第三章 模型篇:模型与模型的搭建
写在前面的话
这部分只解释代码,不对线性层(全连接层),卷积层等layer的原理进行解释。
尽量写的比较全了,但是自身水平有限,不太确定是否有遗漏重要的部分。
教程参考:
https://pytorch.org/tutorials/
https://github.com/TingsongYu/PyTorch_Tutorial
https://github.com/yunjey/pytorch-tutorial
文章目录
- 模型的定义
- nn.Module()
- nn.Parameters()
- module中的register是如何实现的
- Module()的一些方法
- add_module()
- children() 和 named_children()
- parameters() 和 named_parameters()
- apply(fn)
- modules() and get_submodule(target)
- state_dict()
- 模型的搭建
- 设定训练设备
- 定义自己的网络类
- 一些相关的方法
- nn.Sequential()
- nn.ModuleList()
- nn.ModuleDict()
模型的定义
模型,也就是我们常说的神经网络。它由大量相连连同的节点组成,形成类似于人体内神经的结构,所以被称为神经网络。在使用时,数据会通过网络中一层一层的节点,经过运算后得到一个结果。
神经网络,就由在数据上执行计算操作的layers(层)或者modules(模块)组成。torch.nn提供了我们组成一个神经网络需要的所有单位原件,我们可以使用torch.nn下的各个class,来组成我们的神经网络。
nn.Module()
在pytorch中所有的module都继承了nn.Module(),都是它的子类。一个神经网络也是一个module,只不过它本身包含了其它别的module。
源码链接:https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
需要注意的是 nn.Module()本身的前向传递方法forward()使用的是_forward_unimplemented,所以在使用时需要你自己去实现这个方法。
def _forward_unimplemented(self, *input: Any) -> None:r"""Defines the computation performed at every call.Should be overridden by all subclasses... note::Although the recipe for forward pass needs to be defined withinthis function, one should call the :class:`Module` instance afterwardsinstead of this since the former takes care of running theregistered hooks while the latter silently ignores them."""raise NotImplementedError(f"Module [{type(self).__name__}] is missing the required \"forward\" function")
nn.Parameters()
源码链接:https://pytorch.org/docs/stable/_modules/torch/nn/parameter.html#Parameter
nn.Parameter()它并没有继承nn.Module(), 而是继承了torch.Tensor()。它同样被放到torch.nn这个模块下面,是因为它在用于nn.Module()时会呈现出和一般的tensor不一样的特征。
它会天然地被添加到Module.parameters中去,作为一个可训练的参数使用。
module中的register是如何实现的
在构建网络时,我们基于nn.Module()定义我们自己的模型的class,并在初始化的过程中使用多个不同的layer或者module来组成我们的模型。这些layer和module都会被register到网络中,方便我们使用参数名进行访问。
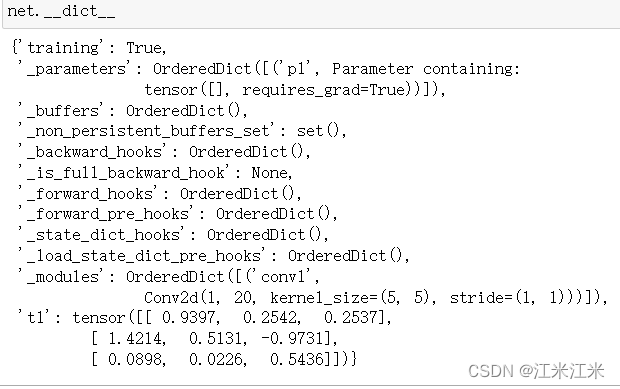
比如说我们现在定义一个非常简单的网络。这个网络在初始化时定义了三个变量,分别是self.t1:一个普通的tensor,self.p1:一个parameter和self.conv1:一个卷积层。这个卷积层,同样也继承了nn.Module(),它会被储存在Module._modules中。

self._modules会在你构建网络的过程中进行更新,更具体的讲,在你执行obj.name = value的命令时,一个名为 __setattr__的函数会起作用,判断你所构建的变量的类型。
比如说你的变量的类型是"Parameter",那么它就会被加到self._parameters中去;如果你的变量的类型是"Module",那么它就会被加到self._modules中去。下方举例了添加module的代码,具体可以参考源码链接。
[docs] def add_module(self, name: str, module: Optional['Module']) -> None:r"""Adds a child module to the current module.The module can be accessed as an attribute using the given name.Args:name (str): name of the child module. The child module can beaccessed from this module using the given namemodule (Module): child module to be added to the module."""if not isinstance(module, Module) and module is not None:raise TypeError("{} is not a Module subclass".format(torch.typename(module)))elif not isinstance(name, str):raise TypeError("module name should be a string. Got {}".format(torch.typename(name)))elif hasattr(self, name) and name not in self._modules:raise KeyError("attribute '{}' already exists".format(name))elif '.' in name:raise KeyError("module name can't contain \".\", got: {}".format(name))elif name == '':raise KeyError("module name can't be empty string \"\"")for hook in _global_module_registration_hooks.values():output = hook(self, name, module)if output is not None:module = outputself._modules[name] = module
在上方,我们已经使用net = Model()实例化了我们的网络,现在来看一下网络里面的参数情况。
可以看到,我们的’p1’,因为类别是"Parameter",所以它被添加到了net._parameters中去;我们的’conv1’,类别是"Module",所以它被添加到了net._modules中去;而我们的t1,因为啥也不是,所以单独地被放到了net.t1。和普通的class中的属性没有什么区别。
Module()的一些方法
这里举例的方法并不是很全,主要是介绍了一些我认为可以去了解的函数。更多的细节还是要自己查询文档。
https://pytorch.org/docs/stable/generated/torch.nn.Module.html
add_module()
在上方我们提供了add_module()的源码,它起到的就是register_module()的作用。
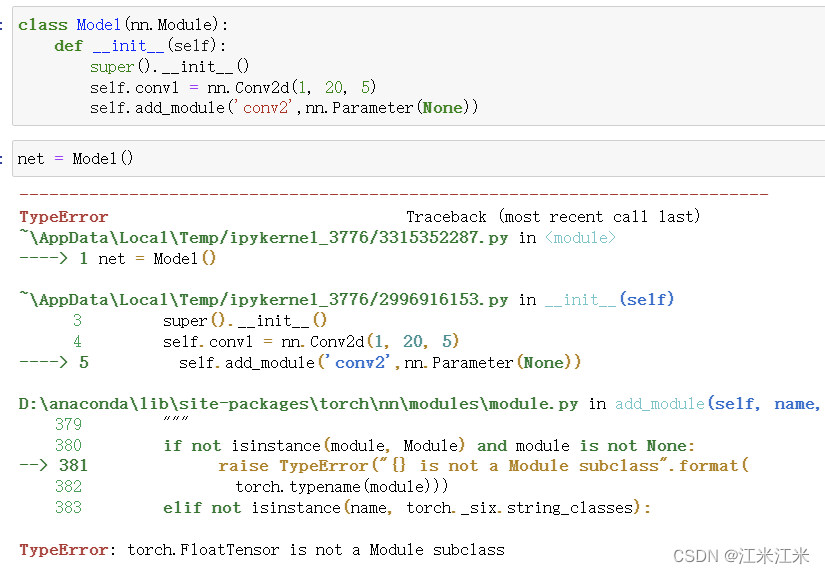
除了使用obj.name = value类似的命令定义网络中的module以外,我们也可以使用self.add_module(name, value)的方法,两者是等价的。需要注意的是,这里的value必须是一个module。
如下图,可以看到,我们用两种方法,都成功将一个卷积层加入到了net._modules中去。

当我们想使用add_module()方法加入一个非module类型的变量时,则会出现报错。从方便的角度讲,一般我们也不会使用这样的方法来构建我们的模型,还是obj.name = value更为简单常用。
children() 和 named_children()
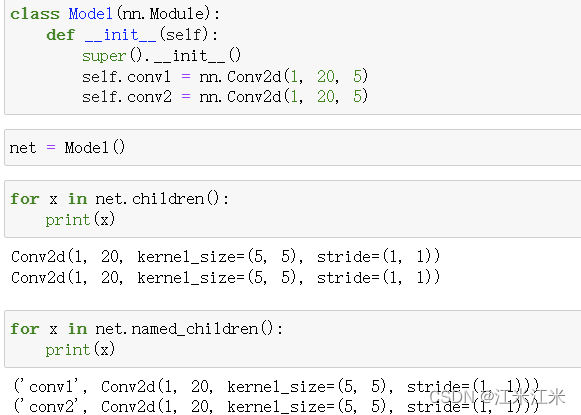
children()和named_children()都返回了一个迭代器,两者也是很好区分。children()只返回了定义的模型中的module,而named_children()在返回module的同时,还返回了module的名字。
parameters() 和 named_parameters()
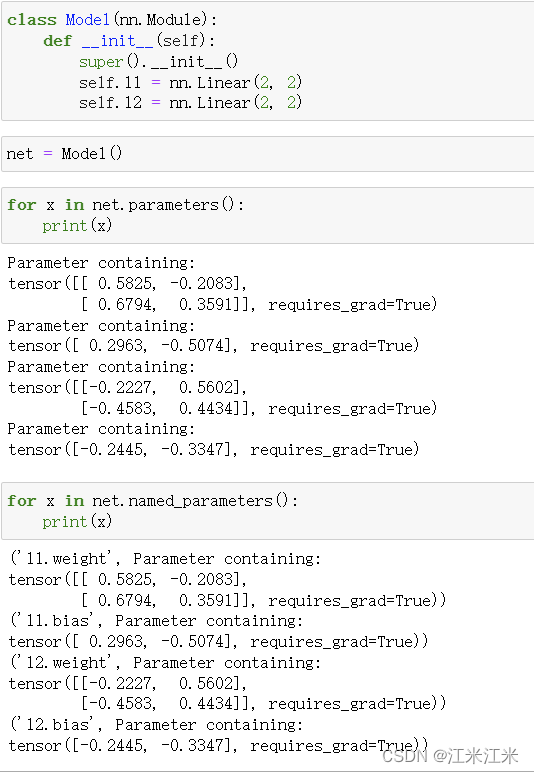
类似于上面的children()和named_children(),parameters()和named_parameters()同样也返回了一个迭代器,只不过迭代器中的内容不再是module和它的名字,而是换成了module._parameters。
我们在这里使用Linear层做例子。
apply(fn)
apply()的作用是在你模型的所有module上执行同一个函数,因此输入参数是一个函数,在使用时,它会对你的self.children()的结果进行遍历,并在每个结果上递归地都执行传入的函数。
def apply(self, fn)for module in self.children():module.apply(fn)fn(self)return self
比如说,在对模型进行权重初始化时,就可以使用这个函数。在tutorial文档中也给出了相应的例子。下方的代码给出了一个初始化权重的方法,假如module是一个线性层,就将它的权重的数值全部别为1。我们在上方定义的模型上使用这个函数。
@torch.no_grad()
def init_weights(m):print(m)if type(m) == nn.Linear:m.weight.fill_(1.0)print(m.weight)
可以看到在我们的结果中,net中的l1和l2的weights都受到了影响,但是bias没有发生变化。你也可以使用类似的方法改变它的bias或者别的module中的权重值。

modules() and get_submodule(target)
modules()函数也可以返回我们的网络中的module,来看一下它和children()的区别。使用我们之前构建的有两个卷积层的网络,可以看到net.modules()除了返回它的submodule外,还返回了它本身。

而get_submodule(target)中的target,代表你想获得的module的name,使用name可以获得对应的module。

state_dict()
state_dict()是一个比较重要的方法,它可以orderdict的形式返回我们的模型中各个模块的权重和权重名。
以我们定义的包含两个线性层的模型为例子,state_dict()返回了l1的weight和bias以及l2的weight和bias。并且我们可以通过名称来检测对应的权重值。

模型的搭建
设定训练设备
假设我们现在有一个搭建好的模型net,我们可以将模型放到我们希望使用的设备上,从而利用设备的加速能力。
在pytorch tutorial同样给出了代码样例。
device = ("cuda"if torch.cuda.is_available()else "mps"if torch.backends.mps.is_available()else "cpu"
)
print(f"Using {device} device")
net.to(device)
在确定设备后,我们使用.to()函数,就可以把网络放到对应的设备上。
定义自己的网络类
定义模型的三要素:
- 继承nn.Module()
- 在__init__中定义组件
- 在forward()中确定组件使用的顺序
我们要基于nn.Module()类来构建我们自己的网络,并且在__init__中进行初始化,我们可以使用各种各样的组件来完成我们的网络,并在forward中决定我们的输入在各个组件中传递的顺序。
需要注意的是,这个顺序不是随便决定的,我们要考虑我们使用的组件的输入维度和输出维度。
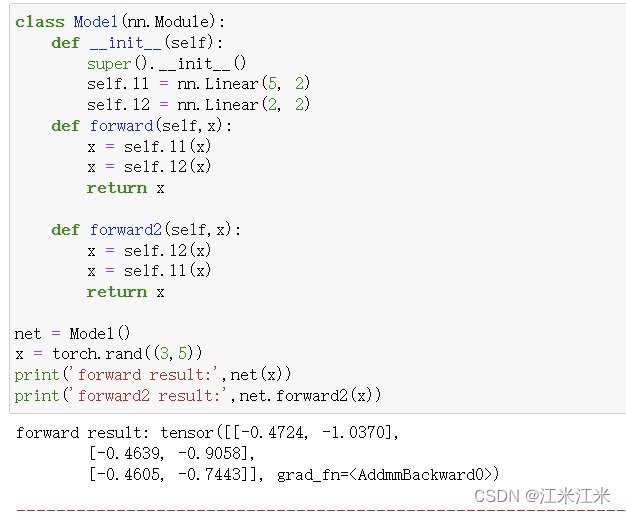
比如说下面这个例子,我们定义了两个forward,其中第一个forward()会在__call__()中被调用,所以我们可以使用net(x)直接调用第一个forward(),第二个forward2()则需要用函数名调用。
在这个例子中,我们定义了两个线性层,其中l1的输入大小为5,输出大小为2。l2的输入大小为2,输出大小为2。而我们创建的输入变量的大小是(3,5),相当于batchsize = 3,channel=5,因此在先使用l1后使用l2时,代码可以成功执行。但是反过来后代码就会报错。
一些相关的方法
nn.Sequential()
nn.Sequential()方法也继承了nn.Module(),它的作用是作为一个container,把组件按照入参时的顺序添加进来,并且在forward()时,传入的数据也会按照顺序通过这些组件。
nn.Sequential()的传入参数有两种形式,第一种是OrderedDict[str, Module],其中有序字典的key代表的是你给要传入的module起的名字。如果使用的不是有序字典作为输入,而是直接使用的Module,那么这个方法会按从0开始的index给组件命名。
具体可以直接看源码:
可以看到,在__init__()函数中,该方法对输入的组件进行了遍历,并且使用add_module()进行register。
def __init__(self, *args):super().__init__()if len(args) == 1 and isinstance(args[0], OrderedDict):for key, module in args[0].items():self.add_module(key, module)else:for idx, module in enumerate(args):self.add_module(str(idx), module)
我们给出一个非常简单的样例,我们使用nn.Sequential()构建一个简单的网络,模型里只有两个线形层。这个定义好的网络是直接可以使用的。

需要注意的是,nn.Sequential()在forward()中进行数据的传递时是按照组件传入的顺序进行的,因此你的组件顺序不对,仍然会出现报错。
nn.ModuleList()
nn.ModuleList()方法也继承了nn.Module(),它和nn.Sequential()一样,也是一个container,但是两者也存在一些区别。
nn.ModuleList()中没有实现forward()的方法,它只是把传入的组件放到了一个类似于python中list的序列中。
nn.ModuleList()中也不可以使用OrderedDict作为输入。
nn.ModuleList()中传入组件时不需要考虑组件的顺序。
以下给入了一个使用的例子。
class MyModule(nn.Module):def __init__(self):super().__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])def forward(self, x):# ModuleList can act as an iterable, or be indexed using intsfor i, l in enumerate(self.linears):x = self.linears[i // 2](x) + l(x)return x
要注意的是我们不能使用python的list来代替nn.Module(),因为之前提到过在进行register时会判断你所创建的obj.name = value的value的类别,假如这个类不是Module,则不会被add_module()添加到self._modules中去。
nn.ModuleDict()
nn.ModuleDict()与nn.ModuleList()类似,不同的是它传入的是一个dict。这也弥补了nn.ModuleList()中不能给组件起名字的缺点,传入的dict中的key就代表了对应组建的名字。
这个方法同样也没有实现forward()函数。
下方给出一个使用的例子。在forward()中调用组件时,用的也不再是nn.ModuleList()中的index,而是dict中的key。
class MyModule(nn.Module):def __init__(self):super().__init__()self.choices = nn.ModuleDict({'conv': nn.Conv2d(10, 10, 3),'pool': nn.MaxPool2d(3)})self.activations = nn.ModuleDict([['lrelu', nn.LeakyReLU()],['prelu', nn.PReLU()]])def forward(self, x, choice, act):x = self.choices[choice](x)x = self.activations[act](x)return x
相关文章:
第三章 模型篇:模型与模型的搭建
写在前面的话 这部分只解释代码,不对线性层(全连接层),卷积层等layer的原理进行解释。 尽量写的比较全了,但是自身水平有限,不太确定是否有遗漏重要的部分。 教程参考: https://pytorch.org/tutorials/ https://githu…...

深度学习一些简单概念的整理笔记
大概看了一点动手学深度学习,简单整理一些概念。 一些问题 测试结果 Precision-Recall曲线定性分析模型精度average precision(AP) 平均精度 Precision :检索出来的条目中有多大比例是我们需要的。 一些概念 损失函数(loss function&…...

Vue3中引入Element-plus
安装 npm install element-plus --save完整引入 打包后体积很大,适合学习,不适合生产。 此方法对于 vite 和 cli 脚手架创建的vue3均适用 // main.ts import { createApp } from vue //引入element-plus import ElementPlus from element-plus //引入…...

如何查看 Facebook 公共主页的广告数量上限?
作为Facebook的资深人员,了解如何查看公共主页的广告数量上限对于有效管理和优化广告策略至关重要。本文将详细介绍如何轻松查看Facebook公共主页的广告数量上限,以帮助您更好地掌握广告投放策略。 一、什么是Facebook公共主页的广告数量上限?…...
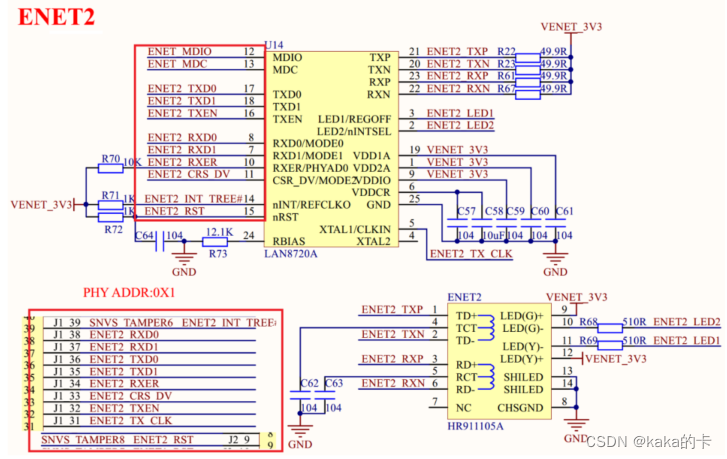
U-Boot移植 (2)- LCD 驱动修改和网络驱动修改
文章目录 1. LCD 驱动修改1.1 修改c文件配置1.2 修改h文件配置1.3 编译测试 2. 网络驱动修改2.1 I.MX6U-ALPHA 开发板网络简介2.2 网络 PHY 地址修改2.3 删除 uboot 中 74LV595 的驱动代码2.4 添加开发板网络复位引脚驱动2.5 更新 PHY 的连接状态和速度2.6 烧写调试2.7 测试一下…...

Ubuntu 23.10 现在由Linux内核6.3提供支持
对于那些希望在Ubuntu上尝试最新的Linux 6.3内核系列的人来说,今天有一个好消息,因为即将发布的Ubuntu 23.10(Mantic Minotaur)已经重新基于Linux内核6.3。 Ubuntu 23.10的开发工作于4月底开始,基于目前的临时版本Ubu…...

Python 学习之NumPy(一)
文章目录 1.为什么要学习NumPy2.NumPy的数组变换以及索引访问3.NumPy筛选使用介绍筛选出上面nb数组中能被3整除的所有数筛选出数组中小于9的所有数提取出数组中所有的奇数数组中所有的奇数替换为-1二维数组交换2列生成数值5—10,shape 为(3,5)的二维随机浮点数 NumP…...
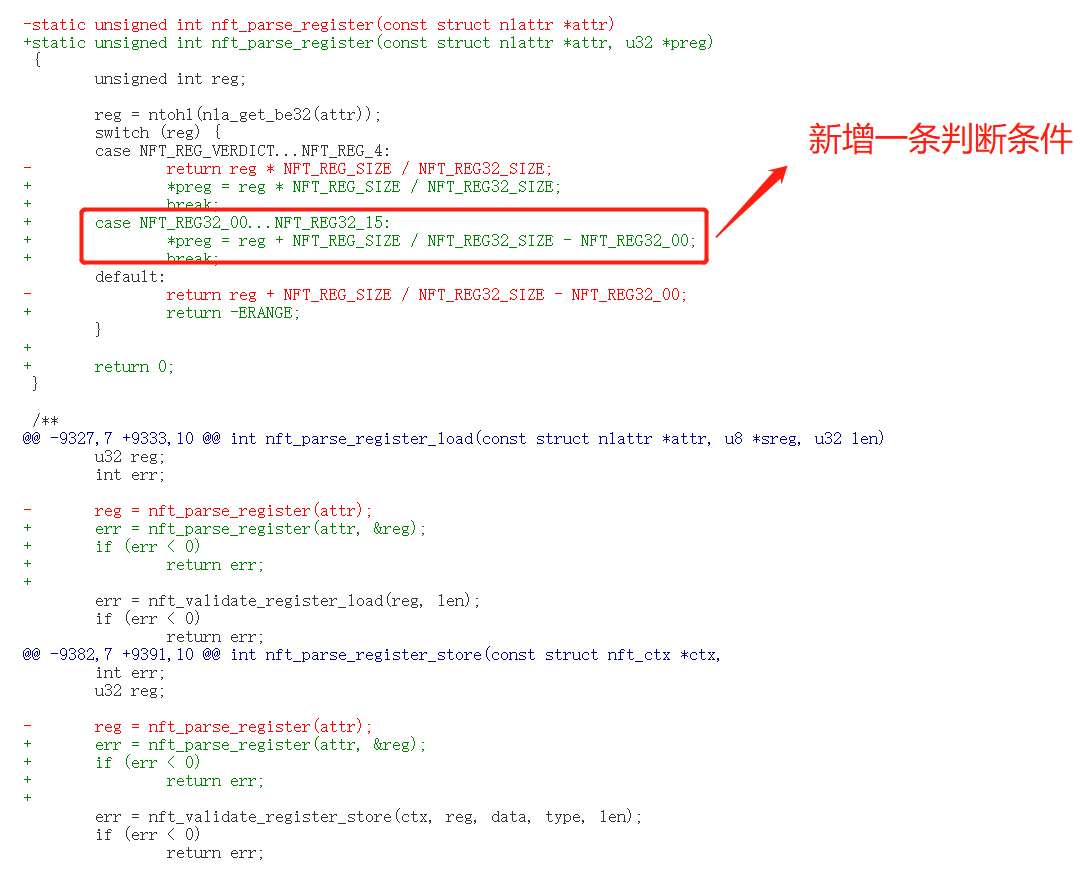
Nftables栈溢出漏洞(CVE-2022-1015)复现
背景介绍 Nftables Nftables 是一个基于内核的包过滤框架,用于 Linux 操作系统中的网络安全和防火墙功能。nftables 的设计目标是提供一种更简单、更灵活和更高效的方式来管理网络数据包的流量。 钩子点(Hook Point) 钩子点的作用是拦截数…...
【C++】 Qt-事件(上)(事件、重写事件、事件分发)
文章目录 事件重写事件事件分发 事件 事件(event)是由系统或Qt本身在不同的时刻发出的。比如,当用户按下鼠标,敲下键盘,或窗口需要重新绘制的时候,都会发出一个相应的事件。一些事件是在对用户操作做出响应…...
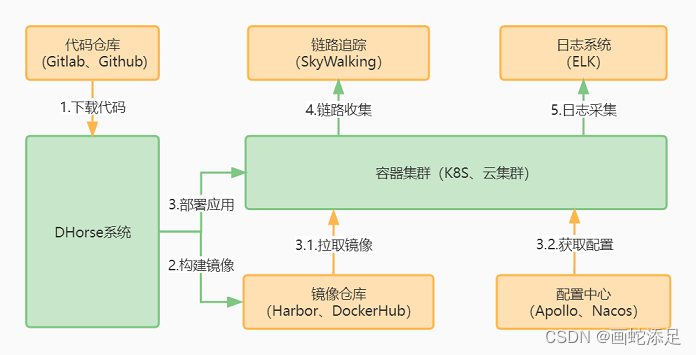
k8s部署springboot
前言 首先以SpringBoot应用为例介绍一下k8s的部署步骤。 1.从代码仓库下载代码,比如GitLab; 2.接着是进行打包,比如使用Maven; 3.编写Dockerfile文件,把步骤2产生的包制作成镜像; 4.上传步骤3的镜像到远程…...

备战秋招002(20230704)
文章目录 前言一、今天学习了什么?二、关于问题的答案1.线程池2.synchronized关键字3、volatile 总结 前言 提示:这里为每天自己的学习内容心情总结; Learn By Doing,Now or Never,Writing is organized thinking. …...

游泳买耳机买什么的比较好,列举几款实战性好的游泳耳机
对于运动用户来说,在运动时都会选择听一些节奏感比较强的音乐,让自己运动是更有活力。现在已经是三伏天中的前伏期间,不少人会选择在三伏天的日子里进行减肥瘦身,耳游泳已经成为很多人都首选运动,游泳是非常好的有氧运…...
【无线传感器】使用 MATLAB和 XBee连续监控温度传感器无线网络研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Java基础-多线程JUC-生产者和消费者
1. 生产者与消费者 实现线程轮流交替执行的结果; 实现线程休眠和唤醒均要使用到锁对象; 修改标注位(foodFlag); 代码实现: public class demo11 {public static void main(String[] args) {/*** 需求&#…...
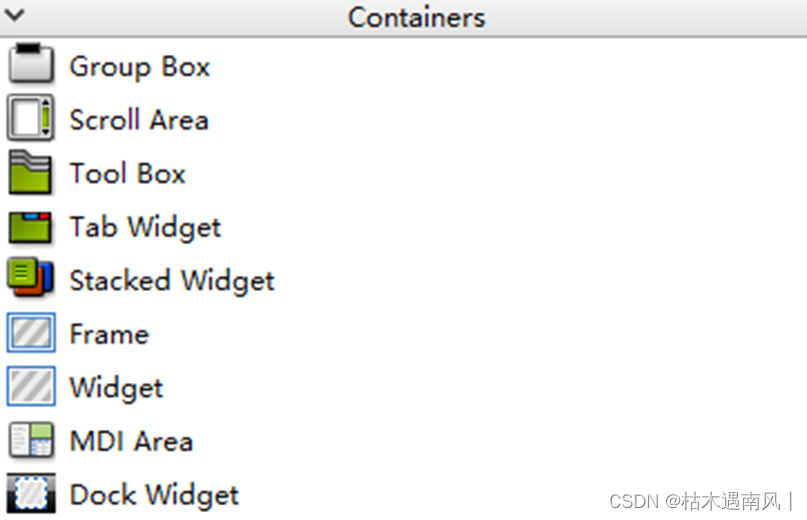
day2 QT按钮与容器
目录 按钮 1、QPushButton 2、QToolButton 3、QRadioButton 4、QCheckBox 示例 容器 编辑 1. QGroupBox(分组框) 2. QScrollArea(滚动区域) 3. QToolBox(工具箱) 4. QTabWidget(选…...
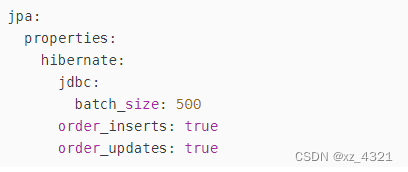
JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题 使用jpa saveAll接口的话需要了解原理: TransactionalOverridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<…...

为啥离不了 linux
Linux与Windows都是十分常见的电脑操作系统,相信你对它们二者都有所了解!在你的使用过程中,是否有什么事让你觉得在Linux上顺理成章,换到Windows上就令你费解?亦或者关于这二者你有任何想要分享的,都可以在…...

基于分形的置乱算法和基于混沌系统的置乱算法哪种更安全?
在信息安全领域中,置乱算法是一种重要的加密手段,它可以将明文进行混淆和打乱,从而实现保密性和安全性。常见的置乱算法包括基于分形的置乱算法和基于混沌系统的置乱算法。下面将从理论和实践两方面,对这两种置乱算法进行比较和分…...

pve使用cloud-image创建ubuntu模板
首先连接pve主机的终端 下载ubuntu22.04的cloud-image镜像 wget -P /opt https://mirrors.cloud.tencent.com/ubuntu-cloud-images/jammy/current/jammy-server-cloudimg-amd64.img创建虚拟机,id设为9000,使用VirtIO SCSI控制器 qm create 9000 -core…...
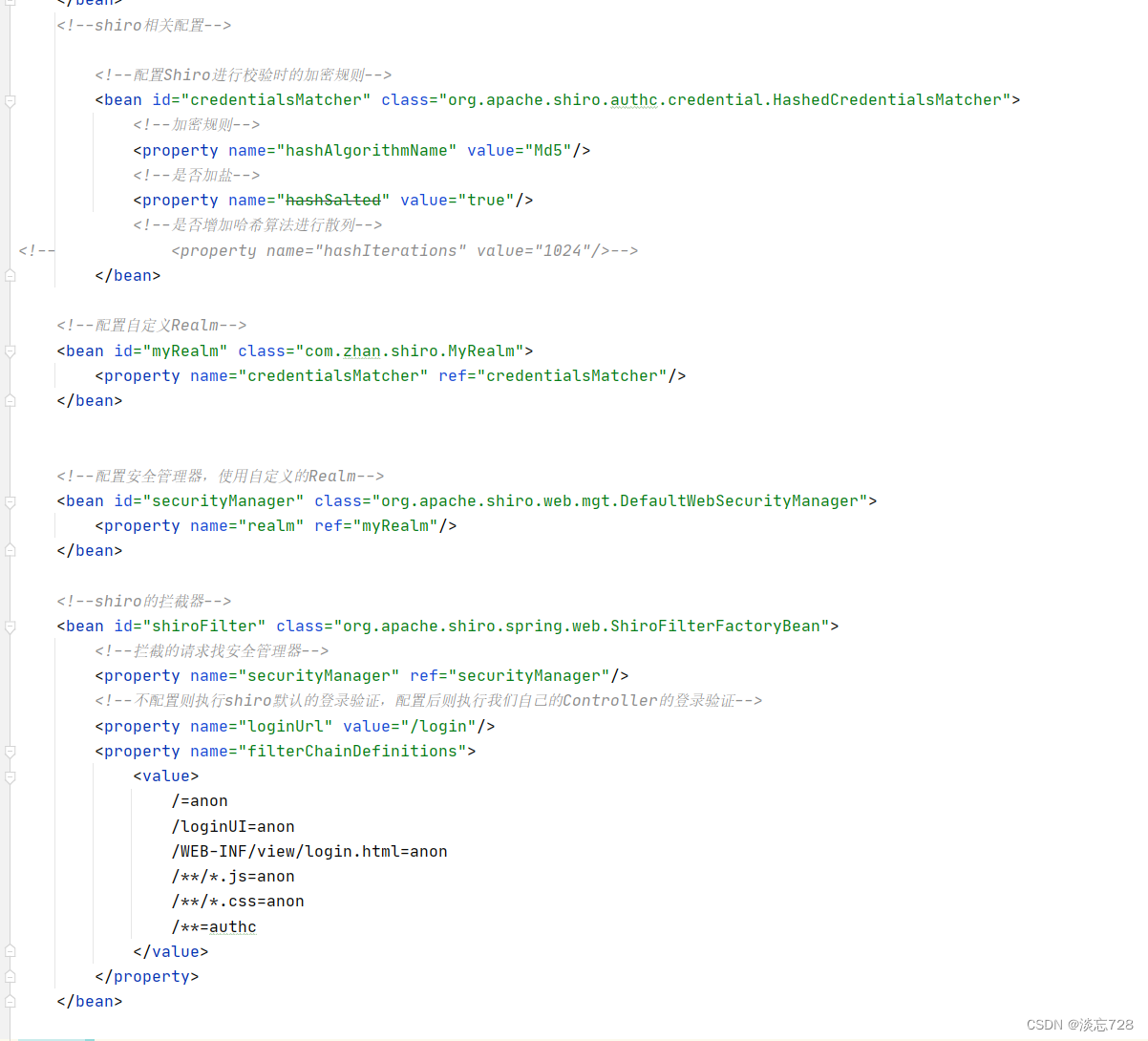
shiro入门
1、概述 Apache Shiro 是一个功能强大且易于使用的 Java 安全(权限)框架。借助 Shiro 您可以快速轻松地保护任何应用程序一一从最小的移动应用程序到最大的 Web 和企业应用程序。 作用:Shiro可以帮我们完成 :认证、授权、加密、会话管理、与 Web 集成、…...

COMSOL 6.1 激光粉末床熔融气孔缺陷演化仿真:开启微观世界的探索之旅
COMSOL 6.1 激光粉末床熔融气孔缺陷演化仿真案例模型 本案例选用层流和流体传热模块,采用水平集法,考虑材料的热物性以及激光加工过程中的马兰戈尼效应、熔融金属表面张力、反冲压力、相变潜热、热对流和热辐射,建立含气孔缺陷的二维数值仿真…...

LeetCode 11. Container With Most Water 题解
LeetCode 11. Container With Most Water 题解 题目描述 给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0) 。找出其中的两条…...

RTX 3090环境下的BEVFusion实战部署:从源码编译到多模态训练调优
1. RTX 3090环境准备与BEVFusion适配 在RTX 3090上部署BEVFusion最大的挑战就是硬件与软件版本的兼容性问题。官方推荐的环境是CUDA 9.2和PyTorch 1.3.1,但这对于RTX 3090来说完全不适用——30系显卡需要CUDA 11才能发挥全部性能。我刚开始尝试直接按照官方文档安装…...

如何用Nucleus Co-Op实现本地多人游戏:5个维度解析开源工具的技术突破与应用价值
如何用Nucleus Co-Op实现本地多人游戏:5个维度解析开源工具的技术突破与应用价值 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 当你和…...
)
野火挑战者开发板实战:用STM32CubeMX从零配置GPIO、UART和ADC(附完整代码)
野火挑战者开发板实战:从零构建环境监测系统 刚拿到野火挑战者开发板时,面对密密麻麻的引脚和复杂的配置选项,很多初学者会感到无从下手。本文将带你用STM32CubeMX图形化工具,快速配置GPIO、UART和ADC这三个最常用的外设ÿ…...

从Stable Diffusion到多模态大模型:图文交错数据如何让AI学会‘边想边画’?
图文交错数据:多模态大模型实现"边想边画"的关键突破 当Stable Diffusion以惊艳的画质震惊世界时,人们很快发现它存在一个根本局限——这个能画出精美图像的模型,却无法理解自己笔下的内容。与此同时,擅长理解图像的多模…...

如何快速实现ngx-bootstrap国际化:多语言应用开发完整指南
如何快速实现ngx-bootstrap国际化:多语言应用开发完整指南 【免费下载链接】ngx-bootstrap Fast and reliable Bootstrap widgets in Angular (supports Ivy engine) 项目地址: https://gitcode.com/gh_mirrors/ng/ngx-bootstrap ngx-bootstrap作为Angular生…...

OpenAddresses多语言支持:全球地址数据的终极处理指南
OpenAddresses多语言支持:全球地址数据的终极处理指南 【免费下载链接】openaddresses A global repository of open address data. 项目地址: https://gitcode.com/gh_mirrors/op/openaddresses OpenAddresses是全球最大的开源地址数据仓库,提供…...
)
收藏!程序员转型AI大模型应用开发,必学四大核心技能(小白友好版)
当下AI大模型风口持续爆发,越来越多程序员想抓住机遇转型入局,但大多陷入“盲目跟风、无从下手、学了没用”的困境——其实,转型AI大模型应用开发无需急于求成,不用追求“面面俱到”,先吃透核心技能,搭建完…...

在供应链与资本获取驱动下,近半数全球高管计划于未来12个月内拓展美国业务布局
• 45%的企业高层管理人员计划在未来12个月内设立美国法律实体;另有27%表示将在未来两至三年内考虑进入美国市场 • 65%的受访者将供应链或制造效率视为推动赴美扩张的首要驱动因素 • 88%的企业将联邦及州层面的税务申报认定为美国合规中最具挑战性的领域 CSC最新研…...