大数据教程【01.01】--大数据介绍及开发环境
更多信息请关注WX搜索GZH:XiaoBaiGPT
大数据简介
大数据(Big Data)是指规模庞大、结构复杂、增长速度快且难以使用传统技术处理的数据集合。大数据分析可以帮助企业和组织从海量的数据中提取有价值的信息,用于业务决策、市场分析、预测等方面。
大数据具有以下特点:
-
Volume(大量):大数据以海量数据为基础,通常超出传统数据库的处理能力。 -
Velocity(高速):大数据的生成速度非常快,需要实时或准实时处理。 -
Variety(多样):大数据涵盖多种数据类型,如结构化数据(关系型数据库中的表格数据)、半结构化数据(XML、JSON)和非结构化数据(文本、图像、视频等)。 -
Veracity(真实性):大数据具有不确定性和不准确性,包含错误和噪声。 -
Value(价值):大数据分析可以从庞大的数据集中提取有价值的信息,促进业务发展和创新。
大数据开发环境
大数据开发环境通常包括以下组件和工具:
-
Hadoop:Hadoop是一个用于分布式存储和处理大数据的开源框架。它包括Hadoop分布式文件系统(HDFS)用于数据存储和Hadoop MapReduce用于数据处理。
-
Spark:Spark是一个快速通用的大数据处理引擎,它提供了高级API(如Spark SQL、Spark Streaming、MLlib和GraphX)和用于构建大规模数据处理应用程序的分布式计算模型。
-
Python:Python是一种流行的编程语言,在大数据开发中被广泛使用。Python具有丰富的数据分析库(如Pandas、NumPy和SciPy)和可视化库(如Matplotlib和Seaborn),方便进行数据处理和分析。
-
Jupyter Notebook:Jupyter Notebook是一个开源的Web应用程序,用于创建和共享可编辑的文档,其中可以包含实时代码、方程式、可视化和说明文本。它是大数据开发中常用的交互式开发环境。
-
PySpark:PySpark是Spark的Python API,可以使用Python编写Spark应用程序。PySpark提供了与Spark相同的功能和性能,同时具备Python语言的简洁性和易用性。
示例:使用Python进行大数据分析
接下来,我们将使用Python和PySpark来展示一个简单的大数据分析示例。假设我们有一个大型的销售交易数据集,包含产品名称、销售日期和销售额等信息。我们的目标是计算每个产品的总销售额。
步骤 1:安装PySpark
首先,我们需要安装PySpark库。在命令行中执行以下命令:
pip install pyspark
步骤 2:启动Jupyter Notebook
在命令行中执行以下命令来启动Jupyter Notebook:
jupyter notebook
然后,浏览器将自动打开Jupyter Notebook的界面。
步骤 3:创建一个新的Jupyter Notebook
在Jupyter Notebook界面中,点击右上角的「New」按钮,选择「Python 3」以创建一个新的Python Notebook。
步骤 4:导入必要的库
在新建的Jupyter Notebook中,首先导入PySpark库和其他必要的库:
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum
# 创建SparkSession
spark = SparkSession.builder.appName("BigDataAnalysis").getOrCreate()
步骤 5:加载数据集
接下来,我们将加载销售交易数据集。假设数据集保存为CSV文件,其中每一行包含产品名称、销售日期和销售额,以逗号分隔。
# 加载CSV文件并创建DataFrame
data = spark.read.csv("sales_data.csv", header=True, inferSchema=True)
步骤 6:数据处理和分析
现在,我们可以对数据进行处理和分析了。在本例中,我们将按产品名称进行分组,并计算每个产品的总销售额。
# 按产品名称分组,并计算每个产品的总销售额
sales_by_product = data.groupBy("product_name").agg(sum("sales_amount").alias("total_sales"))
# 显示结果
sales_by_product.show()
以上代码将计算每个产品的总销售额,并显示结果。
步骤 7:保存结果
如果需要,我们可以将结果保存到文件中,以便进一步分析或共享。
# 将结果保存为CSV文件
sales_by_product.write.csv("sales_by_product.csv", header=True)
以上代码将结果保存为CSV文件。
结论
通过使用Python和PySpark,我们可以方便地进行大数据分析。上述示例仅为一个简单的演示,实际的大数据分析可能涉及更复杂的数据处理和算法。然而,这个示例提供了一个入门点,帮助您开始使用Python进行大数据分析。你可以根据自己的需求和数据集进行进一步的扩展和定制。
本文由 mdnice 多平台发布
相关文章:

大数据教程【01.01】--大数据介绍及开发环境
更多信息请关注WX搜索GZH:XiaoBaiGPT 大数据简介 大数据(Big Data)是指规模庞大、结构复杂、增长速度快且难以使用传统技术处理的数据集合。大数据分析可以帮助企业和组织从海量的数据中提取有价值的信息,用于业务决策、市场分析、…...

文件阅览功能的实现(适用于word、pdf、Excel、ppt、png...)
需求描述: 需要一个组件,同时能预览多种类型文件,一种类型文件可有多个的文件。 看过各种博主的方案,其中最简单的是利用第三方地址进行预览解析(无需任何插件); 这里推荐三个地址:…...

面试-RabbitMQ常见面试问题
1.什么是RabbitMQ? RabbitMQ是一款基于AMQP协议的消息中间件,消费方并不需要确保提供方的存在,实现服务之间的高度解耦。 基本组成有: Queue:消息队列,存储消息,消息送达队列后转发给指定的消费方Exchange:消息队列交…...

使用VBA在单元格中快速插入Unicode符号
Unicode 符号 Unicode 符号在实际工作中有着广泛的应用,比如用于制作邮件签名、文章排版、演示文稿制作等等。在 Excel 表格中,插入符号可以让表格的排版更加美观,同时也能够帮助用户更清晰地表达意思。 Dingbats Dingbats是一个包含装饰符…...

PyTorch 深度学习 || 专题六:PyTorch 数据的准备
PyTorch 数据的准备 1. 生成数据的准备工作 import torch import torch.utils.data as Data#准备建模数据 x torch.unsqueeze(torch.linspace(-1, 1, 500), dim1) # 生成列向量 y x.pow(3) # yx^3#设置超参数 batch_size 15 # 分块大小 torch.manual_seed(10) # 设置种子点…...

迅为RK3568开发板2800页手册+220集视频
iTOP-3568开发板采用瑞芯微RK3568处理器,内部集成了四核64位Cortex-A55处理器。主频高达2.0Ghz,RK809动态调频。集成了双核心架构GPU,ARM G52 2EE、支持OpenGLES1.1/2.0/3.2OpenCL2.0、Vulkan 1.1、内高性能2D加速硬件。 内置NPU 内置独立NP…...

模拟电子 | 稳压管及其应用
模拟电子 | 稳压管及其应用 稳压二极管工作在反向击穿状态时,其两端的电压是基本不变的。利用这一性质,在电路里常用于构成稳压电路。 稳压二极管构成的稳压电路,虽然稳定度不很高,输出电流也较小,但却具有简单、经济实…...

使用大型语言模(LLM)构建系统(二):内容审核、预防Prompt注入
今天我学习了DeepLearning.AI的 Building Systems with LLM 的在线课程,我想和大家一起分享一下该门课程的一些主要内容。 下面是我们访问大型语言模(LLM)的主要代码: import openai#您的openai的api key openai.api_key YOUR-OPENAI-API-KEY def get_…...

springboot---mybatis操作事务配置的处理
目录 前言: 事务的相关问题 1、什么是事务? 2、事务的特点(ACID) 3、什么时候想到使用事务? 4、通常使用JDBC访问数据库,还是mybatis访问数据库,怎么处理事务? 5、问题中事务处…...

游戏盾是什么防御DDOS攻击的
游戏盾是一种专门用于防御分布式拒绝服务(DDoS)攻击的安全工具。DDoS攻击是指攻击者利用大量的计算机或设备同时向目标服务器发送海量的请求,以使目标服务器超负荷运行,无法正常提供服务。游戏盾通过一系列智能的防护措施…...

java快速结束嵌套循环
java快速结束嵌套循环 快速结束for循环 out:for (int i 0; i < 5; i) {in:for (int j 0; j < 5; j) {if (j 2) {break out;}System.out.println("i " i " j " j);}}解释 将外层for循环起别名 o u t \color{red}{out} out,将内层for循环起别名…...

chatgpt赋能python:Python屏蔽一段代码
Python屏蔽一段代码 在Python编程中,有时我们需要屏蔽一段代码以便于调试或者测试。在很多情况下,我们可能不想删除这段代码,因为需要在将来的某个时间再次使用它。为了解决这个问题,我们可以使用Python中的注释语句或者条件语句…...
项目跑不起来
Sa-Token/sa-token-core/src/main/java/cn/dev33/satoken/temp/SaTempUtil.java:10:8 java: 写入cn.dev33.satoken.temp.SaTempUtil时出错: Output directory is not specified 写入cn.dev33.satoken.temp.SaTempUtil时出错: Output directory is not specified 答案…...
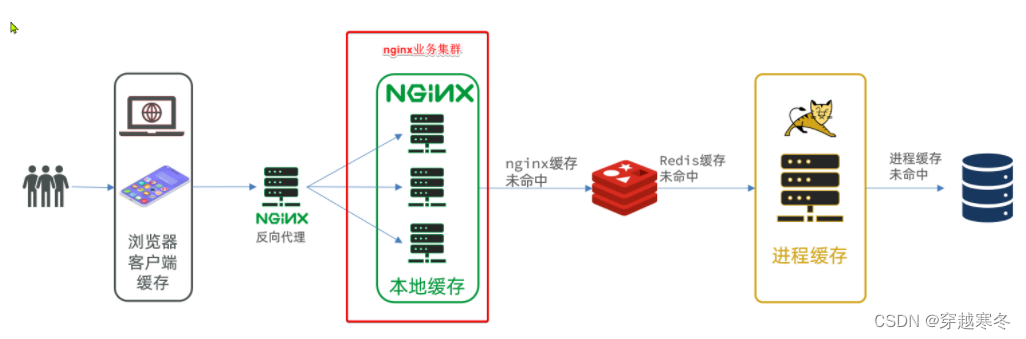
黑马Redis视频教程高级篇(多级缓存案例导入说明)
目录 一、安装MYSQL 1.1、准备目录 1.2、运行命令 1.3、修改配置 1.4、重启 二、导入SQL 三、导入Demo工程 3.1、分页查询商品 3.2、新增商品 3.3、修改商品 3.4、修改库存 3.5、删除商品 3.6、根据id查询商品 3.7、根据id查询库存 3.8、启动 四、导入商品查询…...

2023系统分析师下午案例分析真题
真题1 阅读以下关于软件系统分析与建模的叙述,在纸上回答问题1至3. 说明: 某软件公司拟开发一套汽车租赁系统,科学安全和方便的管理租赁公司的各项业务,提高公司效率,提升利率。注册用户在使用系统镜像车辆预约时需执行以下操作…...

【Python练习】Matplotlib数据可视化
文章目录 一、实验目标二、实验内容1. 用画布的各种设置,绘制类似如图1所示的:y1=sin(x)和y2=cos(x)的曲线图2. 某校高一3班12名同学语数外三科成绩分布情况如表5-2所示,数据值也可以自拟,适当调整。绘制折线图、纵向条形图分析这些同学单科成绩情况,绘制纵向堆叠条形图查…...
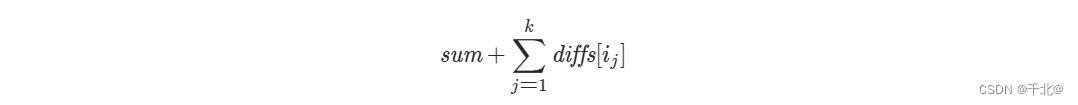
【2611. 老鼠和奶酪】
来源:力扣(LeetCode) 描述: 有两只老鼠和 n 块不同类型的奶酪,每块奶酪都只能被其中一只老鼠吃掉。 下标为 i 处的奶酪被吃掉的得分为: 如果第一只老鼠吃掉,则得分为 reward1[i] 。如果第二…...

Reid strong baseline 代码详解
本项目是对Reid strong baseline代码的详解。项目暂未加入目标检测部分,后期会不定时更新,请持续关注。 本相比Reid所用数据集为Markt1501,支持Resnet系列作为训练的baseline网络。训练采用表征学习度量学习的方式。 目录 训练参数 训练代…...
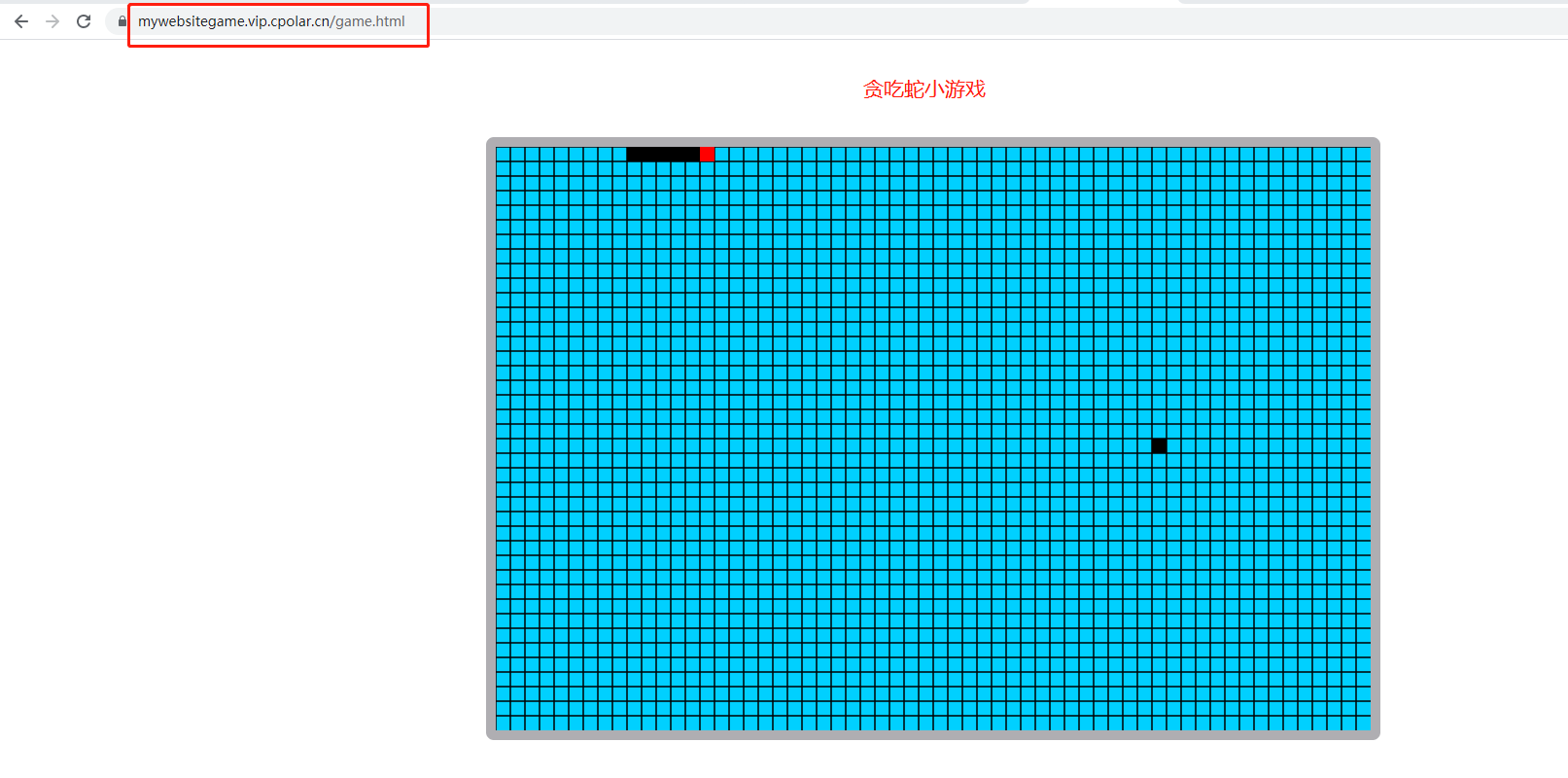
宝塔面板搭建网站教程:Linux下使用宝塔一键搭建网站,内网穿透发布公网上线
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 转载自cpolar内网穿透的文章:使用宝塔面板快速搭建网站,并内网穿透实现公网远程访问 前言 宝塔面板作为简单好用的服务器运维管理面板&…...

常微分方程(ODE)求解方法总结
常微分(ODE)方程求解方法总结 1 常微分方程(ODE)介绍1.1 微分方程介绍和分类1.2 常微分方程的非计算机求解方法1.3 线性微分方程求解的推导过程 2 一阶常微分方程(ODE)求解方法2.1 欧拉方法2.1.1 欧拉方法2…...

C语言数字炸弹游戏:如何优化随机数生成与用户交互体验
C语言数字炸弹游戏:如何优化随机数生成与用户交互体验 数字炸弹游戏是许多C语言初学者接触的第一个完整项目,它简单有趣却蕴含着程序设计的关键要素。本文将深入探讨如何通过优化随机数生成算法和提升用户交互体验,让这个经典小游戏焕发新生。…...

s2-pro镜像管理:容器健康检查脚本编写与自动化服务恢复方案
s2-pro镜像管理:容器健康检查脚本编写与自动化服务恢复方案 1. 引言 s2-pro作为专业级语音合成模型镜像,在实际业务场景中承担着重要角色。当服务出现异常时,如何快速发现问题并自动恢复成为运维工作的关键。本文将详细介绍如何为s2-pro编写…...

大模型小白程序员必看:收藏这份AI智能体学习路径与构建思路
大模型小白程序员必看:收藏这份AI智能体学习路径与构建思路 本文系统梳理AI智能体的概念、发展脉络与核心架构,清晰拆解其与传统工作流的本质差异,聚焦智能体三大核心组件(规划能力、记忆系统、工具使用机制)的技术细节…...

别再死记硬背BPSK公式了!用Python+NumPy手把手带你仿真2PSK信号生成与解调全过程
用Python实战BPSK:从信号生成到误码率分析的完整指南 通信工程专业的学生常常被各种调制公式搞得晕头转向,尤其是BPSK(二进制相移键控)这类基础但抽象的概念。今天,我们将彻底改变这种学习方式——通过Python代码和可视…...

放弃OpenVINO!在树莓派5上用Anaconda环境直接跑通YOLOv5摄像头检测
放弃OpenVINO!在树莓派5上用Anaconda环境直接跑通YOLOv5摄像头检测 树莓派作为嵌入式开发的明星产品,其第五代在性能上有了显著提升,4GB内存和2.4GHz四核处理器让它能够胜任更多AI推理任务。而YOLOv5作为目标检测领域的轻量级标杆,…...

FLUX.1-dev实战教程:像素幻梦中多LoRA叠加与风格混合生成技巧
FLUX.1-dev实战教程:像素幻梦中多LoRA叠加与风格混合生成技巧 1. 像素幻梦工坊简介 Pixel Dream Workshop(像素幻梦工坊)是基于FLUX.1-dev扩散模型构建的专业像素艺术生成工具。与传统AI绘图工具不同,它专为像素艺术创作优化&am…...

技术驱动B端拓客升级:号码核验行业的痛点突围与发展新路径,氪迹科技核验筛选算法系统,法人股东核验,阶梯式价格
在B端市场竞争愈发精细化的当下,拓客工作的核心竞争力已从“广撒网”转向“精准触达”,而企业核心决策人的有效联系方式,正是精准拓客的关键载体。号码核验作为拓客流程的前置核心环节,直接决定着拓客投入的回报效率,更…...

XML Notepad:免费高效的XML编辑器终极指南
XML Notepad:免费高效的XML编辑器终极指南 【免费下载链接】XmlNotepad XML Notepad provides a simple intuitive User Interface for browsing and editing XML documents. 项目地址: https://gitcode.com/gh_mirrors/xm/XmlNotepad XML Notepad是一款由微…...

如何快速搭建专业级游戏串流系统:Sunshine完整教程
如何快速搭建专业级游戏串流系统:Sunshine完整教程 【免费下载链接】Sunshine Sunshine: Sunshine是一个自托管的游戏流媒体服务器,支持通过Moonlight在各种设备上进行低延迟的游戏串流。 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine …...

ES920 Arduino库深度解析:Sub-1GHz工业无线通信实战指南
1. ES920无线模块Arduino库深度解析:面向工业级Sub-1GHz通信的工程实践指南ES920系列是日本Echostar公司推出的高性能Sub-1GHz无线通信模块,涵盖FSK调制的ES920与LoRa调制的ES920LR两个子型号。该系列模块专为日本920MHz ISM频段(920.6–928.…...