Spark OOM问题常见解决方式
文章目录
- Spark OOM问题常见解决方式
- 1.map过程产生大量对象导致内存溢出
- 2.数据不平衡导致内存溢出
- 3.coalesce调用导致内存溢出
- 4.shuffle后内存溢出
- 5. standalone模式下资源分配不均匀导致内存溢出
- 6.在RDD中,共用对象能够减少OOM的情况
- 优化
- 1.使用mapPartitions代替大部分map操作,或者连续使用的map操作
- 2.broadcast join和普通join
- 3.先filter在join
- 4.partitonBy优化
- 5.combineByKey的使用:
- 6.内存不足时的优化
- 7.在spark使用hbase的时候,spark和hbase搭建在同一个集群:
- 参数优化部分
- 8.spark.driver.memory (default 1g)
- 9.spark.rdd.compress (default false)
- 10.spark.serializer (default org.apache.spark.serializer.JavaSerializer )
- 11.spark.memory.storageFraction (default 0.5)
- 12.spark.locality.wait (default 3s)
- 13.spark.speculation (default false)
Spark OOM问题常见解决方式
1.map过程产生大量对象导致内存溢出
这种溢出的原因是在单个map中产生了大量的对象导致的。例如:
rdd.map(x=>for(i <- 1 to 10000) yield i.toString)
这个操作在rdd中,每个对象都产生了10000个对象,这肯定很容易产生内存溢出的问题。
针对这种问题,在不增加内存的情况下,可以通过减少每个Task的大小,以便达到每个Task即使产生大量的对象Executor的内存也能够装得下。
具体做法可以在会产生大量对象的map操作之前调用repartition方法,分区成更小的块传入map。例如:
rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。
面对这种问题注意,不能使用rdd.coalesce方法,这个方法只能减少分区,不能增加分区,不会有shuffle的过程。
2.数据不平衡导致内存溢出
数据不平衡除了有可能导致内存溢出外,也有可能导致性能的问题,解决方法调用repartition重新分区。
3.coalesce调用导致内存溢出
理想情况下:所以Spark计算后如果产生的文件太小,我们会调用coalesce合并文件再存入hdfs中。例如在coalesce之前有100个文件,这也意味着能够有100个Task,现在调用coalesce(10),最后只产生10个文件。
但是事实上:因为coalesce会降低父RDD的分区数,这意味着coalesce并不是按照原本想的那样先执行100个Task,再将Task的执行结果合并成10个,而是从头到位只有10个Task在执行,原本100个文件是分开执行的,现在每个Task同时一次读取10个文件,使用的内存是原来的10倍,这导致了OOM。
源码参考
解决这个问题的方法是:
令程序按照我们想的先执行100个Task再将结果合并成10个文件,这个问题同样可以通过repartition解决,调用repartition(10),因为这就有一个shuffle的过程,shuffle前后是两个Stage,一个100个分区,一个是10个分区,就能按照我们的想法执行。
4.shuffle后内存溢出
shuffle内存溢出的情况可以说都是shuffle后,单个文件过大导致的。
在Spark中,join,reduceByKey这一类型的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) ,参数只对HashPartitioner有效.
所以如果是别的Partitioner或者自己实现的Partitioner就不能使用spark.default.parallelism这个参数来控制shuffle的并发量了。如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
5. standalone模式下资源分配不均匀导致内存溢出
在standalone的模式下如果配置了–total-executor-cores 和 –executor-memory 这两个参数,但是没有配置–executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。
这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
6.在RDD中,共用对象能够减少OOM的情况
下面这段代码会OOM,因为每次(“key”,”value”)都产生一个Tuple对象
rdd.flatMap(x=>for(i <- 1 to 1000) yield (“key”,”value”))
但是下面这段就不会出现OOM,”key”+”value”,不管多少个,都只有一个String对象,指向常量池
rdd.flatMap(x=>for(i <- 1 to 1000) yield “key”+”value”)
如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用.
优化
1.使用mapPartitions代替大部分map操作,或者连续使用的map操作
这里需要稍微讲一下RDD和DataFrame的区别。RDD强调的是不可变对象,每个RDD都是不可变的,当调用RDD的map类型操作的时候,都是产生一个新的对象,这就导致了一个问题,如果对一个RDD调用大量的map类型操作的话,每个map操作会产生一个到多个RDD对象,这虽然不一定会导致内存溢出,但是会产生大量的中间数据,增加了gc操作。另外RDD在调用action操作的时候,会出发Stage的划分,但是在每个Stage内部可优化的部分是不会进行优化的,例如rdd.map(+1).map(+1),这个操作在数值型RDD中是等价于rdd.map(_+2)的,但是RDD内部不会对这个过程进行优化。DataFrame则不同,DataFrame由于有类型信息所以是可变的,并且在可以使用sql的程序中,都有除了解释器外,都会有一个sql优化器,DataFrame也不例外,有一个优化器Catalyst,具体介绍看后面参考的文章。
上面说到的这些RDD的弊端,有一部分就可以使用mapPartitions进行优化,mapPartitions可以同时替代rdd.map,rdd.filter,rdd.flatMap的作用,所以在长操作中,可以在mapPartitons中将RDD大量的操作写在一起,避免产生大量的中间rdd对象,另外是mapPartitions在一个partition中可以复用可变类型,这也能够避免频繁的创建新对象。使用mapPartitions的弊端就是牺牲了代码的易读性。
2.broadcast join和普通join
在大数据分布式系统中,大量数据的移动对性能的影响也是巨大的。基于这个思想,在两个RDD进行join操作的时候,如果其中一个RDD相对小很多,可以将小的RDD进行collect操作然后设置为broadcast变量,这样做之后,另一个RDD就可以使用map操作进行join,这样能够有效的减少相对大很多的那个RDD的数据移动。
3.先filter在join
这个就是谓词下推,这个很显然,filter之后再join,shuffle的数据量会减少,这里提一点是spark-sql的优化器已经对这部分有优化了,不需要用户显示的操作,个人实现rdd的计算的时候需要注意这个。
4.partitonBy优化
这一部分在另一篇文章《spark partitioner使用技巧 》有详细介绍,这里不说了。
5.combineByKey的使用:
这个操作在Map-Reduce中也有,这里举个例子:rdd.groupByKey().mapValue(_.sum)比rdd.reduceByKey的效率低
combineByKey的过程减少了shuffle的数据量,下面的没有。combineByKey是key-value型rdd自带的API,可以直接使用。
6.内存不足时的优化
在内存不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache():
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
7.在spark使用hbase的时候,spark和hbase搭建在同一个集群:
在spark结合hbase的使用中,spark和hbase最好搭建在同一个集群上上,或者spark的集群节点能够覆盖hbase的所有节点。hbase中的数据存储在HFile中,通常单个HFile都会比较大,另外Spark在读取Hbase的数据的时候,不是按照一个HFile对应一个RDD的分区,而是一个region对应一个RDD分区。所以在Spark读取Hbase的数据时,通常单个RDD都会比较大,如果不是搭建在同一个集群,数据移动会耗费很多的时间。
参数优化部分
8.spark.driver.memory (default 1g)
这个参数用来设置Driver的内存。在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。
9.spark.rdd.compress (default false)
这个参数在内存吃紧的时候,又需要persist数据有良好的性能,就可以设置这个参数为true,这样在使用persist(StorageLevel.MEMORY_ONLY_SER)的时候,就能够压缩内存中的rdd数据。减少内存消耗,就是在使用的时候会占用CPU的解压时间。
10.spark.serializer (default org.apache.spark.serializer.JavaSerializer )
建议设置为 org.apache.spark.serializer.KryoSerializer,因为KryoSerializer比JavaSerializer快,但是有可能会有些Object会序列化失败,这个时候就需要显示的对序列化失败的类进行KryoSerializer的注册,这个时候要配置spark.kryo.registrator参数或者使用参照如下代码:
valconf=newSparkConf().setMaster(…).setAppName(…)
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2]))
valsc =newSparkContext(conf)
11.spark.memory.storageFraction (default 0.5)
这个参数设置内存表示 Executor内存中 storage/(storage+execution),虽然spark-1.6.0+的版本内存storage和execution的内存已经是可以互相借用的了,但是借用和赎回也是需要消耗性能的,所以如果明知道程序中storage是多是少就可以调节一下这个参数。
12.spark.locality.wait (default 3s)
spark中有4中本地化执行level,PROCESS_LOCAL->NODE_LOCAL->RACK_LOCAL->ANY,一个task执行完,等待spark.locality.wait时间如果,第一次等待PROCESS的Task到达,如果没有,等待任务的等级下调到NODE再等待spark.locality.wait时间,依次类推,直到ANY。分布式系统是否能够很好的执行本地文件对性能的影响也是很大的。如果RDD的每个分区数据比较多,每个分区处理时间过长,就应该把 spark.locality.wait 适当调大一点,让Task能够有更多的时间等待本地数据。特别是在使用persist或者cache后,这两个操作过后,在本地机器调用内存中保存的数据效率会很高,但是如果需要跨机器传输内存中的数据,效率就会很低。
13.spark.speculation (default false)
一个大的集群中,每个节点的性能会有差异,spark.speculation这个参数表示空闲的资源节点会不会尝试执行还在运行,并且运行时间过长的Task,避免单个节点运行速度过慢导致整个任务卡在一个节点上。这个参数最好设置为true。与之相配合可以一起设置的参数有spark.speculation.×开头的参数。参考中有文章详细说明这个参数。
参考
相关文章:

Spark OOM问题常见解决方式
文章目录Spark OOM问题常见解决方式1.map过程产生大量对象导致内存溢出2.数据不平衡导致内存溢出3.coalesce调用导致内存溢出4.shuffle后内存溢出5. standalone模式下资源分配不均匀导致内存溢出6.在RDD中,共用对象能够减少OOM的情况优化1.使用mapPartitions代替大部…...

【Calcite源码学习】ImmutableBitSet介绍
Calcite中实现了一个ImmutableBitSet类,用于保存bit集合。在很多优化规则和物化视图相关的类中都使用了ImmutableBitSet来保存group by字段或者聚合函数参数字段对应的index,例如: //MaterializedViewAggregateRule#compensateViewPartial()…...

RabbitMQ相关概念介绍
这篇文章主要介绍RabbitMQ中几个重要的概念,对于初学者来说,概念性的东西可能比较难以理解,但是对于理解和使用RabbitMQ却必不可少,初学阶段,现在脑海里留有印象,随着后续更加深入的学习,就会很…...

在jenkins容器内部使用docker
在jenkins容器内部使用docker 1.使用本地的docker 进入/var/run,找到docker.sock [rootnpy run]# ls auditd.pid containerd cryptsetup dmeventd-client docker.pid initramfs lvm netreport sepermit sudo tmpfiles.d user chro…...

分布式事务解决方案
数据不会无缘无故丢失,也不会莫名其妙增加 一、概述 1、曾几何时,知了在一家小公司做项目的时候,都是一个服务打天下,所以涉及到数据一致性的问题,都是直接用本地事务处理。 2、随着时间的推移,用户量增…...

2022黑马Redis跟学笔记.实战篇(三)
2022黑马Redis跟学笔记.实战篇 三4.2.商家查询的缓存功能4.3.1.认识缓存4.3.1.1.什么是缓存4.3.1.2.缓存的作用1.为什么要使用缓存2.如何使用缓存3. 添加商户缓存4. 缓存模型和思路4.3.1.3.缓存的成本4.3.2.添加redis缓存4.3.3.缓存更新策略4.3.3.1.三种策略(1).内存淘汰:Redis…...
hadoop环境新手安装教程
1、资源准备: (1)jdk安装包:我的是1.8.0_202 (2)hadoop安装包:我的是hadoop-3.3.1 注意这里不要下载成下面这个安装包了,我就一开始下载错了 错误示例: 2、主机网络相…...
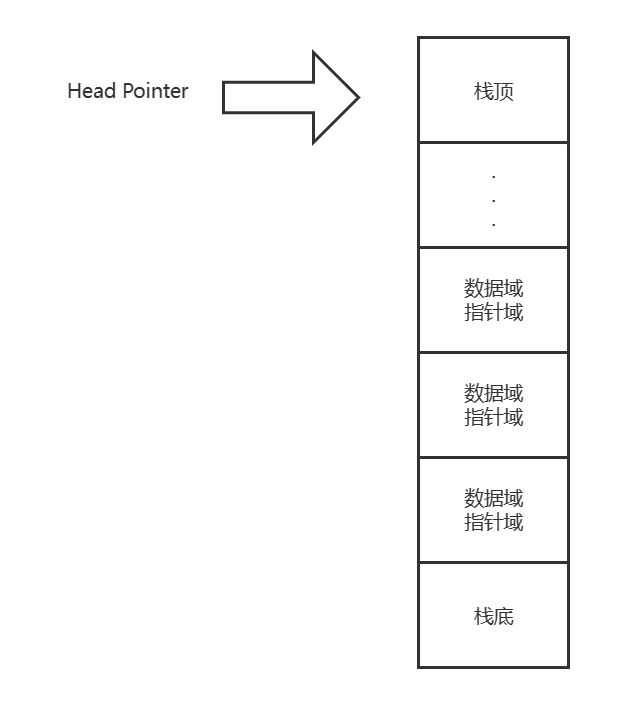
数据结构与算法基础-学习-11-线性表之链栈的初始化、判断非空、压栈、获取栈长度、弹栈、获取栈顶元素
一、个人理解链栈相较于顺序栈不存在上溢(数据满)的情况,除非内存不足,但存储密度会低于顺序栈,因为会多存一个指针域,其他逻辑和顺序表一致。总结如下:头指针指向栈顶。链栈没有头节点直接就是…...

Hive内置函数
文章目录Hive内置函数字符串函数时间类型函数数学函数集合函数条件函数类型转换函数数据脱敏函数其他函数用户自定义函数Hive内置函数 查询内置函数用法: DESCRIBE FUNCTION EXTENDED 函数名;字符串函数 字符串连接函数:concat带分隔符字符串连接函数…...
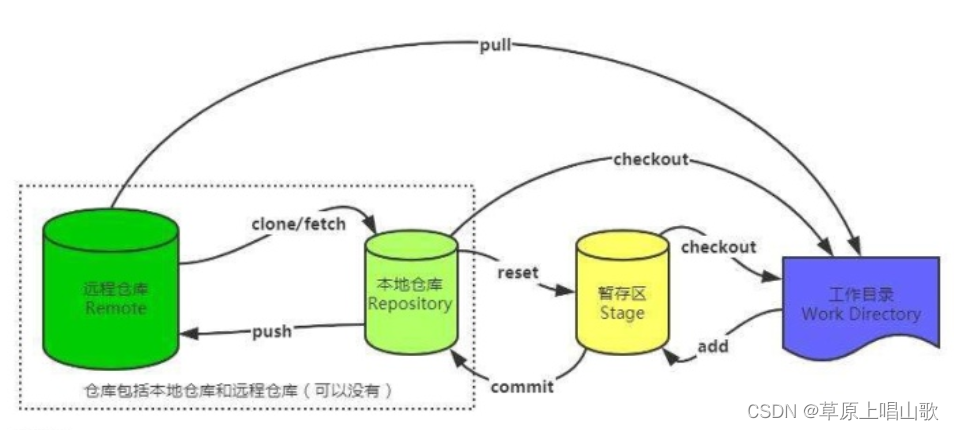
Git如何快速入门
什么是Git?我们开发的项目,也需要一个合适的版本控制系统来协助我们更好地管理版本迭代,而Git正是因此而诞生的(有关Git的历史,这里就不多做阐述了,感兴趣的小伙伴可以自行了解,是一位顶级大佬在…...
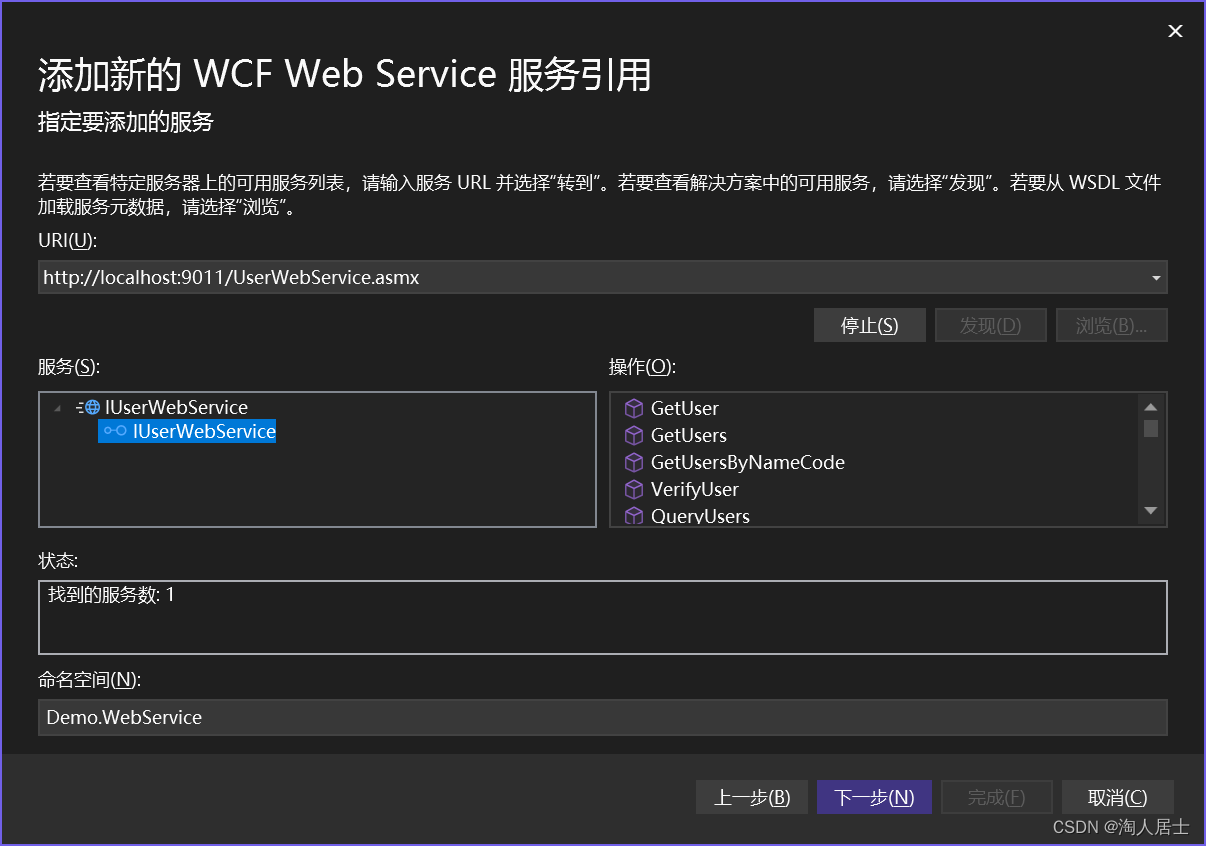
netcore构建webservice以及调用的完整流程
目录构建前置准备编写服务挂载服务处理SoapHeader调用添加服务调用服务补充内容构建 前置准备 框架版本要求:netcore3.1以上 引入nuget包 SoapCore 编写服务 1.编写服务接口 示例 using System.ServiceModel;namespace Services;[ServiceContract(Namespace &…...
)
Mysql事务基础(解析)
并发事务带来的问题A和B是并发事务脏写(A被B覆盖)两个事务。B事务覆盖了A事务。解决:应该事务并行脏读(B读到了A的执行中间结果)A修改了东西。B看到了他的中间状态。解决:读写冲突。加锁,改完再…...

2023 年首轮土地销售活动来了 与 The Sandbox 一起体验「体素狂热」!
2 月 14 日晚上 11 点,开始你的体素冒险。 The Sandbox 很高兴推出 2023 年的第一次土地销售活动。欢迎来到「体素狂热 (Voxel Madness)」! 简要概括 土地销售抽奖活动将于北京时间 2 月 14 日星期二晚上 11 点开始 「体素狂热」 土地销售活动将于 2 月…...

vue AntD中栅格布局的四种大小xs,sm,md,lg
cssBootstrap栅格布局的四种大小xs,sm,md,lg前端为了页面在不同大小的设备上也能够正常显示,通常会使用栅格布局的方式来实现。使用bootStrap的网格系统时,常见到一下格式的类名col-*-*visible-*-*hidden_*_* 中间可为xs,xsm,md,lg等表示大小的单词的缩写…...
打开窗口全屏)
window.open()打开窗口全屏
window.open (page.html, page, height100, width400, top0, left0, toolbarno, menubarno, scrollbarsno, resizableno,locationn o, statusno, fullscreenyes); 参数解释: window.open() 弹出新窗口的命令; ‘page.html’ 弹出窗口的文件名ÿ…...
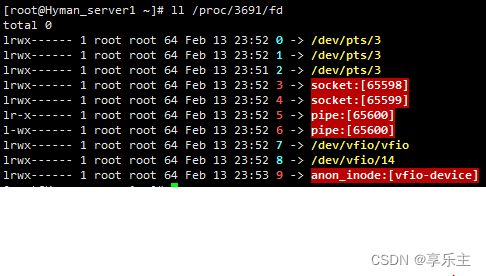
VFIO软件依赖——VFIO协议
文章目录背景PCI设备模拟PCI设备抽象VFIO协议实验Q&A背景 在虚拟化应用场景中,虚拟机想要在访问PCI设备时达到IO性能最优,最直接的方法就是将物理设备暴露给虚拟机,虚拟机对设备的访问不经过任何中间层的转换,没有虚拟化的损…...

C/C++【内存管理】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 Love is a choice. It is a conscious commitment. It is something you choose to make work every day with a person who has chosen the same thi…...

第8篇:Java编程语言的8大优势
目录 1、简单性 2、面向对象 3、编译解释性 4、稳健性 5、安全性 6、跨平台性...

STM32定时器实现红外接收与解码
1.NEC协议 红外遥控是一种比较常用的通讯方式,目前红外遥控的编码方式中,应用比较广泛的是NEC协议。NEC协议的特点如下: 载波频率为 38KHz8位地址和 8位指令长度地址和命令2次传输(确保可靠性)PWM 脉冲位置调制&#…...
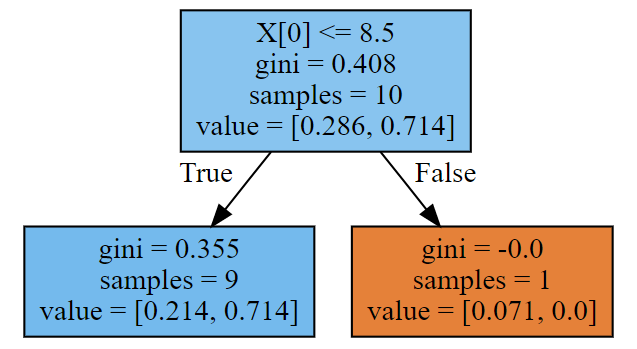
18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树: from sklearn.ensemble import AdaBoostClassifier model AdaBoostClassifier(n_estimators500) model.fit(X_train,y_train) 1、Adaboost算法介绍 1.1、算法引出 AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...