YOLOv7训练自己的数据集(txt文件,笔记)
目录
1.代码下载
2.数据集准备(.xml转.txt)
(1)修改图像文件名
(2)图片和标签文件数量不对应,解决办法
(3).xml转.txt
(4).txt文件随机划分出对应的训练集、测试集、验证集
3.训练数据集
(1)修改.yaml文件
(2)修改网络参数
(3)训练中断
1.代码下载
论文地址:https://arxiv.org/abs/2207.02696
论文代码下载地址:mirrors / WongKinYiu / yolov7 · GitCode
2.数据集准备(.xml转.txt)
(1)修改图像文件名
制作数据集运用到的一些功能代码_桦拾的博客-CSDN博客
(2)图片和标签文件数量不对应,解决办法
通过以下代码进行对比后,输出多余文件名,自己再根据实际情况和需要进行增删文件:python 两个文件夹里的文件名对比_inspur秃头哥的博客-CSDN博客
# -*- coding: utf-8 -*-
import ospath1 = r'./train'
path2 = r'./train_xml'def file_name(image_dir,xml_dir):jpg_list = []xml_list = []for root, dirs, files in os.walk(image_dir):for file in files:jpg_list.append(os.path.splitext(file)[0])for root, dirs, files in os.walk(xml_dir):for file in files:xml_list.append(os.path.splitext(file)[0])print(len(jpg_list))diff = set(xml_list).difference(set(jpg_list)) # 差集,在a中但不在b中的元素for name in diff:print("no jpg", name + ".xml")diff2 = set(jpg_list).difference(set(xml_list)) # 差集,在b中但不在a中的元素print(len(diff2))for name in diff2:print("no xml", name + ".jpg")
if __name__ == '__main__':file_name(path1,path2)
(3).xml转.txt
(需增加或减少数据集种类,只需修改classes列表、if语句部分,以及print部分;对应文件夹目录也需修改)
将xml转化为yolov5的训练格式txt - 知乎
import os
from glob import glob
import xml.etree.ElementTree as ETxml_dir = r'F:\datasets\tomato_dataset\xml'####xml文件夹
output_txt_dir = r'F:\datasets\tomato_dataset\txt'####输出yolo所对应格式的文件夹###进行归一化操作
def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def load_xml():####这里是你自己的分类classes = ['bruise','crack','blackspot', 'rot']xml_list = glob(os.path.join(xml_dir, '*.xml'))# print(len(xml_list), xml_list)count_pictures = {}count_detection = {}count = 0class_num0 = 0class_num1 = 0class_num2 = 0class_num3 = 0class_num4 = 0class_num5 = 0for file in xml_list:count = count + 1imgName = file.split('\\')[-1][:-4] # 文件名,不包含后缀imglabel = os.path.join(output_txt_dir, imgName + '.txt') # 创建TXT(文件夹路径加文件名加.TXT)# print(imglabel)out_file = open(imglabel, 'w', encoding='UTF-8') # 以写入的方式打开TXTtree = ET.parse(file)root = tree.getroot()for child in root:if child.tag == 'size':w = child[0].texth = child[1].textif child.tag == 'object':x_min = child[4][0].texty_min = child[4][1].textx_max = child[4][2].texty_max = child[4][3].textbox = convert((int(w), int(h)), (int(x_min), int(x_max), int(y_min), int(y_max)))label = child[0].textif label in classes:##按照上面的顺序填写标签,如果超过这些自己增加复制就行了if label == 'bruise':label = '0'class_num0 += 1out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n') # 把内容写入TXT中if label == 'crack':label = '1'class_num1 += 1out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')if label == 'blackspot':label = '2'class_num2 += 1out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')if label == 'rot':label = '3'class_num3 += 1out_file.write(str(label) + ' ' + ' '.join([str(round(a, 6)) for a in box]) + '\n')print('ALL:', count, " bruise:", class_num0, " crack:", class_num1, " blackspot:", class_num2," rot:", class_num3)return len(xml_list), classes, count_pictures, count_detection # return 用在函数内部表示当调用该函数时,if __name__ == '__main__':classes = load_xml()print(classes)(4).txt文件随机划分出对应的训练集、测试集、验证集
此代码生成相应的 train.txt; val.txt; test.txt 文件。

YOLOv7保姆级教程(个人踩坑无数)----训练自己的数据集_AmbitionToFree的博客-CSDN博客
# 将图片和标注数据按比例切分为 训练集和测试集
# 直接划分txt文件jpg文件
#### 强调!!! 路径中不能出现中文,否则报错找不到文件
import shutil
import random
import os# 原始路径
image_original_path = r"E:\0_net_code\datasets\images"
label_original_path = r"E:\0_net_code\datasets\txt"cur_path = os.getcwd()# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
print("----------")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
print("----------")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
print("----------")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
print("----------")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
print("----------")def del_file(path):for i in os.listdir(path):file_data = path + "\\" + ios.remove(file_data)def mkdir():if not os.path.exists(train_image_path):os.makedirs(train_image_path)else:del_file(train_image_path)if not os.path.exists(train_label_path):os.makedirs(train_label_path)else:del_file(train_label_path)if not os.path.exists(val_image_path):os.makedirs(val_image_path)else:del_file(val_image_path)if not os.path.exists(val_label_path):os.makedirs(val_label_path)else:del_file(val_label_path)if not os.path.exists(test_image_path):os.makedirs(test_image_path)else:del_file(test_image_path)if not os.path.exists(test_label_path):os.makedirs(test_label_path)else:del_file(test_label_path)def clearfile():if os.path.exists(list_train):os.remove(list_train)if os.path.exists(list_val):os.remove(list_val)if os.path.exists(list_test):os.remove(list_test)def main():mkdir()clearfile()file_train = open(list_train, 'w')file_val = open(list_val, 'w')file_test = open(list_test, 'w')total_txt = os.listdir(label_original_path)num_txt = len(total_txt)list_all_txt = range(num_txt)num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)# train从list_all_txt取出num_train个元素# 所以list_all_txt列表只剩下了这些元素val_test = [i for i in list_all_txt if not i in train]# 再从val_test取出num_val个元素,val_test剩下的元素就是testval = random.sample(val_test, num_val)print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = image_original_path + '\\' + name + '.jpg'srcLabel = label_original_path + '\\' + name + ".txt"if i in train:dst_train_Image = train_image_path + name + '.jpg'dst_train_Label = train_label_path + name + '.txt'shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)file_train.write(dst_train_Image + '\n')elif i in val:dst_val_Image = val_image_path + name + '.jpg'dst_val_Label = val_label_path + name + '.txt'shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)file_val.write(dst_val_Image + '\n')else:dst_test_Image = test_image_path + name + '.jpg'dst_test_Label = test_label_path + name + '.txt'shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)file_test.write(dst_test_Image + '\n')file_train.close()file_val.close()file_test.close()if __name__ == "__main__":main()3.训练数据集
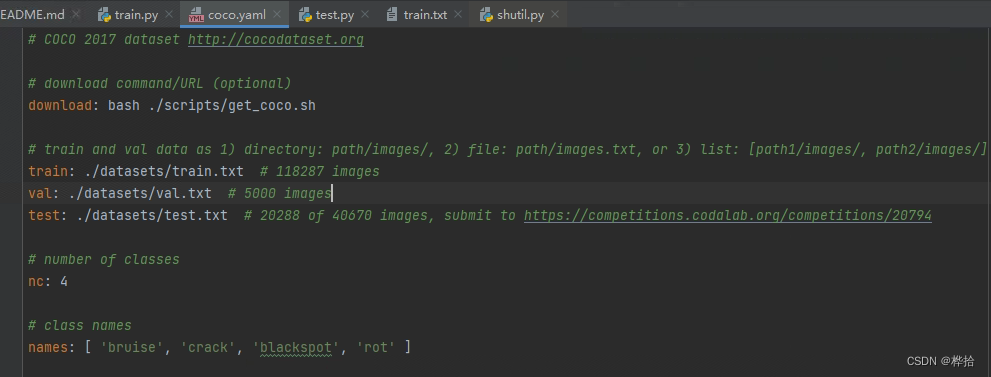
(1)修改.yaml文件
根据自己数据集情况,修改数据集文件路径、数据集种类、标签名
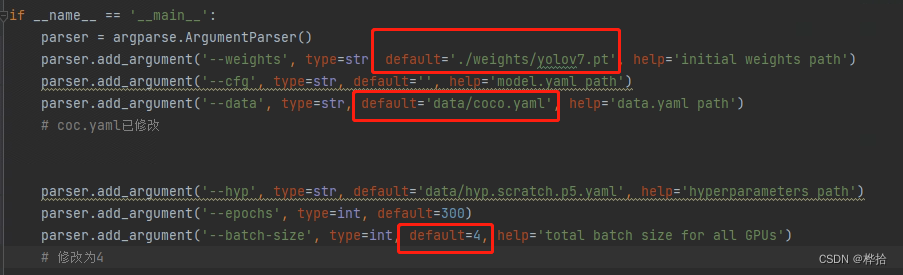
(2)修改网络参数
根据GPU情况修改参数,注意权重文件路径、yaml文件路径
(3)训练中断
若训练中断,可从最新的epcho开始训练,将resume参数的default改为True即可。

相关文章:
YOLOv7训练自己的数据集(txt文件,笔记)
目录 1.代码下载 2.数据集准备(.xml转.txt) (1)修改图像文件名 (2)图片和标签文件数量不对应,解决办法 (3).xml转.txt (4).txt文件随机划分出对应的训练…...
防止机械/移动硬盘休眠 - NoSleepHD
防止机械/移动硬盘休眠 - NoSleepHD 前言解决方案计算机硬盘移动硬盘 前言 机械硬盘休眠后唤醒需要一定时间,且频繁的启动和停止并不有利于硬盘的寿命,因此可根据自身需求防止机械硬盘休眠,下文以Win10系统为例介绍解决方案。 值得一提的是…...
(二)app自动化脚本录制回放
上一篇:(一)app自动化测试环境搭建(maciosairtest )_airtest环境搭建_要开朗的spookypop的博客-CSDN博客 注:后续都是用IOS设备来介绍自动化测试,安卓就不赘述了。 接上一篇,搭建好自动化测试环境后&#…...
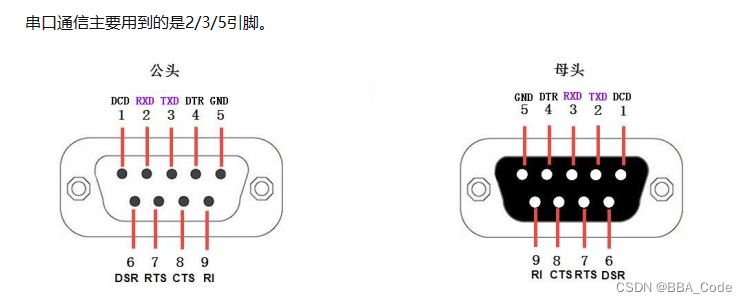
STM32HAL库USART外设配置流程及库函数讲解
HAL库中USART外设配置流程及库函数讲解 一说到串口通信,及必须说一下aRS-232/485协议。232协议标准物理接口就是我们常用的DB9串口线 RS-232电平: 逻辑1:-15~-3 逻辑0: 3~15 COMS电平: 逻辑1:3.3 逻辑0&a…...

Qt 实现TCP通信和UDP通信
Qt 实现TCP通信和UDP通信 1、TCP通信 QT中实现TCP通信主要用到了以下类:QTcpServer、QTcpSocket、QHostAddress等; 使用QTcpServer来创建一个TCP服务器,在新的连接建立时,将新建立连接的socket添加到列表中,以便发送…...

完成近4亿元C轮融资+自研底盘域控,本土线控制动玩家“拼”了
显然,线控制动赛道已经进入白热化竞争阶段。 高工智能汽车研究院监测数据显示,2022年中国市场(不含进出口)乘用车前装搭载线控制动系统(One-Box,Two-Box)上险交付合计497.39万辆,同…...
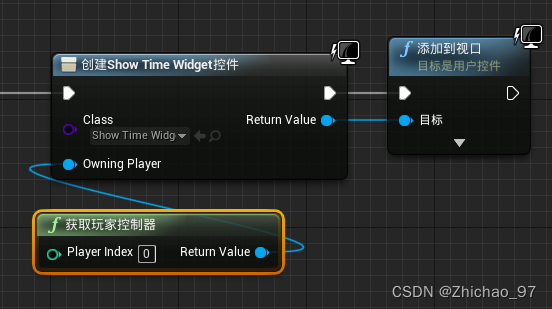
【UE】一个简易的游戏计时器
效果 步骤 1. 打开“ThirdPersonGameMode” 创建两个整型变量,分别命名为“Seconds”、“Minutes” 在事件图表中添加如下节点,实现“Seconds”每秒加1 继续添加如下节点: 当秒数大于60时,就让分钟数1,然后将秒数重新…...

Leetcode力扣秋招刷题路-0455
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 455. 分发饼干 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对每个孩子 i,都有一个胃口值 g[i]&#x…...
)
一小时学会CSS (上)
1、CSS是什么? CSS (Cascading Style Sheets)层叠样式表,是一种来为结构化文档,例如HTML 、XML 添加字体,间距和颜色等样式的计算机语言,扩展名是.CSS 。 2、CSS语法规则 CSS写在哪里,CSS写在…...

DockerImage镜像版本说明
参考文章 1、https://medium.com/swlh/alpine-slim-stretch-buster-jessie-bullseye-bookworm-what-are-the-differences-in-docker-62171ed4531d 2、https://stackoverflow.com/questions/52083380/in-docker-image-names-what-is-the-difference-between-alpine-jessie-stret…...
ROS学习第三十三节——Arbotix使用
https://download.csdn.net/download/qq_45685327/87718484 1.介绍 通过 URDF 结合 rviz 可以创建并显示机器人模型,不过,当前实现的只是静态模型,如何控制模型的运动呢?在此,可以调用 Arbotix 实现此功能。 Arboti…...

ElasticSearch第十九讲 ES-best fields,most fields策略
multi-field多字段搜索 假设有个网站允许用户搜索博客的内容,以下面两篇博客内容文档为例: PUT /my_index/my_type/1 {"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen." }PUT /my_index/my_type/2 {&…...

Netty详解,5分钟了解,面试不用慌
1. 概述 1.1 Netty 是什么? Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty 是一个异步的、基于事件驱动的网络应用框架,用…...
Logstash学习
一、Logstash基础 1、什么是Logstash logstash是一个数据抽取工具,将数据从一个地方转移到另一个地方。下载地址:https://www.elastic.co/cn/downloads/logstash logstash之所以功能强大和流行,还与其丰富的过滤器插件是分不开的ÿ…...
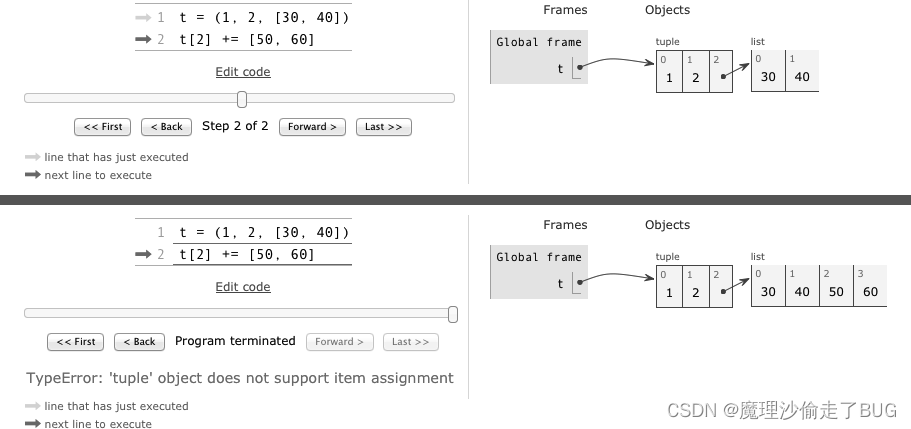
【流畅的Python学习笔记】2023.4.22
此栏目记录我学习《流畅的Python》一书的学习笔记,这是一个自用笔记,所以写的比较随意 元组 元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。简单试试元组的特性: char…...

使用django_celery_beat在admin后台配置计划任务
一、依赖包的安装 django中使用celery做异步任务和计划任务最头疼的点就是包之间版本兼容性问题,项目一启动花花报错,大概率都是版本问题。每次都会花很大时间在版本兼容性问题上。本例使用如下版本: Django3.2 celery5.2.7 django-celery-b…...
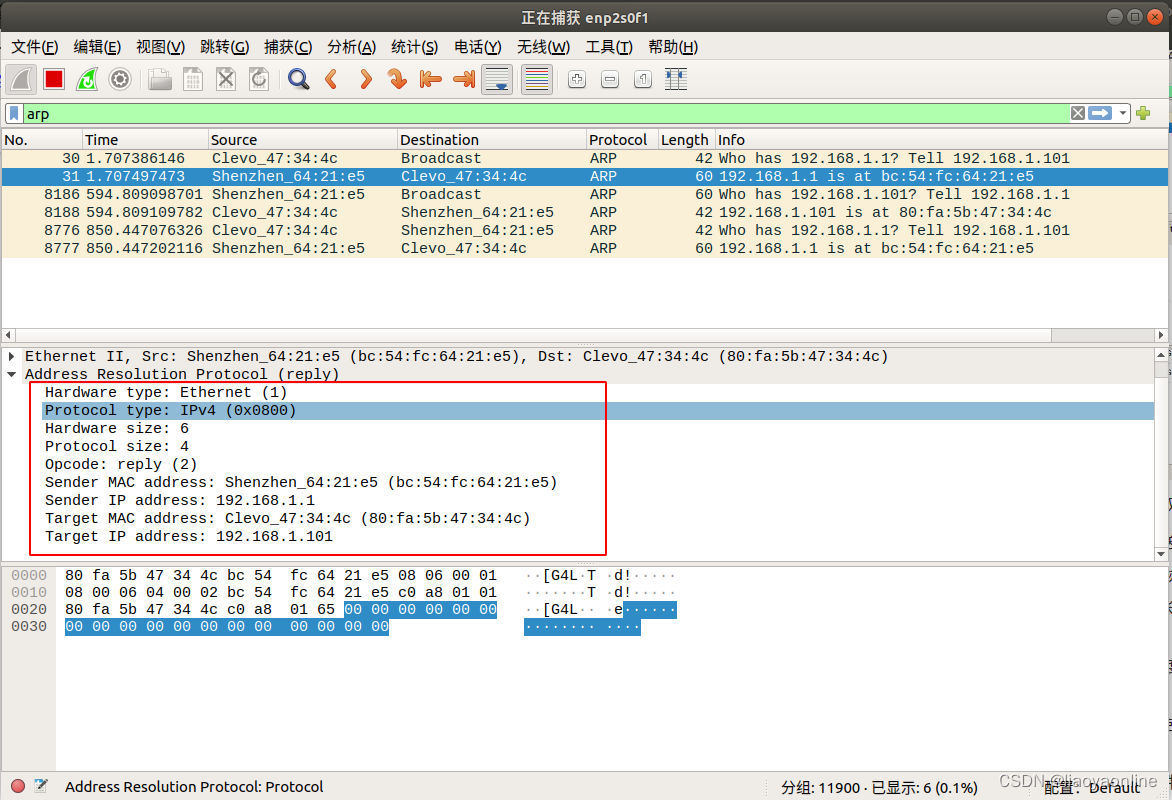
ARP协议详解
ARP协议详解 文章目录 ARP协议详解ARP协议介绍ARP抓包ARP包解析 ARP协议介绍 ARP(Address Resolution Protocol)是一种用于将网络层地址(如IP地址)转换为数据链路层地址(如MAC地址)的协议,当一…...

不同数量的预测框和Ground Truth框计算IoU
import numpy as npdef calculate_iou(boxes1, boxes2):# 转换为 numpy 数组boxes1 np.array(boxes1)boxes2 np.array(boxes2)# 扩展维度,以便广播计算boxes1 np.expand_dims(boxes1, axis1)boxes2 np.expand_dims(boxes2, axis0)# 计算两组框的交集坐标范围x_m…...
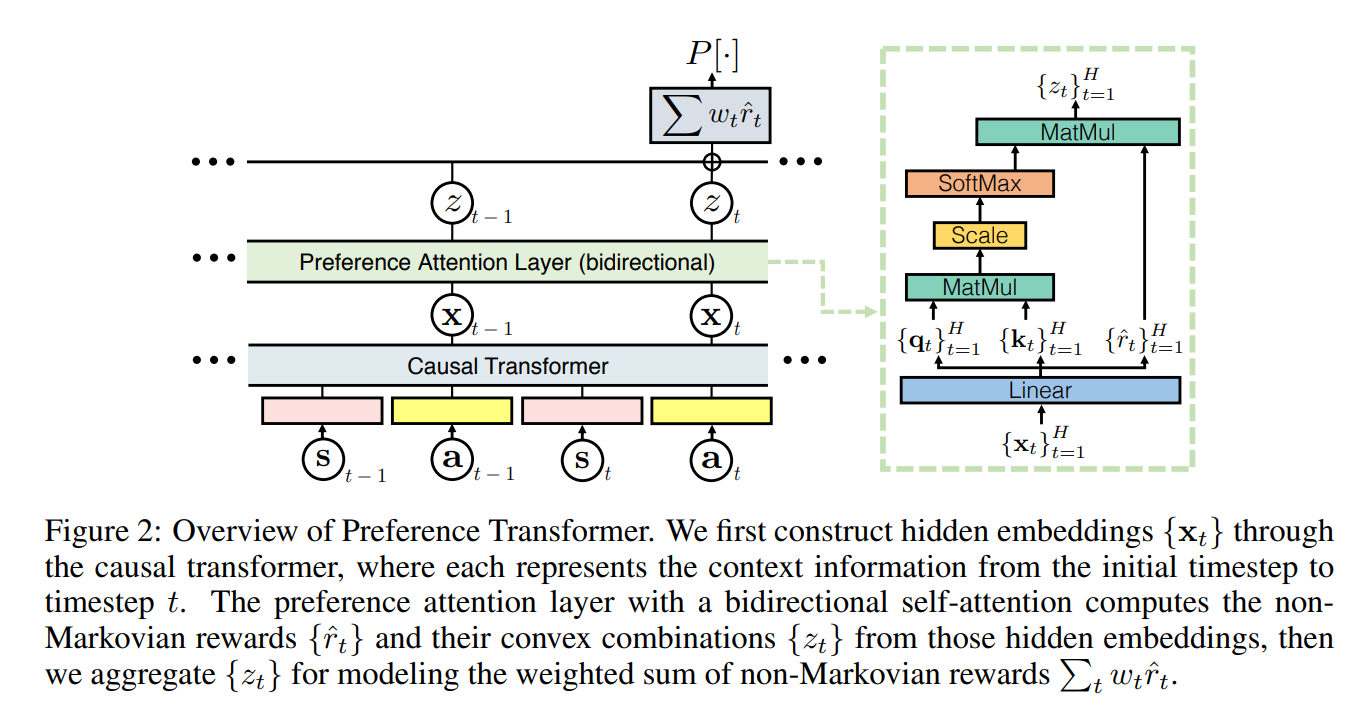
偏好强化学习概述
文章目录 为什么需要了解偏好强化学习什么是偏好强化学习基于偏好的马尔科夫决策过程(Markov decision processes with preferences,MDPP) 反馈类型分类学习算法分类近似策略分布(Approximating the Policy Distribution)比较和排序策略(Comp…...

苹果笔到底有没有必要买?苹果平板电容笔排行榜
事实上,Apple Pencil与市场上普遍存在的电容笔最大的区别,就是两者的重量以及所具有的压感都互不相同。但是,苹果原有的电容笔因其昂贵的价格而逐步被平替电容笔所替代,而平替电容笔所具备的各种性能也在逐步提高。接下来…...

UE5 Nanite配置指南:开启D3D12与SM6渲染管线
1. 这个提示不是报错,而是UE5在“敲你门”问你准备好了吗?刚打开UE5项目,编辑器右上角突然弹出一个黄色感叹号提示:“Nanite requires project settings to be configured for SM6 and D3D12”——很多新手第一反应是慌࿱…...

Unity军事资源包的战术语义架构与实战集成指南
1. 这个资源包不是“拿来就能用”的万能钥匙,而是需要你亲手校准的战术装备“POLYGON Military”——光看名字,很多人第一反应是:Unity Asset Store上那个标着“POLYGON”风格、封面全是迷彩涂装M4和悍马车的军事资源包。它确实存在ÿ…...

1987年6月27日下午13-15点出生性格、运势和命运
1987年6月17日,下午15点到17点之间,正值盛夏时节,阳光炽烈而漫长。这一天出生的孩子,是中国改革开放后“黄金十年”中诞生的又一批弄潮儿。他们的成长轨迹,与全球化浪潮的涌入、市场经济的深化以及互联网的萌芽几乎同步…...

前端架构演进:从单体到微前端
前端架构演进:从单体到微前端 前端架构的发展历程 第一阶段:单体应用(Mono Repo) ├── src/ │ ├── components/ │ ├── pages/ │ ├── services/ │ ├── utils/ │ └── styles/ └── index.html…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...

使用Taotoken后Keil5项目代码审查效率的直观提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后Keil5项目代码审查效率的直观提升 1. 背景与需求 在嵌入式开发领域,代码审查是保证软件质量的关键环节…...

技术人的人际关系:建立良好的职业网络
技术人的人际关系:建立良好的职业网络 引言 作为一名技术人,人际关系同样重要。良好的人际关系可以帮助我们获得更多机会,提升职业发展。 今天就来分享一下如何建立良好的职业网络。 为什么人际关系重要 职业发展 良好的人际关系有助于职业发…...

计算机视觉与深度学习融合的群养猪行为识别与分类算法【附算法】
✨ 长期致力于计算机视觉、深度学习、攻击识别、多物体玩耍识别、饮水和玩耍饮水器分类、进食识别、行为量化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&…...

PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发
PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发 【免费下载链接】vscode-intelephense PHP intellisense for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intelephense PHP Intelephense是一款为Visual Studio …...

【YOLOv8多模态融合改进】| IEEE2025 分层特征融合模块HFF 自适应权重 + 三重注意力,强化弱小目标细节保留
一、本文介绍 本文记录的是利用分层特征融合模块HFF改进YOLOv8的可见光-红外双模态目标检测。 HFF(Hierarchical Feature Fusion)通过浅层-深层特征逐元素融合、空间-通道-像素三重注意力建模与自适应加权分配结合,实现多模态来源下不同语义层级特征的自适应重要性学习与精…...