒。
41 bit 可以表示的数字多达 2^41 - 1,也就是可以表示 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
10 bit:记录工作机器 ID。
代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
但是 10 bit 里 5 个 bit 代表机房 ID,5 个 bit 代表机器 ID。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),也可以根据自己公司的实际情况确定。
12 bit:这个是用来记录同一个毫秒内产生的不同 ID。
12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 ID。
简单来说,你的某个服务假设要生成一个全局唯一 ID,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 ID。
这个 SnowFlake 算法系统首先肯定是知道自己所在的机房和机器的,比如机房 ID = 17,机器 ID = 12。
接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 ID,64 个 bit 中的第一个 bit 是无意义的。
接着 41 个 bit,就可以用当前时间戳(单位到毫秒),然后接着 5 个 bit 设置上这个机房 ID,还有 5 个 bit 设置上机器 ID。
最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 ID 的请求累加一个序号,作为最后的 12 个 bit。
最终一个 64 个 bit 的 ID 就出来了,类似于:
这个算法可以保证,一个机房的一台机器上,在同一毫秒内生成了一个唯一的 ID。可能一个毫秒内会生成多个 ID,但是有最后 12 个 bit 的序号来区分开来。
下面我们简单看看这个 SnowFlake 算法的一个代码实现,这就是个示例,大家如果理解了这个意思之后,以后可以自己尝试改造这个算法。
总之就是用一个 64 bit 的数字中各个 bit 位来设置不同的标志位,区分每一个 ID。
2、SnowFlake 算法的实现
SnowFlake 算法的实现代码如下:
public class IdWorker {//因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。//机器ID 2进制5位 32位减掉1位 31个private long workerId;//机房ID 2进制5位 32位减掉1位 31个private long datacenterId;//代表一毫秒内生成的多个id的最新序号 12位 4096 -1 = 4095 个private long sequence;//设置一个时间初始值 2^41 - 1 差不多可以用69年private long twepoch = 1585644268888L;//5位的机器idprivate long workerIdBits = 5L;//5位的机房idprivate long datacenterIdBits = 5L;//每毫秒内产生的id数 2 的 12次方private long sequenceBits = 12L;// 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内private long maxWorkerId = -1L ^ (-1L << workerIdBits);// 这个是一个意思,就是5 bit最多只能有31个数字,机房id最多只能是32以内private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << sequenceBits);//记录产生时间毫秒数,判断是否是同1毫秒private long lastTimestamp = -1L;public long getWorkerId(){return workerId;}public long getDatacenterId() {return datacenterId;}public long getTimestamp() {return System.currentTimeMillis();}public IdWorker(long workerId, long datacenterId, long sequence) {// 检查机房id和机器id是否超过31 不能小于0if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;}// 这个是核心方法,通过调用nextId()方法,让当前这台机器上的snowflake算法程序生成一个全局唯一的idpublic synchronized long nextId() {// 这儿就是获取当前时间戳,单位是毫秒long timestamp = timeGen();if (timestamp < lastTimestamp) {System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp - timestamp));}// 下面是说假设在同一个毫秒内,又发送了一个请求生成一个id// 这个时候就得把seqence序号给递增1,最多就是4096if (lastTimestamp == timestamp) {// 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,//这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围sequence = (sequence + 1) & sequenceMask;//当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生IDif (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}// 这儿记录一下最近一次生成id的时间戳,单位是毫秒lastTimestamp = timestamp;// 这儿就是最核心的二进制位运算操作,生成一个64bit的id// 先将当前时间戳左移,放到41 bit那儿;将机房id左移放到5 bit那儿;将机器id左移放到5 bit那儿;将序号放最后12 bit// 最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) | sequence;}/*** 当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID* @param lastTimestamp* @return*/private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}//获取当前时间戳private long timeGen(){return System.currentTimeMillis();}/*** main 测试类* @param args*/public static void main(String[] args) {System.out.println(1&4596);System.out.println(2&4596);System.out.println(6&4596);System.out.println(6&4596);System.out.println(6&4596);System.out.println(6&4596);// IdWorker worker = new IdWorker(1,1,1);// for (int i = 0; i < 22; i++) {// System.out.println(worker.nextId());// }}
}
3、SnowFlake 的优缺点
SnowFlake 算法的优点:
高性能高可用:生成时不依赖于数据库,完全在内存中生成。
容量大:每秒钟能生成数百万的自增 ID。
ID 自增:存入数据库中,索引效率高。
SnowFlake 算法的缺点:
依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成 ID 冲突或者重复。
实际中我们的机房并没有那么多,我们可以改进改算法,将 10bit 的机器 ID 优化,成业务表或者和我们系统相关的业务。
相关文章:
什么是雪花算法?啥原理?
1、SnowFlake核心思想 SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的…...
)
【华为OD机试真题】 统计差异值大于相似值二元组个数(javapython)
统计差异值大于相似值二元组个数 知识点数组进制转换Q整数范围循环 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 题目描述:对于任意两个正整数A和B,定义它们之间的差异值和相似值: 差异值:A、B转换成二进制后,对于二进制的每一位,对应位置的bit值不相同则为…...

【cmake篇】选择编译器及设置编译参数
实际开发的过程中,可能有多个版本的编译器,不同功能可能需要设置不同的编译参数。 参考文章链接:选择编译器及设置编译器选项 目录 一、选择编译器 1、查看系统中已有的编译器 2、选择编译器的两种方式 二、设置编译参数 1、add_compil…...
MySQL having关键字详解、与where的区别
1、having关键字概览 1.1、作用 对查询的数据进行筛选 1.2、having关键字产生的原因 使用where对查询的数据进行筛选时,where子句中无法使用聚合函数,所以引出having关键字 1.3、having使用语法 having单独使用(不与group by一起使用&a…...

CSS中相对定位与绝对定位的区别及作用
CSS中相对定位与绝对定位的区别及作用 场景复现核心干货相对定位绝对定位子绝父相🔥🔥定位总结绝对定位与相对定位的区别 场景复现 在学习前端开发的过程中,熟练掌握页面布局和定位是非常重要的,因此近期计划出一个专栏ÿ…...

7.1 基本运放电路(1)
集成运放的应用首先表现在它能构成各种运算电路上,并因此而得名。在运算电路中,以输入电压作为自变量,以输出电压作为函数;当输入电压变化时,输出电压将按一定的数学规律变化,即输出电压反映输入电压某种运…...
交友项目【首页推荐,今日佳人,佳人信息】
目录 1:首页推荐 1.1:接口地址 1.2:流程分析 1.3:代码实现 2:今日佳人 1.1:接口地址 1.2:流程分析 1.3:代码实现 3:佳人信息 1.1:接口地址 1.2&am…...
kafka-5 kafka的高吞吐量和高可用性
kafka的高吞吐量和高可用性 6.1 高吞吐量6.2 高可用(HA) 6.1 高吞吐量 kafka的高吞吐量主要是由4方面保证的: (1)顺序读写磁盘 Kafka是将消息持久化到本地磁盘中的,一般人会认为磁盘读写性能差ÿ…...
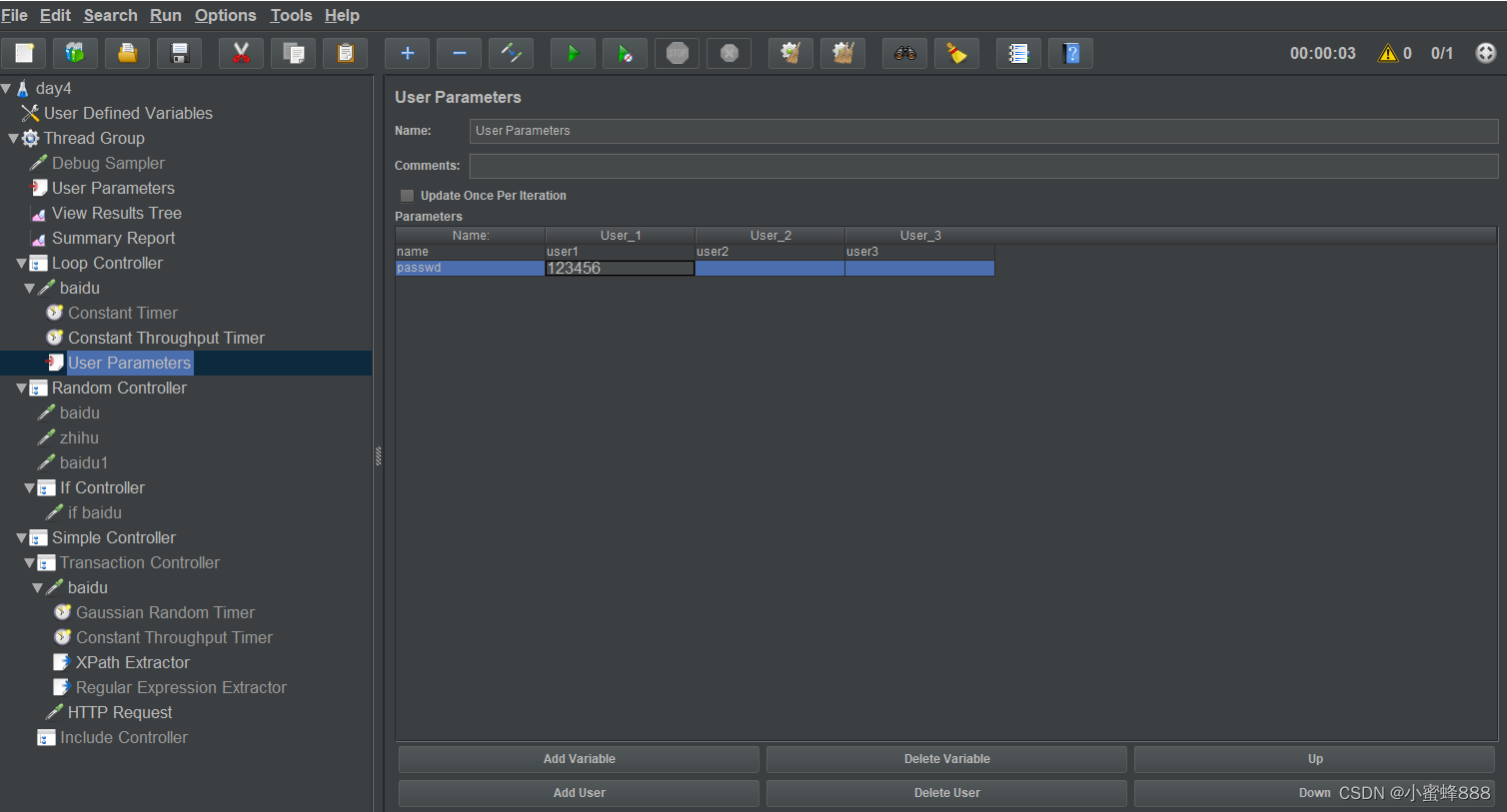
Jmeter前置处理器和后置处理器
1. 后置处理器(Post Processor) 本质上是⼀种对sampler发出请求后接受到的响应数据进⾏处理 (后处理)的⽅法 正则表达式后置处理器 (1)引⽤名称:下⼀个请求要引⽤的参数名称,如填写title,则可…...

手把手带你了解《线程池》
文章目录 线程池的概念池的目的线程池的优势为什么从池子里拿线程更高效?构造方法参数讲解线程拒绝策略模拟实现线程池一个线程池设置多少线程合适? 线程池的概念 线程池:提前把线程准备好,创建线程不是直接从系统申请࿰…...
idea中使用git工具
目录 一、IDEA中配置git二、git操作将项目设置成git仓库 一、IDEA中配置git 打开idea,点击File–>Settings 点击版本控制,然后点击git 将你的git.exe安装目录填到下面位置 点击test可以看到显示了版本,说明配置成功 二、git操作 将项目设…...
的使用方法)
剖析DLL(动态链接库)的使用方法
为了更好地理解和应用dll,我们首先需要了解dll的概念和原理。 一、dll(Dynamic Link Library)的概念 dll是一种动态链接库,它是在Windows操作系统中广泛使用的一种机制,它允许程序在运行时调用动态链接库中的函数。d…...

第二章 设计模式七大原则
文章目录 前言一、单一职责 🍧1、单一职责原则注意事项和细节2、代码实现2、1 错误示例2、2 正确示例但有缺陷2、3 最终形态 二、接口隔离原则 🥩1、代码示例 三、依赖倒转原则 🥥1、代码示例2、依赖关系传递的三种方式 四、里氏替换原则 &am…...

计网第五章.运输层—TCP报文的首部
以下来自湖科大计算机网络公开课笔记及个人所搜集资料 TCP报文格式如下: 那6个标志位对应的中文名: 下面是按TCP首部的顺序介绍各个字段: 源端口和目的端口分别是表示发送TCP报文段的应用进程。从网络编程角度,进程里创建sock…...
程序员最新赚钱指南!
程序员们的主要收入来源 1️⃣首先,我们要明白程序员无论编程开发多么努力,随着时间推移,受年龄、生活、健康等因素,程序员们都会面临职业天花板,这是大多数人不可规避的一个事实。 2️⃣其次,这几年因为…...

如何快速获取淘宝商品的详细信息?看这里就够了
taobao.item_get 公共参数 名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等]cacheString否[yes,…...

id生成器
使用说明 ⚠️ 所有使用id的业务场景,应该在数据库层设置合理的唯一索引 功能 自增id 基于 redis 自增 redis 中的key为:[spring.application.name].idGenetate.[key] ⚠️ key 在不同的业务不应该重复使用,否则单号无法连续使用 private f…...

为什么许多人吐槽C++11,那些语法值得我们学习呢?
致前行的人: 人生像攀登一座山,而找寻出路,却是一种学习的过程,我们应当在这过程中,学习稳定冷静,学习如何从慌乱中找到生机。 目录 1.C11简介 2.统一的列表初始化 2.1 {}初始化 …...

千耘农机导航的“星地一体”能力究竟是什么?
伴随农业机械化和智能化的发展,越来越多的人开始使用农机自动驾驶系统助力耕作,千耘农机导航的“星地一体”能力可有效解决信号受限的问题,实现作业提效。究竟什么是“星地一体”,又是如何解决智能化农机作业的痛点的?…...

(数字图像处理MATLAB+Python)第四章图像正交变换-第四、五节:Radon变换和小波变换
文章目录 一:Radon变换(1)Radon变换原理(2)Radon变换实现(3)Radon变换性质(4)Radon变换应用 二:小波变换(1)小波A:定义B&a…...

基于httpx的异步HTTP客户端xcapy:提升开发效率与代码健壮性
1. 项目概述:一个为现代网络应用量身定制的HTTP客户端库在开发网络应用时,HTTP客户端是我们与外部世界沟通的桥梁。从调用一个公开的API接口,到抓取网页数据,再到构建微服务间的通信,一个稳定、高效且易于使用的HTTP客…...

智慧能耗管理系统:嵌入式工控机在工业节能中的核心应用
1. 工厂能耗管理的痛点与智能化转型契机 在制造业摸爬滚打十几年,我见过太多工厂在能耗管理上的“粗放式”经营。电费单是每个月固定的大额支出,但具体电用在了哪里,哪个车间、哪条产线、甚至哪台设备是“电老虎”,很多时候都是一…...

从省级技术中心认证,看嵌入式企业如何以系统工程能力赋能开发者
1. 从“省级企业技术中心”认定,看一家嵌入式企业的硬核实力最近,在河北省发改委公布的2023年省级企业技术中心认定名单里,我看到了一个熟悉的名字——保定飞凌嵌入式技术有限公司。对于圈内人来说,“飞凌嵌入式”这个名字并不陌生…...
)
06-AI产品的伦理边界-当上瘾设计遇上算法合规(系列二-上瘾模型的AI重构)
AI产品的伦理边界:当上瘾设计遇上算法合规本文是「上瘾模型的AI重构」系列的第6篇(系列收官)本文你将获得 🧠 上瘾设计的伦理困境全景📐 AI放大伦理风险的5个维度📊 “设计上瘾” vs "设计价值"的…...

从零构建私有数字保险库:硬件选型、加密策略与实战部署
1. 项目概述:从“0”开始的数字资产保险库在数字资产日益成为个人与企业核心财富的今天,如何安全、自主地保管这些资产,成为了一个绕不开的难题。无论是加密货币的私钥、重要的数字凭证、敏感的商业文档,还是家庭成员的密码本&…...

Arm DynamIQ架构缓存一致性协议解析与优化
1. Arm DynamIQ架构中的缓存一致性技术解析在异构计算架构中,缓存一致性协议是确保多核处理器高效协同工作的关键技术。作为Arm体系结构的重要组成部分,DynamIQ共享单元(DSU)通过AMBA ACE和CHI协议实现了灵活的系统级缓存一致性管理。这两种协议虽然设计…...

终极GTA5安全增强菜单:YimMenu完全使用指南
终极GTA5安全增强菜单:YimMenu完全使用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu Y…...

专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案
专业日志分析利器glogg:解决大规模日志监控与智能搜索的技术方案 【免费下载链接】glogg A fast, advanced log explorer. 项目地址: https://gitcode.com/gh_mirrors/gl/glogg 在当今的分布式系统和微服务架构中,日志分析已成为系统运维、故障排…...

修音翻车现场实录:用Melodyne选择工具时,这3个坑我劝你别踩
Melodyne修音避坑指南:选择工具三大致命操作误区解析 第一次用Melodyne修人声时,我对着屏幕上的波形信心满满地拖动音符,结果导出的音频听起来像电子合成器故障——音高扭曲、节奏支离破碎。后来才发现,问题都出在那个看似简单的…...

数字家谱系统架构设计:从关系数据库到可视化交互的完整实现
1. 项目概述:从“家谱”到“数字家谱”的跨越最近在GitHub上看到一个挺有意思的项目,叫qiaoshouqing/familytree。光看名字,你可能会觉得,这不就是个家谱吗?没错,它的核心确实是家谱,但如果你把…...