【机器学习】机器故障的二元分类模型-Kaggle竞赛
竞赛介绍
数据集描述
本次竞赛的数据集(训练和测试)是从根据机器故障预测训练的深度学习模型生成的。特征分布与原始分布接近,但不完全相同。随意使用原始数据集作为本次竞赛的一部分,既可以探索差异,也可以了解在训练中合并原始数据集是否可以提高模型性能。
文件
训练.csv - 训练数据集; 是(二进制)目标(为了与原始数据集的顺序保持一致,它不在最后一列位置)Machine failure
测试.csv - 测试数据集;您的目标是预测概率Machine failure
sample_submission.csv - 正确格式的示例提交文件
文件下载地址:https://download.csdn.net/download/qq_37400312/87940914
竞赛地址
https://www.kaggle.com/competitions/playground-series-s3e17
目录
- 竞赛介绍
- 数据集描述
- 文件
- 竞赛地址
- 参赛项目
- 介绍
- 二分类相关知识点介绍
- 二分类
- 准确度
- 交叉熵
- 损失函数
- 评价指标
- 项目源码
- 获取数据
- 查看行
- 查看训练数据
- 查看测试数据
- 将训练数据的目标值单独拿出
- 查看训练数据的目标值
- 将训练集分割为训练集和验证集
- 查看训练集中非数值数据
- 将训练集中非数值数据进行onehot编码,数值数据转换为标准差形式
- 创建模型
- 编译模型
- 训练模型
- 验证模型
- 对测试数据进行预测
参赛项目
介绍
采用二分类方法进行数据预测,本篇文章主要以入门为主,详细介绍二元分类的使用方法,下一篇文章将详细介绍冠军的代码
二分类相关知识点介绍
二分类
分类为一个常见的机器学习问题之一。你可能想预测客户是否有可能进行购买,信用卡交易是否存在欺诈,宇宙信号是否显示有新行星的证据,或者医学检测有疾病的证据。这些都是二分类问题。
在原始数据中,类可能由“Yes”和“No”或“Dog”和“Cat”等字符串表示。在使用这些数据之前,我们将分配一个类标签:一个类将是0,另一个将是1。指定数字标签将数据置于神经网络可以使用的形式。
准确度
衡量分类问题成功与否的众多指标之一。准确度是正确预测与总预测的比率:准确度=正确数/总数。一个总是正确预测的模型的准确度得分为1.0。在所有其他条件相同的情况下,每当数据集中的类以大约相同的频率出现时,准确度是一个合理的指标。
交叉熵
准确性(以及大多数其他分类指标)的问题在于,它不能用作损失函数。随机梯度下降法(SGD)需要一个平稳变化的损失函数,但精度,作为计数的比率,在“跳跃”中变化。因此,我们必须选择一个替代品作为损失函数。这个替代品是交叉熵函数。
回想一下损失函数定义了训练期间网络的目标。通过回归,我们的目标是最小化预期结果和预测结果之间的距离。我们选择了MAE来测量这个距离。
对于分类,我们想要的是概率之间的距离,这就是交叉熵提供的。交叉熵是一种度量从一个概率分布到另一个概率分布的距离的方法。
损失函数
对于二分类问题,常用的损失函数有:
- binary_crossentropy:对Sigmoid/Logistic激活得到的概率计算loss,更适用于二分类。
- mean_squared_error:直接对不激活的预测结果计算MSE loss,不是很符合二分类的真实损失计算方式。
评价指标
评价指标也具有相似性,二分类常用:
- binary_accuracy:根据阈值将概率转为0/1预测,计算准确率。
- AUC:计算ROC曲线下的面积,作为模型区分正负样本能力的重要指标。
优化器的选择也相对灵活,常用的有: - SGD:简单梯度下降,容易设置但收敛慢,需要较小的学习率。
- Adam:运用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,收敛快。
- RMSprop:也是对每个参数的学习率进行调整,可以加速SGD收敛,在一定程度上解决了它的缺点。
项目源码
获取数据
import pandas as pd
from IPython.display import displayX_test = pd.read_csv('test.csv')
X_train = pd.read_csv('train.csv')sid = X_test["id"]
查看行
print(X_train.columns)
Index(['id', 'Product ID', 'Type', 'Air temperature [K]','Process temperature [K]', 'Rotational speed [rpm]', 'Torque [Nm]','Tool wear [min]', 'Machine failure', 'TWF', 'HDF', 'PWF', 'OSF','RNF'],dtype='object')
查看训练数据
X_train
| id | Product ID | Type | Air temperature [K] | Process temperature [K] | Rotational speed [rpm] | Torque [Nm] | Tool wear [min] | Machine failure | TWF | HDF | PWF | OSF | RNF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | L50096 | L | 300.6 | 309.6 | 1596 | 36.1 | 140 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | M20343 | M | 302.6 | 312.1 | 1759 | 29.1 | 200 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | L49454 | L | 299.3 | 308.5 | 1805 | 26.5 | 25 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | L53355 | L | 301.0 | 310.9 | 1524 | 44.3 | 197 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | M24050 | M | 298.0 | 309.0 | 1641 | 35.4 | 34 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 136424 | 136424 | M22284 | M | 300.1 | 311.4 | 1530 | 37.5 | 210 | 0 | 0 | 0 | 0 | 0 | 0 |
| 136425 | 136425 | H38017 | H | 297.5 | 308.5 | 1447 | 49.1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 136426 | 136426 | L54690 | L | 300.5 | 311.8 | 1524 | 38.5 | 214 | 0 | 0 | 0 | 0 | 0 | 0 |
| 136427 | 136427 | L53876 | L | 301.7 | 310.9 | 1447 | 46.3 | 42 | 0 | 0 | 0 | 0 | 0 | 0 |
| 136428 | 136428 | L47937 | L | 296.9 | 308.1 | 1557 | 39.3 | 229 | 0 | 0 | 0 | 0 | 0 | 0 |
136429 rows × 14 columns
查看测试数据
X_test
| id | Product ID | Type | Air temperature [K] | Process temperature [K] | Rotational speed [rpm] | Torque [Nm] | Tool wear [min] | TWF | HDF | PWF | OSF | RNF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 136429 | L50896 | L | 302.3 | 311.5 | 1499 | 38.0 | 60 | 0 | 0 | 0 | 0 | 0 |
| 1 | 136430 | L53866 | L | 301.7 | 311.0 | 1713 | 28.8 | 17 | 0 | 0 | 0 | 0 | 0 |
| 2 | 136431 | L50498 | L | 301.3 | 310.4 | 1525 | 37.7 | 96 | 0 | 0 | 0 | 0 | 0 |
| 3 | 136432 | M21232 | M | 300.1 | 309.6 | 1479 | 47.6 | 5 | 0 | 0 | 0 | 0 | 0 |
| 4 | 136433 | M19751 | M | 303.4 | 312.3 | 1515 | 41.3 | 114 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 90949 | 227378 | L51130 | L | 302.3 | 311.4 | 1484 | 40.4 | 15 | 0 | 0 | 0 | 0 | 0 |
| 90950 | 227379 | L47783 | L | 297.9 | 309.8 | 1542 | 33.8 | 31 | 0 | 0 | 0 | 0 | 0 |
| 90951 | 227380 | L48097 | L | 295.6 | 306.2 | 1501 | 41.4 | 187 | 0 | 0 | 0 | 0 | 0 |
| 90952 | 227381 | L48969 | L | 298.1 | 307.8 | 1534 | 40.3 | 69 | 0 | 0 | 0 | 0 | 0 |
| 90953 | 227382 | L52525 | L | 303.5 | 312.8 | 1534 | 36.1 | 92 | 0 | 0 | 0 | 0 | 0 |
90954 rows × 13 columns
将训练数据的目标值单独拿出
Y_train = X_train.pop('Machine failure')
查看训练数据的目标值
Y_train
0 0
1 0
2 0
3 0
4 0..
136424 0
136425 0
136426 0
136427 0
136428 0
Name: Machine failure, Length: 136429, dtype: int64
将训练集分割为训练集和验证集
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = \train_test_split(X_train,Y_train, stratify=Y_train, train_size=0.75)
查看训练集中非数值数据
X_train['Type'].unique()
array(['M', 'L', 'H'], dtype=object)
X_valid['Type'].unique()
array(['L', 'M', 'H'], dtype=object)
X_test['Type'].unique()
array(['L', 'M', 'H'], dtype=object)
将训练集中非数值数据进行onehot编码,数值数据转换为标准差形式
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer# X_train['Type'] = \
# X_train['Type'].map(
# {'L':1, 'M': 2, 'H':3}
# )
# X_valid['Type'] = \
# X_valid['Type'].map(
# {'L':1, 'M': 2, 'H':3}
# )
# X_test['Type'] = \
# X_test['Type'].map(
# {'L':1, 'M': 2, 'H':3}
# )# 数值数据的特征
features_num = ["Air temperature [K]","Process temperature [K]","Rotational speed [rpm]","Torque [Nm]","Tool wear [min]","TWF","HDF","PWF","OSF","RNF",
]
# 非数值数据的特征
features_cat = ["Type",
]# 创建标准化管道
transformer_num = make_pipeline(SimpleImputer(strategy="constant"), # there are a few missing valuesStandardScaler(),
)
# 创建onehot编码管道
transformer_cat = make_pipeline(SimpleImputer(strategy="constant"),OneHotEncoder(handle_unknown='ignore'),
)preprocessor = make_column_transformer((transformer_num, features_num),(transformer_cat, features_cat),
)X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
X_test = preprocessor.transform(X_test)input_shape = [X_train.shape[1]]
创建模型
from tensorflow import keras
from tensorflow.keras import layersmodel = keras.Sequential([layers.BatchNormalization(input_shape=input_shape),layers.Dense(256, activation='relu'),layers.BatchNormalization(),layers.Dropout(0.5),layers.Dense(256, activation='relu'),layers.BatchNormalization(),layers.Dropout(0.5),layers.Dense(1, activation='sigmoid'),
])
编译模型
model.compile(#选择Adam作为优化器optimizer='adam', #因为是二分类问题,所以使用binary_crossentropy作为损失函数loss='binary_crossentropy',#计算二分类精度,所以使用binary_accuracy作为评价指标metrics=['binary_accuracy'],)
训练模型
early_stopping = keras.callbacks.EarlyStopping(patience=5,min_delta=0.001,restore_best_weights=True,
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=10,callbacks=[early_stopping],
# verbose=0, # hide the output because we have so many epochs
)history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")# 交叉熵
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")# 准确性 Epoch 1/10
200/200 [==============================] - 6s 18ms/step - loss: 0.2060 - binary_accuracy: 0.9362 - val_loss: 0.0387 - val_binary_accuracy: 0.9965
Epoch 2/10
200/200 [==============================] - 3s 16ms/step - loss: 0.0427 - binary_accuracy: 0.9959 - val_loss: 0.0303 - val_binary_accuracy: 0.9965
Epoch 3/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0395 - binary_accuracy: 0.9956 - val_loss: 0.0289 - val_binary_accuracy: 0.9964
Epoch 4/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0310 - binary_accuracy: 0.9959 - val_loss: 0.0258 - val_binary_accuracy: 0.9964
Epoch 5/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0319 - binary_accuracy: 0.9959 - val_loss: 0.0250 - val_binary_accuracy: 0.9964
Epoch 6/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0289 - binary_accuracy: 0.9959 - val_loss: 0.0240 - val_binary_accuracy: 0.9965
Epoch 7/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0291 - binary_accuracy: 0.9959 - val_loss: 0.0234 - val_binary_accuracy: 0.9964
Epoch 8/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0292 - binary_accuracy: 0.9959 - val_loss: 0.0234 - val_binary_accuracy: 0.9964
Epoch 9/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0276 - binary_accuracy: 0.9959 - val_loss: 0.0234 - val_binary_accuracy: 0.9965
Epoch 10/10
200/200 [==============================] - 3s 17ms/step - loss: 0.0321 - binary_accuracy: 0.9948 - val_loss: 0.0226 - val_binary_accuracy: 0.9964<AxesSubplot:title={'center':'Accuracy'}>
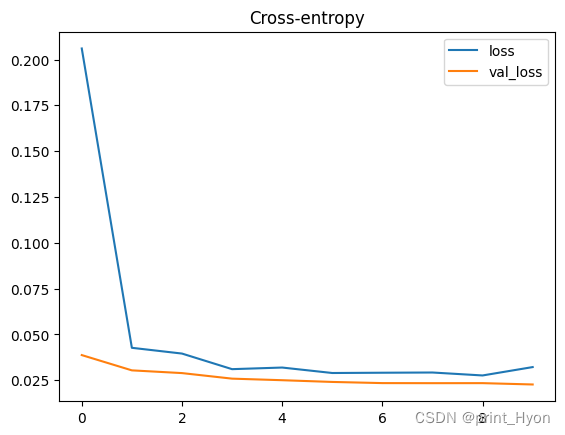
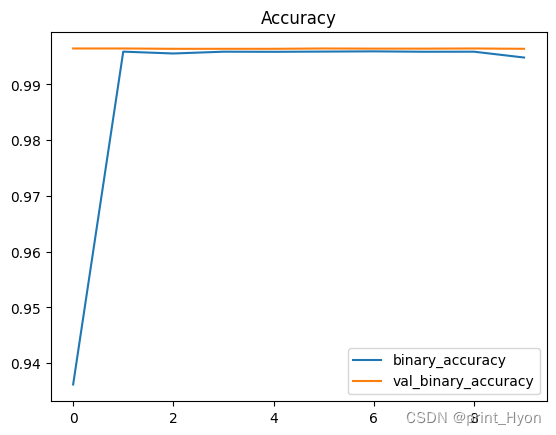
验证模型
# 获取验证集的预测结果
Y_valid_predict = model.predict(X_valid)
# 将预测结果由概率转变为0或1
threshold = 0.5
Y_valid_predict = (Y_valid_predict > threshold).astype('int')1066/1066 [==============================] - 3s 3ms/step
# 计算预测的准确性
from sklearn.metrics import accuracy_score
acc_score = accuracy_score(Y_valid_predict, y_valid)
print("Accuracy on valid set: {}%".format(acc_score*100))
Accuracy on valid set: 99.6393807904304%
对测试数据进行预测
X_test
array([[ 1.30927485, 1.12648811, -0.15104398, ..., 0. ,1. , 0. ],[ 0.98707189, 0.76543703, 1.38960729, ..., 0. ,1. , 0. ],[ 0.77226992, 0.33217574, 0.03613795, ..., 0. ,1. , 0. ],...,[-2.2886582 , -2.7006533 , -0.13664537, ..., 0. ,1. , 0. ],[-0.94614587, -1.54528986, 0.10093169, ..., 0. ,1. , 0. ],[ 1.95368077, 2.06522091, 0.10093169, ..., 0. ,1. , 0. ]])
# 获取验证集的预测结果
Y_test = model.predict(X_test)
2843/2843 [==============================] - 7s 3ms/step
# 将预测结果由概率转变为0或1
threshold = 0.5
Y_test = (Y_test > threshold).astype('int')
import numpy as np
sid = np.array(sid)
Y_test
array([[0],[0],[0],...,[0],[0],[0]])
output = pd.DataFrame({"id": sid, "Machine failure": Y_test[:, 0]})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
Your submission was successfully saved!
相关文章:
【机器学习】机器故障的二元分类模型-Kaggle竞赛
竞赛介绍 数据集描述 本次竞赛的数据集(训练和测试)是从根据机器故障预测训练的深度学习模型生成的。特征分布与原始分布接近,但不完全相同。随意使用原始数据集作为本次竞赛的一部分,既可以探索差异,也可以了解在训…...

ADB usage
查看手机设备的信息 获取设备的Android版本号 adb shell getprop ro.build.version.release 获取设备的API版本号 adb shell getprop ro.build.version.sdkAdb 获得 sdk版本 adb shell getprop ro.build.version.sdk27 Adb 获得Android版本 adb shell getprop ro.build.vers…...
模拟并通过机器学习进行预测以揭示增材制造过程中热场变化:基于ABAQUS和Python的研究实践)
利用有限元法(FEM)模拟并通过机器学习进行预测以揭示增材制造过程中热场变化:基于ABAQUS和Python的研究实践
1. 引言 增材制造(Additive Manufacturing,AM)近年来引起了大量的研究关注,这主要是因为它可以提供定制化、复杂结构的零件制造解决方案。在AM过程中,热场的分布和变化直接影响了零件的质量和性能。对此,采…...

Kafka与Flume的对比分析
Kafka与Flume的对比分析 一、Kafka和Flume1. Kafka架构2. Flume架构3. Kafka和Flume异同点 二、Kafka和Flume的性能对比1. 数据处理性能对比2. 大规模数据流处理的性能对比 三、性和稳定性对比1. 高可用集群的搭建KafkaFlume 2. 数据丢失和重复消费的问题处理KafkaFlume 四、适…...
)
docker启动redis哨兵报错(sentinel.conf is not writable: Permission denied)
Sentinel config file /usr/local/sentinel/sentinel.conf is not writable: Permission denied. Exiting… 用这个命令不报错:docker run --net host -p 6666:6666–name redis-sentinel -v /usr/mcc/redis/conf:/usr/local/sentinel/ -v /usr/mcc/redis/data/sent…...

如何编写优秀代码
最近在阅读别人写的代码,进行相应功能的修改。发现很多不规范或者比较绕的地方,总有那么几句看着多此一举,阅读别人的代码就是这样,有时候真的不懂写代码的人当时怎么想的。 例如有这么一段: 用户输入一个名字&#…...

信道编码:Matlab RS编码、译码使用方法
Matlab RS编码、译码使用方法 1. 相关函数 在MATLAB中进行RS编码的过程可以使用rsenc()函数或者comm.RSEncoder()函数。 1.1 rsenc()函数使用方法 在MATLAB中帮助中可以看到有三种使用形式,分别为 code rsenc(msg,n,k) code rsenc(msg,n,k,genpoly) code rs…...
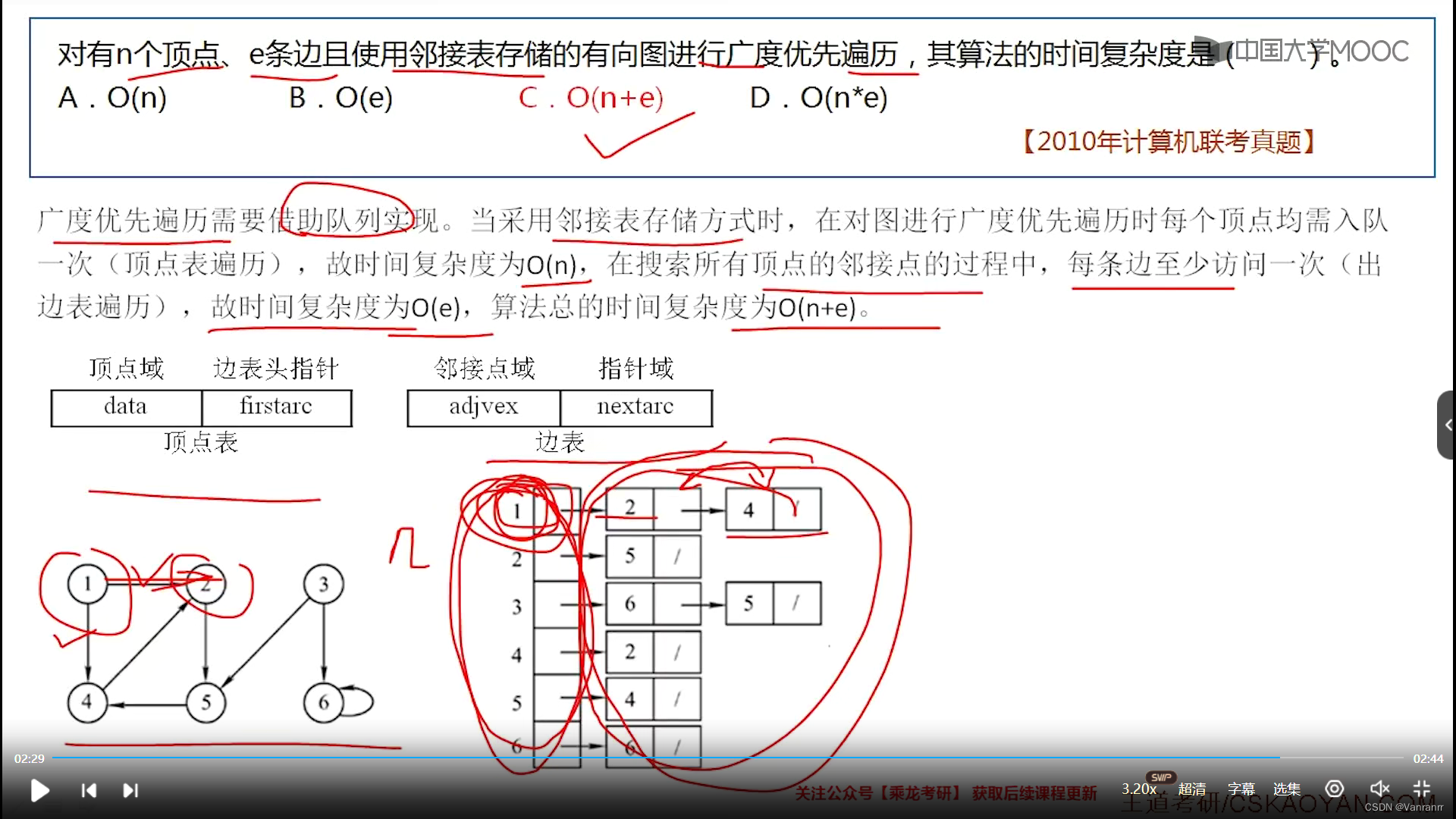
数据结构第六章 图 6.1-6.3 错题整理
6.1 6.C 加上一个点实现非连通 去除每个边都是一颗不同的生成树 一共n条边 13.C n个顶点、e条边的无向图,森林。树的角度看,除了根节点没有一条边与其对应,其他顶点都对应一条边,用顶点-边得出有多少颗树 14.A II 等于 也可以…...
12 MFC常用控件(一)
文章目录 button 按钮设置默认按钮按下回车后会响应禁用开启禁用设置隐藏设置显示设置图片设置Icon设置光标 Cbutton 类创建按钮创建消息单选按钮多选按钮 编辑框组合框下拉框操作 CListBox插入数据获取当前选中 CListCtrl插入数据设置表头修改删除 button 按钮 设置默认按钮按…...
Springboot搭配Redis实现接口限流
目录 介绍 限流的思路 代码示例 必需pom依赖 自定义注解 redis工具类 redis配置类 主拦截器 注册拦截器 介绍 限流的需求出现在许多常见的场景中: 秒杀活动,有人使用软件恶意刷单抢货,需要限流防止机器参与活动 某 api 被各式各样…...

php中的双引号与单引号的基本使用
字符串,在各类编程语言中都是一个非常重要的数据类型 网页当中的图片,文字,特殊符号,HTMl标签,英文等都属于字符串 PHP字符串变量用于存储并处理文本, 在创建字符串之后,我们就可以对它进行操作。我们可以直接在函数中使用字符串,或者把它存储在变量中 字…...

【Neo4j教程之CQL命令基本使用】
🚀 Neo4j 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,C…...
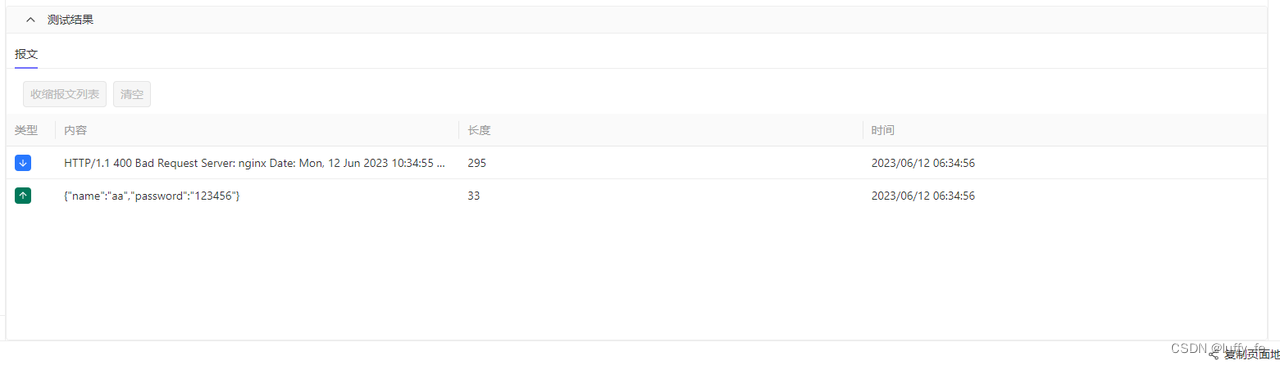
Apikit 自学日记:发起文档测试-TCP/UDP
进入某个TCP/UDP协议的API文档详情页,点击文档上方 测试 标签,即可进入 API 测试页,系统会根据API文档的定义的求头部、Query参数、请求体自动生成测试界面并且填充测试数据。 填写/修改请求参数 1.1设置请求参数 与发起HTTP协议测试类似&am…...

坚鹏:中国邮储银行金融科技前沿技术发展与应用场景第1期培训
中国邮政储蓄银行金融科技前沿技术发展与应用场景第1期培训圆满结束 中国邮政储蓄银行拥有优良的资产质量和显著的成长潜力,是中国领先的大型零售银行。2016年9月在香港联交所挂牌上市,2019年12月在上交所挂牌上市。中国邮政储蓄银行拥有近4万个营业网点…...
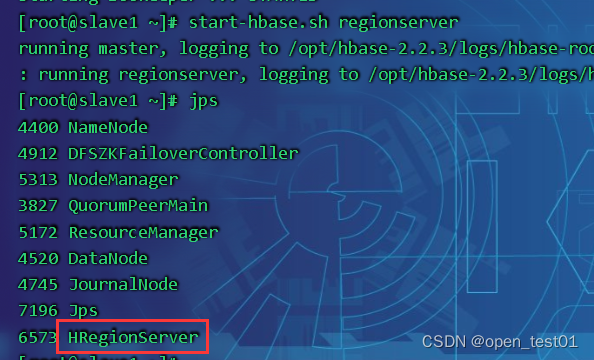
HBase分布式安装配置
首先 先安装zookeeper ZooKeeper配置 解压安装 解压 tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt 改名 mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7 在根目录下创建两个文件夹 mkdir Zlogs mkdir Zdata配置zoo.cfg文件,在解压后的ZooKeep…...

Microsoft365有用吗?2023最新版office有哪些新功能?
office自97版到现在已有20多年,一直是作为行业标准,格式和兼容性好,比较正式,适合商务使用。包含多个组件,除了常用的word、excel、ppt外,还有收发邮件的outlook、管理数据库的access、排版桌面的publisher…...

结构体的定义与实例化
结构体的定义与实例化 在Go语言中,结构体是一种用户自定义的数据类型(复合类型,而非引用类型),可以用来封装多个不同类型的数据成员。结构体的定义和实例化分别如下: 结构体的定义 结构体的定义使用关键…...

canvas详解03-绘制图像和视频
canvas 更有意思的一项特性就是图像操作能力。可以用于动态的图像合成或者作为图形的背景,以及游戏界面(Sprites)等等。浏览器支持的任意格式的外部图片都可以使用,比如 PNG、GIF 或者 JPEG。你甚至可以将同一个页面中其他 canvas 元素生成的图片作为图片源。 引入图像到 …...

VB+ACCESS高校题库管理系统设计与实现
开发数据库题库管理系统主要是为了建立一个统一的题库,并对其用计算机进行管理,使教师出题高效、快捷。 其开发主要包括后台数据库的建立、维护以及前端应用程序的开发两个方面。对于前者要求建立起数据一致性和完整性强、数据安全性好的库。而对于后者则要求应用程序功能完…...
centos 安装 nginx
1.下载nginx安装包 wget -c https://nginx.org/download/nginx-1.24.0.tar.gz 下载到了当前目录下 2.解压安装包 解压后的结果 3.安装依赖 yum -y install gcc gcc-c make libtool zlib zlib-devel openssl openssl-devel pcre pcre-devel 4. ./configure --prefix/usr/lo…...

Flow.js源码深度解析:分块算法、上传策略与事件系统的实现原理
Flow.js源码深度解析:分块算法、上传策略与事件系统的实现原理 【免费下载链接】flow.js A JavaScript library providing multiple simultaneous, stable, fault-tolerant and resumable/restartable file uploads via the HTML5 File API. 项目地址: https://gi…...
 、流程框架、实施方法与最佳实践108页PPT)
华为五级流程体系(L1-L5) 、流程框架、实施方法与最佳实践108页PPT
一、华为流程体系 业务流程持续变革促进华为业务的高速发展,持续管理变革,降低运作成本、提升运作效率,实现对客户端到端优质交付.把过去,好的方法固话下来。推广出去,提高效率和质量降低业务风险;提供多条路径和方法,…...

别再给云存储打工了!手把手教你用飞牛NAS搭建低成本监控中心,守护小店每一分钱。
对于个体商户来说,监控是刚需,但传统的方案要么一次性投入巨大,要么长期订阅云存储费用高昂。本文将介绍一种基于 飞牛NAS 萤石摄像头 的本地化监控方案,旨在帮助商户省钱、好用、省心,实现监控成本的显著降低。&…...

Z-Image-Turbo-辉夜巫女快速入门:10分钟完成Dify工作流集成与调用
Z-Image-Turbo-辉夜巫女快速入门:10分钟完成Dify工作流集成与调用 想在自己的应用里快速加上AI画图功能,但又不想写一堆复杂的代码?今天咱们就来聊聊怎么把Z-Image-Turbo-辉夜巫女这个挺火的图像生成模型,轻松集成到Dify平台的工…...

3个高效技巧:百度网盘秒传工具实现跨平台文件管理
3个高效技巧:百度网盘秒传工具实现跨平台文件管理 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 在数字化时代,高效文件传输…...

GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程
GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程 第一次接触GNSS数据处理时,面对各种数据中心的复杂目录和神秘的文件命名规则,我完全懵了。记得当时为了找一个.BSX文件,整整花了两天时间在不同网站间来回切…...

MySQL数据恢复实战:从frm和ibd文件重建完整数据表
1. MySQL数据恢复实战:从frm和ibd文件重建完整数据表 数据库管理员最怕听到的就是"数据丢了"三个字。我经历过好几次半夜被叫起来处理数据丢失的紧急情况,那种头皮发麻的感觉至今难忘。不过别担心,只要.frm和.ibd文件还在ÿ…...

利用kimi与快马平台,十分钟搭建个人博客web应用原型
最近想快速验证一个个人博客的创意,但自己从头写代码太费时间。尝试用InsCode(快马)平台的Kimi模型生成原型,没想到十分钟就搞定了可运行的Web应用,分享下这个高效流程: 明确需求梳理结构 先花2分钟在纸上画了博客的基本框架&…...

RWKV7-1.5B-g1a参数调优教程:temperature=0.1稳输出 vs 0.8活生成,效果差异实测
RWKV7-1.5B-g1a参数调优教程:temperature0.1稳输出 vs 0.8活生成,效果差异实测 1. 模型简介 rwkv7-1.5B-g1a是基于RWKV-7架构的多语言文本生成模型,特别适合以下场景: 基础问答文案续写简短总结轻量中文对话 这个1.5B参数的版…...

Fish Speech 1.5 Web界面保姆级教程:上传参考音频→文本对齐→语音生成全链路
Fish Speech 1.5 Web界面保姆级教程:上传参考音频→文本对齐→语音生成全链路 你是不是也想用AI生成和自己声音一模一样的语音?Fish Speech 1.5就能帮你实现这个愿望!这个强大的语音合成工具不仅能生成自然流畅的语音,还能通过参…...