flink1.17.0 集成kafka,并且计算
前言
flink是实时计算的重要集成组件,这里演示如何集成,并且使用一个小例子。例子是kafka输入消息,用逗号隔开,统计每个相同单词出现的次数,这么一个功能。
一、kafka环境准备
1.1 启动kafka
这里我使用的kafka版本是3.2.0,部署的方法可以参考,
kafka部署
cd kafka_2.13-3.2.0
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
启动后查看java进程是否存在,存在后执行下一步。
1.2 新建topic
新建一个专门用于flink消费topic
bin/kafka-topics.sh --create --topic flinkTest --bootstrap-server 192.168.184.129:9092
1.3 测试生产消费是否正常
生产端:
bin/kafka-console-producer.sh --topic flinkTest --bootstrap-server 192.168.184.129:9092
客户端:
bin/kafka-console-consumer.sh --topic flinkTest --from-beginning --bootstrap-server 192.168.184.129:9092
1.4 测试生产消费
在生产端输入aaa

查看客户端是否能消费到
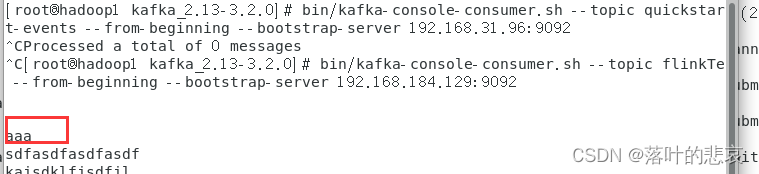
可以看到客户端已经消费成功了,kafka环境准备好了。
二、flink集成kafka
2.1 pom文件修改
pom文件修改之前,先看看官网的指导依赖是什么样的,
这里我们使用的是datastream api去做,
flink1.17.0官方文档
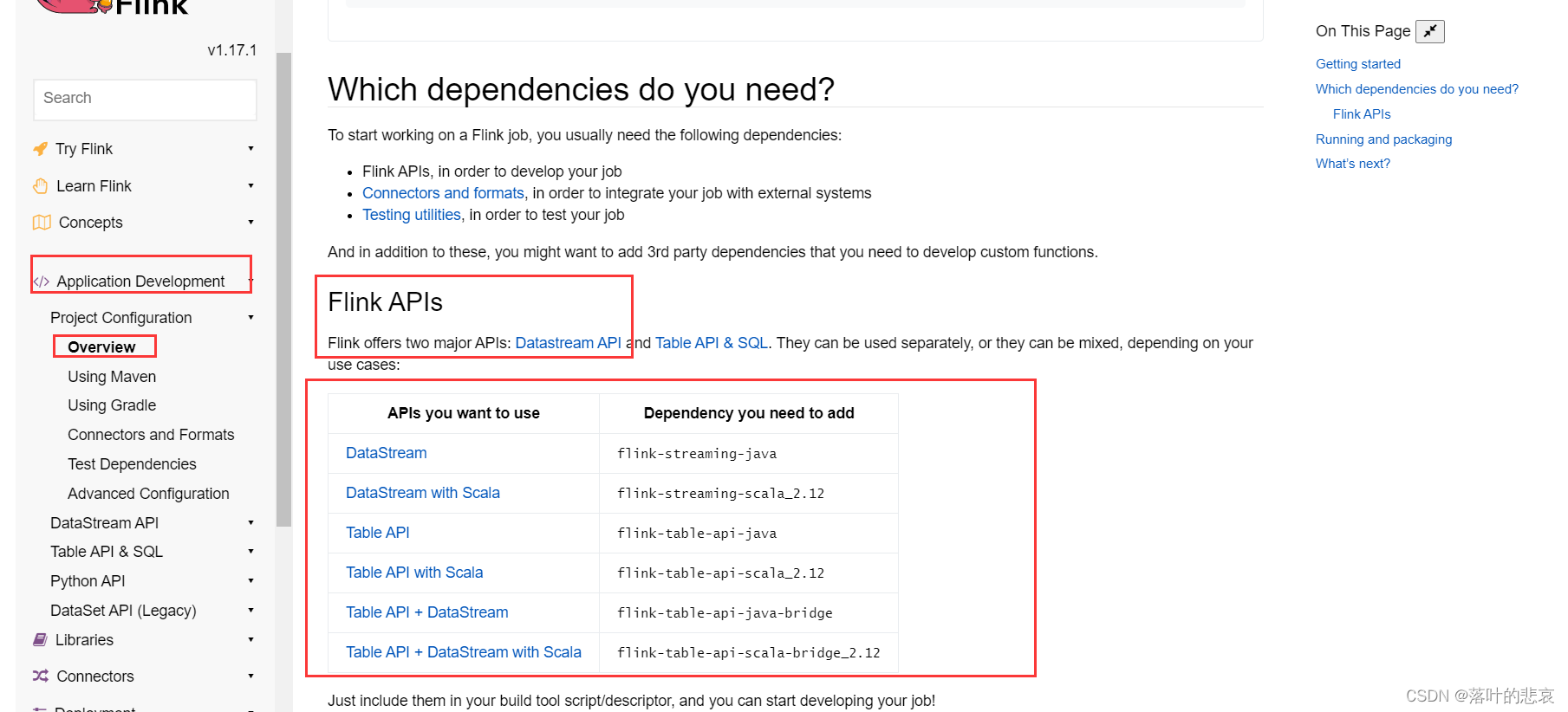
这里说明了相关的依赖需要引入的依赖包的版本,还有使用kafka消费的时候需要引入的连接包版本
完整的pom引入依赖如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.wh.flink</groupId><artifactId>flink</artifactId><version>1.0-SNAPSHOT</version><name>flink</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><flink.version>1.17.1</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- Flink 依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><!-- Flink Kafka连接器的依赖 -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-connector-kafka-0.11_2.11</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- Flink 开发Scala需要导入以下依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><!--<dependency>--><!--<groupId>org.scala-lang</groupId>--><!--<artifactId>scala-library</artifactId>--><!--<version>2.11.12</version>--><!--</dependency>--><!-- log4j 和slf4j 包,如果在控制台不想看到日志,可以将下面的包注释掉--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-log4j12</artifactId>--><!--<version>1.7.25</version>--><!--<scope>test</scope>--><!--</dependency>--><!--<dependency>--><!--<groupId>log4j</groupId>--><!--<artifactId>log4j</artifactId>--><!--<version>1.2.17</version>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-api</artifactId>--><!--<version>1.7.25</version>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-nop</artifactId>--><!--<version>1.7.25</version>--><!--<scope>test</scope>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-simple</artifactId>--><!--<version>1.7.5</version>--><!--</dependency>--></dependencies><build><plugins><!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<!-- <plugin>-->
<!-- <groupId>org.scala-tools</groupId>-->
<!-- <artifactId>maven-scala-plugin</artifactId>-->
<!-- <version>2.15.2</version>-->
<!-- <executions>-->
<!-- <execution>-->
<!-- <goals>-->
<!-- <goal>compile</goal>-->
<!-- <goal>testCompile</goal>-->
<!-- </goals>-->
<!-- </execution>-->
<!-- </executions>-->
<!-- </plugin>--><plugin><artifactId>maven-assembly-plugin</artifactId><version>2.4</version><configuration><!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” --><!--<appendAssemblyId>false</appendAssemblyId>--><archive><manifest><mainClass>com.hadoop.demo.service.flinkDemo.FlinkDemo</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin></plugins></build>
</project>
项目结构如图
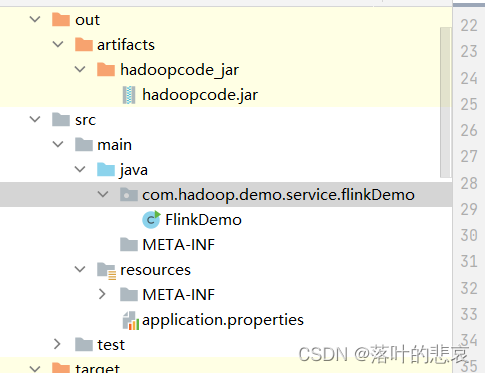
2.2 代码编写
package com.hadoop.demo.service.flinkDemo;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.FlatMapIterator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;
import java.util.Iterator;public class FlinkDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//新建kafka连接KafkaSource<String> kfkSource = KafkaSource.<String>builder().setBootstrapServers("192.168.184.129:9092").setGroupId("flink").setTopics("flinkTest").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();//添加到flink环境DataStreamSource<String> lines = env.fromSource(kfkSource, WatermarkStrategy.noWatermarks(), "kafka source");//根据逗号分组SingleOutputStreamOperator<Tuple2<String, Integer>> map = lines.flatMap(new FlatMapIterator<String, String>() {@Overridepublic Iterator<String> flatMap(String s) throws Exception {return Arrays.asList(s.split(",")).iterator();}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String s) throws Exception {return new Tuple2<>(s, 1);}});//统计每个单词的数量SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy(0).sum(1);sum.print();//System.out.println(sum.get);env.execute();}}2.3 maven打包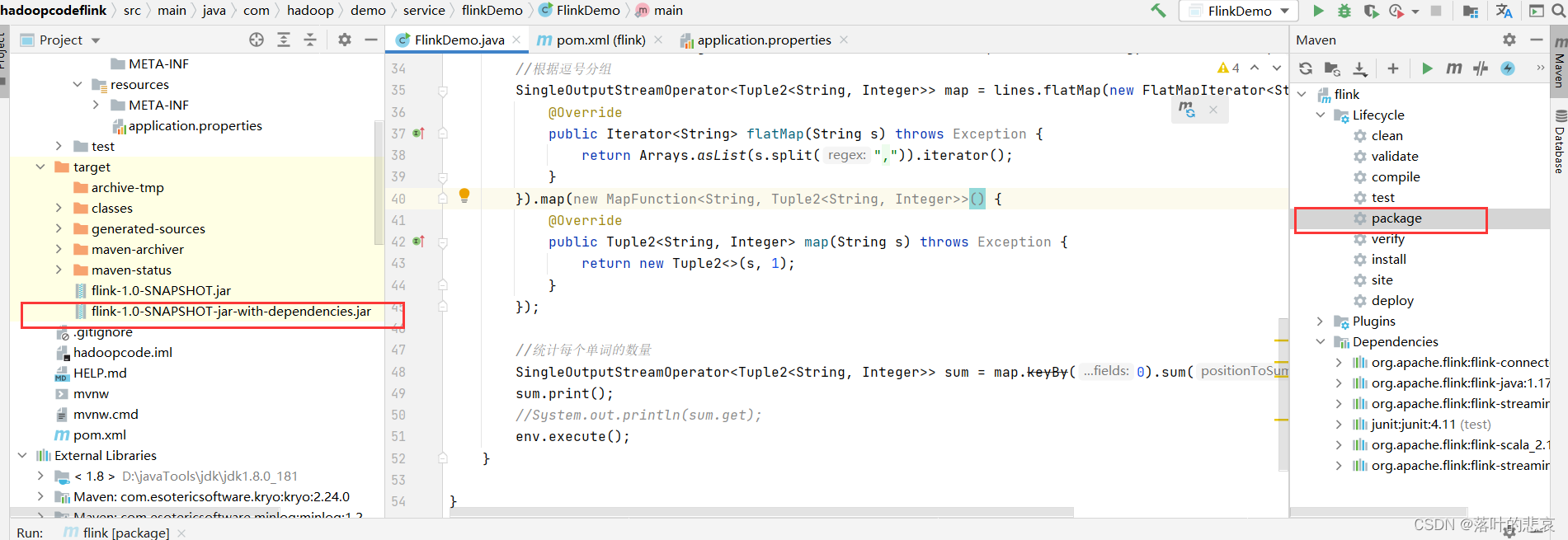
点击打包按钮,这里注意要选择带依赖的jar包,否则会出现以下错误。
NoClassDefFoundError: org/apache/flink/connector/kafka/source/KafkaSource
三、测试
3.1启动 hadoop集群,启动flink集群
这里如果不知道怎么搭建这两个集群可以看我其他文章
hadoop集成flink
./hadoop.sh start
./bin/yarn-session.sh --detached
3.2 上传jar包到flink集群
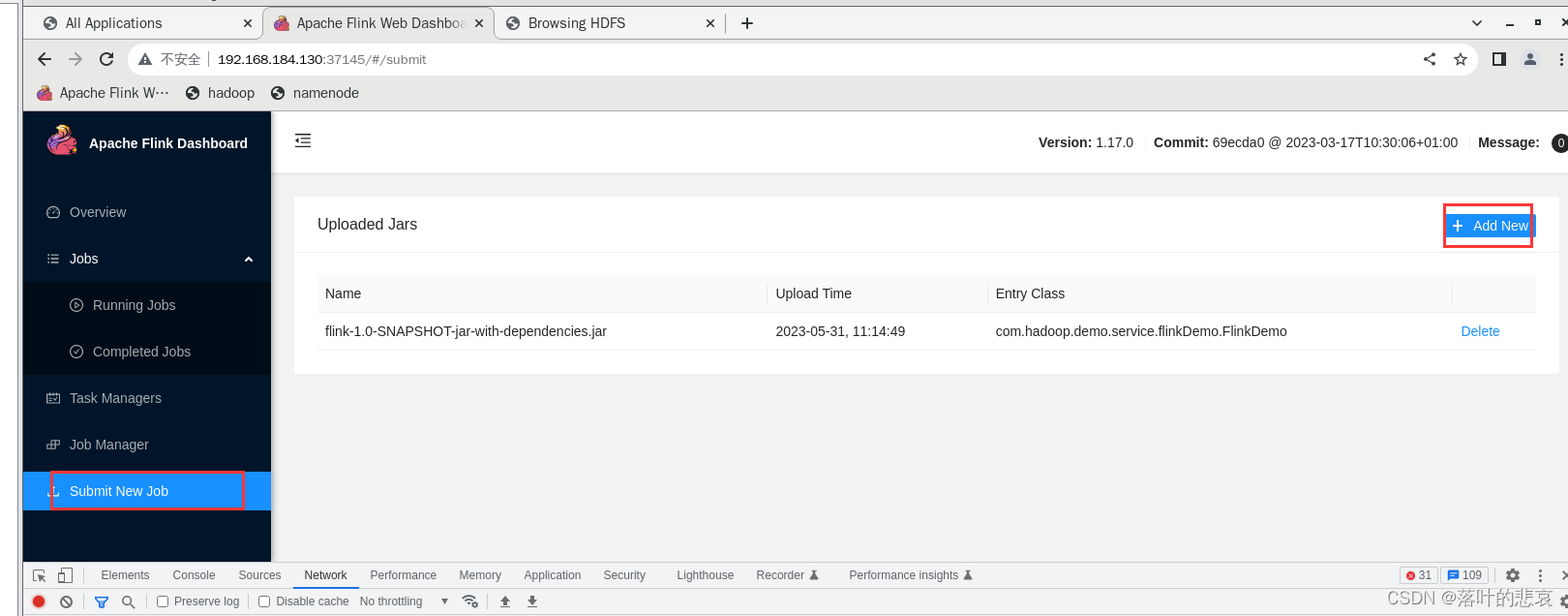
上传后填写主类类名,点击提交
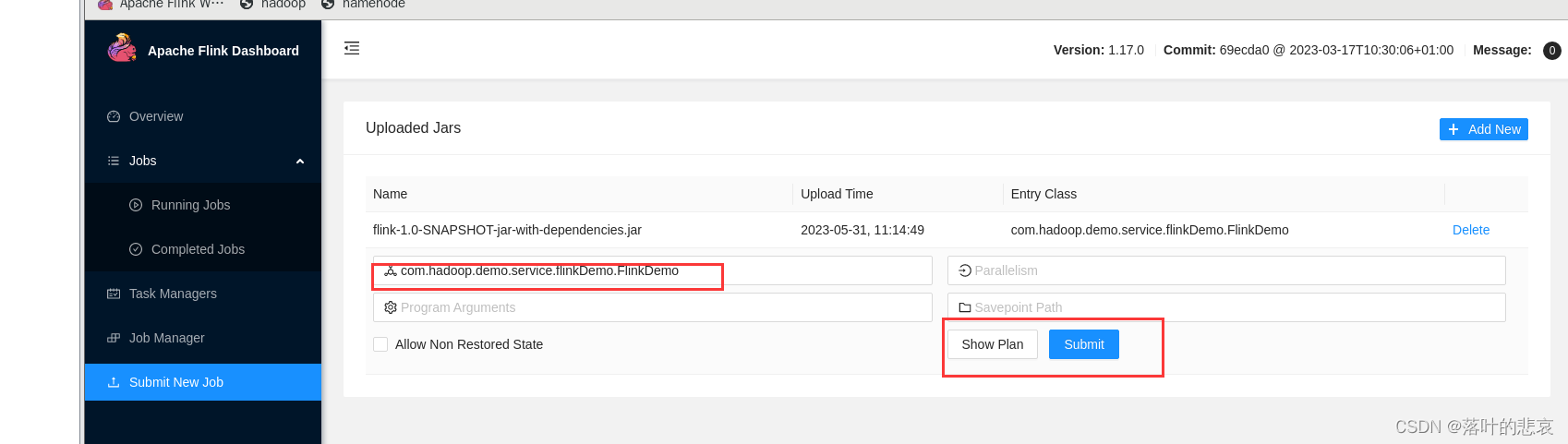
3.3 测试
点击后,可以看到执行job这里能看到在运行的job
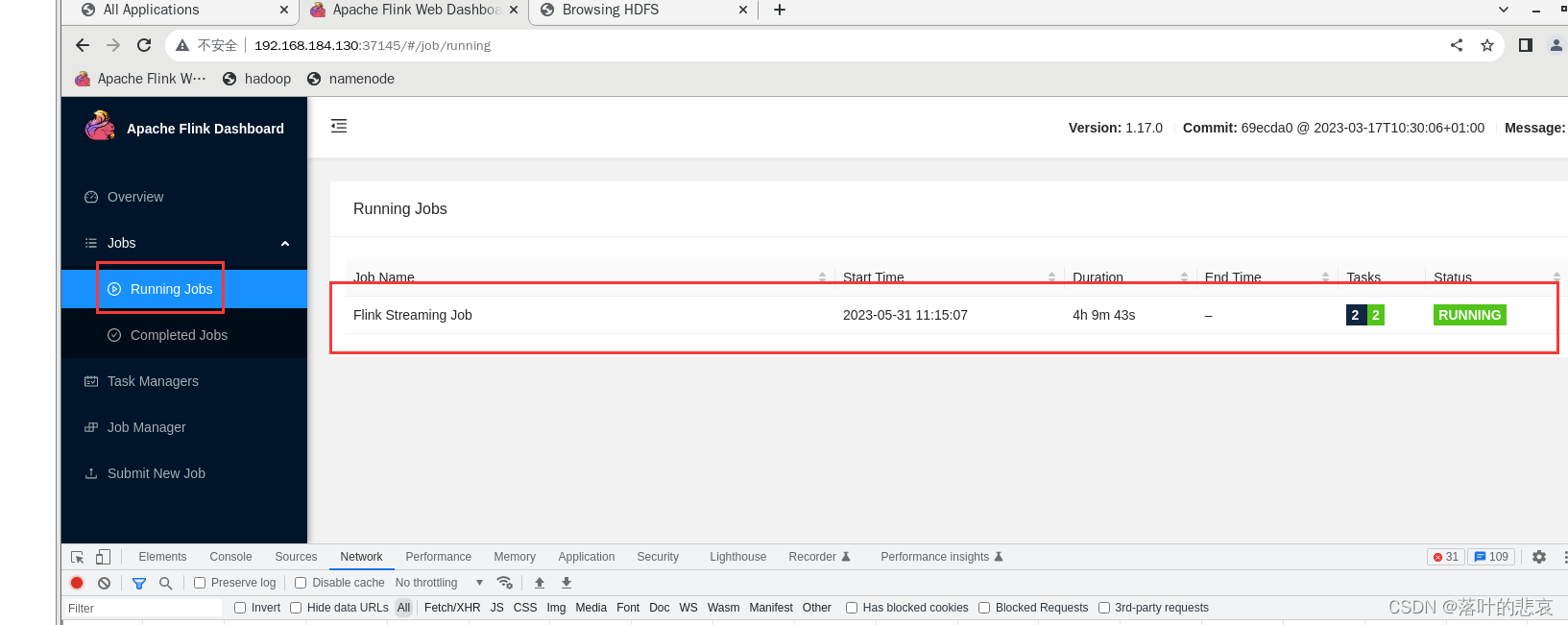
点击运行的task
点击输出
这里可以看到输出内容,
在kafka消费端输入内容,
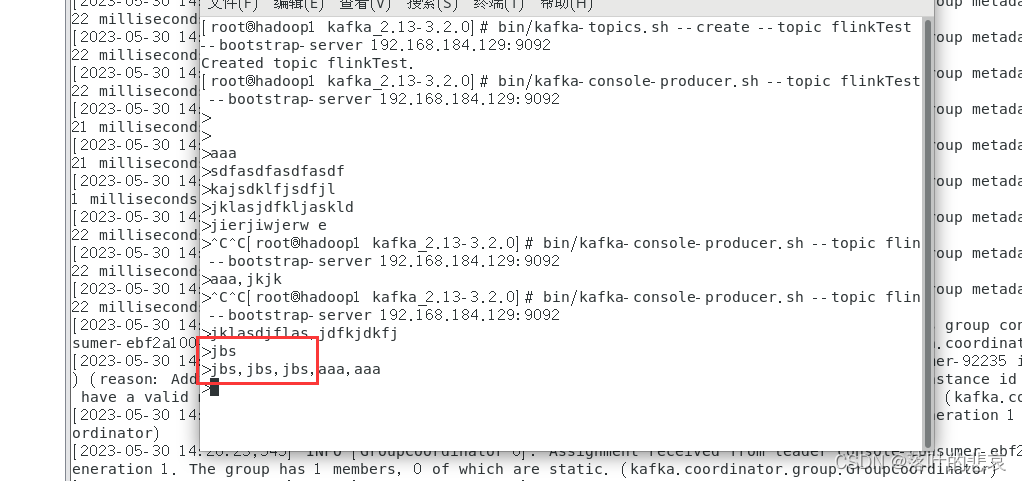
这里的jbs出现了4次,看下输出控制台,
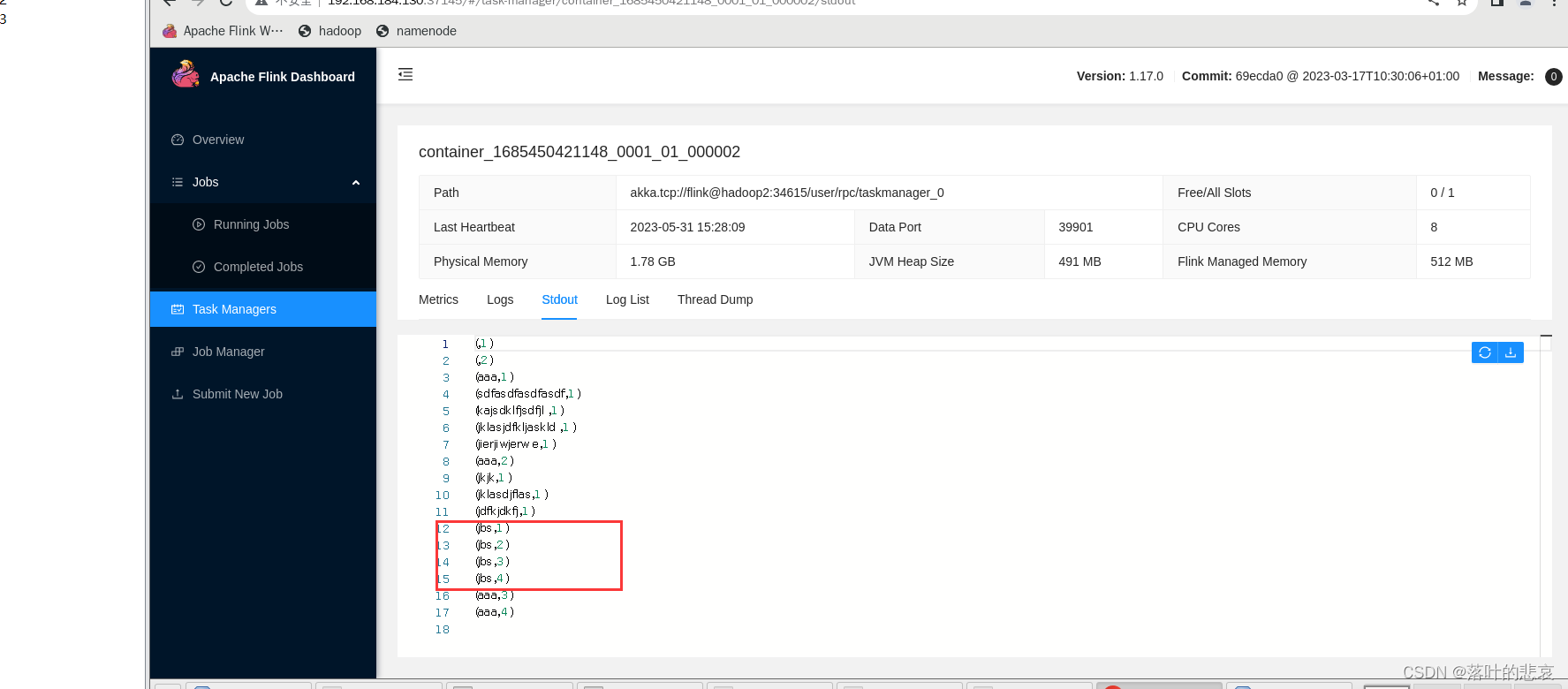
可以看到这里依次累加了四次,说明统计生效了。
总结
这里只是做了一个简单的消费kafka的flink例子,消费成功后还可以通过sink发送出去,还可以用transform进行转换,这里后面再演示,如果不对的可以指出。
相关文章:
flink1.17.0 集成kafka,并且计算
前言 flink是实时计算的重要集成组件,这里演示如何集成,并且使用一个小例子。例子是kafka输入消息,用逗号隔开,统计每个相同单词出现的次数,这么一个功能。 一、kafka环境准备 1.1 启动kafka 这里我使用的kafka版本…...

【华为OD机试】数组组成的最小数字【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述: 给定一个整型数组,请从该数组中选择3个元素组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述: 一行用半角逗号分割的字符串记录的整型数…...

Exponential Loss 中的关于indicator 函数的一个恒等式
− x y 2 I ( x ≠ y ) − 1 -xy2\mathbf{ I}(x \ne y)-1 −xy2I(xy)−1 其中 I \mathbf{ I} I 是 indicator 函数, 定义域 为True ,函数值为 1 反之为 0 x,y 都 可以取值 {-1,1} 证明过程见下表: xy左式右式-1-1-1-111-1-1-11111-111...
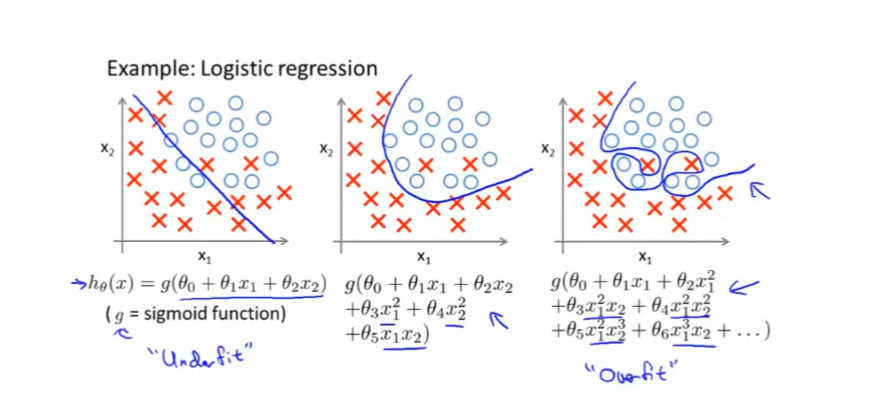
【机器学习】浅析过拟合
过度拟合 我们来想象如下一个场景:我们准备了10000张西瓜的照片让算法训练识别西瓜图像,但是这 10000张西瓜的图片都是有瓜梗的,算法在拟合西瓜的特征的时候,将西瓜带瓜梗当作了一个一般性的特征。此时出现一张没有瓜梗的西瓜照片…...
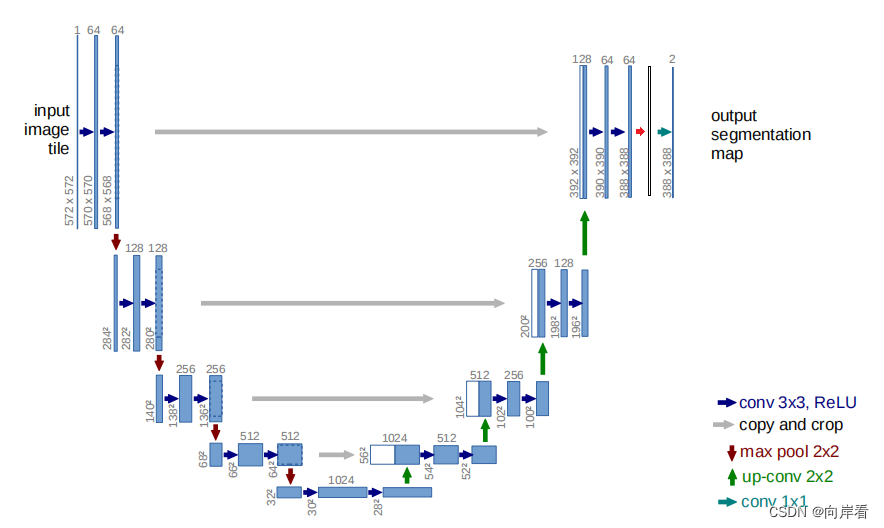
尝试在UNet的不同位置添加SE模块
目录 (1)se-unet01(在卷积后,下采样前,添加SE模块) (2)se-unet02(在卷积后,上采样前,添加SE模块) (3)se-un…...
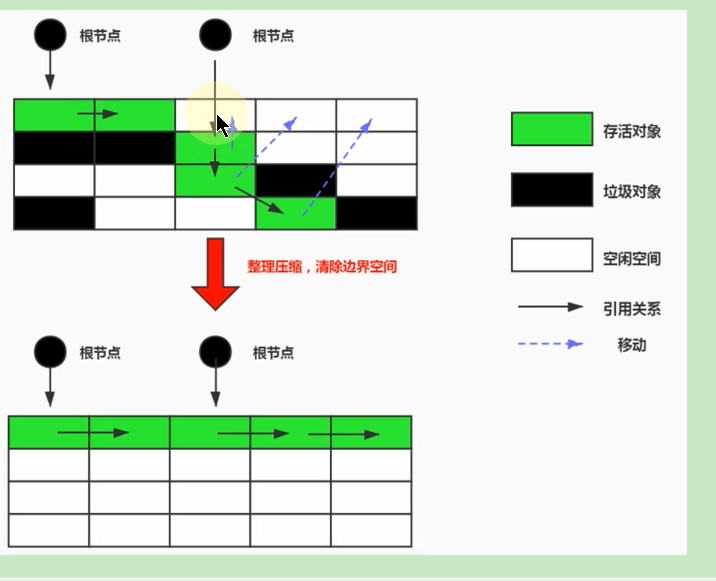
JVM垃圾回收篇之相关概念和算法
垃圾回收相关概念 什么是垃圾 垃圾就是指在运行程序中没有任何指针指向的对象,这个对象就是需要被回收掉的垃圾,如果不及时进行清理,越积越多就会导致内存溢出. 为什么需要GC 不进行回收,早晚会导致内存溢出,Java自动管理垃圾回收,不需要开发人员手动干预,这就有可能导致开…...
(学习日记)2023.04.27
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

亚马逊CPC广告每日该怎么调整?
01 CPC广告需要每日调整吗? 其实,亚马逊广告是不建议每天都做过多调整的。 为什么呢?调整太频繁了,看不到每天调整的结果是不是? 什么时候需要调整呢? 就是广告指标,比如说曝光、点击、转化率情…...
ffmpeg下载及ffmpy3安装使用
ffmpeg下载及ffmpy3安装使用 1.下载ffmpeg 进入网址:https://www.gyan.dev/ffmpeg/builds/ 在release builds中下载ffmpeg-release-full.7z 下载好后解压到自己想存放的目录,例如:D:\Tool\ffmpeg-6.0-full_build 2.配置环境变量 右键此电…...

设计模式之~原型模式
定义:用原型实例指导创建对象的种类,并且通过拷贝这些原型创建新的对象。原型模式其实就是从一个对象再创建另外一个可定制的对象,而且不需知道任何创建的细节。 优点: 一般在初始化的信息不发生变化的情况下,克隆是最…...

多传感器融合SLAM --- 8.LIO-SAM基础知识解读
目录 1 惯性测量单元简介及预积分 1.1 IMU 器件介绍及选型建议 1.2 IMU状态传递方程...

多模态大模型时代下的文档图像智能分析与处理
多模态大模型时代下的文档图像智能分析与处理 0. 前言1. 人工智能发展历程1.1 传统机器学习1.2 深度学习1.3 多模态大模型时代 2. CCIG 文档图像智能分析与处理论坛2.1 文档图像智能分析与处理的重要性和挑战2.2 文档图像智能分析与处理高峰论坛2.3 走进合合信息 3. 文档图像智…...
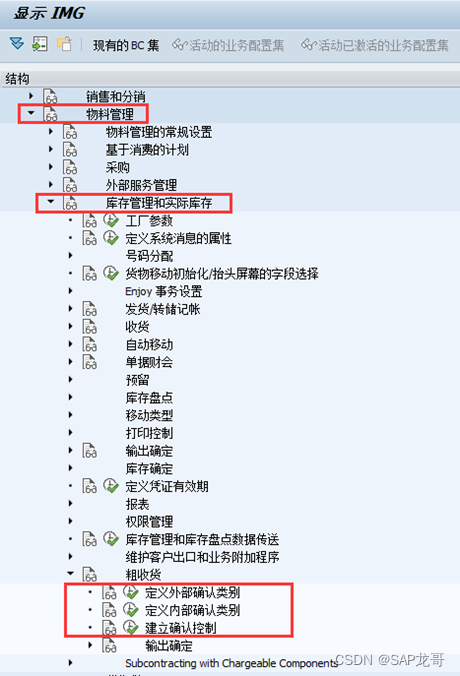
SAP-MM-内向外向交货单
1、内向&外向交货单概念 外向交货(outbound delivery)是用在客户与企业之间的交货单,而内向交货(inbound delivery)则是用在供应商与企业之间的交货单;换言之,外向交货多用于SD 模块&#…...

Mysql - date、datetime、timestamp 的区别
date、datetime 的区别 顾名思义,date 日期,datetime 日期时间,所以 date 是 datetime 的日期部分MySQL 以 格式检索和显示 datetime 值 YYYY-MM-DD hh:mm:ss datetime 支持的日期时间范围 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 d…...
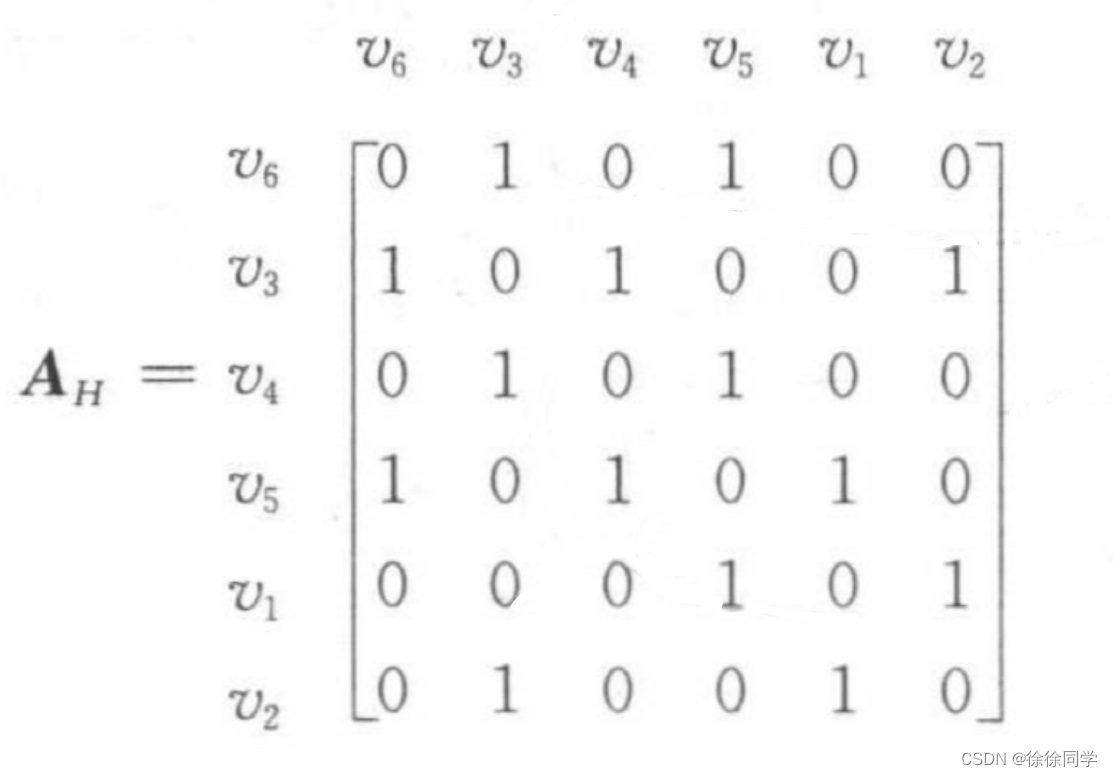
离散数学_十章-图 ( 4 ):图的表示和图的同构
📷10.4 图的表示和图的同构 1. 图的表示1.1 邻接表1.1.1 简单图的邻接表1.1.2 有向图的邻接表 1.2 邻接矩阵❗在邻接表和邻接矩阵之间取舍1.3 关联矩阵 2. 图同构3. ⚡判断两个简单图是否同构 图的表示方式有很多种,选择最方便的表示有助于对图的处理~ …...

MySQL锁的分类
MySQL锁的分类 全局锁 表级锁 ● 表锁 ● 元数据锁,Meta Data Lock,MDL锁 ● 意向锁 ● AUTO_INC 锁 行级锁(Innodb引擎牛比的地方) ● record lock,记录锁,也就是仅仅把一条记录给锁上了 ● gap lock,间隙锁ÿ…...

程序员如何给变量起名字
程序员如何给变量起名字 在编写代码时,为变量命名是非常重要的。良好的命名习惯可以提高代码的可读性和可维护性,使得其他开发者能够更容易地理解你的代码。在这篇文章中,我们将讨论程序员如何为变量选择合适的名称。 规范 首先࿰…...
)
隔板法(求解的组数)
文章目录 隔板法(求解的组数)隔板法扩展 例题 隔板法(求解的组数) 文章首发于我的个人博客:欢迎大佬们来逛逛 隔板法 隔板法能够解决的问题: 求线性不定方程的解的组数求相同元素分组的方案数 给我们 …...

智能文档处理黑科技,拥抱更高效的数字世界
目录 0 写在前面1 为何要关注智慧文档?2 图像弯曲矫正3 手写板反光擦除4 版面元素检测5 文档篡改检测总结 0 写在前面 近期,中国图象图形学学会文档图像分析与识别专业委员会与上海合合信息科技有限公司联合打造了《文档图像智能分析与处理》高峰论坛。…...

vue ts写法
Vue.js 和 TypeScript 结合使用可以让你的项目更加健壮和易于维护。在 Vue 3 中,你可以使用 Vue.js 的 Composition API 和 TypeScript 一起使用。以下是一个简单的 Vue.js 和 TypeScript 结合使用的例子: 首先,确保你已经安装了 Vue.js 和 T…...

华实展厅出圈!大自然标识匠心打造,目视化呈现基建巨头的实力底气
当建筑的厚重与视觉的美感碰撞,当企业的成长与科技的便捷融合,华实建设集团企业展厅——由专业的长沙市大自然标识设计制作公司倾力打造,不仅是品牌形象的“窗口”,更是实力与文化的“立体名片”。长沙市大自然标识设计制作有限公…...

将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量 当企业内部多个业务线或团队开始独立探索和应用大模型能力时&#…...

王小川All in医疗大模型:从通用赛道抽身,“造AI医生”能否突围?
All in医疗有它的代价一年前,王小川带着百川智能大幅缩减通用模型团队,关闭多条行业线,All in医疗大模型。当时整个大模型行业热闹非凡,平均3天就有一个新版本的通用大模型面世。而百川在5月22日交出答卷,发布新医疗大…...

别再只盯着交叉熵了:用PyTorch的TripletMarginLoss搞定人脸识别和商品推荐
超越交叉熵:PyTorch TripletMarginLoss在人脸识别与商品推荐中的实战指南 在深度学习的世界里,交叉熵损失函数长期占据着分类任务的主导地位。然而,当我们需要衡量样本之间的相对距离而非绝对类别时,一种更为强大的工具正在悄然改…...
)
Gemini深度研究模式 vs Claude 3.5 Sonnet vs GPT-4o Research:12项学术任务横向评测(含原始数据表)
更多请点击: https://codechina.net 第一章:Gemini深度研究模式体验 Gemini 深度研究模式(Deep Research Mode)是 Google 推出的面向复杂信息探索任务的增强型交互能力,专为学术调研、技术尽调与跨源知识整合场景设计…...

iOS自动化测试避坑指南:WebDriverAgent签名与真机调试实战
1. 这不是“又一个Appium教程”,而是我踩了三个月坑后画的避坑地图你搜“Appium iOS自动化测试教程”,首页全是“三步跑通Demo”“手把手教你写第一个脚本”——结果照着做,Xcode一编译就报错,WebDriverAgent装不上,真…...

G-Helper终极指南:三步打造高效轻量的华硕笔记本控制中心
G-Helper终极指南:三步打造高效轻量的华硕笔记本控制中心 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

高效网络资源捕获工具res-downloader完全指南:从入门到精通
高效网络资源捕获工具res-downloader完全指南:从入门到精通 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

HACS极速版终极指南:告别智能家居插件下载龟速的完整解决方案
HACS极速版终极指南:告别智能家居插件下载龟速的完整解决方案 【免费下载链接】integration 🇨🇳 HACS 极速版,无需登陆Github 项目地址: https://gitcode.com/gh_mirrors/int/integration 你是否曾经为了给Home Assistant…...

华硕笔记本G-Helper显示管理全攻略:从色彩异常到专业校准的5步解决方案
华硕笔记本G-Helper显示管理全攻略:从色彩异常到专业校准的5步解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivob…...