一条SQL如何被MySQL架构中的各个组件操作执行的?
文章目录
- 1. 单表查询SQL在MySQL架构中的各个组件的执行过程
- 2. SELECT的各个关键字在哪里执行?
- 3. 表关联查询SQL在MySQL架构中的各个组件的执行过程
- 4. LEFT JOIN将过滤条件放在子查询中再关联和放在WHERE子句上有什么区别?
- 5. 聚集索引和全表扫描有什么区别呢?
1. 单表查询SQL在MySQL架构中的各个组件的执行过程
简单用一张图说明下,MySQL架构有哪些组件,接下来给大家用SQL语句分析
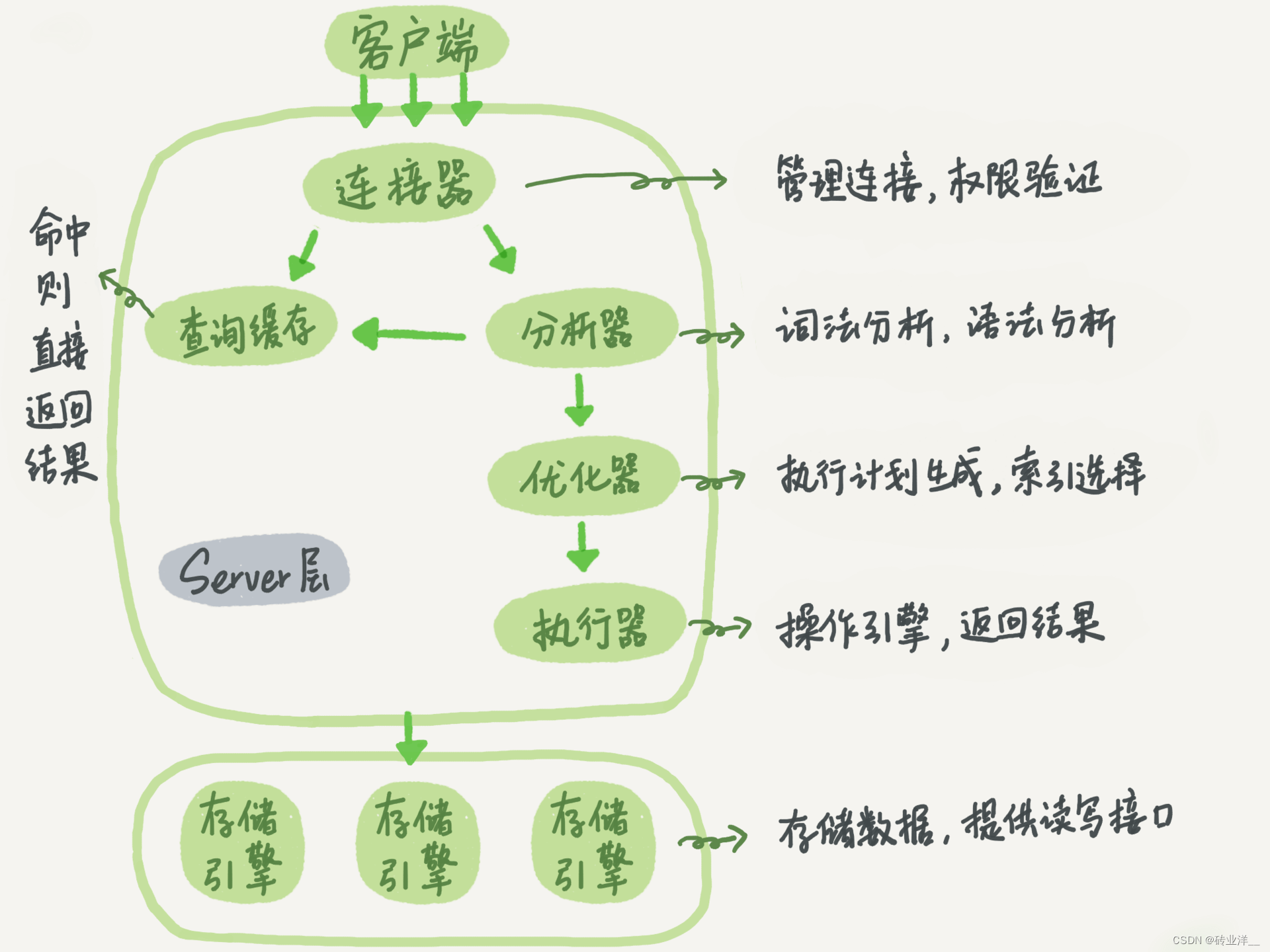
SQL语句是这样
SELECT * FROM student WHERE name = 'lcy' AND age > 18 GROUP BY class_no
其中name为索引,我们按照时间顺序来分析一下
-
客户端:客户端(如
MySQL命令行工具、Navicat、MySQL Workbench或其他应用程序)发送SQL查询到MySQL服务器。 -
连接器:连接器负责与客户端建立连接、管理连接和维护连接。当客户端连接到
MySQL服务器时,连接器验证客户端的用户名和密码,然后分配一个线程来处理客户端的请求。 -
查询缓存:查询缓存用于缓存先前执行过的查询及其结果。当收到新的查询请求时,
MySQL首先检查查询缓存中是否已有相同的查询及其结果。如果查询缓存中有匹配的查询结果,MySQL将直接返回缓存的结果,而无需再次执行查询。但是,如果查询缓存中没有匹配的查询结果,MySQL将继续执行查询。查询缓存在MySQL 8.0中已被移除,不详细解释。 -
分析器:
- 解析查询语句,检查语法。
- 验证表名和列名的正确性。
- 生成查询树。
-
优化器:分析查询树,考虑各种执行计划,估算不同执行计划的成本,选择最佳的执行计划。在这个例子中,优化器可能会选择使用
name索引进行查询,因为name是索引列。 -
执行器:根据优化器选择的执行计划,向存储引擎发送请求,获取满足条件的数据行。
-
存储引擎(如
InnoDB):- 负责实际执行索引扫描,如在
student表的name索引上进行等值查询,因查询全部列,涉及到回表访问磁盘。 - 在访问磁盘之前,先检查
InnoDB的缓冲池(Buffer Pool)中是否已有所需的数据页。如果缓冲池中有符合条件的数据页,直接使用缓存的数据。如果缓冲池中没有所需的数据页,从磁盘加载数据页到缓冲池中。
- 负责实际执行索引扫描,如在
-
执行器:
- 对于每个找到的记录,再次判断记录是否满足索引条件
name。这是因为基于索引条件加载到内存中是数据页,数据页中也有可能包含不满足索引条件的记录,满足name条件则继续判断age > 18过滤条件。 - 根据
class_no对满足条件的记录进行分组。 - 执行器将处理后的结果集返回给客户端。
- 对于每个找到的记录,再次判断记录是否满足索引条件
在整个查询执行过程中,这些组件共同协作以高效地执行查询。客户端负责发送查询,连接器管理客户端连接,查询缓存尝试重用先前查询结果,解析器负责解析查询,优化器选择最佳执行计划,执行器执行优化器选择的计划,存储引擎(如InnoDB)负责管理数据存储和访问。这些组件的协同作用使得MySQL能够高效地执行查询并返回结果集。
根据索引列过滤条件加载索引的数据页到内存这个操作是存储引擎做的。加载到内存中之后,执行器会进行索引列和非索引列的过滤条件判断。
2. SELECT的各个关键字在哪里执行?
根据执行顺序,如下:
(1)FROM:FROM子句用于指定查询所涉及的数据表。在查询执行过程中,执行器需要根据优化器选择的执行计划从存储引擎中获取指定表的数据。
(2)ON:ON子句用于指定连接条件,它通常与JOIN子句一起使用。在查询执行过程中,执行器会根据ON子句中的条件从存储引擎获取满足条件的记录。如果连接条件涉及到索引列,存储引擎可能会使用索引进行优化。
(3)JOIN:JOIN子句用于指定表之间的连接方式(如INNER JOIN, LEFT JOIN等)。在查询执行过程中,执行器会根据优化器选择的执行计划,从存储引擎中获取需要连接的表的数据。然后,执行器根据JOIN子句的类型和ON子句中的连接条件,对数据进行连接操作。
(4)WHERE:执行器对从存储引擎返回的数据进行过滤,只保留满足WHERE子句条件的记录。部分过滤条件如果涉及到索引,在存储引擎层就已经进行了过滤。
(5)GROUP BY:执行器对满足WHERE子句条件的记录按照GROUP BY子句中指定的列进行分组。
(6)HAVING:执行器在进行分组后,根据HAVING子句条件对分组后的记录进行进一步过滤。
(7)SELECT:执行器根据优化器选择的执行计划来获取查询结果。
(8)DISTINCT:执行器对查询结果进行去重,只返回不重复的记录。
(9)ORDER BY:执行器对查询结果按照ORDER BY子句中指定的列进行排序。
(10)LIMIT:执行器根据LIMIT子句中指定的限制条件对查询结果进行截断,只返回部分记录
3. 表关联查询SQL在MySQL架构中的各个组件的执行过程
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM student s
JOIN score sc ON s.id = sc.student_id
WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
这个例子中,student_id和subject是联合索引,age是索引。
我们按照时间顺序来分析一下
-
连接器:当客户端连接到
MySQL服务器时,连接器负责建立和管理连接。它验证客户端提供的用户名和密码,确定客户端具有相应的权限,然后建立连接。 -
查询缓存:
MySQL服务器在处理查询之前,会先检查查询缓存。如果查询缓存中已经存在相同的查询及其结果集,服务器将直接返回缓存中的结果,而不再执行后续的查询处理。由于查询缓存在MySQL 8.0中已被移除,我们在这个示例中不再详细讨论。 -
解析器:解析器的主要任务是解析
SQL查询语句,确保查询语法正确。解析器会将查询语句分解成多个组成部分,例如表、列、条件等。在这个示例中,解析器会识别出涉及的表(student和score)以及需要的列(id、name、age、subject、score)。 -
优化器:优化器的职责是根据解析器提供的信息生成执行计划。它会分析多种可能的执行策略,并选择成本最低的策略。在这个示例中,优化器可能会分析各种表扫描和索引扫描的组合,最终选择一种成本最低的执行计划。
-
执行器:根据优化器生成的执行计划处理查询,向存储引擎发送请求,获取满足条件的数据行。
-
存储引擎(如
InnoDB):存储引擎负责管理数据的存储和检索。- 存储引擎首先接收来自执行器的请求。请求可能包括获取满足查询条件的数据行,以及使用哪种扫描方法(如全表扫描或索引扫描)。
- 假设执行器已经决定使用索引扫描。在这个示例中,存储引擎可能会先对
student表进行索引扫描(使用age索引),然后对score表进行索引扫描(使用student_id和subject的联合索引)。 - 存储引擎会根据请求查询相应的索引结构。在
student表中,存储引擎会找到满足age > 18条件的记录。在score表中,存储引擎会找到满足subject = 'math' AND score > 80条件的记录。 - 一旦找到了满足条件的记录,存储引擎需要将这些记录所在的数据页从磁盘加载到内存中。存储引擎首先检查缓冲池(
InnoDB Buffer Pool),看这些数据页是否已经存在于内存中。如果已经存在,则无需再次从磁盘加载。如果不存在,存储引擎会将这些数据页从磁盘加载到缓冲池中。 - 加载到缓冲池中的记录可以被多个查询共享,这有助于提高查询效率。
-
执行器:处理连接、排序、聚合、过滤等操作。
- 在内存中执行连接操作,将
student表和score表的数据行连接起来。 - 对连接后的结果集进行过滤,只保留满足查询条件(
age > 18、subject = 'math'、score > 80)的数据行。 - 将过滤后的数据行作为查询结果返回给客户端。
- 在内存中执行连接操作,将
前面说过,根据存储引擎根据索引条件加载到内存的数据页有多数据,可能有不满足索引条件的数据,如果执行器不再次进行索引条件判断, 则无法判断哪些记录满足索引条件的,所以这里会有索引条件
age > 18、subject = 'math'、score > 80的判断。
4. LEFT JOIN将过滤条件放在子查询中再关联和放在WHERE子句上有什么区别?
先看例子
查询1
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id
WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
查询2
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM (SELECT id, name, age FROM student WHERE age > 18) s
LEFT JOIN (SELECT student_id, subject, score FROM score WHERE subject = 'math' AND score > 80) sc
ON s.id = sc.student_id
查询3
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id AND s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
先给出结论: 查询2和3是一样的,也就是过滤条件放在子查询中和放在on上面是一样的,后面就只讨论查询1、2,查询1和查询2是不一样的,过滤条件放在where子句中和放在子查询再关联查询出的结果也是有区别的。
分析一下
从运行结果来看,对于查询1
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id
WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
在这个查询中,首先执行LEFT JOIN,将student表和score表连接起来。连接操作是基于s.id = sc.student_id条件进行的。LEFT JOIN操作会保留左表(student表)中的所有行,即使它们在右表(score表)中没有匹配的行。如果右表中没有匹配的行,那么右表的列将显示为NULL。
然后,WHERE子句会过滤连接后的结果集,只保留那些满足s.age > 18 and sc.subject = 'math' and sc.score > 80条件的行。这意味着,右表为NULL的记录将被排除,因为右表的过滤条件sc.subject = 'math' and sc.score > 80条件不满足。
对于查询2:
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM (select id, name, age from student where age > 18) s
LEFT JOIN (select subject, score from score where subject = 'math' AND score > 80) sc
ON s.id = sc.student_id
在这个查询中,我们首先执行两个子查询。第一个子查询从student表中选择所有age > 18的行,而第二个子查询从score表中选择所有subject = 'math' and score > 80的行。这意味着,在进行连接操作之前,我们已经对两个表分别进行了过滤。
接下来,执行LEFT JOIN操作,将过滤后的s和sc子查询的结果集连接起来,基于s.id = sc.student_id条件。因为LEFT JOIN操作会保留左表(s子查询的结果集)中的所有行,右表为NULL的记录包含了。
结果差异:
查询1和查询2的主要区别在于WHERE子句和子查询的使用。查询1在连接操作后应用过滤条件,这可能导致右表为NULL的关联记录因为右表的过滤条件而被排除在外。而查询2在连接操作之前就已经过滤了表中的数据,这意味着查询结果会包含所有左表过滤条件的记录,以及右表过滤条件的记录和NULL的记录。
如果查询
1想保留右表为NULL的记录,只需要改为WHERE s.age > 18 AND (sc.student_id is null OR (sc.subject = 'math' AND sc.score > 80));这样查询1和2会有相同的结果集。
我们分析一下这两个查询在MySQL架构中各个组件中执行的区别
对于查询1:
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id
WHERE s.age > 18 AND sc.subject = 'math' AND sc.score > 80;
-
连接器:客户端与服务器建立连接。
-
查询缓存:检查缓存是否存在此查询的结果。如果有,直接返回结果。否则,继续执行。
-
解析器:解析查询语句,检查语法是否正确。
-
优化器:对查询进行优化,生成执行计划,决定连接和过滤条件的顺序等。
-
执行器:开始请求执行查询。
-
存储引擎(
InnoDB):从磁盘或者缓冲池读取满足条件的数据行(s.id = sc.student_id),因为是left join,所以即便sc.student_id为null也会被关联。 -
执行器:将从存储引擎获取的数据行进行左连接,应用过滤条件
s.age > 18 and sc.subject = 'math' and sc.score > 80进行过滤,将结果集返回给客户端。
当查询包含索引列的条件时,
MySQL的存储引擎会首先利用索引在磁盘上定位到满足索引条件的记录。接着,将这些索引数据对应的数据页加载到内存中的缓冲池。然后,执行器在内存中对这些记录进行进一步的过滤,根据索引条件和非索引列的条件来过滤数据。
当查询涉及到非聚集索引时,需要回表的操作会导致聚集索引和非聚集索引都被加载到内存中。但是,如果查询只涉及到聚集索引(如主键查询),那么只需要加载聚集索引的数据页即可。
对于查询2
SELECT s.id, s.name, s.age, sc.subject, sc.score
FROM (SELECT id, name, age FROM student WHERE age > 18) s
LEFT JOIN (SELECT student_id, subject, score FROM score WHERE subject = 'math' AND score > 80) sc
ON s.id = sc.student_id
-
连接器:客户端与服务器建立连接。
-
查询缓存:检查缓存是否存在此查询的结果。如果有,直接返回结果。否则,继续执行。
-
解析器:解析查询语句,检查语法是否正确。
-
优化器:决定使用哪些索引进行查询优化,以及确定连接顺序。
-
执行器:开始请求执行子查询。
-
存储引擎(
InnoDB):首先,对student表进行扫描,将满足条件s.age > 18的记录对应的数据页加载到缓冲池(如果缓冲池没有这个页的数据)。然后,使用subject = 'math' AND score > 80对score表进行扫描,将满足条件的记录对应的数据页加载到缓冲池(如果缓冲池没有这个页的数据)。 -
执行器:对从存储引擎获取的数据应用所有的过滤条件,过滤后的结果存入临时表,执行主查询,从临时表中获取数据,将
s和sc进行左连接,根据s.id = sc.student_id组合结果。将连接后的结果返回给客户端。
从这里我们可以看出,查询2是先过滤后连接,每张表的索引都很重要,如果没设置好索引,单表过滤会全表扫描。
写SQL的时候,查询1和查询2到底采用哪种方式呢?
根据不同情况各有应用场景,需要注意的是,对于查询2,子查询的结果集被存储在一个临时表中,临时表不会继承原始索引,包括聚集索引和非聚集索引,所以刚刚的例子中,临时表中s.id和sc.student_id已经不是任何索引列了。对于查询1,最终满足关联条件s.id = sc.student_id的所有记录都会被加载到内存后再进行过滤。
-
当单表过滤后的数据量较小时,查询
2可能是一个更好的选择,因为它可以减少关联操作的数据量,从而提高查询效率。子查询阶段,MySQL依然会利用原始表上的索引进行过滤。子查询执行完成后,将过滤后的数据存储在临时表中。所以查询2的方式可以优化的点就是在单表查询时尽可能的利用索引。 -
当单表过滤后的数据量较大时,查询
1可能更合适,因为它可以更好地利用索引进行关联操作。这样可以减少关联操作的时间开销,查询2因为临时表不继承索引,表关联的时间开销比较大。
5. 聚集索引和全表扫描有什么区别呢?
走 PRIMARY索引(聚集索引)和全表扫描有什么区别 呢?准确来说,使用InnoDB存储引擎的情况下,全表扫描的数据和聚集索引的数据在InnoDB表空间中的存储位置是相同的,也就是说它们的内存地址也是相同的。所以你也可以理解为,他们其实都是在聚集索引上操作的(聚集索引B+树的叶子结点是根据主键排好序的完整的用户记录,包含表里的所有字段),区别就在于
全表扫描将聚集索引B+树的叶子结点从左到右依次顺序扫描并判断条件。
聚集索引是利用二分思想将聚集索引B+树到指定范围区间进行扫描,比如select * from demo_info where id in (1, 2)这种条件字段是主键id,可以很好的利用PRIMARY索引进行二分的快速查询。
在MyISAM中,全表扫描的数据和索引数据的存储位置是分开的。然而MyISAM已经被InnoDB取代,不再是MySQL的推荐存储引擎,从MySQL5.5开始,InnoDB就成了MySQL的默认存储引擎。
默认情况下,InnoDB使用一个名为ibdata1的共享表空间文件存储所有的数据和索引,包括聚集索引和二级索引(又称非聚集索引或辅助索引)。
欢迎一键三连~
有问题请留言,大家一起探讨学习
blog地址:https://liuchenyang0515.blog.csdn.net/
----------------------Talk is cheap, show me the code-----------------------
相关文章:
一条SQL如何被MySQL架构中的各个组件操作执行的?
文章目录 1. 单表查询SQL在MySQL架构中的各个组件的执行过程2. SELECT的各个关键字在哪里执行?3. 表关联查询SQL在MySQL架构中的各个组件的执行过程4. LEFT JOIN将过滤条件放在子查询中再关联和放在WHERE子句上有什么区别?5. 聚集索引和全表扫描有什么区…...
)
Go语言面试题--进阶语法(30)
文章目录 1.下面的代码能否正确输出?2.下面代码输出什么?3.下面的代码有什么问题?4.下面代码有什么不规范的地方吗? 1.下面的代码能否正确输出? func main() {var fn1 func() {}var fn2 func() {}if fn1 ! fn2 {pri…...

JavaScript概述四(DOM文档对象模型)
1.DOM(Document Object Model) 会把网页里面的元素当成对象去操作,包含对象的属性,属性值,方便我们去 操作网页。 整个页面最终会形成一个对象 :document ,页面里面的所有的元素(如 标签 ) 最终都会转换成 js 里面的对象。 1.1 获取页面的元素(通过选择器࿰…...

【玩转client-go】如何获取 Kubernetes API 客户端的 *rest.Config 对象
目录 1. 使用 kubeconfig 文件 2. 使用 Kubernetes 集群内的 Service Account 3. 直接指定 API Server 的地址和认证信息 4. 使用 genericclioptions.NewConfigFlags() 总结 在使用 Kubernetes API 客户端——client-go 的过程中,我们通常需要获取 *rest.Config 配…...
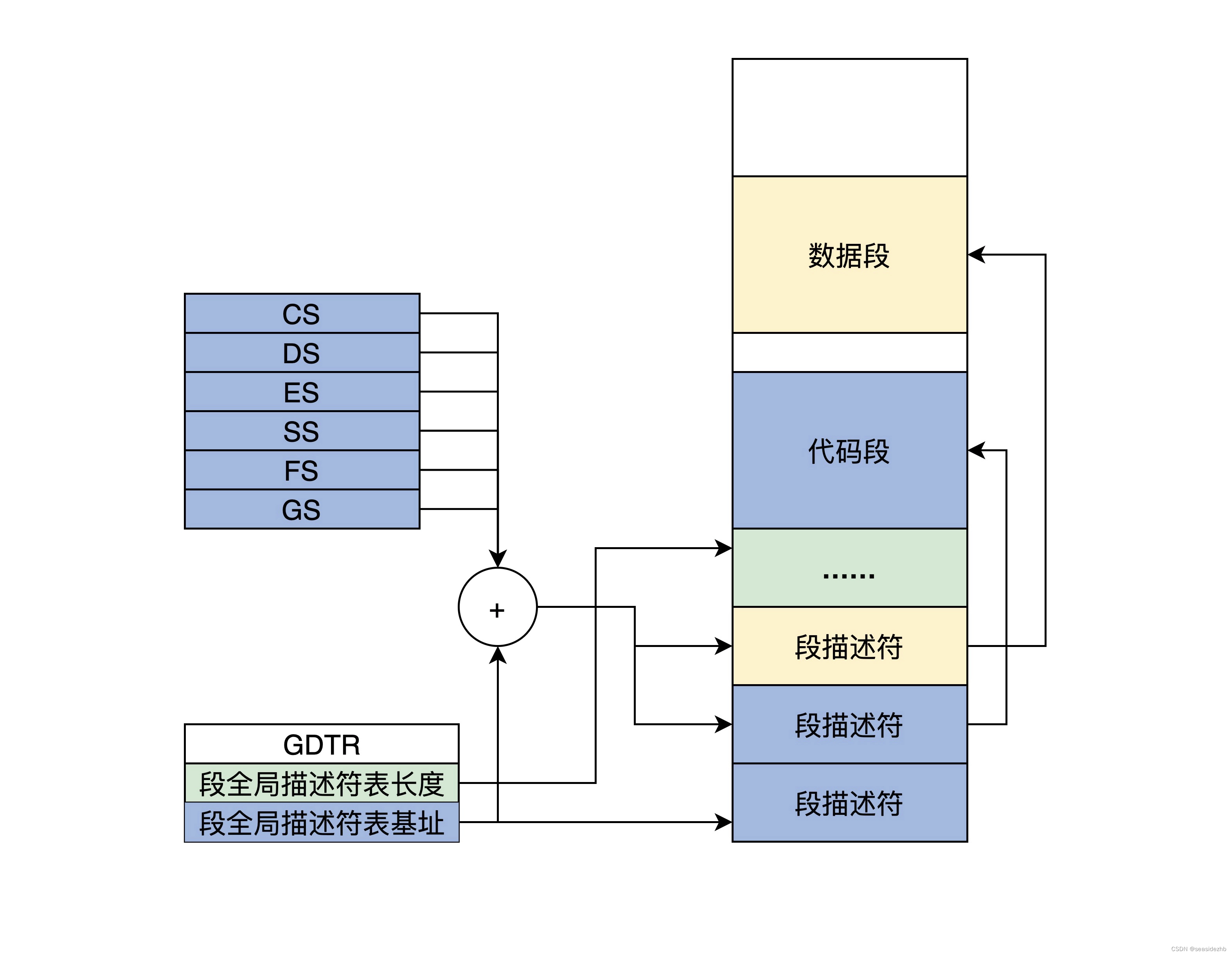
保护模式段描述符
目前为止,内存还是分段模式,所以想要保护内存,就需要保存段。由于CPU的扩展导致了32位的段基地址和段内偏移,所以16位的段寄存器就无法放下这些信息。现在就需要把这些信息放到内存中,这些信息被封装成特定的段描述符。…...

两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 思路: 由于这道题目,输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可…...
原创文章生成器在线版-ai写作生成器
随着人工智能技术的迅猛发展,越来越多的人开始意识到,利用AI可以实现许多以前不可能想象的事情。其中,一种最能体现人工智能技术优势的应用就是“ai原创文章生成器”。它可以为营销从业者提供一种全新的营销推广方式。 那么,什么是…...

打造高性能CSS的九个技巧我是这么做的
在Web开发中,CSS是不可或缺的一部分。但是,如果CSS代码不够优化,会导致页面加载速度变慢,用户体验下降。以下是九个技巧,用于打造高性能的CSS代码。 避免使用通配符选择器:通配符选择器会匹配页面中的所有…...

python tqdm教程
文章目录 1. 搭配迭代器使用2. 设置动态数据打印3. 中途打印不干扰进度条4. 在jupyter中打印不干扰进度条5. 使用gui显示进度条6. 双循环嵌套进度条7. enumerate和tqdm搭配使用参考文献tqdm是python中打印进度条的一个简易工具包,可以方便查看循环的进度。具体见tqdm文档 1. …...

深度学习 - 41.Word2vec、EGES 负采样实现 By Keras
目录 一.引言 二.实现思路 1.样本构建 2.Word2vec 架构 3.EGES 架构 4.基于 NEG 的 Word2vec 架构 三.Keras 实现 Word2vec 1.样本构建 2.模型构建 3.向量获取 四.keras 实现 EGES 1.样本构建 2.模型构建 3.Dot Layer 详解 3.1 init 方法 3.2 call 方法 3.3 完…...

研发管理风险控制
软件研发过程中需要做好风险控制,保证项目按计划发布,下面说明一下个人对软件风险控制的看法 一、规划、技术选型、架构方面提前规避风险 1.选择最熟悉、使用最多的技术 “一个新项目里最好不要使用超过30%的新技术”,我觉得这句话是有一定…...

母婴品牌内容输出怎么做?“四板斧”送你
新媒体时代,信息大爆炸,人们的注意力有限,有噱头和亮点的内容才能博得注意,成为用户关注的焦点。 母婴行业重视品牌效益和产品的质量,毕竟类似“三聚氰胺”的惨剧谁也不希望再发生。母婴产品的质量依赖技术和生产线支…...

【视频】视频存储技术
1、NVR NVR是(网络硬盘录像机)的缩写。NVR最主要的功能是通过网络接收IPC(网络摄像机)设备传输的数字视频码流, 并进行存储、管理,从而实现网络化带来的分布式架构优势。简单来说,通过NVR,可以同时观看、浏览、回放、管理、存储多个网络摄像机。NVR是x86架构储存+监控软…...

【C/C++】MySQL 为什么选择 B+ 树作为底层数据结构
为什么MySQL底层数据结构选择B树?(而不是B树等其他数据结构) B树非叶子节点,不存放数据记录,仅存放指针与关键字,所以一个B树非叶子节点可以存放更多子节点信息,有利于降低树高度,从…...

17、嵌入式Servlet容器
文章目录 1、切换嵌入式Servlet容器1.1、默认支持的webServer1.2、切换服务器 2、原理2.1、ServletWebServerApplicationContext2.2、作用2.3、ServletWebServerFactoryAutoConfiguration2.4、作用2.5、ServletWebServerFactoryConfiguration 配置类2.6、web服务器工厂作用 3、…...

倾斜摄影三维模型转换3DTILTES格式遇到的常见问题
倾斜摄影三维模型转换3DTILTES格式遇到的常见问题 将倾斜摄影三维模型从OSGB格式转换为3DTILES格式时,常见的问题包括: 1、3D Tiles生成时间较长:由于3D Tiles是一种高效的地理数据存储格式,能够支持海量的空间数据呈现和查询&am…...
手机如何访问电脑文件?(iOS和Android)
可以通过手机访问电脑文件吗? “我需要在我的电脑上查看一个文件,但我现在在外面无法实际访问它。我可以通过手机访问我的电脑文件吗?” 答案当然是可以的,无论您使用的是iOS设备还是Android设备,您都可以通过手机…...

TI在物联网和AI边缘计算中落伍了吗?
摘要:本文介绍一下TI在边缘计算工作中所做的努力。 发明“人工智能”这个term的老头儿也不会想到人工智能在中国有多火。 不管是懂还是不懂,啥东西披上“人工智能“的面纱都能瞬间成为大项目。 学习AI 的年轻人认识NVIDIA,可能不太知道DSP是…...

LoadRunner参数化最佳实践:让你的性能测试更加出色!
距离上次使用loadrunnr 已经有一年多的时间了。初做测试时在项目中用过,后面项目中用不到,自己把重点放在了工具之外的东西上,认为性能测试不仅仅是会用工具,最近又想有一把好的利器毕竟可以帮助自己更好的完成性能测试工作。这算…...

软件测试工程师需要达到什么水平才能顺利拿到 20k 无压力?
最近有粉丝朋友问:软件测试员需要达到什么水平才能顺利拿到 20k 无压力? 这里写一篇文章来详细说说: 目录 扎实的软件测试基础知识:具备自动化测试经验和技能:熟练掌握编程语言:具备性能测试、安全测试、全…...

华硕笔记本性能优化终极指南:G-Helper轻量控制工具完整解析
华硕笔记本性能优化终极指南:G-Helper轻量控制工具完整解析 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...

解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案
解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐消费日益普及的今天&…...

Kettle的优势
Kettle说具有非常强大的数据处理功能,没有做不到只有你想不到或者你还没有学会使用,如果确实做不到的情况下你还可以开发插件来进行数据处理,其中Kettle也提供了广泛的数据处理和转换功能,包括数据抽取、清洗、转换、合并、过滤等…...

GPT-4万亿参数仅激活2%?揭秘MoE稀疏激活的工程真相
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的佐证,也常被误读为“GPT-4只用360亿参数&#x…...

80C166/C167芯片内部RAM执行代码技术详解
1. 80C166/C167芯片内部RAM执行代码的技术解析在嵌入式系统开发中,有时我们需要将特定代码从ROM复制到芯片内部RAM执行。这种需求常见于需要改变总线模式的场景,比如在Siemens 80C166/C167微控制器上切换8位/16位模式或改变总线复用配置。根据Siemens官方…...

3步搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG图形界面终极指南
3步搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG图形界面终极指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经遇到过在线视频无法保存的烦恼?特别…...
)
【性能评估】信标辅助双跳认知无线电无线中继选择方案的性能评估研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【案例共创】CodeArts+SKILL 双引擎:AI 驱动 WEB 服务器极速部署
本案例由开发者:JeffDing提供,华为开发者空间案例中心优化并收录。 最新案例动态,请查阅【案例共创】CodeArtsSKILL 双引擎:AI 驱动 WEB 服务器极速部署小伙伴们快来进行实操吧! 一、概述 1.1 案例介绍 华为云码道…...

对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本 1. 成本管理中的常见挑战 对于需要持续调用大模型API的开…...

一次性掌握Mapbox地图开发框架
又到一年毕业季,春招已经基本结束,选择不考研直接就业的同学,如果5月还没拿到offer,接下来只能等暑期实习岗位,再晚一点就只能等秋招了。想找WebGIS相关的岗位,可以通过各种企业官方招聘网站、大众招聘平台…...