人工智能基础部分20-生成对抗网络(GAN)的实现应用
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分20-生成对抗网络(GAN)的实现应用。生成对抗网络是一种由深度学习模型构成的神经网络系统,由一个生成器和一个判别器相互博弈来提升模型的能力。本文将从以下几个方面进行阐述:生成对抗网络的概念、GAN的原理、GAN的实验设计。
一、前言
随着近年来人工智能发展的不断加速,尤其是深度学习的出现,使得计算机视觉领域取得了许多重要突破。生成对抗网络(Generative Adversarial Networks, GAN)是其中一种具有广泛应用前景的技术。GAN是一种生成式模型,它的主要原理是通过博弈论的方式,将生成模型与判别模型进行对抗训练,从而实现生成图像、音频等数据的任务。本文将对GAN 的工作原理进行详细解释,并通过一个图像生成示例项目,展示如何使用 PyTorch 框架实现 GAN,并给出实验结果与完整代码。
二、生成对抗网络(GAN)原理
GAN的核心思想是让两个网络(生成器和判别器)进行博弈,最终迭代得到一个高质量的生成器。生成器的任务是生成与真实数据分布相近的伪数据,而判别器的任务则是判断输入数据是来源于真实数据还是伪数据。通过优化生成器与判别器的博弈过程,使得生成器逐渐改进,能够生成越来越接近真实数据的伪数据。

2.1 生成器
生成器的主要作用是以随机噪声为输入,输出生成的伪数据。随机噪声是一个高斯分布的向量,我们可以通过一个深度神经网络模型(如卷积神经网络、前馈神经网络等)将这个高斯分布的向量映射成我们想要输出的伪数据。
2.2 判别器
判别器是一个二分类神经网络模型,输入可能来自生成器也可能来自真实数据。其任务是对输入数据进行分类,输出一个概率值以判断输入数据是来自真实数据集还是生成器生成的伪数据。
2.3 博弈过程
生成器与判别器博弈的过程即是各自的训练过程。生成器训练的目标是使得判别器对其生成的数据预测为真实数据的概率最大;判别器训练的目标是使得自身对真实数据与生成的数据的分类准确率最高。通过反复迭代这个过程,最终生成器能够生成越来越接近真实数据的伪数据。
2.4 数学原理
生成对抗网络(Generative Adversarial Networks,简称 GAN)是一种基于博弈论的生成模型,其数学原理可以用以下公式表示:
假设表示真实数据的分布,
表示生成器输入随机噪声
的分布,
表示生成器的输出,其中
是生成器的参数,
表示判别器的输出,其中
是判别器的参数。
GAN 的目标是最小化以下损失函数:
其中 表示期望值,
表示自然对数。
这个损失函数的含义是:最小化生成器生成的数据与真实数据之间的差距,同时最大化判别器对生成器生成的数据和真实数据的区分度。具体来说,第一项表示真实数据被判别为真实数据的概率,第二项
表示生成器生成的虚构数据被判别为虚构数据的概率。
在训练过程中,GAN 会交替训练生成器和判别器,通过最小化损失函数 来优化模型参数。具体来说,对于每个训练迭代,我们首先固定生成器的参数,通过最大化损失函数
来优化判别器的参数。然后,我们固定判别器的参数,通过最小化损失函数
来优化生成器的参数。这个过程会一直迭代下去,直到达到预定的迭代次数或者损失函数收敛。
三、实验设计
本文使用 tensorflow 框架实现 GAN,并在图像生成任务上进行训练。实验workflow 分为以下五个步骤:数据准备\构建生成器与判别器\设置损失函数与优化器、训练过程,让我们先从数据准备开始。
四、代码实现
下面我们将使用MNIST(手写数字化)这一经典的数据集来展示GANs的实际应用效果。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers# 设置随机种子以获得可重现的结果
np.random.seed(42)
tf.random.set_seed(42)# 加载MNIST数据集
(x_train, y_train), (_, _) = keras.datasets.mnist.load_data()# 将数据规范化到[-1, 1]范围内
x_train = x_train.astype(np.float32) / 127.5 - 1# 将数据集重塑为(-1, 28, 28, 1)
x_train = np.expand_dims(x_train, axis=-1)# 创建生成器模型
def create_generator():generator = keras.Sequential()generator.add(layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(100,)))generator.add(layers.BatchNormalization())generator.add(layers.LeakyReLU(alpha=0.2))generator.add(layers.Reshape((7, 7, 256)))generator.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias = False))generator.add(layers.BatchNormalization())generator.add(layers.LeakyReLU(alpha=0.2))generator.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias = False))generator.add(layers.BatchNormalization())generator.add(layers.LeakyReLU(alpha=0.2))generator.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias = False, activation ='tanh'))return generatorgenerator = create_generator()# 创建鉴别器模型
def create_discriminator():discriminator = keras.Sequential()discriminator.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape = (28, 28, 1)))discriminator.add(layers.LeakyReLU(alpha=0.2))discriminator.add(layers.BatchNormalization())discriminator.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))discriminator.add(layers.LeakyReLU(alpha=0.2))discriminator.add(layers.BatchNormalization())discriminator.add(layers.Flatten())discriminator.add(layers.Dropout(0.2))discriminator.add(layers.Dense(1, activation='sigmoid'))return discriminatordiscriminator = create_discriminator()# 编译鉴别器
discriminator_optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
discriminator.compile(optimizer=discriminator_optimizer, loss='binary_crossentropy', metrics = ['accuracy'])# 创建和编译整体GAN结构
discriminator.trainable = False
gan_input = keras.Input(shape=(100,))
gan_output = discriminator(generator(gan_input))
gan = keras.Model(gan_input, gan_output)gan_optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
gan.compile(optimizer=gan_optimizer, loss='binary_crossentropy')# 模型训练函数
def train_gan(epochs=100, batch_size=128):num_examples = x_train.shape[0]num_batches = num_examples // batch_sizefor epoch in range(epochs):for batch_idx in range(num_batches):noise = np.random.normal(size=(batch_size, 100))generated_images = generator.predict(noise)real_images = x_train[(batch_idx * batch_size):((batch_idx + 1) * batch_size)]all_images = np.concatenate([generated_images, real_images])labels = np.zeros(2 * batch_size)labels[batch_size:] = 1# 在噪声上加一点随机数,提高生成器的鲁棒性labels += 0.05 * np.random.rand(2 * batch_size)discriminator_loss = discriminator.train_on_batch(all_images, labels)noise = np.random.randn(batch_size, 100)misleading_targets = np.ones(batch_size)generator_loss = gan.train_on_batch(noise, misleading_targets)if (batch_idx + 1) % 50 == 0:print(f"Epoch:{epoch + 1}/{epochs} Batch:{batch_idx + 1}/{num_batches} Discriminator Loss: {discriminator_loss[0]} Generator Loss:{generator_loss}")train_gan()以上实现了生成对抗网络是训练过程,实际中我们可以替换数据训练自己的数据模型。
相关文章:
人工智能基础部分20-生成对抗网络(GAN)的实现应用
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分20-生成对抗网络(GAN)的实现应用。生成对抗网络是一种由深度学习模型构成的神经网络系统,由一个生成器和一个判别器相互博弈来提升模型的能力。本文将从以下几个方面进行阐述࿱…...
)
JavaScript表单事件(上篇)
目录 一、input: 当表单元素的值发生改变时触发,适用于大多数表单元素。 二、change: 当表单元素的值发生改变且失去焦点时触发,适用于输入框、下拉列表等。 三、submit: 当表单提交时触发,适用于 form 元素。 四、reset: 当表单重置时触…...
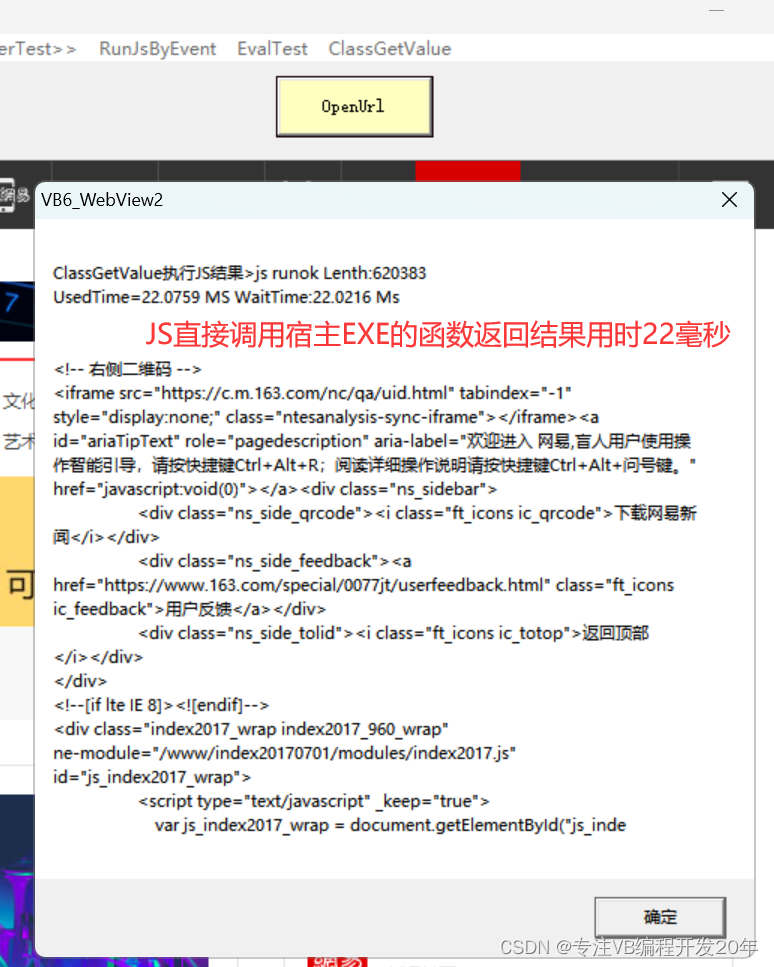
vb6 Webview2微软Edge Chromium内核执行JS取网页数据测速
微软Edge Chromium内核执行JS获取网页数据测试 ExcuteScript eval(document.body.innerHTML) from : https://www.163.com 采集的网页HTM字符串占用字节空间1.2MB ExcuteScript回调事件中取得JS执行结果,用时 54 毫秒 其中JSON转字符13.5209毫秒 jSON数据长度: 增…...

编码,Part 1:ASCII、汉字及 Unicode 标准
个人博客 编码的历史由来就懒得介绍了,只需要知道人类处理文本信息是以字符为基本单位,而计算机在最底层只认识 0/1,所以当计算机要为人类存储/呈现字符时,就需要有一个规则,在字符和 0/1 序列之间建立映射关系&#…...

C++ Eigen库矩阵操作
C Eigen库 序号功能例子1赋值Eigen::MatrixXf mat (12,1); \\% mat << 1, 2, 3, 4,5,6,7,8,9,10,11,12;2Inplace操作 \\% resizemat.resize(4, 3); \\% 1 5 9 \\% 2 6 10 \\% 3 7 11 \\% 4 8 123转置 \\% transposeInPlacemat.transposeInPlace(); \\% 1 2 3 4 \\% 5…...

Linux-0.11 boot目录bootsect.s详解
Linux-0.11 boot目录bootsect.s详解 模块简介 bootsect.s是磁盘启动的引导程序,其概括起来就是代码的搬运工,将代码搬到合适的位置。下图是对搬运过程的概括,可以有个印象,后面将详细讲解。 bootsect.s主要做了如下的三件事: 搬…...

django组件552
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...

【枚举算法的Java实现及其应用】
文章目录 枚举算法概述枚举算法的实现步骤Java实现枚举算法枚举算法的底层工作原理枚举算法的底层代码讲解枚举算法的实际应用场景枚举算法在场景中解决的问题总结 枚举算法概述 枚举算法是一种通过列举所有可能情况来解决问题的方法。这种算法在解决一些特定类型的问题时非常…...

linux led 驱动
前言 今天是儿童节,挣个奖牌给小孩玩玩。 在 linux 驱动大家庭中,LED 驱动算是个儿童,今天就写写他吧。正好之前写过他的婴儿时期《i.MX6ULL 裸机点亮 LED》,记得那时候他还穿着开裆裤呢,裸鸡嘛。 ioremap() 裸机程…...
)
平面最近点对(分治算法)
文章目录 平面最近点对(分治算法)Solution流程完整模板代码 平面最近点对(分治算法) 文章首发于我的个人博客:欢迎大佬们来逛逛 平面最近点对(加强版) - 洛谷 给你一些点,求两点之…...

【基于前后端分离的博客系统】Servlet版本
🎉🎉🎉点进来你就是我的人了博主主页:🙈🙈🙈戳一戳,欢迎大佬指点! 欢迎志同道合的朋友一起加油喔🤺🤺🤺 目录 一. 项目简介 1. 项目背景 2. 项目用到的技…...

在线Excel绝配:SpreadJS 16.1.1+GcExcel 6.1.1 Crack
前端:SpreadJS 16.1.1 后端: GcExcel 6.1.1 全能 SpreadJS 16.1.1此版本的产品中包含以下功能和增强功能。 添加了各种输入掩码样式选项。 添加了在保护工作表时设置密码以及在取消保护时验证密码的支持。 增强了组合图以将其显示为仪表图。 添加了…...

一个轻量的登录鉴权工具Sa-Token 集成SpringBoot简要步骤
Sa-Token 集成SpringBoot简要步骤 1.1 简单介绍 Sa-Token是一个轻量级Java权限认证框架。 主要解决的问题如下: 登录认证 权限认证 单点登录 OAuth2.0 分布式Session会话 微服务网关鉴权等一系列权限相关问题。 1.2 登录认证 设计思路 对于一些登录之后…...
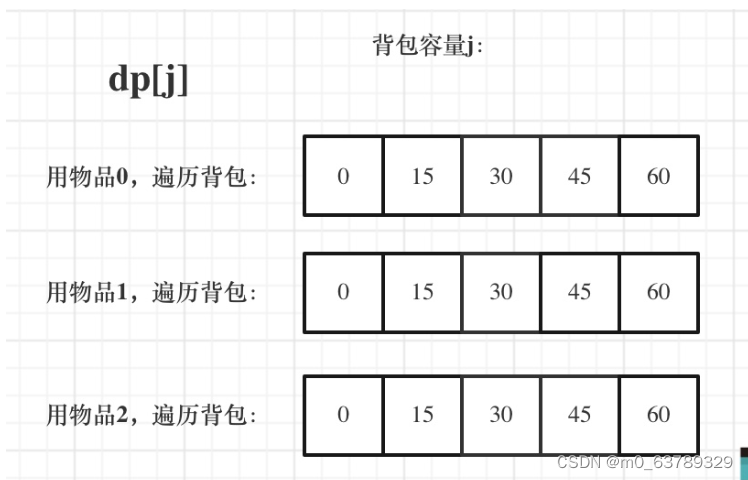
day 44 完全背包:518. 零钱兑换 II;377. 组合总和 Ⅳ
完全背包:物品可以使用多次 完全背包1. 与01背包区别 518. 零钱兑换 II1. dp数组以及下标名义2. 递归公式3. dp数组如何初始化4. 遍历顺序:不能颠倒两个for循环顺序5. 代码 377. 组合总和 Ⅳ:与零钱兑换类似,但是是求组合数1. dp数组以及下标名义2. 递归…...
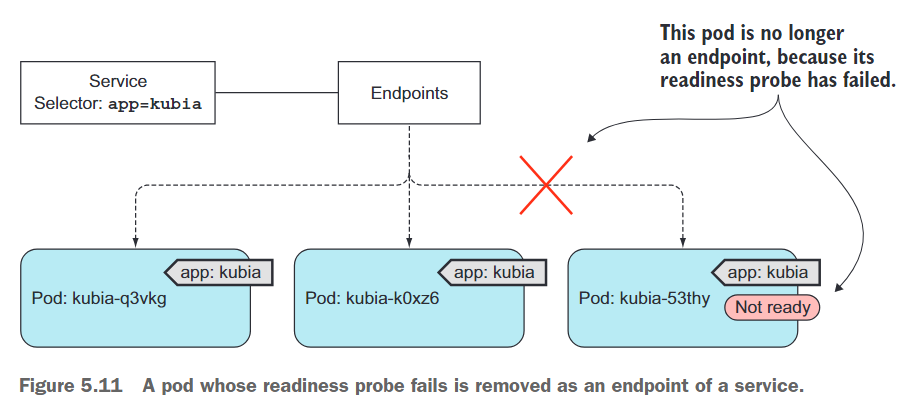
K8s in Action 阅读笔记——【5】Services: enabling clients to discover and talk to pods
K8s in Action 阅读笔记——【5】Services: enabling clients to discover and talk to pods 你已了解Pod以及如何通过ReplicaSets等资源部署它们以确保持续运行。虽然某些Pod可以独立完成工作,但现今许多应用程序需要响应外部请求。例如,在微服务的情况…...

牛客网DAY2(编程题)
圣诞节来啦!请用CSS给你的朋友们制作一颗圣诞树吧~这颗圣诞树描述起来是这样的: 1. "topbranch"是圣诞树的上枝叶,该上枝叶仅通过边框属性、左浮动、左外边距即可实现。边框的属性依次是:宽度为100px、是直线、颜色为gr…...
Java经典笔试题—day14
Java经典笔试题—day14 🔎选择题🔎编程题🍭计算日期到天数转换🍭幸运的袋子 🔎结尾 🔎选择题 (1)定义学生、教师和课程的关系模式 S (S#,Sn,Sd,Dc,SA )(其属性分别为学号、姓名、所…...

一个帮助写autoprefixer配置的网站
前端需要用到postcss的工具,用到一个插件叫autoprefixer,这个插件能够给css属性加上前缀,进行一些兼容的工作。 如何安装之类的问题在csdn上搜一下都能找到(注意,vite是包含postcss的,不用在项目中安装pos…...
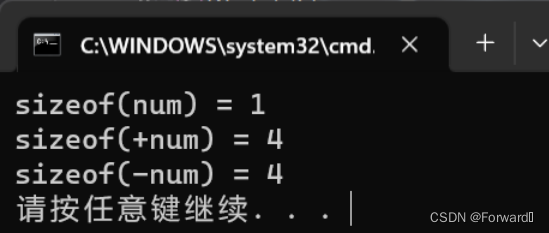
C语言中的类型转换
C语言中的类型转换 隐式类型转换 整型提升 概念: C语言的整型算术运算总是至少以缺省(默认)整型类型的精度来进行的为了获得这个精度,表达式中字符和短整型操作数在使用之前被转换为普通整型,这种转换成为整型提升 如…...
)
String底层详解(包括字符串常量池)
String a “abc”; ,说一下这个过程会创建什么,放在哪里? JVM会使用常量池来管理字符串直接量。在执行这句话时,JVM会先检查常量池中是否已经存有"abc",若没有则将"abc"存入常量池,否…...

在Python项目中集成多模型API如何利用Taotoken实现统一调用与管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中集成多模型API如何利用Taotoken实现统一调用与管理 1. 多模型接入的常见工程挑战 在开发基于大语言模型的Python应…...

Hermes Agent 自定义供应商配置指向 Taotoken 的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 自定义供应商配置指向 Taotoken 的步骤 对于使用 Hermes Agent 进行 AI 应用开发的团队而言,统一管理模型…...
)
FANUC机器人摆焊+电弧跟踪实战:从参数详解到避坑指南(ROBOGUIDE仿真)
FANUC机器人摆焊与电弧跟踪协同优化实战解析 在厚板焊接与复杂轨迹加工领域,正弦摆焊与电弧跟踪技术的协同应用已成为提升焊接质量的关键手段。资深工程师们常常面临这样的挑战:如何在坡口焊接中精准配置那二十余项电弧传感器参数,使机器人既…...

TV Bro电视浏览器:终极Android电视网页浏览解决方案,让大屏上网变得简单高效
TV Bro电视浏览器:终极Android电视网页浏览解决方案,让大屏上网变得简单高效 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾尝试在智能…...

2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解
2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解 智能侦查赛道概述 2025 睿抗机器人大赛智能侦察赛道是 CAIR 工程竞技赛道下的专业国防装备赛项,以无人侦察车为载体、模拟巷战环境开展军事侦察任务,核心培养学生国防意识与科技创新能力且核心硬件…...

如何在Mac上安全导出微信聊天记录:开源工具WeChatExporter终极指南
如何在Mac上安全导出微信聊天记录:开源工具WeChatExporter终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机丢失而担心珍贵的微信聊天记…...

保姆级教程:5分钟快速搭建你的DNC服务器,实现Fanuc/西门子数控程序远程传输与管理
数控机床程序远程管理实战:5分钟构建企业级DNC服务 在金属加工车间里,老师傅们弯腰在机床控制面板上手动输入程序的场景正逐渐成为历史。当车间里同时运行着发那科、西门子和三菱等不同品牌的数控设备时,如何高效管理这些设备的加工程序&…...
)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设) 录制完一段音频后,你是否经常遇到这样的困扰:人声听起来闷闷的像隔了层棉被,或是尖锐刺耳到让人皱眉,又或者整体浑浊不清缺乏层次感&…...

电子供应链服务转型:从元器件分销到技术赋能与韧性构建
1. 项目概述:从“卖货”到“赋能”的供应链服务转型在电子元器件分销这个看似传统的行业里,我从业十几年,亲眼见证了从“电话传真报价”到“线上实时库存”的变迁。最近和一位行业老友,也是某知名分销商的资深销售总监聊天&#x…...

CaldroidListener使用教程:轻松实现Android日期点击事件处理
CaldroidListener使用教程:轻松实现Android日期点击事件处理 【免费下载链接】Caldroid A better calendar for Android 项目地址: https://gitcode.com/gh_mirrors/ca/Caldroid Caldroid是一款功能强大的Android日历组件,而CaldroidListener则是…...