MySQL数据库之表的增删改查(进阶)
目录
- 1. 数据库约束
- 1.1 约束类型
- 1.2 NULL约束
- 1.3 UNIQUE:唯一约束
- 1.4 DEFAULT:默认值约束
- 1.5 PRIMARY KEY:主键约束
- 1.6 FOREIGN KEY:外键约束
- 1.7 CHECK约束
- 2 表之间的关系
- 2.1 一对一
- 2.2 一对多
- 2.3 多对多
- 3 新增
- 4 查询
- 4.1 聚合查询
- 4.1.1 聚合函数
- 4.1.2 GROUP BY
- 4.1.3 HAVING
- 4.2 联合查询
- 4.2.1 内连接
- 4.2.2 外连接
- 4.2.3 自连接
- 4.2.4 子查询
- 4.2.5 合并查询
1. 数据库约束
1.1 约束类型
- NOT NULL : 指示某列不能存储 NULL 值。
- UNIQUE :保证某列的每行必须有唯一的值。
- DEFAULT :规定没有给列赋值时的默认值。
- PRIMARY KEY :NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY :保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK :保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
1.2 NULL约束
创建表时,可以指定某列不为空:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT,
name VARCHAR(20),
mail VARCHAR(20)
);
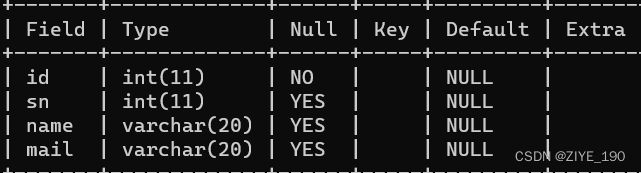
1.3 UNIQUE:唯一约束
指定sn列为唯一的、不重复的:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20),
mail VARCHAR(20)
);
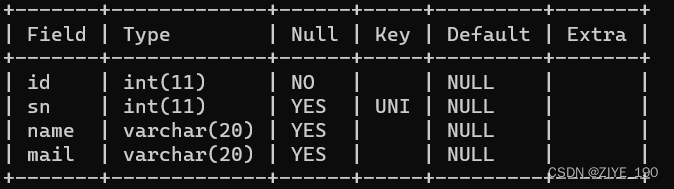
1.4 DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20)
);
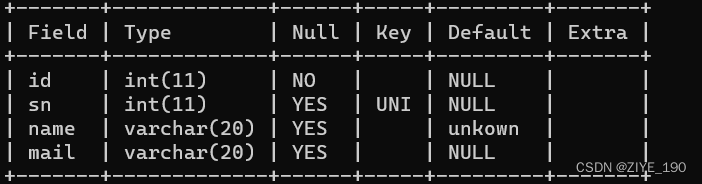
1.5 PRIMARY KEY:主键约束
指定id列为主键:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL PRIMARY KEY,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20)
);
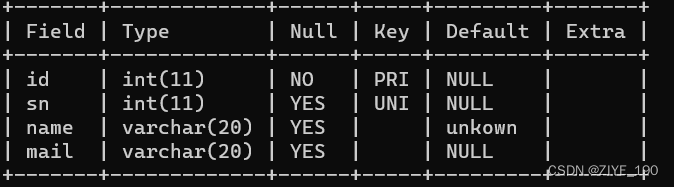
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
-- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
id INT PRIMARY KEY auto_increment,
1.6 FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键,
语法:
foreign key (字段名) references 主表(列)
- 创建班级表classes,id为主键:
-- 创建班级表
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
- 创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,classes_id为外键,关联班级表id
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
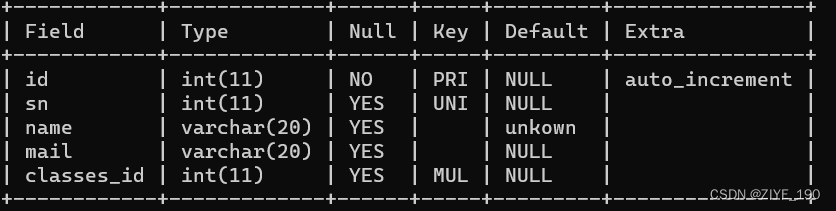
1.7 CHECK约束
MySQL使用时不报错,但忽略该约束:
drop table if exists user;
create table user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
2 表之间的关系
2.1 一对一

2.2 一对多

2.3 多对多
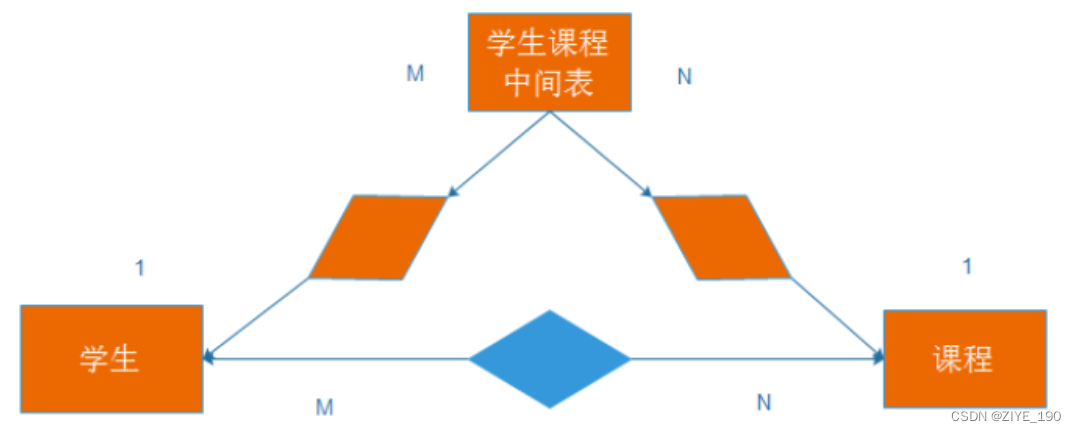
- 创建课程表
-- 创建课程表
DROP TABLE IF EXISTS course;
CREATE TABLE course (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
- 创建学生课程中间表,考试成绩表
-- 创建课程学生中间表:考试成绩表
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),
student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);
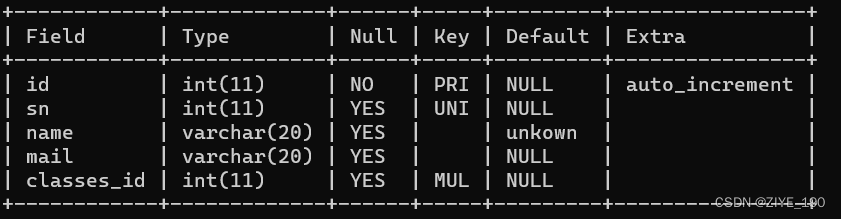
3 新增
插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
示例:
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id INT primary key auto_increment,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
email VARCHAR(20) comment '邮箱',
sex varchar(1) comment '性别',
mobile varchar(20) comment '手机号'
);
-- 将学生表中的所有数据复制到用户表
insert into test_user(name, email) select name, mail from student;
4 查询
4.1 聚合查询
4.1.1 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
4.1.2 GROUP BY
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select column1, sum(column2), .. from table group by column1,column3;
4.1.3 HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
select column1, sum(column2), .. from table group by column1,column3 having ...;
4.2 联合查询
4.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
4.2.2 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
内连接和外连接的区别:
- 内连接必须满足连接条件和其他条件才会返回
- 外连接满足连接条件和其他条件,或满足其他条件,外表存在(即使不满足连接条件) 也可以返回
4.2.3 自连接
自连接是指在同一张表连接自身进行查询。应用场景主要是同个字段,不同行之间进行比较
语法:
select t1.*, .. from table t1,table t2 where t1.column1 = t2.column1 and ...;
4.2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
- 单行子查询:返回一行记录的子查询
select *, .. from table1 where column1 = (select column1 from table1 where ... );
- 多行子查询:返回多行记录的子查询
- [NOT] IN关键字:
select *, .. from table1 where column1 in (select column1 from table2 where ... or ... );
- [NOT] EXISTS关键字:
select *, .. from table1 where exists (select column1 from table2 where (... or ... ) and table1.column1 = table2.column1);
- 在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用
4.2.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
- union
select * from table1 where ...
union
select * from table2 where ...;
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
- union all
select * from table1 where ...
union all
select * from table2 where ...;
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
相关文章:
MySQL数据库之表的增删改查(进阶)
目录 1. 数据库约束1.1 约束类型1.2 NULL约束1.3 UNIQUE:唯一约束1.4 DEFAULT:默认值约束1.5 PRIMARY KEY:主键约束1.6 FOREIGN KEY:外键约束1.7 CHECK约束 2 表之间的关系2.1 一对一2.2 一对多2.3 多对多 3 新增4 查询4.1 聚合查…...

Nginx从开始到结束,简单到小白都能懂哦
绪论 大家好,很高兴能够为大家带来这篇关于Nginx配置的新手指南。在这篇博客中,我们将通过简单明了的图文教程,帮助大家快速上手Nginx配置,解锁Nginx的各种神奇功能! 一、Nginx简介 Nginx是一款功能强大的web服务器…...
)
Qt——Qt控件之按钮-QDialogButtonBox对话框按钮盒子控件的使用总结(例程:自定义按钮)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实战》...

数据库学习-常用的SQL语句
背景: 汇整一下自己学习数据库过程中常见的题目及语句。 一.实例分析题 二.简单SQL查询: 1):统计每个部门员工的数目select dept,count(*) from employee group by dept;2):统计每个部门员工的数目大于一个的记录se…...

5种获取JavaScript时间戳函数的方法
5种获取JavaScript时间戳函数的方法 一、JavasCRIPT时间转时间戳方法一:Date.now()方法二:Date.parse()方法三:valueOf()方法四:getTime()方法五:Number 二、js时间戳转时间方法一:生成2022/1/18 上午10:09…...

图的宽度优先遍历
文章目录 图的宽度优先遍历程序设计程序分析图的宽度优先遍历 【问题描述】根据输入图的邻接矩阵A,给出图的宽度优先遍历序列; 【输入形式】第一行为图的结点个数n,第二行输入顶点的信息,每个顶点用一个字符表示,接下来的n行为图的邻接矩阵A。其中A[i][j]=1表示两个结点邻…...
企业AD域(域控服务器)的安装和配置详细教程
一、环境以及工具准备 软件:VMWare Workstation 2016 ( 下载链接:https://pan.baidu.com/s/1iX1VRilerYPGbGvX4pvaKw 提取码:75R6 ) 镜像:Windows Server 2016 ( 下载地址ÿ…...

面试官:一千万的数据,你是怎么查询的?
面试官:一千万的数据,你是怎么查询的? 1 先给结论 对于1千万的数据查询,主要关注分页查询过程中的性能 针对偏移量大导致查询速度慢: 先对查询的字段创建唯一索引 根据业务需求,先定位查询范围(…...
IntelliJ 上 Azure Event Hubs 全新支持来了!
大家好,欢迎来到 Java on Azure Tooling 的3月更新。在这次更新中,我们将介绍 Azure Event Hubs 支持、Azure Functions 的模板增强,以及在 IntelliJ IDEA 中部署 Azure Spring Apps 时的日志流改进。要使用这些新功能,请下载并安…...
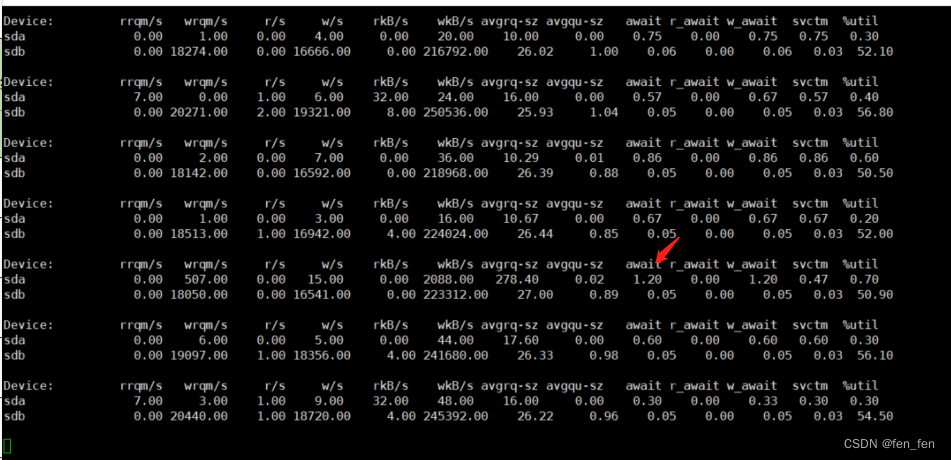
性能测试,监控磁盘读写iostat
性能测试,监控磁盘读写iostat iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出 CPU使用情况。同vmstat一样,ios…...

steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解
steam游戏搬砖项目怎么做?月入过万的steam搬砖项目教程拆解 大家好,我是童话姐姐,今天继续来聊Steam搬砖项目。 Steam搬砖项目也叫CSGO搬砖项目,它并不是什么刚面世的新项目,是已经存在至少七八年的一个资深老牌项目。这个项目…...

协同运力、算力、存力,加速迈向智能世界
2023年4月20日,华为在HAS2023期间举办“迈向智能世界”主题论坛,吸引了来自全球的分析师、专家学者及媒体与会。会上,华为ICT战略与Marketing总裁彭松发表了“持续技术创新,加速迈向智能世界”的主题演讲。 华为ICT战略与Marketin…...

被裁员了,要求公司足额补缴全部公积金,一次补了二十多万!网友兴奋了,该怎么操作?...
被裁员后,能要求公司补缴公积金吗? 一位网友问: 被裁员了,要求公司把历史公积金全部足额缴纳,现在月薪2.3万,但公司每个月只给自己缴纳300元公积金,结果一次补了二十多万,一次性取出…...
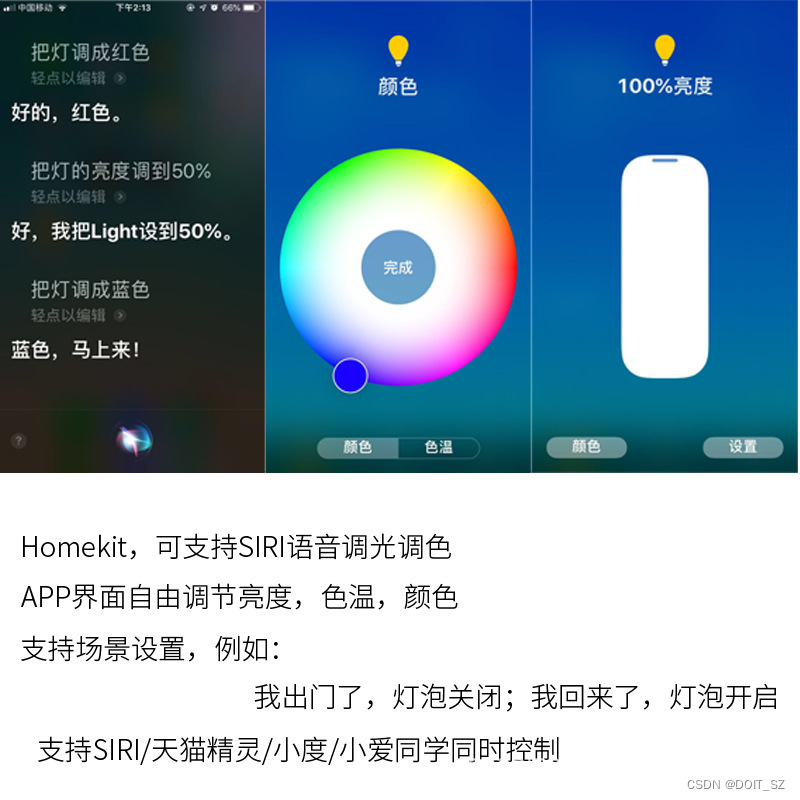
家庭智能插座一Homekit智能
传统的灯泡是通过手动打开和关闭开关来工作。有时,它们可以通过声控、触控、红外等方式进行控制,或者带有调光开关,让用户调暗或调亮灯光。 智能灯泡内置有芯片和通信模块,可与手机、家庭智能助手、或其他智能硬件进行通信&#x…...
什么是雪花算法?啥原理?
1、SnowFlake核心思想 SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的…...
)
【华为OD机试真题】 统计差异值大于相似值二元组个数(javapython)
统计差异值大于相似值二元组个数 知识点数组进制转换Q整数范围循环 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 题目描述:对于任意两个正整数A和B,定义它们之间的差异值和相似值: 差异值:A、B转换成二进制后,对于二进制的每一位,对应位置的bit值不相同则为…...

【cmake篇】选择编译器及设置编译参数
实际开发的过程中,可能有多个版本的编译器,不同功能可能需要设置不同的编译参数。 参考文章链接:选择编译器及设置编译器选项 目录 一、选择编译器 1、查看系统中已有的编译器 2、选择编译器的两种方式 二、设置编译参数 1、add_compil…...
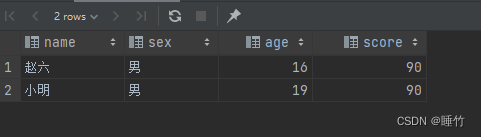
MySQL having关键字详解、与where的区别
1、having关键字概览 1.1、作用 对查询的数据进行筛选 1.2、having关键字产生的原因 使用where对查询的数据进行筛选时,where子句中无法使用聚合函数,所以引出having关键字 1.3、having使用语法 having单独使用(不与group by一起使用&a…...

CSS中相对定位与绝对定位的区别及作用
CSS中相对定位与绝对定位的区别及作用 场景复现核心干货相对定位绝对定位子绝父相🔥🔥定位总结绝对定位与相对定位的区别 场景复现 在学习前端开发的过程中,熟练掌握页面布局和定位是非常重要的,因此近期计划出一个专栏ÿ…...

7.1 基本运放电路(1)
集成运放的应用首先表现在它能构成各种运算电路上,并因此而得名。在运算电路中,以输入电压作为自变量,以输出电压作为函数;当输入电压变化时,输出电压将按一定的数学规律变化,即输出电压反映输入电压某种运…...

基于MCP协议构建AI与MongoDB数据交互的标准化桥梁
1. 项目概述:一个为AI应用注入数据库灵魂的MCP服务器如果你正在开发基于大语言模型(LLM)的AI应用,比如一个智能客服、一个文档分析助手,或者一个能帮你从海量数据中提炼洞察的智能体,你可能会遇到一个核心痛…...

ARM Cortex-R中断处理与ECC机制详解
1. ARM Cortex-R中断处理机制深度解析在嵌入式实时系统中,中断处理机制的设计直接影响系统的响应速度和可靠性。ARM Cortex-R系列处理器作为面向实时控制应用的处理器架构,其中断处理系统经过精心设计,能够满足工业控制、汽车电子等领域的严苛…...

从零搭建到日常调试:一份给新手的 Kafka 命令行操作全流程指南
从零搭建到日常调试:一份给新手的 Kafka 命令行操作全流程指南 第一次接触 Kafka 时,我被它那些晦涩的概念和复杂的命令行参数搞得晕头转向。作为一个从 MySQL 和 Redis 这类传统数据库转过来的开发者,Kafka 的分布式消息队列模型确实需要一些…...

Claude Code安装+配置国产大模型+CC Switch
Claude Code 是一个运行在终端(Terminal)里的 AI 程序员。 它不仅仅是一个聊天框,它拥有操作你电脑文件的权限 https://code.claude.com/docs/en/setup 安装 前提条件 需要 Node.js 18 或更新版本 macOS 用户推荐使用 nvm 或 Homebrew 安装…...
)
Unity3D LineRenderer 从入门到精通:手把手教你绘制炫酷动态轨迹(附完整C#脚本)
Unity3D LineRenderer 动态轨迹绘制实战指南 在游戏开发中,动态轨迹效果是提升视觉体验的重要元素之一。无论是魔法技能的飞行路径、赛车游戏的轮胎痕迹,还是数据可视化中的动态连线,流畅且富有表现力的线条渲染都能显著增强场景的沉浸感。Un…...

3步搞定Windows安卓应用安装:告别模拟器的全新体验
3步搞定Windows安卓应用安装:告别模拟器的全新体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行手机应用,却…...

NotebookLM脑机接口安全红线清单,3类合规风险已致2家医疗AI公司终止临床试验
更多请点击: https://intelliparadigm.com 第一章:NotebookLM脑机接口研究 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,其核心能力在于语义锚定(semantic grounding)与多源文档交叉推…...

Cursor AI插件开发:从代码补全到智能动作执行的范式演进
1. 项目概述:当AI代码助手遇上插件生态最近在GitHub上看到一个挺有意思的项目,叫RightbrainAI/cursor-plugin。光看名字,可能很多用惯了Cursor的朋友会眼前一亮,以为这是Cursor编辑器官方或者某个社区大神出的插件。但点进去仔细一…...

冻肉切丁机性价比排名:企业采购选型策略深度解析
冻肉切丁机性价比排名与企业采购选型策略:FAQ深度解析“不是越贵越好,适合才是王道——冻肉切丁机采购需平衡性能、成本与场景适配性”企业采购冻肉切丁机时,常被市场上五花八门的性价比排名绕晕,既担心买贵了浪费成本,…...

【AI Agent软件直控革命】:20年架构师亲授5大落地陷阱与3步安全接入法
更多请点击: https://intelliparadigm.com 第一章:AI Agent软件直控革命:从概念到产业拐点 AI Agent 已不再停留于对话式助手或任务调度器的初级形态,正加速演进为具备环境感知、自主决策与系统级直控能力的“数字执行体”。其核…...