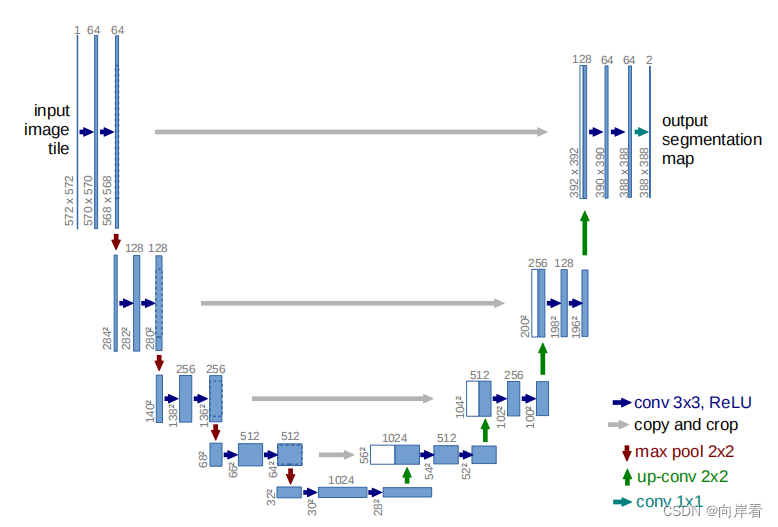
尝试在UNet的不同位置添加SE模块
目录
(1)se-unet01(在卷积后,下采样前,添加SE模块)
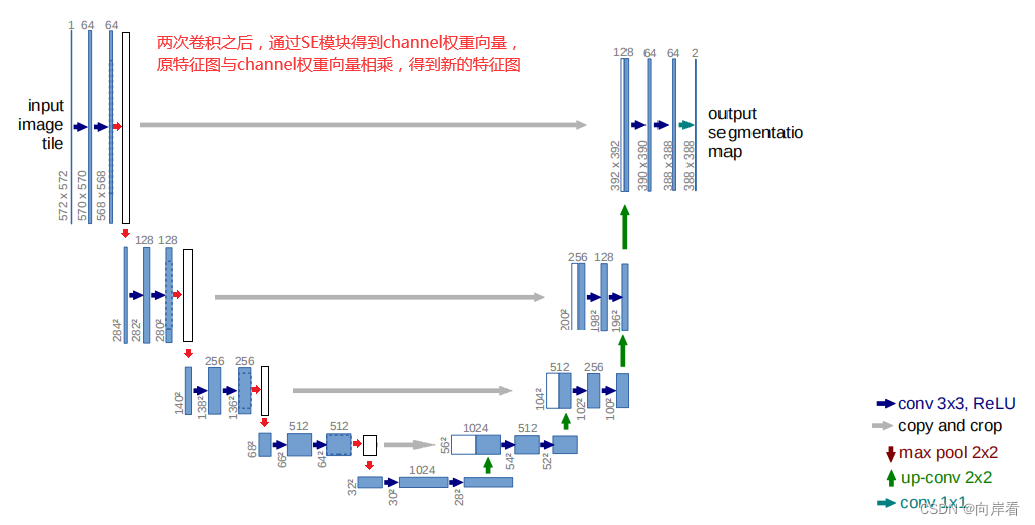
(2)se-unet02(在卷积后,上采样前,添加SE模块)
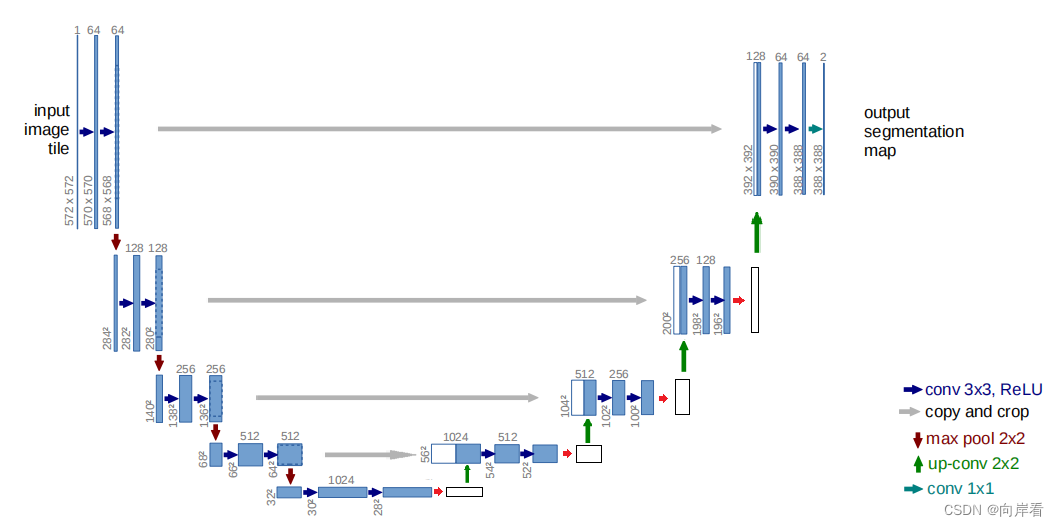
(3)se-unet03(在每两个卷积之后,加上SE模块)
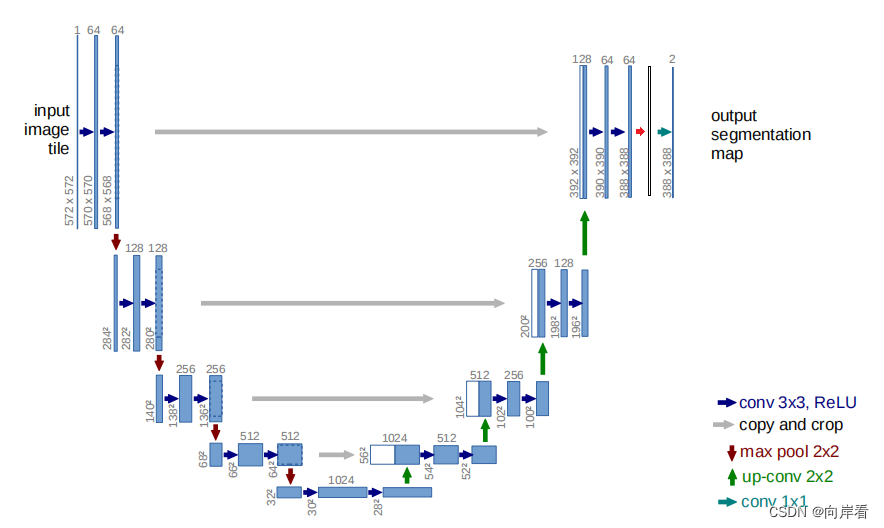
(4)se-unet04(只在最后的输出卷积后,添加SE模块)
数据集:refuge视盘数据集
训练轮次:50
评价指标:dice coefficient、mean IOU
| Architecture | dice coefficient | mean IOU |
| unet | 0.989 | 61.1 |
| se-unet01 | 0.989 | 63.3 |
| se-unet02 | 0.988 | 60.5 |
| se-unet03 | 0.988 | 67.3 |
| se-unet04 | 0.989 | 67.2 |
(1)在卷积后,下采样前,添加SE模块
模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数def __init__(self, in_channels, out_channels, mid_channels=None):if mid_channels is None:mid_channels = out_channelssuper(DoubleConv, self).__init__(# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True),nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))# 下采样
class Down(nn.Sequential):def __init__(self, in_channels, out_channels):super(Down, self).__init__(# 1.最大池化的窗口大小为2, 步长为2nn.MaxPool2d(2, stride=2),# 2.两个卷积DoubleConv(in_channels, out_channels))# 上采样
class Up(nn.Module):# bilinear是否采用双线性插值def __init__(self, in_channels, out_channels, bilinear=True):super(Up, self).__init__()if bilinear:# 使用双线性插值上采样# 上采样率为2,双线性插值模式self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)else:# 使用转置卷积上采样self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:x1 = self.up(x1)# [N, C, H, W]# 上采样之后的特征图与要拼接的特征图,高度方向的差值diff_y = x2.size()[2] - x1.size()[2]# 上采样之后的特征图与要拼接的特征图,宽度方向的差值diff_x = x2.size()[3] - x1.size()[3]# padding_left, padding_right, padding_top, padding_bottom# 1.填充差值x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,diff_y // 2, diff_y - diff_y // 2])# 2.拼接x = torch.cat([x2, x1], dim=1)# 3.卷积,两次卷积x = self.conv(x)return x# 最后的1*1输出卷积
class OutConv(nn.Sequential):def __init__(self, in_channels, num_classes):super(OutConv, self).__init__(nn.Conv2d(in_channels, num_classes, kernel_size=1))class UNet(nn.Module):# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数def __init__(self,in_channels: int = 1,num_classes: int = 2,bilinear: bool = True,base_c: int = 64):super(UNet, self).__init__()self.in_channels = in_channelsself.num_classes = num_classesself.bilinear = bilinearself.in_conv = DoubleConv(in_channels, base_c)# SE模块self.SE1 = SE_Block(base_c)self.SE2 = SE_Block(base_c * 2)self.SE3 = SE_Block(base_c * 4)self.SE4 = SE_Block(base_c * 8)# 下采样,参数:输入通道,输出通道self.down1 = Down(base_c, base_c * 2)self.down2 = Down(base_c * 2, base_c * 4)self.down3 = Down(base_c * 4, base_c * 8)# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1factor = 2 if bilinear else 1# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024self.down4 = Down(base_c * 8, base_c * 16 // factor)self.SE5 = SE_Block(base_c * 16 // factor)# 上采样,参数:输入通道,输出通道self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)self.up4 = Up(base_c * 2, base_c, bilinear)# 最后的1*1输出卷积self.out_conv = OutConv(base_c, num_classes)# 正向传播过程def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:# 1. 定义最开始的两个卷积层x1 = self.in_conv(x)x1 = self.SE1(x1)# 2. contracting path(收缩路径)x2 = self.down1(x1)x2 = self.SE2(x2)x3 = self.down2(x2)x3 = self.SE3(x3)x4 = self.down3(x3)x4 = self.SE4(x4)x5 = self.down4(x4)x5 = self.SE5(x5)# 3. expanding path(扩展路径)x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)# 4. 最后1*1输出卷积logits = self.out_conv(x)return {"out": logits}
(2)在卷积后,上采样前,添加SE模块
模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F# se-unet02
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数def __init__(self, in_channels, out_channels, mid_channels=None):if mid_channels is None:mid_channels = out_channelssuper(DoubleConv, self).__init__(# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True),nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))# 下采样
class Down(nn.Sequential):def __init__(self, in_channels, out_channels):super(Down, self).__init__(# 1.最大池化的窗口大小为2, 步长为2nn.MaxPool2d(2, stride=2),# 2.两个卷积DoubleConv(in_channels, out_channels))# 上采样
class Up(nn.Module):# bilinear是否采用双线性插值def __init__(self, in_channels, out_channels, bilinear=True):super(Up, self).__init__()if bilinear:# 使用双线性插值上采样# 上采样率为2,双线性插值模式self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)else:# 使用转置卷积上采样self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:x1 = self.up(x1)# [N, C, H, W]# 上采样之后的特征图与要拼接的特征图,高度方向的差值diff_y = x2.size()[2] - x1.size()[2]# 上采样之后的特征图与要拼接的特征图,宽度方向的差值diff_x = x2.size()[3] - x1.size()[3]# padding_left, padding_right, padding_top, padding_bottom# 1.填充差值x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,diff_y // 2, diff_y - diff_y // 2])# 2.拼接x = torch.cat([x2, x1], dim=1)# 3.卷积,两次卷积x = self.conv(x)return x# 最后的1*1输出卷积
class OutConv(nn.Sequential):def __init__(self, in_channels, num_classes):super(OutConv, self).__init__(nn.Conv2d(in_channels, num_classes, kernel_size=1))class UNet(nn.Module):# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数def __init__(self,in_channels: int = 1,num_classes: int = 2,bilinear: bool = True,base_c: int = 64):super(UNet, self).__init__()self.in_channels = in_channelsself.num_classes = num_classesself.bilinear = bilinearself.in_conv = DoubleConv(in_channels, base_c)# 下采样,参数:输入通道,输出通道self.down1 = Down(base_c, base_c * 2)self.down2 = Down(base_c * 2, base_c * 4)self.down3 = Down(base_c * 4, base_c * 8)# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1factor = 2 if bilinear else 1# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024self.down4 = Down(base_c * 8, base_c * 16 // factor)# 上采样,参数:输入通道,输出通道self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)self.up4 = Up(base_c * 2, base_c, bilinear)# 最后的1*1输出卷积self.out_conv = OutConv(base_c, num_classes)# SE模块self.SE1 = SE_Block(base_c * 16 // factor)self.SE2 = SE_Block(base_c * 8 // factor)self.SE3 = SE_Block(base_c * 4 // factor)self.SE4 = SE_Block(base_c * 2 // factor)# 正向传播过程def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:# 1. 定义最开始的两个卷积层x1 = self.in_conv(x)# 2. contracting path(收缩路径)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)x5 = self.SE1(x5)# 3. expanding path(扩展路径)x = self.up1(x5, x4)x = self.SE2(x)x = self.up2(x, x3)x = self.SE3(x)x = self.up3(x, x2)x = self.SE4(x)x = self.up4(x, x1)# 4. 最后1*1输出卷积logits = self.out_conv(x)return {"out": logits}
(3)在每两个卷积之后,加上SE模块

模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F# se-unet03
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数def __init__(self, in_channels, out_channels, mid_channels=None):if mid_channels is None:mid_channels = out_channelssuper(DoubleConv, self).__init__(# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True),nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))# 下采样
class Down(nn.Sequential):def __init__(self, in_channels, out_channels):super(Down, self).__init__(# 1.最大池化的窗口大小为2, 步长为2nn.MaxPool2d(2, stride=2),# 2.两个卷积DoubleConv(in_channels, out_channels))# 上采样
class Up(nn.Module):# bilinear是否采用双线性插值def __init__(self, in_channels, out_channels, bilinear=True):super(Up, self).__init__()if bilinear:# 使用双线性插值上采样# 上采样率为2,双线性插值模式self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)else:# 使用转置卷积上采样self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:x1 = self.up(x1)# [N, C, H, W]# 上采样之后的特征图与要拼接的特征图,高度方向的差值diff_y = x2.size()[2] - x1.size()[2]# 上采样之后的特征图与要拼接的特征图,宽度方向的差值diff_x = x2.size()[3] - x1.size()[3]# padding_left, padding_right, padding_top, padding_bottom# 1.填充差值x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,diff_y // 2, diff_y - diff_y // 2])# 2.拼接x = torch.cat([x2, x1], dim=1)# 3.卷积,两次卷积x = self.conv(x)return x# 最后的1*1输出卷积
class OutConv(nn.Sequential):def __init__(self, in_channels, num_classes):super(OutConv, self).__init__(nn.Conv2d(in_channels, num_classes, kernel_size=1))class UNet(nn.Module):# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数def __init__(self,in_channels: int = 1,num_classes: int = 2,bilinear: bool = True,base_c: int = 64):super(UNet, self).__init__()self.in_channels = in_channelsself.num_classes = num_classesself.bilinear = bilinearself.in_conv = DoubleConv(in_channels, base_c)# 下采样,参数:输入通道,输出通道self.down1 = Down(base_c, base_c * 2)self.down2 = Down(base_c * 2, base_c * 4)self.down3 = Down(base_c * 4, base_c * 8)# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1factor = 2 if bilinear else 1# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024self.down4 = Down(base_c * 8, base_c * 16 // factor)# 上采样,参数:输入通道,输出通道self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)self.up4 = Up(base_c * 2, base_c, bilinear)# 最后的1*1输出卷积self.out_conv = OutConv(base_c, num_classes)# SE模块self.SE1 = SE_Block(base_c)self.SE2 = SE_Block(base_c * 2)self.SE3 = SE_Block(base_c * 4)self.SE4 = SE_Block(base_c * 8)self.SE5 = SE_Block(base_c * 16 // factor)self.SE6 = SE_Block(base_c * 8 // factor)self.SE7 = SE_Block(base_c * 4 // factor)self.SE8 = SE_Block(base_c * 2 // factor)# 正向传播过程def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:# 1. 定义最开始的两个卷积层x1 = self.in_conv(x)x1 = self.SE1(x1)# 2. contracting path(收缩路径)x2 = self.down1(x1)x2 = self.SE2(x2)x3 = self.down2(x2)x3 = self.SE3(x3)x4 = self.down3(x3)x4 = self.SE4(x4)x5 = self.down4(x4)x5 = self.SE5(x5)# 3. expanding path(扩展路径)x = self.up1(x5, x4)x = self.SE6(x)x = self.up2(x, x3)x = self.SE7(x)x = self.up3(x, x2)x = self.SE8(x)x = self.up4(x, x1)# 4. 最后1*1输出卷积logits = self.out_conv(x)return {"out": logits}
(4)只在最后的输出卷积前,添加SE模块
模型修改代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F# se-unet04
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数def __init__(self, in_channels, out_channels, mid_channels=None):if mid_channels is None:mid_channels = out_channelssuper(DoubleConv, self).__init__(# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True),nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))# 下采样
class Down(nn.Sequential):def __init__(self, in_channels, out_channels):super(Down, self).__init__(# 1.最大池化的窗口大小为2, 步长为2nn.MaxPool2d(2, stride=2),# 2.两个卷积DoubleConv(in_channels, out_channels))# 上采样
class Up(nn.Module):# bilinear是否采用双线性插值def __init__(self, in_channels, out_channels, bilinear=True):super(Up, self).__init__()if bilinear:# 使用双线性插值上采样# 上采样率为2,双线性插值模式self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)else:# 使用转置卷积上采样self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:x1 = self.up(x1)# [N, C, H, W]# 上采样之后的特征图与要拼接的特征图,高度方向的差值diff_y = x2.size()[2] - x1.size()[2]# 上采样之后的特征图与要拼接的特征图,宽度方向的差值diff_x = x2.size()[3] - x1.size()[3]# padding_left, padding_right, padding_top, padding_bottom# 1.填充差值x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,diff_y // 2, diff_y - diff_y // 2])# 2.拼接x = torch.cat([x2, x1], dim=1)# 3.卷积,两次卷积x = self.conv(x)return x# 最后的1*1输出卷积
class OutConv(nn.Sequential):def __init__(self, in_channels, num_classes):super(OutConv, self).__init__(nn.Conv2d(in_channels, num_classes, kernel_size=1))class UNet(nn.Module):# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数def __init__(self,in_channels: int = 1,num_classes: int = 2,bilinear: bool = True,base_c: int = 64):super(UNet, self).__init__()self.in_channels = in_channelsself.num_classes = num_classesself.bilinear = bilinearself.in_conv = DoubleConv(in_channels, base_c)# 下采样,参数:输入通道,输出通道self.down1 = Down(base_c, base_c * 2)self.down2 = Down(base_c * 2, base_c * 4)self.down3 = Down(base_c * 4, base_c * 8)# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1factor = 2 if bilinear else 1# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024self.down4 = Down(base_c * 8, base_c * 16 // factor)# 上采样,参数:输入通道,输出通道self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)self.up4 = Up(base_c * 2, base_c, bilinear)# 最后的1*1输出卷积self.out_conv = OutConv(base_c, num_classes)# SE模块self.SE4 = SE_Block(base_c)# 正向传播过程def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:# 1. 定义最开始的两个卷积层x1 = self.in_conv(x)# 2. contracting path(收缩路径)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)# 3. expanding path(扩展路径)x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)x = self.SE4(x)# 4. 最后1*1输出卷积logits = self.out_conv(x)return {"out": logits}
相关文章:
尝试在UNet的不同位置添加SE模块
目录 (1)se-unet01(在卷积后,下采样前,添加SE模块) (2)se-unet02(在卷积后,上采样前,添加SE模块) (3)se-un…...
JVM垃圾回收篇之相关概念和算法
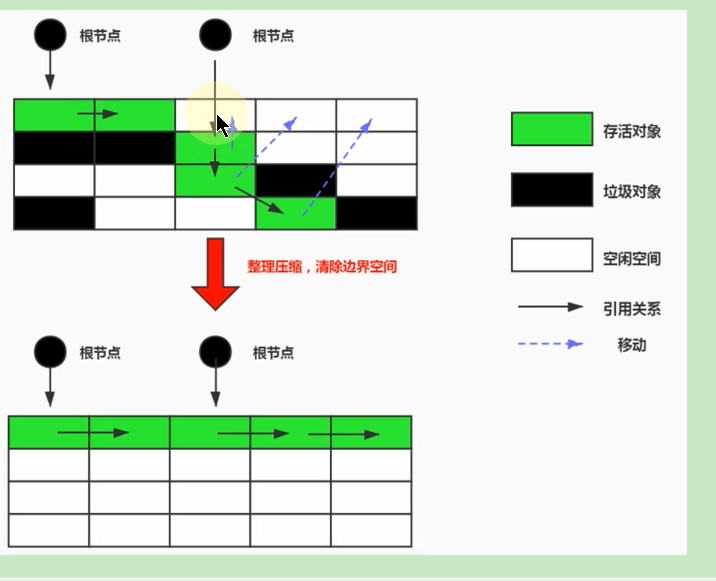
垃圾回收相关概念 什么是垃圾 垃圾就是指在运行程序中没有任何指针指向的对象,这个对象就是需要被回收掉的垃圾,如果不及时进行清理,越积越多就会导致内存溢出. 为什么需要GC 不进行回收,早晚会导致内存溢出,Java自动管理垃圾回收,不需要开发人员手动干预,这就有可能导致开…...
(学习日记)2023.04.27
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

亚马逊CPC广告每日该怎么调整?
01 CPC广告需要每日调整吗? 其实,亚马逊广告是不建议每天都做过多调整的。 为什么呢?调整太频繁了,看不到每天调整的结果是不是? 什么时候需要调整呢? 就是广告指标,比如说曝光、点击、转化率情…...
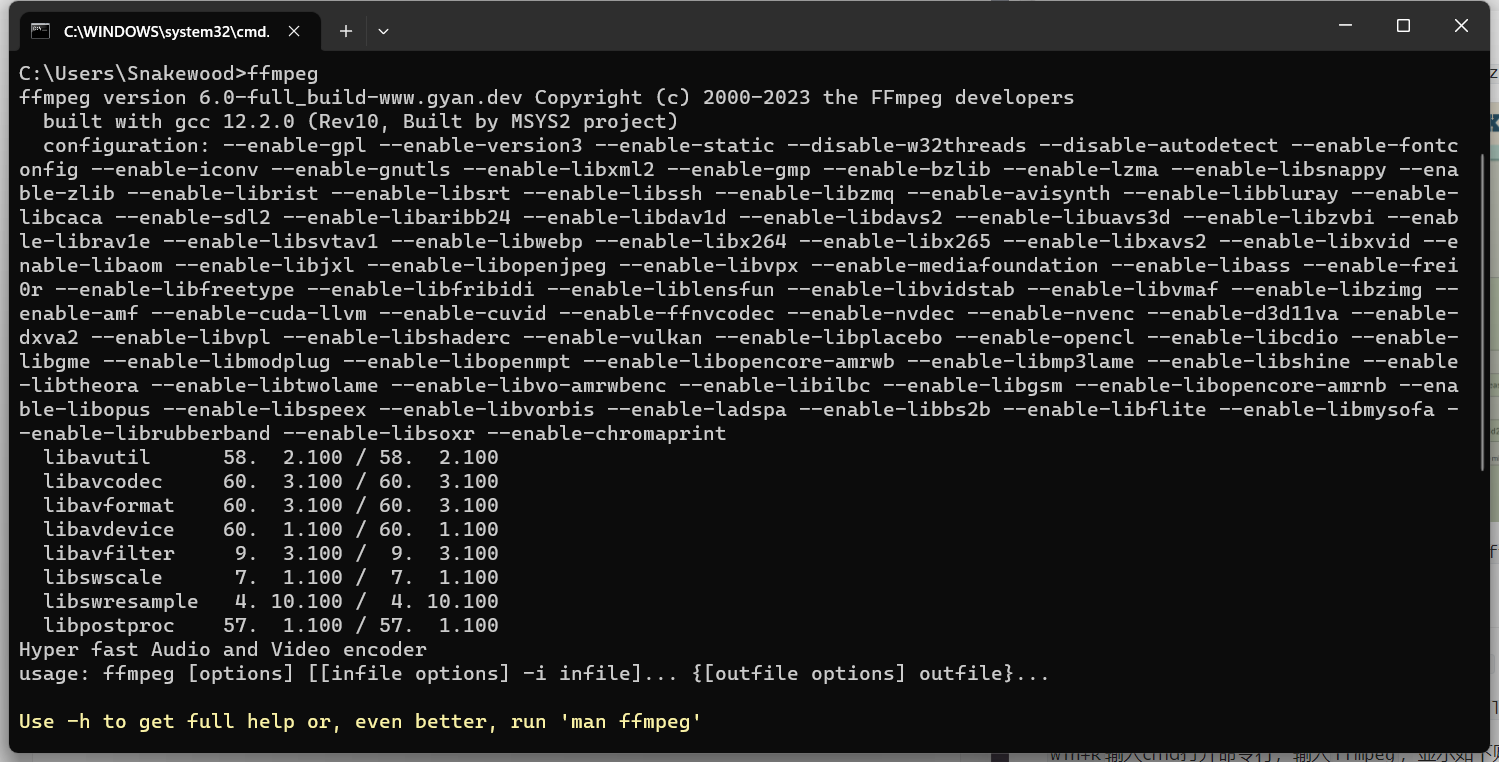
ffmpeg下载及ffmpy3安装使用
ffmpeg下载及ffmpy3安装使用 1.下载ffmpeg 进入网址:https://www.gyan.dev/ffmpeg/builds/ 在release builds中下载ffmpeg-release-full.7z 下载好后解压到自己想存放的目录,例如:D:\Tool\ffmpeg-6.0-full_build 2.配置环境变量 右键此电…...

设计模式之~原型模式
定义:用原型实例指导创建对象的种类,并且通过拷贝这些原型创建新的对象。原型模式其实就是从一个对象再创建另外一个可定制的对象,而且不需知道任何创建的细节。 优点: 一般在初始化的信息不发生变化的情况下,克隆是最…...

多传感器融合SLAM --- 8.LIO-SAM基础知识解读
目录 1 惯性测量单元简介及预积分 1.1 IMU 器件介绍及选型建议 1.2 IMU状态传递方程...

多模态大模型时代下的文档图像智能分析与处理
多模态大模型时代下的文档图像智能分析与处理 0. 前言1. 人工智能发展历程1.1 传统机器学习1.2 深度学习1.3 多模态大模型时代 2. CCIG 文档图像智能分析与处理论坛2.1 文档图像智能分析与处理的重要性和挑战2.2 文档图像智能分析与处理高峰论坛2.3 走进合合信息 3. 文档图像智…...
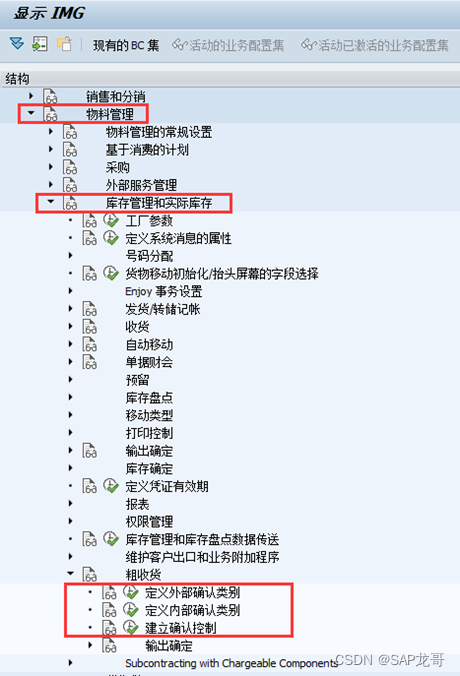
SAP-MM-内向外向交货单
1、内向&外向交货单概念 外向交货(outbound delivery)是用在客户与企业之间的交货单,而内向交货(inbound delivery)则是用在供应商与企业之间的交货单;换言之,外向交货多用于SD 模块&#…...

Mysql - date、datetime、timestamp 的区别
date、datetime 的区别 顾名思义,date 日期,datetime 日期时间,所以 date 是 datetime 的日期部分MySQL 以 格式检索和显示 datetime 值 YYYY-MM-DD hh:mm:ss datetime 支持的日期时间范围 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 d…...
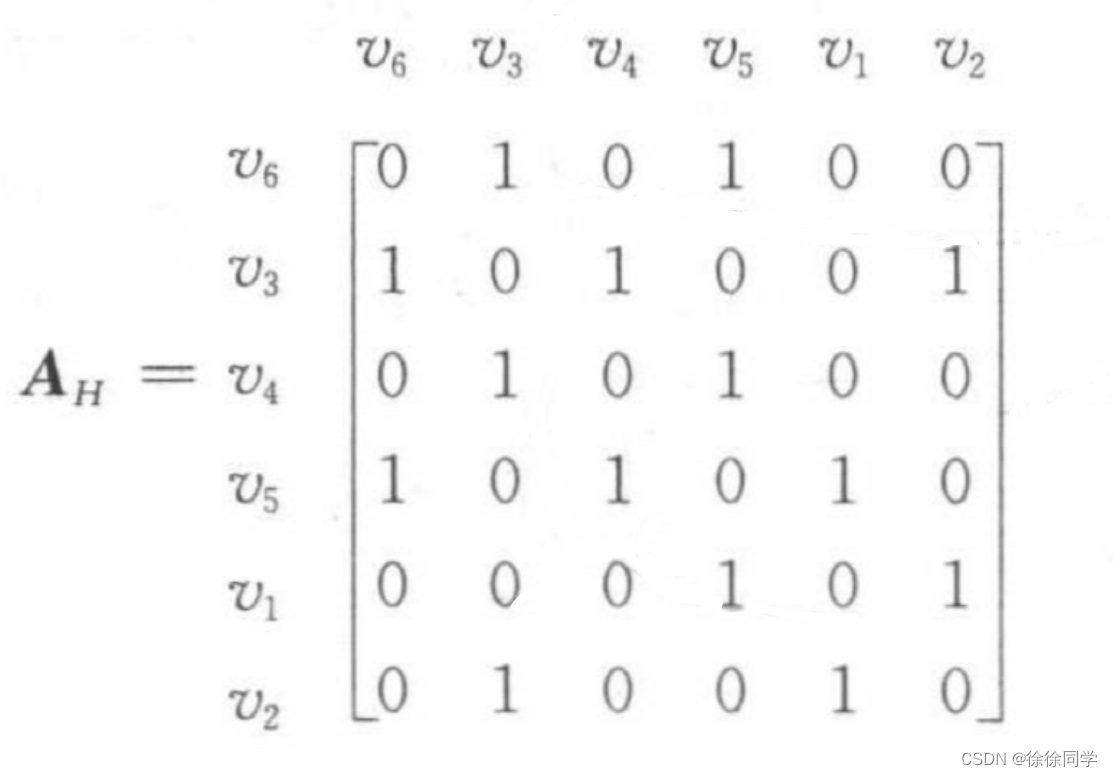
离散数学_十章-图 ( 4 ):图的表示和图的同构
📷10.4 图的表示和图的同构 1. 图的表示1.1 邻接表1.1.1 简单图的邻接表1.1.2 有向图的邻接表 1.2 邻接矩阵❗在邻接表和邻接矩阵之间取舍1.3 关联矩阵 2. 图同构3. ⚡判断两个简单图是否同构 图的表示方式有很多种,选择最方便的表示有助于对图的处理~ …...

MySQL锁的分类
MySQL锁的分类 全局锁 表级锁 ● 表锁 ● 元数据锁,Meta Data Lock,MDL锁 ● 意向锁 ● AUTO_INC 锁 行级锁(Innodb引擎牛比的地方) ● record lock,记录锁,也就是仅仅把一条记录给锁上了 ● gap lock,间隙锁ÿ…...

程序员如何给变量起名字
程序员如何给变量起名字 在编写代码时,为变量命名是非常重要的。良好的命名习惯可以提高代码的可读性和可维护性,使得其他开发者能够更容易地理解你的代码。在这篇文章中,我们将讨论程序员如何为变量选择合适的名称。 规范 首先࿰…...
)
隔板法(求解的组数)
文章目录 隔板法(求解的组数)隔板法扩展 例题 隔板法(求解的组数) 文章首发于我的个人博客:欢迎大佬们来逛逛 隔板法 隔板法能够解决的问题: 求线性不定方程的解的组数求相同元素分组的方案数 给我们 …...

智能文档处理黑科技,拥抱更高效的数字世界
目录 0 写在前面1 为何要关注智慧文档?2 图像弯曲矫正3 手写板反光擦除4 版面元素检测5 文档篡改检测总结 0 写在前面 近期,中国图象图形学学会文档图像分析与识别专业委员会与上海合合信息科技有限公司联合打造了《文档图像智能分析与处理》高峰论坛。…...

vue ts写法
Vue.js 和 TypeScript 结合使用可以让你的项目更加健壮和易于维护。在 Vue 3 中,你可以使用 Vue.js 的 Composition API 和 TypeScript 一起使用。以下是一个简单的 Vue.js 和 TypeScript 结合使用的例子: 首先,确保你已经安装了 Vue.js 和 T…...

Unity中的PostProcessBuild:深入解析与实用案例
Unity中的PostProcessBuild:深入解析与实用案例 在Unity游戏开发中,我们经常需要在构建完成后对生成的应用程序进行一些额外的处理。这时,我们可以使用Unity提供的PostProcessBuild功能。本文将详细介绍Unity中的PostProcessBuild方法&#…...

SimpleCG绘图函数(4)--绘制圆
在前一篇教程我们利用绘制矩形功能绘制了一个城市,接下来我们讲解另外一个同样重要且基础的图形----圆形。并一起看看该图形能绘制哪些应用呢。 绘制圆形相关函数如下: //圆心坐标(nXCenter,nYCenter),半径为nRatio//绘无填充制圆 void circle( int nXCenter, int …...

打包和优化
私人博客 许小墨のBlog —— 菜鸡博客直通车 系列文章完整版,配图更多,CSDN博文图片需要手动上传,因此文章配图较少,看不懂的可以去菜鸡博客参考一下配图! 系列文章目录 前端系列文章——传送门 后端系列文章——传送…...
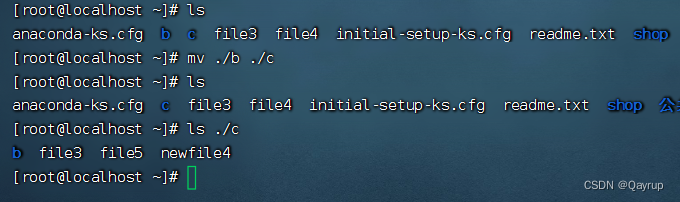
linuxOPS基础_Linux文件管理
Linux下文件命名规则 可以使用哪些字符? 理论上除了字符“/”之外,所有的字符都可以使用,但是要注意,在目录名或文件名中,不建议使用某些特殊字符,例如, <、>、?、* 等&…...

戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进
戴森球计划蓝图架构范式:从模块化设计到星际规模工程的技术演进 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 在戴森球计划的工厂建设中,蓝图设计…...

计算机图形学——四、光栅化与消隐
第四章 光栅转化与消隐 重点总结 一、光栅转化(Rasterization) 定义:把用数学描述的图形(如三角形)变成屏幕上一个个像素点。 1. 多边形扫描转换 顶点表示 → 点阵表示:把多边形的顶点坐标,转成…...

HTTPS抓包原理与Charles证书信任链实战指南
1. 为什么HTTPS抓包成了测试工程师绕不开的“硬门槛” 2024年我带的三批校招测试新人里,有17个人在第一次模拟面试中被问到“怎么抓APP的HTTPS请求”时当场卡壳。不是不会用Charles,而是根本没意识到—— HTTPS不是“开了代理就能抓”,证书…...

终极指南:如何用amdgpu_top实时监控AMD显卡性能
终极指南:如何用amdgpu_top实时监控AMD显卡性能 【免费下载链接】amdgpu_top Tool to display AMDGPU usage 项目地址: https://gitcode.com/gh_mirrors/am/amdgpu_top 还在为AMD显卡性能监控而烦恼吗?想要像NVIDIA用户使用nvidia-smi那样轻松掌握…...

ProperTree:重新定义Plist编辑的技术哲学与设计范式
ProperTree:重新定义Plist编辑的技术哲学与设计范式 【免费下载链接】ProperTree Cross platform GUI plist editor written in python. 项目地址: https://gitcode.com/gh_mirrors/pr/ProperTree 在macOS和iOS开发的世界里,Property List&#x…...

微服务限流实战:Nginx 漏桶与网关令牌桶
限流不是为了让系统“变慢”,而是为了让系统在突发流量、恶意请求或超过承载能力时,仍然能保住核心服务。 一句话概括:限流是在入口处控制请求速度或并发数量,Nginx 常用漏桶算法控制请求流出速率,Spring Cloud Gatewa…...

智能物流系统的技术难点
根据国际供应链与智能制造专家的普遍共识,智能物流系统(Smart Logistics System)作为“AI制造”的外延与闭环,其技术难点已不再是简单的“扫码搬运”,而是如何处理极高动态性、超大规模和强不确定性的复杂场景。核心技…...

利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型 构建智能客服或对话系统时,一个核心挑战是如何从众多大模型…...

长期在ubuntu开发中使用taotoken api感受到的稳定性与支持体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期在ubuntu开发中使用taotoken api感受到的稳定性与支持体验 作为一名在Ubuntu环境下进行日常开发的工程师,我的项目…...

Open WebUI企业级部署指南:全功能AI平台架构与生产环境实践
Open WebUI企业级部署指南:全功能AI平台架构与生产环境实践 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui Open WebUI是一个功能强大的自托管A…...